

Метод остатков от деления
Простейшей хеш-функцией является деление по модулю числового значения ключа Key на размер пространства записи HashTableSize. Результат интерпретируется как адрес записи. Следует иметь в виду, что такая функция хорошо соответствует первому, но плохо – последним трем требованиям к хеш-функции и сама по себе может быть применена лишь в очень ограниченном диапазоне реальных задач. Однако операция деления по модулю обычно применяется как последний шаг в более сложных функциях хеширования, обеспечивая приведение результата к размеру пространства записей.
Если ключей меньше, чем элементов массива, то в качестве хеш-функции можно использовать деление по модулю, то есть остаток от деления целочисленного ключа Key на размерность массива HashTableSize, то есть:
Key % HashTableSize
Данная функция очень проста, хотя и не относится к хорошим. Вообще, можно использовать любую размерность массива, но она должна быть такой, чтобы минимизировать число коллизий. Для этого в качестве размерности лучше использовать простое число. В большинстве случаев подобный выбор вполне удовлетворителен. Для символьной строки ключом может являться остаток от деления, например, суммы кодов символов строки на HashTableSize.
На практике, метод деления – самый распространенный.
//функция создания хеш-таблицы метод деления по модулю
int Hash(int Key, int HashTableSize) {
//HashTableSize
return Key % HashTableSize;
}
Метод функции середины квадрата
Следующей хеш-функцией является функция середины квадрата. Значение ключа преобразуется в число, это число затем возводится в квадрат, из него выбираются несколько средних цифр и интерпретируются как адрес записи.
Метод свертки
Еще одной хеш-функцией можно назвать функцию свертки. Цифровое представление ключа разбивается на части, каждая из которых имеет длину, равную длине требуемого адреса. Над частями производятся определенные арифметические или поразрядные логические операции, результат которых интерпретируется как адрес. Например, для сравнительно небольших таблиц с ключами – символьными строками неплохие результаты дает функция хеширования, в которой адрес записи получается в результате сложения кодов символов, составляющих строку-ключ.
В качестве хеш-функции также применяют функцию преобразования системы счисления. Ключ, записанный как число в некоторой системе счисления P, интерпретируется как число в системе счисления Q>P. Обычно выбирают Q=P+1. Это число переводится из системы Q обратно в систему P, приводится к размеру пространства записей и интерпретируется как адрес.
12.
13.
14.
15.
16.











17.













18.










19.
















20.
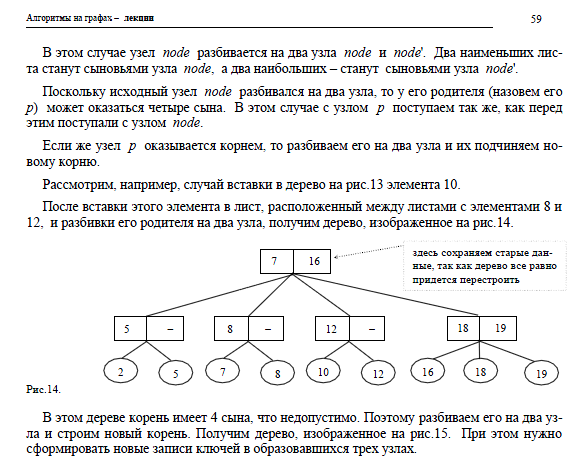
Если граф имеет простой цикл, содержащий все вершины графа по одному разу, то такой цикл называется гамильтоновым циклом, а граф называется гамильтоновым графом. Граф, который содержит простой путь, проходящий через каждую его вершину, называется полугамильтоновым. Это определение можно распространить на ориентированные графы, если путь считать ориентированным.

Гамильтонов цикл не обязательно содержит все ребра графа. Ясно, что гамильтоновым может быть только связный граф и, что всякий гамильтонов граф является полугамильтоновым. Заметим, что гамильтонов цикл существует далеко не в каждом графе.



![]()




21.



















