

Глава 4 случайные величины
В этой главе Вы сведете знакомство с новым и очень важным понятием случайной величины.
Давайте вспомним вкратце содержание предыдущих глав. В первой главе Вы познакомились с простейшим способом вычисления вероятности события — непосредственным подсчетом доли благоприятных случаев. Только-только Вы освоились с этим способом, Вас постигло разочарование: оказалось, что он применим далеко не всегда, а только в тех (сравнительно редких!) задачах, где опыт сводится к схеме случаев, т. е. обладает симметрией возможных исходов. Зато в следующей главе Вы научились приближенно находить вероятность события по его частоте; на опыт никаких ограничений уже не накладывалось. Только-только Вы немножко освоились и с этим способом, как Вас опять постигло разочарование: оказалось, что не он является в теории вероятностей основным! В третьей главе («Основные правила теории вероятностей») Вы, наконец-то, дошли до методов, которые, как следует из заглавия, являются в этой науке основными! «Наконец-то, — думаете Вы, — удалось мне добраться до самых основ, до самой сути! Больше разочарований уже не будет!» Увы, Вас ждет еще одно (на этот раз последнее!) разочарование. Дело в том, что аппарат событий, с которым мы до сих пор имели дело, в современной теории вероятностей... не является основным!
— А какой же аппарат является основным? — кипя от негодования, спросите Вы. — И на кой черт Вы заставляли .меня знакомиться с не основным аппаратом?
— Беда в том, — смиренно ответим мы, — что без того, что Вы уже изучили, невозможно даже подступиться к современному аппарату.
— А что это за аппарат?
— Аппарат случайных величин.
Эта глава и будет посвящена основному понятию современной теории вероятностей — понятию «случайной величины», разновидностям случайных величин, способам их описания и манипулирования с ними. О случайных величинах мы будем говорить не так подробно, как о событиях, а более в «описательном» духе — здесь математический аппарат, если бы мы им вздумали воспользоваться, оказался бы более сложным и мог бы оттолкнуть начинающего. А мы как раз хотим облегчить начинающему его «первые шаги». Итак, познакомимся с понятием случайной величины.
Случайной величиной называется величина, которая в результате опыта может принять то или другое значение, неизвестно заранее — какое именно.
Как всегда в теории вероятностей, определение «смутноватое», содержит упоминание о какой-то неопределенности, неизвестности... Чтобы овладеть понятием случайной величины, надо к нему попросту привыкнуть. Для этого рассмотрим примеры случайных величин.
1. Опыт состоит в бросании двух монет. Число гербов, которое при этом появится, — случайная величина. Ее возможные значения: 0,1,2,3. Какое из них она примет — заранее неизвестно.
2. Ученик идет сдавать экзамен. Отметка, которую он получит, — случайная величина. Ее возможные значения: 2,3,4,5.
3. В группе студентов 28 человек. В какой-то день регистрируется число неявившихся на занятия. Это — случайная величина. Ее возможные значения: 0, 1, ..., 28.
— Ну, нет! — скажете Вы. — Все 28 человек никак заболеть (прогулять) не могут.
— Да, это практически невозможное событие. А кто Вам сказал, что все значения случайной величины должны быть одинаково вероятны?
Все приведенные в примерах случайные величины принадлежат к типу так называемых дискретных. Дискретной называется такая случайная величина, возможные значения которой отделены друг от друга какими-то интервалами. На оси абсцисс эти значения изобразятся отдельными точками.
Бывают случайные величины другого типа, которые называются непрерывными. Значения таких случайных величин сплошь заполняют какой-то участок числовой оси. Границы этого участка иногда бывают четкими, а иногда расплывчатыми, неопределенными. Рассмотрим несколько примеров непрерывных случайных величин.
1. Промежуток времени между двумя отказами («сбоями») вычислительной машины. Значения этой случайной величины сплошь заполняют какой-то участок числовой оси. Нижняя граница этого участка вполне четкая - (0), а верхняя — расплывчатая, неопределенная, может быть найдена только в результате опыта.
2. Вес грузового поезда, подаваемого на станцию для разгрузки.
3. Высота подъема воды в половодье.
4. Ошибка, возникающая при взвешивании тела на аналитических весах (в отличие от предыдущих эта случайная величина может принимать как положительные, так и отрицательные значения).
5. Удельный вес молока, берущегося на пробу в совхозе.
6. Время, проводимое учеником 8-го класса у телевизора в течение дня.
Подчеркнем следующее: для того чтобы говорить о «случайной величине» в том смысле, который приписывается этому понятию в теории вероятностей, необходимо уточнить, в чем состоит опыт, в результате которого случайная величина принимает то или другое значение? Например, в примере 1 непрерывной случайной величины надо указать, о какой машине идет речь, каковы ее возраст и условия эксплуатации. В примере 4 надо уточнить, на каких весах производится взвешивание? Какими разновесками? Необходимость уточнения условий опыта всегда надо иметь в виду, но, в целях краткости изложения, мы не всегда будем эти подробности оговаривать.
Обратим Ваше внимание на следующее обстоятельство. На самом деле все случайные величины, которые мы называли «непрерывными», могут быть измерены только в каких-то единицах (минутах, сантиметрах, тоннах и т. д.) и в этом смысле, строго говоря, являются «дискретными». Например, случайную величину «рост человека» нет смысла измерять точнее, чем до 1 см; получается, в сущности, дискретная случайная величина со значениями, разделенными интервалом в 1 см. Но число таких значений очень велико, и расположены они на оси абсцисс очень «тесно» — в таком случае удобнее рассматривать случайную величину как непрерывную.
Условимся в дальнейшем случайные величины обозначать большими буквами латинского алфавита, а их возможные значения — соответствующими малыми (например, случайная величина X, ее возможные значения x1, х2, ...), а самый термин «случайная величина» — иногда сокращать буквами СВ.
Итак, пусть перед нами СВ X с какими-то значениями. Естественно, что не все эти значения одинаково вероятны: среди них есть более и менее вероятные. Законом распределения случайной величины называется всякая функция, которая описывает распределение вероятностей между ее значениями. Мы познакомим Вас не со всеми формами законов распределения, а только с некоторыми, самыми простыми.
Закон распределения дискретной случайной величины может быть записан в виде так называемого ряда распределения. Так называется таблица, состоящая из двух строк: в верхней перечислены все возможные значения случайной величины: х1, х2, ..., хп, а в нижней — соответствующие им вероятности : р1, р2, ..., рп:
хi |
х1 |
х2 |
…………… |
хn |
pi |
p1 |
p2 |
…………… |
pn |
Каждая вероятность pt есть не что иное, как вероятность события, состоящего в том, что СВ X примет значение хi,:
Pi = P(X = хi) (i = 1, ..., п).
