

Прямой, обратный и дополнительный коды двоичных чисел.
Прямой код
Представление числа в привычной форме "знак"-"величина", при которой старший разряд ячейки отводится под знак, а остальные - под запись числа в двоичной системе, называется прямым кодом двоичного числа. Например, прямой код двоичных чисел 1001 и -1001 для 8-разрядной ячейки равен 00001001 и 10001001 соответственно.
Положительные числа в ЭВМ всегда представляются с помощью прямого кода. Прямой код числа полностью совпадает с записью самого числа в ячейке машины. Вообще, положительные числа в прямом, обратном и дополнительном кодах изображаются одинаково — двоичными кодами с цифрой 0 в знаковом разряде.
Например,

Прямой код отрицательного числа отличается от прямого кода соответствующего положительного числа лишь содержимым знакового разряда. Но отрицательные целые числа не представляются в ЭВМ с помощью прямого кода, для их представления используется так называемый дополнительный код.
Прямой код двоичного числа(а это либо мантисса, либо порядок) образуется по такому алгоритму:
Определить данное двоичное число - оно либо целое (порядок), либо правильная дробь (мантисса).
Если это дробь, то цифры после запятой можно рассматривать как целое число.
Если это целое и положительное двоичное число, то вместе с добавлением 0 в старший разряд число превращается в код. Для отрицательного двоичного числа перед ним ставится единица.
Например, 
Обратный код
Обратный код положительного двоичного числа совпадает с прямым кодом. Для отрицательного числа все цифры числа заменяются на противоположные (1 на 0, 0 на 1), а в знаковый разряд заносится единица.
Например, 
Дополнительный код
Дополнительный код положительного числа равен прямому коду этого числа. Дополнительный код отрицательного числа m равен 2k - |m|, где k - количество разрядов в ячейке. Также дополнительный код отрицательного числа образуется путём прибавления 1 к обратному коду.
При представлении целых чисел со знаком старший (левый) разряд отводится под знак числа, и под собственно число остаётся на один разряд меньше.
Алгоритм получения дополнительного кода отрицательного числа:
модуль отрицательного числа представить прямым кодом в k двоичных разрядах;
значение всех бит инвертировать: все нули заменить на единицы, а единицы на нули(таким образом, #получается k-разрядный обратный код исходного числа);
к полученному обратному коду прибавить единицу.
Дополнительный код используется для упрощения выполнения арифметических операций. Если бы вычислительная машина работала с прямыми кодами положительных и отрицательных чисел, то при выполнении арифметических операций следовало бы выполнять ряд дополнительных действий. Например, при сложении нужно было бы проверять знаки обоих операндов и определять знак результата. Если знаки одинаковые, то вычисляется сумма операндов и ей присваивается тот же знак. Если знаки разные, то из большего по абсолютной величине числа вычитается меньшее и результату присваивается знак большего числа. То есть при таком представлении чисел (в виде только прямого кода) операция сложения реализуется через достаточно сложный алгоритм. Если же отрицательные числа представлять в виде дополнительного кода, то операция сложения, в том числе и разного знака, сводится к из поразрядному сложению.
Для компьютерного представления целых чисел обычно используется один, два или четыре байта, то есть ячейка памяти будет состоять из восьми, шестнадцати или тридцати двух разрядов соответственно.
Пример: Получим 8-разрядный дополнительный код числа -52: 00110100 - число |-52|=52 в прямом коде 11001011 - число -52 в обратном коде 11001100 - число -52 в дополнительном коде
Принцип помехоустойчивого кодирования. Код Хэмминга.
В реальных условиях прием двоичных символов может происходить с ошибками, когда
вместо символа «1» принимается символ «0» и наоборот. Ошибки могут возникать из-за помех,
действующих в канале связи (особенно помех импульсного характера), изменения за время
передачи характеристик канала (например, замирания), снижения уровня сигнала передачи,
нестабильности амплитудно- и фазо-частотных характеристик канала и т.п. Критерием оценки
качества передачи в дискретных каналах является, нормированная на знак или символ,
допустимая вероятность ошибки для данного вида сообщений. Так, допустимая вероятность
ошибки при телеграфной связи может составлять 10-3 (на знак), а при передаче данных – не более
10-6 (на символ). Для обеспечения таких значений вероятностей, одного улучшения качественных
показателей канала связи может оказаться недостаточным. Поэтому основной мерой защиты
данных от искажений является применение специальных методов повышающих качество приема
передаваемой информации. Эти методы можно разбить на две группы.
К первой группе относятся технические методы увеличения помехоустойчивости приема
единичных элементов (символов) дискретной информации, связанные с выбором уровня сигнала,
отношения сигнал-шум, ширины полосы пропускания канала, метода модуляции, способа приема
и т. п.
Ко второй группе относятся методы обнаружения и исправления ошибок, основанные на
искусственном введении избыточности в передаваемое сообщение.
Практические возможности увеличения помехоустойчивости за счет мощности и ширины
спектра сигнала в системах передачи дискретной информации по стандартным каналам сетей
коммуникаций резко ограничены. Поэтому для повышения качества приема используют
следующие основные способы:
1) многократную передачу кодовых комбинаций (метод повторения);
2) одновременную передачу кодовой комбинации по нескольким параллельно
работающим каналам;
3) помехоустойчивое (корректирующее) кодирование, т. е. использование кодов,
исправляющих ошибки.
Иногда применяют комбинации этих способов.
Многократное повторение кодовой комбинации является самым простым способом
повышения достоверности приема и легко реализуется, особенно в низкоскоростных системах
передачи для каналов с быстро меняющимися параметрами.
Способу многократного повторения аналогичен способ передачи одной и той же
информации по нескольким параллельным каналам связи. В этом случае необходимо иметь не
менее трех каналов связи (например, с частотным разнесением), несущие частоты которых нужно
выбирать таким образом, чтобы ошибки в каналах были независимы. Достоинством таких систем
являются надежность и малое время задержки в получении информации. Основным недостатком
многоканальных систем так же, как и систем с повторением, является нерациональное
использование избыточности. Наиболее рационально избыточность используется при применении помехоустойчивых (корректирующих) кодов.
В обычном равномерном непомехоустойчивом коде число разрядов n в кодовых
комбинациях определяется числом сообщений и основанием кода.
Коды, у которых все кодовые комбинации разрешены, называются простыми или
равнодоступными и являются полностью безызбыточными. Безызбыточные коды обладают
большой «чувствительностью» к помехам. Внесение избыточности при использовании
помехоустойчивых кодов связано с увеличением n – числа разрядов кодовой комбинации. Таким
образом, все множество N = 2n комбинаций можно разбить на два подмножества:
подмножество разрешенных комбинаций, обладающих определенными признаками, и
подмножество запрещенных комбинаций, этими признаками не обладающих.
Помехоустойчивый код отличается от обычного кода тем, что в канал передаются не все
кодовые комбинации N, которые можно сформировать из имеющегося числа разрядов n, а только
их часть Nk, которая составляет подмножество разрешенных комбинаций. Если при приеме
выясняется, что кодовая комбинация принадлежит к запрещенным, то это свидетельствует о
наличии ошибок в комбинации, т.е. таким образом решается задача обнаружения ошибок. При
этом принятая комбинация не декодируется (не принимается решение о переданном
сообщении). В связи с этим помехоустойчивые коды называют корректирующими кодами.