22,23
Императи́вное программи́рование — это парадигма программирования, которая, в отличие от декларативного программирования, описывает процесс вычисления в виде инструкций, изменяющих состояние программы. Императивная программа очень похожа на приказы, выражаемые повелительным наклонением в естественных языках, то есть это последовательность команд, которые должен выполнить компьютер.
Императивные языки программирования противопоставляются функциональным и логическим языкам программирования. Функциональные языки, например, Haskell, не представляют собой последовательность инструкций и не имеют глобального состояния. Логические языки программирования, такие как Prolog, обычно определяют что надо вычислить, а не как это надо делать.
Декларативное программирование — термин с двумя различными значениями.
Согласно первому определению, программа «декларативна», если она описывает каково́ нечто, а не как его создать. Например, веб-страницы на HTML декларативны, так как они описывают что должна содержать страница, а не как отображать страницу на экране. Этот подход отличается от языков императивного программирования, требующих от программиста указывать алгоритм для исполнения. В типично декларативном языке программирования XSLT, последовательность исполнения зависит, как правило, от входящего XML (в случае с использованием push-модели — «проталкивание»), в случае использования pull-модели (вытягивания), XSLT вырождается в частный случай функционального программирования и легко может быть заменена на аналогичный код в XQuery.
Согласно второму определению, программа «декларативна», если она написана на исключительно функциональном, логическомили языке программирования с ограничениями. Выражение «декларативный язык» иногда употребляется для описания всех таких языков программирования как группы, чтобы подчеркнуть их отличие от императивных языков.
Программы на языках декларативного программирования легко поддаются методикам метапрограммирования — когда программа может генерироваться по её описанию. Например XSLT-программа может быть сгенерирована из файла XML (часто с помощью другой XSLT) — см. Schematron.
|
Это [декларативное] программирование подразумевает использование данных, а не написание кода для того, чтобы заставить приложение или компонент выполнить что-либо. Написание исходного кода иногда называютимперативным программированием. [...] Очевидно, со временем декларативное программирование получит еще большее распространение. Примеры подобных технологий уже сейчас можно увидеть в Microsoft ASP.NET иMicrosoft Windows Communication Foundation. Даже в Microsoft Windows Presentation Foundation программисты могут разрабатывать пользовательский интерфейс, объявляя (декларируя) его разметку и поведение, используя язык разметки XAML." Джеффри Рихтер[1] |
|
Объе́ктно-ориенти́рованное, или объектное, программи́рование (в дальнейшем ООП) — парадигма программирования, в которой основными концепциями являются понятия объектов и классов. В случае языков с прототипированием вместо классов используются объекты-прототипы.
Абстракция
Абстрагирование — это способ выделить набор значимых характеристик объекта, исключая из рассмотрения незначимые. Соответственно, абстракция — это набор всех таких характеристик.[1]
Инкапсуляция
Инкапсуляция — это свойство системы, позволяющее объединить данные и методы, работающие с ними в классе, и скрыть детали реализации от пользователя.[1]
Наследование
Наследование — это свойство системы, позволяющее описать новый класс на основе уже существующего с частично или полностью заимствующейся функциональностью. Класс, от которого производится наследование, называется базовым, родительским или суперклассом. Новый класс — потомком, наследником или производным классом.[1]
Полиморфизм
Полиморфизм — это свойство системы использовать объекты с одинаковым интерфейсом без информации о типе и внутренней структуре объекта.[1]
Класс
Класс является описываемой на языке терминологии (пространства имён) исходного кода моделью ещё не существующей сущности (объекта). Фактически он описывает устройство объекта, являясь своего рода чертежом. Говорят, что объект — это экземпляр класса. При этом в некоторых исполняющих системах класс также может представляться некоторым объектом при выполнении программы посредством динамической идентификации типа данных. Обычно классы разрабатывают таким образом, чтобы их объекты соответствовали объектам предметной области.
Объект
Сущность в адресном пространстве вычислительной системы, появляющаяся при создании экземпляра класса или копирования прототипа (например, после запуска результатов компиляции и связывания исходного кода на выполнение).
Прототип
Прототип — это объект-образец, по образу и подобию которого создаются другие объекты. Объекты-копии могут сохранять связь с родительским объектом, автоматически наследуя изменения в прототипе; эта особенность определяется в рамках конкретного языка.
[править]Определение ООП и его основные концепции
В центре ООП находится понятие объекта. Объект — это сущность, которой можно посылать сообщения, и которая может на них реагировать, используя свои данные. Объект — это экземпляр класса. Данные объекта скрыты от остальной программы. Сокрытие данных называется инкапсуляцией.
Наличие инкапсуляции достаточно для объектности языка программирования, но ещё не означает его объектной ориентированности — для этого требуется наличиенаследования.
Но даже наличие инкапсуляции и наследования не делает язык программирования в полной мере объектным с точки зрения ООП. Основные преимущества ООП проявляются только в том случае, когда в языке программирования реализован полиморфизм; то есть возможность объектов с одинаковой спецификацией иметь различную реализацию.
По мнению Алана Кея, создателя языка Smalltalk, которого считают одним из «отцов-основателей» ООП, объектно-ориентированный подход заключается в следующем наборе основных принципов (цитируется по вышеупомянутой книге Т. Бадда).
Всё является объектом.
Вычисления осуществляются путём взаимодействия (обмена данными) между объектами, при котором один объект требует, чтобы другой объект выполнил некоторое действие. Объекты взаимодействуют, посылая и получая сообщения. Сообщение — это запрос на выполнение действия, дополненный набором аргументов, которые могут понадобиться при выполнении действия.
Каждый объект имеет независимую память, которая состоит из других объектов.
Каждый объект является представителем класса, который выражает общие свойства объектов (таких, как целые числа или списки).
В классе задаётся поведение (функциональность) объекта. Тем самым все объекты, которые являются экземплярами одного класса, могут выполнять одни и те же действия.
Классы организованы в единую древовидную структуру с общим корнем, называемую иерархией наследования. Память и поведение, связанное с экземплярами определённого класса, автоматически доступны любому классу, расположенному ниже в иерархическом дереве.
Функциона́льное программи́рование — раздел дискретной математики и парадигма программирования, в которой процессвычисления трактуется как вычисление значений функций в математическом понимании последних (в отличие от функций как подпрограмм в процедурном программировании).
Противопоставляется парадигме императивного программирования, которая описывает процесс вычислений как последовательное изменение состояний (в значении, подобном таковому в теории автоматов). При необходимости, в функциональном программировании вся совокупность последовательных состояний вычислительного процесса представляется явным образом, например как список.
Функциональное программирование предполагает обходиться вычислением результатов функций от исходных данных и результатов других функций, и не предполагает явного хранения состояния программы. Соответственно, не предполагает оно и изменяемость этого состояния (в отличие от императивного, где одной из базовых концепций является переменная, хранящая своё значение и позволяющая менять его по мере выполнения алгоритма).
На практике отличие математической функции от понятия «функции» в императивном программировании заключается в том, что императивные функции могут опираться не только на аргументы, но и на состояние внешних по отношению к функции переменных, а также иметь побочные эффекты и менять состояние внешних переменных. Таким образом, в императивном программировании при вызове одной и той же функции с одинаковыми параметрами, но на разных этапах выполнения алгоритма, можно получить разные данные на выходе из-за влияния на функцию состояния переменных. А в функциональном языке при вызове функции с одними и теми же аргументами мы всегда получим одинаковый результат: выходные данные зависят только от входных. Это позволяет средам выполнения программ на функциональных языках кешировать результаты функций и вызывать их в порядке, не определяемом алгоритмом и распараллеливать их без каких-либо дополнительных действий со стороны программиста (см.ниже Чистые функции)
λ-исчисления являются основой для функционального программирования, многие функциональные языки можно рассматривать как «надстройку» над ними[1].
Ля́мбда-исчисле́ние (λ-исчисление) — формальная система, разработанная американским математиком Алонзо Чёрчем, для формализации и анализа понятиявычислимости.
λ-исчисление может рассматриваться как семейство прототипных языков программирования. Их основная особенность состоит в том, что они являются языками высших порядков. Тем самым обеспечивается систематический подход к исследованию операторов, аргументами которых могут быть другие операторы, а значением также может быть оператор. Языки в этом семействе являются функциональными, поскольку они основаны на представлении о функции или операторе, включая функциональную аппликацию и функциональную абстракцию. λ-исчисление реализовано Джоном Маккарти в языке Лисп. Вначале реализация идеи λ-исчисления была весьма громоздкой. Но по мере развития Лисп-технологии (прошедшей этап аппаратной реализации в виде Лисп-машины) идеи получили ясную и четкую реализацию.
Аппликация и абстракция
В основу λ-исчисления положены две фундаментальные операции:
Аппликация (лат. application —
прикладывание, присоединение) означает
применение или вызов функции по отношению
к заданному значению. Её обычно
обозначают![]() ,
где
,
где ![]() —
функция, а
—
функция, а ![]() —
аргумент. Это соответствует общепринятой
в математике записи
—
аргумент. Это соответствует общепринятой
в математике записи ![]() ,
которая тоже иногда используется, однако
для λ-исчисления важно то, что
трактуется
как алгоритм,
вычисляющий результат по заданному
входному значению. В этом смысле
аппликация
к
может
рассматриваться двояко: как результат
применения
к
,
или же как процесс вычисления
.
Последняя интерпретация аппликации
связана с понятием β-редукции.
,
которая тоже иногда используется, однако
для λ-исчисления важно то, что
трактуется
как алгоритм,
вычисляющий результат по заданному
входному значению. В этом смысле
аппликация
к
может
рассматриваться двояко: как результат
применения
к
,
или же как процесс вычисления
.
Последняя интерпретация аппликации
связана с понятием β-редукции.
Абстракция или λ-абстракция (лат. abstraction —
отвлечение, отделение) в свою очередь
строит функции по заданным выражениям.
Именно, если ![]() —
выражение, свободно содержащее
—
выражение, свободно содержащее ![]() ,
тогда запись
,
тогда запись ![]() означает:
означает: ![]() функция
от аргумента
,
которая имеет вид
функция
от аргумента
,
которая имеет вид ![]() ,
обозначает функцию
,
обозначает функцию ![]() .
Таким образом, с помощью абстракции можно
конструировать новые функции. Требование,
чтобы
свободно
входило в
.
Таким образом, с помощью абстракции можно
конструировать новые функции. Требование,
чтобы
свободно
входило в ![]() ,
не очень существенно — достаточно
предположить, что
,
не очень существенно — достаточно
предположить, что ![]() ,
если это не так.
,
если это не так.
Пролог (фр. Programmation en Logique) — язык и система логического программирования, основанные на языке предикатовматематической логики дизъюнктов Хорна, представляющей собой подмножество логики предикатов первого порядка.
Основными понятиями в языке Пролог являются факты, правила логического вывода и запросы, позволяющие описыватьбазы знаний, процедуры логического вывода и принятия решений.
Факты в языке Пролог описываются логическими предикатами с конкретными значениями. Правила в Прологе записываются в форме правил логического вывода с логическими заключениями и списком логических условий.
Особую роль в интерпретаторе Пролога играют конкретные запросы к базам знаний, на которые система логического программирования генерирует ответы «истина» и «ложь». Для обобщённых запросов с переменными в качестве аргументов созданная система Пролог выводит конкретные данные в подтверждение истинности обобщённых сведений и правил вывода.
Факты в базах знаний на языке Пролог представляют конкретные сведения (знания). Обобщённые сведения и знания в языке Пролог задаются правилами логического вывода (определениями) и наборами таких правил вывода (определений) над конкретными фактами и обобщёнными сведениями.
Начало истории языка относится к 1970-м годам.[1] Будучи декларативным языком программирования, Пролог воспринимает в качестве программы некоторое описание задачи или баз знаний и сам производит логический вывод, а также поиск решения задач, пользуясь механизмом поиска с возвратом и унификацией.
Понятия
В языке существует 2 понятия предикаты (условия) и объекты (они же переменные и термы). Предикаты выражают некоторое условие, например объект зеленый или число простое, естественно что условия имеют входные параметры. Например green_object(Object), prime_number(Number) . Сколько в предикате параметров, такова и арность предиката. Объектами — являются термы, константы и переменные. Константы — это числа и строки,переменные — выражают неизвестный объект, возможно искомый, и обозначаются как строчки с большой буквы. Оставим пока термы и рассмотрим простейшую программу.
Программа
Программа — это набор правил, вида Если условие1 и условие2 и… то верно условие. Формально эти правила объединяются через И, но противоречие получить невозможно, так как в Прологе отсутствует логическое отрицание, а в связке То может присутствовать только один предикат (условие). A :- B_1, B_2. % правило читается как : Если B_1 и B_2, то A нечетное_простое(Число) :- простое(Число), нечетное(Число). % Если "Число" - простое и нечетное, то "Число" - нечетное_простое Как видно имя переменной имеет область видимости — это правило. Математически верно, правило звучит: для любой переменной — «Число», если оно простое и нечетное, то оно простое_нечетное. Аналогично, можно перефразировать так: Если существует «Число», что оно нечетное и простое, то оно нечетно_простое. Поэтому имя переменной очень важно! Если в левой части (до :- ) заменить Число на Число2, то правило поменяет смысл: Для любого Число2 и Число, если Число — простое и нечетное, то Число2 — простое нечетное. Получается все числа простые_нечетные! Это самая распространенная ошибка в Прологе.
24.
1.3.1. Структура программного обеспечения ПК
Программное обеспечение
Совокупность программ, предназначенная для решения задач на ПК, называется программным обеспечением. Состав программного обеспечения ПК называют программной конфигурацией.
Программное обеспечение, можно условно разделить на три категории:
системное ПО (программы общего пользования), выполняющие различные вспомогательные функции, например создание копий используемой информации, выдачу справочной информации о компьютере, проверку работоспособности устройств компьютера и т.д.
прикладное ПО, обеспечивающее выполнение необходимых работ на ПК: редактирование текстовых документов, создание рисунков или картинок, обработка информационных массивов и т.д.
инструментальное ПО (системы программирования), обеспечивающее разработку новых программ для компьютера на языке программирования.

