

49. Генерация объектного кода. Построение синтаксического дерева. Генерация объектного кода для линейных участков программ.
Построение синтаксического дерева
В качестве внутренней формы представления синтаксической структуры программы может быть использовано, например, СД, определенное следующим образом:
<дерево> <элемент> | <пусто>
<элемент> <метка> <слева> <справа>
<слева> <дерево>
<справа> <дерево>
<метка> операнд или код операции.
Для получения СД, соответствующего анализируемой цепочки, можно воспользоваться механизмом семантических процедур.
Процесс построения СД в ходе синтаксического анализа целесообразно проследить на примере грамматики, описывающей простейшие арифметические выражения, дополнив ее операциями вычитания и деления ("a" - идентификатор произвольной переменной):
G = ({E, F, T}, {, /, +, -, a}, P, {E}),
P: E E+T | E-T | T
T TF | T/ F | F
F (E)
F a .
Пусть с правилами этой грамматики связаны следующие семантические процедуры, обеспечивающие построение СД:
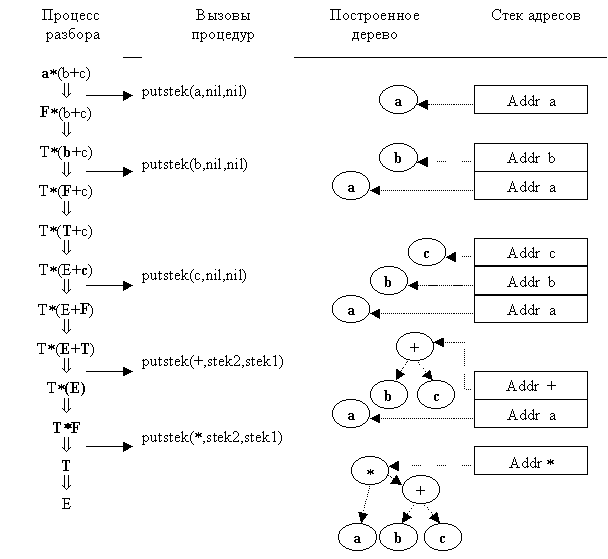
E E+T putstek (("+", stek2, stek1))
E E-T putstek (("-", stek2, stek1))
T TF putstek (("", stek2, stek1))
T T/F putstek (("/", stek2, stek1))
F a putstek ((a, <пусто>, <пусто>)).
Процедуры stek1 и stek2 осуществляют выбор из некоторого магазина адреса элемента, хранящегося соответственно в первой или во второй сверху ячейке магазина (выбранный элемент из магазина удаляется). Процедура putstek(<элемент>) размещает в памяти структуру данных, соответствующую узлу дерева, и помещает его адрес (имя) в вершину магазина.
На рис. 3.1 показана последовательность использования правил грамматики в процессе разбора цепочки a(b+c), соответствующая ей последовательность вызовов процедуры putstek и фрагменты формируемого СД. Адрес корня построенного СД находится в вершине магазина.
После получения внутреннего представления программы транслирующая система должна выполнить последний этап своей работы - сформировать объектный код программы.
При формировании объектного кода должен быть решен целый ряд проблем. К ним, в частности относятся:
генерация машинных команд, непосредственно соответствующих императивным конструктам транслируемой программы;
генерация кодов команд и данных, обеспечивающих распределение памяти ЭВМ под объекты программы и ее своевременное освобождение, реализующих обращение к операционной системе ЭВМ с различными системными запросами, позволяющих эффективно обнаруживать и диагностировать ошибки периода исполнения программы (деление на ноль, переполнение арифметических величин и т.д.).
Прежде чем строить код программы для некоторой ЭВМ, необходимо описать ее архитектуру и систему команд.
1) Процессор ЭВМ имеет N регистров данных (N 1).
2) Процессор может выполнять следующие команды:
LE R,M - загрузка содержимого памяти по адресу M в регистр R;
STE R,M - запись содержимого регистра R в память по адресу M;
LER R1,R2 - копирование содержимого регистра R2 в регистр R1;
<op> R,M - выполнение операции <op> над содержимым регистра R и памяти по адресу M с записью результата в регистр R;
<op>R R1,R2 - выполнение операции <op> над содержимым регистров R1 и R2 с записью результата в регистр R1.