Очевидно, сумма всех вероятностей pi равна единице:
p1+ p2+…..+ pn=1
Эта единица как-то распределена между значениями СВ; отсюда и термин «распределение».
Пример 1. Производятся три независимых выстрела по мишени; вероятность попадания при каждом выстреле равна р =0,4. Дискретная СВ X — число попаданий в мишень. Построить ее ряд распределения.
Решение. Напишем в верхней строке ряда возможные значения С В X: 0, 1, 2, 3, а в нижней — соответствующие им вероятности, которые обозначим р0, р1, р2, p3. Вычислять такие вероятности мы уже умеем (см. главу 3). Имеем:
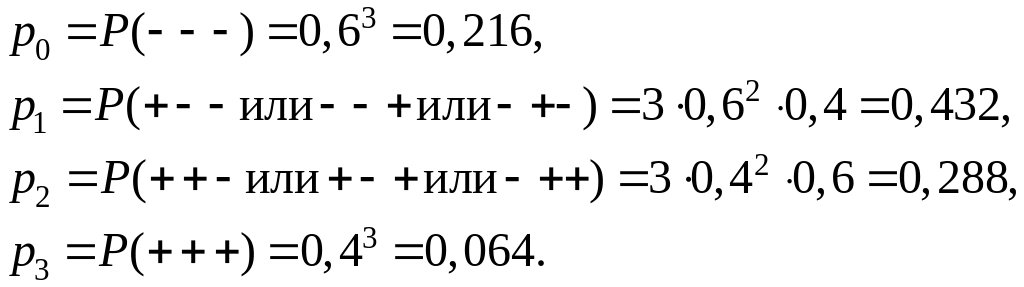
Проверим, равна ли сумма вероятностей единице: равна, значит, все в порядке. Ряд распределения СВ X имеет вид:
хi |
0 |
1 |
2 |
3 |
pi |
0,216 |
0,432 |
0,288 |
0,064 |
Пример 2. Спортсмен производит ряд попыток забросить мяч в кольцо. При каждой попытке (независимо от других) попадание в кольцо происходит с вероятностью р. Как только мяч попал в кольцо, попытки прекращаются. Дискретная СВ X — число попыток, которое придется произвести. Построить ряд распределения СВ X.
Решение. Возможные значения СВ X : х1= 1, х2 = 2, ..., xk = k, ... и т. д., теоретически — до бесконечности. Найдем вероятности всех этих значений; рi — это вероятность того, что мы попадем в кольцо при первой же попытке; она, очевидно, равна р: рi = р. Найдем р2 - вероятность того, что будут произведены две попытки. Для этого нужно совмещение двух событий:
1) при первой попытке мы не попадем в кольцо и
2) при второй — попадем.
Вероятность этого равна (1 — р)р. Аналогично находим р3 = (1 — р)2 р (первые две попытки не удались, а третья удалась), и вообще pi = (1 — р)i-1 р. Ряд распределения СВ X имеет вид:
хi |
1 |
2 |
3 |
….. |
i |
…. |
pi |
p |
(1 — р)р |
(1 — р)2 р |
….. |
(1 — р)i-1 р |
…. |
Заметим, что вероятности pi образуют геометрическую прогрессию со знаменателем
(1 — р), поэтому такое распределение вероятностей называется «геометрическим».
Теперь посмотрим, чем может характеризоваться распределение вероятностей для непрерывной СВ. Для такой случайной величины, значения которой сплошь заполняют какой-то промежуток оси абсцисс, ряда распределения построить нельзя.
— Почему? — спросите Вы.
Отвечаем. Начнем с того, что нельзя записать даже верхнюю его строку, т. е. перечислить, одно за другим, все возможные значения СВ. Действительно, какую бы пару значений мы ни поставили рядом, между ними непременно найдутся еще значения *. Кроме того, на нашем пути встретится еще одна трудность: пытаясь приписать какую-то вероятность каждому отдельному значению непрерывной СВ, мы убедимся в том, что эта вероятность... равна нулю! Да, именно нулю — мы не обмолвились и постараемся Вас в этом убедить.
Вообразите себе, что перед нами целый пляж, усыпанный галькой. Нас интересует случайная величина X — вес отдельного камня.
Ну, что же — Давайте их взвешивать. Сначала начнем взвешивать с разумной точностью — до 1 г. Будем считать за 30 г вес всякого камня, который с точностью до 1 г равен 30 г. Получим какую-то частоту веса 30 г — какова она, мы сейчас не знаем, да это и неважно.
Теперь давайте усилим требования к точности — будем взвешивать камни с точностью до 0,1 г, т. е. считать камень имеющим вес 30 г, если его вес с точностью до 0,1 г равен 30 г. При этом, очевидно, некоторые из камней, которые мы при «грубом» взвешивании считали за тридцатиграммовые, отпадут. Частота события X = 30 (г), станет меньше. Во сколько раз? Примерно в 10.
А теперь еще повысим требования к точности — будем взвешивать камни с точностью до 1... мг! Частота появления веса 30 г станет еще в 100 раз меньше...
* Для лиц, знакомых с теорией множеств, прибавим: число этих значений несчетно.
А частота — родная сестра вероятности — приближается к ней при большом числе опытов (камней на пляже много, так что в этом отношении мы можем быть спокойны— материал для взвешивания всегда найдется!). Какую же вероятность мы должны приписать событию, - состоящему в том, что вес камня будет ровно 30 г, ни на чуточку ни больше, ни меньше? Очевидно, нулевую - никуда не денешься !
Вы недоумеваете. Может быть, Вы даже возмущены! Вы ведь помните, что нулевой вероятностью обладают невозможные события. А событие, состоящее в том, что непрерывная СВ X примет какое-то значение х, возможно! Как же его вероятность может быть равна нулю?
Давайте вспомним хорошенько. Действительно, мы утверждали, что вероятность невозможного события равна нулю, и говорили совершенную правду. Но разве мы утверждали, что любое событие с нулевой вероятностью невозможно? Нисколько! Теперь нам пришлось познакомиться с возможными событиями, вероятности которых равны нулю.
Не торопитесь. Давайте немного поразмышляем. Забудьте на минуту теорию вероятностей и просто вообразите себе на плоскости некоторую фигуру площади S. А теперь возьмем любую точку внутри фигуры. Чему равна площадь этой точки? Очевидно, нулю. Фигура, безусловно, состоит из точек; каждая из них обладает нулевой площадью, а вся фигура — ненулевой! Этот «парадокс» Вас уже не удивляет — просто Вы к нему уже привыкли. Вот так же надо привыкнуть и к тому, что вероятность попадания в каждую отдельную точку для непрерывной случайной величины в точности равна нулю *.
