

1) В общем случае режимы работы с БД можно классифицировать по следующим признакам:
• многозадачность – однопользовательский или многопользовательский;
Многозада́чность — свойство операционной системы или среды программирования обеспечивать возможность параллельной (или псевдопараллельной) обработки нескольких процессов.
• правило обслуживания запросов – последовательное или параллельное;
Это возможность выполнять команды друг за другом или параллельно.
• схема размещение данных – централизованная или распределённая БД.
Следует отметить, что общая тенденция развития технологий обработки данных вполне соответствует этапам развития средств вычислительной техники и информационных технологий, и в первую очередь – сетевых. В этом смысле следует выделить два класса: системы распределённой обработки данных и системы распределённых баз данных.
Разделение процесса выполнения запроса на «клиентскую» и «серверную» компоненту позволяет: • различным прикладным (клиентским) программам одновременно использовать общую БД;
• централизовать функции управления, такие, как защита информации, обеспечение целостности данных, управление совместным использованием ресурсов;
• обеспечивать параллельную обработку запроса в случае распределенных БД;
• высвобождать ресурсы рабочих станций и сети;
• повышать эффективность управления данными за счёт использования ЭВМ, специально разработанных для работы СУБД (серверы баз данных и машины баз данных).
Учитывая, что одним из основных показателей эффективности сетевой обработки данных является время обслуживания запроса, рассмотрим различные модели архитектуры распределённой обработки на примере, когда прикладная программа работы с БД, расположенной на сервере, загружена на рабочую станцию, и пользователю необходимо получить все записи, удовлетворяющие некоторым поисковым условиям. (Прим. автора, далее возможно нужно сказать про архитектуру “файл-сервер”)
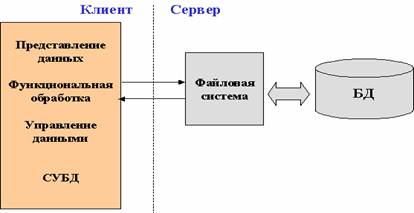
2)В архитектуре «файл-сервер, средства организации и управления БД (в том числе и СУБД) целиком располагаются на машине клиента, а БД, представляющая собой обычно набор специализированных структурированных файлов, – на машине-сервере. В этом случае серверная компонента представлена даже не средствами СУБД, а сетевыми составляющими операционной системы, обеспечивающими удалённый разделяемый доступ к файлам. Таким образом, «файл-сервер» представляет вырожденный случай клиент-серверной архитектуры.
Взаимодействие между клиентом и сервером происходит на уровне команд ввода-вывода файловой системы, которая возвращает запись или блок данных. Запрос к базе, сформулированный на языке манипулирования данными, преобразуется самой СУБД в последовательность команд ввода-вывода, которые обрабатываются операционной системой машины-сервера.
Достоинство - возможность обслуживания запросов нескольких клиентов.
Недостатки: • высокая загрузка сети и машин-клиентов, т.к. обмен идёт на уровне единиц информации файловой системы – физических записей, блоков или даже файлов, из которых на машине клиента будут выбраны и представлены необходимые для приложения элементы данных;
• низкий уровень защиты данных, т.к. доступ к файлам БД управляется общими средствами ОС сервера;
• низкий уровень управления целостностью и непротиворечивостью информации, т.к. бизнес-правила функциональной обработки, сосредоточенные на клиентской части, могут быть противоречивыми и несихронизированными.
3) Cредства управления базой данных и БД размещены на машине-сервере.
Взаимодействие между клиентом и сервером происходит на уровне команд языка манипулирования данными СУБД (обычно SQL), которые обрабатываются СУБД на машине-сервере. Сервер базы данных осуществляет поиск записей и анализирует их. Записи, удовлетворяющие условиям, могут накапливаться на сервере и после того, как запрос будет целиком обработан, пользователю на клиентскую машину передаются все логические записи (запрашиваемые элементы данных), удовлетворяющие поисковым условиям.
Данная
технология позволяет снизить сетевой
трафик и повысить общую эффективность
обработки за счёт оптимизации и
буферизации ввода-вывода. Т.о., сервер
может осуществить поиск и обрабатывать
запросы даже быстрее, чем, если бы они
обрабатывались на рабочей станции.