В качестве обозначения операций <op> могут выступать следующие комбинации символов:
AE - сложение;
SE - вычитание;
ME - умножение;
DE - деление.
3) Для того чтобы не затрагивать вопросы размещения, хранения и адресования данных в памяти ЭВМ, в качестве адресов памяти M при записи команд используются идентификаторы соответствующих переменных.
4. Все операции являются бинарными, все операнды (идентификаторы переменных) - различны, а транслируемые выражения всегда имеют только одно значение;
5. Блок синтаксического анализа обеспечивает построение СД в рассмотренной выше форме.
Процесс генерации кода в общем случае включает в себя этап СД дерева и этап генерации машинного кода. Содержание этих этапов рассматривается применительно к линейным участкам программ - т.е. участкам, не содержащим команд сравнения, перехода и т.д..
Разметка СД имеет целью определения веса каждой его вершины и всего дерева в целом. Весом дерева считается вес его корневой вершины. Как будет показано в п. 3.2.2, вес дерева непосредственно связан с количеством регистров, необходимых для выполнения вычисления значения арифметического выражения без запоминания промежуточных результатов в дополнительных ячейках памяти.
Процесс разметки предполагает обход СД, которые вследствие принятых в п. 3.1 ограничений является двоичным (бинарным) деревом.
Так как бинарное дерево представляет собой рекурсивную структуру данных, для выполнения его обхода с целью разметки может быть использован следующий рекурсивный алгоритм.
Алгоритм разметки СД
Вход: Имя корневой вершины размечаемого дерева
Выход: Размеченное СД
Процесс:
Если вершина является листом (не имеет потомков), то:
если эта вершина - корень дерева, состоящего только из одного узла либо левый потомок узла более большого дерева, то вес этой вершины установить равным 1;
в противном случае данная вершина является правым потомком узла более большого дерева, и ее вес необходимо установить равным 0.
Если же вершина не является листом (имеет потомков), то:
разметить с помощью данного алгоритма левое поддерево;
разметить с помощью данного алгоритма правое поддерево;
если веса поддеревьев совпадают, то вес этой вершины установить равным весу левого или правого поддерева, увеличив его на 1;
если же веса поддеревьев не совпадают, то вес вершины определить равным наибольшему из весов поддеревьев.
На рис пример размеченного СД.
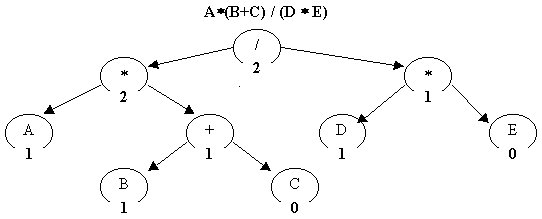
Смысл алгоритма разметки заключается в следующем:
листья СД соответствуют операндам выражения, а для выполнения операции нужно обеспечить наличие не менее одного операнда в регистре - следовательно, для первого (левого) операнда необходим регистр (и его вес равен 1), а второй операнд при использовании операции типа "регистр-память" можно выбирать непосредственно из памяти (и его вес равен 0);
вершины СД, не являющиеся листьями, соответствуют операциям - если оба операнда находятся в регистрах (веса поддеревьев совпадают), то для данной операции нужно иметь на один регистр больше; если же веса поддеревьев не совпадают, то можно обойтись без такого регистра.
Таким образом, выполнив однократный левосторонний восходящий постфиксный обход СД по изложенным выше правилам, можно получить размеченное дерево, необходимое для этапа генерации кода.
Алгоритм построения кода для выражения
Имея размеченное СД, можно выполнить генерацию объектного кода, в основе которой также лежит восходящий постфиксный обход дерева. Этот процесс может быть реализован с помощью следующего рекурсивного алгоритма.
Алгоритм генерации кода
Вход: Размеченное СД T, N регистров R1, R2,..., Rn (N 1).
Выход: Объектный код программы, выполняющей вычисление значения представленного с помощью СД арифметического выражения и помещение этого значения в регистр R1.
Метод:
Выполнить рекурсивную процедуру code(n,i), входом для которой служат вершина n дерева T и целое число i от 1 до N. Число i означает, что в данный момент для вычисления выражения в вершине n доступны регистры Ri, Ri+1,..., RN.