— Как же тогда можно говорить о распределении вероятностей для непрерывной случайной величины? — спросите Вы. — Ведь каждое из ее значений имеет одну и ту же вероятность: нуль!
Вы совершенно правы. О распределении вероятностей между отдельными значениями непрерывной СВ говорить не имеет смысла. А все-таки распределение и таких случайных величин существует! Например, никому из Вас не придет в голову сомневаться, что значение роста человека 170 см вероятнее, чем 210 см, хотя и то, и другое значения возможны.
Тут нам придется ввести новое важное понятие: плотность вероятности.
Понятие «плотности» достаточно известно нам из физики. Например, плотностью вещества называется его вес, приходящийся на единицу объема. А если вещество неоднородно? Приходится рассматривать его местную плотность. Так же и в теории вероятностей мы будем рассматривать местную плотность (т. е. вероятность, приходящуюся на единицу длины, в данной точке х).
* Следует оговориться, что бывают случайные величины особого, так называемого «смешанного», типа: кроме сплошного участка возможных значений с нулевыми вероятностями, они имеют еще отдельные, особые значения с ненулевыми. Таких «хитрых» случайных величин мы с Вами рассматривать не будем, но знайте, что они существуют.
Плотностью вероятности непрерывной случайной величины X называется предел отношения вероятности попадания СВ X на малый участок, примыкающий к точке х, к длине этого участка, когда последняя стремится к нулю.
Понятие «плотности вероятности» легко выводится из родственного ему понятия «плотность частоты». Рассмотрим непрерывную СВ X (например, рост человека или вес камня на пляже). Давайте, прежде всего, произведем над этой случайной величиной ряд опытов, в каждом из которых она принимает какое-то значение (например, измерим рост группы людей или же взвесим много камней). Нас интересует распределение вероятностей для нашей случайной величины. Ну, что же, разобьем весь диапазон значений СВ X на какие-то участки (или, как говорят, «разряды»), например: 150—155 см, 155—160; 160—165,...., 190—195, 195—200. Подсчитаем, сколько значений СВ попало в каждый разряд*, разделим
.на общее число произведенных опытов — получим «частоту разряда» (очевидно, сумма частот всех разрядов должна быть равна единице). Теперь подсчитаем плотность частоты для каждого разряда, для чего разделим частоту на длину разряда (вообще говоря, длины разрядов не обязательно должны быть одинаковыми).
Если в нашем распоряжении достаточно большой массив статистических данных (порядка, скажем, нескольких сот, лучше — более), то, построив для нашей СВ плотность частоты, мы можем получить достаточное представление о распределении этой СВ — о ее плотности вероятности. При обработке такого статистического материала удобно, прежде всего, построить специальный
график, называемый гистограммой (рис. 2). Гистограмма строится следующим образом: на каждом разряде, как на основании, строится прямоугольник,
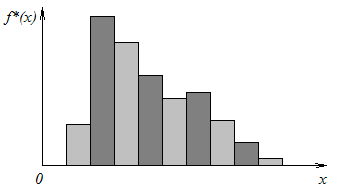
Рис. 2
площадь которого равна частоте разряда (а, значит, высота — плотности частоты). Очевидно, площадь, ограниченная гистограммой, равна единице. По мере увеличения числа опытов N можно брать разряды все меньшими и меньшими, при
этом «ступенчатый» характер гистограммы будет сглаживаться, и она будет приближаться к некоторой плавной кривой, которая называется кривой
* Если значение X попало в точности на границу двух разрядов, припишем по половине к каждому разряду
распределения (рис. 3).По оси ординат будет откладываться уже не плотность частоты, а плотность вероятности. Очевидно, полная площадь, ограниченная кривой распределения, как и площадь ее «сестры» — гистограммы, — будет равна единице. А вероятность попадания
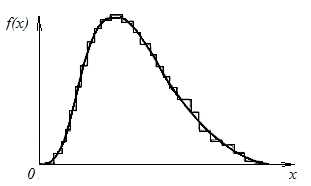
Рис. 3
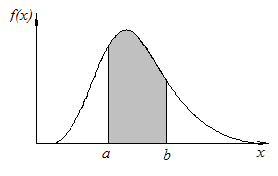
Рис. 4
СВ X на участок от а до b будет равна площади, опирающейся на этот участок (рис. 4). Если обозначить плотность вероятности f(х), то вероятность попадания СВ X на участок от а до b выразится определенным интегралом:
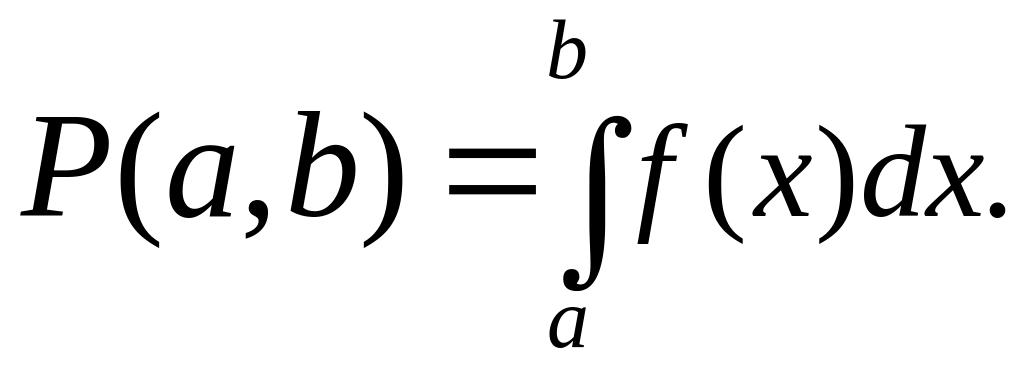
Таким образом, если не пожалеть времени и средств, интересующая нас плотность вероятности f(x) может быть определена как угодно точно по опытным данным. Но стоит ли овчинка выделки? Так ли уж нам нужно совершенно точно знать плотность f(x)? Очень часто нам этого не нужно: достаточно иметь лишь приближенное представление о законе распределения СВ X (ведь все вероятностные расчеты имеют по природе своей приближенный, «прикидочный» характер). А для того чтобы знать приближенно, «примерно», каков закон распределения СВ X, вовсе не нужно какого-то грандиозного числа опытов, можно взять его довольно скромным, например 300—400, а иной раз и меньше. Построив гистограмму по имеющимся опытным данным, можно затем «выровнять» ее с помощью той или другой плавной кривой (разумеется, такой, которая ограничивает площадь, равную единице). Теория вероятностей располагает целым набором кривых, удовлетворяющих этому условию. Некоторые из них обладают известными преимуществами перед другими, например, для них интеграл (1) легко вычисляется или для него оставлены таблицы. Или же условия возникновения нашей случайной величины подсказывают определенный тип распределения, вытекающий из теоретических соображений. Вдаваться здесь в такие подробности мы не будем — это дело специальное. Однако подчеркнем, что и при нахождении законов распределения случайных величин основное значение имеют не прямые, а косвенные методы, позволяющие находить распределения одних случайных величин не непосредственно из опыта, а через имеющиеся у нас данные о других случайных величинах, с ними связанных.
