

Задание 3. Выбор наиболее точной модели связи.
Условие задачи. Исследуется зависимость дозы облучения от толщины слоя защитного материала. Имеются результаты 10 экспериментов (см. рис.6).
Имеются основания предполагать, что зависимость дозы (функция) от толщины слоя материала (аргумент) может выражаться одним из следующих уравнений:
Y=A0 + A1*X (линейная модель);
Y=A0*
 (степенная модель);
(степенная модель);Y=A0+A1/X (гиперболическая модель).
Выберите наиболее точную модель и определите ее коэффициенты.
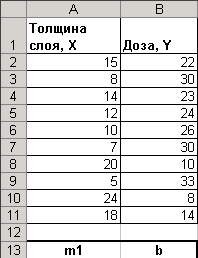
Рис.6 Исходные данные.
Создайте на новом листе таблицу согласно рис. 6.
Постройте на этом же листе точечную диаграмму зависимости Y=f(X).
Нанесите на нее линейный и степенной тренды с уравнениями и величиной достоверности аппроксимации ( ).
Для построения гиперболической модели преобразуйте модель в линейную, получив в ячейках С2:С11 величину 1/Х. А в ячейку С1 введите заглавие: «Величина U=1/X».
Используя функцию ЛИНЕЙН, получите в ячейках А14:В14 коэффициенты уравнения m1 и b (т.е. уравнение Y= b+m1*U).
В ячейку A16 введите заголовок «Гиперболическая модель». В ячейку A17 введите уравнение Y= b+m*x (вместо b и m укажите конкретные числа).
Для построенной гиперболической модели найдите величину достоверности аппроксимации. Для этого найдите сначала среднее значение c помощью функции СРЗНАЧ в ячейке D2. В ячейку D1 введите заглавие «Ср. знач. Y».
В столбце E2:E11 получите модельные значения
 путем подстановки значений U
из блока ячеек С2:С11 в построенную
модель. Для этого в ячейку E2
введите формулу =$B$14+$A$14*C2.
Скопируйте формулу вниз в смежные
ячейки. В ячейку E1
введите заголовок: «Модельные
значения Y».
путем подстановки значений U
из блока ячеек С2:С11 в построенную
модель. Для этого в ячейку E2
введите формулу =$B$14+$A$14*C2.
Скопируйте формулу вниз в смежные
ячейки. В ячейку E1
введите заголовок: «Модельные
значения Y».Найдите сумму квадратов
 ,
скорректированную на среднее:
,
скорректированную на среднее: .
Для этого в столбце F2:F11
получите разность
.
Для этого в столбце F2:F11
получите разность
 .
В ячейку F1
введите заголовок:
«Yi-Ycp.».
.
В ячейку F1
введите заголовок:
«Yi-Ycp.».В столбце G2:G11 получите квадраты разностей, а в ячейку G1 введите заголовок: «(
 ».
».В ячейке Н2 получите итоговую сумму, а в ячейку Н1 введите заголовок: «SSy».
Аналогичным образом найдите сумму квадратов прогнозируемых (модельных) значений, скорректированную на среднее
 .
Для этого используйте столбцы I,
J,
K.
.
Для этого используйте столбцы I,
J,
K.Найдите величину достоверности аппроксимации:
 в ячейке L2.
в ячейке L2.По значениям коэффициентов достоверности аппроксимации выберите наиболее точную модель, которая соответствует максимальному коэффициенту достоверности.
Копия экрана Задания 3. приведена на рис. 7.
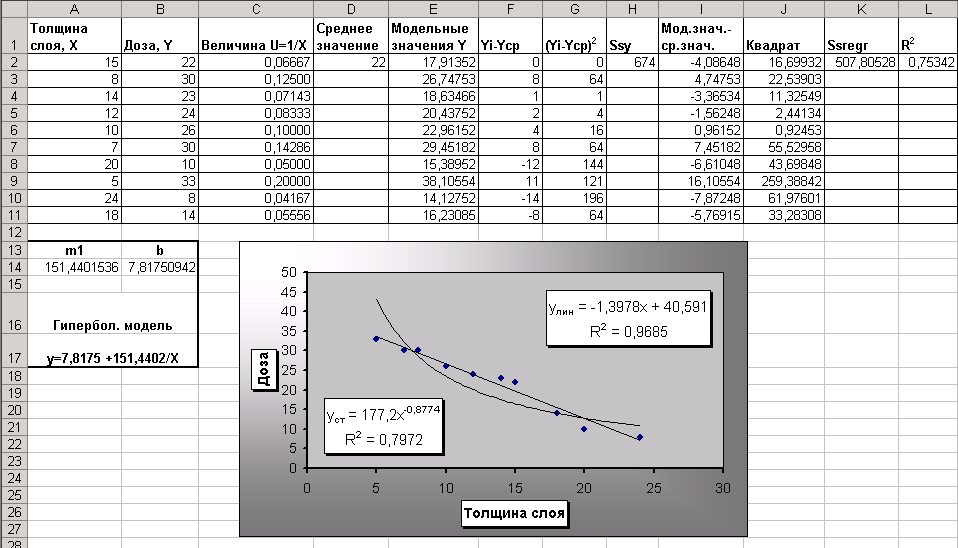
Рис. 7. Расчеты гиперболической модели.
Проверьте правильность вычислений, воспользовавшись инструментом анализа Регрессия.
Задания для самостоятельной работы.
1. Имеются данные по двум экономическим показателям X и Y. Необходимо:
Вычислить коэффициент корреляции.
Построить корреляционное поле.
Построить регрессионную модель (с использованием функции ЛИНЕЙН).
-
Цена (X)
997
987
1002
1012
1011
1017
978
997
1010
989
Спрос (Y)
120
140
115
100
100
90
150
130
95
155
2. Установить, зависит ли количество посетителей музея и посетителей парка от числа ясных дней за определенный период. Для этого:
Вычислить коэффициенты корреляции.
Построить корреляционное поле.
Построить регрессионную модель (графическим способом и с помощью инструмента Регрессия).