Выходом для code(n,i) служит последовательность команд процессора ЭВМ, обеспечивающая вычисление значения выражения в вершине n и помещает его в регистр Ri.
Изначально выполняется вызов code(n0,1), где n0 - корень дерева T. Последовательность команд, сгенерированных при исполнении этого вызова, и будет требуемой программой.
Процедура code(n,i): Предполагается, что n - вершина дерева T, а i - целое число в интервале от 1 до N.
Если n - лист, выполнить шаг 2. В противном случае выполнить шаг 3.
Если вызвана процедура code(n,i), а n - лист, то n всегда будет левым прямым потомком (или корнем, если n - единственная вершина). Если с листом n связано имя переменной X, то code(n,i) = 'LE Ri,X' (выходом процедуры code(n,i) будет команда 'LE Ri,X', помещаемая в выходной поток генератора кода).
Переход на выполнение этого шага означает, что n - внутренняя вершина. Пусть с ней связаны операция <op> и потомки n1 и n2 с весами L1 и L2 (где 1 и 2 - обозначения левого и правого потомков соответственно). Следующий шаг определяется значениями весов L1 и L2:
(а) если L2=0 (n2 - правый лист), выполнить шаг 4,
(б) если 1 L1 < L2 и L1 < N, выполнить шаг 5,
(в) если 1 L2 L1 и L2 < N, выполнить шаг 6,
(г) если N L1 и N L2, выполнить шаг 7.
code (n,i) =
code (n1,i)
'<op> Ri,X',
где x - переменная, связанная с правым листом n2.
code (n,i) =
code (n2,i)
code (n1,i+1)
'<op> Ri+1,Ri'
'LER Ri,Ri+1'.
code (n,i) =
code (n1,i)
code (n2,i+1)
'<op> Ri,Ri+1'.
code (n,i) =
code(n2,i)
j +:= 1; getmain(Sj)
'STE Ri,Sj'
code (n1,i)
'<op> Ri,Sj'
freemain(Sj); j -:= 1.
В приведенном алгоритме используется глобальная переменная j - количество используемых дополнительных ячеек памяти. Необходимость в таких ячейках возникает при недостаточном количестве свободных регистров для запоминания результатов выполнения операций. Предполагается, что с помощью вызова процедуры getmain(Sj) можно получить новую дополнительную ячейку памяти S с номером j, а с помощью вызова процедуры freemain(Sj) - возвратить ячейку с номером j в общую область свободной памяти.
50. Технологии искусственного интеллекта. Понятие «знание».
Знания – это совокупность сведений о сущностях (объектах, предметах) реального мира, их свойствах и отношениях между ними в определенной предметной области. Иными словами, знания – это выявленные закономерности предметной области (принципы, связи, законы), позволяющие решать задачи в этой области. С точки зрения ИИ знания можно определить как формализованную информацию, на которую ссылаются в процессе логического вывода.
В этом случае, под ПрО понимается область человеческих знаний, в терминах которой формулируются задачи и в рамках которой они решаются. Т.е. ПрО представляется описанием части реального мира, которое в силу своей приближенности рассматривается как ее информационная модель.
Проблемная область – это содержательное описание в терминах ПрО проблемы совместно с комплексом условий, факторов и обстоятельств, вызвавших ее возникновение. В исследованиях по ИИ можно выделить два основных направления: программно-прагматическое («не имеет значения, как устроено «мыслящее» устройство, главное, чтобы на заданные входные воздействия оно реагировало, как человеческий мозг») и бионическое («единственный объект, способный мыслить – это человеческий мозг, поэтому любое «мыслящее» устройство должно каким-то образом воспроизводить его структуру»). В рамках данного подхода сформировалась новая наука нейроинформатика.
Ярким же представителем программно-прагматического направления можно считать экспертные системы – это сложные программные комплексы, аккумулирующие знания специалистов-экспертов для обеспечения высокоэффективного решения неформализованных задач в узкой предметной области.
Приведенные выше понятия могут рассматриваться как пример системного изложения аксиоматических основ дисциплины в авторском изложении.
Общепризнанного определения знания, как и определения искусственного интеллекта, не существует. Известные трактовки этого понятия отражают его различные аспекты, поэтому приведем несколько определений.