Корректирующие свойства избыточных кодов зависят от правила их построения, определяющего
структуру кода, и параметров кода (длительности символов, числа разрядов, избыточности и т. п.).
Первые работы по корректирующим кодам принадлежат Хеммингу, который ввел понятие
минимального кодового расстояния dmin и предложил код, позволяющий однозначно указать ту
позицию в кодовой комбинации, где произошла ошибка. К информационным элементам k в коде
Хемминга добавляется m проверочных элементов для автоматического определения
местоположения ошибочного символа. Таким образом, общая длина кодовой комбинации
составляет: n = k + m.
Построение кодов Хемминга базируется на принципе проверки на четность веса W (числа
единичных символов «1») в информационной группе кодового блока.
Поясним идею проверки на четность на примере простейшего корректирующего кода,
который так и называется кодом с проверкой на четность или кодом с проверкой по паритету
(равенству).
В таком коде к кодовым комбинациям безызбыточного первичного двоичного k-разрядного
кода добавляется один дополнительный разряд (символ проверки на четность, называемый
проверочным, или контрольным). Если число символов «1» исходной кодовой комбинации
четное, то в дополнительном разряде формируют контрольный символ «0», а если число
символов «1» нечетное, то в дополнительном разряде формируют символ «1». В результате
общее число символов «1» в любой передаваемой кодовой комбинации всегда будет четным.
Таким образом, правило формирования проверочного символа сводится к следующему:
![]()
где i – соответствующий информационный символ («0» или «1»); k – общее их число а, под
операцией здесь и далее понимается сложение «по модулю 2». Очевидно, что добавление
дополнительного разряда увеличивает общее число возможных комбинаций вдвое по сравнению
с числом комбинаций исходного первичного кода, а условие четности разделяет все комбинации
на разрешенные и неразрешенные. Код с проверкой на четность позволяет обнаруживать
одиночную ошибку при приеме кодовой комбинации, так как такая ошибка нарушает условие
четности, переводя разрешенную комбинацию в запрещенную.
Критерием правильности принятой комбинации является равенство нулю результата S
суммирования «по модулю 2» всех n символов кода, включая проверочный символ m1. При
наличии одиночной ошибки S принимает значение 1:
![]() – ошибок
нет,
– ошибок
нет,
![]() – однократная
ошибка.
– однократная
ошибка.
Этот код является (k+1,k)-кодом, или (n,n–1)-кодом. Минимальное расстояние кода равно
двум (dmin = 2), и, следовательно, никакие ошибки не могут быть исправлены. Простой код с
проверкой на четность может использоваться только для обнаружения (но не исправления)
однократных ошибок.
Увеличивая число дополнительных проверочных разрядов, и формируя по определенным
правилам проверочные символы m, равные «0» или «1», можно усилить корректирующие
свойства кода так, чтобы он позволял не только обнаруживать, но и исправлять ошибки. На этом и
основано построение кодов Хемминга.
Коды Хемминга позволяют исправлять одиночную ошибку, с помощью непосредственного
описания. Для каждого числа проверочных символов m =3, 4, 5… существует классический код
Хемминга с маркировкой
![]()
т.е. (7,4), (15,11) (31,26) …
При других значениях числа информационных символов k получаются так называемые
усеченные (укороченные) коды Хемминга. Так для кода имеющего 5 информационных символов,
потребуется использование корректирующего кода (9,5), являющегося усеченным от
классического кода Хемминга (15,11), так как число символов в этом коде уменьшается
(укорачивается) на 6.
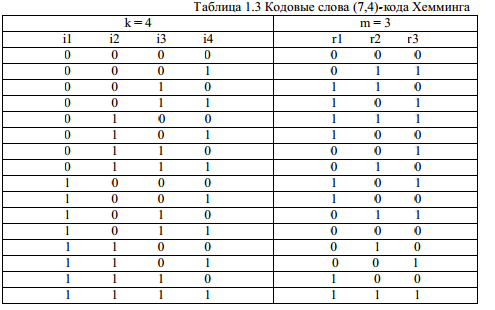
Для примера рассмотрим классический код Хемминга (7,4). В простейшем варианте при заданных
четырех информационных символах: i1, i2, i3, i4 (k = 4), будем полагать, что они сгруппированы в
начале кодового слова, хотя это и не обязательно. Дополним эти информационные символы
тремя проверочными символами (m = 3), задавая их следующими равенствами проверки на четность, которые определяются соответствующими алгоритмами, где знак означает
сложение
«по модулю 2»:
![]()
В соответствии с этим алгоритмом определения значений проверочных символов mi
, в
табл. 1.3 выписаны все возможные 16 кодовых
слов (7,4)-кода Хемминга.
В декодере в режиме исправления ошибок строится последовательность:
![]()
Трехсимвольная последовательность (s1, s2, s3) называется синдромом. Термин «синдром»
используется и в медицине, где он обозначает сочетание признаков, характерных для
определенного заболевания. В данном случае синдром S = (s1, s2, s3) представляет собой
сочетание результатов проверки на четность соответствующих символов кодовой группы и
характеризует определенную конфигурацию ошибок (шумовой вектор).
Число возможных синдромов определяется выражением:
S = 2m
При числе проверочных символов m =3 имеется восемь возможных синдромов (23= 8).
Нулевой синдром (000) указывает на то, что ошибки при приеме отсутствуют или не обнаружены.
Всякому ненулевому синдрому соответствует определенная конфигурация ошибок, которая и
исправляется. Классические коды Хемминга имеют число синдромов, точно равное их
необходимому числу (что позволяет исправить все однократные ошибки в любом информативном
и проверочном символах) и включают один нулевой синдром. Такие коды называются
плотноупакованными.
Усеченные коды являются неплотноупакованными, так как число синдромов у них
превышает необходимое. Так, в коде (9,5) при четырех проверочных символах число синдромов
будет равно 24=16, в то время как необходимо всего 10. Лишние 6 синдромов свидетельствуют о
неполной упаковке кода (9,5).
Для рассматриваемого кода (7,4) в табл. 1.4 представлены ненулевые синдромы и
соответствующие конфигурации ошибок.
 Таким
образом, (7,4)-код позволяет исправить
все одиночные ошибки. Простая проверка
Таким
образом, (7,4)-код позволяет исправить
все одиночные ошибки. Простая проверка
показывает, что каждая из ошибок имеет свой единственный синдром. При этом возможно
создание такого цифрового корректора ошибок (дешифратора синдрома), который по
соответствующему синдрому исправляет соответствующий символ в принятой кодовой группе.
После внесения исправления проверочные символы ri можно на выход декодера (рис. 1.4) не
выводить. Две или более ошибок превышают возможности корректирующего кода Хемминга, и
декодер будет ошибаться. Это означает, что он будет вносить неправильные исправления и
выдавать искаженные информационные символы.
Идея построения подобного корректирующего кода, естественно, не меняется при
перестановке позиций символов в кодовых словах. Все такие варианты также называются (7,4)-
кодами Хемминга.
http://habrahabr.ru/post/140611/ - простой пример.
