

Разработка и описание алгоритма:
Как было замечено в предыдущих разделах, первоочередной задачей данного алгоритма должно являться преобразование входных данных в более удобный для работы с ними формат.
Эта работа возлагается на программный модуль INIT (initialization). Структурная схема работы данного модуля очевидна, учитывая уже рассмотренный формат входных данных:
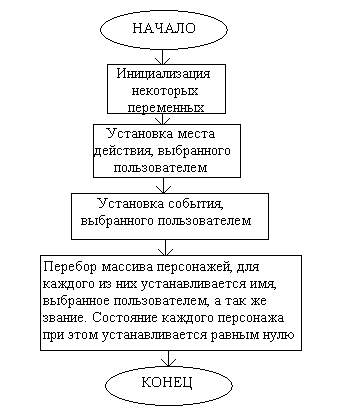
Далее приведу функциональную схему этого модуля с последующими пояснениями:
Функциональная схема программного модуля INIT:
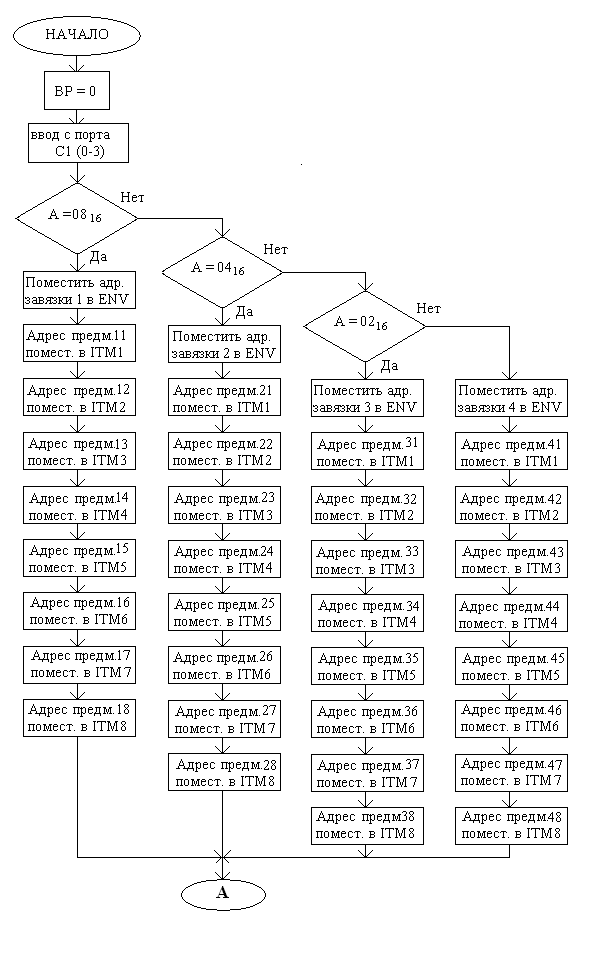
Функциональная схема программного модуля INIT (продолжение):
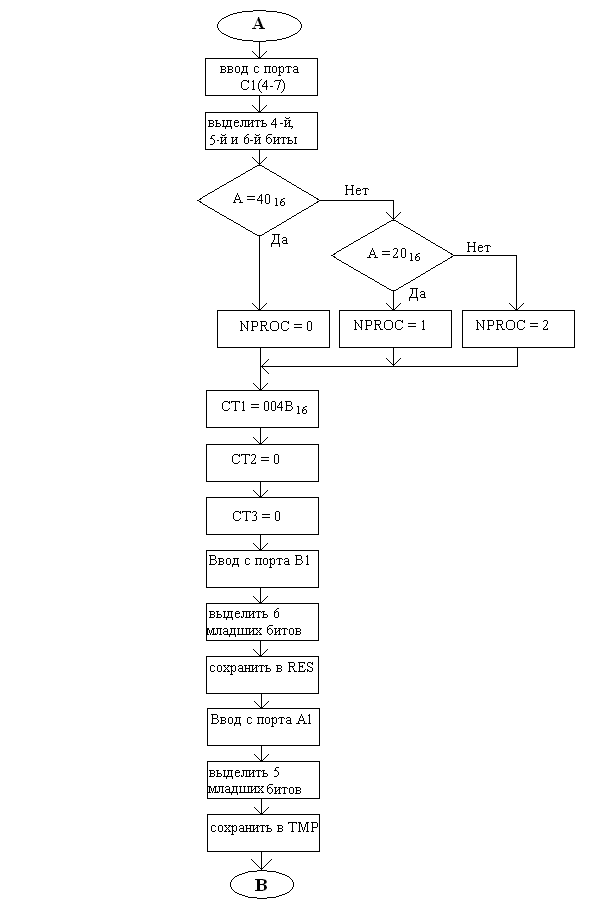
Функциональная схема программного модуля INIT (продолжение):
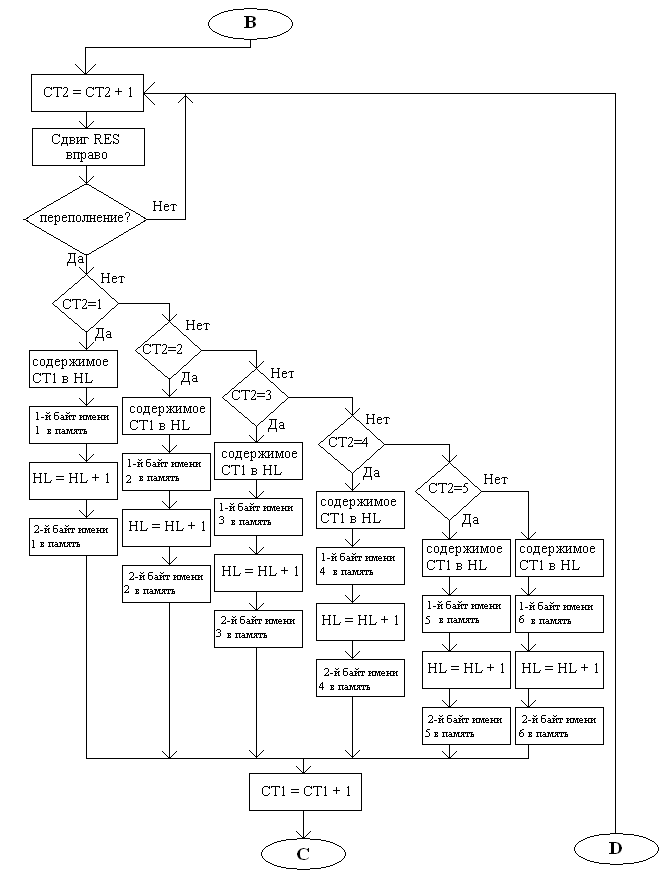
Функциональная схема программного модуля INIT (продолжение):
На стр. 21 производится установка указателя записи в текстовый буфер на начало этого буфера; далее с порта С (0-3) первого интерфейса считывается набор бит. Т.к. пользователь должен выбрать только одно из 4 мест действия, то просто проверяется, какой именно бит из 4 равен 1, и в зависимости от этого устанавливается описание места действия (в ENV записывается адрес текста с описанием) и предметы, находящиеся в данной местности (в ITM1 – ITM8 записываются адреса текстов с названиями предметов).
