

Блочная адресация
Блочная адресация используется в командах, для которых единицей обработки служит блок данных, расположенных в последовательных ячейках памяти. Этот способ очень удобен при работе с внешними запоминающими устройствами и в операциях с векторами. Для описания блока обычно берется адрес ячейки, где хранится первый или последний элемент блока, и общее количество элементов блока, заданное числом байтов или ячеек. Вместо длины блока может использоваться специальный признак «конец блока» помещаемый за последним элементом блока.
Законы Амдала и Густафсона.
DOP (Degree Of Parallelism)
Степень параллелизма программы – D(t) – число процессоров, участвующих в исполнении рограммы в момент времени t
DOP зависит от алгоритма программы, эффективности компиляции и доступных ресурсов при исполнении
График D(t) – профиль параллелизма программы
T(n) – время исполнения программы на n процессорах
T(n)<T(1), если параллельная версия алгоритма эффективна
T(n)>T(1), если накладные расходы (издержки) реализации параллельной версии алгоритма чрезмерно велики
Speedup
Ускорение за счёт параллельного выполнения
S(n) = T(1) / T(n)
Efficiency
Эффективность системы из n процессоров
E(n) = S(n) / n
Случай S(n)=n – линейное ускорение – масштабируемость (Scalability) алгоритма (возможность ускорения вычислений пропорционально числу процессоров)
Случай S(n)>n – суперлинейное ускорение (например, из-за большего коэффициента кеш-попаданий)
Закон Амдала
Gene Amdahl (1967)
f – доля последовательной части программы
1-f – доля распараллеливаемой части программы
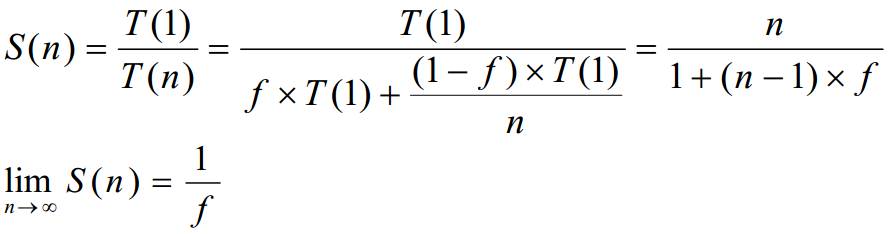

Практические ограничения ускорения

Джин Амдал сформулировал закон в 1967 году, обнаружив простое по существу, но непреодолимое по содержанию ограничение на рост производительности при распараллеливании вычислений:
«В случае, когда задача разделяется на несколько частей, суммарное время ее выполнения на параллельной системе не может быть меньше времени выполнения самого длинного фрагмента». Если разделяемая часть кода f может быть равномерно формально распределена по n процессорам, то закономерность может быть записана, как представлено на рис. 1.

Закон определяет теоретически возможную верхнюю границу, но на практике дело обстоит еще хуже – часть ресурсов каждого процессора уходит на обеспечение коллаборативной работы, а шины обладают конечной пропускной способностью.
Закон Густафсона
Единственная известная гипотеза о возможности преодоления описанных ограничений была высказана в 1988 году Джоном Густафсоном, но она не распространяется на подмножество фиксированных задач. На основании полученного опыта Густафсон пришел к выводу, что при построении более мощных систем пользователи стремятся не сократить время работы текущей версии задачи, а перейти к новой версии, обеспечивающей более высокое качество решения:
S(P)= P – l(P – 1), где P – число процессоров, S – ускорение, l – часть кода, не поддающаяся распараллеливанию.
Закон масштабируемого ускорения (Scaled Speedup):

Допустим, некоторую конструкцию можно рассчитать методом конечных элементов, и в таком случае, чем меньшим берется размер элемента, тем выше будет точность. Сегодня идеи Густафсона, связанные с совершенствованием методов коммуникации между узлами, реализуются в компании Massively Parallel Technologies (MPT), где, кстати, работает и сам Амдал. Допустимо сказать, что эти методы позволяют преодолеть ограничения закона, названного его именем, но только косвенно.