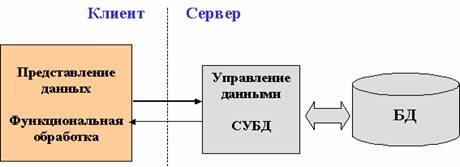
Достоинства: • возможность обслуживания запросов нескольких клиентов;
• снижение нагрузки на сеть и машины сервера и клиентов;
• защита данных осуществляется средствами СУБД, что позволяет блокировать неразрешенные пользователю действия;
• сервер реализует управление транзакциями и может блокировать попытки одновременного изменения одних и тех же записей.
Недостатки: • бизнес-логика функциональной обработки и представление данных могут быть одинаковыми для нескольких клиентских приложений, и это увеличит совокупные потребности в ресурсах при исполнении – повторение части кода программ и запросов;
• низкий уровень управления непротиворечивостью информации, т.к. бизнес-правила функциональной обработки, сосредоточенные на клиентской части, могут быть противоречивыми.
4) Для того чтобы устранить недостатки, свойственные архитектуре сервера базы данных необходимо, чтобы непротиворечивость бизнес-логики и изменения БД контролировались на стороне сервера. Причём некоторые, заранее специфицированные состояния могли бы изменять последовательность взаимодействия приложения с БД.
Для этого функции бизнес-логики разделяются между клиентской и серверной частью. Общие или критически значимые функции оформляются в виде хранимых процедур, включаемых в состав БД. Кроме этого, вводится механизм отслеживания событий БД – триггеров, также включаемых в состав базы. При возникновении соответствующего события (обычно изменения данных), СУБД вызывает для выполнения хранимую процедуру, связанную с триггером, что позволяет эффективно контролировать изменение БД.
Хранимые
процедуры и триггеры могут быть
использованы любыми клиентскими
приложениями, работающими с БД. Это
снижает дублирование программных кодов
и исключает необходимость компиляции
каждого запроса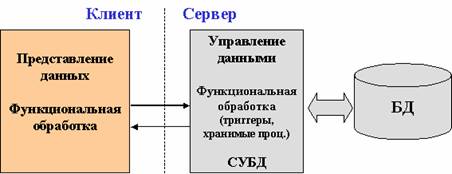
Недостатком такой архитектуры становится существенно возрастающая загрузка сервера за счёт необходимости отслеживания событий и выполнения части бизнес-правил.
5) Рассмотренные иные архитектуры являются двухзвенными – все функции доступа и обработки распределены между программой клиента и сервером БД. Дальнейшее снижение требований к ресурсам клиента достигается за счёт введения промежуточного звена – сервера приложений, на который переносится значительная часть программных компонентов управления данными и большая часть бизнес-логики. При этом серверы баз данных обеспечивают исключительно функции СУБД по ведению и обслуживанию БД.
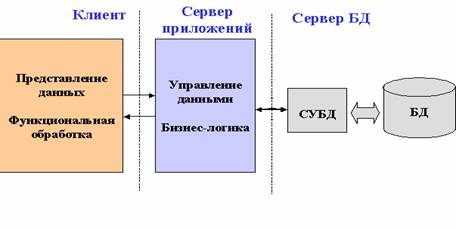
К другим (организационно-технологическим) достоинствам трёхзвенной архитектуры можно отнести: • централизованное ведение бизнес-логики и в случае их изменения отсутствие необходимости их тиражирования в клиентских приложениях;отсутствие необходимости устанавливать на клиентских машинах компонент программного обеспечения управления доступом к данным; возможность отложенного обновления БД в случае изменения данных, запрошенных с сервера, в автономном режиме. Данные будут обновлены в базе после следующего соединения клиентской программы с сервером приложений.
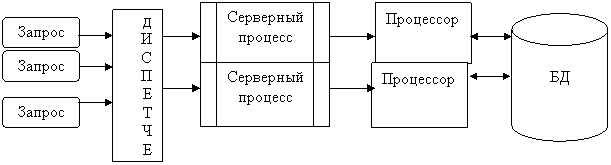
6)Повышение эффективности и оперативности обслуживания большого числа клиентских запросов, помимо простого увеличения ресурсов и вычислительной мощности сервера, может быть достигнуто двумя путями: снижением суммарного расхода памяти и вычислительных ресурсов за счёт буферизации (кэширования) и совместного использования (разделяемые ресурсы) наиболее часто запрашиваемых данных и процедур;
распараллеливанием процесса обработки запроса – использованием разных процессоров для параллельной обработки изолированных подзапросов и (или) для одновременного обращения к частям БД, размещённым на отдельных физических носителях.