Системное ПО
Это программы общего пользования не связаны с конкретным применением ПК и выполняют традиционные функции: планирование и управление задачами, управления вводом-выводом и т.д.
Другими словами, системные программы выполняют различные вспомогательные функции, например, создание копий используемой информации, выдачу справочной информации о компьютере, проверку работоспособности устройств компьютера и т.п. К системному ПО относятся:
операционные системы (эта программа загружается в ОЗУ при включении компьютера)
программы – оболочки (обеспечивают более удобный и наглядный способ общения с компьютером, чем с помощью командной строки DOS, например, Norton Commander)
операционные оболочки – интерфейсные системы, которые используются для создания графических интерфейсов, мультипрограммирования и.т.
Драйверы (программы, предназначенные для управления портами периферийных устройств, обычно загружаются в оперативную память при запуске компьютера)
утилиты (вспомогательные или служебные программы, которые представляют пользователю ряд дополнительных услуг) К утилитам относятся:
диспетчеры файлов или файловые менеджеры
средства динамического сжатия данных (позволяют увеличить количество информации на диске за счет ее динамического сжатия)
средства просмотра и воспроизведения
средства диагностики; средства контроля позволяют проверить конфигурацию компьютера и проверить работоспособность устройств компьютера, прежде всего жестких дисков
средства коммуникаций (коммуникационные программы) предназначены для организации обмена информацией между компьютерами
средства обеспечения компьютерной безопасности (резервное копирование, антивирусное ПО).
Необходимо отметить, что часть утилит входит в состав операционной системы, а другая часть функционирует автономно. Большая часть общего (системного) ПО входит в состав ОС. Часть общего ПО входит в состав самого компьютера (часть программ ОС и контролирующих тестов записана в ПЗУ или ППЗУ, установленных на системной плате). Часть общего ПО относится к автономными программам и поставляется отдельно.
Прикладное ПО
Прикладные программы могут использоваться автономно или в составе программных комплексов или пакетов. Прикладное ПО – программы, непосредственно обеспечивающие выполнение необходимых работ на ПК: редактирование текстовых документов, создание рисунков или картинок, создание электронных таблиц и т.д. Пакеты прикладных программ – это система программ, которые по сфере применения делятся на проблемно – ориентированные, пакеты общего назначения и интегрированные пакеты. Современные интегрированные пакеты содержат до пяти функциональных компонентов: тестовый и табличный процессор, СУБД, графический редактор, телекоммуникационные средства. К прикладному ПО, например, относятся:
Комплект офисных приложений MS OFFICE
Бухгалтерские системы
Финансовые аналитические системы
Интегрированные пакеты делопроизводства
CAD – системы (системы автоматизированного проектирования)
Редакторы HTML или Web – редакторы
Браузеры – средства просмотра Web - страниц
Графические редакторы
Экспертные системы И так далее.
Инструментальное ПО
Инструментальное ПО или системы программирования - это системы для автоматизации разработки новых программ на языке программирования. В самом общем случае для создания программы на выбранном языке программирования (языке системного программирования) нужно иметь следующие компоненты: 1. Текстовый редактор для создания файла с исходным текстом программы. 2. Компилятор или интерпретатор. Исходный текст с помощью программы-компилятора переводится в промежуточный объектный код. Исходный текст большой программы состоит из нескольких модулей(файлов с исходными текстами). Каждый модуль компилируется в отдельный файл с объектным кодом, которые затем надо объединить в одно целое. 3. Редактор связей или сборщик, который выполняет связывание объектных модулей и формирует на выходе работоспособное приложение – исполнимый код. Исполнимый код – это законченная программа, которую можно запустить на любом компьютере, где установлена операционная система, для которой эта программа создавалась. Как правило, итоговый файл имеет расширение .ЕХЕ или .СОМ. 4. В последнее время получили распространение визуальный методы программирования (с помощью языков описания сценариев), ориентированные на создание Windows-приложений. Этот процесс автоматизирован в средах быстрого проектирования. При этом используются готовые визуальные компоненты, которые настраиваются с помощью специальных редакторов.
Операцио́нная систе́ма, сокр. ОС (англ. operating system, OS) — комплекс управляющих и обрабатывающих программ, которые, с одной стороны, выступают какинтерфейс между устройствами вычислительной системы и прикладными программами, а с другой стороны — предназначены для управления устройствами, управлениявычислительными процессами, эффективного распределения вычислительных ресурсов между вычислительными процессами и организации надёжных вычислений. Это определение применимо к большинству современных операционных систем общего назначения.
Ядро — центральная часть операционной системы, управляющая выполнением процессов, ресурсами вычислительной системы и предоставляющая процессам координированный доступ к этим ресурсам. Основными ресурсами являются процессорное время, память и устройства ввода-вывода. Доступ к файловой системе и сетевое взаимодействие также могут быть реализованы на уровне ядра.
Как основополагающий элемент операционной системы, ядро представляет собой наиболее низкий уровень абстракции для доступа приложений к ресурсам вычислительной системы, необходимым для их работы. Как правило, ядро предоставляет такой доступ исполняемым процессам соответствующих приложений за счёт использования механизмов межпроцессного взаимодействия и обращения приложений к системным вызовам ОС.
Описанная задача может различаться в зависимости от типа архитектуры ядра и способа её реализации.
Объекты ядра ОС:
Процессы
Файлы
События
Потоки
Семафоры
Мьютексы
Каналы
Файлы, проецируемые в память
ПОНЯТИЕ ОПЕРАЦИОННОЙ СРЕДЫ
Операционная система выполняет функции управления вычислительными процессами в вычислительной системе, распределяет ресурсы вычислительной системы между различными вычислительными процессами и образует программную среду, в которой выполняются прикладные программы пользователя. Такая среда называется операционной.
Любая программа имеет дело с некоторыми исходными данными, которые она обрабатывает и порождает некоторые выходные данные, т.е. результаты вычислений. В абсолютном большинстве случаев исходные данные попадают в оперативную память внешних (периферийных) устройств.
Результаты вычислений также выводятся на внешние устройства. Программирование операций ввода/вывода является наиболее сложной задачей. Именно поэтому развитие операционной системы пошло по пути выделения наиболее часто встречающихся операций и создании для них соответствующих модулей, которые можно в дальнейшем использовать во вновь создаваемых программах. //В конечном итоге возникла ситуация, когда при создании двоичных машинных программ …//
Программисты могут вообще не знать многих деталей управления ресурсами вычислительной системы, а должны обращаться к некоторой программной подсистеме с соответствующими выводами и получить необходимые функции сервиса. Эта программная подсистема и есть операционная система, а набор её функций сервиса и привело обращение к ней и образует базовое понятие, которое называется операционной средой, т.е. термин операционная среда означает необходимые интерфейсные программы пользователя для обращения к операционной системе с целью получить определённый сервис. Параллельное существование терминов “операционная система” и “операционная среда” вызвано тем, что операционная система может поддержать несколько операционных сред. Например, операционная система OS/2 Warp может выполнять следующие программы:
1) так называемые нативные (Native) программы, созданные с учётом 32-разрядного операционного интерфейса;
2) 16-битные программы, созданные для OS/2 первого поколения;
3) 16-битные программы, разработанные для MS-DOS PS и DOS.
4) 16-битовые программы для операционной среды Windows.
5) Сама операционная оболочка Windows 3.X и уже в ней, созданные для неё, программы.
Понятия вычислительного
процесса и ресурса
Понятие
«вычислительный процесс» (или просто
— «процесс») является одним из основных
при рассмотрении операционных систем.
Последовательный процесс (иногда
называемый «задачей») — это выполнение
отдельной программы с ее данными на
последовательном процессоре. В концепции,
которая получила распространение в
70-е годы, задача – это совокупность
связанных между собой и образующих
единое целое программных модулей и
данных, требующая ресурсов вычислительной
системы. В последующие годы задачей
стали называть единицу работы, для
выполнения которой предоставляется
центральный процессор. Процесс может
включать в себя несколько задач. В
качестве примеров можно назвать следующие
процессы (задачи): выполнение прикладных
программ пользователей, утилит и других
системных обрабатывающих программ.
Процессами могут быть редактирование
какого-либо текста, трансляция исходной
программы, ее компоновка, исполнение.
Причем трансляция какой-нибудь
исходной программы является одним
процессом, а трансляция следующей
исходной программы — другим процессом,
поскольку, хотя транслятор как объединение
программных модулей здесь выступает
как одна и та же программа, но данные,
которые он обрабатывает, являются
разными.
Определение
концепции процесса преследует цель
выработать механизмы распределения
и управления ресурсами. Понятие ресурса,
так же как и понятие процесса,
является,
пожалуй, основным при рассмотрении
операционных систем. Термин ресурс
обычно применяется по отношению к
повторно используемым, относительно
стабильным и часто недостающим объектам,
которые запрашиваются, используются
и освобождаются процессами в период их
активности. Другими словами, ресурсом
называется всякий объект, который может
распределяться внутри системы.
Ресурсы
могут быть разделяемыми, когда несколько
процессов могут их использовать
одновременно (в один и тот же момент
времени) или параллельно (в течение
некоторого интервала времени процессы
используют ресурс попеременно), а
могут быть и неделимыми (рис. 1.1).