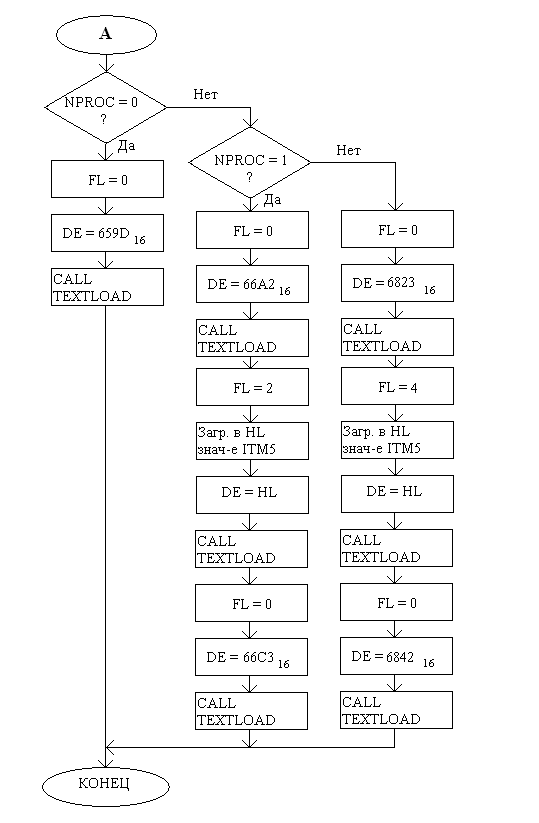
На стр. 22 аналогичная операция производится с выбором события, разворачивающегося на протяжении рассказа. Только считывание ведётся с порта С(4-7), и из считанного значения выделяется 3 бита, т.к. пользователю на выбор было предоставлено 3 варианта событий. В зависимости от того, что выбрал пользователь, устанавливается значение NPROC.
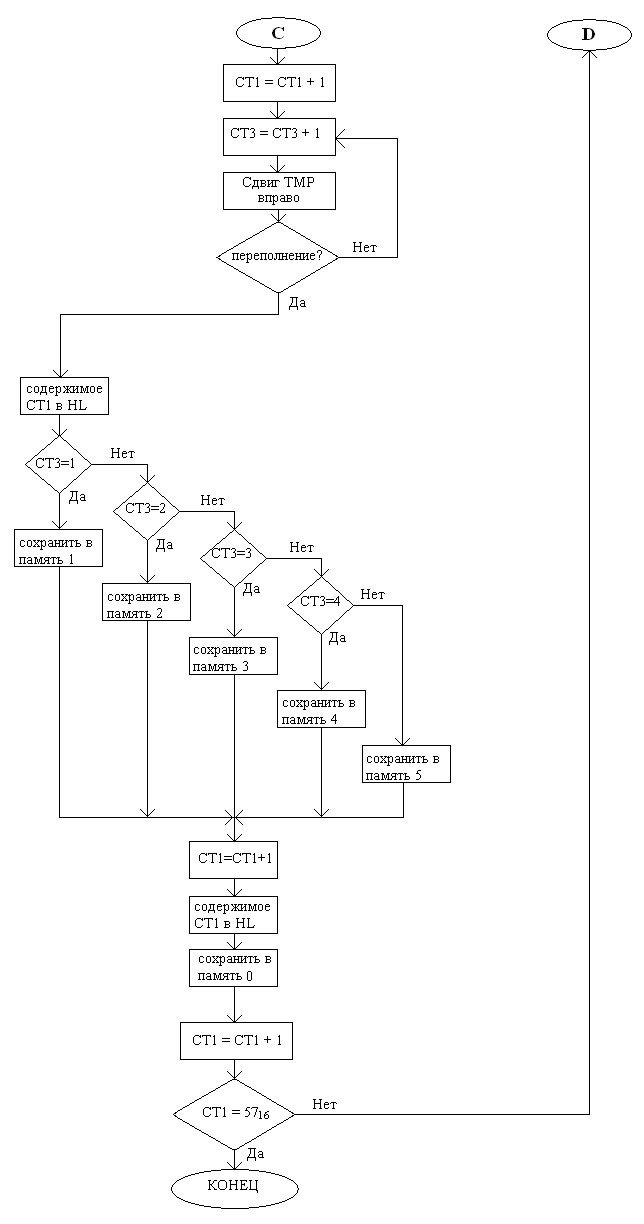
На стр. 22 – 24 производится инициализация массива персонажей. Для этого сначала счётчики CT2 и CT3 устанавливаются в 0, а СТ1 – на адрес первого персонажа в массиве. Считанные с портов А и В значения сохраняются во временных переменных. Сначала в цикле производится сдвиг значения RES влево, количество сдвигов подсчитывает CT2. При переполнении (т.е. если в данном разряде установлена 1), персонажу, на которого указывает СТ1, присваивается имя в зависимости от значения СТ2; после присвоения имени тоже самое производится и со званием, и как только звание присвоено, счётчик переходит к следующему персонажу. Это повторяется 3 раза, т.к. в рассказе участвуют 3 персонажа.
После этого, можно уже начинать строить рассказ на основе полученных начальных условий. Рассказ, как правило, строится из нескольких частей:
Экспозиция, где описывается местность, в которой разворачиваются события, а так же происходит ознакомление с персонажами, участвующими в рассказе;
Основное действие, которое можно разбить на завязку, кульминацию и развязку;
Завершающая часть и эпилог, в которых подводится итог всего изложенного в рассказе и описывается, что происходило с участниками рассказа после завершения сюжетной линии.
Кроме того, учитывая специфику военно-политической литературы о I мировой войне, мы можем определить, как именно будет строиться основное действие: Смысл большинства рассказов на подобную тематику сводится к высмеиванию действий офицерского состава на театре военных действий и показанию неспособности их адекватно командовать своими подчинёнными. Зачастую, если рассказ имеет саркастический характер, автор ставит своих героев в совершенно нелепые ситуации;
Так или иначе, суть в том, чтобы показать совершенно неадекватную реакцию этих персонажей на происходящие события, а так же неспособность командовать подчинёнными.
Рассмотрим все компоненты, участвующие в построении рассказа:
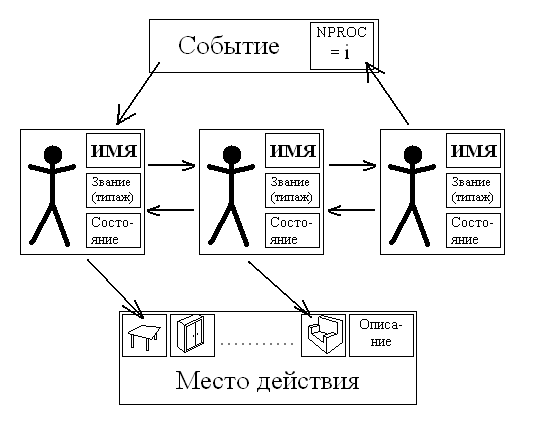
Основную роль в рассказе, как было отмечено в начале, играют именно личности, и в данном случае именно персонажи наделены большим числом характеристик. Имя персонажа и его типаж (т.е. характер) устанавливаются пользователем. Состояние же изначально равно 0; Следует так же отметить, что в данном случае типаж персонажа отождествляется с его званием, это делается с целью присвоить именно офицерам высокого ранга самые отрицательные черты характера, причём, чем выше ранг, тем хуже характер.
