

СТРУКТУРЫ, ОБЪЕДИНЕНИЯ И КЛАССЫ
На ряду с основными (фундаментальными) типами данных, программист с помощью ключевых слов struct, union и class может определить свои собственные типы данных, а также с помощью компонентных функция определить множество операций над ними. В программировании наличие такой возможности у языка называется расширяемостью типов и является одним из элементов объектно-ориентированного программирования.
Необходимость в своих типах данных возникает у программиста почти всегда, когда он начинает решать достаточно сложные задачи. Так, например, пусть программист пишет программу для работы с базой данных, которая содержит информацию о сотрудниках и имеет несколько полей данных (фамилия, имя, дата рождения, зарплата, стаж и т.д.) для каждой записи. Каждое из полей данных - это переменная (объект), которая относится к одному из основных типов данных, но понятно, что все эти объекты являются частью чего-то общего в данном случае частью записи о работнике в базе данных. Поэтому естественным выглядит ввести новый составной (структурированный ) тип данных например Card (запись, карточка), в которую в качестве элементов входили бы все поля данных (фамилия, имя, дата рождения, зарплата, стаж и т.д.). При этом оперируя объектом типа Card программист оперирует сразу совокупностью всех её полей данных, что позволяет существенно упростить процесс написания и отладки сложных программ.
Структура как тип и совокупность данных
Как уже было сказано выше, с помощью ключевого слова struct программист может определить свой собственный тип данных и множество операций над ним. Определение нового типа данных может выглядеть следующим образом:
struct имя_нового_типа {
определение компонентного данного_1;
…
определение компонентного данного _N;
определение или описание компонентной функции_1;
…
определение или описание компонентной функции_K;
};
где имя_нового_типа – это идентификатор (имя), которое программист даёт новому типу данных; компонентные данные – это фундаментальные или определённые пользователем типы данных; компонентные функции – это функции реализующие поведение объёкта ( его создание, уничтожение, множество операций над ним и т.д.).
В этом параграфе мы остановимся на способе определения нового типа данных с помощью struct и опустим пока рассмотрение возможностей, связанных с компонентными функциями. В качестве примера приведём определение нового тип address :
struct address {
char* name; // имя
long number; // номер дома
char* street; // улица
char* town; // город
char state[2]; // штат
int zip; // индекс
};
Итак, в этом примере мы определили новый тип данных - address. Этот тип данных содержит шесть полей компонентных данных (name, number, street, town, state, zip), каждый из которых является переменной фундаментального типа данных. Возникает вопрос: Существуют ли какие-либо ограничения на типы данных, включаемых в структурированный объект? Да, одно ограничение существует. Нельзя в определении типа включить поле данных того же самого типа, т.е. определение struct adr { adr z;}; запрещено правилами языка Си++, но включать указатель на тот же самый тип struct adr { adr* z;}; уже можно.
Поскольку address – это новый тип данных то по аналогии с фундаментальными типами данных мы можем определить объект типа address , указатель на объект типа address, массив объектов типа address, ссылку на объект типа address, и т.п. Приведём пример:
int i=2; //определена и инициализирована переменная i типа int.
int *pi = &i, ari[3] = {1,3,7}, &rfi = i; /* определение и инициализация указателя pi на объект типа int; определение и инициализация массива ari объектов типа int; определение ссылки rfi на объект типа int.*/
address Nik={"Jim Dandy", 61, "South Street", "New Providence", {‘N’,‘J’}, 1974}; ./*Определение и инициализация структурированного объекта Nik типа address. Его поля данных name, street, town инициализируются адресами начиная с которых строки "Jim Dandy", "South Street", "New Providence" размещаются в памяти соответственно. Его поля number, zip инициализируются числами 61 и 1974 соответственно. Элементы массива state объекта Nik инициализируется символами ‘N’, ‘J’ */
address *pNik = &Nik, ArAddr[3], &rfNik= Nik; /* определение и инициализация указателя pNik на объект типа address; определение массива ArAddr объектов типа address; определение ссылки rfNik на объект типа address.*/
Как видно из примера структурированный объект, в данном случае Nik, можно не только определить, но и сразу инициализировать. Поле данных name объекта Nik будет равно адресу, начиная с которого в памяти расположена строковая константа "Jim Dandy"; поле number объекта Nik получает значение 61 и т.д.