Для обслуживания каждого запроса запускается отдельный серверный процесс.
Таким образом, даже если от клиентов поступят совершенно одинаковые запросы, для обработки каждого из них будет запущен отдельный процесс, каждый из которых будет выполнять одинаковые действия и использовать одни и те же ресурсы.

7)Обработку всех клиентских запросов выполняет один серверный процесс (использующий один процессор), взаимодействующий со всеми клиентами и монопольно управляющий ресурсами. При этом для отдельного клиентского процесса создаётся поток, (thread) в рамках которого локализуется обработка запроса.

8) Если для работы СУБД используются многопроцессорные платформы, обслуживание запросов может быть физически распределено для параллельной обработки между процессорами. Такое решение требует введения дополнительного звена, в задачи которого входит диспетчеризация запросов для обеспечения сбалансированной загрузки процессоров.
В случае, когда серверный процесс реализуется как многопоточное приложение, говорят, что СУБД имеет мультисерверную многопотоковую архитектуру.
Следует
отметить, что характер распределения
запросов в значительной степени зависит
от того, поддерживает ли ОС потоковую
обработку, а также от возможностей
средств управления приоритетами задач.
9) Для повышения оперативности за счёт распараллеливания процесса обработки отдельного клиентского запроса в мультисерверной архитектуре можно использовать следующие подходы:
1) Размещение хранимых данных БД на нескольких физических носителях (сегментирование базы). Для обработки запроса в этом случае запускаются несколько серверных процессов (использующих обычно отдельные процессоры), каждый из которых независимо от других выполняет одинаковую последовательность действий, определяемую существом запроса, но с данными, принадлежащими разным сегментам базы. Полученные таким образом результаты объединяются и передаются клиенту. Такой тип распараллеливания называют моделью горизонтального параллелизма.
2) Запрос обрабатывается по конвейерной технологии. Для этого запрос разбивается на взаимосвязанные по результатам подзапросы, каждый из которых может быть обслужен отдельным серверным процессом независимо от обработки других подзапросов. Получаемые результаты объединяются согласно схеме декомпозиции запроса и передаются клиенту. Такой тип распараллеливания называют моделью вертикального параллелизма.
Использование
моделей параллельной обработки позволяет
существенно сократить общее время
обслуживания запроса, что особенно
важно в случае работы с большими БД и
аналитической обработки (OLAP-приложений).

10) Распределенные корпоративные приложения всё более усложняются, интегрируя в себя унаследованные приложения, разрабатываемые и вновь приобретаемые готовые программные средства. Кроме того, разные подсистемы решают разные бизнес-задачи, однако одна из главных целей создания корпоративной системы – получить «единый образ» общего состояния системы, что обеспечит пользователям доступ к нужным операциям и ресурсам.
Основа такой инфраструктуры – так называемое промежуточное программное обеспечение, позволяющее, не вникая в тонкости сетевых реализаций, создавать и эксплуатировать взаимодействующие между собой приложения с разными требованиями к межмодульным коммуникациям.
Промежуточное ПО эволюционировало вместе с архитектурой клиент-сервер. Ранние, но достаточно эффективные как с точки зрения разработки, так и эксплуатации, частные решения предназначались для упрощения доступа к БД в двухзвенной модели, где «толстый» клиент реализует всю логику обработки информации, предоставляемой сервером БД. Такие системы вполне удовлетворяли потребностям небольших корпоративных подразделений с ограниченным числом пользователей и невысокой интенсивностью обмена.