Многопото́чность — свойство платформы (например, операционной системы, виртуальной машины и т. д.) или приложения, состоящее в том, что процесс, порождённый в операционной системе, может состоять из нескольких потоков, выполняющихся «параллельно», то есть без предписанного порядка во времени. При выполнении некоторых задач такое разделение может достичь более эффективного использования ресурсов вычислительной машины.
Такие потоки называют также потоками выполнения (от англ. thread of execution); иногда называют «нитями» (буквальный перевод англ. thread) или неформально «тредами».
Сутью многопоточности является квазимногозадачность на уровне одного исполняемого процесса, то есть все потоки выполняются в адресном пространстве процесса. Кроме этого, все потоки процесса имеют не только общее адресное пространство, но и общие дескрипторы файлов. Выполняющийся процесс имеет как минимум один (главный) поток.
Многопоточность (как доктрину программирования) не следует путать ни с многозадачностью, ни с многопроцессорностью, несмотря на то, что операционные системы, реализующие многозадачность, как правило реализуют и многопоточность.
К достоинствам многопоточности в программировании можно отнести следующее:
Упрощение программы в некоторых случаях за счет использования общего адресного пространства.
Меньшие относительно процесса временны́е затраты на создание потока.
Повышение производительности процесса за счет распараллеливания процессорных вычислений и операций ввода/вывода.
Планирование и диспетчеризация процессов и задач
Когда говорят о диспетчеризации, то всегда в явном или неявном виде подразумевают понятие задачи (потока выполнения). Если операционная система не поддерживает механизм потоковых вычислений, то можно заменять понятие задачи понятием процесса. Ко всему прочему, часто понятие задачи используется в таком контексте, что для его трактовки приходится использовать термин «процесс».
Очевидно, что на распределение ресурсов влияют конкретные потребности тех задач, которые должны выполняться параллельно. Другими словами, можно столкнуться с ситуациями, когда невозможно эффективно распределять ресурсы с тем, чтобы они не простаивали. Например, пусть всем выполняющимся процессам требуется некоторое устройство с последовательным доступом. Но поскольку, как мы уже знаем, оно не может разделяться между параллельно выполняющимися процессами, то процессы вынуждены будут очень долго ждать своей очереди, то есть недоступность одного ресурса может привести к тому, что длительное время не будут использоваться многие другие ресурсы.
Если же мы возьмем такой набор процессов, что они не будут конкурировать между собой за неразделяемые ресурсы при своем параллельном выполнении, то, скорее всего, процессы смогут выполниться быстрее (из-за отсутствия дополнительных ожиданий), да и имеющиеся в системе ресурсы, скорее всего, будут использоваться более эффективно. Таким образом, возникает задача подбора такого множества процессов, которые при своем выполнении будут как можно реже конфликтовать за имеющиеся в системе ресурсы. Такая задача называется планированием вычислительных процессов.
Задача планирования процессов возникла очень давно — в первых пакетных операционных системах при планировании пакетов задач, которые должны были выполняться на компьютере и по возможности бесконфликтно и оптимально использовать его ресурсы. В настоящее время актуальность этой задачи стала меньше. На первый план уже очень давно вышли задачи динамического (или краткосрочного) планирования, то есть текущего наиболее эффективного распределения ресурсов, возникающего практически по каждому событию. Задачи динамического планирования стали называть диспетчеризацией1.Очевидно, что планирование процессов осуществляется гораздо реже, чем текущее распределение ресурсов между уже выполняющимися задачами. Основное различие между долгосрочным и краткосрочным планировщиками заключается в частоте их запуска, например: краткосрочный планировщик может запускаться каждые 30 или 100 мс, долгосрочный — один раз в несколько минут (или чаще; тут многое зависит от общей длительности решения заданий пользователей).
Долгосрочный планировщик решает, какой из процессов, находящихся во входной очереди, в случае освобождения ресурсов памяти должен быть переведен в очередь процессов, готовых к выполнению. Долгосрочный планировщик выбирает процесс из входной очереди с целью создания неоднородной мультипрограммной смеси. Это означает, что в очереди готовых к выполнению процессов должны находиться в разной пропорции как процессы, ориентированные на ввод-вывод, так и процессы, ориентированные преимущественно на активное использование центрального процессора.
Краткосрочный планировщик решает, какая из задач, находящихся в очереди готовых к выполнению, должна быть передана на исполнение. В большинстве современных операционных систем, с которыми мы сталкиваемся, долгосрочный планировщик отсутствует.
Планирование вычислительных процессов и стратегии планирования
Прежде всего, следует отметить, что при рассмотрении стратегий планирования, как правило, идет речь о краткосрочном планировании, то есть о диспетчеризации. Долгосрочное планирование, как мы уже отметили, заключается в подборе таких вычислительных процессов, которые бы меньше всего конкурировали между собой за ресурсы вычислительной системы. Иногда используется термин стратегия обслуживания.
Стратегия планирования определяет, какие процессы мы планируем на выполнение для того, чтобы достичь поставленной цели. Известно большое количество различных стратегий выбора процесса, которому необходимо предоставить процессор. Среди них, прежде всего, можно выбрать следующие:
по возможности заканчивать вычисления (вычислительные процессы) в том же самом порядке, в котором они были начаты;
отдавать предпочтение более коротким вычислительным задачам;
предоставлять всем пользователям (процессам пользователей) одинаковые услуги, в том числе и одинаковое время ожидания.
Когда говорят о стратегии обслуживания, всегда имеют в виду понятие процесса, а не понятие задачи, поскольку процесс, как мы уже знаем, может состоять из нескольких потоков выполнения (задач).
На сегодняшний день абсолютное большинство компьютеров — это персональные IBM-совместимые компьютеры, работающие на платформах Windows компании Microsoft. Это однопользовательские диалоговые мультипрограммные и мультизадачные системы. При создании операционных систем для персональных компьютеров разработчики, прежде всего, стараются обеспечить комфортную работу с системой, то есть основные усилия уходят на проработку пользовательского интерфейса. Что касается эффективности организации вычислений, то она, видимо, тоже должна оцениваться с этих позиций. Если же считать системыWindows операционными системами общего назначения, что тоже возможно, ибо эти системы повсеместно используют для решения самых разнообразных задач автоматизации, то также следует признать, что принятые в системах Windows стратегии обслуживания приводят к достаточно высокой эффективности вычислений. Некоторым даже удается использовать системы Windows NT/2000 для решения задач реального времени. Однако выбор этих операционных систем для таких задач скорее всего делается либо вследствие некомпетентности, либо из-за невысоких требований ко времени отклика и гарантиям обслуживания со стороны самих систем реального времени, которые реализуются на Windows NT/2000.
Прежде всего, система, ориентированная на однопользовательский режим, должна обеспечить хорошую реакцию системы на запросы от того приложения, с которым сейчас пользователь работает. Мало пользователей, которые могут параллельно работать с большим числом приложений. Поэтому по умолчанию для задачи, с которой пользователь непосредственно работает и которую называют задачей переднего плана (foreground task), система устанавливает более высокий уровень приоритета. В результате процессорное время прежде всего предоставляется текущей задаче пользователя, и он не будет испытывать лишний раз дискомфорт из-за медленной реакции системы на его запросы. Для обеспечения надлежащей работы коммуникационных процессов и для возможности выполнять системные функции приоритет задач пользователя должен быть ниже, чем у тех задач, которые реализуют операции ввода-вывода и иные управляющие функции.
Например, в Windows 2000 можно открыть окно Свойства системы, перейти на вкладку Дополнительно, щелчком на кнопке Параметры быстродействия открыть одноименное окно и с помощью переключателя в разделе Отклик приложений установить режим Оптимизировать быстродействие приложений. Это будет соответствовать выбору такой стратегии диспетчеризации задач, в соответствии с которой приоритет на получение процессорного времени будут иметь задачи пользователя, а не фоновые служебные вычисления. В предыдущей версии ОС — Windows NT 4.0 — для выбора нужной ему стратегии пользователь должен был на вкладке Быстродействие окна Свойства системы установить желаемое значение в поле Ускорение приложения переднего плана. Это ускорение можно сделать максимальным (по умолчанию), а можно его свести к нулю. Последний вариант означал бы, что все запущенные пользователем приложения будут иметь одинаковый приоритет. Последнее важно, если пользователь часто запускает сразу по нескольку задач, каждая из которых требует длительных вычислений, причем эти приложения часто используют операции ввода-вывода. Например, если нужно обработать несколько десятков музыкальных или графических файлов, причем каждый файл имеет большие размеры, то выполнение всей этой работы как множества параллельно исполняющихся задач будет завершено за меньшее время, если указать стратегию равенства обслуживания. Должно быть очевидным, что любой другой вариант решения этой задачи потребует больше времени. Например, последовательное выполнение задач обработки каждого файла (то есть обработка следующего файла может начинаться только по окончании обработки предыдущего) приведет к самому длительному варианту. Стратегия предоставления процессорного времени в первую очередь текущей задаче пользователя, которая установлена в системах Windows по умолчанию, приведет нас к промежуточному (по затратам времени) результату.
Очевидно, что в идеале в очереди готовых к выполнению задач должны находиться в разной пропорции как задачи, ориентированные на ввод-вывод, так и задачи, ориентированные преимущественно на работу с центральным процессором. Практически все операционные системы стараются учесть это требование, однако не всегда оно выполняется настолько удачно, что пользователь получает превосходное время реакции системы на свои запросы и при этом видит, что его ресурсоемкие приложения выполняются достаточно быстро
25.
Виртуальное адресное пространство
Виртуальное адресное пространство - это системе адресации , используемая в современных операционных системах - в частности - при работе операционной системы с процессами (/потоками). ] Такая система удобна по различным причинам - в том числе и потому, что позволяет изолировать "рабочие пространства" процессов друг от друга . Очередной адрес, создаваемый процессом для идентификации области памяти, а которой процесс хранит некоторые данные называется логическим (виртуальным) адресом и относится именно к виртуальному адресному пространству.
Каждый раз, когда программа запускается внутри операционной системы - операционная система (ОС) создаёт хотя бы один новый процесс и новое виртуальное адресное пространство (ВАП) для него.
Виртуальное адресное пространство зависит от:
архитектуры процессора;
операционной системы (которая может накладывать дополнительные ограничения)
Виртуальное адресное пространство не зависит от:
- объема реальной физической(оперативной) памяти, установленной в компьютере.
- объема жёсткого диска
Адреса команд и переменных в готовой машинной программе, подготовленной к выполнению системой программирования, как раз и являются виртуальными адресами.
Прилагательное «виртуальное» применительно к адресному пространству означает, что это общее число доступных приложению уникально адресуемых ячеек памяти, но не общий объём памяти, установленной в компьютере, или выделенной в конкретный момент времени данному приложению - в том числе - адреса в виртуальном пространстве не обязательно постоянно соответствуют одним и тем же адресам реальной физической памяти. Например - когда физической (оперативной) памяти не хватает, диспетчер памяти выгружает часть содержимого памяти на диск. При обращении потока по виртуальному адресу, соответствующему переписанным на диск данным, диспетчер памяти снова загружает эти данные с диска в память.
Виртуальное адресное пространство процесса.
Виртуальное адресное пространство процесса - это фактически всего лишь диапазон адресов, который может данный процесс использовать.
Сегментный способ организации виртуальной памяти
Первым среди разрывных методов распределения памяти был сегментный. Для этого метода программу необходимо разбивать на части и уже каждой такой части выделять физическую память. Естественным способом разбиения программы на части является разбиение её на логические элементы - так называемые сегменты. В принципе каждый программный модуль (или их совокупность, если мы того пожелаем) может быть воспринят как отдельный сегмент, и вся программа тогда будет представлять собой множество сегментов. Каждый сегмент размещается в памяти как до определенной степени самостоятельная единица. Логически обращение к элементам программы в этом случае будет представляться как указание имени сегмента и смещения относительно начала этого сегмента. Физически имя (или порядковый номер) сегмента будет соответствовать