Событие характеризуется лишь своим идентификатором.
Место действия характеризуется набором предметов, которые могут находиться именно в этой местности. Кроме того, для большего удобства, оно наделяется и описанием, которое сразу выводится в начале рассказа, а дальнейшей роли не играет.
Стрелками показано, как могут разные компоненты взаимодействовать друг с другом: Событие оказывает воздействие на персонажа, вызывая у него некоторую реакцию на происходящее, и изменяя его состояние; Персонажи также могут изменять ход событий, просто изменяя идентификатор текущего события; Персонажи могут взаимодействовать между собой, но этому взаимодействию в данном случае отводится второстепенная роль, т.к. офицеры пытаются воздействовать на рядовых, что у них весьма плохо получается (как правило, это взаимодействие выражается в виде диалога, и не меняет состояния взаимодействующих персонажей); Наконец, персонажи могут весьма поверхностно взаимодействовать с окружающей местностью, просто используя некоторые предметы, находящиеся на ней.
Из рассмотренного уже становится ясно, как производится формировка описания персонажей, экспозиции и завязки. Однако, основное действие требует более детального рассмотрения.
Основное действие рассказа строится на переборе массива персонажей и вызове для каждого из них подпрограммы REACTij (reaction – реакция на событие), где i определяется идентификатором текущего события, а j – чином/типажом данного персонажа, что вполне очевидно: реакция персонажа на событие зависит, естественно, от самого события и от характера персонажа. Например, на событие «враг атакует» трусливый персонаж прореагирует, спрятавшись в укрытии, а смелый – пойдя в контратаку. Кроме того, реакция персонажа зависит и от состояния, в котором он находился до события: тот же трусливый персонаж не станет прятаться в укрытии, если он там уже находится. Однако проверка состояния делается уже в самой подпрограмме REACTij. На основе всего сказанного, можно записать структурную схему, общую для всех подпрограмм REACTij:
Очевидно также, что для написания подпрограмм REACTij необходимо иметь полную диаграмму состояний, в которых персонаж с характером/чином = j может находиться на протяжении рассказа:
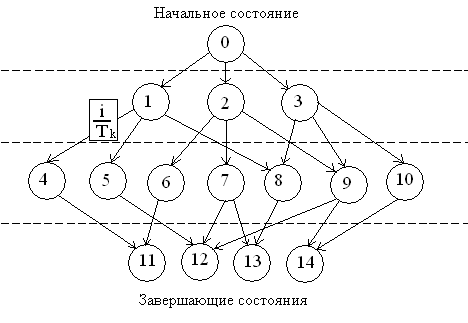
Эта диаграмма строится с учётом некоторых ограничений:
Начальное состояние всегда одно;
За конечное число переходов персонаж должен перейти в одно из завершающих состояний, которые потом будут анализироваться специальной подпрограммой, и на их основе будет строиться эпилог;
В диаграмма должна являться ациклической;
Для составления подпрограммы REACTij, достаточно взять все состояния (кроме завершающих, т.к. выйти из них персонаж не может) и посмотреть, в какие состояния он из них выходит по событию = i, изменить его состояние и выдать текст Tk, описывающий данный переход из состояния в состояние. Кроме этого, при переходе, персонаж может изменить ход текущих событий или провзаимодействовать с другим персонажем.
Здесь приводится функциональная схема подпрограммы REACT14. Остальные схемы достаточно однообразны, поэтому нет смысла приводить их все. Отличие между ними, как уже можно понять, заключается в:
количестве состояний, а следовательно и проверок, т.е. наличии/отсутствии блоков 1 – 11;
расположении блоков 45, 46, отвечающих за изменение хода событий, т.к. разные персонажи по-разному меняют события и в разные моменты времени;
наличии-отсутствии блоков 47 – 51 и 52 – 60, отвечающих за взаимодействие с другими персонажами;
в текстах, выводимых при переходах (т.е. в адресах, заносимых в регистровую пару DE).
Несмотря на простоту структурной схемы, функциональная схема выглядит значительно более сложной. Это объясняется рядом факторов:
Подпрограмма REACTij не знает, для какого именно персонажа в массиве персонажей она вызывается, поэтому перед вызовом REACTij адрес этого персонажа записывается в ячейки OBJ и SUB, а по этому адресу данная п/п уже получает доступ к требуемым свойствам персонажа – состоянию, имени и званию/характеру. Для этого используется косвенная адресация, что и усложняет подпрограмму;
Логическая связность текста требует, чтобы в рассказе все персонажи и вещи назывались своими именами, поэтому выводимый текст бьётся на части, между которыми подставляются имена персонажей и названия предметов;
В русском языке существительные изменяются по числам и падежам, а это требует дополнительной орфографической обработки. Часть из этой обработки REACTij берёт на себя, т.к. только на момент её выполнения известно, в каком числе/падеже употреблено выводимое ею слово. Чтобы соответствующая подпрограмма произвела орфографическую обработку текста, перед его выводом REACTij выставляет значение FL не равным нулю. Ноль означает, что никакой обработки не требуется, значения от 1 до 6 соответствуют единственному числу (1 - именительный падеж, 2 – родительный падеж, и т. д.), а значения от 7 до 12 – множественному числу. Оперируя этими значениями, соответствующая подпрограмма производит расстановку окончаний в словах.
Рассмотрим теперь взаимодействие двух персонажей. Персонажи в данном случае взаимодействуют по принципу начальник-подчинённый, и для реализации этого принципа используются подпрограммы SEARCH и ANSWERj. Подпрограмма SEARCH вызывается тем персонажем, который пытается провзаимодействовать с кем-либо и находит в массиве персонажа, звание которого ниже определённого значения, и, при нахождении такого персонажа, помещает его адрес в переменную OBJ. При этом, перебор массива персонажей производится как от начала к концу, так и наоборот (для большего разнообразия), в зависимости от значения переменной DIR. Реализация этой п/п настолько очевидна, что не нуждается в структурной схеме, поэтому приведу сразу функциональную схему:
Функциональная схема подпрограммы SEARCH:
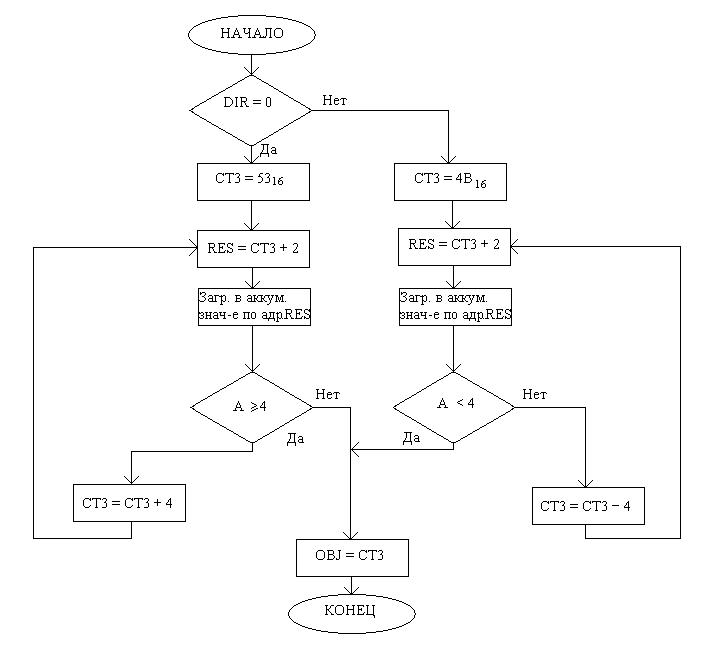
В качестве счётчика здесь выступает CT3, т.к. предполагается, что СТ1 и СТ2 могут быть заняты программными модулями, вызвавшими эту подпрограмму. Т.к. набор персонажей, из которого пользователю предлагается выбрать трёх, состоит из 5 типажей, среди которых 2 офицера, то нет альтернативной ветви, предполагающей отсутствие в массиве персонажей, стоящих по званию ниже офицера.
