

4. Методи стохастичного факторного аналізу
Функціонування економіки України в ринковому середовищі потребує вивчення і врахування дії цілого комплексу взаємопов'язаних факторів для оперативного прийняття та реалізації зважених управлінських рішень. При цьому традиційних методів та методів детермінованого факторного аналізу вже недостатньо у зв'язку з обмеженістю їх аналітичних можливостей, недостатністю інформаційного забезпечення тощо. Тому виникає необхідність ширшого застосування методів стохастичного факторного аналізу, які, на відміну від жорстко регламентованих методів детермінованого аналізу, основаних на функціональній залежності результативного показника від факторних, дають змогу врахувати вплив сукупності факторів, що носять імовірнісний, невизначений характер.
До методів стохастичного факторного аналізу належать: дисперсійний, регресійний, кореляційний, компонентний, багатовимірний та інші види аналізу.
Дисперсійний аналіз
Дисперсія (лат. dispersio – розсіювання) часто застосовується в теорії ймовірностей і математичній статистиці. Означає ступінь розсіювання навколо середнього значення випадкової величини. У статистичному розумінні дисперсія є середнє арифметичне із квадратів відхилень величин від їх середнього арифметичного. На практиці при проведенні аналізу економічного стану підприємства чи галузі часто необхідно оцінити розсіювання можливих значень випадкової величини навколо її середнього значення, а також виявити та виміряти силу зв'язку між факторними та результативною ознаками.
Дисперсійний аналіз – це статистичний метод, призначений для встановлення структури зв'язку між результативною та факторними ознаками. Він дає змогу визначити вплив одного або декількох факторів на результативний показник.
Дисперсійний аналіз може застосовуватися за обмеженої кількості одиниць спостереження. До того ж він особливо ефективний в умовах, коли результативна ознака суттєво змінюється під одночасною дією кількох факторів з неоднаковою силою впливу.
Дисперсійний метод аналізу відіграє велику роль в економічних дослідженнях завдяки тому, що він має самостійне значення. Завдяки цьому методу вирішуються такі завдання:
– кількісне вимірювання сили впливу факторних ознак та їх сполучень на результативну;
– оцінка вірогідності впливу та його довірчих меж;
– аналіз окремих середніх і статистична оцінка їх різниці.
Крім того, у поглибленому аналізі дисперсійний метод може виконувати допоміжні функції, які дають змогу обґрунтовано використовувати інші методи аналізу.
Розв'язання задачі виміру зв'язку спирається на розкладення суми квадратів відхилень досліджуваних значень результативної ознаки від загальної середньої на окремі частини, які обумовлюють зміну цієї ознаки. Якщо сукупність розбита на групи, то при цьому розраховуються загальна, групова, середня з групових і міжгрупова дисперсії.
Загальна
дисперсія (![]() )
– це середній квадрат відхилень окремих
значень ознак (х) від їх середньої
величини. Вона обчислюється за формулою
)
– це середній квадрат відхилень окремих
значень ознак (х) від їх середньої
величини. Вона обчислюється за формулою
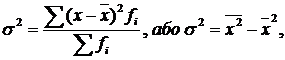
де ![]() –
загальна середня для всієї досліджуваної
сукупності;
–
загальна середня для всієї досліджуваної
сукупності;
f – обсяг сукупності (кількість одиниць).
Загальна дисперсія відображає варіацію досліджуваної ознаки за рахунок усіх умов, які впливають на неї у цій сукупності.
Групова
дисперсія (![]() )
є середнім квадратом відхилень варіантів
ознаки (х) від групової середньої
величини. Розраховується за формулою
)
є середнім квадратом відхилень варіантів
ознаки (х) від групової середньої
величини. Розраховується за формулою
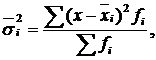
де ![]() –
групова середня;
–
групова середня;
і – порядковий номер х та f в межах групи. Групова дисперсія характеризує варіацію ознаки в межах групи за рахунок всіх інших факторів за виключенням того, який покладений в основу групування.
Щоб виміряти таку варіацію для сукупності в цілому, необхідно знайти середню із групових дисперсій.
Середня
з групових дисперсій (![]() )
визначається за формулою
)
визначається за формулою
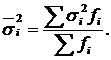
Середня з групових дисперсій характеризує випадкову варіацію в кожній окремій групі. Ця варіація виникає під впливом інших факторів, що не враховуються, і не залежить від ознаки-фактора, покладеної в основу групування.
Міжгрупова
дисперсія (![]() )
або дисперсія групових середніх вимірює
варіацію результативної ознаки за
рахунок факторної ознаки, покладеної
в основу групування. Її формула
)
або дисперсія групових середніх вимірює
варіацію результативної ознаки за
рахунок факторної ознаки, покладеної
в основу групування. Її формула
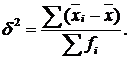
Приклад. За даними табл. 12.1 зробити дисперсійний аналіз варіації урожайності озимої пшениці за двома виробничими підрозділами. При цьому другий підрозділ вніс мінеральні добрива, а перший – ні.
Таблиця 12.1. Посівні площі та урожайність озимої пшениці в господарстві за двома виробничими підрозділами
Підрозділ № 1 (не вносив добрив) |
|
|||||
1 |
50 |
20 |
1000 |
400 |
20 000 |
|
2 |
25 |
22 |
550 |
484 |
12 100 |
|
3 |
25 |
25 |
625 |
625 |
15 625 |
|
Разом |
100 |
— |
2175 |
1509 |
47 725 |
|
Підрозділ № 2 (вносив добрива) |
||||||
4 |
50 |
30 |
1500 |
900 |
45 000 |
|
5 |
75 |
35 |
2625 |
1225 |
91875 |
|
6 |
25 |
40 |
1000 |
1600 |
40 000 |
|
Разом |
150 |
— |
5125 |
3725 |
176 875 |
|
Всього по господарству |
250 |
— |
7300 |
5234 |
224 600 |
|
Розрахуємо спочатку середню врожайність по господарству:
![]() .
.
Далі визначаємо:
Для підрозділу № 1: 1) групову середню
2) середній квадрат варіантів ознаки
3) загальну дисперсію
|
Для підрозділу № 2: 1) групову середню
2) середній квадрат варіантів ознаки
3) загальну дисперсію =1179,17-
|
Визначимо середню з групових дисперсій як середню арифметичну зважену із групових дисперсій:
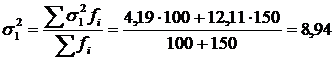 .
.
Знайдемо міжгрупову дисперсію:
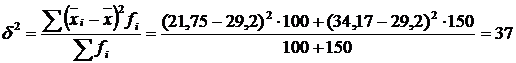 .
.
Тоді загальна дисперсія за урожайністю озимих зернових становитиме:
![]() .
.
Отже, про зв'язок між досліджуваними ознаками можна судити за допомогою коефіцієнта детермінації, який є відношенням міжгрупової дисперсії до загальної і записується у вигляді формули
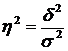 .