некоторому адресу, с которого этот сегмент начинается при его размещении в памяти, и смещение должно прибавляться к этому базовому адресу.
Преобразование имени сегмента в его порядковый номер осуществит система программирования, а операционная система будет размещать сегменты в память и для каждого сегмента получит информацию о его начале. Таким образом, виртуальный адрес для этого способа будет состоять из двух полей - номер сегмента и смещение относительно начала сегмента. Соответствующая иллюстрация приведена на рис.2.7. На этом рисунке изображен случай обращения к ячейке, виртуальный адрес которой равен сегменту с номером 11 и смещением от начала этого сегмента, равным 612. Как мы видим, операционная система разместила данный сегмент в памяти, начиная с ячейки с номером 19 700.
Каждый сегмент, размещаемый в памяти, имеет соответствующую информационную структуру, часто называемую дескриптором сегмента. Именно операционная система строит для каждого исполняемого процесса соответствующую таблицу дескрипторов сегментов и при размещении каждого из сегментов в оперативной или внешней памяти в дескрипторе отмечает его текущее местоположение.
Если сегмент задачи в данный момент находится в оперативной памяти, то об этом делается пометка в дескрипторе. Как правило, для этого используется «бит присутствия» (present). В этом случае в поле «адрес» диспетчер памяти записывает адрес физической памяти, с которого сегмент начинается, а в поле «длина сегмента» (limit) указывается количество адресуемых ячеек памяти. Это поле используется не только для того, чтобы размещать сегменты без наложения один на другой, но и для того, чтобы проконтролировать, не обращается ли код исполняющейся задачи за пределы текущего сегмента. В случае превышения длины сегмента вследствие ошибок программирования мы можем говорить о нарушении адресации и с помощью введения специальных аппаратных средств генерировать сигналы прерывания, которые позволят фиксировать (обнаруживать) такого рода ошибки.
Если бит present в дескрипторе указывает, что сейчас этот сегмент находится не в оперативной, а во внешней памяти (например, на винчестере), то названные поля адреса и длины используются для указания адреса сегмента в координатах внешней памяти. Помимо информации о местоположении сегмента, в дескрипторе сегмента, как правило, содержатся данные о его типе (сегмент кода или сегмент данных), правах доступа к этому сегменту (можно или нельзя его модифицировать, предоставлять другой задаче), отметка об обращениях к данному сегменту (информация о том, как часто или как давно/недавно этот сегмент используется или не используется, на основании которой можно принять решение о том, чтобы предоставить место, занимаемое текущим сегментом, другому сегменту).
При передаче управления следующей задаче ОС должна занести в соответствующий регистр адрес таблицы дескрипторов сегментов этой задачи. Сама таблица дескрипторов сегментов, в свою очередь, также представляет собой сегмент данных, который обрабатывается диспетчером памяти операционной системы.
При таком подходе появляется возможность размещать в оперативной памяти не все сегменты задачи, а только те, с которыми в настоящий момент происходит работа. С одной стороны, становится возможным, чтобы общий объём виртуального адресного пространства задачи превосходил объём физической памяти компьютера, на котором эта задача будет выполняться. С другой стороны, даже если потребности в памяти не превосходят имеющуюся физическую память, появляется возможность размещать в памяти как можно больше задач. А увеличение коэффициента мультипрограммирования ji, как мы знаем, позволяет увеличить загрузку системы и более эффективно использовать ресурсы вычислительной системы. Очевидно, однако, что увеличивать количество задач можно только до определенного предела, ибо если в памяти не будет хватать места для часто используемых сегментов, то производительность системы резко упадет. Ведь сегмент, который сейчас находится вне оперативной памяти, для участия в вычислениях должен быть перемещен в оперативную память. При этом если в памяти есть свободное пространство, то необходимо всего лишь найти его во внешней памяти и загрузить в оперативную память. А если свободного места сейчас нет, то необходимо будет принять решение - на место какого из ныне присутствующих сегментов будет загружаться требуемый.
Итак, если требуемого сегмента в оперативной памяти нет, то возникает прерывание и управление передаётся через диспетчер памяти программе загрузки сегмента. Пока происходит поиск сегмента во внешней памяти и загрузка его в оперативную, диспетчер памяти определяет подходящее для сегмента место. Возможно, что свободного места нет, и тогда принимается решение о выгрузке какого-нибудь сегмента и его перемещение во внешнюю память. Если при этом ещё остается время, то процессор передаётся другой готовой к выполнению задаче. После загрузки необходимого сегмента процессор вновь передаётся задаче, вызвавшей прерывание из-за отсутствия сегмента. Всякий раз при считывании сегмента в оперативную память в таблице дескрипторов сегментов необходимо установить адрес начала сегмента и признак присутствия сегмента.
При поиске свободного места используется одна из вышеперечисленных дисциплин работы диспетчера памяти (применяются правила «первого подходящего» и «самого неподходящего» фрагментов). Если свободного фрагмента памяти достаточного объёма сейчас нет, но тем не менее сумма этих свободных фрагментов превышает требования по памяти для нового сегмента, то в принципе может быть применено «уплотнение памяти», о котором мы уже говорили в подразделе «Разделы с фиксированными границами» при рассмотрении динамического способа разбиения памяти на разделы.
В идеальном случае размер сегмента должен быть достаточно малым, чтобы его можно было разместить в случайно освобождающихся фрагментах оперативной памяти, но достаточно большим, чтобы содержать логически законченную часть программы с тем, чтобы минимизировать межсегментные обращения.
Для решения проблемы замещения (определения того сегмента, который должен быть либо перемещен во внешнюю память, либо просто замещен новым) используются следующие дисциплины1:
правило FIFO (first in - first out, что означает: «первый пришедший первым и выбывает»);
правило LRU (least recently used, что означает «последний из недавно использованных» или, иначе говоря, «дольше всего неиспользуемый»);
правило LFU (least frequently used, что означает: «используемый реже всех остальных»);
♦ случайный (random) выбор сегмента.
Первая и последняя дисциплины являются самыми простыми в реализации, но они не учитывают, насколько часто используется тот или иной сегмент и, следовательно, диспетчер памяти может выгрузить или расформировать тот сегмент, к которому в самом ближайшем будущем будет обращение. Безусловно, достоверной информации о том, какой из сегментов потребуется в ближайшем будущем, в общем случае иметь нельзя, но вероятность ошибки для этих дисциплин многократно выше, чем у второй и третьей дисциплины, которые учитывают информацию об использовании сегментов.
Алгоритм FIFO ассоциирует с каждым сегментом время, когда он был помещён в память. Для замещения выбирается наиболее старый сегмент. Учет времени необязателен, когда все сегменты в памяти связаны в FIFO-очередь и каждый помещаемый в память сегмент добавляется в хвост этой очерёди. Алгоритм учитывает только время нахождения сегмента в памяти, но не учитывает фактическое использование сегментов. Например, первые загруженные сегменты программы могут содержать переменные, используемые на протяжении работы всей программы. Это приводит к немедленному возвращению к только что замещенному сегменту.
Для реализации дисциплин LRU и LFU необходимо, чтобы процессор имел дополнительные аппаратные средства. Минимальные требования - достаточно, чтобы при обращении к дескриптору сегмента для получения физического адреса, с которого сегмент начинает располагаться в памяти, соответствующий бит обращения менял свое значение (скажем, с нулевого, которое установила ОС, в единичное). Тогда диспетчер памяти может время от времени просматривать таблицы дескрипторов исполняющихся задач и собирать для соответствующей обработки статистическую информацию об обращениях к сегментам. В результате можно составить список, упорядоченный либо по длительности не использования (для дисциплины LRU), либо по частоте использования (для дисциплины LFU).
Важнейшей проблемой, которая возникает при организации мультипрограммного режима, является защита памяти. Для того чтобы выполняющиеся приложения не смогли испортить саму ОС и другие вычислительные процессы, необходимо, чтобы доступ к таблицам сегментов с целью их модификации был обеспечен только для кода самой ОС. Для этого код ОС должен выполняться в некотором привилегированном режиме, из которого можно осуществлять манипуляции с дескрипторами сегментов, тогда как выход за пределы сегмента в обычной прикладной программе должен вызывать прерывание по защите памяти. Каждая прикладная задача должна иметь возможность обращаться только к своим собственным сегментам.
При использовании сегментного способа организации виртуальной памяти появляется несколько интересных возможностей. Во-первых, появляется возможность при загрузке программы на исполнение размещать её в памяти не целиком, а «по мере необходимости». Действительно, поскольку в подавляющем большинстве случаев алгоритм, по которому работает код программы, является разветвлённым, а не линейным, то в зависимости от исходных данных некоторые части программы, расположенные в самостоятельных сегментах, могут быть и не задействованы; значит, их можно и не загружать в оперативную память. Во-вторых, некоторые программные модули могут быть разделяемыми. Эти программные модули являются сегментами, и в этом случае относительно легко организовать доступ к таким сегментам. Сегмент с разделяемым кодом располагается в памяти в единственном экземпляре, а в нескольких таблицах дескрипторов сегментов исполняющихся задач будут находиться указатели на такие разделяемые сегменты.
Однако у сегментного способа распределения памяти есть и недостатки. Прежде всего, из рис. 2.7 видно, что для получения доступа к искомой ячейке памяти необходимо потратить намного больше времени. Мы должны сначала найти и прочитать дескриптор сегмента, а уже потом, используя данные из него о местонахождении нужного нам сегмента, можем вычислить и конечный физический адрес. Для того чтобы уменьшить эти потери, используется кэширование - то есть те дескрипторы, с которыми мы имеем дело в данный момент, могут быть размещены в сверхоперативной памяти (специальных регистрах, размещаемых в процессоре).
Несмотря на то, что этот способ распределения памяти приводит к существенно меньшей фрагментации памяти, нежели способы с неразрывным распределением, фрагментация остается. Кроме этого, мы имеем большие потери памяти и процессорного времени на размещение и обработку дескрипторных таблиц. Ведь на каждую задачу необходимо иметь свою таблицу дескрипторов сегментов. А при определении физических адресов необходимо выполнять операции сложения.
Поэтому следующим способом разрывного размещения задач в памяти стал способ, при котором все фрагменты задачи одинакового размера и длины, кратной степени двойки, чтобы операции сложения можно было заменить операциями конкатенации (слияния). Это - страничный способ организации виртуальной памяти.
Примером использования сегментного способа организации виртуальной памяти является операционная система для ПК OS/2 первого поколения1, которая была создана для процессора i80286. В этой ОС в полной мере использованы аппаратные средства микропроцессора, который специально проектировался для поддержки сегментного способа распределения памяти.
OS/2 v.l поддерживала распределение памяти, при котором выделялись сегменты программы и сегменты данных. Система позволяла работать как с именованными, так и неименованными сегментами. Имена разделяемых сегментов данных имели ту же форму, что и имена файлов. Процессы получали доступ к именованным разделяемым сегментам, используя их имена в специальных системных вызовах. OS/2 v.l допускала разделение программных сегментов приложений и подсистем, а также глобальных сегментов данных подсистем. Вообще, вся концепция системы OS/2 была построена на понятии разделения памяти: процессы почти всегда разделяют сегменты с другими процессами. В этом состояло существенное отличие от систем типа UNIX, которые обычно разделяют только реентерабельные программные модули между процессами.
Сегменты, которые активно не использовались, могли выгружаться на жесткий диск. Система восстанавливала их, когда в этом возникала необходимость. Так как все области памяти, используемые сегментом, должны были быть непрерывными, OS/2 перемещала в основной памяти сегменты таким образом, чтобы максимизировать объём свободной физической памяти. Такое размещение называется компрессией или перемещением сегментов (уплотнением памяти). Программные сегменты не выгружались, поскольку они могли просто перезагружаться с исходных дисков. Области в младших адресах физической памяти, которые использовались для запуска DOS-программ и кода самой OS/2, не участвовали в перемещении или подкачке. Кроме этого, система или прикладная программа могли временно фиксировать сегмент в памяти с тем, чтобы гарантировать наличие буфера ввода/вывода в физической памяти до тех пор, пока операция ввода/вывода не завершится.
Если в результате компрессии памяти не удавалось создать необходимое свободное пространство, то супервизор выполнял операции фонового плана для перекачки достаточного количества сегментов из физической памяти, чтобы дать возможность завершиться исходному запросу.
Механизм перекачки сегментов использовал файловую систему для перекачки данных из физической памяти и в неё. Ввиду того, что перекачка и сжатие влияют на производительность системы в целом, пользователь может сконфигурировать систему так, чтобы эти функции не выполнялись.
Было организовано в OS/2 и динамическое присоединение обслуживающих программ. Программы OS/2 используют команды удаленного вызова. Ссылки, генерируемые этими вызовами, определяются в момент загрузки самой программы или её сегментов. Такое отсроченное определение ссылок называется динамическим присоединением. Загрузочный формат модуля OS/2 представляет собой расширение формата загрузочного модуля DOS. Он был расширен, чтобы поддерживать необходимое окружение для свопинга сегментов с динамическим присоединением. Динамическое присоединение уменьшает объём памяти для программ в OS/2, одновременно делая возможным перемещения подсистем и обслуживающих программ без необходимости повторного редактирования адресных ссылок к прикладным программам.
Страничный способ организации виртуальной памяти
Как мы уже сказали, при таком способе все фрагменты программы, на которые она разбивается (за исключением последней её части), получаются одинаковыми. Одинаковыми полагаются и единицы памяти, которые мы предоставляем для размещения фрагментов программы. Эти одинаковые части называют страницами и говорят, что память разбивается на физические страницы, а программа - на виртуальные страницы. Часть виртуальных страниц задачи размещается в оперативной памяти, а часть - во внешней. Обычно место во внешней памяти, в качестве которой в абсолютном большинстве случаев выступают накопители на магнитных дисках (поскольку они относятся к быстродействующим устройствам с прямым доступом), называют файлом подкачки или страничным файлом (paging file). Иногда этот файл называют swap-файлом, тем самым подчеркивая, что записи этого файла - страницы - замещают друг друга в оперативной памяти. В некоторых ОС выгруженные страницы располагаются не в файле, а в специальном разделе дискового пространства. В UNIX-системах для этих целей выделяется специальный раздел, но кроме него могут быть использованы и файлы, выполняющие те же функции, если объёма раздела недостаточно.
Разбиение всей оперативной памяти на страницы одинаковой величины, причем величина каждой страницы выбирается кратной степени двойки, приводит к тому, что вместо одномерного адресного пространства памяти можно говорить о двумерном. Первая координата адресного пространства - это номер страницы, а вторая координата - номер ячейки внутри выбранной страницы (его называют индексом). Таким образом, физический адрес определяется парой (Pp, i), а виртуальный адрес - парой (Pv, i), где Pv - это номер виртуальной страницы, Pp - это номер физической страницы и i - это индекс ячейки внутри страницы. Количество битов, отводимое под индекс, определяет размер страницы, а количество битов, отводимое под номер виртуальной страницы, - объём возможной виртуальной памяти, которой может пользоваться программа. Отображение, осуществляемое системой во время исполнения, сводится к отображению Pv в Pp и приписывании к полученному значению битов адреса, задаваемых величиной i. При этом нет необходимости ограничивать число виртуальных страниц числом физических, то есть не поместившиеся страницы можно размещать во внешней памяти, которая в данном случае служит расширением оперативной.
Для отображения виртуального адресного пространства задачи на физическую память, как и в случае с сегментным способом организации, для каждой задачи необходимо иметь таблицу страниц для трансляции адресных пространств. Для описания каждой страницы диспетчер памяти ОС заводит соответствующий дескриптор, который отличается от дескриптора сегмента прежде всего тем, что в нем нет необходимости иметь поле длины - ведь все страницы имеют одинаковый размер. По номеру виртуальной страницы в таблице дескрипторов страниц текущей задачи находится соответствующий элемент (дескриптор). Если бит присутствия имеет единичное значение, значит, данная страница сейчас размещена в оперативной, а не во внешней памяти и мы в дескрипторе имеем номер физической страницы, отведенной под данную виртуальную. Если же бит присутствия равен нулю, то в дескрипторе мы будем иметь адрес виртуальной страницы, расположенной сейчас во внешней памяти. Таким образом и осуществляется трансляция виртуального адресного пространства на физическую память. Этот механизм трансляции проиллюстрирован на рис. 2.8.
Защита страничной памяти, как и в случае с сегментным механизмом, основана на контроле уровня доступа к каждой странице. Как правило, возможны следующие уровни доступа: только чтение; чтение и запись; только выполнение. В этом случае каждая страница снабжается соответствующим кодом уровня доступа. При трансформации логического адреса в физический сравнивается значение кода разрешенного уровня доступа с фактически требуемым. При их несовпадении работа программы прерывается.