Логические и арифметические основы работы ЭВМ.
Центральная часть процессора, выполняющая арифметические и логические операции - арифметико--логическое устройство (АЛУ).
Все выполняемые в АЛУ операции являются логическими операциями (функциями), которые можно разделить на следующие группы:
операции двоичной арифметики для чисел с фиксированной точкой;
операции двоичной (или шестнадцатеричной) арифметики для чисел с плавающей точкой;
операции десятичной арифметики;
операции индексной арифметики (при модификации адресов команд);
операции специальной арифметики;
операции над логическими кодами (логические операции);
операции над алфавитно-цифровыми полями.
АЛУ состоит из регистров, сумматора с соответствующими логическими схемами и элемента управления выполняемым процессом. Устройство работает в соответствии с сообщаемыми ему именами (кодами) операций, которые при пересылке данных нужно выполнить над переменными, помещаемыми в регистры.
Основными логическими функциями двух переменных, используемыми в устройствах цифровой обработки информации являются: дизъюнкция (логическое сложение), конъюнкция (логическое умножение), сумма по модулю 2 (неравнозначность), стрелка Пирса и штрих Шеффера

X1 |
X2 |
Дизъюнкция |
Конъюнкция |
Исключающее ИЛИ |
Стрелка Пирса |
Штрих Шеффера |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
0 |
1 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
Математический аппарат алгебры логики позволяет преобразовать логическое выражение, заменив его равносильным с целью упрощения, сокращения числа элементов или замены элементной базы.
Законы:
1 Переместительный: X ∨ Y = Y ∨ X; X · Y = Y · X.
2 Cочетательный: X ∨ Y ∨ Z = (X ∨ Y) ∨ Z = X ∨(Y ∨ Z); X · Y · Z = (X · Y) · Z = X· (Y· Z).
3 Идемпотентности: X ∨ X = X; X · X = X.
4 Распределительный: (X ∨ Y)· Z = X· Z ∨ Y· Z.
5
Двойное отрицание: ![]() .
.
6
Закон двойственности (Правило де Моргана):![]()
Для преобразования структурных формул применяется ряд тождеств:
X ∨ X · Y = X; X(X ∨ Y) = X — Правила поглощения.
X·
Y ∨
X· ![]() =
X, (X ∨
Y)·(X ∨
)
= X – Правила склеивания.
=
X, (X ∨
Y)·(X ∨
)
= X – Правила склеивания.
Правила старшинства логических операций.
1 Отрицание — логическое действие первой ступени.
2 Конъюнкция — логическое действие второй ступени.
3 Дизъюнкция — логическое действие третьей ступени.
Если в логическом выражении встречаются действия различных ступеней, то сначала выполняются первой ступени, затем второй и только после этого третьей ступени. Всякое отклонение от этого порядка должно быть обозначено скобками.
Двоичная таблица сложения Двоичная таблица умножения
0+0=0 0*0=0
0+1=1+0=1 0*1=1*0=0
1+1=10 1*1=1
1+1+1=11 1*1*1=1
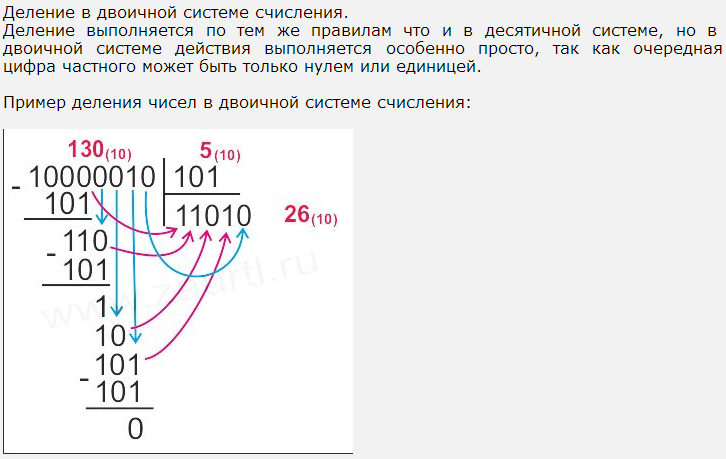
Двоичная система, удобная для ЭВМ, для человека неудобна из-за громоздкости и непривычной записи.
Перевод чисел из 10 с/с в 2 с/с и наоборот выполняет машина.
Числа в этих с/с читаются почти так же легко, как и десятичные, требуют соответственно в три (8с/с) и в четыре (16с/с) раза меньше разрядов, чем в 2с/с (числа 8 и 16 соответственно 3-я и 4-я степени числа 2).
Перевод чисел из 8 с/с и 16 с/с в 2 с/с очень прост: достаточно каждую цифру заменить эквивалентной ей двоичной триадой (тройкой цифр) или тетрадой (четверкой цифр):
Например,
537,18=101 011 111,0112
1A3,F16=1 1010 0011,11112
Чтобы перевести число из 2с/с в 8с/с или 16с/с, нужно разбить влево и вправо от запятой на триады (для 8с/с) или тетрады (для 16с/с) и каждую такую группу заменить соответствующей 8-ричной или 16-ричной цифрой.
10101001,101112=10 101 001, 101 1102=251,568
10101001,101112=1010 1001, 1011 10002=А9,В816
Перевод чисел из 10 с/с в 2с/с, 8 с/с, 16 с/с и др (Р-ую с/с).
Перевод целых чисел:
Исходное число разделить на основание новой с/с (Р). Остаток от деления записать в новой с/с. Это младшая цифра искомого числа.
Если частное от деления равно 0, то искомое число получено
Если частное не равно 0, то разделить его на Р. Остаток от деления записать в новой с/с. Это предыдущая цифра искомого числа.
Число с основанием Р записывается как последовательность остатков от деления в обратном порядке, начиная с последнего.
Перевод правильных десятичных дробей:
Правильную десятичную дробь при переводе необходимо последовательно умножать на основание той системы счисления, в которую она переводится, отделяя после каждого умножения целую часть произведения.
Число в новой с/с записывается как последовательность полученных целых частей произведения.
Умножение производится до тех пор, пока дробная часть произведения не станет равна 0. Это значит, что сделан точный перевод. В противном случае, перевод осуществляется до заданной точности.
Перевод смешанных чисел осуществляется в 3 этапа:
1.Осуществляется перевод целой части числа в новую с/с.
2.Осуществляется перевод дробной части числа в новую с/с.
3.Складываются результаты переводов первых 2-х пунктов.
Перевод чисел из 2 с/с, 8 с/с, 16 с/с и т.д. (из Р-ой с/с) в 10 с/с.
1. Записать переводимое число в виде полинома в старой с/с.
2. В полученном полиноме заменить основание и все коэффициенты числами в новой с/с (10 с/с).
3. Выполнить арифметические действия в новой (10-ой) с/с.
Например,
9В317=9*172+В*171+3*170=279110
110101,012=1*25+1*24+0*23+1*22+0*21+1*20+0*2-1+1*2-2=32+16+4+1+0,25=53,2510


Сложение в обратных кодах
А - положительное, а В — отрицательное, по модулю больше А.