.
Коефіцієнт детермінації показує ступінь участі факторної ознаки у формуванні загальної змінюваності результативної ознаки. Зокрема, щодо нашого прикладу ступінь впливу кількості внесених добрив на урожайність зернових становить 80,5%:
 ,
або 80,5%.
,
або 80,5%.
Ступінь впливу інших неврахованих факторів на результативну ознаку обчислюють за співвідношенням
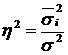
 ,
або 19,5%.
,
або 19,5%.
Рівень впливу інших неврахованих чинників дорівнює 19,5%.
Проте найчастіше в економічному аналізі в ролі показника тісноти зв'язку застосовується кореляційне відношення (емпіричне), яке є коренем другого ступеня із коефіцієнта детермінації. Формула його така:
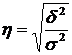 .
.
У
нашому прикладі  .
.
Це свідчить про те, що мінеральні добрива суттєво впливають на урожайність озимої пшениці.
Для підтвердження істотності зв'язку використаємо критерій Фішера
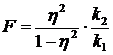 ,
,
де ![]() ,
, ![]() –
число ступенів свободи;
–
число ступенів свободи;
n – число одиниць сукупності;
m – кількість груп.
![]() ;
; ![]() .
.
Отже, 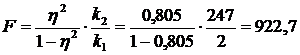 .
.
За допомогою таблиці критичних значень F-критерію порівняємо отриманий критерій із критичним значенням для рівня ймовірності 0,95. Для рівня значимості а = 0,05 табличне значення не перевищує 2,99. Оскільки розраховане значення критерію Фішера більше критичного (922,7 > 2,99), то це підтверджує істотність зв'язку між кількістю внесених добрив і урожайністю озимої пшениці.
Регресійний аналіз
Під терміном "регресія" розуміють рух назад, повернення до попереднього стану. Названий термін ввів у кінці XIX ст. Френсіс Галтон. В результаті проведеного ним дослідження зв'язку між зростом батьків і дітей, виявилося, що наявна обернена залежність. Так, у батьків з дуже високим зростом діти мають менший зріст порівняно з середнім зростом батьків. І, навпаки, у дуже низьких батьків середній зріст дітей вищий. В одному і другому випадку середній зріст дітей прямує (повертається) до середнього зросту населення певної місцевості. Саме такою залежністю і пояснюють вибір терміна "регресія".
Регресійний аналіз (англ. regression analysis) – це метод визначення відокремленого і спільного впливу факторів на результативну ознаку та кількісної оцінки цього впливу шляхом використання відповідних критеріїв.
Регресійний аналіз проводиться на основі побудованого рівняння регресії і визначає внесок кожної незалежної змінної у варіацію досліджуваної (прогнозованої) залежної змінної величини.
Основним
завданням регресійного аналізу є
визначення впливу факторів на
результативний показник (в абсолютних
показниках). Передусім для цього необхідно
підібрати та обґрунтувати рівняння
зв'язку, що відповідає характеру
аналітичної стохастичної залежності
між досліджуваними ознаками. Рівняння
регресії показує як в середньому
змінюється результативна ознака (![]() )
під впливом зміни факторних ознак (хі).
)
під впливом зміни факторних ознак (хі).
У загальному вигляді рівняння регресії можна представити так:
![]() ,
,
де – залежна змінна величина;
х – незалежні змінні величини (фактори).
Залежно від кількості змінних величин виділяють різні види регресійного аналізу. Якщо змінна величина завжди
одна, то змінних може бути як одна, так і декілька. Виходячи з цього, виділяють два види регресійного аналізу: парний (простий ) регресійний аналіз і регресійний аналіз на основі множинної регресії, або багатофакторний.
Парний регресійний аналіз – вид регресійного аналізу, що включає у себе розгляд однієї незалежної змінної величини, а багатофакторний – відповідно дві величини і більше.
Зважаючи на характер зв'язку, в регресійному аналізі можуть використовуватися лінійні та нелінійні функції. Для визначення характеру залежності та, відповідно, побудови рівняння регресії доцільно застосувати графічний метод, порівняння рівнобіжних рядів вихідних даних, табличний метод.
Так, графічний метод дає найбільш наочну картину розміщення крапок на графіку, завдяки чому можна виявити напрям і вид залежності між досліджуваними показниками: прямолінійна чи криволінійна.
За допомогою порівняння рівнобіжних рядів ознак можна спостерігати за рівномірністю їх взаємних змін. Якщо зміна факторної ознаки (х) призводить до відносно рівномірної зміни результативної ( ), тоді використовується лінійна функція (наприклад, залежність між урожайністю культур і кількістю внесених добрив).
Найпростішим рівнянням парної регресії, що описує лінійну залежність між факторною і результативною ознаками, є рівняння прямої, яке має такий вигляд:
![]() ,
,
де – залежна змінна, яка оцінюється або прогнозується (результативна ознака);
![]() –
вільний
член рівняння;
–
вільний
член рівняння;
![]() –
коефіцієнт
регресії;
–
коефіцієнт
регресії;
х – незалежна змінна (факторна ознака), яка використовується для визначення залежної змінної.
Параметри рівняння обчислюються на основі системи нормальних рівнянь методом найменших квадратів:

Звідси

 ,
або
,
або ![]()
Для зручності розрахунків регресійного та кореляційного аналізу (розглянемо далі) доцільно використати таку форму таблиці (табл. 12.2).
Таблиця 12.2. Вихідні та розрахункові дані для обчислення регресійно-кореляційних характеристик (парна прямолінійна кореляція)
№ з/п |
Вихідні дані |
Розрахункові величини |
|
|||
Факторна ознака(х) |
Результативна ознака(у) |
|
|
|
||
1 |
|
|
|
|
|
|
2 |
|
|
|
|
|
|
... |
|
|
|
|
|
|
X (в середньому) |
|
|
|
|
|
|
Основне змістовне навантаження в рівнянні регресії несе коефіцієнт регресії. Найчастіше застосовуються лінійні рівняння або приведені до лінійного вигляду. Коефіцієнт регресії – це кутовий коефіцієнт у прямолінійному рівнянні кореляційного зв'язку. У лінійній функції рівняння регресії він показує на скільки одиниць в середньому зміниться результативна ознака (у) при зміні факторної ознаки (х) на одиницю свого натурального виміру. Тобто, коефіцієнт регресії – це варіація у, яка припадає на одиницю варіації х. Коефіцієнт регресії має одиницю виміру результативної ознаки. За наявності прямого зв'язку коефіцієнт регресії є додатною величиною, а за зворотного зв'язку – від'ємною.
Параметр а0 – вільний член рівняння регресії, тобто це значення у при х=0. Цей показник має тільки розрахункове значення у випадках, коли х не має нульових значень.