Наиболее общее определение трактует знание как всю совокупность данных (информации), необходимую для решения задачи. В этом определении подчеркивается, что данные в привычном понимании также являются знаниями. Однако знания в информационном плане не ограничиваются рамками данных. В полном объеме информация, содержащаяся в знаниях, должна включать сведения о: системе понятий предметной области, в которой решаются задачи; системе понятий формальных моделей, на основе которых решаются задачи; соответствии систем понятий, упомянутых выше; методах решения задачи; текущем состоянии предметной области. Из перечисленных компонентов только последний в явном виде соответствует понятию "данные". В целом обо всей приведенной выше информации иногда говорят, что она составляет проблемную область решаемой задачи.
Несмотря на сложности формулировки определения знания считается общепризнанным, что знания имеют ряд свойств, позволяющих отличать их от данных: внутреннюю интерпретируемость; внутреннюю (рекурсивную) структурированность; внешнюю взаимосвязь единиц; шкалирование; погружение в пространство с семантической метрикой; активность.
51. Понятие модели представления знаний (МПЗ). Основные МПЗ, их особенности и области применения. Понятие вывода на знаниях.
Модель представления знаний (МПЗ) - это способ и результат формального описания знаний в БЗ. Она должна быть понятной пользователю и обеспечивать однородность представления знаний, за счет чего упрощаются управление знаниями и логический вывод, а также удовлетворять ряду других требований.
К настоящему времени разработано достаточно много различных МПЗ, и работа по созданию новых моделей продолжается. Однако наибольшее распространение получили четыре модели: модель семантической сети, фреймовая, продукционная и логические.
Логические МПЗ - это модели, основанные на правилах формальной логики. Все логические МПЗ представляются четверкой (формальной системой):
M = < T, P, A, F >,
где T - алфавит (множество базовых элементов);
P - множество правил построения синтаксически правильных выражений;
A - априорно истинные выражения (аксиомы);
F - правила вывода новых истинных выражений в рамках М.
МПЗ, основанные на правилах, являются наиболее распространенными и более 80% ЭС используют именно их. Продукционная модель основана на правилах, позволяющая представить
знания в виде предложений типа "Если (условие), то (действие)".
Под "условием" (антецедентом) понимается некоторое предложение-образец, по которому осуществляется поиск в базе знаний, а под "действием" (консеквентом) - действия, выполняемые при успешном исходе поиска (они могут быть промежуточными, выступающими далее как условия, и терминальными или целевыми, завершающими работу системы).
Чаще всего вывод на такой БЗ бывает прямой (от данных к поиску цели) или обратный (от цели для ее подтверждения – к данным). Данные - это исходные факты, хранящиеся в базе фак-
тов, на основании которых запускается машина вывода или интерпретатор правил, перебирающий правила из продукционной базы знаний.
Фреймовая МПЗ базируется на понятии функционального программирования - способа составления программ, в которых единственным действием является вызов функции, единственным
способом расчленения программ на части является введение имени для функции и задание для этого имени выражения, вычисляющего значение функции, а единственным правилом композиции - оператор суперпозиции других функций.
Термин "семантическая" означает "смысловая", а сама семантика — это наука, устанавливающая отношения между символами и объектами, которые они обозначают, т. е. наука, определяющая смысл знаков.
Семантическая сеть наиболее близка к тому, как представляются знания в текстах на естественном языке. В ее основе лежит идея о том, что вся необходимая информация может быть описана как совокупность троек ( a r b ), где а и b - два объекта или понятия, а r двоичное отношение между ними.
Графически семантическая сеть представляется в виде помеченного ориентированного графа, в котором вершинам соответствуют объекты (понятия), а дугам - их отношения. Дуги помечаются именами соответствующих отношений.
Семантическая сеть является моделью широкого предназначения. Выделяются различные виды семантических сетей:
ситуационные сети, которые описывают временные, постранственные и причинно-следственные (клаузальные) отношения;
целевые сети, используемые в системах планирования и синтеза, которые описывают отношения "цель-средства" и "цель подцель";
классификационные сети, использующие отношения "родвид", "класс-подкласс";
функциональные сети, использующие отношения "аргумент-функция" и т.д.
52. Концепция экспертной системы. Назначение и основные свойства. Обобщенная структура экспертной системы. Классификация экспертных систем.