Однако, по мере того, как клиент-серверная архитектура стала проникать в сферу высококритичных корпоративных приложений, обслуживающих уже не десятки, а сотни пользователей и работающих со значительными массивами данных, стали очевидны недостатки двухзвенного подхода. Этот способ реализации клиент-серверной схемы доступа ограничивал возможности масштабирования, поскольку увеличение числа обращений к одной БД непомерно увеличивало нагрузку на сервер и делало доступ к данным «узким местом» в общей производительности системы. Кроме того, всякая модификация логики приложения требовала внесения изменений во все экземпляры клиентских приложений.
Чтобы избежать таких проблем, для разработки корпоративных приложений используют трёхзвенную модель, которая переносит логику приложения на отдельный уровень сервера приложений. В результате клиентская часть приложения становится «тоньше» и в основном отвечает за предоставление удобного пользовательского интерфейса. Как правило, сервер баз данных также освобождается от необходимости поддерживать бизнес-логику, которая в двухзвенной модели реализуется с помощью специальных расширений СУБД, например, хранимых процедур. Перенос основных операций приложения на отдельный уровень позволяет с максимальной эффективностью распределить нагрузку на аппаратные средства (трёхзвенная модель на самом деле может быть многозвенной с разделением нагрузки на несколько серверов приложений) и обеспечивает безболезненное наращивание как функциональности приложения, так и числа обслуживаемых пользователей.
11) Системы распределенной обработки данных в основном связаны с первым поколением БД, которые строились на мультипрограммных операционных системах, хранились на устройствах внешней памяти центральной ЭВМ и использовали терминальный многопользовательский режим доступа. При этом пользовательские терминалы не имели собственных ресурсов, т.е. процессоров и памяти, которые могли бы использоваться для хранения и обработки данных.
Для работы с распределенными данными создаются системы управления распределенными базами данных (СУРБД) таким образом, чтобы максимально обеспечить соблюдение принципа независимости прикладных программ от локализации данных в сети, при котором логическое представление распределенной БД и манипулирование данными для прикладной программы ничем не отличаются от соответствующего локального варианта базы. Такие СУРБД оснащены каталогами, в которых хранятся структура сети, информация о локальных СУРБД и базах данных, а также программным обеспечением, которое на основе этой информации управляет взаимодействием прикладной программы и конкретной локальной базой данных сети.
Сложность управления распределенными базами данных во многом зависит от того, поддерживаются ли они однотипными локальными СУРБД, взаимодействие между которыми осуществляется просто. В противном случае приходится включать в такую сеть различные программные и технические устройства, обеспечивающие единый интерфейс, согласование и возможность выполнения информационных процессов, например, использовать промежуточную интерфейсную СУРБД, протокол Z39.50 и др.
12)Сравнительный анализ различных базовых архитектур.В архитектуре «файл-сервер», средства организации и управления БД (в том числе и СУБД) целиком располагаются на машине клиента, а БД, представляющая собой обычно набор специализированных структурированных файлов, – на машине-сервере. В этом случае серверная компонента представлена даже не средствами СУБД, а сетевыми составляющими операционной системы, обеспечивающими удалённый разделяемый доступ к файлам. Таким образом, «файл-сервер» представляет вырожденный случай клиент-серверной архитектуры.Взаимодействие между клиентом и сервером происходит на уровне команд ввода-вывода файловой системы, которая возвращает запись или блок данных. Запрос к базе, сформулированный на языке манипулирования данными, преобразуется самой СУБД в последовательность команд ввода-вывода, которые обрабатываются операционной системой машины-сервера.
Архитектура «выделенный сервер базы данных»- Взаимодействие между клиентом и сервером происходит на уровне команд языка манипулирования данными СУБД (обычно SQL), которые обрабатываются СУБД на машине-сервере. Сервер базы данных осуществляет поиск записей и анализирует их. Записи, удовлетворяющие условиям, могут накапливаться на сервере и после того, как запрос будет целиком обработан, пользователю на клиентскую машину передаются все логические записи (запрашиваемые элементы данных), удовлетворяющие поисковым условиям.
Архитектура «активный сервер баз данных»- функции бизнес-логики разделяются между клиентской и серверной частью. Общие или критически значимые функции оформляются в виде хранимых процедур, включаемых в состав БД. Кроме этого, вводится механизм отслеживания событий БД – триггеров, также включаемых в состав базы. При возникновении соответствующего события (обычно изменения данных), СУБД вызывает для выполнения хранимую процедуру, связанную с триггером, что позволяет эффективно контролировать изменение БД.Хранимые процедуры и триггеры могут быть использованы любыми клиентскими приложениями, работающими с БД. Это снижает дублирование программных кодов и исключает необходимость компиляции каждого запроса.