У разі, коли зі зміною факторної ознаки результативна змінюється нерівномірно, використовуються нелінійні функції. Так, якщо зміна факторного показника сприяла прискореній динаміці результативного показника (наприклад, вплив обсягу грошової маси на рівень інфляції), доцільно використати степеневу функцію:
![]() .
.
У випадку, коли під впливом факторної ознаки результативна змінюється нерівномірно, причому з уповільненням, використовується рівняння гіперболи:
![]() .
.
Прикладом такої залежності є залежність рівня продуктивності праці робітників від рівня їх заробітної плати.
Якщо зміна факторної ознаки супроводжується нерівномірною варіацією факторної ознаки із зміною напряму зв'язку, нелінійна регресія описується рівнянням параболи:
![]() .
.
Так, за допомогою функції параболи можна виразити залежність урожайності культур від кількості опадів.
Приклад. За даними 25 заводів дослідити залежність між рівнями озброєності праці основними засобами та її продуктивністю, використовуючи регресійний аналіз (табл. 12.3).
Таблиця 12.3. Озброєність праці основними засобами та рівень її продуктивності в групі заводів України, тис. грн
№ з/п |
Озброєність праці |
Вироблено продукції на 1 працівника |
Розрахункові величини |
|
|||||||||
n |
x |
y |
|
|
|
|
|
||||||
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
||||||
1 |
9,6 |
12,8 |
92,2 |
163,5 |
122,7 |
11,9 |
|
||||||
2 |
11,0 |
12,6 |
121,0 |
157,9 |
138,2 |
13,3 |
|
||||||
3 |
11,2 |
15,5 |
125,4 |
241,1 |
173,9 |
13,4 |
|
||||||
4 |
11,4 |
15,7 |
130,0 |
246,2 |
178,9 |
13,6 |
|
||||||
5 |
11,5 |
9,3 |
132,3 |
87,2 |
107,4 |
13,7 |
|
||||||
6 |
12,1 |
16,4 |
146,4 |
267,5 |
197,9 |
14,3 |
|
||||||
7 |
12,2 |
17,6 |
148,8 |
308,0 |
214,1 |
14,4 |
|
||||||
8 |
12,3 |
17,6 |
151,3 |
310,6 |
216,8 |
14,5 |
|
||||||
9 |
12,6 |
14,6 |
158,8 |
213,3 |
184,0 |
14,8 |
|
||||||
10 |
12,8 |
13,7 |
163,8 |
188,2 |
175,6 |
15,0 |
|
||||||
11 |
13,2 |
14,8 |
174,2 |
219,0 |
195,4 |
15,3 |
|
||||||
12 |
13,2 |
14,8 |
174,2 |
219,0 |
195,4 |
15,3 |
|
||||||
13 |
13,3 |
16,1 |
176,9 |
258,1 |
213,7 |
15,4 |
|
||||||
14 |
13,3 |
16,1 |
176,9 |
258,1 |
213,7 |
15,4 |
|
||||||
15 |
14,6 |
23,2 |
213,2 |
539,4 |
339,1 |
16,7 |
|
||||||
16 |
16,0 |
21,5 |
256,0 |
461,1 |
343,6 |
18,0 |
|
||||||
17 |
16,4 |
25,0 |
269,0 |
625,0 |
410,0 |
18,4 |
|
||||||
18 |
17,3 |
6,9 |
299,3 |
48,0 |
119,9 |
19,2 |
|
||||||
19 |
17,3 |
6,9 |
299,3 |
48,0 |
119,9 |
19,2 |
|
||||||
20 |
17,6 |
14,9 |
309,8 |
221,8 |
262,1 |
19,5 |
|
||||||
21 |
17,6 |
14,9 |
309,8 |
221,8 |
262,1 |
19,5 |
|
||||||
22 |
17,7 |
22,2 |
313,3 |
490,7 |
392,1 |
19,6 |
|
||||||
23 |
17,9 |
18,3 |
320,4 |
335,4 |
327,8 |
19,8 |
|
||||||
24 |
22,8 |
30,1 |
519,8 |
905,5 |
686,1 |
24,5 |
|
||||||
25 |
24,9 |
31,1 |
620,0 |
970,2 |
775,6 |
26,5 |
|
||||||
Сума |
369,8 |
422,5 |
5802,0 |
8004,8 |
6565,9 |
421,3 |
|
||||||
В середньому |
14,8 |
16,9 |
232,1 |
320,2 |
262,6 |
16,9 |
|
||||||
|
|
|
|
|
|
|
|
||||||
Паралельне зіставлення рядів значень рівнів озброєності праці основними засобами та її продуктивності, а також крапковий графік "кореляційного поля" (рис. 12.1) свідчать про наявність і напрям зв'язку (прямий) між наведеними показниками. Причому зміна озброєності праці (факторної ознаки х) приводить до відносно рівномірної зміни продуктивності праці (результативної ознаки у), що видно із графіка.
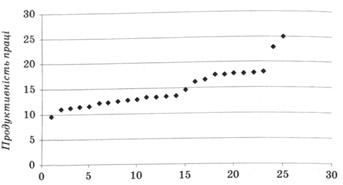
Рис. 12.1. Крапковий графік рівнів озброєності праці основними засобами та її продуктивності по 25 заводах України, тис. грн
Отже, можна зробити висновок про наявність між зазначеними ознаками парного прямолінійного зв'язку, який виражається найпростішим рівнянням регресії лінійної функції
де – вільний член рівняння регресії;
– коефіцієнт регресії.
Для зручності розрахунків скористаємося наведеними нижче формулами, в які підставляємо попередньо обчислені необхідні розрахункові дані (табл. 12.1):

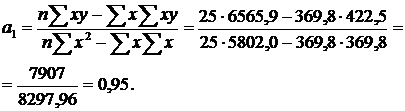
Рівняння залежності матиме такий вигляд:
![]() .
.
Перевірка: ![]() ,
що відповідає середньому рівню
продуктивності праці (табл. 12.3).
,
що відповідає середньому рівню
продуктивності праці (табл. 12.3).
Зобразимо графічно залежність між рівнями озброєності праці основними засобами та її продуктивністю, використавши рівняння регресії (рис. 12.2).
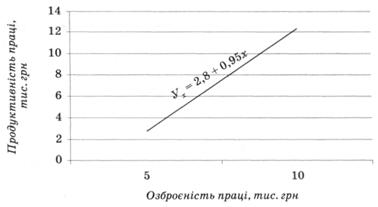
Рис. 12.2. Залежність між рівнями озброєності та продуктивності праці
Якщо підставити в отримане рівняння регресії відповідні значення фактора (х) по заводах, то одержимо вирівняні значення продуктивності праці залежно від озброєності її основними засобами. Результати розрахунків наведені в табл. 12.3 (остання графа).
З рівняння регресії видно, що підвищення озброєності праці основними засобами на одну тисячу гривень забезпечує підвищення рівня продуктивності праці на 0,95 тис. грн.