ЭС – это программное средство, использующее экспертные знания для обеспечения высокоэффективного решения неформализованных задач в узкой проблемной области.
Основу ЭС составляет БЗ о ПрО, которая накапливается в процессе построения и эксплуатации ЭС. Накопление и организация знаний – важнейшее свойство всех ЭС. Использование знаний определяет такие свойства ЭС, как применение для решения выявленных проблем высококачественного опыта, который представляет собой мышления наиболее квалифицированных экспертов в данной области, что в конечном счете приводит к точным и эффективным результатам;
наличие прогностических возможностей, при которых ЭС выдает ответы не только для конкретной ситуации, но и показывает, как изменяются эти ответы в новых ситуациях и существует возможность получения подробного объяснения каким образом новая ситуация привела к изменениям;
институциональная память – набор знаний, за счет входящей в состав ЭС базы знаний, становится постоянно обновляемым справочником наилучших стратегий и методов, используемых персоналом, таким образом ведущие специалисты уходят, но их опыт остается;
возможность использования ЭС для обучения и тренировки специалистов, по которым можно изучать рекомендуемую политику и методы.
Классификация по специфике решаемых задач.
Интерпретация данных. Это одна из традиционных задач для ЭС. Под интерпретацией понимается определение смысла данных, результаты которого должны быть согласованными и корректными. Обычно предусматривается многовариантный анализ данных: обнаружение и идентификация различных типов океанских судов; определение основных свойств личности по результатам психодиагностического тестирования.
Диагностика. Под диагностикой понимается обнаружение неисправности в некоторой системе. Неисправность – это отклонение от нормы. Такая трактовка позволяет с единых теоретиче-
ских позиций рассматривать и неисправность оборудования в технических системах, и заболевания живых организмов, и всевозможные природные аномалии. Важной спецификой является необходимость понимания функциональной структуры диагностирующей системы: диагностика и терапия сужения коронарных сосудов; диагностика ошибок в аппаратуре и математическом обеспечении ЭВМ.
Мониторинг. Основная задача мониторинга – непрерывная интерпретация данных в реальном масштабе времени и сигнализация о выходе тех или иных параметров за допустимые пределы. Главные проблемы – пропуск тревожной ситуации и инверсная задача ложного срабатывания. Сложность этих проблем в размытости симптомов тревожных ситуаций и необходимость учета временного контекста: контроль за работой электростанций, помощь диспетчерам атомного реактора; контроль аварийных датчиков на химическом заводе.
Проектирование. Проектирование состоит в подготовке спецификаций на создание объектов с заранее определенными свойствами. Под спецификацией понимается весь набор необхо-
димых документов – чертеж, пояснительная записка и т.д. Основные проблемы здесь – получение четкого структурного описания знаний об объекте и проблема «следа». Для организацииэффективного проектирования и, в еще большей степени, перепроектирования необходимо формировать не только сами проектные решения, но и мотивы их принятия. Таким образом, в задачах проектирования тесно связываются два основных процесса, выполняемых в рамках соответствующей ЭС: процесс вывода решения и процесс объяснения: проектирование БИС; синтез электрических цепей.
Прогнозирование. Прогнозирующие системы логически выводят вероятные следствия из заданных ситуаций. В прогнозирующей системе обычно используется параметрическая динамическая модель, в которой значения параметров «подгоняются» под заданную ситуацию. Выводимые из этой модели следствия составляют основу для прогнозов с вероятностными оценками: предсказание погоды; прогнозы в экономике.
Планирование. Под планированием понимается нахождение планов действий, относящихся к объектам, способным выполнять некоторые функции. В таких ЭС используются модели поведения реальных объектов с тем, чтобы логически вывести последствия планируемой деятельности: планирование промышленных заказов; планирование эксперимента.
Обучение. Системы обучения диагностируют ошибки при изучении какой-либо дисциплины с помощью ЭВМ и подсказывают правильные решения. Они аккумулируют знания о гипотетическом «ученике» и его характерных ошибках, затем в работе способны диагностировать слабости в знаниях обучаемых и находить соответствующие средства для их ликвидации. Кроме того, они планируют акт общения с учеником в зависимости от успехов ученика с целью передачи знаний.