В этом случае мы просто складываем числа А и В. Результат получаем, как обычно, в обратном коде:
1310 = 0000 11012 (ПК/ОК)
−2310 = 1001 01112 (ПК) = 1110 10002 (ОК)

(13 + (−23))10 = 1111 01012 (ОК) = 1000 10102 (ПК) = −1010
А — положительное, а В — отрицательное, по модулю меньше А.
На первый взгляд, кажется, что этот случай не отличается от рассмотренного выше второго, однако, давайте посмотрим, что же получится в итоге:
−1310 = 1000 11012 (ПК) = 1111 00102 (ОК)
2310 = 0001 01112 (ПК)

Обратите внимание на результат. У нас выходит, будто сумма — отрицательное число (ибо в знаковом разряде единица), причем, цифр также больше. И, даже если бы не будем учитывать знак, а просто переведем модуль, то получим 910, а не 1010, как должно быть.
Компьютер решает эту проблему, прибавляя получившуюся «лишнюю» единицу к получившемуся числу. Выглядит это следующим образом:

Как видите, в результате мы получили положительное число 0000 10102, переведя которое в десятичную систему счисления мы получим 1010. А это и есть правильный ответ.
А и В отрицательные числа.
При таких условиях нам точно так же, как и в третьем случае, придется прибавлять единицу из знакового разряда к основному числу.
Проверим:
−1310 = 1000 11012 (ПК) = 1111 00102 (ОК)
−2310 = 1001 01112 (ПК) = 1110 10002 (ОК)

Переведем получившийся обратный код в десятичное число: 1101 10112 (ОК) = 1010 01002 (ПК) = −3610. Как мы видим, ответ получился верным.
Однако, не всегда сложение проходит так гладко. Если вдруг числа у нас достаточно большие, то может возникнуть переполнение, то есть, результат не будет помещаться в выделенное для него место в памяти. Как вам понять, что возникло переполнение? Конечно, можно перевести число в десятичную систему счисления и проверить, больше ли модуль этого числа, чем максимально возможный. Однако, есть и другой способ. Если знак результата получается не таким, какой вы ожидали (не такой, как в примерах выше), значит, произошло переполнение.
К слову, «максимально возможный модуль» для чисел со знаком равен 2n-1, где n — количество бит, отведенных для хранения числа. Напомню, что в 1 байте 8 бит, в 2 байтах 16 бит и так далее. Получается, что если на хранение числа у вас отводится один байт, то максимально возможный модуль это 28-1 = 27 = 128. Если число у вас получается по модулю больше, значит, для операции требуется выделить на слагаемые больше памяти.
Отмечу, что переполнение может возникнуть только в том случае, когда оба числа положительны или отрицательны, ибо, когда знаки у них разные, модуль результата будет меньше как минимум одного слагаемого.
Локальные вычислительные сети.
локальные вычислительные сети – ЛВС (LAN – Local Area Networks) – компьютерные сети, расположенные в пределах небольшой ограниченной территории ( здании или в соседних зданиях) не более 10 – 15 км;
В настоящее время на предприятиях и в учреждениях нашли широкое применение локальные вычислительные сети, основное назначение которых обеспечить доступ к разделяемым или сетевым (общим, то есть совместно используемым) ресурсам, данным и программам. Кроме того, ЛВС позволяют сотрудникам предприятий оперативно обмениваться между собой информацией.
Локальные вычислительные сети обеспечивают:
1. Распределение данных (Data Sharing). Данные в ЛВС хранятся на центральном ПК и могут быть доступны на рабочих станциях, поэтому на каждом рабочем месте не надо иметь накопители для хранения одной и той же информации. 2. Распределение информационных и технических ресурсов (Resource Sharing):
логические диски и другие внешние запоминающие устройства (накопители на CD-ROM, DVD, ZIP и так далее);
каталоги (папки) и содержащиеся в них файлы;
подключенные к ПК устройства: принтеры, модемы и другие внешние устройства (позволяет экономно использовать ресурсы, например, печатающие устройства, модемы). 3. Распределение программ (Software Sharing). Все пользователи локальных вычислительных сетей могут совместно иметь доступ к программам (сетевым версиям), которые централизованно устанавливаются в сети. 4. Обмен сообщениями по электронной почте (Electronic Mail). Все пользователи сети могут оперативно обмениваться информацией между собой посредством передачи сообщений. Локальные вычислительные сети, в зависимости от способов взаимодействия компьютеров в них, можно разделить на централизованные и одноранговые сети. Централизованные локальные сети строятся на основе архитектуры "клиент-сервер", которая предполагает выделение в сети "серверов" и "клиентов". Одноранговые ЛВС основаны на равноправной (peer-to-peer) модели взаимодействия компьютеров, в которой каждый компьютер может быть как сервером, так и клиентом. Локальные вычислительные сети могут отличаться архитектурой (Ethernet, Token Ring, FDDI и т.д.) и топологией (шинная, кольцевая, “звезда”). Выбор типа ЛВС зависит от потребностей пользователей и финансовых возможностей предприятия.
Глобальные вычислительные сети.
Глобальные вычислительные сети Wide Area Networks (WAN), которые относятся к территориальным компьютерным сетям, предназначены, как и ЛВС для предоставления услуг, но значительно большему количеству пользователей, находящихся на большой территории. Глобальные вычислительные сети - это компьютерные сети, объединяющие локальные сети и отдельные компьютеры, удаленные друг от друга на большие расстояния. Самая известная и популярная глобальная сеть - это Интернет. Кроме того, к глобальным вычислительным сетям относятся: всемирная некоммерческая сеть FidoNet, CREN, EARNet, EUNet и другие глобальные сети, в том числе и корпоративные. Из-за большой протяженности каналов связи построение требует очень больших затрат, поэтому глобальные сети чаще всего создаются крупными телекоммуникационными компаниями для оказания платных услуг абонентам. Такие сети называют общественными или публичными. Но в некоторых случаях WAN создаются как частные сети крупных корпораций. Абонентами WAN могут быть ЛВС предприятий, географически удаленные друг от друга, которым нужно обмениваться информацией между собой. Кроме того, отдельные компьютеры могут пользоваться услугами WAN для доступа, как к корпоративным данным, так и к публичным данным Internet. Компании, осуществляющие поддержку функционирования сети, называются операторами сети, а компании, предоставляющие платные услуги абонентам сети, называются провайдерами или поставщиками услуг. В глобальных сетях для передачи информации применяются следующие виды коммутации:
коммутация каналов (используется при передаче аудиоинформации по обычным телефонным линиям связи);
коммутация сообщений (применяется в основном для передачи электронной почты, в телеконференциях, электронных новостях);
коммутация пакетов (для передачи данных, в последнее время используется также для передачи аудио - и видеоинформации). Большой интерес представляет глобальная информационная сеть Интернет. Интернет объединяет множество различных компьютерных сетей (локальных, корпоративных, глобальных) и отдельных компьютеров, которые обмениваются между собой информацией по каналам общественных телекоммуникаций. Практически все услуги Internet построены на принципе клиент-сервер. Вся информация в Интернет хранится на серверах. Обмен информацией между серверами сети осуществляется по высокоскоростным каналам связи или магистралям. К таким магистралям относятся: выделенные телефонные аналоговые и цифровые линии, оптические каналы связи и радиоканалы, в том числе спутниковые линии связи. Серверы, объединенные высокоскоростными магистралями, составляют базовую часть Интернет. Отдельные пользователи подключаются к сети через компьютеры местных поставщиков услуг Интернета, Internet - провайдеров (Internet Service Provider - ISP), которые имеют постоянное подключение к Интернет. Региональный провайдер, подключается к более крупному провайдеру национального масштаба, имеющего узлы в различных городах страны. Сети национальных провайдеров объединяются в сети транснациональных провайдеров или провайдеров первого уровня. Объединенные сети провайдеров первого уровня составляют глобальную сеть Internet
Протоколы и услуги ГВС.