Принцип замены простых задач более сложными, предложенный Густафсоном, скорее экзотика, чем повседневная практика, поэтому в массовых приложениях, на которые рассчитываются многоядерные процессоры, действует закон Амдала.
Закон Амдала и его следствия
Приобретая
для решения своей задачи параллельную
вычислительную систему, пользователь
рассчитывает на значительное повышение
скорости вычислений за счет распределения
вычислительной нагрузки по множеству
параллельно работающих процессоров. В
идеальном случае система из N процессоров
могла бы ускорить вычисления в N раз. В
реальности достичь такого показателя
по ряду причин не удается. Главная из
этих причин заключается в невозможности
полного распараллеливания ни одной из
задач. Как правило, в каждой программе
имеется фрагмент кода, который
принципиально должен выполняться
последовательно и только одним из
процессоров. Это может быть часть
программы, отвечающая за запуск задачи
и распределение распараллеленного кода
по процессорам, либо фрагмент программы,
обеспечивающий операции ввода/вывода.
Можно привести и другие примеры, но
главное состоит в том, что о полном
распараллеливании задачи говорить не
приходится. Известные проблемы возникают
и с той частью задачи, которая поддается
распараллеливанию. Здесь идеальным был
бы вариант, когда параллельные ветви
программы постоянно загружали бы все
процессоры системы, причем так, чтобы
нагрузка на каждый процессор была
одинакова. К сожалению, оба этих условия
на практике трудно реализуемы. Таким
образом, ориентируясь на параллельную
ВС, необходимо четко сознавать, что
добиться прямо пропорционального числу
процессоров увеличения производительности
не удастся, и, естественно, встает вопрос
о том, на какое реальное ускорение можно
рассчитывать. Ответ на этот вопрос в
какой-то мере дает закон Амдала.
Джин
Амдал (Gene Amdahl) — один из разработчиков
всемирно известной системы IBM 360, в своей
работе [48], опубликованной в 1967 году,
предложил формулу, отражающую зависимость
ускорения вычислений, достигаемого на
многопроцессорной ВС, от числа процессоров
и соотношения между последовательной
и параллельной частями программы.
Показателем сокращения времени вычислений
служит такая метрика, как «ускорение».
Напомним, что ускорение S
— это отношение времени ![]() ,
затрачиваемого на проведение вычислений
на однопроцессорной ВС (в варианте
наилучшего последовательного алгоритма),
ко времени
,
затрачиваемого на проведение вычислений
на однопроцессорной ВС (в варианте
наилучшего последовательного алгоритма),
ко времени ![]() решения
той же задачи на параллельной системе
(при использовании наилучшего параллельного
алгоритма):
решения
той же задачи на параллельной системе
(при использовании наилучшего параллельного
алгоритма):
![]() Оговорки
относительно алгоритмов решения задачи
сделаны, чтобы подчеркнуть тот факт,
что для последовательного и параллельного
решения лучшими могут оказаться разные
реализации, а при оценке ускорения
необходимо исходить именно из наилучших
алгоритмов.
Проблема рассматривалась
Амдалом в следующей постановке (рис.
10.2).
Оговорки
относительно алгоритмов решения задачи
сделаны, чтобы подчеркнуть тот факт,
что для последовательного и параллельного
решения лучшими могут оказаться разные
реализации, а при оценке ускорения
необходимо исходить именно из наилучших
алгоритмов.
Проблема рассматривалась
Амдалом в следующей постановке (рис.
10.2).