При обращении к виртуальной странице, не оказавшейся в данный момент в оперативной памяти, возникает прерывание и управление передаётся диспетчеру памяти, который должен найти свободное место. Обычно предоставляется первая же свободная страница. Если свободной физической страницы нет, то диспетчер памяти по одной из вышеупомянутых дисциплин замещения (LRU, LFU, FIFO, random) определит страницу, подлежащую расформированию или сохранению во внешней памяти. На её место он разместит ту новую виртуальную страницу, к которой было обращение из задачи, но её не оказалось в оперативной памяти.
Напомним, что алгоритм выбирает для замещения ту страницу, на которую не было ссылки на протяжении наиболее длинного периода времени. Дисциплина LRU (least recently used) ассоциирует с каждой страницей время последнего её использования. Для замещения выбирается та страница, которая дольше всех не использовалась.
Для использования дисциплин LRU и LFU в процессоре должны быть соответствующие аппаратные средства. В дескрипторе страницы размещается бит обращения (подразумевается, что на рис. 2.8 этот бит расположен в последнем поле), и этот бит становится единичным при обращении к дескриптору.
Если объём физической памяти небольшой и даже часто требуемые страницы не удается разместить в оперативной памяти, то возникает так называемая «пробуксовка». Другими словами, пробуксовка - это ситуация, при которой загрузка нужной нам страницы вызывает перемещение во внешнюю память той страницы, с которой мы тоже активно работаем. Очевидно, что это очень плохое явление. Чтобы его не допускать, желательно увеличить объём оперативной памяти (сейчас это стало самым простым решением), уменьшить количество параллельно выполняемых задач либо попробовать использовать более эффективные дисциплины замещения. В абсолютном большинстве современных ОС используется дисциплина замещения страниц LRU как самая эффективная. Так, именно эта дисциплина используется в OS/2 и Linux. Однако в такой ОС, как Windows NT, разработчики, желая сделать систему максимально независимой от аппаратных возможностей процессора, пошли на отказ от этой дисциплины и применили правило FIFO. А для того, чтобы хоть как-нибудь сгладить её неэффективность, была введена «буферизация» тех страниц, которые должны быть записаны в файл подкачки на диск1 или просто расформированы. Принцип буферирования прост. Прежде чем замещаемая страница действительно будет перемещена во внешнюю память или просто расформирована, она помечается как кандидат на выгрузку. Если в следующий раз произойдет обращение к странице, находящейся в таком «буфере», то страница никуда не выгружается и уходит в конец списка FIFO. В противном случае страница действительно выгружается, а на её место в «буфере» попадает следующий «кандидат». Величина такого «буфера» не может быть большой, поэтому эффективность страничной реализации памяти в Windows NT намного ниже, чем у вышеназванных ОС, и явление пробуксовки начинается даже при существенно большем объёме оперативной памяти.
В ряде ОС с пакетным режимом работы для борьбы с пробуксовкой используется метод «рабочего множества». Рабочее множество - это множество «активных» страниц задачи за некоторой интервал. То есть тех страниц, к которым было обращение за этот интервал времени. Реально количество активных страниц задачи (за интервал Т) все время изменяется, и это естественно, но, тем не менее, для каждой задачи можно определить среднее количество её активных страниц. Это среднее число активных страниц и есть рабочее множество задачи. Наблюдения за исполнением множества различных программ показали [28, 37, 49], что даже если Т равно времени выполнения всей работы, то размер рабочего множества часто существенно меньше, чем общее число страниц программы. Таким образом, если ОС может определить рабочие множества исполняющихся задач, то для предотвращения пробуксовки достаточно планировать на выполнение только такое количество задач, чтобы сумма их рабочих множеств не превышала возможности системы.
Как и в случае с сегментным способом организации виртуальной памяти, страничный механизм приводит к тому, что без специальных аппаратных средств он будет существенно замедлять работу вычислительной системы. Поэтому обычно используется кэширование страничных дескрипторов. Наиболее эффективным способом кэширования является использование ассоциативного кэша. Именно такой ассоциативный кэш и создан в 32-разрядных микропроцессорах i80x86. Начиная с i80386, который поддерживает страничный способ распределения памяти, в этих микропроцессорах имеется кэш на 32 страничных дескриптора. Поскольку размер страницы в этих микропроцессорах равен 4 Кбайт, возможно быстрое обращение к 1 28 Кбайт памяти.
Итак, основным достоинством страничного способа распределения памяти является минимально возможная фрагментация. Поскольку на каждую задачу может приходиться по одной незаполненной странице, то становится очевидно, что память можно использовать достаточно эффективно; этот метод организации виртуальной памяти был бы одним из самых лучших, если бы не два следующих обстоятельства.
Первое - эта то, что страничная трансляция виртуальной памяти требует существенных накладных расходов. В самом деле, таблицы страниц нужно тоже размещать в памяти. Кроме этого, эти таблицы нужно обрабатывать; именно с ними работает диспетчер памяти.
Второй существенный недостаток страничной адресации заключается в том, что программы разбиваются на страницы случайно, без учета логических взаимосвязей, имеющихся в коде. Это приводит к тому, что межстраничные переходы, как правило, осуществляются чаще, нежели межсегментные, и к тому, что становится трудно организовать разделение программных модулей между выполняющимися процессами.
Для того чтобы избежать второго недостатка, постаравшись сохранить достоинства страничного способа распределения памяти, был предложен ещё один способ - сегментно-страничный. Правда, за счёт дальнейшего увеличения накладных расходов на его реализацию.
Сегментно-страничный способ организации виртуальной памяти
Как и в сегментном способе распределения памяти, программа разбивается на логически законченные части - сегменты - и виртуальный адрес содержит указание на номер соответствующего сегмента. Вторая составляющая виртуального адреса - смещение относительно начала сегмента - в свою очередь, может состоять из двух полей: виртуальной страницы и индекса. Другими словами, получается, что виртуальный адрес теперь состоит из трех компонентов: сегмент, страница, индекс. Получение физического адреса и извлечение из памяти необходимого элемента для этого способа представлено на рис. 2.9.
Из рисунка сразу видно, что этот способ организации виртуальной памяти вносит ещё большую задержку доступа к памяти. Необходимо сначала вычислить адрес дескриптора сегмента и прочитать его, затем вычислить адрес элемента таблицы страниц этого сегмента и извлечь из памяти необходимый элемент, и уже только после этого можно к номеру физической страницы приписать номер ячейки в странице (индекс). Задержка доступа к искомой ячейке получается по крайней мере в три раза больше, чем при простой прямой адресации. Чтобы избежать этой неприятности, вводится кэширование, причем кэш, как правило, строится по ассоциативному принципу. Другими словами, просмотры двух таблиц в памяти могут быть заменены одним обращением к ассоциативной памяти.