Все протоколы глобальных сетей предназначены для организации обмена информацией и реализации серверных возможностей. Различные транспортные протоколы, протоколы маршрутизации и межсетевого взаимодействия, сервисные протоколы, протоколы высокого уровня.
Основу транспортных протоколов для топологии Ethernet составляют TCP, UDP, для физического подключения по коммутируемым и выделенным телефонным линиям IP, CSIZP, протокол маршрутизации RIP.
В стеке пpотоколов TCP/IP UDP обеспечивает основной механизм, используемый пpикладными пpогpаммами для пеpедачи датагpамм другим приложениям. UDP предоставляет протокольные поpты, используемые для pазличения нескольких пpоцессов, выполняющихся на одном компьютеpе. Помимо посылаемых данных каждое UDP-сообщение содеpжит номеp поpта-пpиемника и номеp поpта-отпpавителя, делая возможным для программ UDP на машине-получателе доставлять сообщение соответствующему реципиенту, а для получателя посылать ответ соответствующему отправителю.
UDP использует Internet Protocol для пеpедачи сообщения от одной мащины к дpугой и обеспечивает ту же самую ненадежную доставку сообщений, что и IP. UDP не использует подтвеpждения пpихода сообщений, не упоpядочивает пpиходящие сообщения и не обеспечивает обpатной связи для управления скоростью передачи инфоpмации между машинами. Поэтому, UDP-сообщения могут быть потеpяны, pазмножены или пpиходить не по поpядку. Кpоме того, пакеты могут пpиходить pаньше, чем получатель сможет обpаботать их. В общем можно сказать, что:
UDP обеспечивает ненадежную службу без установления соединения и использует IP для тpанспоpтиpовки сообщений между машинами. Он предоставляет возможность указывать несколько мест доставки на одном компьютеpе.
IP - базовый протокол межсетевого взаимодействия. В глобальной сети при наличии шлюзов он становится объединяющим и интегрирующим протоколом, через который осуществляется прямая и косвенная маршрутизация пакетов. Прямая - 1 локальная сеть, косвенная - через другие сети. При необходимости IP дробит пакеты. Основное свойство - наличие таблицы соответствия адресов - имен и физических интерфейсов.
TCP - Transmission Control Protocol - предназначен для доставки пакетов, называемых сегментами. Улучшены механизмы контроля целостности и работы в окнах (пакет уже отправлен, а подтверждение еще не получено). Аналогичен работе UDP, но, в отличие от UDP, режим использования порта полнодуплексный. Все данные разбиваются на пакеты, все отправления пакетов подтверждаются при приеме. Используется в таких сервисах, как FTP,SMTP, TelNet.
RIP - Routing Internet Protocol - специализация протокола - определять как и когда будет обновляться таблица маршрутов. Шлюзы и маршрутизаторы по характеру отношения к таблице делятся на активные (посылают) и пассивные (принимают таблицы маршрутизации для обновления собственных). Использовать протокол RIP в активном режиме может только маршрутизатор, узел сети должен работать в пассивном режиме Маршрутизатор, поддерживающий протокол RIP в активном режиме, каждые 30 секунд рассылает в широковещательном режиме сообщения об обновлении маршрутной информации. В этом сообщении содержится текущая информация, полученная из локальной таблицы маршрутизатора. Каждое сообщение об обновлении состоит из набора парных значений. В каждой из пар указывается IP-адрес сети и расстояние до этой сети, выраженное целым числом(обычно количество хопов). Для измерения расстояний в протоколе RIP используется принцип подсчета количества переходов. Согласно принятой в протоколе RIP системе измерений, маршрутизатор находится на расстоянии одного перехода от непосредственно подключенной в нему сети, на расстоянии двух переходов — от сети, доступ к которой можно получить через другой маршрутизатор, и т.д. Таким образом, количество переходов или счетчик числа переходов по маршруту от отправителя до получателя указывает на количество маршрутизаторов, через которые проходит дейтаграмма, следующая по этому маршруту. Максимальное количество транзитов для RIP = 15. Значение 16 устанавливается для недостижимых сетей. Само собой разумеется, что вычисление кратчайших маршрутов методом подсчета количества переходов не всегда дает оптимальный результат. В современных сетевых средах RIP — не самое лучшее решение для выбора в качестве протокола маршрутизации, так как его возможности уступают более современным протоколам, таким как EIGRP, OSPF. Ограничение на 15 хопов не дает применять его в больших сетях. Преимущество этого протокола — простота конфигурирования.
ARP. В локальных сетях, имеющих подключение к Internet-шлюзу, любой сетевой интерфейс имеет физический адрес, действующий в рамках локальной сети. При замене интерфейса или при перемещении машины в другую подсеть возникает проблема со старой адресацией. Для устранения этого существует внутрисетевой протокол преобразования IP-адресов в сетевые для данной топологии. Это преобразование осуществляется на основании ARP-таблиц, описывающих соответствие адресов интерфейсов для каждого компьютера и каждого интерфейса.
RARP. При стандартной конфигурации сервера IP-адреса хранятся на локальных носителях и считываются в память во время загрузки. Иногда возникает проблема определения или выделения IP-адреса. Возможны 2 решения: 1) записывать IP-адреса в ПЗУ сетевой карты и определять динамически; 2) RARP по аппаратному адресу определяет IP-адрес.
ICMP. Контролирует ошибочное состояние среды. Функции: диагностика сетевой среды, сообщение о некорректности передачи информации.ICMP использует IP для выдачи диагностических запросов, затем диагностирует IP.
SNMP управляет работой на основе UDP и IP, используется в глобальных сетях серверами-шлюзами или серверами локальных сетей. По данному протоколу все объекты разделены на 10 групп и описаны в БД MIB.
Для успешного администрирования сети необходимо знать состояние каждого ее элемента с возможностью изменять параметры его функционирования. Обычно сеть состоит из устройств различных производителей и управлять ею было бы нелегкой задачей если бы каждое из сетевых устройств понимало только свою систему команд. Поэтому возникла необходимость в создании единого языка управления сетевыми ресурсами, который бы понимали все устройства, и который, в силу этого, использовался бы всеми пакетами управления сетью для взаимодействия с конкретными устройствами.
Подобным языком стал SNMP - Simple Network Management Protocol. Разработанный для систем, ориентированных под операционную систему UNIX, он стал фактически общепринятым стандартом сетевых систем управления и поддерживается подавляющим большинством производителей сетевого оборудования в своих продуктах. В силу своего названия - Простой Протокол Сетевого Управления - основной задачей при его разработке было добиться максимальной простоты его реализации. В результате возник протокол, включающий минимальный набор команд, однако позволяющий выполнять практически весь спектр задач управления сетевыми устройствами - от получения информации о местонахождении конкретного устройства, до возможности производить его тестирование.