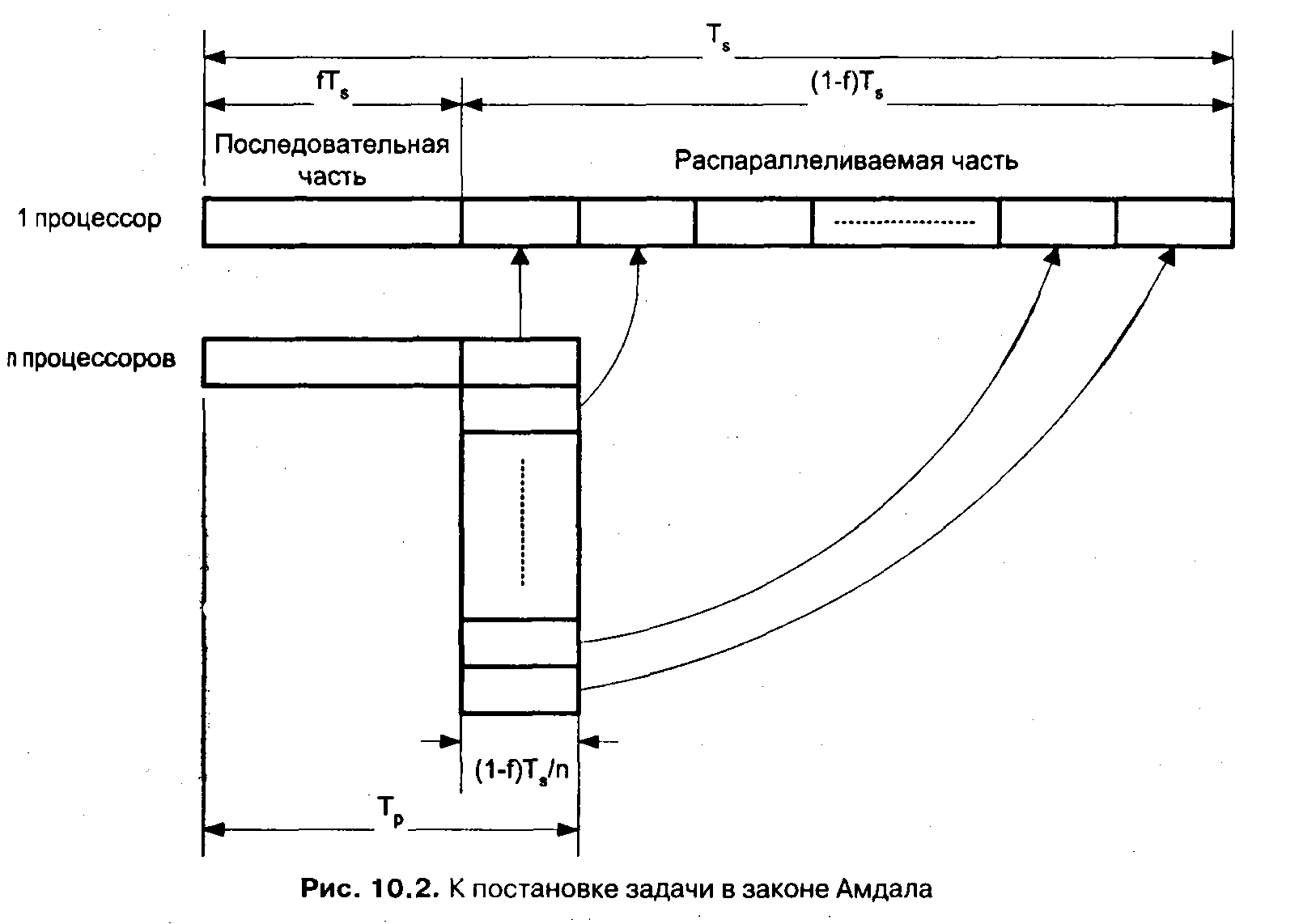 Прежде
всего, объем решаемой задачи с изменением
числа процессоров, участвующих в ее
решении, остается неизменным. Программный
код решаемой задачи состоит из двух
частей: последовательной и распараллеливаемой.
Обозначим долю операций, которые должны
выполняться последовательно одним из
процессоров, через f, где 0 ≤ f ≤ 1 (здесь
доля понимается не по числу строк кода,
а по числу реально выполняемых операций).
Отсюда доля, приходящаяся на
распараллеливаемую часть программы,
составит (1–f). Крайние случаи в значениях
f соответствуют полностью параллельным
(f=0) и полностью последовательным (f= 1)
программам. Распараллеливаемая часть
программы равномерно распределяется
по всем процессорам.
С учетом
приведенной формулировки имеем:
Прежде
всего, объем решаемой задачи с изменением
числа процессоров, участвующих в ее
решении, остается неизменным. Программный
код решаемой задачи состоит из двух
частей: последовательной и распараллеливаемой.