Классификация по типу решаемых задач во времени Статические ЭС разрабатываются для ПрО, характеризующихся неизменностью входных данных в процессе поиска решения: диагностика неисправностей в автомобиле.
Динамические ЭС разрабатываются для проблемных областей, требующих обеспечить возможность изменения входных данных в процессе поиска решения: система обслуживания биржевых операций.
Классификация по степени интеграции Автономные ЭС работают непосредственно в режиме консультаций с пользователем для обеспечения высокоэффективного решения неформализованных задач в узкой проблемной области, не требующих дополнительного привлечения традиционных методов обработки данных (расчеты, моделирование и т.д.), т.е. изолированная ЭС, не рассчитанная на взаимодействие с другими программными системами. Гибридные ЭС представляют собой программный комплекс, агрегирующий стандартные пакеты прикладных программ (например, математическую статистику, линейное программирование или системы управления базами данных) и средства манипулирования знаниями. Это может быть интегрированная среда для решения сложной задачи с элементами экспертных знаний.
Классификация по сложности и мощности
Здесь мощность определяется множеством используемых правил. Малые ЭС реализовываются на ПК (IBM PC, Macintosh и подобные) как автономные (изолированные) ЭС. Средние ЭС работают в режиме клиент-сервер, используются в большинстве случаев как гибридные (интегрированные) ЭС.Большие ЭС реализовываются на ЭВМ общего назначения и используют БЗ большого объема.
Классификация по диапазону использования
Закрытые ЭС ориентированы на использование только в программной среде конкретной ИС. Открытые ЭС ориентированы на использование в разнородном программно-аппаратном окружении и могут быть перенесены на другие платформы без существенных изменений.
53. Технология разработки экспертных систем.
ЭС – это программное средство, использующее знания экспертов, для высокоэффективного решения задач в интересующей пользователя проблемной области. Она является системой, а не просто программой, так как содержит базу знаний, решатель проблем и компоненты поддержки, которые помогают пользователю взаимодействовать с основной программой.
Технология разработки ЭС включает в себя шесть этапов: этапы идентификации, концептуализации, формализации, выполнения, тестирования, опытной эксплуатации. Рассмотрим более подробно последовательности действий, которые необходимо выполнить на каждом из этапов.
На этапе идентификации необходимо выполнить следующие действия:
определить задачи, подлежащие решению и цели разработки;
определить экспертов и тип пользователей.
На этапе идентификации определяются участники процесса проектирования и их роли, идентифицируется задача (задачи), определяются ресурсы и цели построения системы. Главными участниками на этом этапе являются эксперт и инженер по знаниям. Взаимодействие их между собой происходит в следующих формах:эксперт выступает в роли информатора, а инженер по знаниям в роли получателя информации;
После выбора участников инженер по знаниям и основной эксперт начинают идентификацию задачи. Идентификация задачи заключается в составлении неформального (вербального) описания решаемой задачи. В этом описании указываются:
общие характеристики задачи;
подзадачи, выделяемые внутри данной задачи;
ключевые понятия (объекты), характеристики и отношения;
входные и выходные данные;
предположительный вид решения;
знания, релевантные решаемой задаче;
примеры (тесты) решения задачи.
Цель идентификации задачи - дать общую характеристику задачи и структуры поддерживающих ее знаний и таким образом обеспечить начальный импульс для развития базы знаний.
В ходе идентификации задачи необходимо ответить на следующие вопросы (примерный состав):
какой класс задач будет решать данная ЭС;
как эти задачи могут быть охарактеризованы или определены;
на какие подзадачи разбивается каждая задача;
какие данные они используют;
каковы основные понятия и взаимоотношения, используемые при формулировании и решении задачи;
какой вид имеет решение и какие знания используются в нем;
какие аспекты опыта эксперта существенны при решении задач;
какие возможны ситуации, препятствующие решению;
как эти препятствия влияют на ЭС.
При идентификации задачи эксперт и инженер по знаниям работают в тесном контакте. Эксперт дает начальное неформальное описание задачи, которое используется инженером по знаниям для уточнения терминов и ключевых понятий. Затем эксперт дает подробное описание типовых задач, объясняет, как решать эти задачи, какие соображения лежат в основе решений. После нескольких циклов обсуждений инженер по знаниям и эксперт достигают окончательного неформального описания задачи.
