

Семантическое ядро
Первое, чем мы займемся - научимся грамотно подбирать семантическое ядро, которое будет приносить людей, а не радовать глаз красивыми цифрами.
В первую очередь забудьте про Статистику ключевых слов от поисковой системы Яндекс - это самый неточный сервис, а учитывая спам прессинг - тем более. Ориентируясь на эту статистику - вы поддерживаете seo спамеров и продвигаете и без того бестолковые запросы дальше, накручивая показы все больше и больше.
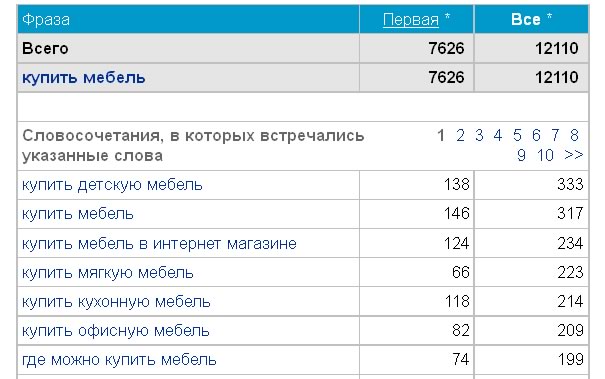
Для примера - возьмем фразу "купить мебель".
Статистика ключевых слов поисковой системы Яндекс дает следующую статистику – 179982 показов в месяц:
 И
все оптимизаторы и клиенты радуются
большой цифре, но:
И
все оптимизаторы и клиенты радуются
большой цифре, но:
точная фраза "купить мебель", дает уже 4050

точная фраза именно в этой форме "!купить !мебель", дает и того меньше – 3541

запрос не супер мега ВЧ, а банально НЧ.
Что же мы делаем, чтобы не терять время и не брать бестолковые запросы?
Методика сбора семантического ядра для молодых сайтов
Многие используют программу "Key Collector", но на входе - это банальный парсинг Вордстата, нескольких сервисов и опять же бестолковая статистика.
Так куда же двигаться нам?
В самом начале, мы выбираем тематику, в которой вы будем работать, то есть еще до того, как создать сайт – мы думаем о семантике.
Есть несколько путей развития:
партизанский маркетинг (проиндексированые страницы в поисковых системах, SEMRush, Alexa)
поисковые подсказки (Яндекс, Google, Nigma, Mail.ru, Rambler, Bing, Yahoo)
парсинг статистики Рамблера (http://adstat.rambler.ru/wrds/)
Использование партизанского маркетинга оправдано всегда, особенно когда тематика хоть немного конкурентна - сами же спамеры seo`шники вам подскажут, какие запросы они двигают.
Самое стандартное – посмотреть проиндексированные страницы в Яндекс и Google. На выходе мы видим все title, в которых прослеживается текущее положение дел – обычно запросы через запятую, либо автогенерация. Самое важное в данном случае – не повторить ошибки своих конкурентов, а понять, что они делают неправильно.
Поисковые подсказки, необходимы для постоянного привлечения трафика. Подсказки генерируются на основе показов и того, что вбивается в поисковой строке. Как ни странно - это самое слабое звено в поиске и их очень часто накручивают. Поэтому стоит проверять то, что вы берете из подсказок - все запросы с названиями, телефонами и прочим - накручены, эти запросы следует пробивать и по другим сервисам - в первую очередь по SEMRush, о нем поговорим ниже.
Не забывайте, что поисковых систем у нас больше, чем две, поэтому подсказки стоит собирать из всех источников.
Статистика Рамблера - учитывайте то, что выдача в нем от поисковой системы Яндекс, на данный момент - статистика основана на просчете введенных в строку поиска запросов. Теоретически можно рассчитать, сколько будет посетителей в Яндексе, но и тут есть подвох - разница в аудиториях слишком высока (Рамблер – основная аудитория старше 30-35 лет), поэтому довольствуемся более точной статистикой, не более.
Пошаговая схема сбора семантического ядра:
обзор тематики и пробивка конкурентов (проиндексированные страницы - запросы в них)
поиск трафогенерящих запросов и пустышек (Alexa, SEMRush, Рамблер)
просмотр и сбор подсказок (за вычетом накрученых, о чем было сказано выше)
сбор трендовых запросов (Alexa, SEMRush) с примерной ориентацией на Директ, но только в статистике по месяцам, чтобы видеть реальные тренды.
В идеале, мы получаем следующий список запросов:
тренды (выбираем те, что только начали расти и рост постоянный)
трафогенерящие запросы (подсказки и высокочастотные запросы)
околотематичные запросы, для сбора дополнительного трафика
Все это мы собираем на отдельные листы Excel для дальнейшей работы.
Какие колонки нам необходимы?
запрос
количество результатов (выбирайте Яндекс или Google)
конкурентность ( по SEMRush или количество страниц по слову в кавычках в Яндексе)
Методика сбора семантического ядра для старых сайтов
Все то, о чем мы говорили выше - относится сугубо к молодым сайтам, либо к сайтам, которых еще нет.
Если мы берем старый сайт - все по-другому, во всяком случае на первых этапах:
ставим Яндекс Метрику
добавляемся в Яндекс Вебмастер
добавляемся в Google Вебмастер
ставим Live Internet
используем шаги, описанные выше
Что мы ищем?
по Метрике ищем слова не в топе
по Метрике и Live Internet - слова приносящие трафик
слова с максимум отказов, зачем? Будем улучшать поведенческие.
Это именно те слова, над которыми стоит работать.
Из них и будем выбирать те, что будут приносить трафик.
Итак:
по Яндекс Метрике берем все те запросы, которых нет на первой странице - можно двигать дальше
в Яндекс Вебмастер - смотрим слова с высоким и низким CTR - будем улучшать позиции или улучшать сниппет, в зависимости от ситуации
в Google Вебмастер - смотрим тоже, что и в предыдущем случае
Live Internet нам покажет те запросы. что приносят трафик, те, что не в топе - двигаем дальше
Вывод:
у нас есть статистика - достаточно недели для сбора семантического ядра
думаем про конверсии исходя из вебмастер панелей
Грань ВЧ, СЧ и НЧ
Важно понимать, что мы не привязываемся к названиям и границам. Нас не должно волновать НЧ запрос или нет, нам важнее понимать – есть конкуренция по запросу или нет? Выше уже упоминалась возможность проверить конкуренцию – ищем слово в кавычках и смотрим на количество документов. Чем больше документов – тем более конкурентен запрос.
А теперь к цифрам – запрос можно считать сложным, за что придется побороться, если количество документов более миллиона. Все что ниже порога в 500000 документов – можно продвигать бесплатно.
Что мы перекладываем на главную? Естественно, самый конкурентный запрос, над которым надо будет работать, все остальное раскидываем по внутренним страницам.