Якщо б на заводі під № 1 озброєність праці була вище середньої, наприклад 17,9 тис. грн, то виробіток продукції на одного працівника становив би 19,8 тис. грн:
![]() .
.
Величина 17,9, яка взята на заводі, де озброєність праці перевищує середнє її значення – 14,8 тис. грн, називається середньою прогресивною.
Таким чином, регресійний аналіз може бути використаний ще й для визначення резервів шляхом застосування середньопрогресивного значення факторіальної ознаки. У наведеному прикладі цей резерв мають 19 заводів, що мають виробіток продукції на одного працівника менший за 19,8 тис. грн.
Також слід зазначити, що регресійний аналіз доцільно застосовувати для обґрунтування проектних, прогнозних чи очікуваних показників. Для цього необхідно підставити в одержане рівняння регресії проектне значення фактора. Зокрема, якщо б заводу № 7 поставити за мету доведення рівня озброєності праці основними засобами до 20 тис. грн, то можна зробити прогноз продуктивності праці, яка становитиме 21,8 тис. грн:
![]() .
.
Безумовно, що при застосуванні регресійного аналізу дотримуються деяких умовностей. Так, попередньо обумовлюється, що дія інших факторів, крім взятого за факторну ознаку, залишиться незмінною, а в дослідженні взято тільки один фактор.
Проте останню умовність можна усунути за допомогою застосування множинної регресії та кореляції, за яких підбирається значна кількість факторів.
Аналіз на основі множинної регресії (анг. multiple regression analysis) – вид регресійного аналізу, який ґрунтується на використанні в рівнянні регресії більше, ніж однієї незалежної змінної. Так, його застосовують при прогнозуванні попиту. Причому спочатку ідентифікуються фактори, що визначають попит, потім встановлюються наявні між ними взаємозв'язки та прогнозуються ймовірні майбутні їх значення. На основі отриманих даних виводиться прогнозне значення попиту.
Багатофакторне рівняння множинної регресії при лінійній залежності має такий вигляд:
![]() ,
,
де – вільний член рівняння;
![]() –
коефіцієнти
регресії;
–
коефіцієнти
регресії;
![]() –
незалежні
змінні (факторні ознаки);
–
незалежні
змінні (факторні ознаки);
n – кількість незалежних змінних.
Визначення параметрів множинної регресії вимагає трудомістких розрахунків із застосуванням комп'ютерних інформаційних систем. Однак одержані результати будуть достовірними і можуть широко використовуватися в економічній та управлінській діяльності насамперед для складання довгострокових прогнозів. Відомо, що однофакторна модель придатна для короткострокових прогнозів (на 2–3 роки).
Метод регресійного аналізу вважається найдосконалішим з усіх використовуваних нині нормативно-параметричних методів. Він широко застосовується для аналізу та встановлення рівня і співвідношень вартості продукції, яка характеризується наявністю одного або декількох техніко-економічних параметрів, що характеризують головні споживчі якості. Регресивний аналіз надає можливість знайти емпіричну форму залежності ціни від техніко-економічних параметрів товарів і виробів. При цьому він виступає в ролі цільової функції параметрів.
Метод регресійного аналізу особливо ефективний за умови здійснення розрахунків за допомогою сучасних інформаційних технологій і систем.
Кореляційний аналіз
Кореляція дослівно з латинської "correlation" – відношення, тобто це означає співвідношення, відповідність речей, понять. Кореляційним зв'язком називається такий зв'язок між ознаками суспільно-економічних явищ, за якого на величину результативної ознаки крім факторної впливають багато інших ознак, які можуть діяти в різних напрямах одночасно чи
послідовно. Цей зв'язок характеризується тим, що між факторною і результативною ознаками немає повної відповідності, а лише є певне співвідношення. Особливістю кореляційного зв'язку є те, що кожному значенню факторної ознаки відповідає не одне, а ціла низка значень результативної ознаки. Кореляційний зв'язок можна виявити тільки у вигляді загальної тенденції при масовому порівнянні факторів.
Кореляційний аналіз (кореляційний метод) – метод дослідження взаємозалежності ознак у генеральній сукупності, які є випадковими величинами з нормальним характером розподілу.
Основними вимогами до застосування кореляційного аналізу є достатня кількість спостережень, сукупності факторних і результативних показників, а також їх кількісний вимір і відображення в інформаційних джерелах.
Застосування кореляційного аналізу тісно пов'язане з регресійним аналізом, тому його часто називають кореляційно-регресійним. Головними завданнями кореляційного аналізу є:
– визначення форми зв'язку;
– вимірювання щільності (сили) зв'язку;
– виявлення впливу факторів на результативну ознаку.
Здійснення кореляційного аналізу передбачає такі послідовні етапи:
1) встановлення причинно-наслідкових зв'язків між досліджуваними ознаками (виявлення факторів та вибір серед них тих, які найбільше впливають на результативний показник);
2) формування кореляційно-регресійної моделі (інформаційне забезпечення аналізу, вибір типу і форми зв'язку, складання моделі);
3) визначення кореляційних характеристик (показників зв'язку);
4) статистична оцінка параметрів зв'язку (економічна інтерпретація, оцінка значимості коефіцієнтів кореляції (наскільки відібрані фактори пояснюють варіацію результативного показника) та використання їх для вирішення практичних завдань, наприклад прийняття рішень, прогнозування, планування, нормування тощо (рис. 12.3).
Отже, на початковому етапі аналізу виявляються зв'язки між результативною і факторними ознаками. Ці зв'язки можуть бути різними залежно від характеру залежності, напряму дії та аналітичного виразу (рис. 12.4).
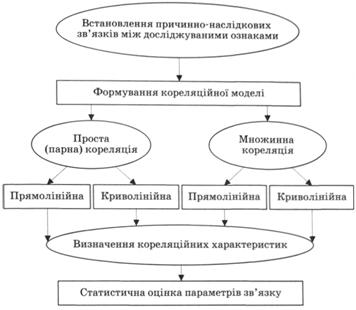
Рис. 12.3. Схема кореляційно-регресійного аналізу
На другому етапі оцінюється вихідна інформація для дослідження з використанням різних статистичних критеріїв (середнє квадратичне відхилення, коефіцієнт варіації тощо), а потім формується модель стохастичного зв'язку.
Для здійснення кореляційного аналізу скористаємося прикладом, який використали раніше для демонстрації регресійного аналізу. Спочатку оцінимо типовість та однорідність даних спостереження, які визначаються відносним їх розподілом навколо середнього рівня, за допомогою таких критеріїв, як середньоквадратичне відхилення (а) та коефіцієнт варіації (V).
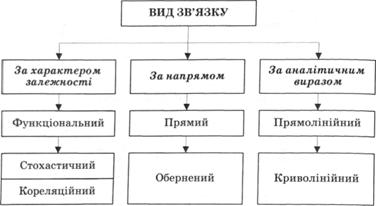
Рис. 12.4. Види зв'язків суспільних явищ
 ;
;
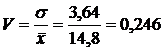 ,
або 24,6%.