В осуществлении этих косвенных методов большую роль играет аппарат так называемых числовых характеристик случайных величин.
«Числовые характеристики» — это некоторые числа, характеризующие те или другие свойства, отличительные признаки случайных величин — например, среднее значение, вокруг которого происходит случайный разброс, степень этого разброса (как бы «степень случайности» случайной величины) и ряд других признаков. Оказывается, многие задачи теории вероятностей можно решать, не прибегая (или почти не прибегая) к законам распределения, а пользуясь только числовыми характеристиками. Здесь мы познакомим Вас только с двумя (зато важнейшими!) числовыми характеристиками случайной величины: математическим ожиданием и дисперсией.
Математическим ожиданием М [X] дискретной СВ X называется сумма произведений всех ее возможных значений на соответствующие им вероятности:
М [X] = х1р1 + х2р2 + ... +хпрп, (1)
или короче, пользуясь знаком суммы:
![]() (2)
(2)
где х1, х2, …, хп — возможные значения СВ X, рi — вероятность того, что СВ X примет значение xi.
Как видно из формулы (2), математическое ожидание случайной величины X есть не что иное, как «среднее взвешенное» всех ее возможных значений, причем каждое из них входит в сумму с «весом», равным его вероятности. Если число возможных значений СВ
(как в примере 2) бесконечно, то сумма (2) состоит из бесконечного числа слагаемых.
Математическое ожидание или среднее значение СВ является как бы ее «представителем», которым можно ее заменить при грубоориентировочных расчетах. В сущности, мы так всегда и поступаем, когда в каких-нибудь задачах не учитываем случайности.
Пример 3. Найти математическое ожидание СВ X (число попаданий при трех выстрелах), рассмотренной в примере 1.
Решение. По формуле (2) имеем:
![]()
Для непрерывной СВ X тоже вводится понятие математического ожидания, но, естественно, в формуле (2) сумма заменяется интегралом:
![]() (3)
(3)
где f(х) — плотность вероятности непрерывной СВ X.
Теперь поговорим немного о математическом ожидании, о его физическом смысле и «генеалогии». Аналогично тому, как у вероятности есть «родная сестра» — частота, у математического ожидания тоже есть родной брат (сестра? родственник?) — среднее арифметическое результатов наблюдений. Так же как частота приближается к вероятности при большом числе опытов, так же с увеличением числа опытов среднее арифметическое наблюденных значений СВ приближается к ее математическому ожиданию.
Докажем это для дискретных СВ (думаем, что для непрерывных Вы охотно примете это на веру!). Итак, пусть имеется дискретная СВ X с рядом распределения:
xi |
x1 |
x2 |
………….. |
xn |
pi |
p1 |
p2 |
………… |
pn |
Пусть
произведено N опытов, в результате
которых значение х1
появилось
М1
раз,
значение х2
—
М
2
раз
и т. д. Найдем среднее арифметическое
наблюденных значений СВ
X;
обозначим его![]() :
:
![]()
Но
![]() есть не что иное, как частота события
(X
= хi);
обозначим
ее
есть не что иное, как частота события
(X
= хi);
обозначим
ее
![]()
![]()
откуда
![]() .
.
Мы
знаем, что при увеличении числа опытов
N
частота
события
![]() с
практической достоверностью приближается
к его вероятности pi;
значит,
и среднее
арифметическое наблюденных значений
случайной величины при увеличении числа
опытов с практической достоверностью
будет сколь угодно близко к ее
математическому ожиданию.
с
практической достоверностью приближается
к его вероятности pi;
значит,
и среднее
арифметическое наблюденных значений
случайной величины при увеличении числа
опытов с практической достоверностью
будет сколь угодно близко к ее
математическому ожиданию.
Подчеркнутое положение представляет собой одну из форм закона больших чисел (так называемую теорему Чебышева), играющую очень большую роль в практических приложениях теории вероятностей. Действительно, так же как неизвестную вероятность события можно приближенно определить по его частоте в длинной серии опытов, так же можно приближенно найти математическое ожидание СВ X как среднее арифметическое ее наблюденных значений:
![]() (4)
(4)
Отметим специально, что для того чтобы вычислить по опытным данным математическое ожидание интересующей нас случайной величины, вовсе нет надобности знать ее закон распределения: просто надо вычислить среднее из всех результатов наблюдений.
Сделаем еще одно замечание: для того чтобы с удовлетворительной точностью найти математическое ожидание случайной величины, совсем не нужно столько опытов (порядка нескольких сот), как для построения гистограммы, а достаточно значительно меньшего числа (порядка десятков).
Теперь введем вторую важнейшую числовую характеристику случайной величины: ее дисперсию. Слово «дисперсия» в переводе значит «рассеивание» — дисперсия СВ характеризует как раз разброс (рассеивание) ее значений вокруг среднего. Чем больше дисперсия, тем «случайнее» случайная величина.
Дисперсия дискретной СВ X вычисляется так: из каждого возможного значения вычитается среднее (математическое ожидание); полученное отклонение значения от среднего возводится в квадрат, множится на вероятность соответствующего значения, и все такие произведения суммируются; получается дисперсия, которую мы обозначим D[X ]:
![]()
или, короче,
![]() (5)
(5)
Может возникнуть вопрос: а для чего нам понадобилось возводить отклонение от среднего в квадрат? Для того, чтобы избавиться от знака (плюс или минус). Разумеется, можно было бы от него избавиться, просто отбросив знак (взявши модуль отклонения), но получилась бы характеристика, гораздо менее удобная для вычисления и манипулирования, чем дисперсия.
Пример 4. Найти дисперсию числа попаданий X в условиях примера 1.
Решение. По формуле (5) имеем:
![]()
Заметим, что формула (5) — не самая удобная для вычисления дисперсии. Ее можно (и обычно удобно) вычислять по формуле:
![]() (6)
(6)
т. е. дисперсия СВ равна математическому ожиданию ее квадрата минус квадрат математического ожидания.
Эту формулу легко вывести из (5) с помощью тождественных преобразований, но мы не будем на этом задерживаться. Лучше проверим ее справедливость на предыдущем примере:
![]() .
.