Обозначим долю операций, которые должны
выполняться последовательно одним из
процессоров, через f, где 0 ≤ f ≤ 1 (здесь
доля понимается не по числу строк кода,
а по числу реально выполняемых операций).
Отсюда доля, приходящаяся на
распараллеливаемую часть программы,
составит (1–f). Крайние случаи в значениях
f соответствуют полностью параллельным
(f=0) и полностью последовательным (f= 1)
программам. Распараллеливаемая часть
программы равномерно распределяется
по всем процессорам.
С учетом
приведенной формулировки имеем:
![]() В
результате получаем формулу Амдала,
выражающую ускорение, которое может
быть достигнуто на системе из N
процессоров:
В
результате получаем формулу Амдала,
выражающую ускорение, которое может
быть достигнуто на системе из N
процессоров:
![]() Закон
Амдала констатирует, что максимальное
ускорение для алгоритма ограничено
относительным числом операций, которые
должны быть выполнены последовательно,
то есть последовательной частью
алгоритма.
Отметим,
что при
Закон
Амдала констатирует, что максимальное
ускорение для алгоритма ограничено
относительным числом операций, которые
должны быть выполнены последовательно,
то есть последовательной частью
алгоритма.
Отметим,
что при ![]() величина
ускорения
величина
ускорения ![]() ,
то есть ускорение всегда ограничено
величиной
,
то есть ускорение всегда ограничено
величиной ![]() ,
независимо от числа используемых
процессоров. Проявление закона Амдала
при N = 10 и N = 1024 показано на рис. 6. Если
параллельная программа содержит 1%
последовательного кода, то максимальное
ускорение на 10 процессорах будет равно
9, а на 1024 процессорах — только 91. На рис.
7 приведена зависимость ускорения от
числа процессоров для различных
значений f.
,
независимо от числа используемых
процессоров. Проявление закона Амдала
при N = 10 и N = 1024 показано на рис. 6. Если
параллельная программа содержит 1%
последовательного кода, то максимальное
ускорение на 10 процессорах будет равно
9, а на 1024 процессорах — только 91. На рис.
7 приведена зависимость ускорения от
числа процессоров для различных
значений f.
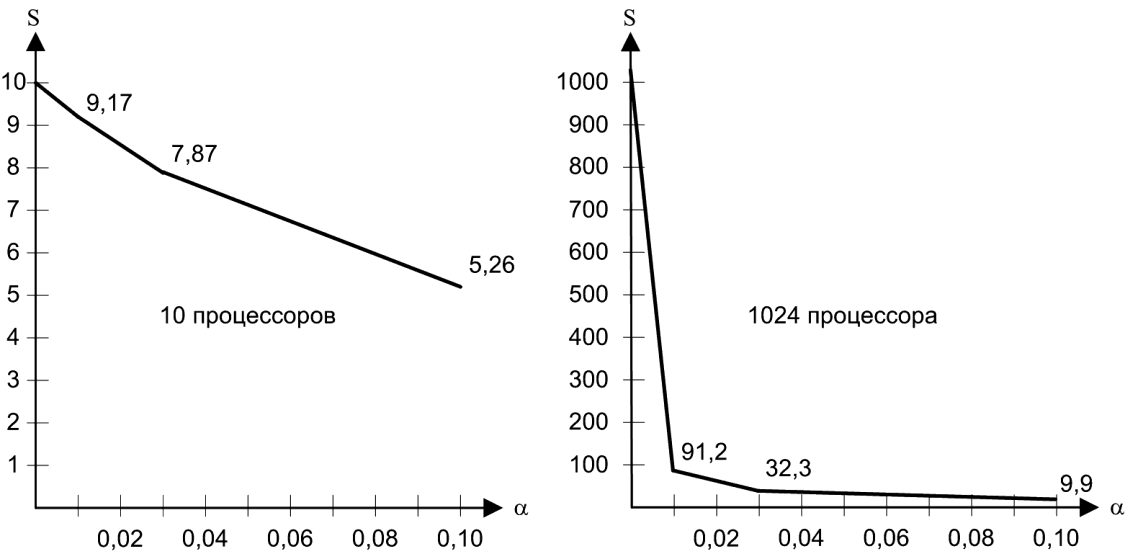 Рис.