,
або 24,6%.
Хоча варіація факторної ознаки і велика, проте вона не перевищує 33%. Це означає, що вихідні дані можна оцінити як однорідні та використати в подальших дослідженнях. Вважається, якщо варіація вище 33% – це свідчить про неоднорідність сукупності та потребує виключення нетипових матеріалів спостереження, як правило, в перших та останніх ран-жованих рядах вибірки. Незначною визнається варіація, що не перевищує 10% (табл. 12.4).
Формування кореляційної моделі передбачає визначення чи це буде проста (парна) кореляція (результативна ознака з одним фактором), чи множинна (результативна ознака і декілька факторів). У свою чергу за характером зв'язку кореляційні моделі можуть бути лінійними (прямолінійними, з оберненою лінійною залежністю) чи нелінійними (криволінійними).
Таблиця 12.4. Оцінка варіації за коефіцієнтом варіації
Значення коефіцієнта варіації |
Оцінка варіації |
5% |
Варіація слабка |
6—10% |
Варіація помірна |
11—20% |
Варіація значна |
21—50% |
Варіація велика |
Більше 50% |
Варіація дуже велика |
У лінійних моделях тіснота зв'язку між досліджуваними показниками вимірюється за допомогою лінійного коефіцієнта кореляції (Пірсона) r за формулою
 .
.
При цьому:
![]() ;
;
![]() .
.
Коефіцієнт кореляції набуває значень у межах ±1, завдяки чому відображає не лише щільність (тісноту) зв'язку, а й його напрям. Так, додатне значення свідчить про наявність прямого зв'язку, а від'ємне – зворотного.
Розрахуємо коефіцієнт кореляції:
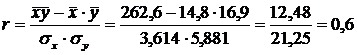 .
.
Отже, розрахований коефіцієнт кореляції свідчить про наявність значного зв'язку між рівнем озброєності праці основними засобами та продуктивністю праці.
Оскільки обчислений коефіцієнт кореляції більший за критичне його значення (0,6 > 0,3809), то з вірогідністю 0,95 можна стверджувати про статистично достовірну залежність між озброєністю і продуктивністю праці.
Шкала оцінки тісноти зв'язку за коефіцієнтом кореляції та критичне його значення наведені в табл. 12.5 і 12.6.
Таблиця 12.5. Величина коефіцієнта кореляції і тіснота зв'язку за "Таблицею Чеддока"
Коефіцієнт кореляції |
Тіснота зв'язку |
1,00 |
Зв'язок функціональний |
0,90—0,99 |
Дуже сильний |
0,70—0,89 |
Сильний |
0,50—0,69 |
Значний |
0,30—0,49 |
Помірний |
0,10—0,29 |
Слабкий |
0,00 |
Зв'язок відсутній |
Крім відображення щільності зв'язку, коефіцієнт кореляції відіграє ще одну важливу роль – через коефіцієнт детермінації (D) він характеризує розмір впливу факторів на результативну ознаку:
![]() .
.
Таблиця 12.6. Критичне значення коефіцієнта кореляції
Кількість одиниць сукупності |
Вірогідність |
|
0,95 |
0,99 |
|
1 |
2 |
3 |
10 |
0,5760 |
0,7079 |
11 |
0,5529 |
0,6835 |
12 |
0,5324 |
0,6614 |
13 |
0,5139 |
0,6411 |
14 |
0,4973 |
0,6226 |
15 |
0,4821 |
0,6055 |
16 |
0,4683 |
0,5897 |
17 |
0,4555 |
0,5751 |
18 |
0,4138 |
0,5614 |
19 |
0,4329 |
0,5487 |
20 |
0,4227 |
0,5368 |
25 |
0,3809 |
0,4869 |
30 |
0,3194 |
0,4487 |
35 |
0,3246 |
0,4182 |
40 |
0,3044 |
0,3932 |
45 |
0,2875 |
0,3721 |
50 |
0,2732 |
0,3511 |
60 |
0,2500 |
0,3248 |
70 |
0,2319 |
0,3017 |
80 |
0,2172 |
0,2830 |
90 |
0,2050 |
0,2673 |
100 |
0,1946 |
0,2540 |
У нашому прикладі
![]() .
.
Це означає, що у наведеному прикладі 36% рівня продуктивності праці формується під впливом озброєності працівників основними засобами. Решту 64% становлять інші фактори – матеріальна зацікавленість робітників, інтенсивність використання робочого часу тощо.
Залежності між декількома факторними ознаками складніші q виражаються рівнянням множинної лінійної кореляції
![]() .
.
Коефіцієнт множинної кореляції характеризує ступінь тісноти зв'язку між залежною змінною та кількома незалежними змінними. Він не може бути меншим, ніж абсолютна величина будь-якого коефіцієнта парної чи множинної кореляції і набуває значення від 0 до 1.
Загальний математичний вираз коефіцієнта множинної кореляції має вигляд
 ,
,
де ![]() –
теоретична (відтворена) варіація –
дисперсія значень величини у, розрахованих
шляхом підстановки значень факторів у
знайдене рівняння регресії
–
теоретична (відтворена) варіація –
дисперсія значень величини у, розрахованих
шляхом підстановки значень факторів у
знайдене рівняння регресії
![]() ,
,
де ![]() –
загальна варіація – дисперсія фактичних
значень величини у.
–
загальна варіація – дисперсія фактичних
значень величини у.
Рівняння множинної регресії і показники множинної кореляції розв'язують і визначають за допомогою спеціальних комп'ютерних програм.
Таким чином, кореляційний аналіз має велике значення в економічному аналізі, вивченні суспільних явищ і процесів. Зокрема, він допомагає вирішити такі завдання:
– встановлення характеру і тісноти зв'язку між досліджуваними явищами;
– кількісний вимір ступеня впливу окремих факторів та їх сукупності на рівень явища, яке вивчається;
– розрахунок кількісних змін аналізованого явища при прогнозуванні показників та об'єктивна оцінка господарської діяльності підприємства.
Велике значення відводиться кореляційному аналізу в дослідженні кореляційних зв'язків на виробництві, зокрема між рівнем продуктивності праці та озброєністю її основними засобами, між урожайністю і кількістю внесених добрив, між собівартістю і випуском продукції та ін.
Завдяки кореляційному аналізу є можливість глибше дослідити взаємозв'язки економічних явищ і процесів, виявити вплив факторів на результати господарської діяльності, виявити і підрахувати резерви підвищення ефективності виробництва. Все це позитивно позначається на здійсненні управлінської, маркетингової та інших видів діяльності, прийнятті економічно обґрунтованих господарських рішень.
Кластерний аналіз
Кластерний аналіз з'явився порівняно недавно – у 1939 р. Його запропонував вчений К. Тріон. Дослівно термін "кластер" в перекладі з англійської "cluster" означає гроно, згусток, пучок, група.