Для непрерывных случайных величин дисперсия вычисляется аналогично формуле (5), но, естественно, вместо суммы стоит интеграл:
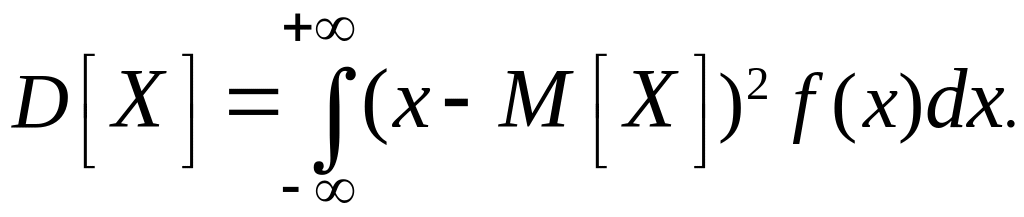 (7)
(7)
Обычно удобнее бывает находить ее по формуле (6), которая для непрерывного случая даст:
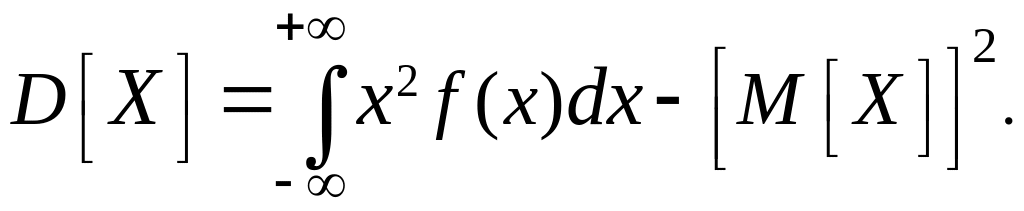 (8)
(8)
Так же как для приближенного нахождения математического ожидания нет надобности в обязательном порядке знать закон распределения, так же можно приближенно найти и дисперсию непосредственно по результатам опытов, осредняя квадраты отклонений наблюденных значений СВ от их среднего арифметического:
![]() (9)
(9)
где k — номер опыта; xk — значение СВ, наблюденное в k-м опыте; N — число опытов.
Опять-таки удобнее вычислять дисперсию через «средний квадрат минус квадрат среднего» по формуле:
![]() (10)
(10)
Формулы
(9) и (10) пригодны для грубоприближенной
оценки дисперсии и при не очень большом
числе опытов (лучше что-нибудь, чем
ничего!) но, естественно, дают ее с не
очень большой точностью. В математической
статистике принято вводить в этом случае
«поправку на малое число опытов», множа
полученный результат на поправочный
множитель
![]() .
Разумеется, множить можно, но не нужно
придавать
этой поправке слишком большого значения,
помня о том, что при малом числе опытов
все равно ничего хорошего из их
обработки получить нельзя (как ни
обрабатывай!), а при большом N
поправоч-ный
множитель близок к единице.
.
Разумеется, множить можно, но не нужно
придавать
этой поправке слишком большого значения,
помня о том, что при малом числе опытов
все равно ничего хорошего из их
обработки получить нельзя (как ни
обрабатывай!), а при большом N
поправоч-ный
множитель близок к единице.
Дисперсия случайной величины как характеристика рассеивания имеет одну неприятную особенность: ее размерность (как видно из формулы (5)) равна квадрату размерности СВ X. Например, если СВ X выражается, скажем, в минутах, то ее дисперсия — в «квадратных минутах», что, согласитесь, не очень-то наглядно. Чтобы этого избежать, из дисперсии извлекают квадратный корень; получается новая характеристика рассеивания — так называемое «среднее квадратическое отклонение» (или, иначе, «стандарт»):
![]() (11)
(11)
Среднее
квадратическое отклонение — очень
наглядная и удобная характеристика
рассеивания. Она сразу же дает понятие
о размахе колебаний СВ около среднего
значения. Для большинства встречающихся
на практике случайных величин с
практической достоверностью можно
утверждать, что они не отклонятся от
своего математического ожидания больше
чем на
![]() .
Уровень
доверия зависит от закона распределения
СВ,
но
во всех не искусственно придуманных
случаях он довольно высок. Приведенное
выше правило носит название «правила
трех сигм».
.
Уровень
доверия зависит от закона распределения
СВ,
но
во всех не искусственно придуманных
случаях он довольно высок. Приведенное
выше правило носит название «правила
трех сигм».
Таким образом, если нам тем или другим способом удалось найти две числовые характеристики СВ X — ее математическое ожидание и среднее квадратическое отклонение, мы сразу же получаем ориентировочное представление о том, в каких пределах могут лежать ее возможные значения.
Тут Вы можете спросить: если мы находили эти характеристики из опыта, кто нам мог бы помешать из того же опыта найти и пределы возможных значений?
Да, Вы совершенно правы, если эти характеристики находятся непосредственно из опыта. Но не эти (прямые) методы нахождения числовых характеристик являются в теории вероятностей основными. Снова (уже в который раз!) мы скажем, что основными являются не прямые, а косвенные методы, позволяющие находить числовые характеристики интересующих нас случайных величин по числовым характеристикам других случайных величин, с ними связанных. При этом применяются основные правила действий с числовыми характеристиками; некоторые из них (разумеется, без доказательства) мы приведем здесь.
Правило сложения математических ожиданий: математическое ожидание суммы случайных величин равно сумме математических ожиданий слагаемых.
Правило сложения дисперсий: дисперсия суммы независимых случайных величин равна сумме дисперсий слагаемых.
Правило вынесения неслучайного множителя из-под знака математического ожидания: неслучайную величину с можно выносить из-под знака математического ожидания, т. е. М [сХ] = сМ [X].
Правило вынесения неслучайного множителя из-под знака дисперсии: неслучайную величину с можно выносить из-под знака дисперсии, возводя ее в квадрат, т. е.
D [сХ] = с2D [X].
Все эти правила представляются довольно естественными, кроме, может быть, последнего. Чтобы Вас убедить в его справедливости, возьмем такой пример. Пусть, скажем, мы удвоили случайную величину X. Ее математическое ожидание, естественно, тоже удвоилось; отклонение отдельного значения от среднего тоже удвоилось, а квадрат этого отклонения учетверился!
Уже такого небольшого набора правил достаточно для того, чтобы решать некоторые интересные задачи, в чем Вы сейчас убедитесь.
Задача 1. Производится N независимых .опытов, в каждом из которых событие А появляется с вероятностью р. Рассматривается СВ X — число опытов, в которых появится событие А (короче, число появлений события А). Найти математическое ожидание и дисперсию случайной величины X.