Архитектура «сервер приложений»- Рассмотренные выше архитектуры являются двухзвенными – все функции доступа и обработки распределены между программой клиента и сервером БД. Дальнейшее снижение требований к ресурсам клиента достигается за счёт введения промежуточного звена – сервера приложений, на который переносится значительная часть программных компонентов управления данными и большая часть бизнес-логики. При этом серверы баз данных обеспечивают исключительно функции СУБД по ведению и обслуживанию БД.
Архитектура один к одному- Повышение эффективности и оперативности обслуживания большого числа клиентских запросов, помимо простого увеличения ресурсов и вычислительной мощности сервера, может быть достигнуто двумя путями:снижением суммарного расхода памяти и вычислительных ресурсов за счёт буферизации (кэширования) и совместного использования (разделяемые ресурсы) наиболее часто запрашиваемых данных и процедур;распараллеливанием процесса обработки запроса – использованием разных процессоров для параллельной обработки изолированных подзапросов и (или) для одновременного обращения к частям БД, размещённым на отдельных физических носителях. Таким образом, даже если от клиентов поступят совершенно одинаковые запросы, для обработки каждого из них будет запущен отдельный процесс, каждый из которых будет выполнять одинаковые действия и использовать одни и те же ресурсы.
13)Архитектура файл сервер: Архитектура с выделенным сервером базы данных:
Архитектура «активный сервер баз данных»: Архитектура сервера приложений
14) Доступ к базам данных в двухзвенных моделях клиент-сервер
В простых двухзвенных моделях клиент-сервер, где несколько БД обслуживают ограниченное число пользователей настольных ПК, в роли встроенного ПО доступа к данным могут выступать обычные ODBC-драйверы.
Необходимость в более сложных решениях возникает в больших, разнородных многозвенных системах, где множество приложений в параллельном режиме осуществляет доступ к разнообразным источникам данных, включая разнотипные СУБД и хранилища данных. В таких системах между клиентами и серверами баз данных размещается промежуточное звено – SQL-шлюз, представляющий набор общих API, позволяющих разработчику строить унифицированные запросы к разнородным данным (в формате SQL или с помощью ODBC-интерфейса). SQL-шлюз выполняет синтаксический разбор такого запроса, анализирует и оптимизирует его и, в конце концов, выполняет преобразование в SQL-диалект нужной СУБД. ПО этого типа реализует синхронный механизм связи, когда выполнение приложения, сделавшего запрос, блокируется до момента получения данных.
Пример такого приложения – система анализа статистических данных о деятельности компаний, отбирающая соответствующую информацию из расположенных в различных регионах БД с разными СУБД. Подобные решения достаточно просты, не требуют сложных механизмов управления транзакциями и способны обеспечить постепенную миграцию важных приложений с унаследованных платформ в архитектуру клиент-сервер. Каждое приложение, построенное на основе архитектуры «клиент-сервер», включает, как минимум, две части:
клиентскую часть, отвечающую за целевую обработку данных и организацию взаимодействия с пользователем;
серверную часть, собственно хранящую данные, обрабатывающую запросы и посылающую результаты клиенту для специальной обработки.
В общем случае предполагается, что эти части приложения функционируют на отдельных компьютерах, т.е. к выделенному серверу БД с помощью сети подключены узлы – компьютеры пользователей (клиенты). При этом узел-клиент сам может быть СУБД.
15) Использование библиотек доступа и встраиваемого sql
Каждая СУБД помимо интерактивной SQL-утилиты обязательно имеет библиотеку процедур доступа и набор драйверов СУБД для различных операционных систем.