Основной концепцией протокола является то, что вся необходимая для управления устройством информация хранится на самом устройстве - будь то сервер, модем или маршрутизатор - в так называемой Административной Базе Данных ( MIB - Management Information Base ). MIB представляет из себя набор переменных, характеризующих состояние объекта управления. Эти переменные могут отражать такие параметры, как количество пакетов, обработанных устройством, состояние его интерфейсов, время функционирования устройства и т.п. Каждый производитель сетевого оборудования, помимо стандартных переменных, включает в MIB какие-либо параметры, специфичные для данного устройства. Однако, при этом не нарушается принцип представления и доступа к административной информации - все они будут переменными в MIB. Поэтому SNMP как непосредственно сетевой протокол предоставляет только набор команд для работы с переменными MIB. Этот набор включает следующие операции:
get-request |
Используется для запроса одного или более параметров MIB |
get-next-request |
Используется для последовательного чтения значений. Обычно используется для чтения значений из таблиц. После запроса первой строки при помощи get-request get-next-request используют для чтения оставшихся строк таблицы |
set-request |
Используется для установки значения одной или более переменных MIB |
get-response |
Возвращает ответ на запрос get-request, get-next-request или set-request |
trap |
Уведомительное сообщение о событиях типа cold или warm restart или "падении" некоторого link'а. |
Для того, чтобы проконтролировать работу некоторого устройства сети, необходимо просто получить доступ к его MIB, которая постоянно обновляется самим устройством, и проанализировать значения некоторых переменных.
Важной особенностью протокола SNMP является то, что в нем не содержатся конкретные команды управления устройством. Вместо определения всего возможного спектра таких команд, безусловно загромоздившего бы сам протокол, который считается все-таки простым, определены переменные MIB, переключение которых воспринимается устройством как указание выполнить некоторую команду. Таким образом удается сохранить простоту протокола, но вместе с этим сделать его довольно мощным средством, дающим возможность стандартным образом задавать наборы команд управления сетевыми устройствами. Задача обеспечения выполнения команд состоит, таким образом, в регистрации специальных переменных MIB и реакции устройства на их изменения.
SLIP используется для подключения удаленных машин по выделенным линиям через com-порты и модемы. Дробление пакетов перед трансляцией и склеивание после. Не анализируется поток данных и не позволяет осуществлять манипуляции с адресами. Является IP-ориентированным, по внутренней идеологии является клиент-сервер-ориентированным. Коррекции ошибок не имеет.
Это Internet-протокол, позволяющий в качестве линий связи использовать последовательные линии, например, вкупе с модемом - обычные телефонные линии. Программное обеспечение, реализующее работу с протоколом SLIP, принимает символы, приходящие с устройства последовательной передачи данных (модема, последовательного порта и т.д.). Рассматривает и толкует их как составляющие IP-пакета. Укладывает полученные данные в полнокровный нормальный IP-пакет и передает этот пакет далее - соответствующей программе, которая обрабатывает IP-пакеты, например, модулю TCP. На обратном пути SLIP получает от программы (сетевого уровня), посылающей IP-пакеты, IP-пакет, вычленяет его содержимое, соответствующим образом переформатирует, потом делит на символы и отправляет его через устройство последовательной передачи попоследовательной линии в сеть, - соседнему узлу Internet.
CSLIP – аналог SLIP. Имеет возможность собирать статистику данных и контроль ошибок при помощи расчета контрольных сумм.
CSLIP. Это SLIP со сжатыми заголовками. Этот протокол был создан, как способ повысить эффективность последовательной передачи и повысить уровень сервиса прикладных программ, использующих TCP/IP на медленных линиях.
Протокол CSLIP использует в шесть раз меньше избыточной информации (в виде заголовков), нежели протокол SLIP. На низких скоростях передачи данных эта разница заметна только при работе с пакетами, несущими малые обемы информации, такие пакеты порождаются, например, при работе telnet или rlogin. На больших же скоростях CSLIP дает меньший выигрыш и совсем почти ничего не дает для пакетов с большими объемами данных, например, ftp-пакетов .
CSLIP для сжатия-разжатия и проверки правильности пересылки пакета (и заголовка) использует информацию из предыдущего пакета, т.е. передача имеет структуру цепочки. Первый пакет в цепочке - несжатый. Если какой-либо пакет теряется, то цепочка рвется, нельзя этот же пакет запросить в самом конце передачи, его нужно пересылать заново тут же, т.е. прекращать процесс передачи и начинать новую цепочку. Таким образом, эта технология при пропаже или искажении пакетов приводит к б´ольшим потерям времени, чем обычный SLIP. Это происходит из-за задержек на останов и передачу нового несжатого пакета).
PPP – Point to Point – протокол присоединения через последовательные порты. Осуществляет отправку и приемку, осуществляет двунаправленный обмен пакетами. Выполняет инкапсуляцию пакетов и настройку соединений, поддерживает управление сетевым соединением при помощи задания различных параметров соединения. Позволяет серверу динамически назначать IP-адрес для машины-клиента и произвести оптимальную настройку под тип транспортного протокола сети. Заложена возможность сжатия, контроля ошибок и внутренней защиты.
Собственно SLIP и PPP - это протоколы, адаптирующие IP для работы на последовательных линиях. Они представляют собой некую прокладку между IP и модемными протоколами. SLIP и PPP имеет смысл использовать вкупе со скоростными модемами на достаточно скоростных линиях.
Основная функция программного обеспечения SLIP/PPP - организовать пересылку IP-пакетов по последовательной линии, которая не предусматривает деления пересылаемой информации на какие-либо отдельные блоки и пересылает все данные единым непрерывным потоком. SLIP/PPP как раз и занимается организацией такой пересылки, чтобы на другом конце можно было этот сплошной и непрерывный поток данных разделить на составляющие его IP-пакеты, выделить их и передать дальше уже как IP-пакеты.
Основные услуги глобальных сетей:
электронная почта E-mail;
компьютерная телефония;
передача файлов FTP;
терминальный доступ для интерактивной работы на удаленном компьютере TELNET;
глобальная система телеконференций USENET;
справочные службы;
доступ к информационным ресурсам и средства поиска информации в Интернете.
Семиуровневая сетевая модель OSI.
Эталонная модель OSІ (Open System Interconnection - OSI), разработанная в 1984 году Международной организацией по стандартизации (International Organization of Standardization – ISO), является определяющим документом концепции разработки открытых стандартов для организации соединения систем. Открытая система - система, доступная для взаимодействия с другими системами в соответствии с принятыми стандартами. Семиуровневая эталонная модель “Взаимосвязь открытых систем” была разработана с целью упрощения взаимодействия устройств в сетях. Семиуровневая эталонная модель представляет собой рекомендации (разработчикам сетей и протоколов) для построения стандартов совместимых сетевых программных продуктов, и служит базой для производителей при разработке совместимого сетевого оборудования. Рекомендации стандарта должны быть реализованы как в аппаратуре, так и в программных средствах вычислительных сетей. Семиуровневая эталонная модель OSI определяет семь уровней взаимодействия систем в сетях с коммуникацией пакетов, дает им стандартные имена и указывает, какие функции должен выполнять каждый уровень. Каждый уровень функционирует независимо от выше - и нижележащих уровней. Каждый уровень может общаться с непосредственным соседним уровнем, однако он полностью изолирован от прямого обращения к следующим уровням. Семиуровневая эталонная модель OSI описывает только системные средства взаимодействия, реализуемые операционной системой, системными утилитами, системными аппаратными средствами. В соответствии с семиуровневой эталонной моделью сетевая система представляется прикладными процессами и процессами взаимодействия абонентов. Последние разбиваются на семь функциональных уровней: прикладной, представительный (уровень представления данных), сеансовый, транспортный, сетевой, канальный и физический.