Решение. Представим X в виде суммы N случайных величин:
![]() (12)
(12)
где СВ Xk равна единице, если в k-м опыте событие А произошло, и нулю — если не произошло. Теперь применим к этому выражению правило сложения математических ожиданий:
![]() (13)
(13)
Так как опыты независимы, то случайные величины Xlt Х2, ..., XN также независимы. По правилу сложения дисперсий:
![]() (14)
(14)
Теперь найдем математическое ожидание и дисперсию каждой из случайных величин Xk. Возьмем одну (любую) из них; это — дискретная СВ, имеющая два возможных значения: 0 и 1, с вероятностями (1 —р) и р. Математическое ожидание такой СВ равно:
![]()
Дисперсию этой СВ найдем по формуле (6):
![]()
Подставляя в (13) и (14), получим решение задачи:
![]()
Задача 2. Производится N независимых опытов, в каждом из которых событие А происходит с вероятностью р. Рассматривается СВ Р* — частота события А в этой серии опытов. Найти приближенно диапазон практически возможных значений СВ Р*.
Решение. По определению частоты она равна числу X появлений события А, деленному на число опытов N:
![]()
Найдем числовые характеристики (математическое ожидание и дисперсию) этой случайной величины. Пользуясь правилами 3 и 4, получим:
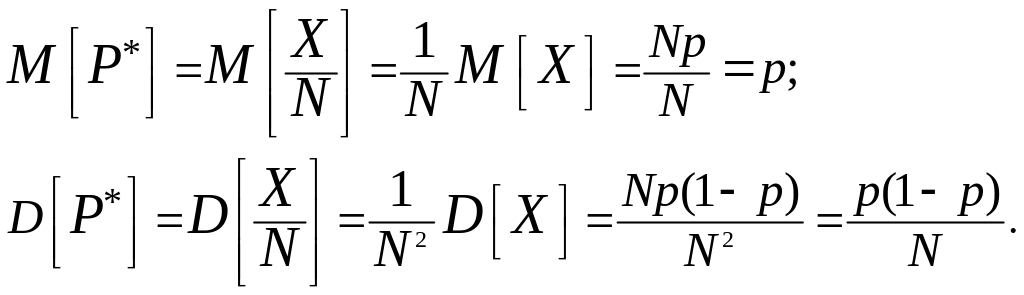
Извлекая
корень квадратный из дисперсии, найдем
среднее квадратическое отклонение
![]() :
:
![]()
А теперь воспользуемся «правилом трех сигм» и найдем приближенно диапазон практически возможных значений СВ Р*:
![]()
«Ба, да ведь это — наша старая знакомая! — воскликнете Вы, если были внимательны. — Ведь эту самую формулу нам демонстрировали для доверительного интервала, в который с вероятностью 0,997 уложится значение частоты события при большом числе опытов N. Наряду с ней (и даже предпочтительно) нам рекомендовали другую, где перед корнем стояла двойка, а не тройка, и та, помнится, выполнялась с вероятностью 0,95. Формулы-то получены. А вероятность откуда?»
Погодите, имейте терпение. Чтобы понять, откуда взялись вероятности 0,997 и 0,95, Вам нужно познакомиться с одним очень важным законом распределения — с так называемым нормальным законом.
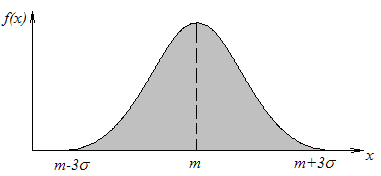
Рис. 5
Рассмотрим непрерывную случайную величину X. Говорят, что она «распределена по нормальному закону» (или «имеет нормальное распределение»), если ее плотность вероятности выражается формулой:
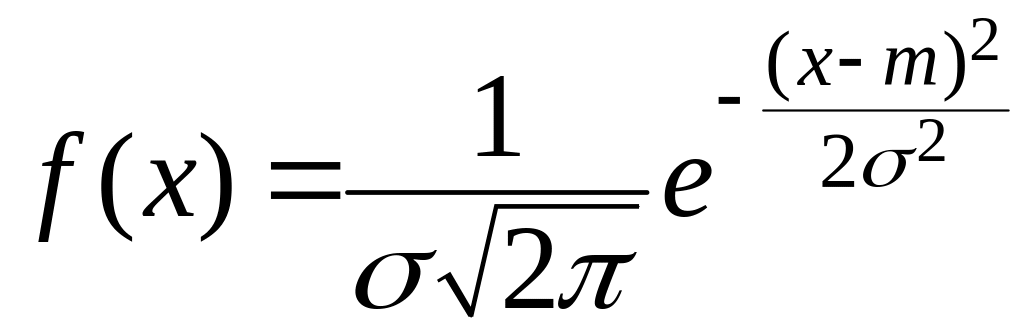 (15)
(15)
где
![]() — известное Вам из геометрии число, а
— известное Вам из геометрии число, а
![]() —
так называемое основание натуральных
логарифмов (
—
так называемое основание натуральных
логарифмов (![]() 2,71828
...). Кривая нормального закона имеет
симметричный, колоколообразный вид
(рис. 5), достигая максимума
в точке т;
по
мере удаления от т
плотность
вероятности падает
и в пределе стремится к нулю. Закон (15)
зависит от
двух параметров:
2,71828
...). Кривая нормального закона имеет
симметричный, колоколообразный вид
(рис. 5), достигая максимума
в точке т;
по
мере удаления от т
плотность
вероятности падает
и в пределе стремится к нулю. Закон (15)
зависит от
двух параметров:
![]() и
и
![]() . Первый из них, т,
как
Вы, вероятно,
догадались, есть не что иное, как
математическое ожидание
СВ
X,
а
второй —
— ее среднее квадратическое отклонение.
При изменении т
кривая
f(х),
не
меняя своей формы, будет «ездить»
туда-сюда вдоль оси абсцисс. Если же
менять
,
кривая f(х)
будет
менять форму, становясь
при возрастании
более «распластанной», а при уменьшении
— более вытянутой вверх, «иглообразной».
. Первый из них, т,
как
Вы, вероятно,
догадались, есть не что иное, как
математическое ожидание
СВ
X,
а
второй —
— ее среднее квадратическое отклонение.
При изменении т
кривая
f(х),
не
меняя своей формы, будет «ездить»
туда-сюда вдоль оси абсцисс. Если же
менять
,
кривая f(х)
будет
менять форму, становясь
при возрастании
более «распластанной», а при уменьшении
— более вытянутой вверх, «иглообразной».
Особая роль, которую играет нормальный закон в теории вероятностей, связана с одним его замечательным свойством. Оказывается, если складывать большое число независимых (или слабо зависимых) случайных величин, сравнимых между собой по порядку своих дисперсий, то каковы бы ни были законы распределения слагаемых, закон распределения суммы будет близок к нормальному — тем ближе, чем больше случайных величин складывается. Приведенное выше положение — это грубая формулировка так называемой «центральной предельной теоремы», играющей очень большую роль в теории вероятностей. У этой теоремы много различных форм, различающихся между собой условиями, которым должны удовлетворять случайные величины, чтобы их сумма с увеличением числа слагаемых «нормализовалась».