Схема взаимодействия с использованием библиотек процедур доступа
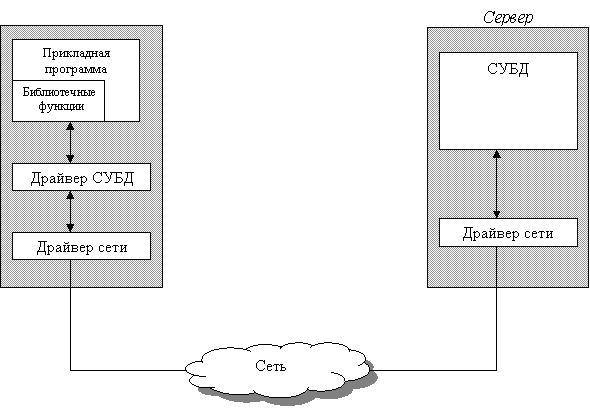
Библиотека доступа содержит набор функций, позволяющих клиентскому приложению соединяться с БД, передавать запросы серверу и получать данные – результаты обработки запроса. Типичный набор функций такой библиотеки включает:
соединение с БД;
запрос к БД на выполнение SQL-выражения;
запрос на извлечение данных;
запрос на изменение данных;
закрытие соединения с БД.
Обычно в библиотеке присутствуют также функции, позволяющие определить характеристики структуры набора результата (число, порядок и имена столбцов, число строк, номер текущей строки), передвигаться по этой структуре не только вперед, но и назад и т.д.
Библиотечные вызовы преобразуются драйвером БД в сетевые вызовы и передаются сетевым ПО на сервер. На сервере происходит обратный процесс преобразования сетевых пакетов в SQL-запросы, которые обрабатываются СУБД. Результаты обработки передаются клиенту.
Такой способ создания приложений достаточно гибок и позволяет реализовать практически любое приложение, однако имеет и недостатки:разработка клиентской программы возможна только для той ОС и на том языке программирования, в которых поддерживается библиотека; драйвер БД определяет допустимые типы сетевых интерфейсов;библиотечные функции обычно неунифицированы.
Некоторой модификацией данного способа является использование «встроенного» языка SQL. В этом случае текст программы на языке третьего поколения вместо вызовов функций библиотеки включает непосредственно предложения SQL, которые предваряются выражением «EXEC SQL». Перед компиляцией в машинный код такая программа обрабатывается препроцессором, который транслирует смесь операторов «собственного» языка СУБД и SQL-предложений в промежуточный «чистый» исходный код, а затем коды SQL замещаются вызовами соответствующих процедур из библиотек, поддерживающих конкретную СУБД. Такой подход позволяет несколько снизить степень привязанности к СУБД, например, при переключении ПП на работу с другим сервером базы данных – достаточно указать новый сервер и заново перекомпилировать программу.
16) Интерфейс уровня вызова - CLI (Call Level Interface), в котором стандартизован общий набор рабочих процедур, обеспечивающий совместимость со всеми основными серверами баз данных. Ключевой элемент CLI - специальная библиотека для компьютера-клиента, в которой хранятся вызовы процедур и большинство часто используемых сетевых компонентов для организации связи с сервером. Это ПО поставляется разработчиком средств SQL, не является универсальным и поддерживает разнообразные транспортные протоколы.
Использование программных вызовов позволяет свести к минимуму операции на компьютере-клиенте. В общем случае клиент формирует оператор языка SQL в виде строки и пересылает ее на сервер посредством процедуры исполнения (execute). Когда же сервер в качестве ответа возвращает несколько строк данных, клиент считывает результат с помощью серии вызовов процедуры выборки данных. Далее информация из столбцов полученной таблицы может быть связана с соответствующими переменными приложения. Вызов специальной процедуры позволяет клиенту определить считанное число строк, столбцов и типы данных в каждом столбце.
Интерфейс CLI построен таким образом, что перед передачей запроса серверу клиент не должен заботиться о типе оператора SQL, будь то выборка, обновление, удаление или вставка
17) Мобильный интерфейс к базам данных на платформе Java.JDBC (Java Data Base Connectivity) – интерфейс прикладного программирования (API) для выполнения SQL-запросов к БД из программ, написанных на платформенно-независимом языке Java, позволяющем создавать как самостоятельные приложения (standalone application), так и апплеты, встраиваемые в web-страницы.JDBC во многом подобен ODBC, он также построен на основе спецификации CLI, однако имеет ряд следующих отличий.приложение загружает JDBC-драйвер динамически, следовательно, администрирование клиентов упрощается, более того, появляется возможность переключаться на работу с другой СУБД без перенастройки клиентского рабочего места.