Иногда нет необходимости вводить новый тип данных, но есть необходимость определить несколько объектов структурированного типа. В этом случае после ключевого слова struct опускают имя типа, пример:
struct { char N[12]; int value ;} XX, Y[7], *pXX; /* определение структурированного объекта XX, массива структурированных объектов Y, и указателя на структурированный объект рХХ. Каждый из объектов содержит массив N и поле value .*/
Поскольку в этом примере не было дано имя новому типу, то соответственно нет возможности за пределами определения создать объекты этого типа, другими словами XX и массив Y будут единственными объектами этого безымянного структурированного типа.
Существуют несколько способов доступа с помощью имени структурированного объекта и указателя на него к полям данных структурированного объекта. В общем случае их можно записать в полной или краткой формах так,
Полная форма (квалифицированное имя ) |
Краткая форма (уточненное имя) |
имя_объекта.имя_типа::имя_поля_данных |
имя_объекта. имя_поля_данных |
указатель_на_объект-> имя_типа::имя_поля_данных |
указатель_на_объект-> имя_поля_данных |
(*указатель_на_объект). имя_типа::имя_поля_данных |
(*указатель_на_объект).имя_поля_данных |
Полная и краткая форма записи абсолютно эквивалентны, поэтому чаще всего на практике используется краткая форма записи, но иногда при множественном наследовании возникает необходимость в использовании полной формы записи.
В таблице мы впервые виде как используются операции (точка), (стрелочка) и (двойное двоеточие) для структурированного объекта. Если посмотреть в таблицу приоритетов операций, то видно, что они имеют самый высокий ранг. Кроме того если выражение имя_объекта имеет тип структурированного данного, то выражение имя_объекта.имя_поля_данных, или указатель_на_объект->имя_поля_данных, или (*указатель_на_объект).имя_поля данных совпадает с типом поля данных, пример:
Nik.name // выражение имеет тип char* и с ним можно делать всё, что раньше делалось с переменной char*
Nik.name = “Иванов”; /*Указатель name типа char* структурированного объекта Nik настраивается на начало фрагмент памяти, в котором расположена литерная константа “Иванов “*/
Nik.number = 34; /*C помощью операции точка получили доступ к полю number структурированного объекта Nik и присвоили ему значение 34. Выражение Nik.number имеет тип long */
ArAddr[0].number =75; /*C помощью операции точка получили доступ к полю number структурированного объекта ArAddr[0] и присвоили ему значение 75. Выражение ArAddr[0].number имеет тип long */
pNik->street = “Фрунзе”; /* C помощью операции стрелочка и указателя на объект Nik получили доступ к полю street объекта Nik. Поскольку поле street в определении структурированного объекта имеет тип char* , то выражение pNik->street тоже имеет тип char*. В данном случае в поле street структурированного объекта Nik запоминается адрес, начиная с которого в памяти размещена строковая константа “Фрунзе”.*/
(*pNik).zip = 3456; /* Такой способ записи в принципе эквивалентен первому, так как операция звёздочка – это операция разыменования указателя, следовательно вместо скобок появится объект, и с помощью операции точка мы получим доступ к полю zip и присвоим ему значение 3456. Выражение (*pNik).zip естественно имеет тип int. */
Таким образом в нашем примере мы переопределили значение некоторых полей структурированного объекта Nik. Если их значения вывести на печать с помощью строк программы
cout << “\n Фамилия: “<< Nik.name << “\t Номер дома: “<<Nik.number<<”\t Улица: “<<Nik.street ;
cout<<”\t Город: <<Nik.state<<”\t Штат: “<<Nik.state[0]<< Nik.state[1]<<”\t Индекс: “<<Nik.zip;
то мы получим на экране
Фамилия: Иванов Номер дома: 34 Улица: Фрунзе Город: New Providence Штат: NJ Индекс: 3456
Строка программы cout<< Nik будет выдавать ошибку, так как объект cout «знает» как выводить на печать все объекты основных типов данных , но не объекты типа address. Для того чтобы эта строка заработала необходимо написать компонентную функцию и переопределить поведение объекта cout для объекта типа address. Но этим мы займёмся позже.