Особливо бурхливий розвиток кластерного аналізу відбувся у 60-х роках минулого століття. Передумовами цього були поява швидкісних комп'ютерів та визнання класифікацій фундаментальним методом наукових досліджень.
Кластерний аналіз – це метод багатомірного статистичного дослідження, до якого належать збір даних, що містять інформацію про вибіркові об'єкти, та упорядкування їх в порівняно однорідні, схожі між собою групи.
Отже, сутність кластерного аналізу полягає у здійсненні класифікації об'єктів дослідження за допомогою численних обчислювальних процедур. В результаті цього утворюються "кластери" або групи дуже схожих об'єктів. На відміну від інших методів, цей вид аналізу дає можливість класифікувати об'єкти не за однією ознакою, а за декількома одночасно. Для цього вводяться відповідні показники, що характеризують певну міру близькості за всіма класифікаційними параметрами.
Мета кластерного аналізу полягає в пошуку наявних структур, що виражається в утворенні груп схожих між собою об'єктів – кластерів. Водночас його дія полягає й у привнесенні структури в досліджувані об'єкти. Це означає, що методи кластеризації необхідні для виявлення структури в даних, яку нелегко знайти при візуальному обстеженні або за допомогою експертів.
Основними завданнями кластерного аналізу є:
– розробка типології або класифікації досліджуваних об'єктів;
– дослідження та визначення прийнятних концептуальних схем групування об'єктів;
– висунення гіпотез на підставі результатів дослідження даних;
– перевірка гіпотез чи справді типи (групи), які були виділені певним чином, мають місце в наявних даних.
Кластерний аналіз потребує здійснення таких послідовних кроків:
1) проведення вибірки об'єктів для кластеризації;
2) визначення множини ознак, за якими будуть оцінюватися відібрані об'єкти;
3) оцінка міри подібності об'єктів;
4) застосування кластерного аналізу для створення груп подібних об'єктів;
5) перевірка достовірності результатів кластерного рішення.
Кожен з цих кроків відіграє значну роль у практичному здійсненні аналізу.
Визначення
множини ознак, які покладаються в основу
оцінки об'єктів (![]() ),
у кластерному аналізі є одним із
найважливіших завдань дослідження.
Мета цього кроку повинна полягати у
визначенні сукупності змінних ознак,
яка найкраще відображає поняття
подібності. Ці ознаки мають вибиратися
з урахуванням теоретичних положень,
покладених в основу класифікації, а
також мети дослідження.
),
у кластерному аналізі є одним із
найважливіших завдань дослідження.
Мета цього кроку повинна полягати у
визначенні сукупності змінних ознак,
яка найкраще відображає поняття
подібності. Ці ознаки мають вибиратися
з урахуванням теоретичних положень,
покладених в основу класифікації, а
також мети дослідження.
При визначенні міри подібності об'єктів кластерного аналізу використовуються чотири види коефіцієнтів: коефіцієнти кореляції, показники віддалей, коефіцієнти асоціативності та ймовірносні, коефіцієнти подібності. Кожен з цих показників має свої переваги та недоліки, які попередньо потрібно врахувати. На практиці найбільшого розповсюдження у сфері соціальних та економічних наук здобули коефіцієнти кореляції та віддалей.
В результаті аналізу сукупності вхідних даних створюються однорідні групи у такий спосіб, що об'єкти всередині цих груп подібні між собою за деяким критерієм, а об'єкти з різних груп відрізняються один від одного.
Кластеризація може здійснюватися двома основними способами, зокрема за допомогою ієрархічних чи ітераційних процедур.
Ієрархічні процедури – послідовні дії щодо формування кластерів різного рангу, підпорядкованих між собою за чітко встановленою ієрархією. Найчастіше ієрархічні процедури
здійснюються шляхом агломеративних (об'єднувальних) дій. Вони передбачають такі операції:
– послідовне об'єднання подібних об'єктів з утворенням матриці подібності об'єктів;
– побудова дендрограми (деревоподібної діаграми), яка відображає послідовне об'єднання об'єктів у кластери;
– формування із досліджуваної сукупності окремих кластерів на першому початковому етапі аналізу та об'єднання всіх об'єктів в одну велику групу на завершальному етапі аналізу.
Ітераційні процедури полягають в утворенні з первинних даних однорівневих (одного рангу) ієрархічно не підпорядкованих між собою кластерів.
Одним із найбільш поширених способів проведення ітераційних процедур ось уже понад сорок років виступає метод k-середніх (розроблений у 1967 р. Дж. МакКуіном). Застосування його потребує здійснення таких кроків:
– розділення вихідних даних досліджуваної сукупності на задану кількість кластерів;
– обчислення багатовимірних середніх (центрів тяжіння) виділених кластерів;
– розрахунку
Евклідової відстані кожної одиниці
сукупності до визначених центрів тяжіння
кластерів та побудова матриці відстаней,
яка ґрунтується на метриці відстаней.
Використовують різні метрики відстаней,
наприклад: Евклідова відстань (проста
і зважена), Манхеттенська, Чебишева,
Мінковського, Махалонобіса ![]() тощо;
тощо;
– визначення нових центів тяжіння та нових кластерів.
Найбільш відомими та широко застосовуваними методами
формування кластерів є:
– одиничного зв'язку;
– повного зв'язку;
– середнього зв'язку;
– метод Уорда.
Метод одиничного зв'язку (метод близького сусіда) передбачає приєднання одиниці сукупності до кластера, якщо вона близька (знаходиться на одному рівні схожості) хоча б до одного представника цього кластера.
Метод повного зв'язку (далекого сусіда) вимагає певного рівня подібності об'єкта (не менше граничного рівня), що передбачається включити у кластер, з будь-яким іншим.
Метод середнього зв'язку ґрунтується на використанні середньої відстані між кандидатом на включення у кластер і представниками наявного кластера.
Згідно методу Уорда приєднання об'єктів до кластерів здійснюється у випадку мінімального приросту внутрішньогрупової суми квадратів відхилень. Завдяки цьому утворюються кластери приблизно одного розміру, які мають форму гіперсфер.
Оптимальною прийнято вважати кількість кластерів, яка визначається як різниця кількості спостережень і кількості кроків, після якої відстань об'єднання збільшується стрибкоподібно.
Кластерний аналіз, як і інші методи вивчення стохастичного зв'язку, вимагає численних складних розрахунків, які краще здійснювати за допомогою сучасних інформаційних систем, зокрема з використанням програмного продукту Statistica 6.0.