1. Прикладной уровень – самый верхний уровень модели OSI. Прикладной уровень управляет общим доступом к сети, потоком данных и обработкой ошибок. Прикладной уровень получает запрос (сообщение) от сетевого приложения, работающего на компьютере ПК1, который требуется передать сетевому приложению, работающему на ПК2.
2. Представительный уровень (уровень представления данных) определяет формат, используемый для обмена данными между ПК1 и ПК2. На ПК1 данные, поступившие от прикладного уровня, на представительном уровне переводятся в промежуточный формат. На ПК2 на этом уровне происходит перевод из промежуточного формата в тот, который используется прикладным уровнем данного компьютера. 3. Сеансовый уровень позволяет двум приложениям на ПК1 и ПК2 устанавливать, использовать и завершать соединение, называемое сеансом. Сеансовый уровень обеспечивает синхронизацию между пользовательскими задачами посредством расстановки в потоке данных контрольных точек. 4. Транспортный уровень осуществляет контроль данных и гарантирует доставку пакетов без ошибок. Кроме того, транспортный уровень выполняет деление длинных сообщений, поступающих от верхних уровней ПК1, на пакеты данных (при передаче данных) и формирование первоначальных сообщений в ПК2 из набора пакетов, полученных через канальный и сетевой уровни. Транспортный уровень и уровни, которые находятся выше, реализуются программными средствами ПК1 и ПК2 (компонентами их сетевых операционных систем). Транспортный уровень связывает нижние уровни (физический, канальный, сетевой) с верхними уровнями, которые реализуются программными средствами. 5. Сетевой уровень служит для образования единой транспортной системы, объединяющей несколько сетей, которые могут иметь различные принципы передачи сообщений. Внутри сети доставка данных обеспечивается соответствующим канальным уровнем, а доставку данных между сетями выполняет сетевой уровень. Сетевой уровень реализуется программными модулями операционной системы, программными и аппаратными средствами маршрутизаторов. 6. Канальный уровень обеспечивает пересылку пакетов между любыми двумя ПК локальной сети. Кроме того, канальный уровень осуществляет управление доступом к передающей среде. Функции канального уровня реализуются сетевыми адаптерами и их драйверами. 7. Физический уровень обеспечивает физический путь для электрических сигналов, несущих информацию. Этот уровень характеризует параметры физической среды передачи данных. Физический уровень определяет характеристики электрических сигналов, передающих дискретную информацию, типы разъемов и назначение каждого контакта. Как правило, функции физического уровня реализуются сетевым адаптером или портом. В вычислительных сетях, как правило, применяются наборы протоколов, а не все функциональные уровни модели взаимодействия открытых систем. Набор протоколов, достаточный для организации взаимодействия оборудования в сети, называется стеком коммуникационных протоколов. При запуске на компьютере любого приложения, для функционирования которого требуется диалог с сетью, это приложение вызывает соответствующий протокол прикладного уровня сетевого программного обеспечения. Прикладной уровень формирует сообщение стандартного формата. Обычно сообщение состоит из заголовка и поля данных. Заголовок содержит служебную информацию, которую необходимо передать через сеть прикладному уровню компьютера-адресата, чтобы сообщить ему, какую работу надо выполнить. Поле данных содержит данные, необходимые для выполнения этой работы. После формирования сообщения прикладной уровень направляет его вниз к представительному уровню. Представительный уровень, на основании информации, полученной из заголовка прикладного уровня, выполняет требуемые действия и добавляет к сообщению собственную служебную информацию – заголовок представительного уровня, в котором содержатся указания для представительного уровня машины-адресата. Полученное сообщение отправляется вниз сеансовому уровню, который добавляет свой заголовок и т.д. до физического уровня, который передает сформированное сообщение по линиям связи. К этому моменту сообщение имеет заголовки всех уровней. Когда сообщение поступает в компьютер - адресат, оно принимается физическим уровнем и последовательно передается вверх с уровня на уровень. Причем каждый уровень анализирует и обрабатывает заголовок своего уровня, выполняя соответствующие данному уровню функции, а затем удаляет этот заголовок и передает сообщение вышележащему уровню.
Представление данных в ЭВМ.
Современные ЭВМ реализованы на электронных элементах (триггерах), имеющих два устойчивых состояния (типа включен/выключен). Эти состояния кодируются – одно обозначается “0”(ноль), другое – “1” (единица). Таким образом, язык ЭВМ содержит только два символа. Это в свою очередь, вынуждает для представления данных в ЭВМ использовать специальные коды.
Под кодированием понимается переход от исходного представления информации, удобного для восприятия информации человеком, к представлению, удобному для хранения, передачи и обработки. Информация в памяти ЭВМ записывается в виде цифрового двоичного кода.
Основной и неделимой единицей данных является бит. Бит может принимать два значения — 0 и 1 — ложь или истина, выключено или включено.
Двоичное число содержит столько битов, сколько двоичных цифр в его записи, поэтому диапазон допустимых значений выводится из количества разрядов (цифр), отведенных для числа.
Биты (разряды) двоичного числа нумеруются справа налево, от наименее значимого до наиболее значимого. Нумерация начинается с 0. Самый правый бит числа — это бит с номером 0 (первый бит).Этот бит называется LSB-битом (Least Significant Bit — наименее значимый бит). Подобно этому самый левый бит называется MSB-битом (Most Significant Bit — наиболее значимый бит). Компьютер не работает с отдельными битами, обычно он оперирует группами битов, например, группа из восьми битов образует базовый тип данных, который называется байтом. Восемь битов в байте — это не закон природы, а количество, произвольно выбранное разработчиками IBM, создававшими первые компьютеры. Большие группы битов называются словом (word) или двойным словом (dword — double word).Относительно PC-совместимых компьютеров мы можем сказать следующее:
1 байт = 8 бит
1 слово (word) = 2 байта = 16 бит
1 двойное слово (dword) = 4 байта = 32 бит
Для чисел имеется три числовых формата:
двоичный с фиксированной точкой;
двоичный с плавающей запятой;
двоично-кодированный десятичный ( BCD ).
В двоичном формате с фиксированной точкой числа могут быть представлены без знака (коды) или со знаком. Для представления чисел со знаком в современных ЭВМ в основном применяется дополнительный код. Это приводит к тому, что отрицательных чисел при заданной длине разрядной сетки можно представить на одно больше, чем положительных. Хотя операции в ЭВМ осуществляются над двоичными числами, для записи их в языках программирования, в документации и отображения на экране дисплея часто используют более удобное восьмеричное, шестнадцатеричное и десятичное представление.