Необходимо также отметить, что при определении любого структурированного объекта для каждого из них выделяется свой собственный фрагмент памяти под все поля данных, записанных в определении структурированного типа, т.е. структурированный объект имеет свою собственную независимую от других объектов копию всех полей компонентных данных. Другими словами записав Nik.number, мы обращаемся к полю number структурированного объекта Nik, а записав ArAddr[0].number, мы обращаемся к полю number структурированного объекта ArAddr[0] – это поля никак не связаны между собой, потому что относятся к разным объектам (в первом хранится значение 34, во втором 75).
Структурированный объект может быть передан в функцию по значению в качестве параметра и возвращён функцией по значению с помощью оператора return. Пример:
address current = {"Сидоров ", 31, "Петровская ", "Таганрог", {‘R’,‘U’}, 3900};
address set_current(address next)
{
address prev = current;
current = next;
return prev;
}
Void main (){
address Nik={"Jim Dandy", 61, "South Street", "New Providence", {‘N’,‘J’}, 1974}, f2;
f2 = set_current(Nik);
}
Напомним, что при передачи по значению формальным параметрам присваивается значения фактических параметров в строгом соответствии с порядком в списке. В данном случае next является формальным параметром , Nik – фактическим . Следовательно все поля объекта next получат те же значения, что и поля объекта Nik. Поскольку функция set_current () возвращает структурированный объект address по значению, то в точке вызова функции будет создан неименованный объект типа address, поля которого будут инициализированы полями локального структурированного объекта prev . После чего локальный структурированный объект prev будет уничтожен, а объекту f2 будет присвоено значение неименованного объекта, т.е. поля объекта f2 получат те же самые значения, что и поля неименованного объекта. Таким образом будут переданы данные по значению из функции (локального параметра prev в f2).
Функция может также иметь формальные параметры в виде указателей или ссылок на структурированный объект и возвращать указатель или ссылку на структурированный объект. В общем, никаких особых отличий при использовании структурированных типов в функции от использования фундаментальных типов нет.
Операции, определенные по умолчанию над структурированными объектами
Над структурированными объектами по умолчанию определено всего несколько операций (&, *, sizeof(), =, операции выбора компонентов структурированного объекта (точка ) и ->, операции с компонентами классов *, ->*, :: ). Программист может при желании расширить список операций над структурированными объектами определив их с помощью компонентных функций, но пока рассмотрим только операции определённые по умолчанию.
Унарная операция получения адреса структурированного объекта & возвращает адрес, начиная с которого в памяти расположены поля данных структурированного объекта. Поля в памяти размещены в той же последовательности, как и при их записи в определении структурированного объекта.
Унарная операция разыменования (доступа по адресу) * может быть применена к указателю на структурированный объект. С помощью неё можно получить доступ к объекту на который указывает указатель.
Операции выбора компонентов структурированного объекта (точка ) и -> были рассмотрены выше. С помощью имени структурированного объекта или указателя на него мы можем обратиться к полю данных структурированного объекта.
Операция sizeof () может быть применена, как и в случае с фундаментальными типами данных, к имени типа или к имени объекта структурированного типа. Результатом выполнения операции является число, указывающее сколько байт в памяти занимает структурированный объект. Это число можно рассчитать самостоятельно, оно буде равно сумме количества байт отводимых под каждое поле данных + сумме количества байт отводимых под таблицу виртуальных функций (таблица существует, если в структурированном объекте определены или унаследованы виртуальные компонентные функции) + некоторое количество байт необходимое для того, чтобы выровнять общее количество байт до границы слова (т. е. сделать общее количество байт кратным 4 ). Например, sizeof (address) = 20 если считать, что int занимает 2 байта и sizeof (address) = 24, если sizeof (int) = 4 байта.