6. Зависимость
ускорения от величины
для двух систем: с 10 процессорами и с
1024 процессорами
Рис.
6. Зависимость
ускорения от величины
для двух систем: с 10 процессорами и с
1024 процессорами
 Рис.
7. Зависимость
ускорения от числа процессоров для
различных значений
Следствия
из закона Амдала:
Рис.
7. Зависимость
ускорения от числа процессоров для
различных значений
Следствия
из закона Амдала:
последовательная часть накладывает строгие ограничения на ускорение, которое может быть достигнуто путем увеличения числа процессоров;
построение системы с большим числом процессоров неэффективно, поскольку достаточное ускорение при этом не достигается;
с другой стороны, большинство важных приложений, нуждающихся в распараллеливании, содержат очень незначительную долю последовательных вычислений и в этом случае системы с большим числом процессоров вполне обоснованы.
Посмотрим на проблему с другой стороны: а какую же часть кода надо ускорить (а значит и предварительно исследовать), чтобы получить заданное ускорение? Ответ можно найти в следствии из закона Амдала: для того чтобы ускорить выполнение программы в q раз необходимо ускорить не менее, чем в q раз не менее, чем (1-1/q)-ю часть программы. Следовательно, если есть желание ускорить программу в 100 раз по сравнению с ее последовательным вариантом, то необходимо получить не меньшее ускорение не менее, чем на 99.99% кода, что почти всегда составляет значительную часть программы! Отсюда первый вывод - прежде, чем основательно переделывать код для перехода на параллельный компьютер (а любой суперкомпьютер, в частности, является таковым) надо основательно подумать. Если, оценив заложенный в программе алгоритм, вы поняли, что доля последовательных операций велика, то на значительное ускорение рассчитывать явно не приходится и нужно думать о замене отдельных компонентов алгоритма. В ряде случаев последовательный характер алгоритма изменить не так сложно. Допустим, что в программе есть следующий фрагмент для вычисления суммы n чисел: s := 0 Do i = 1, n s = s + a(i) EndDo По своей природе он строго последователен, так как на i-й итерации цикла требуется результат с (i-1)-й и все итерации выполняются одна за одной. Имеем 100% последовательных операций, а значит и никакого эффекта от использования параллельных компьютеров. Вместе с тем, выход очевиден. Поскольку в большинстве реальных программ1 нет существенной разницы, в каком порядке складывать числа, выберем иную схему сложения. Сначала найдем сумму пар соседних элементов: a(1)+a(2), a(3)+a(4), a(5)+a(6) и т.д. Заметим, что при такой схеме все пары можно складывать одновременно! На следующих шагах будем действовать абсолютно аналогично, получив вариант параллельного алгоритма. Казалось бы в данном случае все проблемы удалось разрешить. Но представьте, что доступные вам процессоры разнородны по своей производительности. Значит, будет такой момент, когда кто-то из них еще трудится, а кто-то уже все сделал и бесполезно простаивает в ожидании. Если разброс в производительности компьютеров большой, то и эффективность всей системы при равномерной загрузке процессоров будет крайне низкой. Но пойдем дальше и предположим, что все процессоры одинаковы. Проблемы кончились? Опять нет! Процессоры выполнили свою работу, но результат-то надо передать другому для продолжения процесса суммирования... а на передачу уходит время... и в это время процессоры опять простаивают... Словом, заставить параллельную вычислительную систему или супер-ЭВМ работать с максимальной эффективность на конкретной программе это, прямо скажем, задача не из простых, поскольку необходимо тщательное согласование структуры программ и алгоритмов с особенностями архитектуры параллельных вычислительных систем.
Закон Густафсона для масштабируемых задач
Одним
из недостатков закона Амдала в плане
его применимости состоит в том, что он
не дает ответа в случае, когда при
увеличении размера вычислительной
системы и связанного с этим ростом
вычислительной мощности, увеличивают
и размер решаемой задачи. Наличие
широкого круга приложений, критичных
к времени вычислений, стало одним из
побудительных мотивов для совершенствования
концепции ускорения при фиксированной
нагрузке и согласованного с ней закона
Амдала. По мере того, как мы увеличиваем
размер вычислительной системы, чтобы
повысить ее мощность, возникает желание
увеличить размер решаемой задачи, с
тем, чтобы увеличить рабочую нагрузку,
сохраняя неизменным время
вычислений.