Число ясных дней (Х) |
8 |
14 |
20 |
25 |
20 |
15 |
Количество посетителей музея (Y) |
495 |
503 |
380 |
305 |
348 |
465 |
Количество посетителей парка (Y) |
132 |
348 |
643 |
865 |
743 |
541 |
2. Методические положения проведения регрессионного анализа.
1 этап. Первым этапом составления прогноза проводится анализ зависимости между двумя переменными с помощью метода наименьших квадратов. Для наглядного изображения исходных данных, дальнейшего анализа и прогнозирования составляется диаграмма рассеивания исходных данных. Оценивается выборочный коэффициент корреляции, по результатам расчетов необходимо сделать соответствующие выводы.
2 этап. Построение прямой регрессии с помощью метода наименьших квадратов.
Для набора пар данных X — Y в качестве прямой наилучшего приближения будет выбираться такая, для которой наименьшее значение принимает сумма квадратов расстояний от точек (х, у) из заданного набора данных до этой прямой, измеренных в вертикальном направлении (по оси Y). Эта прямая называется прямой регрессии, а ее уравнение — уравнением регрессии.
Уравнение
прямой приближения имеет вид
![]() .
Первый
параметр
.
Первый
параметр
![]() называется
свободным членом, а второй
называется
свободным членом, а второй
![]() —
угловым
коэффициентом, отражающим величину,
на которую изменяется значение Y
при
увеличении X
на
единицу. Таким образом, необходимо
определить данные параметры.
—
угловым
коэффициентом, отражающим величину,
на которую изменяется значение Y
при
увеличении X
на
единицу. Таким образом, необходимо
определить данные параметры.
Построение прямой регрессии проводится с помощью критерия наименьших квадратов.
![]() (4.1)
(4.1)
 ,
(4.2)
,
(4.2)
![]() ,
(4.3)
,
(4.3)
где - свободный член;
- угловой коэффициент;
SSE – сумма квадратов ошибок.
Как можно предположить, значение углового коэффициента связано с выборочным коэффициентом корреляции. В данном случае получается следующее:
 .
(4.4)
.
(4.4)
Значит и b0 пропорциональны друг другу и имеют один и тот же знак.
Разности
между фактически полученными значениями
Y
и вычисленными по уравнению регрессии
соответствующими значениями прогнозов
![]() называются
отклонениями.
Отклонения
— это расстояния по вертикали
(положительные или отрицательные) от
точек, отмеченных по исходным данным,
до прямой регрессии.
называются
отклонениями.
Отклонения
— это расстояния по вертикали
(положительные или отрицательные) от
точек, отмеченных по исходным данным,
до прямой регрессии.
Можно сказать, что величины прогноза являются моделируемыми значениями рассматриваемых данных, а отклонения показывают отличие от ожидаемой модели. Разделение на прогноз и отклонение применяется и в тех ситуациях, когда рассматривается модель, отличная от прямой линии.
В модели простой линейной регрессии зависимая величина Y является суммой ее математического ожидания и случайного отклонения ε. Значения ε отражают возможную вариацию величин Y, в них скрыто влияние различных ненаблюдаемых факторов.
3 этап. Определение стандартной ошибки оценки.
Имея
прямую регрессии, можно определить,
насколько сильно точки исходных данных
отклоняются от прямой регрессии. Можно
выполнить оценку разброса, аналогичную
стандартному отклонению выборки.
Этот показатель, называемый стандартной
ошибкой оценки,
измеряет степень отличия реальных
значений Y
от
оцененной
величины
![]() .
Она обозначается
через
.
Она обозначается
через
![]() и вычисляется по следующей формуле:
и вычисляется по следующей формуле:
 .
(4.5)
.
(4.5)
Стандартная
ошибка оценки подобна стандартному
отклонению. Ее можно использовать для
оценки стандартного отклонения
совокупности. Фактически
оценивает стандартное отклонение σ
слагаемого ошибки в статистической
модели простой линейной регрессии.
Другими словами
оценивает общее стандартное отклонение
σ
нормального распределения значений Y,
имеющих математические ожидания
![]() +
ε
для каждого X.
+
ε
для каждого X.
Если стандартная ошибка оценки велика, точки данных могут значительно удаляться от прямой.
Для удобства вычислений уравнение (4.5) можно привести к следующему виду:
 .
(4.6)
.
(4.6)
4 этап. Прогнозирование величины Y.
Регрессионную прямую можно использовать для оценки величины переменной Y при данных значениях переменной X. Чтобы получить точечный прогноз, или предсказание для данного значения X, необходимо вычислить значение найденной функции регрессии в точке X.
Есть два источника неопределенности в точечном прогнозе, использующем уравнение регрессии.
Неопределенность, обусловленная отклонением точек данных от выборочной прямой регрессии.
Неопределенность, обусловленная отклонением выборочной прямой регрессии от регрессионной прямой генеральной совокупности.
Интервальный прогноз значений переменной Y можно построить так, что при этом будут учтены оба источника неопределенности.
Стандартная
ошибка прогноза
![]() дает
меру вариативности предсказанного
значения Y
около истинной величины Y
для данного значения X.
Стандартная ошибка прогноза равна
следующему:
дает
меру вариативности предсказанного
значения Y
около истинной величины Y
для данного значения X.
Стандартная ошибка прогноза равна
следующему:
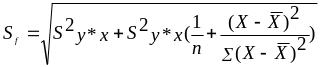 ;
(4.7)
;
(4.7)
. (4.8)
Первое
слагаемое
(4.8)
Первое
слагаемое
![]() под первым радикалом в уравнении 5.7 дает
меру отклонения точек данных от выборочной
прямой регрессии (первый источник
неопределенности). Второе слагаемое
под первым радикалом в уравнении 5.7 дает
меру отклонения точек данных от выборочной
прямой регрессии (первый источник
неопределенности). Второе слагаемое
![]() измеряет отклонение выборочной прямой
регрессии от регрессионной прямой
генеральной совокупности (второй
источник неопределенности). Отметим,
что стандартная ошибка прогноза зависит
от значения X,
для которого прогнозируется величина
Y.