Операция присваивания = обычно переопределяется с помощью компонентных функций программистом, если же она программистом не переопределена, то выполняется операция присваивания реализованная в компиляторе по умолчанию, т.е. всем полям структурированного объекта, стоящего слева от знака присваивания, присваиваются значения полей данных структурированного объекта, стоящего справа от знака присваивания (см. примеры выше). В общем случае это не всегда правильно ( именно поэтому обычно операцию присваивания по умолчанию переопределяют). При выполнении операции присваивания компилятор проверяет соответствие типов. В простейшем случае слева и справа от операции присваивания должны стоять структурированные объекты одного и того же типа, в противном случае компилятор выдаст сообщение об ошибке.
Операция (::) двойное двоеточие применяется при использовании полного имени при обращении к полю структурированного объекта.
Операция ->* используется в записи указатель_на_структурированный_объект->*указатель. Такая операция эквивалентна операции *(указатель_на_структурированный_объект->указатель), т.е. значение выражения в скобках - это указатель, к которому применяется операция (*) разыменования.
Кроме определения структурированного типа в программе может использоваться и его описание, которое в общем случае имеет вид:
Одно из ключевых слов struct, union, class имя_структурированного_типа;
C помощью описания программист сообщает компилятору, что идентификатор имя_структурированного_типа – это имя типа данных, определённого программистом где-то ниже по тексту или в другом файле программы. Иногда без описание вообще невозможно обойтись, так, в приведённом ниже примере описание помогает нам обойти безвыходную ситуацию
struct A;// Описание, сообщающее, что А – это новое имя типа данных ,определённого где-то ниже по тексту.
struct B { A* pa;};//Определение структурированного типа В
struct A { B*pb;}; //Определение структурированного типа А
Эквивалентность типов
Два структурных типа считаются различными даже тогда, когда они имеют одни и те же члены. Например, ниже определены различные типы:
struct s1 { int a; };
struct s2 { int a; };
В результате имеем:
s1 x;
s2 y =x; // ошибка: несоответствие типов
Кроме того, структурные типы отличаются от основных типов, поэтому получим:
s1 x;
int i = x; // ошибка: несоответствие типов
Есть, однако, возможность, не определяя новый тип, задать новое имя для типа. В описании, начинающемся служебным словом typedef, описывается не переменная указанного типа, а вводится новое имя для типа.
Приведем пример:
typedef char* Pchar;
Pchar p1, p2;
char* p3 = p1; // ошибки нет типы соответствуют
Это просто удобное средство сокращения записи.
Реализация линейного списка на языке СИ++
Линейный список – это в общем случае абстрактное понятие, под которым подразумевается наличие некоторого отличного от нуля количества объектов (узлов), связанных друг с другом таким образом, что их можно представить в виде цепи или ожерелья (звенья цепи или бусинки ожерелья – это объекты), вытянутого в одну линию.
Над линейным списком обычно определены следующие операции
получение доступа к k-му узлу списка для проверки и/или изменения содержимого его полей;
вставка нового узла сразу после или до k-го узла;
удаление k-го узла;
объединение в одном списке двух (или более) линейных списков;
разбиение линейного списка на два (или более) списка;
создание копии линейного списка;
определение количества узлов в списке;
сортировка узлов в порядке возрастания значений в определённых полях этих узлов;
поиск узла с заданным значением в некотором поле.
В одной программе редко используются сразу все девять типов операций в общей их формулировке. Поэтому линейные списки могут иметь самые разные представления в зависимости от класса операций, которые наиболее часто должны с ними выполняться . Достаточно трудно создать единое представление линейных списков, при котором эффективно выполнялись бы все эти операции. Поэтому нужно различать разные типы линейных списков в зависимости от выполняемых с ними основных операций.