После того, как в OBJ был записан адрес объекта взаимодействия, субъект может использовать любые его характеристики (например, обратиться к нему по имени в диалоге), в частности, вызвать п/п ANSWERj, где j определяется опять же званием/характером объекта взаимодействия. Эти подпрограммы реализуют ответ объекта на воздействие субъекта. В принципе, они эквивалентны подпрограммам REACTij, за исключением того, что не изменяют состояния объекта, т.е. в них отсутствуют блоки 12 – 44. Кроме того, отличие заключается и в том, что адрес персонажа, для которого вызвана п/п ANSWERj будет находиться уже в переменной OBJ, а переменная SUB может использоваться для того, чтобы в диалоге объект мог обратиться к субъекту по имени.
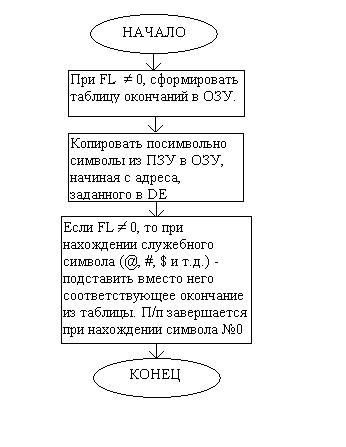
Далее, отдельного рассмотрения заслуживает и подпрограмма загрузки текста в буфер (TEXTLOAD). Её особенность заключается в том, что она производит завершающую часть орфографической обработки текста. Её структурную схему можно представить следующим образом:
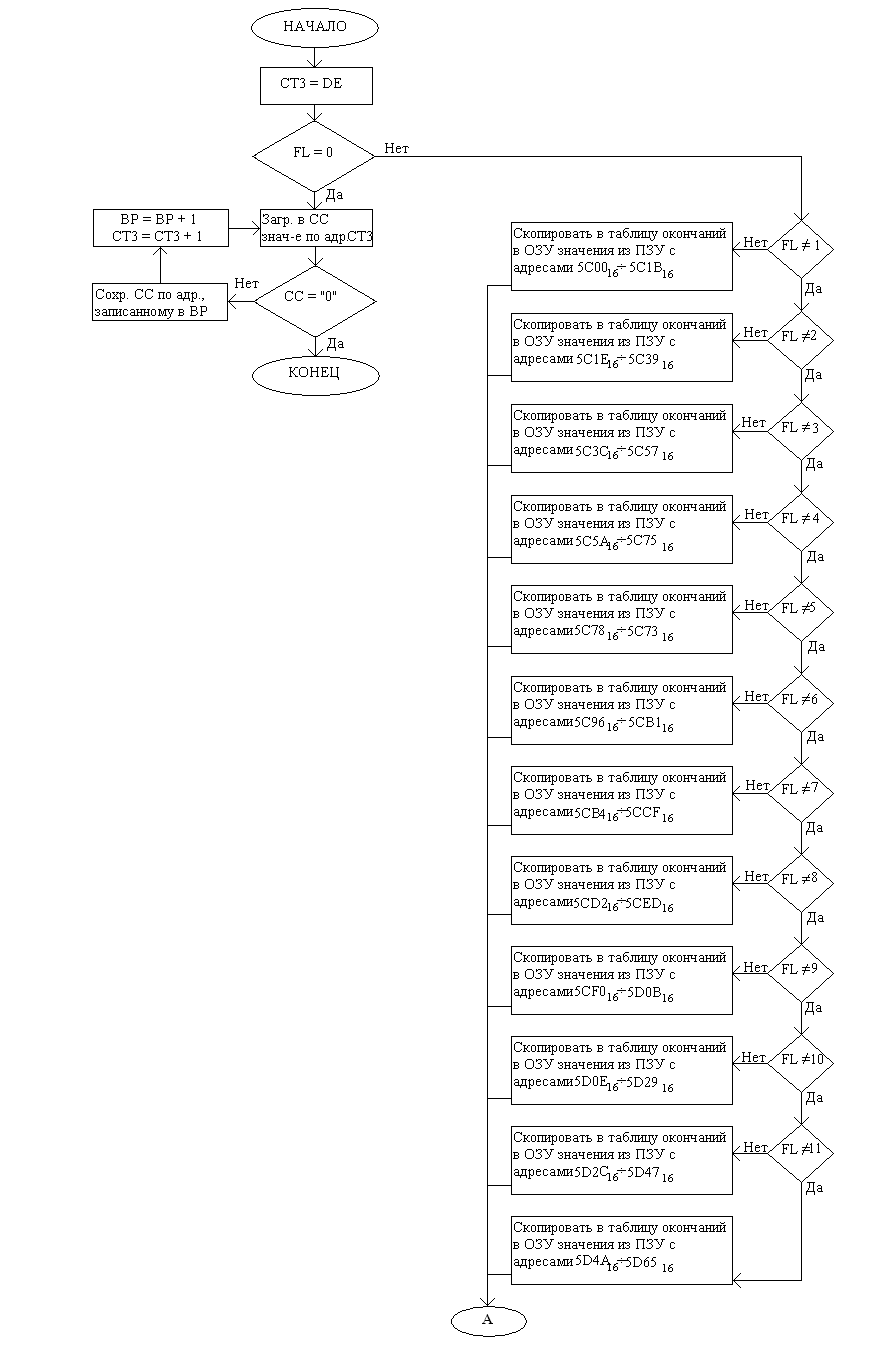
Функциональная схема этой подпрограммы выглядит следующим образом:
Функциональная схема подпрограммы TEXTLOAD:
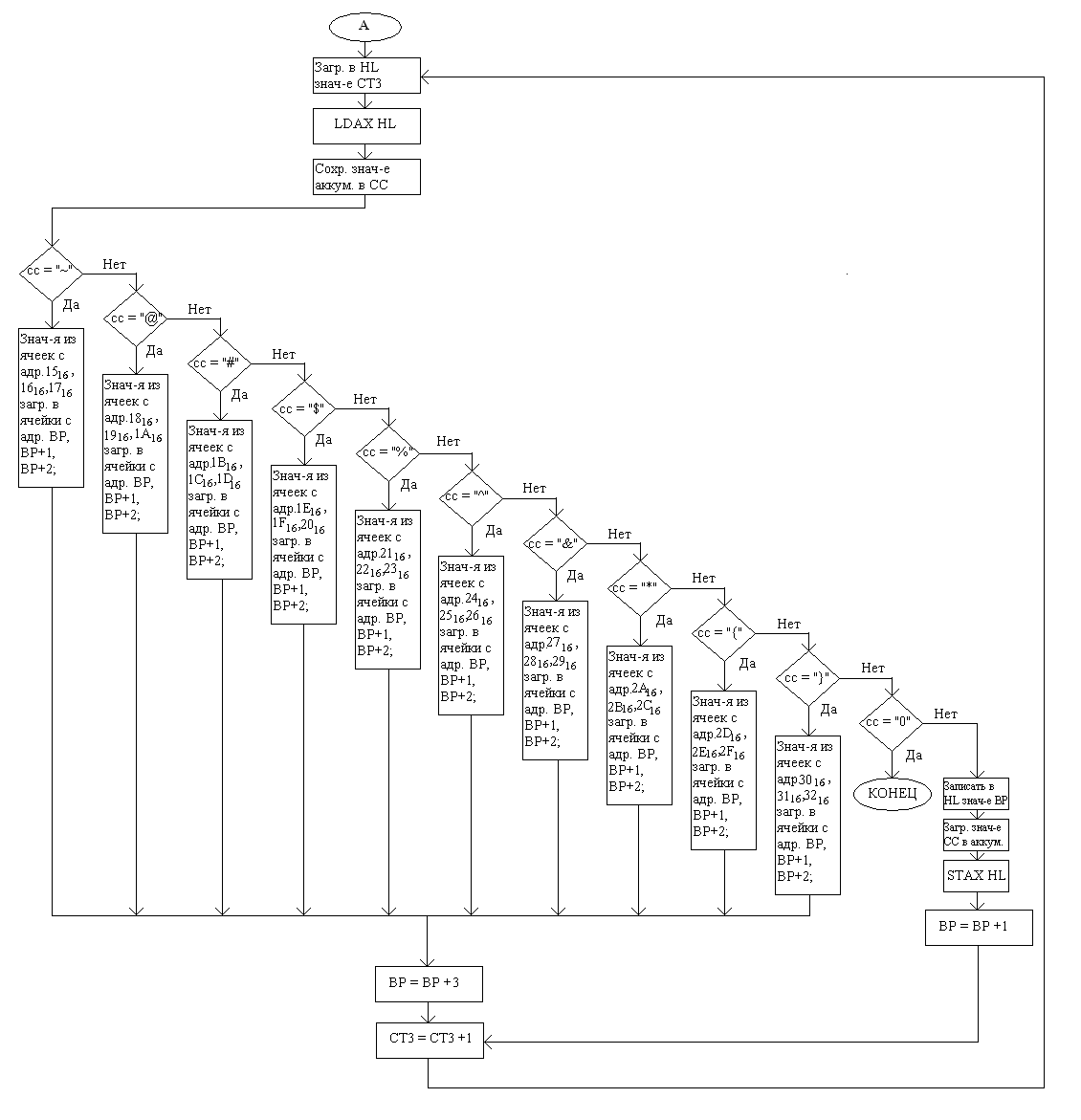
Функциональная схема подпрограммы TEXTLOAD (продолжение):
На стр. 33 делается проверка значения переменной FL. Если она = 0, это означает, что обработка текста не требуется, и поэтому текст посимвольно копируется из ПЗУ в буфер, начиная с адреса, указанного в регистровой паре DE, до тех пор, пока не будет обнаружен завершающий символ.
Если же FL не равен нулю, то сначала формируется таблица окончаний в ОЗУ. Причём, таблица формируется не для некоторого слова, а для заданного числа и падежа, т.е. при составлении таблиц окончаний мною были рассмотрены все слова, используемые в рассказе, и, скажем, при FL = 1 в таблицу помещаются окончания всех слов в единственном числе и именительном падеже.