Также
следует отметить, что
минимально, когда X
=
измеряет отклонение выборочной прямой
регрессии от регрессионной прямой
генеральной совокупности (второй
источник неопределенности). Отметим,
что стандартная ошибка прогноза зависит
от значения X,
для которого прогнозируется величина
Y.
Также
следует отметить, что
минимально, когда X
=
![]() , поскольку
тогда числитель в третьем слагаемом
под корнем в уравнении 4.7 будет
, поскольку
тогда числитель в третьем слагаемом
под корнем в уравнении 4.7 будет
![]() = 0 . При прочих неизменных величинах
большему отличию X
от
соответствует
большее значение стандартной ошибки
прогноза.
= 0 . При прочих неизменных величинах
большему отличию X
от
соответствует
большее значение стандартной ошибки
прогноза.
Если статистическая модель простой линейной регрессии соответствует действительности, границы интервала прогноза величины Y равны следующему:
![]() tsf ,
(4.9)
tsf ,
(4.9)
где t — квантиль распределения Стьюдента с п-2 степенями свободы (df=n-2).
Если
выборка велика (n![]() 30),
этот квантиль можно заменить соответствующим
квантилем стандартного нормального
распределения. Например, для большой
выборки 95%-ный интервал прогноза задается
следующими значениями:
30),
этот квантиль можно заменить соответствующим
квантилем стандартного нормального
распределения. Например, для большой
выборки 95%-ный интервал прогноза задается
следующими значениями:
![]() .
(4.10)
.
(4.10)
5 этап. Разложение дисперсии.
Из уравнения можно выявить следующее:
![]() или
или
![]() (4.11)
(4.11)
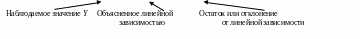
В идеале, когда все точки лежат на прямой регрессии, все остатки равны нулю и значения Y полностью вычисляются или объясняются линейной функцией от X.
Отнимая
![]() от
обеих частей предыдущего равенства,
имеется следующее:
от
обеих частей предыдущего равенства,
имеется следующее:
![]() .
(4.12)
.
(4.12)
Несложными алгебраическими преобразованиями можно показать, что суммы квадратов складываются:
![]() (4.13)
(4.13)
или
SST=SSR+SSE , (4.14)
где
SST=![]() ,
SSR=
,
SSR=![]() ,
SSE=
,
SSE=![]() .
.
Здесь SS обозначает "сумма квадратов'' (Sum of Squares), а Т, R, Е — соответственно "общая" (Total), "регрессионная" (Regression) и "ошибки" (Еrrоr). С этими суммами квадратов связаны следующие величины степеней свободы:
df (SST) = n-1;
df (SSR) = n;
df (SSE) = n-2.
Так же, как и суммы квадратов, степени свободы связаны следующим соотношением.
n – 1 = 1 + (n-2) . (4.15)
Если линейной связи нет, Y не зависит от X и дисперсия Y оценивается значением выборочной дисперсии:
![]() .
(4.16)
.
(4.16)
Если, с другой стороны, связь между X и Y имеется, она может влиять на некоторые разности значений Y.
Регрессионная сумма квадратов, SSR, измеряет часть дисперсии Y, объясняемую линейной зависимостью. Сумма квадратов ошибок, SSE, — это оставшаяся часть дисперсии Y, или дисперсия Y, не объясненная линейной зависимостью.
Разложение дисперсии |
||
SST = |
SSR + |
SSE |
Общая изменчивость Y |
Изменчивость, объясненная линейной зависимостью |
Остаток, или необъясненная изменчивость |
Суммы квадратов, связанные с разложением изменчивости Y, и их соответствующие величины степеней свободы могут быть размещены так, как показано в табл. 4.1, известной как таблица анализа дисперсии или таблица ANOVA (ANalisis Of VArianse).
Таблица 4.1
Таблица ANOVA для прямолинейной регрессии
Источник |
Сума квадратов |
Степени свободы |
Среднеквадратическое отклонение |
Регрессия |
SST |
1 |
MSR = SSR / 1 |
Ошибки |
SSE |
n - 2 |
MSE = SSE / (n-2) |
Общая |
SSR |
n - 1 |
|
Последний столбец таблицы ANOVA — это среднеквадратичные значения. Среднеквадратичное регрессии, MSR — это регрессионная сумма квадратов, разделенная на их величину степеней свободы. Аналогично среднеквадратичное ошибок, МSЕ — это сумма квадратов ошибок, разделенная на их величину степеней свободы.
Из уравнения 4.8 имеется следующее:
![]()
, (4.17)
т.е. равенство МSЕ квадрату стандартной ошибки оценки. Отношение среднеквадратичных значений будет использовано для другой цели в этой главе дальше.
6 этап. Определение коэффициента детерминации.
Коэффициент детерминации измеряет долю изменчивости Y, которую можно объяснить с помощью информации об изменчивости (разнице значений) независимой переменной X.
Тождество (формула 4.14) приводит к разбиению дисперсии, данному в уравнении 4.15. Для регрессионной прямой данных проводимого прогноза гипотетических точек данных разбиение графически представлено на рис. 4.2.
Если
величина Y
не зависит от X,
специалисту следует ожидать значения
Y,
близкие к
![]() ,
а разности Y
-
просто
отражают случайные отклонения. Однако
в действительности величина Y
зависит от X,
что демонстрируется функцией регрессии.
На рисунке взято значение
X,
большее
,
и известно, что X
и
Y
имеют
значительную отрицательную корреляцию
(r
= -0,86). Общее расстояние по вертикали
равно Y
-
,
величина
-
,
следовательно
"объясняется" изменением X,
тогда
как оставшееся по вертикали расстояние
Y
-
"не
объясняется" изменением X.
,
а разности Y
-
просто
отражают случайные отклонения. Однако
в действительности величина Y
зависит от X,
что демонстрируется функцией регрессии.
На рисунке взято значение
X,
большее
,
и известно, что X
и
Y
имеют
значительную отрицательную корреляцию
(r
= -0,86). Общее расстояние по вертикали
равно Y
-
,
величина
-
,
следовательно
"объясняется" изменением X,
тогда
как оставшееся по вертикали расстояние
Y
-
"не
объясняется" изменением X.