Линейные списки, в которых операции вставки, удаления и доступа к значениям чаще всего выполняются в первом или последнем узле, получили следующие специальные названия.
Стек – это линейный список, в котором все операции вставки и удаления (и, как правило, операции доступа к данным ) выполняются только на одном из концов списка.
Очередь или односторонняя очередь – это линейный список, в котором все операции вставки выполняются на одном из концов списка, а все операции удаления (и, как правило, операции доступа к данным) – на другом.
Дек или двухсторонняя очередь - это линейный список, в котором все операции вставки и удаления (и, как правило, операции доступа к данным ) выполняются на обоих концах списка.
На рис. 1 представлен один из способов организации линейного списка на языке Си++ (так называемый двухсвязный список). Каждый элемент (звено) списка содержит три поля: P-указатель на предыдущее звено в списке; O – указатель на объект, включаемый в список; N – указатель на следующее звено в списке. Указатели begin и end – это указатели на первое и последнее звено в списке.

Рис. 1. Организация линейного двухсвязного списка
Из рисунка видно, что такая организация в принципе избыточна достаточно было бы односвязного списка, т.е. или поле Р, или поле N вообще можно опустить, но в этом случае возможно уменьшится скорость доступа к элементам списка. Так, если мы опускаем поле Р, то при вставке или удалении элемента из конца списка нам необходимо будет перебрать все элементы списка. Из рисунка видно, что в список в принципе могут быть включены любые объекты, т.е. указатель О может настраиваться на адреса любых объектов, которые программист хочет хранить в памяти в виде списка. Обычно предполагается, что все объекты будут одного и того же типа, но в принципе это не обязательно.
Приведём пример программы на Си++, реализующей двухсвязный список.
#include "stdafx.h"
#include<string.h>
#include<iostream.h>
В качестве объекта вставляемого в список выберем структурированный объект card, определение которого приведено ниже.
struct card { //Определение структурного типа для книги
char *author; // Ф.И.О. автора
char *title; // Заголовок книги
char *city; // Место издания
char *firm; // Издательство
int year; // Год издания
int pages; // Количество страниц
};
//Функция печати сведений о книге:
void printbook(card& car)
{ static int count = 0;
cout<<"\n"<< ++count <<". "<<car.author;
cout<<" "<<car.title<<".- "<<car.city;
cout<<": "<<car.firm<<", ";
cout<<"\n"<<car.year<<".- "<<car.pages<<" c.";
}
Звенья цепи списка удобно представить в виде структурированного объекта, который мы назовём record. Поля prior и next играют роль указателей P и N приведённых на рис. 1. Указатель obj – это поле О, т.е. указатель на объект, который предполагается хранить в звене списке.
struct record { //Структурный тип для элемента списка (1)
void* obj;
record *prior;
record *next;
};
//Исходные данные о книгах:
card books[] = { //Инициализация массива структур: (2)
{ "Kruglinski David", "Visual C++ 6.0", "М", "Мир",2000, 819},
{ "Stroustrup B","Язык Си++", "Киев","ДиаСофт",1993, 560},
{ "Turbo C++.", "Руководство программиста", "М","ИНТКВ",1991,394},
{ "Lippman S.B.","C++ для начинающих", "М","ГЕЛИОН",1993,496}
};
void main()
{ record *begin = NULL, //Указатель начала списка (3)
*last = NULL, //Указатель на очередную запись
*list; //Указатель на элементы списка
// n-количество записей в списке:
int n = sizeof(books)/sizeof(books[0]);
// Цикл обработки исходных записей о книгах:
for (int i=0;i<n; i++)
{//Создать новую запись(элемент списка): (4)
last = new(record);
card * pcd = new (card);
//Занести сведения о книге в новую запись:
pcd->author = books[i].author;
pcd->title = books[i].title;
pcd->city = books[i].city;
pcd->firm = books[i].firm;
pcd->year = books[i].year;
pcd->pages = books[i].pages;
last->obj = pcd;
//Включить запись в список(установить связи):
if (begin == NULL) //Списка ещё нет (5)
{last->prior = NULL;
begin = last;