Напомним, что принцип действия ассоциативного запоминающего устройства предполагает, что каждой ячейке памяти такого устройства ставится в соответствие ячейка, в которой записывается некий ключ (признак, адрес), позволяющий однозначно идентифицировать содержимое ячейки памяти. Сопутствующую ячейку с информацией, позволяющей идентифицировать основные данные, обычно называют полем тега. Просмотр полей тега всех ячеек ассоциативного устройства памяти осуществляется одновременно, то есть в каждой ячейке тега есть необходимая логика, позволяющая посредством побитовой конъюнкции найти данные по их признаку за одно обращение к памяти (если они там, конечно, присутствуют). Часто поле тегов называют аргументом, а поле с данными - функцией. В качестве аргумента при доступе к ассоциативной памяти выступают номер сегмента и номер виртуальной страницы, а в качестве функции от этих аргументов получаем номер физической страницы. Остается приписать номер ячейки в странице к полученному номеру, и мы получаем искомую команду или операнд.
Оценим достоинства сегментно-страничного способа. Разбиение программы на сегменты позволяет размещать сегменты в памяти целиком. Сегменты разбиты на страницы, все страницы сегмента загружаются в память. Это позволяет уменьшить обращения к отсутствующим страницам, поскольку вероятность выхода за пределы сегмента меньше вероятности выхода за пределы страницы. Страницы исполняемого сегмента находятся в памяти, но при этом они могут находиться не рядом друг с другом, а «россыпью», поскольку диспетчер памяти манипулирует страницами. Наличие сегментов облегчает реализацию разделения программных модулей между параллельными процессами. Возможна и динамическая компоновка задачи. А выделение памяти страницами позволяет минимизировать фрагментацию.
Однако, поскольку этот способ распределения памяти требует очень значительных затрат вычислительных ресурсов и его не так просто реализовать, используется он редко, причем в дорогих, мощных вычислительных системах. Возможность реализовать сегментно-страничное распределение памяти заложена и в семейство микропроцессоров i80x86, однако вследствие слабой аппаратной поддержки, трудностей при создании систем программирования и операционной системы, практически он не используется в ПК.
26.
Средства синхронизации и взаимодействия процессов
Проблема синхронизации
Процессам часто нужно взаимодействовать друг с другом, например, один процесс может передавать данные другому процессу, или несколько процессов могут обрабатывать данные из общего файла. Во всех этих случаях возникает проблема синхронизации процессов, которая может решаться приостановкой и активизацией процессов, организацией очередей, блокированием и освобождением ресурсов.

Рис. 2.3. Пример необходимости синхронизации
Пренебрежение вопросами синхронизации процессов, выполняющихся в режиме мультипрограммирования, может привести к их неправильной работе или даже к краху системы. Рассмотрим, например (рисунок 2.3), программу печати файлов (принт-сервер). Эта программа печатает по очереди все файлы, имена которых последовательно в порядке поступления записывают в специальный общедоступный файл "заказов" другие программы. Особая переменная NEXT, также доступная всем процессам-клиентам, содержит номер первой свободной для записи имени файла позиции файла "заказов". Процессы-клиенты читают эту переменную, записывают в соответствующую позицию файла "заказов" имя своего файла и наращивают значение NEXT на единицу. Предположим, что в некоторый момент процесс R решил распечатать свой файл, для этого он прочитал значение переменной NEXT, значение которой для определенности предположим равным 4. Процесс запомнил это значение, но поместить имя файла не успел, так как его выполнение было прервано (например, в следствие исчерпания кванта). Очередной процесс S, желающий распечатать файл, прочитал то же самое значение переменной NEXT, поместил в четвертую позицию имя своего файла и нарастил значение переменной на единицу. Когда в очередной раз управление будет передано процессу R, то он, продолжая свое выполнение, в полном соответствии со значением текущей свободной позиции, полученным во время предыдущей итерации, запишет имя файла также в позицию 4, поверх имени файла процесса S.
Таким образом, процесс S никогда не увидит свой файл распечатанным. Сложность проблемы синхронизации состоит в нерегулярности возникающих ситуаций: в предыдущем примере можно представить и другое развитие событий: были потеряны файлы нескольких процессов или, напротив, не был потерян ни один файл. В данном случае все определяется взаимными скоростями процессов и моментами их прерывания. Поэтому отладка взаимодействующих процессов является сложной задачей. Ситуации подобные той, когда два или более процессов обрабатывают разделяемые данные, и конечный результат зависит от соотношения скоростей процессов, называются гонками.
Критическая секция
Важным понятием синхронизации процессов является понятие "критическая секция" программы.Критическая секция - это часть программы, в которой осуществляется доступ к разделяемым данным. Чтобы исключить эффект гонок по отношению к некоторому ресурсу, необходимо обеспечить, чтобы в каждый момент в критической секции, связанной с этим ресурсом, находился максимум один процесс. Этот прием называют взаимным исключением.
Простейший способ обеспечить взаимное исключение - позволить процессу, находящемуся в критической секции, запрещать все прерывания. Однако этот способ непригоден, так как опасно доверять управление системой пользовательскому процессу; он может надолго занять процессор, а при крахе процесса в критической области крах потерпит вся система, потому что прерывания никогда не будут разрешены.