На практике очень многие случайные величины образуются по «принципу суммы» и, значит, распределены нормально или почти нормально. Например, ошибки всевозможных измерений, представляющие собой сумму многих «элементарных», практически независимых, ошибок, вызванных отдельными причинами. По тому же закону распределяются, как правило, ошибки стрельбы, наведения, совмещения. Отклонения напряжения в сети от номинала также вызваны суммарным действием многих независимых причин, результаты действия которых складываются. Нормальному (или близкому к нему) закону подчиняются такие СВ, как суммарная выплата страхового общества за большой период, суммарное время простоя ЭЦВМ за год и т. д. Покажем, в частности, что такая интересная случайная величина, как частота события при большом числе опытов N, тоже имеет приближенно нормальное распределение. Действительно,
![]()
где Xk — случайная величина, равная единице, если в k-м опыте событие А появилось, и нулю, если не появилось. Отсюда видно, что частота Р* при большом числе опытов N есть сумма большого числа независимых слагаемых, причем каждое из них имеет одну и ту же дисперсию:
![]()
Отсюда заключаем, что частота Р* события А при большом числе опытов N имеет приближенно нормальное распределение.
Поскольку нормальный закон распределения часто встречается на практике, нередко приходится вычислять вероятность попадания СВ X, распределенной по нормальному закону, в пределы участка (а, b). Интеграл (1) в этом случае не выражается через элементарные функции (как любят говорить студенты, «не берется»)- для его вычисления пользуются таблицами специальной функции — так называемой функции Лапласа:
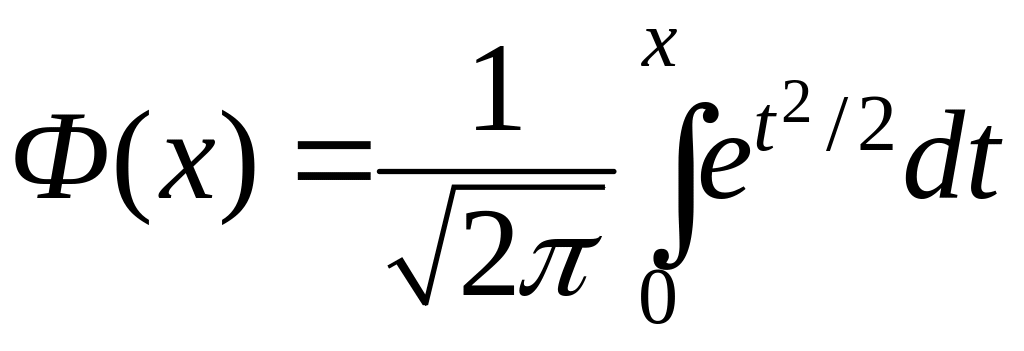
Краткие выдержки из таблиц функции Лапласа приведены в таблице
Таблица
x |
Ф(х) |
x |
Ф(х) |
x |
Ф(Х) |
x |
Ф(х) |
0,0 |
0,0000 |
1,0 |
0,3413 |
2,0 |
0,4772 |
3,0 |
0,4986 |
0,1 |
0,0398 |
1,1 |
0,3643 |
2,1 |
0,4821 |
3,1 |
0,4990 |
0,2 |
0,0793 |
1,2 |
0,3849 |
2,2 |
0,4861 |
3,2 |
0,4993 |
0,3 |
0,1179 |
1,3 |
0,4032 |
2,3 |
0,4893 |
3,3 |
0,4995 |
0,4 |
0,1554 |
1,4 |
0,4192 |
2,4 |
0,4918 |
3,4 |
0,4997 |
0,5 |
0,1915 |
1,5 |
0,4332 |
2,5 |
0,4938 |
3,5 |
0,4998 |
0,6 |
0,2257 |
1,6 |
0,4452 |
2,6 |
0,4953 |
3,6 |
0.4998 |
0,7 |
0,2580 |
1,7 |
0,4554 |
2,7 |
0.4965 |
3,7 |
0,4999 |
0,8 |
0,2881 |
1,8 |
0,4641 |
2,8 |
0,4947 |
3,8 |
0,4999 |
0,9 |
0,3159 |
1,9 |
0,4713 |
2,9 |
0,4981 |
3,9 |
0,5000 |
При
![]() можно принимать с точностью до 4 го знака
после запятой Ф (х)
=
0,5000.
можно принимать с точностью до 4 го знака
после запятой Ф (х)
=
0,5000.
При пользовании таблицей следует учитывать, что функция Лапласа нечетная, т. е.
Ф (—х) = — Ф (х).
Вероятность попадания СВ X, имеющей нормальное распределение с параметрами т и , в пределы участка (с, b) выражается через функцию Лапласа формулой:
![]() (16)
(16)
Пример
5.
Найти вероятность того, что СВ
X,
имеющая
нормальное распределение с параметрами
![]() :
:
а) отклонится от своего математического ожидания не больше чем на 2 ; б) отклонится от него не больше чем на З .
Решение. Пользуясь формулой (16) и таблицей, найдем:
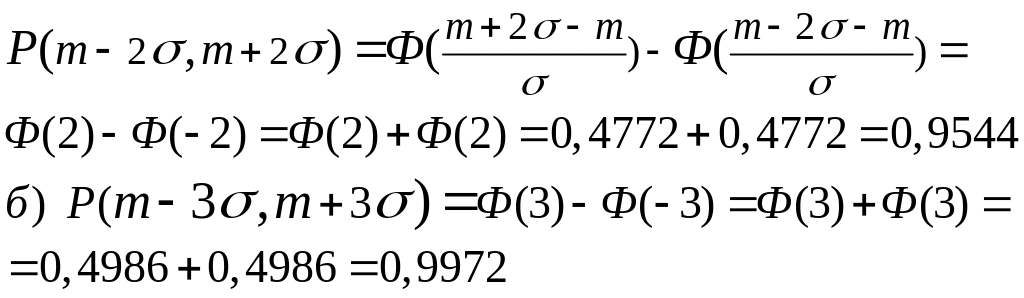
Так вот они, наконец, вычислены — две доверительные вероятности: 0,95 и 0,997, с которыми мы в главе 2 задавали доверительные интервалы для частоты события! Долгонько нам пришлось до них добираться...
Зато теперь, владея нормальным законом, мы можем решать некоторые поучительные задачи.
Пример
6.
Поезд состоит из N
=
100 вагонов. Вес каждого вагона—случайная
величина с математическим ожиданием
mq
=
65 (т) и средним квадратическим отклонением
![]() q
=
9 (т). Локомотив может везти поезд, если
его вес не превышает 6600 т; в противном
случае приходится подцеплять второй
локомотив. Найти вероятность того, что
этого делать не придется.
q
=
9 (т). Локомотив может везти поезд, если
его вес не превышает 6600 т; в противном
случае приходится подцеплять второй
локомотив. Найти вероятность того, что
этого делать не придется.