Далее, на стр. 34 производится то же самое посимвольное копирование, однако, кроме завершающего символа, ищутся ещё и служебные символы. При нахождении одного из них, в буфер копируется не он, а соответствующее ему окончание из таблицы. После этого указатель записи в буфер увеличивается на 3 (под окончание выделяется 3 символа), а значение СТ3 – на единицу. СТ3 в данном случае выступает как указатель чтения из ПЗУ.
Наконец, рассмотрев все основные алгоритмы, можем кратко рассмотреть все остальные. Учитывая все рассмотренные части, из которых должен строиться текст (экспозиция, завязка, основное действие и т. д.), логично было бы записать структурную схему работы всего алгоритма в следующем виде:
Структурная схема работы всего алгоритма:

Причём, каждый блок реализуется в виде отдельного программного модуля. Следует отметить, что принцип работы первого блока был нами уже рассмотрен;
Рассмотрим реализацию программного модуля, отвечающего за экспозицию, описание персонажей и завязку (BEGIN). Его структурная схема выглядит следующим образом:
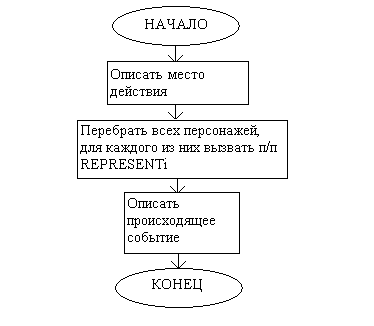
Впрочем, это и так очевидно. Описание места действия хранится в переменной ENV, и его вывод труда не составляет. Происходящее событие определяется значением NPROC, а его описание мы не можем хранить нигде – в описание событий могут подставляться названия предметов окружающей среды, требующие орфографической обработки. Описание каждого персонажа определяется его званием/характером, но в него тоже могут подставляться названия предметов, и, естественно, должно подставляться и имя персонажа, что значительно усложняет блок-схему, поэтому описание персонажей было возложено на подпрограмму REPRESENTi, где i определяется чином/характером персонажа.