Рис. 2.4. Реализация критических секций с использованием блокирующих переменных
Другим способом является использование блокирующих переменных. С каждым разделяемым ресурсом связывается двоичная переменная, которая принимает значение 1, если ресурс свободен (то есть ни один процесс не находится в данный момент в критической секции, связанной с данным процессом), и значение 0, если ресурс занят. На рисунке 2.4 показан фрагмент алгоритма процесса, использующего для реализации взаимного исключения доступа к разделяемому ресурсу D блокирующую переменную F(D). Перед входом в критическую секцию процесс проверяет, свободен ли ресурс D. Если он занят, то проверка циклически повторяется, если свободен, то значение переменной F(D) устанавливается в 0, и процесс входит в критическую секцию. После того, как процесс выполнит все действия с разделяемым ресурсом D, значение переменной F(D) снова устанавливается равным 1.
Если все процессы написаны с использованием вышеописанных соглашений, то взаимное исключение гарантируется. Следует заметить, что операция проверки и установки блокирующей переменной должна быть неделимой. Поясним это. Пусть в результате проверки переменной процесс определил, что ресурс свободен, но сразу после этого, не успев установить переменную в 0, был прерван. За время его приостановки другой процесс занял ресурс, вошел в свою критическую секцию, но также был прерван, не завершив работы с разделяемым ресурсом. Когда управление было возвращено первому процессу, он, считая ресурс свободным, установил признак занятости и начал выполнять свою критическую секцию. Таким образом был нарушен принцип взаимного исключения, что потенциально может привести к нежелаемым последствиям. Во избежание таких ситуаций в системе команд машины желательно иметь единую команду "проверка-установка", или же реализовывать системными средствами соответствующие программные примитивы, которые бы запрещали прерывания на протяжении всей операции проверки и установки.
Реализация критических секций с использованием блокирующих переменных имеет существенный недостаток: в течение времени, когда один процесс находится в критической секции, другой процесс, которому требуется тот же ресурс, будет выполнять рутинные действия по опросу блокирующей переменной, бесполезно тратя процессорное время. Для устранения таких ситуаций может быть использован так называемый аппарат событий. С помощью этого средства могут решаться не только проблемы взаимного исключения, но и более общие задачи синхронизации процессов. В разных операционных системах аппарат событий реализуется по своему, но в любом случае используются системные функции аналогичного назначения, которые условно назовем WAIT(x) и POST(x), где x - идентификатор некоторого события. На рисунке 2.5 показан фрагмент алгоритма процесса, использующего эти функции. Если ресурс занят, то процесс не выполняет циклический опрос, а вызывает системную функцию WAIT(D), здесь D обозначает событие, заключающееся в освобождении ресурса D. Функция WAIT(D) переводит активный процесс в состояние ОЖИДАНИЕ и делает отметку в его дескрипторе о том, что процесс ожидает события D. Процесс, который в это время использует ресурс D, после выхода из критической секции выполняет системную функцию POST(D), в результате чего операционная система просматривает очередь ожидающих процессов и переводит процесс, ожидающий события D, в состояние ГОТОВНОСТЬ.
Обобщающее средство синхронизации процессов предложил Дейкстра, который ввел два новых примитива. В абстрактной форме эти примитивы, обозначаемые P и V, оперируют над целыми неотрицательными переменными, называемыми семафорами. Пусть S такой семафор. Операции определяются следующим образом:
V(S) : переменная S увеличивается на 1 одним неделимым действием; выборка, инкремент и запоминание не могут быть прерваны, и к S нет доступа другим процессам во время выполнения этой операции.
P(S) : уменьшение S на 1, если это возможно. Если S=0, то невозможно уменьшить S и остаться в области целых неотрицательных значений, в этом случае процесс, вызывающий P-операцию, ждет, пока это уменьшение станет возможным. Успешная проверка и уменьшение также является неделимой операцией.

Рис. 2.5. Реализация критической секции с использованием системных функций WAIT(D) и POST(D)
В частном случае, когда семафор S может принимать только значения 0 и 1, он превращается в блокирующую переменную. Операция P заключает в себе потенциальную возможность перехода процесса, который ее выполняет, в состояние ожидания, в то время как V-операция может при некоторых обстоятельствах активизировать другой процесс, приостановленный операцией P (сравните эти операции с системными функциями WAIT и POST).
Рассмотрим использование семафоров на классическом примере взаимодействия двух процессов, выполняющихся в режиме мультипрограммирования, один из которых пишет данные в буферный пул, а другой считывает их из буферного пула. Пусть буферный пул состоит из N буферов, каждый из которых может содержать одну запись. Процесс "писатель" должен приостанавливаться, когда все буфера оказываются занятыми, и активизироваться при освобождении хотя бы одного буфера. Напротив, процесс "читатель" приостанавливается, когда все буферы пусты, и активизируется при появлении хотя бы одной записи.
Введем два семафора: e - число пустых буферов и f - число заполненных буферов. Предположим, что запись в буфер и считывание из буфера являются критическими секциями (как в примере с принт-сервером в начале данного раздела). Введем также двоичный семафор b, используемый для обеспечения взаимного исключения. Тогда процессы могут быть описаны следующим образом:
// Глобальные переменные
#define N 256
int e = N, f = 0, b = 1;
void Writer ()
{
while(1)
{
PrepareNextRecord(); /* подготовка новой записи */
P(e); /* Уменьшить число свободных буферов, если они есть */
/* в противном случае - ждать, пока они освободятся */
P(b); /* Вход в критическую секцию */
AddToBuffer(); /* Добавить новую запись в буфер */
V(b); /* Выход из критической секции */
V(f); /* Увеличить число занятых буферов */
}
}
void Reader ()
{
while(1)
{ P(f); /* Уменьшить число занятых буферов, если они есть */
/* в противном случае ждать, пока они появятся */
P(b); /* Вход в критическую секцию */
GetFromBuffer(); /* Взять запись из буфера */
V(b); /* Выход из критической секции */
V(e); /* Увеличить число свободных буферов */
ProcessRecord(); /* Обработать запись */
}
}
Тупики
Приведенный выше пример поможет нам проиллюстрировать еще одну проблему синхронизации -взаимные блокировки, называемые также дедлоками (deadlocks), клинчами (clinch) или тупиками. Если переставить местами операции P(e) и P(b) в программе "писателе", то при некотором стечении обстоятельств эти два процесса могут взаимно заблокировать друг друга. Действительно, пусть "писатель" первым войдет в критическую секцию и обнаружит отсутствие свободных буферов; он начнет ждать, когда "читатель" возьмет очередную запись из буфера, но "читатель" не сможет этого сделать, так как для этого необходимо войти в критическую секцию, вход в которую заблокирован процессом "писателем".
Рассмотрим еще один пример тупика. Пусть двум процессам, выполняющимся в режиме мультипрограммирования, для выполнения их работы нужно два ресурса, например, принтер и диск. На рисунке 2.6,а показаны фрагменты соответствующих программ. И пусть после того, как процесс А занял принтер (установил блокирующую переменную), он был прерван. Управление получил процесс В, который сначала занял диск, но при выполнении следующей команды был заблокирован, так как принтер оказался уже занятым процессом А. Управление снова получил процесс А, который в соответствии со своей программой сделал попытку занять диск и был заблокирован: диск уже распределен процессу В. В таком положении процессы А и В могут находиться сколь угодно долго.
В зависимости от соотношения скоростей процессов, они могут либо совершенно независимо использовать разделяемые ресурсы (г), либо образовывать очереди к разделяемым ресурсам (в), либо взаимно блокировать друг друга (б). Тупиковые ситуации надо отличать от простых очередей, хотя и те и другие возникают при совместном использовании ресурсов и внешне выглядят похоже: процесс приостанавливается и ждет освобождения ресурса. Однако очередь - это нормальное явление, неотъемлемый признак высокого коэффициента использования ресурсов при случайном поступлении запросов. Она возникает тогда, когда ресурс недоступен в данный момент, но через некоторое время он освобождается, и процесс продолжает свое выполнение. Тупик же, что видно из его названия, является в некотором роде неразрешимой ситуацией.

Рис. 2.6. (a) фрагменты программ А и В, разделяющих принтер и диск; (б) взаимная блокировка (клинч);(в) очередь к разделяемому диску; (г) независимое использование ресурсов
В рассмотренных примерах тупик был образован двумя процессами, но взаимно блокировать друг друга могут и большее число процессов.
Проблема тупиков включает в себя следующие задачи:
предотвращение тупиков,
распознавание тупиков,
восстановление системы после тупиков.
Тупики могут быть предотвращены на стадии написания программ, то есть программы должны быть написаны таким образом, чтобы тупик не мог возникнуть ни при каком соотношении взаимных скоростей процессов. Так, если бы в предыдущем примере процесс А и процесс В запрашивали ресурсы в одинаковой последовательности, то тупик был бы в принципе невозможен. Второй подход к предотвращению тупиков называется динамическим и заключается в использовании определенных правил при назначении ресурсов процессам, например, ресурсы могут выделяться в определенной последовательности, общей для всех процессов.
В некоторых случаях, когда тупиковая ситуация образована многими процессами, использующими много ресурсов, распознавание тупика является нетривиальной задачей. Существуют формальные, программно-реализованные методы распознавания тупиков, основанные на ведении таблиц распределения ресурсов и таблиц запросов к занятым ресурсам. Анализ этих таблиц позволяет обнаружить взаимные блокировки.
Если же тупиковая ситуация возникла, то не обязательно снимать с выполнения все заблокированные процессы. Можно снять только часть из них, при этом освобождаются ресурсы, ожидаемые остальными процессами, можно вернуть некоторые процессы в область свопинга, можно совершить "откат" некоторых процессов до так называемой контрольной точки, в которой запоминается вся информация, необходимая для восстановления выполнения программы с данного места. Контрольные точки расставляются в программе в местах, после которых возможно возникновение тупика.
Из всего вышесказанного ясно, что использовать семафоры нужно очень осторожно, так как одна незначительная ошибка может привести к останову системы. Для того, чтобы облегчить написание корректных программ, было предложено высокоуровневое средство синхронизации, называемое монитором. Монитор - это набор процедур, переменных и структур данных. Процессы могут вызывать процедуры монитора, но не имеют доступа к внутренним данным монитора. Мониторы имеют важное свойство, которое делает их полезными для достижения взаимного исключения: только один процесс может быть активным по отношению к монитору. Компилятор обрабатывает вызовы процедур монитора особым образом. Обычно, когда процесс вызывает процедуру монитора, то первые несколько инструкций этой процедуры проверяют, не активен ли какой-либо другой процесс по отношению к этому монитору. Если да, то вызывающий процесс приостанавливается, пока другой процесс не освободит монитор. Таким образом, исключение входа нескольких процессов в монитор реализуется не программистом, а компилятором, что делает ошибки менее вероятными.
В распределенных системах, состоящих из нескольких процессоров, каждый из которых имеет собственную оперативную память, семафоры и мониторы оказываются непригодными. В таких системах синхронизация может быть реализована только с помощью обмена сообщениями. Подробнее об этом смотрите в разделе "Синхронизация в распределенных системах".
27.