При проектировании ЭС типичными ресурсами являются:
источники знаний;
время разработки;
вычислительные средства (возможности ЭВМ и программного инструментального средства);
объем финансирования.
Для достижения успеха при построении ЭС эксперт и инженер по знаниям должны использовать все доступные им источники знаний. Для эксперта таковыми являются его предшествующий опыт, книги, конкретные примеры задач и использованных решений. Для инженера по знаниям источниками являются опыт в решении аналогичных задач, существующие методы решения и представления решений, программное инструментальное средство.
При определении времени разработки необходимо иметь в виду, что при трудоемкости 5 чел.-лет сроки разработки и внедрения ЭС составляют (за редким исключением) не менее года. Если объем финансирования оказывается недостаточным, то предпочтение может быть отдано не разработке оригинальной новой системы, а модернизации существующей.
Определение целей заключается в формулировании в явном виде целей построения ЭС. При этом необходимо отличать цели, ради которых создается ЭС, от задач, которые она должна решать. Примерами возможных целей являются:
формализация неформальных знаний экспертов;
улучшение качества решений, принимаемых экспертом;
автоматизация рутинных аспектов работы эксперта (пользо-
вателя);
тиражирование знаний эксперта.
Выявленные цели проектирования ЭС образуют дополнительные ограничения, которые необходимо учитывать при выборе подхода к решению задачи.
54. Понятие интеллектуального анализа данных. Место интеллектуального анализа данных в ИИС.
Термин интеллектуальный анализ данных можно понимать двояко.
ИАД (Data Mining) - мультидисциплинарная область, возникшая и развивающаяся на базе таких наук как прикладная статистика, распознавание образов, искусственный интеллект, теория баз данных и т.д. ИАД - это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Суть и цель технологии ИАД можно охарактеризовать так: это технология, которая предназначена для поиска в больших объемах данных неочевидных, объективных и полезных на практике закономерностей.
Неочевидных - найденные закономерности не обнаруживаются стандартными методами обработки информации или экспертным путем.
Объективных - обнаруженные закономерности будут полностью соответствовать действительности, в отличие от экспертного мнения, которое всегда является субъективным.
Практически полезных - выводы имеют конкретное значение, которому можно найти практическое применение.
Различные инструменты ИАД имеют различную степень"дружелюбности" интерфейса и требуют определенной квалификации пользователя. Поэтому программное обеспечение должно соответствовать уровню подготовки пользователя. Использование ИАД должно быть неразрывно связано с повышением квалификации пользователя. Однако специалистов по ИАД, которые бы хорошо разбирались в бизнесе, пока еще мало.
55. Расчет структурных схем надежности.
Задача расчета надежности - определение показателей безотказности системы, состоящей из невосстанавливаемых элементов, по данным о надежности элементов и связях между ними.
Цель расчета надежности:
обосновать выбор того или иного конструктивного решения;
выяснить возможность и целесообразность резервирования;
выяснить, достижима ли требуемая надежность при существующей технологии разработки и производства.
Расчет надежности состоит из следующих этапов:
1. Определение состава рассчитываемых показателей надежности.
2. Составление (синтез) структурной логической схемы надежности (структуры системы), основанное на анализе функционирования системы (какие блоки включены, в чем состоит их работа, перечень свойств исправной системы и т. п.), и выбор метода расчета надежности.
3. Составление математической модели, связывающей рассчитываемые показатели системы с показателями надежности элементов.
4. Выполнение расчета, анализ полученных результатов, корректировка расчетной модели.
Состав рассчитываемых показателей:
Системы с невосстанавливаемыми элементами: |
- cредняя наработка
до отказа
|
|
- ВБР к заданной
наработке
|
|
- ИО к заданной
наработке
|
|
- ПРО к заданной
наработке
|
Системы с восстанавливаемыми элементами: |
-
|
 ;
; ;
;
 ;
;
 ;
коэффициент готовности, коэффициент
оперативной готовности, параметр
потока отказов.
;
коэффициент готовности, коэффициент
оперативной готовности, параметр
потока отказов.Структура системы – логическая схема взаимодействия элементов, определяющая работоспособность системы или иначе графическое отображение элементов системы, позволяющее однозначно определить состояние системы (работоспособное/неработоспособное) по состоянию (работоспособное/ неработоспособное) элементов.