Показатель SST измеряет общую вариацию относительно , а ее часть, объясненная изменением X, соответствует SSR. Оставшаяся, или необъясненная вариация соответствует SSE. Отношение объясненной вариации к общей называется выборочным коэффициентом детерминации и обозначается r2.
 (4.18)
(4.18)

Рис. 4.2. Объясненная и необъясненная дисперсии для данных прогноза
3. Практический пример построения прогноза на основе регрессионного анализа.
Специалист планово-экономического отдела (ПЭО) машиностроительного завода изучает цены и объемы продажи изделия, выбрав произвольным образом десять недель. Собранные им данные представлены в табл. 4.2.
Таблица 4.2
Данные о продаже изделия
Номер недели |
Количество проданного изделия (тыс. шт) - Y |
Цена одного изделия (усл. ед) - Х |
1 |
10 |
1,3 |
2 |
6 |
2,0 |
3 |
5 |
1,7 |
4 |
12 |
1,5 |
5 |
10 |
1,6 |
6 |
15 |
1,2 |
7 |
5 |
1,6 |
8 |
12 |
1,4 |
9 |
17 |
1,0 |
10 |
20 |
1,1 |
Решение.
Этап 1. Для наглядного изображения исходных данных и дальнейшего анализа и прогнозирования составляется диаграмма рассеивания для исходных данных, представленная на рис. 4.3.
 Рис.
4.3. Диаграмма рассеивания
Рис.
4.3. Диаграмма рассеивания
Диаграмма показывает, что имеет место обратная линейная зависимость между переменной Y (количеством проданных изделий) и переменной X (ценой одного изделия). Можно сделать вывод, что при возрастании цены объем продаж уменьшается.
Таким образом, далее целесообразно оценить количественную меру обнаруженной зависимости. Для этого вычисляется выборочный коэффициент корреляции на основе формулы 4.19.
![]() .
(4.19)
.
(4.19)
Вспомогательные расчеты представляются в таблице 4.3.
Таблица 4.3
Расчеты коэффициента корреляции
n=10 |
Y |
X |
XY |
Y2 |
Х2 |
|
10,0 |
1,3 |
13,00 |
100,00 |
1,69 |
6,0 |
2,0 |
12,00 |
36,00 |
4,00 |
|
5,0 |
1,7 |
8,50 |
25,00 |
2,89 |
|
12,0 |
1,5 |
18,00 |
144,00 |
2,25 |
|
10,0 |
1,6 |
16,00 |
100,00 |
2,56 |
|
15,0 |
1,2 |
18,00 |
225,00 |
1,44 |
|
5,0 |
1,6 |
8,00 |
25,00 |
2,56 |
|
12,0 |
1,4 |
16,80 |
144,00 |
1,96 |
|
17,0 |
1,0 |
17,00 |
289,00 |
1,00 |
|
20,0 |
1,1 |
22,00 |
400,00 |
1,21 |
|
Сумма |
112,0 |
14,4 |
149,30 |
1488,00 |
21,56 |
![]() .
.
Расчеты коэффициента корреляции достаточно просто можно провести в Excel: Сервис → Анализ данных → Корреляция.
По результатам расчетов значение выборочного коэффициента корреляции, равное -0,86, указывает на довольно тесную обратную зависимость между переменными Y и Х, т.е. при возрастании цены одного изделия количество продаваемых изделий падает.
При этом возникает следующий вопрос: на сколько уменьшается продажа изделий при увеличении его цены? В данном случае на диаграмме рассеивания можно провести прямую, проходящую достаточно близко от отмеченных точек. Тогда наклон прямой покажет, на сколько изделий в среднем будет уменьшаться величина Y при увеличении величины Х на одну усл. ед.
Этап 2. Провести требуемую прямую, визуально сориентировав ее так, чтобы она находилась как можно ближе к отмеченным на диаграмме точкам, можно по-разному. Необходим такой способ нахождения прямой наилучшего приближения, при использовании которого любой человек будет получать один и тот же результат для заданного набора данных. Для однозначного определения прямой наилучшего приближения чаще всего применяется критерий наименьших квадратов.
С помощью метода наименьших квадратов вычисляются оценки коэффициентов регрессии для данных специалиста ПЭО. Вычисления проводятся на основе уравнений 4. 3 и 4. 4, а также числовых значений из табл. 4.3. Определяется следующее:
![]() ,
,
![]() .
.
Тогда уравнение прямой регрессии, определенное по методу наименьших квадратов, будет иметь следующий вид:
![]() . (4.21)
. (4.21)
Смысл коэффициентов из этого уравнения: свободный член — это значение Y при X, равном нулю. Формально интерпретируя уравнение, получаем, что при Х = 0 (т.е. при нулевой стоимости изделия) среднее количество продаваемых изделий будет равно 32 140. Это не соответствует здравому смыслу. Данная проблема связана с прогнозом значений Y для значений X, заметно отличающихся от тех, которые представлены в выборке данных. Так, в выборке нет величин X, близких к нулю. В этой ситуации, как и во многих других случаях применения регрессионного анализа, разумная интерпретация свободного члена уравнения регрессии не представляется возможной.
В общем случае неразумно прогнозировать значения Y для тех X, которые лежат вне множества значений переменной X, встречающихся в выборке. Функцию регрессии следует считать подходящей аппроксимацией реальной ситуации только в той области, из которой взяты анализируемые данные. Экстраполяция функции вне этой области возможна только при справедливости достаточно ограничивающего предположения о том, что характер зависимости Y от X при этом не изменяется.
Угловой коэффициент можно интерпретировать как среднее изменение величины Y при возрастании Х на единицу. В данном примере Y в среднем уменьшается на 14 540 (т.е. будет продано на 14 540 тыс. шт. меньше) при возрастании X на единицу (т.е. при возрастании цены изделия на одну усл. ед.). Каждое увеличение цены на одну усл. ед. уменьшает объем продажи в среднем на 14 540 изделий, т.е. наша выборка показывает, что увеличение цены на одну усл. ед. уменьшает количество продаваемых изделий на 14,54.