Так или иначе, функциональная схема подпрограммы BEGIN выглядит следующим образом:
Функциональная схема программного модуля BEGIN:
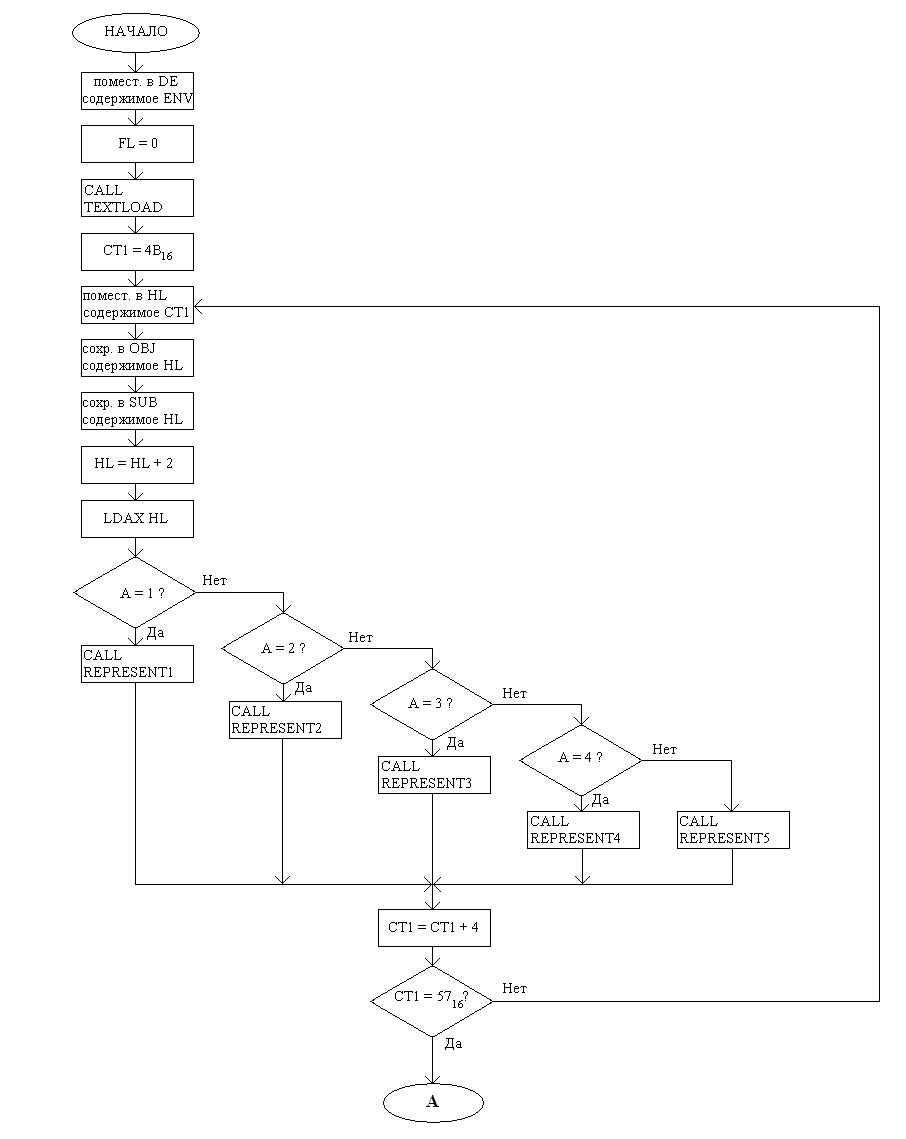
Функциональная схема программного модуля BEGIN (продолжение):
На стр. 38 сначала производится вывод текста с описанием местности, потом производится итерация массива персонажей, для каждого из них, в зависимости от чина/характера вызывается п/п REPRESENTi, описывающая персонажа.
На стр. 39 производится описание текущего события, определяемого переменной NPROC. В описании используются и названия некоторых предметов, расположенных в данной местности.
Функциональная схема подпрограммы REPRESENT4:
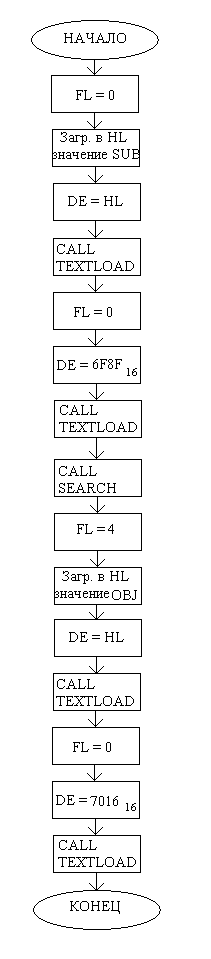
Здесь представлена функциональная схема подпрограммы REPRESENT4. В ней производится описание персонажа с чином, равным 4. Сначала выводится его имя, затем описание. Далее персонаж пытается провзаимодействовать с другим персонажем, вызывая п/п SEARCH, и обращается к найденному персонажу по имени, однако никакой ответной реакции не происходит (не были вызваны п/п ANSWERj).
Теперь рассмотрим следующий программный модуль, отвечающий за описание основных событий (ITERATION). Его задача состоит в том, чтобы 3 раза перебрать массив персонажей, причём, при каждой итерации записать в переменные OBJ и SUB адрес итерируемого персонажа. После этого, в зависимости от звания/характера итерируемого персонажа, и текущего события, вызвать п/п REACTij. Порядок перебора массива персонажей должен постоянно изменяться, чтобы придать тексту большее разнообразие:
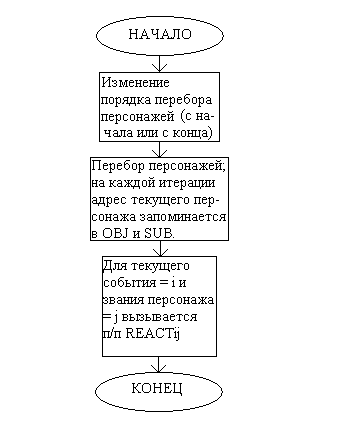
Функциональная схема программного модуля ITERATION:
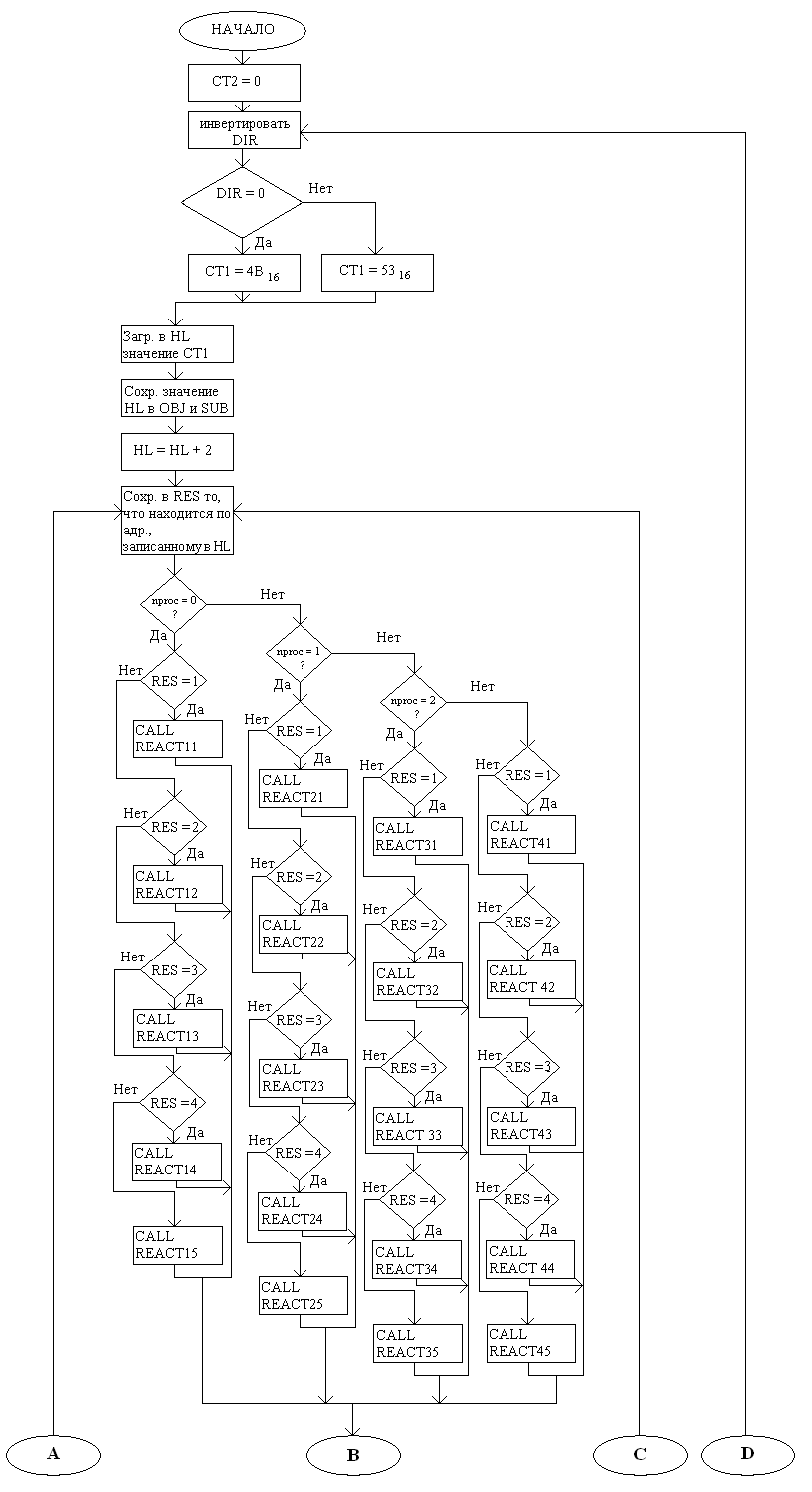
Функциональная схема программного модуля ITERATION (продолжение):
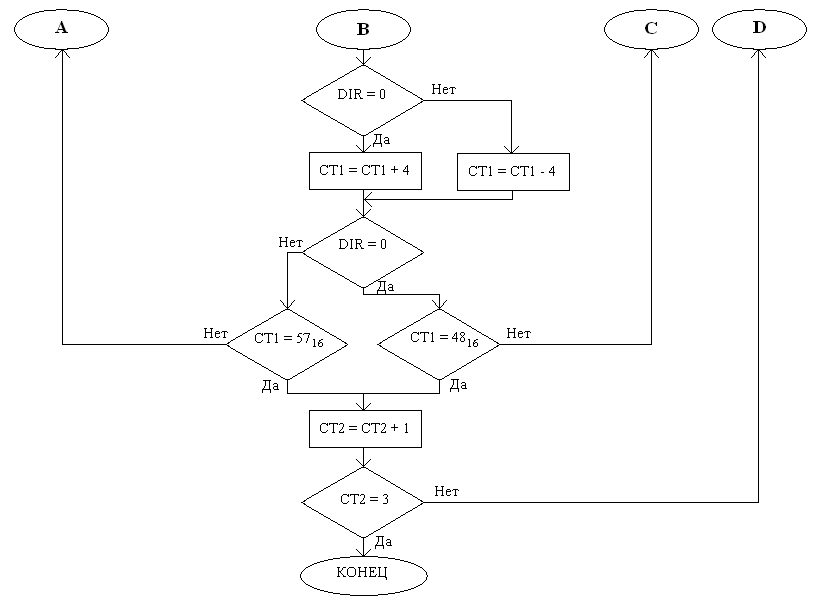