Известную
долю оптимизма в оценку, даваемую законом
Амдала, вносят исследования Джона
Густафсона из NASA Ames research. Решая на
вычислительной системе из 1024 процессоров
три больших задачи, для которых доля
последовательного кода f лежала в
пределах 0.4-0.8 % он получил ускорения по
сравнению с однопроцессорным вариантом,
равные соответственно 1021, 1020 и 1016.
Согласно закону Амдала для данного
числа процессоров и диапазона f, ускорение
не должно было превысить величину
порядка 201. Пытаясь объяснить это явление,
Густафсон пришел к выводу, что причина
кроется в исходной предпосылке, лежащей
в основе закона Амдала: увеличение числа
процессоров не сопровождается увеличением
объема решаемой задачи. Реальное же
поведение пользователей существенно
отличается от такого представления.
Обычно получая в свое распоряжение
более мощную систему, пользователь не
стремится сократить объем вычислений,
а сохраняя его практически неизменным,
старается пропорционально приросту
вычислительной мощности ВС увеличить
объем решаемой задачи. И тут оказывается,
что наращивание общего объема программы
касается главным образом распараллеливаемой
части программы. Это ведет к сокращению
значения f. Примером может служить
решение дифференциального уравнения
в частных производных. Если доля
последовательного кода составляет 10%
для 1000 узловых точек, то для 100000 точек
доля последовательного кода снизится
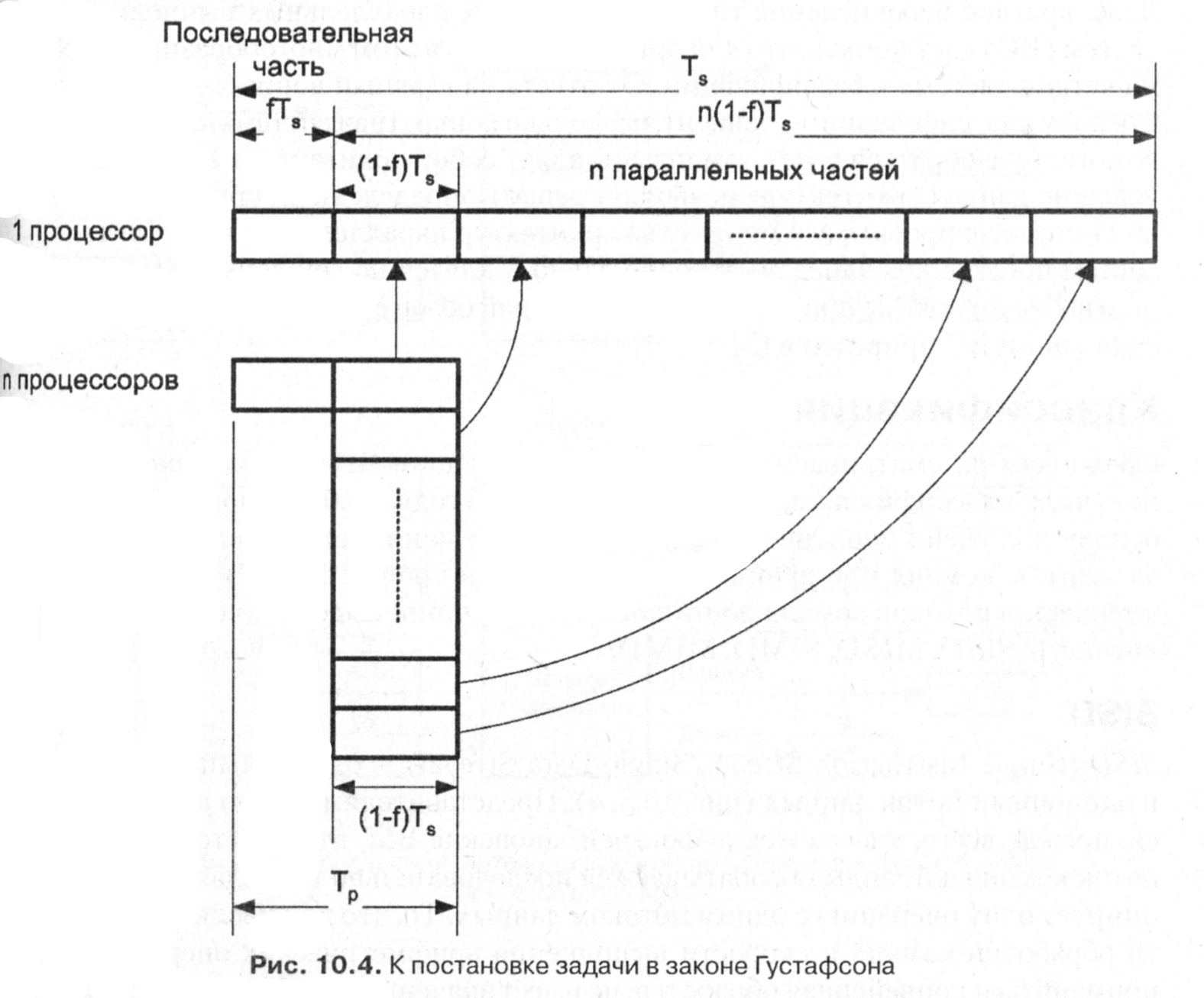
до 0.1%. Сказанное иллюстрирует рис. 10.4,
который отражает тот факт, что оставаясь
практически неизменной, последовательная
часть кода в общем объеме увеличенной
программы имеет уже меньший удельный
вес.
Было
отмечено, что в первом приближении объем
работы, которая может быть произведена
параллельно, возрастает линейно с ростом
числа процессоров в системе. Для того
чтобы оценить возможность ускорения
вычислений, когда объем последних
увеличивается с ростом количества
процессоров в системе (при постоянстве
общего времени вычислений), Густафсон
рекомендует использовать выражение,
предложенное Е. Барсисом (E. Barsis):
![]() Из
выражения следует, что если объем задачи
возрастает одновременно с мощностью
системы, последовательная часть перестает
быть узким местом.