Связь значений переменных X и Y может быть проиллюстрирована на диаграмме рассеивания путем проведения прямой, являющейся наилучшим приближением этой зависимости (рис. 4.4).






Рис. 4.4. Данные прогноза
Обратите внимание на то, что вертикальные отрезки от точек данных до прямой проведены
пунктиром. Сумма квадратов длин отрезков, проведенных к этой прямой, должна быть меньше аналогичной суммы квадратов длин, проведенных к любой другой прямой. (Для данных специалиста ПЭО сумма квадратов длин равна SSЕ = 59,14). Из метода наименьших квадратов следует, что данная прямая является наилучшим приближением для заданных 10 точек исходных данных.
Этап 3. Определение стандартной ошибки.
Для данных специалиста ПЭО стандартная ошибка оценки равна следующему:
 .
.
Для величины Y принимающей значения от 3 до 18 (рис. 4.4), значение = 2,72 довольно велико и указывает, что существенная часть вариации величины Y (количества проданных изделий) не объясняется изменением величины X (цены). Это утверждение будет исследовано позже.
Этап 4. Прогнозирование величины Y.
Предположительно специалист хочет получить прогноз количества изделий, которое будет продано при цене 1,63 усл. ед. за штуку. Из уравнения (4.21) получается 8440 штук.
![]() .
.
Данный прогноз — это значение величины Y. Поэтому интересующий прогноз будет координатой Y точки с координатой X = 1,63 на регрессионной прямой.
Конечно, реальные значения величины Y, соответствующие рассматриваемым значениям величины X, к сожалению, не лежат в точности на регрессионной прямой. Фактически они разбросаны относительно прямой в соответствии с величиной . Более того, выборочная (построенная графически) регрессионная прямая является оценкой регрессионной прямой генеральной совокупности, основанной на выборке всего лишь из 10 пар данных. Другая случайная выборка 10 пар данных даст иную выборочную прямую регрессии; это аналогично ситуации, когда различные выборки из одной и той же генеральной совокупности дают различные значения выборочного среднего.
Графически 95%-ный интервал прогноза значений Y для данных специалиста представлен на рис. 4.5.
Y

Рис. 4.5. 95%-ный интервал прогноза значений Y
Используя результаты из табл. 4.3 и уравнения 4.11, где X =1,44 , определяется стандартная ошибка прогноза в точке X = 1,63.
Таблица 4.4
Расчет стандартной ошибки прогноза
X |
|
1,3 |
0,0196 |
2,0 |
0,3136 |
1,7 |
0,0676 |
1,5 |
0,0036 |
1,6 |
0,0256 |
1,2 |
0,0576 |
1,6 |
0,0256 |
1,4 |
0,0016 |
1,0 |
0,1936 |
1,1 |
0,1156 |
|
|
 .
.
При
![]() и X=1,63,
используя уравнение 11, определяется
95%-ный
интервал прогноза значений Y:
и X=1,63,
используя уравнение 11, определяется
95%-ный
интервал прогноза значений Y:
![]() =8,44
=8,44
![]() 2,306*2,91=8,44
6,71
2,306*2,91=8,44
6,71
или (1,73;15,15), т.е. от 1730 до 15150 штук.
Здесь
2,306=![]() -
это нижний 2,5%-ый квантиль; t
–
распределения с 8 степенями свободы.
-
это нижний 2,5%-ый квантиль; t
–
распределения с 8 степенями свободы.
Интервал прогноза настолько велик, что практически бесполезен для прогнозирования значений величины Y. Это связано с тем, что исходная выборка мала, а значение сравнительно велико. Степень неопределенности, представленная большим интервалом прогноза, не видна по отдельным точечным прогнозам, полученным из функции регрессии. Значительным преимуществом интервальной оценки является явное отражение неопределенности, связанной с прогнозом.
Вообще говоря, опасно использовать регрессионную функцию для предсказания значений величины Y вне области имеющихся данных. Специалист вполне оправданно пытается получить прогноз для величины Y при Х= 1,63, поскольку некоторые из имеющихся в исходных данных значений X близки к 1,63. С другой стороны, нельзя прогнозировать значение Y при X=3,00. Среди исходных данных нет таких больших значений X и поэтому любой прогноз значения Y для подобного значения X очень сомнителен. При попытке оценить количество изделий, которое может быть продано по цене 3 усл. ед. за штуку, специалист должен исходить из предположения, что при подобных значениях цены линейная модель остается верной. У него могут быть определенные причины считать так, однако никаких явных свидетельств этого не существует.
Этап 5. Разложение дисперсии.
Специалист
ПЭО начал свой анализ данных с информации
об объемах продаж только за 10 недель
(переменная Y).
Если другой информации не поступит, он
может использовать выборочное среднее
Y=11,2
как прогноз количества продаваемых
изделий для каждой недели. Ошибки или
отклонения, связанные с этим прогнозом,
равны Y
-
,
и сумма квадратов ошибок даст
.
Последнее значение,
,
в
точности равно SST,
обшей сумме квадратов, введенной в
уравнение 5.10. Таким образом, SSТ
измеряет отклонение значения Y
от прогноза, использующего лишь значения
Y
в его вычислении. (Если анализ остановить
на этом этапе, отклонения Y
следует измерять выборочной дисперсией
![]() вместо
SST=
.
Выборочная дисперсия является обычной
мерой изменчивости наблюдений одной
переменной.) Прогноз величины
,
значения отклонения Y
-
суммы квадратов SST=
приведены
в табл. 4.5. (Сумма отклонений Y
—
всегда равна нулю, поскольку среднее
является математическим центром значений
Y).
вместо
SST=
.
Выборочная дисперсия является обычной
мерой изменчивости наблюдений одной
переменной.) Прогноз величины
,
значения отклонения Y
-
суммы квадратов SST=
приведены
в табл. 4.5. (Сумма отклонений Y
—
всегда равна нулю, поскольку среднее
является математическим центром значений
Y).