Дослідники застосовують кластерний аналіз в різноманітних дослідженнях, наприклад при вивченні рівня добробуту населення країн СНД (О. Мірошниченко). Спочатку для цього було відібрано 16 статистичних основних соціально-економічних показників, які характеризують рівень життя громадян у різних країнах СНД:
1) ВВП у розрахунку на одну особу, дол. США;
2) середньомісячна номінальна заробітна плата, рос. руб.;
3) середньомісячний розмір пенсії, рос. руб.;
4) індекс інвестицій в основний капітал, процентів;
5) індекс споживчих цін, процентів;
6) частка витрат на купівлю продуктів харчування у споживчих витратах домогосподарств, процентів;
7) споживання м'яса та м'ясопродуктів у середньому за рік у розрахунку на одну особу, кг;
8) кількість пшеничного хліба, що можна було б придбати на суму середнього наявного грошового доходу за місяць (на одну особу), кг;
9) загальний коефіцієнт народжуваності (на 1000 осіб наявного населення);
10) коефіцієнт дитячої смертності (померло дітей віком до одного року на 1000 народжених);
11) число зайнятих у відсотках до економічно активного населення;
12) забезпеченість населення житлом у середньому (на одну особу), м2 загальної площі;
13) кількість хворих на злоякісні новоутворення (на 100 000 населення), осіб;
14) кількість зареєстрованих злочинів (на 100 000 населення), од.;
15) викиди шкідливих речовин в атмосферу стаціонарними джерелами забруднення (на одну особу), кг;
16) відвідування музеїв у середньому за рік (на 1000 населення), од. (табл. 12.7).
Кратерний
аналіз здійснюється на основі співмірних
та односпрямованих показників. Тому
показники вхідної матриці слід спочатку
стандартизувати. Одним із поширених
способів для неоднорідних сукупностей
(зокрема у нашому прикладі) є стандартизація
показників шляхом відношення відхилення ![]() -
а до одиниці стандартизації q. У цьому
випадку одиницею стандартизації буде
фактичний варіаційний розмах
-
а до одиниці стандартизації q. У цьому
випадку одиницею стандартизації буде
фактичний варіаційний розмах ![]() .
.
При
цьому, як показано у наукових працях
учених-економістів A.M. Єріної та С.С.
Ващаєва, для показників-стимуляторів
береться ![]() ,
тим часом як для показників-дестимуляторів
,
тим часом як для показників-дестимуляторів ![]() .
Виходячи з цього, стандартизовані
значення показників розраховуються за
формулами:
.
Виходячи з цього, стандартизовані
значення показників розраховуються за
формулами:
– для
показників стимуляторів: 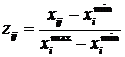 ;
;
– для
показників-дестимуляторів: 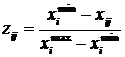 .
.
де ![]() –
стандартизоване значення i-ro показника
для у-ї одиниці сукупності,
–
стандартизоване значення i-ro показника
для у-ї одиниці сукупності, ![]() ,
, ![]() ;
;
– вхідне значення і-го показника для j-ї одиниці сукупності.
Отримані стандартизовані вхідні дані представлені в табл.12.8.
№ з/п |
Азербайджан |
Білорусь |
Вірменія |
Казахстан |
Киргизстан |
Молдова |
Росія |
Таджикистан |
1 |
853,0 |
1763,0 |
905,0 |
1785,0 |
372,0 |
459,0 |
3026,0 |
249,0 |
2 |
2920,0 |
4630,0 |
2345,0 |
5998,0 |
1514,0 |
2577,0 |
6740,0 |
599,0 |
3 |
679,0 |
2215,0 |
505,0 |
1537,0 |
399,0 |
725,0 |
2025,0 |
155,0 |
4 |
135,0 |
121,0 |
115,0 |
123,0 |
102,0 |
108,0 |
111,0 |
150,0 |
5 |
107,0 |
118,0 |
107,0 |
107,0 |
104,0 |
112,0 |
111,0 |
107,0 |
6 |
56,1 |
46,0 |
56,4 |
42,3 |
49,7 |
44,4 |
39,5 |
64,5 |
7 |
21,0 |
59,0 |
28,0 |
54,0 |
39,0 |
27,0 |
53,0 |
14,0 |
8 |
131,0 |
119,0 |
53,0 |
164,0 |
53,0 |
93,0 |
315,0 |
34,0 |
9 |
16,1 |
9,1 |
11,7 |
18,2 |
21,6 |
10,6 |
10,4 |
26,8 |
10 |
9,8 |
6,9 |
11,6 |
14,5 |
25,7 |
12,2 |
11,6 |
15,0 |
11 |
98,6 |
97,5 |
90,6 |
91,6 |
91,0 |
91,9 |
91,7 |
98,0 |
12 |
12,0 |
23,0 |
22,0 |
17,0 |
12,4 |
21,0 |
20,5 |
8,6 |
13 |
271,0 |
1909,0 |
826,0 |
760,0 |
380,0 |
988,0 |
1626,0 |
108,0 |
14 |
203,0 |
1690,0 |
314,0 |
954,0 |
640,0 |
801,0 |
2021,0 |
164,0 |
15 |
65,9 |
38,8 |
12,8 |
202,5 |
7,4 |
5,0 |
141,7 |
5,5 |
16 |
183,0 |
393,0 |
233,0 |
233,0 |
86,0 |
247,0 |
518,0 |
94,0 |
* Тут і далі наведені результати кластерного аналізу, проведеного О.Ю. Мірошниченко.
Таблиця 12.8. Матриця стандартизованих вхідних даних
№ з/п |
Азербайджан |
Білорусь |
Вірменія |
Казахстан |
Киргизстан |
Молдова |
Росія |
Таджикистан |
Україна |
1 |
0,22 |
0,55 |
0,24 |
0,55 |
0,04 |
0,08 |
1,00 |
0,00 |
0,29 |
2 |
0,38 |
0,66 |
0,28 |
0,88 |
0,15 |
0,32 |
1,00 |
0,00 |
0,42 |
3 |
0,25 |
1,00 |
0,17 |
0,67 |
0,12 |
0,28 |
0,91 |
0,00 |
0,73 |
4 |
0,69 |
0,40 |
0,27 |
0,44 |
0,00 |
0,13 |
0,19 |
1,00 |
0,54 |
5 |
0,79 |
0,00 |
0,79 |
0,79 |
1,00 |
0,43 |
0,50 |
0,79 |
0,64 |
6 |
0,34 |
0,74 |
0,32 |
0,89 |
0,59 |
0,80 |
1,00 |
0,00 |
0,17 |
7 |
0,16 |
1,00 |
0,31 |
0,89 |
0,56 |
0,29 |
0,87 |
0,00 |
0,56 |
8 |
0,35 |
0,30 |
0,07 |
0,46 |
0,07 |
0,21 |
1,00 |
0,00 |
0,33 |
9 |
0,40 |
0,01 |
0,15 |
0,52 |
0,71 |
0,09 |
0,08 |
1,00 |
0,00 |
10 |
0,85 |
1,00 |
0,75 |
0,60 |
0,00 |
0,72 |
0,75 |
0,57 |
0,86 |
11 |
1,00 |
0,86 |
0,00 |
0,13 |
0,05 |
0,16 |
0,14 |
0,93 |
0,10 |
12 |
0,24 |
1,00 |
0,93 |
0,58 |
0,26 |
0,86 |
0,83 |
0,00 |
0,93 |
13 |
0,91 |
0,00 |
0,60 |
0,91 |
0,85 |
0,51 |
0,16 |
1,00 |
0,07 |
14 |
0,98 |
0,18 |
0,92 |
0,57 |
0,74 |
0,66 |
0,00 |
1,00 |
0,49 |
15 |
0,69 |
0,83 |
0,96 |
0,00 |
0,99 |
1,00 |
0,31 |
1,00 |
0,59 |
16 |
0,22 |
0,71 |
0,34 |
0,34 |
0,00 |
0,37 |
1,00 |
0,02 |
0,71 |
Наступним кроком кластерного аналізу повинна бути побудова матриці відстаней, що передбачає насамперед вибір метрики відстаней. На практиці застосовують різні метрики відстаней: Евклідова, зважена Евклідова, Манхеттенська, Чебишева, Мінковського, Махалонобіса D2 та ін. В даному випадку розподіл країн СНД на групи можна здійснити за допомогою Манхеттенської відстані. Вона розрахована за формулою
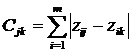 ,
,
де
та ![]() –
стандартизовані значення і-го показника
j-ї та k-ї одиниць сукупності.