В качестве счётчика количества переборов используется CT2, а в качестве счётчика персонажей – CT1. Адрес итерируемого персонажа сохраняется в OBJ и SUB, а его звание помещается в старший байт временной переменной RES. В аккумулятор загружается сначала значение NPROC и проверяется, и только потом из RES загружается звание персонажа и снова проверяется. В зависимости от обоих значений вызываются п/п REACTij. Далее происходит увеличение или уменьшение счётчика персонажей (в зависимости от DIR) и всё повторяется для следующего персонажа в массиве. Как только будут перебраны все персонажи, CT2 инкрементируется, инвертируется DIR, и всё происходит заново, пока CT2 не станет равным 3. По истечении трёх переборов считается, что каждый персонаж перешёл в какое-то из завершающих состояний, которые уже начинают обрабатываться следующим программным модулем.
Работа этого программного модуля заключается в подведении итогов всего изложенного в рассказе, и выводе сгенерированного текста на дисплей. Для этого сначала описывается, как закончилось основное событие рассказа, а потом, на основании состояний, в которых к концу рассказа находятся персонажи, описывается их дальнейшая судьба. После этого вызывается специальная подпрограмма вывода текста. Структурная схема этого программного модуля выглядит следующим образом:
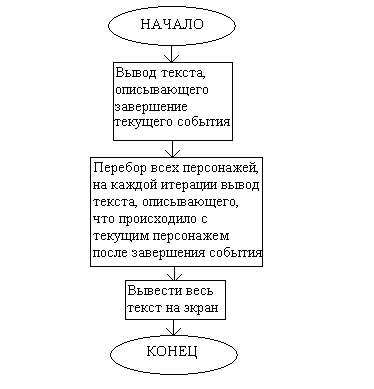
Функциональная схема программного модуля END:
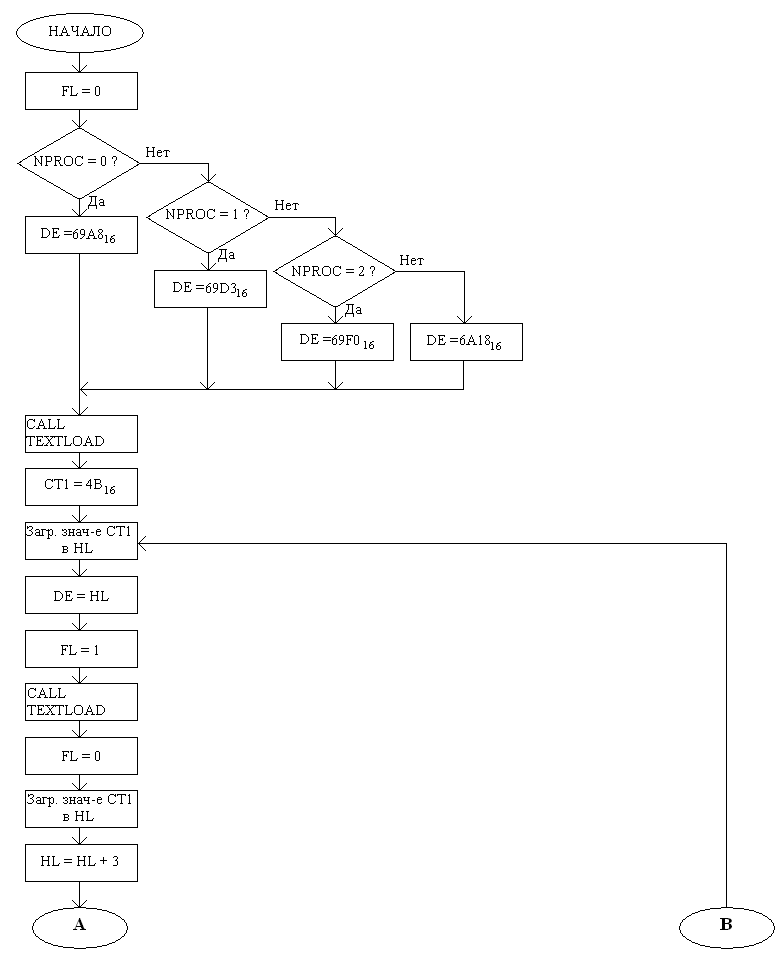
Функциональная схема программного модуля END (продолжение):
Этот программный модуль берёт на себя и часть работы по синтаксической обработке текста: При итерации каждого персонажа сначала берётся его имя, записывается в буфер, затем после имени идёт описание дальнейшей судьбы персонажа в зависимости от его состояния, после этот ставится запятая, либо запятая с каким-либо предлогом, и только потом производится переход к следующему персонажу. После перебора всех персонажей, ставится точка и вызывается подпрограмма вывода текста на дисплей (OUTPUT).