Таблица 4.5
Отклонения для данных прогноза и значения прогноза
Данные Y |
Прогноз Y ( ) |
Отклонения (Y- ) |
(Y- )2 |
10 |
11,2 |
-1,2 |
1,44 |
6 |
11,2 |
-5,2 |
27,04 |
5,0 |
11,2 |
-6,2 |
38,44 |
12,0 |
11,2 |
0,8 |
0,64 |
10,0 |
11,2 |
-1,2 |
1,44 |
15,0 |
11,2 |
3,8 |
14,44 |
5,0 |
11,2 |
-6,2 |
38,44 |
12,0 |
11,2 |
0,8 |
0,64 |
17,0 |
11,2 |
5,8 |
33,64 |
20,0 |
11,2 |
8,8 |
77,44 |
Сумма: |
0,0 |
233,6 |
|
Прогнозист также имеет информацию о значениях переменной X (о цене одного изделия), соответствующих величинам Y. (r = -0,86.) Можно ожидать, что с помощью этой дополнительной переменной мы сможем объяснить часть изменчивости (разностей) значений Y, не объясненной прогнозом .
По
расчетам линейный прогноз пар значений
Х-Y
задается
уравнением
= 32,14
- 14,54X.
Таблица,
подобная табл. 5.5, может быть построена
при
в
качестве прогноза значений Y.
Результат
приводится в табл. 4.6. (Если свободный
член включен в уравнение регрессии,
сумма отклонений
![]() всегда равна нулю).
всегда равна нулю).
Таблица 4.6
Отклонения для данных при значении прогноза
X |
Y |
Прогноз Y ( ), использующий уравнение |
Отклонения (Y- ) |
(Y- )2 |
1,3 |
10,0 |
13,238 |
-3,238 |
10,485 |
2,0 |
6,0 |
3,06 |
2,940 |
8,644 |
1,7 |
5,0 |
7,422 |
-2,422 |
5,866 |
1,5 |
12,0 |
10,33 |
1,670 |
2,789 |
1,6 |
10,0 |
8,876 |
1,124 |
1,263 |
1,2 |
15,0 |
14,692 |
0,308 |
0,095 |
1,6 |
5,0 |
8,876 |
-3,876 |
15,023 |
1,4 |
12,0 |
11,784 |
0,216 |
0,047 |
1,0 |
17,0 |
17,6 |
-0,600 |
0,360 |
1,1 |
20,0 |
16,146 |
3,854 |
14,853 |
Сумма: |
0,0 |
59,41 |
||
Сравнение табл. 4.5 и 4.6 показывает, что использование в качестве прогноза значения Y приводит, вообще говоря, к меньшим отклонениям (по абсолютной величине) и существенно меньшим суммам квадратов остатков (ошибок), чем применение для прогноза значения . Использование соответствующих значений X уменьшает ошибку прогноза (предсказания). Таким образом, знание значений X помогает лучше объяснить разности Y. Но в какой мере может помочь знание значений X? Ответ на этот вопрос можно получить посредством разбиения изменчивости.
Используя данные из табл. 4.5, 4.6 и уравнение 4.14, имеется
SST= =233,6;
SSE= =59,41
и, следовательно,
SSR= = SST- SSE = 233,6 - 59,41 = 174,19.
Разбиение изменчивости является следующим:
SST = |
SSR + |
SSE |
233,6 = |
174,19 + |
59,41 |
Общая вариация |
Объясненная вариация |
Необъясненная вариация |
Для изменчивости, оставшейся после предсказания Y через значение , специалист получил следующее значение:
![]() .
.
Это та часть, которая объясняется взаимосвязью значений Y и X. Доля вариации Y относительно , равная 1 – 0,75 = 0,25, осталась необъясненной. С этой точки зрения знание значений соответствующей переменной X приводит к лучшему прогнозу значений Y, чем прогноз, полученный из значения , не зависящего от Х.
Разбиение изменчивости для данных прогноза может быть представлено в таблице анализа дисперсии ANOVA, общий вид которой представлен в табл. 4.1., 4.7.
Таблица 4.7
Таблица ANOVA по данным прогноза
Источник |
Сумма квадратов |
Степени свободы |
Среднеквадратическое отклонение |
Регрессия |
174,19 |
1 |
174,19 |
Ошибки |
59,41 |
8 |
7,43 |
Общая |
233,6 |
9 |
|
Разбиение изменчивости ясно показано в столбце с суммами квадратов. Необходимо обратить внимание на то, что с учетом погрешности округления MSE=7,43=(2,72)2 = .
Этап 6. Расчет коэффициента детерминации r2 .
Для данных прогнозиста коэффициент был вычислен ранее. Значение коэффициента детерминации также можно легко получить из таблицы ANOVA, представленной табл. 5.7.
SST= =233,6; SSR= = 174,19; SSE= =59,41
и
r2=![]() .
.
Кроме того, r2 можно вычислить следующим образом:
r2=![]() .
.
Около 75% изменчивости количества проданных штук изделий (Y) можно объяснить разницей в цене изделия (X). Около 25% изменчивости количества проданного молока нельзя объяснить изменением цены. Эта часть изменчивости может быть объяснена влиянием факторов, не учтенных в проведенном регрессионном анализе (например, рекламой, возможностью замены изделий, качеством материалов и т.п.).
В случае прямолинейной регрессии коэффициент детерминации r2 равен квадрату коэффициента корреляции r:
коэффициент детерминации = (коэффициент корреляции)2,
r2 = (r)2.
Значит для данных специалиста, с учетом погрешности округления,
0,746 = (-0,843)2.
Почему в регрессионном анализе коэффициенты r и r2 необходимо рассматривать отдельно? Причина в том, что они несут различную информацию.
Коэффициент корреляции выявляет не только силу, но и направление линейной связи. В случае данных, собранных прогнозистом, имеет место отрицательная взаимосвязь (r = -0,86). В других случаях значение r может указывать на положительную взаимосвязь. Когда существует дело с большим набором переменных, иногда полезно учитывать характер взаимосвязи в некоторых парах переменных. Следует отметить, что когда коэффициент корреляции возводится в квадрат, полученное значение всегда будет положительным и информация о характере взаимосвязи теряется.
