

4.2.3 Метод разбора
В качестве метода разбора был выбран нисходящий метод, а именно, не рекурсивный предиктивный синтаксический анализ, в зарубежной литературе его также называют таблично управляемым LL(k) анализом.
В этом методе явно используется стек в отличие от рекурсивного спуска. На рис. 4.3 схематично представлен синтаксический анализатор управляемый таблицей синтаксического анализа. Он имеет входной буфер, стек, содержащий как терминалы, так и нетерминалы, таблицу синтаксического анализа, предварительно построенную, и выходной буфер.

Рисунок 4.3 – Модель синтаксического анализатора, управляемого таблицей
Синтаксический анализатор управляется программой, которая рассматривает символ на вершине стека Xи текущий входной символa. Если Xявляется нетерминалом, синтаксический анализатор выбирает X–продукцию в соответствиис записью M[X,a] в таблице синтаксического анализа M(здесь может выполняться дополнительный код, например, для построения узла дерева разбора илипредо смотра второго символа). В противном случае проверяется соответствие между терминалом Xи текущим входным символом a.
Прежде чем рассматривать алгоритм синтаксического анализа рассмотрим понятие таблицы синтаксического анализа и способ её построения.Таблица представляет собой двумерный массив, каждая ячейка которого адресуется парой [нетерминал, терминал].Ячейка может либо быть пустой,либо содержать продукцию.
Для построения таблицы необходимо ввести понятие функций – FIRSTиFOLLOW, связанные с грамматикой G.
Определим FIRST(a), где a–произвольная строка символов грамматики, как множество терминалов, с которых начинаются строки, порождаемые a. Если a →* ε, то ε FIRST(a).
Определим FOLLOW(A)для нетерминала Aкак множество терминалов a,которые могут располагаться непосредственно справаот Aв некоторой сентенциальной форме, т.е. множество терминалов a, таких,чтосуществует порождение вида S→*aAabдля некоторыхaиb. Кроме того, если Aможет оказаться крайним справа символом некоторой сентенциальной формы, тоEOF FOLLOW(A). Подробное описание пошаговых правил по вычислению этих функций можно найти в литературе [2].
Теперь можно описать метод построения таблицы синтаксического анализа с использованием введённых функций и грамматики G.Он заключается в применение для каждой продукции грамматики следующих действий:
Для каждого терминала aиз FIRST(a) добавляем A→aв ячейку M[A,a];
Если ε FIRST(a), то для каждого терминала bизFOLLOW(A)добавляемA→aв M[A,b].Еслиε FIRST(a) иEOF FOLLOW(A), тодобавляемA→aтак же ивM[A,EOF].
Если после выполнения этих действий ячейка M[A,a] осталась без продукции, устанавливаем её значение равным error (это значение обычно представляется пустой записью таблицы).
На рисунке 4.4 приведена таблица синтаксического анализа для грамматики LISMA+, построенная по описанному методу. Записи чисел в ячейках обозначают номер продукции, запись synуказываетна синхронизирующий токен при восстановлении после ошибки. Далее об этой записи будет рассказано более подробно.

Рисунок 4.4 “Таблица синтаксического анализа”
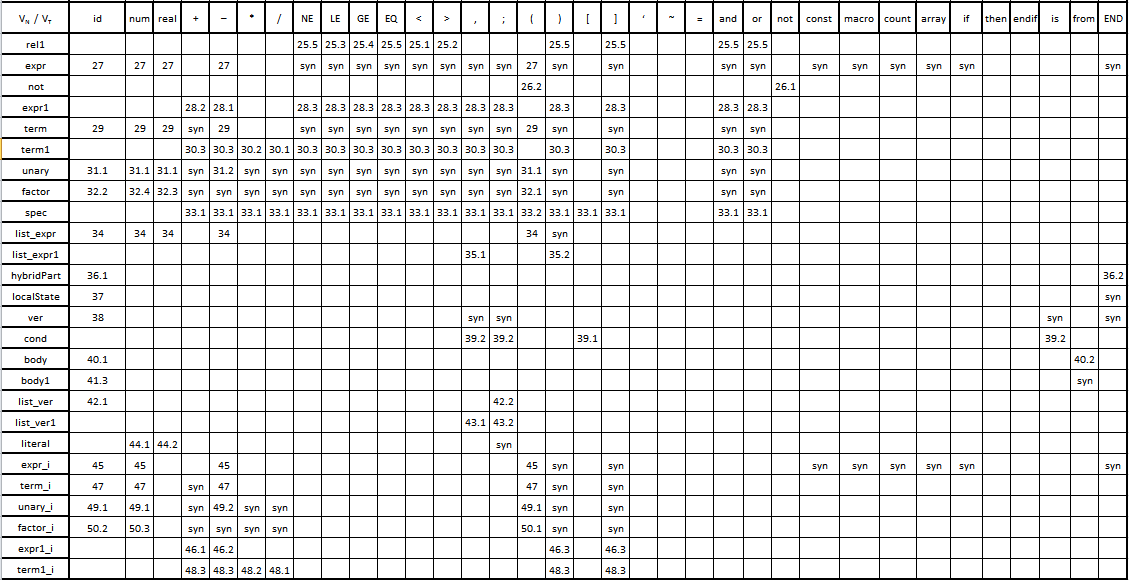
Продолжение рисунка 4.4
Теперь рассмотрим алгоритм разбора, представленный на рис. 4.5.

Рисунок 4.5– Алгоритм предиктивного синтаксического анализа
Входными данными для него служит входной поток токенов и таблица синтаксического анализа M, выходными данными - подтверждение принадлежности входной строки языку порождаемой данной грамматикой, иначе сообщение об ошибке. Изначально стартовый символ грамматики Programнаходится на вершине стека.Этот алгоритм имитирует левое порождение цепочек языка. По этой причине указатель входного потока указывает на крайний слева символ.