Из
выражения следует, что если объем задачи
возрастает одновременно с мощностью
системы, последовательная часть перестает
быть узким местом.
 Данное
выражение известно как закон
масштабируемого ускорения или
закон Густафсона-Барсиса. Отметим, что
этот закон не противоречит закону
Амдала. Различие состоит лишь в форме
утилизации дополнительной вычислительной
мощности, возникающей при увеличении
числа процессоров.
Данное
выражение известно как закон
масштабируемого ускорения или
закон Густафсона-Барсиса. Отметим, что
этот закон не противоречит закону
Амдала. Различие состоит лишь в форме
утилизации дополнительной вычислительной
мощности, возникающей при увеличении
числа процессоров.
Модель ускорения при фиксированном размере памяти
В
1993 году Сан и Ни (Xian-He Sun, Lionel Ni) [SUNN93]
представили модель ускорения при
ограничениях на память вычислительной
системы, которая распространяет законы
Амдала и Густафсона на максимизацию
использования возможностей как
процессоров, так и памяти. Большие
научные и инженерные вычисления требует
наличия памяти значительной емкости.
Когда для решения большой задачи
совместно используется много узлов
многопроцессорной вычислительной
системы, емкость доступной памяти
пропорционально возрастает. Модель
ограниченной памяти была разработана
исходя из этой философии. Идея состоит
в решении максимально большой задачи,
ограниченной только емкостью памяти,
с достижением наибольшего ускорения,
более высокой точности и лучшего
использования ресурсов при условии
масштабируемой рабочей нагрузки.
Пусть
M — это требования к емкости памяти,
необходимой для решения определенной
проблемы, а W — вычислительная нагрузка.
Эти два фактора влияют друг на друга
по-разному, в зависимости от адресного
пространства и архитектурных ограничений.
Запишем это в виде W = g(M) или M = g-1(W). В
многопроцессорной системе емкость
памяти растет линейно с увеличением
числа узлов. Запишем рабочую нагрузку
последовательного выполнения вычислений
на одном узле, как  ,
а масштабированную рабочую нагрузку
для выполнения на n узлах —
,
а масштабированную рабочую нагрузку
для выполнения на n узлах —  ,
где m* — максимальная степень параллелизма
в масштабированной (увеличенной) задаче.