Решение. Вес поезда X можно представить как сумму 100 случайных величин. Qk — весов отдельных вагонов:
![]()
имеющих одно и то же математическое ожидание mq = 65 и одну и ту же дисперсию Dq = 2q = 81. По правилу сложения математических ожиданий:
М [X] = 100 • 65 = 6500.
По правилу сложения дисперсий:
D [X] = 100 • 81 = 8100.
Извлекая
корень, найдем среднее квадратическое
отклонение:![]() .
.
Для того, чтобы один локомотив мог везти поезд, нужно, чтобы вес поезда X оказался приемлемым, т. е. попал в пределы участка (0; 6600). Случайную величину X — сумму 100 слагаемых можно считать распределенной нормально. По формуле (16):
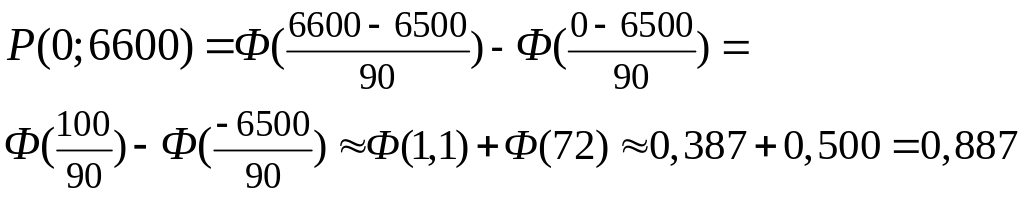
Итак, локомотив «справится» С поездом приблизительно с вероятностью 0,887.
Теперь давайте уменьшим число вагонов в поезде на два, т. е. возьмем N = 98. Подсчитайте сами вероятность того, что локомотив «справится» с поездом. Скорее всего результат подсчета Вас удивит: эта вероятность приближенно равна 0,99; значит, событие, о котором идет речь, практически достоверно! И всего-то для этого пришлось убрать два вагона...
Вот видите, какие любопытные задачки можно решать, имея дело с суммами большого числа случайных величин. Тут, естественно, возникает вопрос: а сколько это «много»? Сколько нужно сложить случайных величин, чтобы закон распределения суммы уже «нормализовался»?
А это зависит от того, каковы законы распределения слагаемых. Бывают такие замысловатые законы, что нормализация наступает только при очень-очень большом числе слагаемых. Опять повторим: чего только не придумают математики! Но природа специально не устраивает нам таких пакостей. Обычно на практике для того, чтобы можно было пользоваться нормальным законом, бывает достаточно 5—6, ну 10, ну от силы 20 слагаемых (особенно если они имеют одно и то же распределение).
Быстроту, с которой «нормализуется» закон распределения суммы одинаково распределенных случайных величин, можно проиллюстрировать на примере (тут Вам опять придется верить нам на слово — ничего не поделаешь! Но до сих пор мы Вас не обманывали). Пусть имеется непрерывная СВ, распределенная с постоянной плотностью на участке (0; 1) (рис. 6). Кривая распределения имеет вид прямоугольника. Казалось бы, уж как непохоже на нормальный закон! А сложим две такие (независимые) случайные величины — получим новую СВ, распределенную по так называемому закону Симпсона (рис. 7). Тоже непохоже на нормальный закон, но уже лучше... А если сложить три такие равномерно распределенные случайные величины — получится СВ с плотностью, показанной на рис. 8, — кривая распределения состоит из трех отрезков парабол и по виду ужасно напоминает нормальный закон. А уж если сложить шесть равномерно распределенных случайных величин — ни Вы, ни я, ни кто другой не сможет отличить кривую распределения от нормальной. На этом основан широко применяемый при моделировании случайных явлений на ЭЦВМ метод получения нормально распределенной случайной величины: достаточно сложить шесть независимых случайных величин, имеющих равномерное распределение на отрезке (0; 1) (кстати, датчиками таких случайных чисел оснащено в наше время большинство ЭЦВМ).
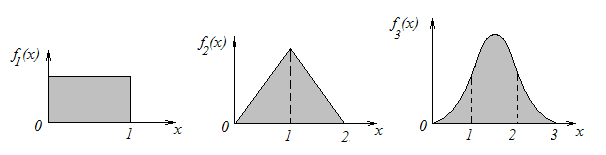
Рис. 6 Рис. 7 Рис. 8
И все-таки нельзя слишком увлекаться и сразу провозглашать нормальным закон распределения суммы нескольких случайных величин. Нужно сначала посмотреть (хотя бы в первом приближении), каковы их распределения. Если они, например, очень асимметричны, может понадобиться большое число слагаемых. В частности, нужно с некоторой осторожностью пользоваться правилом, что «при большом числе опытов частота события распределяется по нормальному закону». Если вероятность события р в одном опыте очень мала (или, наоборот, очень близка к единице), для этого может понадобиться огромное число опытов. Кстати, сообщим Вам практический способ, позволяющий проверить, можно ли для частоты события пользоваться нормальным законом. Нужно по уже известному нам способу построить доверительный интервал для частоты события (с уровнем доверия 0,997):
![]()
и если он весь (оба его конца!) не выходит за разумные границы, в которых может лежать частота, и вероятность тоже (от 0 до 1), то можно пользоваться нормальным законом. Если же какая-нибудь из границ интервала оказывается за пределами отрезка (0, 1), то нормальным законом пользоваться нельзя. В таких случаях можно для приближенного решения задачи воспользоваться другим распределением — так называемым распределением Пуассона. Но разговор об этом распределении (так же, как и о ряде других, которых в теории вероятностей великое множество!) выходит за пределы наших «первых шагов».
В общем, в результате изучения нашей немудреного введения Вы, по-видимому, получили некоторое понятие о том, что такое теория вероятностей и чем она занимается. Возможно, что Вы получили к ней решительное отвращение — в таком случае первое знакомство с ней станет для Вас и последним. Жалко, конечно, но ничего не поделаешь: есть люди (даже среди математиков!), органически не переносящие теории вероятностей.
Но возможно (для этого, в сущности, и написано введение), что тематика, методы и возможности теории вероятностей Вас заинтересовали. Тогда познакомьтесь с нашей наукой поподробнее (см. список литературы). Не будем скрывать, что углубленное знакомство с теорией вероятностей потребует от Вас умственных усилий, гораздо более серьезных, чем «первые шаги». Дальнейшие будут труднее, но зато и интереснее. Недаром говорит пословица: «корень учения горек, а плоды — сладки».