Коэффициент детерминации r2 измеряет силу взаимосвязи между Y и X иначе, чем коэффициент корреляции r. Значение r2 измеряет долю изменчивости Y, объясненную разницей значений X. Эту полезную интерпретацию можно обобщить на взаимосвязь между Y и более чем одной переменной X.
На рис. 4.6 иллюстрируется два крайних случая для значения коэффициента r2: r2 = 0 и r2=1. В случае (а) изменчивость Y никак не объясняется изменениями X: диаграмма рассеивания не показывает никакой линейной взаимосвязи между значениями величин X и Y. В случае (б), когда коэффициент r2 = 1, изменчивость Y полностью объясняется, если известны значения X: все точки данных в нашей выборке лежат на прямой регрессии.
X


![]()
![]()
а) линейная корреляция отсутствует б) четко выраженная линейная корреляция
Рис. 4.6. Интерпретация крайних значений коэффициента детерминации r2
Примечание. Проведенные расчеты представленных и прогнозируемых данных по всем пунктам можно проверить с помощью компьютерных расчетов в Excel – функции регрессионного анализа.
4. Задание лабораторной работы.
Примечание. В большинстве из приведенных ниже упражнений представлены данные, предназначенные для обработки с помощью процедур регрессионного анализа. Хотя в одном или двух случаях возможно, и даже полезно, выполнение необходимых вычислений вручную, для студента важно научиться использовать компьютер для решения подобных задач.
Общие задания для выбранных по вариантам задач.
Существует ли значимая взаимосвязь между рассматриваемыми показателями Х и Y, пояснить какая.
Построить диаграмму рассеивания для имеющихся данных.
Вычислить коэффициент корреляции и интерпретировать его значения.
Определить регрессионную прямую методом наименьших квадратов.
Проверить значимость углового коэффициента на 5%-ном уровне значимости. Является ли значимым коэффициент корреляции? Объяснить полученные результаты.
Определить уравнение регрессии.
Построить таблицу ANOVA, рассмотреть остатки.
Составьте отчет, содержащий объяснения по результатам выполненного анализа.
Вариант
1.
Рассмотрите данные в табл. 4.8., где в
столбце X
приведены
суммы еженедельных расходов на рекламу
АЗС, а в столбце
![]() —
еженедельный объем продаж. Используя
эти данные, ответьте на вопросы 1, 7, 8.
—
еженедельный объем продаж. Используя
эти данные, ответьте на вопросы 1, 7, 8.
Таблица 4.8
Исходные данные
Y (усл. ед.) |
Х(усл. ед.) |
Y (усл. ед.) |
Х (усл. ед.) |
1250 |
41 |
1300 |
46 |
1380 |
54 |
1400 |
62 |
1425 |
63 |
1510 |
61 |
1425 |
54 |
1575 |
64 |
1450 |
48 |
1650 |
71 |
Необходимо определить уравнение для расчета прогноза результирующего показателя. Какой процент вариаций показателя Х, Y объясняется уравнением прогноза? Составить прогноз показателя Y при составляющих (п+1) значения (выбор значения Х произвольное).
Определить величину необъясненной и общей вариации.
Вариант 2. Сведения о времени, затраченном на обслуживание станка, и соответствующих объемах произведенных изделий приведены в табл. 4.9. Используя эти данные, ответить на вопросы 1,2,3,5,7,8.
Таблица 4.9
Исходные данные
Время обслуживания (мин.) |
Объем изделий (усл. ед.) |
Время обслуживания (мин.) |
Объем изделий (усл. ед.) |
3,6 |
30,6 |
1,8 |
6,2 |
4,1 |
30,5 |
4,3 |
40,1 |
0,8 |
2,4 |
0,2 |
2,0 |
5.7 |
42,2 |
2,6 |
15,5 |
3,4 |
21,8 |
1,3 |
6,5 |
Вычислить точечную и 99%-ную интервальную оценку величины Y при Х= 3,0.
Вариант 3. Служащему автобусного парка необходимо определить, существует ли положительная взаимосвязь между годовыми расходами на содержание автобуса и сроком его эксплуатации. Если подобная взаимосвязь будет обнаружена, он сможет лучше планировать размер годового бюджета автобусного парка. Им собраны данные, приведенные в табл. 4.10. Используя эти данные, ответьте на вопросы 2,3,4,5,7,8.
Спрогнозировать стоимость годового содержания автобуса, который находится в эксплуатации уже пять лет.
Таблица 4.10
Исходные данные
Автобус |
Расходы на содержание (долл.) |
Срок эксплуатации (годы) |
Автобус |
Расходы на содержание (долл.) |
Срок эксплуатации (годы) |
1 |
859 |
8 |
6 |
224 |
2 |
2 |
682 |
5 |
7 |
320 |
1 |
3 |
471 |
3 |
8 |
651 |
8 |
4 |
708 |
9 |
9 |
1049 |
12 |
5 |
1094 |
11 |
|
|
|
Вариант 4. Необходимо составить прогноз объемов продаж книг в мягких обложках за неделю, основываясь на суммарной длине книжных полок в магазине (в ед. изм.). Выборочные данные за 11 недель представлены в табл. 4.11. Используя эти данные, необходимо ответить на вопросы 1 - 5,7,8.
Спрогнозировать количество книг, продаваемых за неделю при суммарной длине книжной полки в магазине, равной 4 ед. изм.
Таблица 4.11
Исходные данные
Неделя |
Количество проданных книг, Y |
Суммарная длина книжных полок (ед. изм.), X |
1 |
275 |
6,8 |
2 |
142 |
3,3 |
3 |
168 |
4,1 |
4 |
197 |
4,2 |
5 |
215 |
4,8 |
6 |
188 |
3,9 |
7 |
241 |
4,9 |
8 |
295 |
7,7 |
9 |
125 |
3,1 |
10 |
266 |
5,9 |
11 |
200 |
5,0 |
Вариант 5. В табл.4.12 приведена информация по 12 различным городам, где продаются товары по почте. Используя данные, ответьте на вопросы 6,7,8. Вычислите стандартную ошибку оценки. Определите, имеется ли значимая линейная взаимосвязь между этими двумя переменными (при уровне значимости 0,05). Какой процент изменчивости переменной количества заказов объясняется переменной количества распространенных каталогов? Проверьте, будет ли угловой коэффициент существенно отличаться от нуля (используйте уровень значимости 0,01). Постройте 90%-ный интервал прогноза для количества полученных заказов, если считать, что было распространено 10 000 каталогов.