JDBC, как и Java в целом, не привязан к конкретной аппаратной платформе, следовательно, проблемы с переносимостью приложений практически снимаются.использование Java-приложений и связанной с ними идеологии «тонких клиентов» обещает снизить требования к оборудованию клиентских рабочих мест.
18) OLEDB (ObjectLinkingandEmbeddingDataBase), как и ODBC – прикладные интерфейсы доступа к данным с использованием SQL.
OLEDB специфицирует взаимодействие, обеспечивая единый интерфейс доступа к данным через провайдеров – поставщиков данных не только из реляционных БД. В отличие от ODBC, OLEDB предоставляет общее решение обеспечения COM-приложениям доступа к информации независимо от типа источника данных.
OLEDB включает два базовых компонента: провайдер данных и потребитель данных. Потребитель (клиент) – приложение или COM-компонент, обращающийся посредством API-вызовов к OLEDB. Провайдер (сервер) – приложение, отвечающее на вызовы OLEDB и возвращающее запрашиваемый объект – обычно это данные в табличном виде.
Структурная
схема доступа к данным с использованием
JDBC: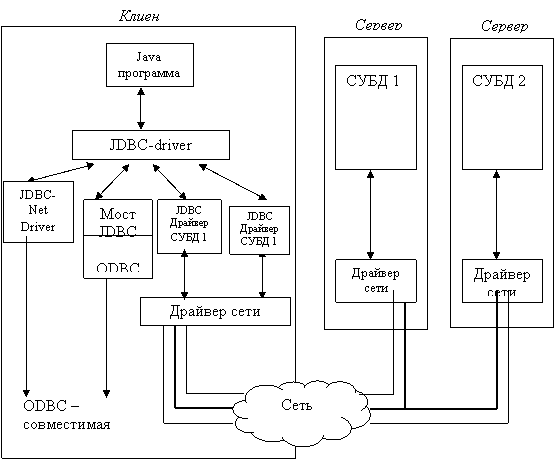
ADO (ActiveDataObject) – универсальный интерфейс высокого уровня к OLEDB. Модель объекта ADO не содержит таблиц, среды или машины БД. Здесь основными объектами являются следующие: объект Соединение, создающий связь с провайдером данных; объект Набор данных и объект Команда – выполнение процедуры, SQL-строки.
В общем случае ADO можно рассматривать как язык программирования с БД, позволяющий выбирать, модифицировать и удалять записи. Поскольку он опирается на универсальный OLEDB, то может использоваться практически в любых приложения Microsoft.
Рассмотренные технологии построения приложения ориентированы на извлечение данных непосредственно из статического источника (хранилища данных) и не могут обращаться за данными к другому прикладному модулю.
19)Определить основные понятия реляционной базы данных. Пояснить какие формы языка SQL существуют и их назначение.Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение.Тип данных - хранение символьных, числовых данных, битовых строк, специализированных числовых данных, а также специальных "темпоральных" данных (дата, время, временной интервал).
Домен - допустимого потенциального множества значений данного типа. Например, домен "Имена" в нашем примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака).
Схема отношения базы данных - это именованное множество пар {имя атрибута, имя домена (или типа, если понятие домена не поддерживается)}. Степень или "арность" схемы отношения - мощность этого множества. Степень отношения СОТРУДНИКИ равна четырем, то есть оно является 4-арным. Если все атрибуты одного отношения определены на разных доменах, осмысленно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута).
Схема базы данных (в структурном смысле) - это набор именованных схем отношений.
Кортеж, соответствующий данной схеме отношения в базе данных, - это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения.
Отношение - это множество кортежей данной базы данных, соответствующих одной схеме отношения. понятие схемы отношения в базе данных ближе всего к понятию структурного типа данных в языках программирования.
Формы языка SQL:
Интерактивный — позволяет конечному пользователю в интерактивном режиме выполнять SQL-операторы.
Статический SQL — может реализовываться как встроенный SQL или модульный, формируется до запуска программы.
Динамический SQL - формирует операторы SQL в ходе работы программы.
Встроенный SQL- позволяет включать операторы SQL в код программы на другом языке программирования (напр., С++).