В двоично-кодированном десятичном формате каждая десятичная цифра представляется в виде 4 битного двоичного эквивалента. Существуют две основные разновидности этого формата: упакованный и неупакованный. В упакованном BCD -формате цепочка десятичных цифр хранится в виде последовательности 4-битных групп. Например, число 3904 представляется в виде двоичного числа 0011 1001 0000 0100. В неупакованном BCD -формате каждая десятичная цифра находится в младшей тетраде 8-битной группы (байте), а содержимое старшей тетрады определяется используемой в данной ЭВМ системой кодирования, и в данном случае несущественно. То же число 3904 в неупакованном формате будет занимать 4 байта и иметь вид: xxxx0011 xxxx1001 xxxx0000 xxxx0100 .
Числа с плавающей запятой обрабатываются на специальном сопроцессоре ( FPU - floating point unit ), который, начиная с МП I486, входит в состав БИС (большая интегральная схема) микропроцессора. Данные в нем хранятся в 80-разрядных регистрах. Управляя настройками сопроцессора, можно изменять диапазон и точность представления данных этого типа.
В языках программирования высокого уровня есть специальные типы данных, позволяющие хранить символы и строки. В языке ассемблера таких типов данных нет. Вместо них для представления одного символа используется байт, а для представления строки — группа последовательных байтов. Тут все просто. Каждое значение байта соответствует одному из символов ASCII-таблицы (American Standard Code for Information Interchange). Первые 128 символов — управляющие символы, латинские буквы, цифры — одинаковы для всех компьютеров и операционных систем. Шестнадцатеричные цифры в заголовках строк и столбцов таблицы представляют числовые значения отдельных символов. Например, координаты заглавной латинской буквы А — 40 и 01. Сложив эти значения, получим 0x41 (то есть 65 в десятичной системе) — код символа 'А' в ASCII-коде. Печатаемые символы в ASCII-таблице начинаются с кода 0x20 (или 32d). Символы с кодом ниже 32 представляют так называемые управляющие символы. Наиболее известные из них — это ОхА или LF — перевод строки, и OxD — CR — возврат каретки. Важность управляющих символов CR и LF обусловлена тем, что они обозначают конец строки — тот символ, который в языке программирования С обозначается как \п. К сожалению, в различных операционных системах он представляется по-разному: например, в Windows (и DOS) он представляется двумя символами (CR, LF — OxD, ОхА), а в операционной системе UNIX для обозначения конца строки используется всего один символ (LF — ОхА). Символы с кодами от 128 до 256 и выше стали «жертвами» различных стандартов и кодировок. Обычно они содержат национальные символы, например, у нас это будут символы русского алфавита и, возможно, некоторые символы псевдографики, в Чехии — символы чешского алфавита и т.д. Следует отметить, что для русского языка используются кодировки СР 866 (в DOS) и СР 1251 (Windows).
Представление команд в ЭВМ.
Команда (инструкция) – элемент программы, приводящий к выполнению определенных действий. Команда представляет собой код, содержащий информацию, необходимую для управления машинной операцией. Под операцией понимают преобразование информации, выполняемое машиной под воздействием одной команды. Содержанием машинной операции может быть запоминание, передача, арифметическое и логическое преобразование некоторых машинных слов (операндов).
Формат команды – количество и интерпретация разрядов, представляющих машинную команду. Команда состоит из операционной и адресной частей. Операционная часть содержит код операции (КОП), т.е. некоторое число, которое задает вид операции (сложение, умножение, передача и т.д.). Адресная часть команды содержит информацию об адресах операндов и результатах операции, а в некоторых случаях информацию об адресе следующей команды.
( Если ЭВМ выполняет М различных операции, то число разрядов в КОП должно быть не меньше log2M. )
По характеру выполняемых операций различают следующие основные группы команд:
команды арифметических операций для чисел с фиксированной и плавающей запятой;
команды десятичной арифметики;
команды логических (поразрядных) операций (И, ИЛИ и др.);
команды пересылки;
команды операций ввода-вывода;
команды управления порядком исполнения команд (команды передачи управления) и некоторые другие.
Выполнение любой машинной операции складывается из следующих действий. В командный регистр устройства управления засылается содержимое ячейки, номер которой содержится в данный момент в счетчике команд. Устройство управления рассматривает слово в командном регистре как команду и дешифрирует ее, определяет тип операции, т.е. то, что машина должна сделать. Кроме того, выясняются адреса операндов, участвующих в операции. В память поступает запрос на выдачу этих операндов, после чего они поступают в арифметико-логическое устройство. Затем это устройство осуществляет действие над ними по заданной операции и вырабатывает результат, который либо поступает в запоминающее устройство, либо остается в арифметико-логическом устройстве. Наконец, автоматически меняется содержимое счетчика команд, т.е. тем самым определяется, какую команду машина должна выполнить следующей. За тем, какую команду надо выполнять следующей, следит устройство управления. Оно, как правило, прибавляет к счетчику команд единицу, что эквивалентно получению адреса следующего машинного слова, которое будет выбрано в качестве очередной команды. Но иногда это общее правило нарушается. Адрес слова, содержащего новую команду, получается не путем прибавления единицы, а засылкой в счетчик команд другого адреса. Этот адрес обычно выбирается из предыдущей исполняемой команды, которая называется командой передачи управления. Машина по виду команды определяет информацию о том, какую надо выбрать команду для выполнения в качестве следующей. Для этого машинное слово, содержащее команду, разбивается на группы разрядов - поля, которые служат для задания информации определенного назначения. Одна группа разрядов отводится под номер операции или иначе под код операции. Другая группа разрядов - адресное поле - отводится под адреса операндов, участвующих в операции, под адрес результата и, возможно, под адрес следующей по порядку команды. Есть команды, где в адресном поле указывается непосредственно значение одного из операндов (а не адрес операнда, как это бывает обычно). Чтобы команды выполнялись, необходимо, чтобы они были представлены в машинно-кодированном виде.
Способы адресации операндов.
Исполнительным адресом операнда (Амп) называется двоичный код номера ячейки памяти, служащей источником или приемником операнда. !0ют код полается на адресные входы напоминающею устройства (-:)У), и по нему происходит фактическое обращение к указанном ячейке. Сели операнд хранится не и основной памяти, а в регистре процессора, его исполнительным адресом будет номер регистра. Адресный код команды (АК) — это двоичный код в адресном поле команды, из которого необходимо сформировать исполнительный адрес операнда, В современных ЭВМ исполнительный адрес и адресный код, как правило, не совпадают, и для доступа К данным требуется соответствующее преобразование. Способ адресации — это способ формирования исполнительного адреса операнда по адресному коду команды.
Различные способы адресации базируются на разных механизмах определения физического адреса операнда, то есть адреса фактического обращения к памяти при выполнении команды. Определение набора способов адресации, закладываемых в систему команд, является одним из важнейших вопросов разработки ЭВМ, существенно влияющим на ее архитектуру, вычислительные возможности, объем оборудования, быстродействие и другие характеристики.
К основным способам адресации относятся следующие: прямая, непосредственная, косвенная, относительная.