–
стандартизовані значення і-го показника
j-ї та k-ї одиниць сукупності.
Виходячи з обраної міри відстаней, можна побудувати симетричну матрицю відстаней між країнами СНД (табл. 12.9).
№ з/п |
Країни СНД |
Азербайджан |
Білорусь |
Вірменія |
Казахстан |
Киргизстан |
Молдова |
Росія |
Таджи-кистан |
Україна |
1 |
Азербайджан |
0,00 |
7,50 |
3,85 |
5,71 |
5,32 |
4,95 |
9,63 |
3,81 |
5,38 |
2 |
Білорусь |
7,50 |
0,00 |
6,93 |
6,38 |
9,65 |
5,80 |
5,06 |
10,80 |
4,20 |
3 |
Вірменія |
3,85 |
6,93 |
0,00 |
5,72 |
4,19 |
2,20 |
7,74 |
5,85 |
3,89 |
4 |
Казахстан |
5,71 |
6,38 |
5,72 |
0,00 |
6,21 |
5,41 |
5,15 |
8,63 |
5,24 |
5 |
Киргизстан |
5,32 |
9,65 |
4,19 |
6,21 |
0,00 |
4,54 |
10,08 |
5,18 |
7,14 |
6 |
Молдова |
4,95 |
5,80 |
2,20 |
5,41 |
4,54 |
0,00 |
6,36 |
7,08 |
4,14 |
7 |
Росія |
9,63 |
5,06 |
7,74 |
5,15 |
10,08 |
6,36 |
0,00 |
13,10 |
5,25 |
8 |
Таджикистан |
3,81 |
10,80 |
5,85 |
8,63 |
5,18 |
7,08 |
13,10 |
0,00 |
8,69 |
9 |
Україна |
5,38 |
4,20 |
3,89 |
5,24 |
7,14 |
4,14 |
5,25 |
8,69 |
0,00 |
Наступним етапом аналізу є вибір методу об'єднання країн СНД у кластери. Як уже зазначалося, найпоширенішими методами формування кластерів є:
– одиничного зв'язку;
– повного зв'язку;
– середнього зв'язку;
– метод Уорда.
Скористаємося методом Уорда, який дає змогу мінімізувати внутрішньогрупову дисперсію всередині кластерів. Згідно з цим методом, приєднання об'єктів до кластерів здійснюється за мінімального приросту внутрішньогрупової суми квадратів відхилень. Це сприяє утворенню кластерів приблизно однакового розміру, які мають форму гіперсфер. Дендрограму результатів кластерного аналізу зображено на рис 12.5.

Рис. 12.5. Дендрограма результатів кластерного аналізу країн СНД за рівнем життя населення
Як видно з рисунка, вертикальна вісь дендрограми відображає країни СНД, а горизонтальна є відстанню об'єднання.
З метою визначення оптимальної кількості кластерів слід побудувати графік списку об'єднання регіонів України у кластери, відклавши на вертикальній його осі відстані, а на горизонтальній – крок об'єднання (рис. 12.6).
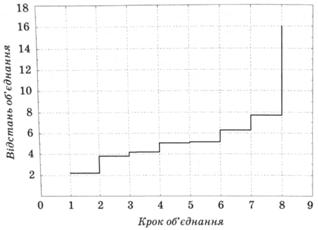
Рис. 12.6. Графік списку об'єднання країн СНД у кластери
Як бачимо оптимальним, згідно з встановленими вимогами оптимальності, є розбиття країн СНД за рівнем життя населення на три кластери. Зазначимо, що оптимальною вважається така кількість кластерів, яка дорівнює різниці кількості спостережень (у нашому прикладі – 9) і кількості кроків, після яких відстань об'єднання зростає стрибкоподібно (у нашому прикладі – 6).
Таким чином, країни СНД розподілено на три кластери. До першого кластера увійшли: Азербайджан і Таджикистан, до другого – Білорусь, Україна, Росія та Казахстан, і третього – Вірменія, Молдова і Киргизстан.
За допомогою методу k-середні обчислені середні значення показників для кожного з трьох кластерів (рис. 12.7).

Рис. 12.7. Середні значення показників для кожного кластера
Як зображено на рис. 12.7, до першого кластера входять країни, у яких середні значення восьми показників менші, ніж у інших кластерах.
Так, Азербайджан і Таджикистан, що належать до першого кластера, мають низькі показники ВВП на одну особу, середньомісячної заробітної плати (номінальної), пенсії, споживання м'яса та м'ясопродуктів, забезпеченості житлом. Проте у цих країнах вищі інші середні показники, зокрема: індекс інвестицій в основний капітал, індекс споживчих цін, коефіцієнт народжуваності .
Країни, віднесені до другого кластера, відзначаються найвищими параметрами економічної складової рівня життя, але, на жаль, низькою народжуваністю, вищим рівнем захворюваності на злоякісні новоутворення, злочинності, більшими викидами шкідливих речовин в атмосферу стаціонарними джерелами забруднення, що підтверджується відповідними показниками.
Країни третього кластера характеризуються найнижчими показниками: індексу інвестицій в основний капітал, рівня зайнятості населення в суспільному господарстві, зареєстрованих злочинів, що свідчить про їх низьку інвестиційну привабливість і значне безробіття.
Отже, кластерний аналіз, за оцінкою науковців, має велике значення в проведенні аналітичних досліджень завдяки можливості перетворити великий обсяг різнобічної інформації в упорядкований, компактний вигляд. Це сприяє підвищенню рівня наочності, зрозумілості та сприйняття результатів аналізу, а також створює підґрунтя для прогнозування.