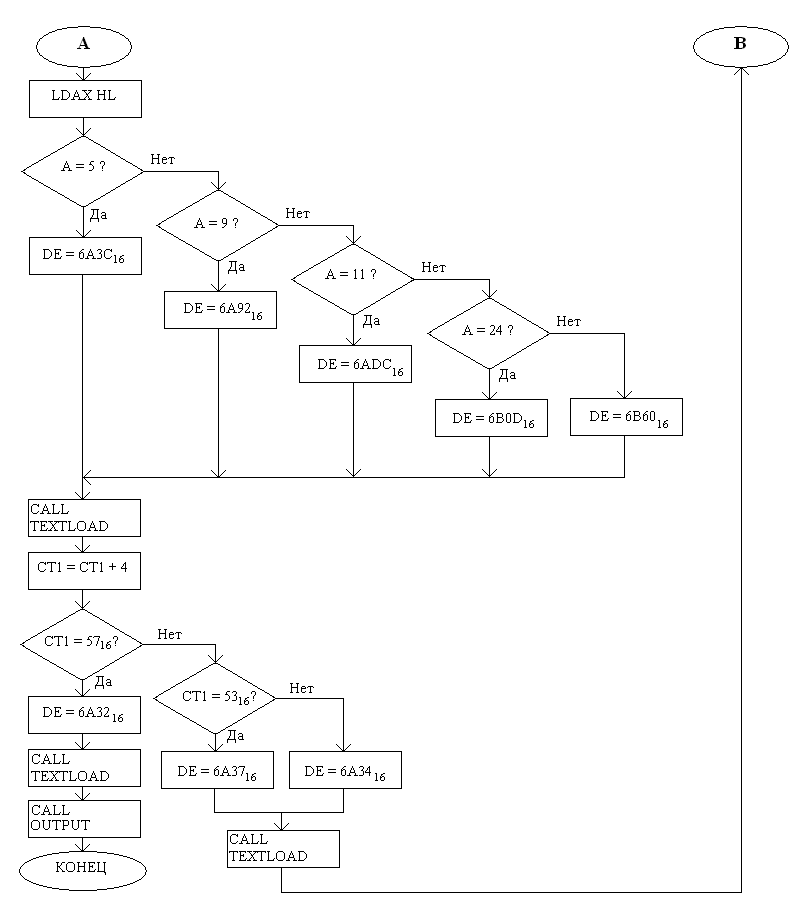
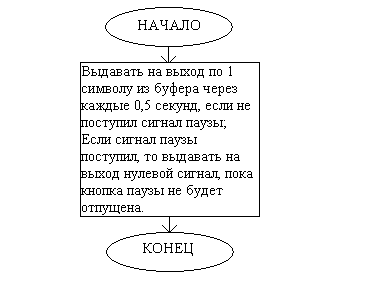
Структурная схема программного модуля OUTPUT:
Функциональная схема программного модуля OUTPUT:
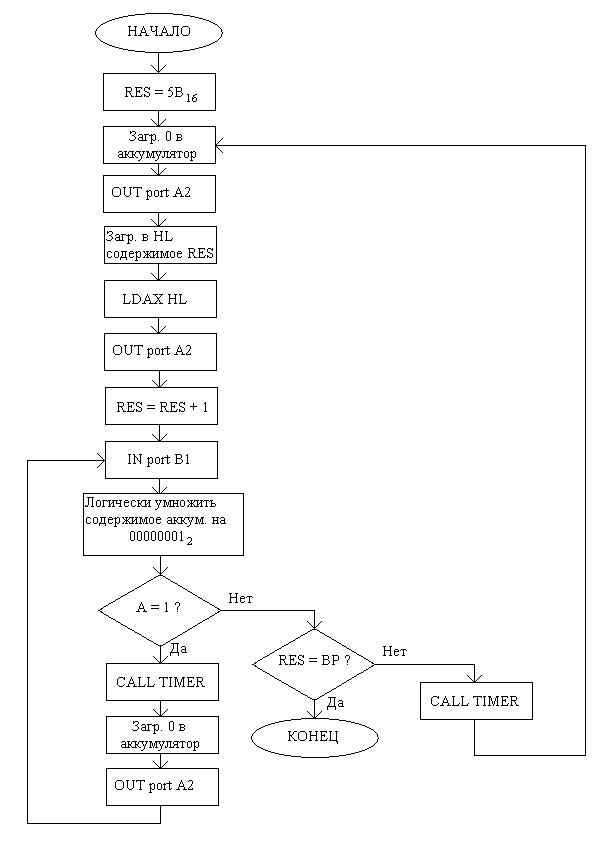
Этот программный модуль выдаёт символы из буфера на порт А2 через каждые ~0,5 секунд, увеличивая при этом на 1 значение RES, которая в данном случае выступает как указатель чтения. В случае, если нажата кнопка паузы, выдаётся нулевой символ, и инкремент RES не производится. Как только указатель чтения сравняется с указателем записи, работа подпрограммы прекращается, т.к. это означает, что весь текст был выдан.
Подпрограмма OUTPUT использует подпрограмму TIMER для задержки между выдачей символов (т.к. человек не может читать текст со скоростью, с которой его выдавал бы процессор в отсутствии таймера) и для создания интервала времени между опросом порта B1 на предмет нажатия кнопки паузы (т.к. частое чтение с портов может привести к нежелательным последствиям).
Функциональная схема п/п TIMER, опять же, очевидна, и в пояснении не нуждается:
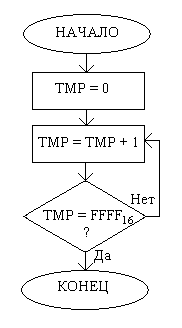
Оценка времени задержки производилась следующим образом: Инкремент однобайтной переменной в памяти (INR M) занимает 10 тактов, операция сравнения с памятью (CMP M) занимает 7 тактов, количество тактов на операции загрузки значений в регистровую пару HL и в аккумулятор до начала цикла считается пренебрежимо малым; Т.к. переменная TMP двухбайтная, то, при переполнении её младшего байта, надо инкрементировать старший байт и снова повторять инкремент младшего байта до следующего переполнения. Переполнение байта происходит после 255 инкрементов, после каждого инкремента производится сравнение значения этого байта с FF16. Т.о. суммарное число тактов можно грубо оценить как: ((255 * (10 + 7)) + 7 + 10) * 255 = 1109760. Тактовая частота КР580ИК80А = 2,5 МГц, вычисляя отношение этих двух величин получаем ~0,44 секунды на выполнение п/п TIMER. Выдача символов с интервалом ~0,5 секунд достаточно удобна для чтения бегущей строки, а задержка в пол секунды при опросе порта на предмет нажатия кнопки «пауза» совсем не критична.