Таблица 4.12
Исходные данные
Город |
Количество заказов на товары (тыс. шт) |
Количество распространенных каталогов (тыс. шт) |
A |
24 |
6 |
B |
16 |
2 |
C |
23 |
5 |
D |
15 |
1 |
E |
32 |
10 |
F |
25 |
7 |
G |
18 |
15 |
H |
18 |
3 |
I |
35 |
11 |
J |
34 |
13 |
K |
15 |
2 |
L |
32 |
12 |
Вариант 6. В табл. 4.13 приведены размеры банковских вкладов и начисляемых процентов за 10 лет. Используя эти данные, ответьте на вопросы 1,3,7,8.
Таблица 4.13
Исходные данные
Размеры вкладов (тыс. усл. ед.) |
Средний банковский процент |
1060 |
4,8 |
940 |
5,1 |
920 |
5,9 |
1110 |
5,1 |
1590 |
4,8 |
2050 |
3,8 |
2070 |
3,7 |
2030 |
4,5 |
1780 |
4.9 |
1420 |
6,2 |
Может ли быть найдено эффективное уравнение прогноза? Спрогнозируйте объем вкладов, если банковская ставка будет равна 4%?
Вариант 7. Аналитиком компании выявлена положительная зависимость между общим количеством выданных разрешений на строительство и объемом работ, за которые могла бы взяться его компания. Теперь необходимо выяснить, можно ли использовать информацию о размере банковской учетной ставки для прогнозирования количества разрешений на строительство, выдаваемых за месяц. Соответствующие данные, собранные за девять месяцев, представлены в табл. 4.14. Используя эти данные, ответьте на вопросы 2,5,6,7,8.
Таблица 4.14
Исходные данные
Месяц |
Количество разрешений на строительство, Y |
Банковская учетная ставка, X |
1 |
786 |
10,2 |
2 |
494 |
12,6 |
3 |
289 |
13,5 |
4 |
892 |
9,7 |
5 |
343 |
10,8 |
6 |
888 |
9.5 |
7 |
509 |
10,9 |
8 |
987 |
9,2 |
9 |
187 |
14,2 |
На сколько уменьшается в среднем количество разрешений на строительство при возрастании банковской ставки на 1%? Вычислите значение коэффициента детерминации, поясните его.
Вариант 8. На одном из этапов процесса производства электромоторов используется фрезерный станок для изготовления канавок на оси мотора. Каждая партия осей тестируется, и все изделия, размеры которых не соответствуют заданным параметрам, бракуются. Перед изготовлением каждой партии осей фрезерный станок необходимо настроить.
С целью определения оптимального размера партии необходимо выяснить, как размер партии будет влиять на количество бракованных осей. Для этой цели использовать данные о 13 партиях изделий среднего размера, приведенные в табл. 4.15. Используя эти данные, ответьте на вопросы 1,5,7,8. Спрогнозируйте количество бракованных осей для партии размером в 300 изделий.
Таблица 4.15
Исходные данные
Партия |
Количество бракованных изделий |
Размер партии |
Партия |
Количество бракованных изделий |
Размер партии |
1 |
4 |
25 |
8 |
49 |
200 |
2 |
8 |
50 |
9 |
53 |
225 |
3 |
6 |
75 |
10 |
70 |
250 |
4 |
16 |
100 |
11 |
82 |
275 |
5 |
22 |
125 |
12 |
95 |
300 |
6 |
27 |
150 |
13 |
109 |
325 |
7 |
36 |
175 |
|
|
|
Вариант 9. В табл. 4.16 представлены данные, собранные при проведении исследований по оценке стоимости недвижимости. Приведенные в таблице величины — это оценка стоимости в городской книге инвентаризации, X, и рыночная цена продажи, Y, (в тыс. усл. ед.) для п = 30 домов, проданных в течение одного года в определенном районе. Используя эти данные, ответьте на вопросы 2,3,7,8.
Таблица 4.16
Исходные данные
Дом |
Оценка инвентаризации (тыс. усл. ед.) |
Рыночная стоимость (тыс. усл. ед.) |
Дом |
Оценка инвентаризации (тыс. усл. ед.) |
Рыночная стоимость (тыс. усл. ед.) |
1 |
2 |
3 |
4 |
5 |
6 |
1 |
68,2 |
87,4 |
16 |
74,0 |
88,4 |
2 |
74,6 |
88,0 |
17 |
72,8 |
93,6 |
3 |
64,6 |
87,2 |
18 |
80,4 |
92,8 |
4 |
80,2 |
94,0 |
19 |
74,2 |
90,6 |
5 |
76,0 |
94,2 |
20 |
80,0 |
91,6 |
6 |
78,0 |
93,6 |
21 |
81,6 |
92,8 |
7 |
76,0 |
88,4 |
22 |
75,6 |
89,0 |
8 |
77,0 |
92,2 |
23 |
79,4 |
91,8 |
9 |
75,2 |
90,4 |
24 |
82,2 |
98,4 |
10 |
72,4 |
90,4 |
25 |
67,0 |
89,8 |
Продолжение табл. 4. 16
1 |
2 |
3 |
4 |
5 |
6 |
11 |
80,0 |
93,6 |
26 |
72,0 |
97,2 |
12 |
76,4 |
91,4 |
27 |
73,6 |
95,2 |
13 |
70,2 |
89,6 |
28 |
71,4 |
88,8 |
14 |
75,8 |
91,8 |
29 |
81,0 |
97,4 |
15 |
79,2 |
94,8 |
30 |
80,6 |
95,4 |
Используя модель линейной регрессии, определите прямую регрессионной зависимости рыночной стоимости от цены инвентаризации.
Является ли регрессионная зависимость значимой? Объясните свой ответ. Спрогнозируйте рыночную стоимость дома, цена инвентаризации которого равна 90,5 тыс. долл. Не опасно ли делать такой прогноз?