По структуре системы могут быть:
система без резервирования (основная система);
системы с резервированием.
Для одних и тех же систем могут быть составлены различные структурные схемы надежности в зависимости от вида отказов элементов (см. таблицу 8.1).

VD1
Для отказа типа «к.з» система оказывается не работоспособна при отказе одного диода
структура надежности

P1
P2
VD2
электронная схема: принципиальная)
При отказе типа «обрыв» система работоспособна, пока работоспособен хотя бы один диод
структура надежности
структура надежности
Для отказа типа «к.з» (пробой конденсатора)система оказывается работоспособной
С1
С2

Таб.8.1. Структурные схемы надежности
Математическая модель надежности – формальные преобразования, позволяющие получить расчетные формулы.
Модели могут быть реализованы с помощью:
метода интегральных и дифференциальных уравнений;
на основе графа возможных состояний системы;
на основе логико-вероятностных методов;
на основе дедуктивного метода (дерево отказов).
Наиболее важным этапом расчета надежности является составление структуры системы и определение показателей надежности составляющих ее элементов.
Во-первых, классифицируется понятие (вид) отказов, которые существенным образом влияет на работоспособность системы.
Во-вторых, в состав системы в виде отдельных элементов могут входить электрические соединения пайкой, сжатием или сваркой, а также другие соединения (штепсельные и пр.), поскольку на их долю приходится 10-50% общего числа отказов.
В-третьих, имеется неполная информация о показателях надежности элементов, поэтому приходится либо интерполировать показатели, либо использовать показатели аналогов.
Практически расчет надежности производится в несколько этапов:
1. На стадии составления технического задания на проектируемую систему, когда ее структура не определена, производится предварительная оценка надежности, исходя из априорной информации о надежности близких по характеру систем и надежности комплектующих элементов.
2. Составляется структурная схема с показателями надежности элементов, заданными при нормальных (номинальных) условиях эксплуатации.
3. Окончательный (коэффициентный) расчет надежности проводится на стадии завершения технического проекта, когда произведена эксплуатация опытных образцов и известны все возможные условия эксплуатации. При этом корректируются показатели надежности элементов, часто в сторону их уменьшения, вносятся изменения в структуру – выбирается резервирование.
56. Основные количественные и качественные показатели надежности.
Основные показатели надёжности
Надёжность — свойство объекта сохранять во времени в установленных пределах значения всех параметров, характеризующих способность выполнять требуемые функции в заданных режимах и условиях применения, технического обслуживания, хранения и транспортирования.
Интуитивно надёжность объектов связывают с недопустимостью отказов в работе. Это есть понимание надёжности в «узком» смысле — свойство объекта сохранять работоспособное состояние в течение некоторого времени или некоторой наработки. Иначе говоря, надёжность объекта заключается в отсутствии непредвиденных недопустимых изменений его качества в процессе эксплуатации и хранения. Надёжность тесно связана с различными сторонами процесса эксплуатации. Надёжность в «широком» смысле — комплексное свойство, которое в зависимости от назначения объекта и условий его эксплуатации может включать в себя свойства безотказности, долговечности, ремонтопригодности и сохраняемости, а также определённое сочетание этих свойств.
Под показателем надёжности обычно понимают величину или совокупность величин, характеризующих качественно или количественно степень приспособленности систем к выполнению поставленной задачи при применении по назначению.
Качественные показатели надёжности указывают на то, что рассматриваемая система обладает каким-либо свойством, имеет то или иное устройство, способное выполнить поставленные задачи; дают возможность отличать системы друг от друга, но не позволяют сравнивать их по степени выполнения поставленной задачи, т.е. по надёжности.
Порядковые показатели надёжности дают возможность расположить в ряд по степени возрастания надёжности исследуемые варианты системы, но не позволяют оценить, на какую величину отличается достигнутый уровень надёжности рассматриваемых вариантов.
Количественные показатели надёжности выражаются в виде числа, надёжность измеряется или оценивается в принятой шкале оценок в абсолютных или относительных единицах при помощи этих показателей, количественные показатели определяются путём статических наблюдений на основе обработки результатов применения или испытания систем, а также путём аналитических расчетов или моделирования процессов функционирования систем. Они являются основными показателями надёжности. Поэтому основное внимание уделим именно этим показателям.