Тогда требования к емкости памяти для
активного узла можно записать в
виде
,
где m* — максимальная степень параллелизма
в масштабированной (увеличенной) задаче.
Тогда требования к емкости памяти для
активного узла можно записать в
виде  .
Ускорение
при фиксированной памяти определяется
аналогично тому, как это рассматривалось
раньше:
.
Ускорение
при фиксированной памяти определяется
аналогично тому, как это рассматривалось
раньше:
 Ранее
уже отмечалось, что с увеличением числа
узлов системы пропорционально
увеличивается и емкость памяти. Для
гомогенной системы из n узлов полагаем,
что g*(nM) = G(n)g(M) = G(n). Здесь коэффициент
G(n) отражает рост рабочей нагрузки с
увеличением памяти в n раз. В предположении
о том, что Wi =
0, если i
1 или i
n и Q(n) = 0, последнее выражение для ускорения
можно записать в виде:
Ранее
уже отмечалось, что с увеличением числа
узлов системы пропорционально
увеличивается и емкость памяти. Для
гомогенной системы из n узлов полагаем,
что g*(nM) = G(n)g(M) = G(n). Здесь коэффициент
G(n) отражает рост рабочей нагрузки с
увеличением памяти в n раз. В предположении
о том, что Wi =
0, если i
1 или i
n и Q(n) = 0, последнее выражение для ускорения
можно записать в виде:
 .
Модель
фиксированной памяти также предполагает
масштабируемую рабочую нагрузку и
допускает небольшое увеличение времени
вычислений. Увеличение рабочей нагрузки
(размера задачи) ограничено размером
памяти. Рост размера системы при большом
числе процессоров ограничен увеличением
времени на обмен информацией между
процессорами.
Проиллюстрируем
эту концепцию для алгоритма перемножения
матриц. Полагаем, что алгоритм содержит
фиксированную последовательную часть
и полностью распараллеливаемую остальную
часть. Положим также, что для одного
процессора размерность матрицы равна
m. Время последовательного исполнения
равно
T(1)
= W1 +
Wn =
W1 +
m3
При
n процессорах можно обработать матрицы
размерности
.
Модель
фиксированной памяти также предполагает
масштабируемую рабочую нагрузку и
допускает небольшое увеличение времени
вычислений. Увеличение рабочей нагрузки
(размера задачи) ограничено размером
памяти. Рост размера системы при большом
числе процессоров ограничен увеличением
времени на обмен информацией между
процессорами.
Проиллюстрируем
эту концепцию для алгоритма перемножения
матриц. Полагаем, что алгоритм содержит
фиксированную последовательную часть
и полностью распараллеливаемую остальную
часть. Положим также, что для одного
процессора размерность матрицы равна
m. Время последовательного исполнения
равно
T(1)
= W1 +
Wn =
W1 +
m3
При
n процессорах можно обработать матрицы
размерности ![]() поэтому
гипотетическое время последовательного
исполнения будет
T*(1)=W1+n3/2m3
Но
с n процессорами мы получаем
T*(1)=W1+n1/2m3
Таким
образом, ускорение равно
поэтому
гипотетическое время последовательного
исполнения будет
T*(1)=W1+n3/2m3
Но
с n процессорами мы получаем
T*(1)=W1+n1/2m3
Таким
образом, ускорение равно
 Для
матричного умножения время вычисления
возрастает быстрее, чем требования к
памяти. Следовательно, чем мощнее ВС,
тем большая проблема может быть решена,
но время выполнения растет, даже если
система становится все быстрее и быстрее.
В терминах ускорения это дает даже более
оптимистичную картину по сравнению с
ускорением при фиксированном времени.
Для
матричного умножения время вычисления
возрастает быстрее, чем требования к
памяти. Следовательно, чем мощнее ВС,
тем большая проблема может быть решена,
но время выполнения растет, даже если
система становится все быстрее и быстрее.
В терминах ускорения это дает даже более
оптимистичную картину по сравнению с
ускорением при фиксированном времени.