last->next = NULL;
}
else{
//Список уже существует
list = begin;
//Цикл просмотра цикла - поиск места для
//новой записи:
while (list){ //(6)
if (strcmp( ((card*)(last->obj))->author, ((card*)(list->obj))->author) < 0 ){ //Вставить новую запись перед list:
if (begin == list){
//Начало списка: (7)
last->prior = NULL;
begin = last;
}
else{
//Вставить между записями: (8)
list->prior->next = last;
last->prior = list->prior;
}
list->prior = last;
last->next = list;
//Выйти из цикла просмотра списка:
break;
}
if (list->next == NULL){
//Включить запись в конец цикла: (9)
last->next = NULL;
last->prior = list;
list->next = last;
//Выйти из цикла просмотра списка:
break;
}
//Перейти к следующему элементу списка:
ist = list->next;
}//Конец цикла просмотра списка (конец while )
//(Поиск места для новой записи)
} //Включение записи выполнено (конец else )
} //Конец цикла (for) обработки исходных данных
//Печать в алфавитном порядке библиографического списка:
list = begin; // (10)
cout<<"\n";
while (list)
{ printbook(*(card*)(list->obj));
delete (card*)(list->obj);
record* tmp = list;
list = list->next;
delete tmp;
}
}
В общем случае назвать эту программу программой реализации двухсвязного списка нельзя, так как очень трудно отделить реализацию самого списка от примера. Вот если бы каждое из действий над списком (вставка, удаление, доступ к элементу списка и т.д.) было реализовано в виде отдельной функции, то таким списком можно было бы пользоваться в разных программах. В принципе такая реализация списка была бы похожа на ту, что реализована в STL (стандартной библиотеки шаблонов).
Поэтому в качестве примера реализуем функцию вставки в начало списка (предполагается, что все остальные функции студенты реализуют в лабораторной работе). Для начала отметим, что фрагмент приведённого выше кода примера начиная с метки 5 и по 10 реализует вставку в начало, в конец и в середину списка элементов типа record. Поэтому внимательно проанализировав алгоритм и вычленив из него необходимые части, можно без труда реализовать функции вставки. Ниже приведёна реализация функции вставки в начало списка InsertBg и её тестирование.
#include "stdafx.h"
#include<string.h>
#include<iostream.h>
void printSpisok(double * p)
{ static int count = 0;
cout<<"\n"<< ++count <<"\t"<<*p;
}
struct record {
void* obj;
record *prior;
record *next;
static record *begin; //Статический компонент
};
//---------------------------------------------------------------------------
void InsertBg(void* lt){
if(record::begin ==NULL) {//Вставка первого элемента в список
record::begin = new (record);
record::begin->next = NULL;
record::begin->prior = NULL;
record::begin->obj = lt;
return;
}
record* tmp = new (record); //Вставка последующих элементов
record::begin->prior = tmp;
tmp->prior = NULL;
tmp->next = record::begin;
tmp->obj = lt;
record::begin = tmp;
return;
}
//-------------------------------------------------------------------
void ClearList(){
record * list = record::begin;
record* tmp = list;
while (list){
delete (double*)(list->obj);
tmp = list;
list = list->next;
delete tmp;
}
}
//------------------------------------------------------------------------------------------------
record* record::begin=NULL; //Инициализация статического компонента
//--------------------------------------------------------------------------------------------------
void main()
{
record *list;
double *pi = new (double); *pi = 3.14;
double *ex = new (double); *ex = 2.79;
double *z = new (double); *z = 1.1;
InsertBg(pi);
InsertBg(ex);
InsertBg(z);
list = record::begin;
while (list){
printSpisok((double*)list->obj);
cout<<"\t";
list = list->next;
}
ClearList();
}
В результату работы программы на экран выводятся числа 1.1, 2.79, 3.14.
В этом примере в определении структурированного типа record указатель begin определён со спецификатором static. Это делает указатель begin статическим компонентом. Главным отличием статического компонента от обычных компонентных данных заключается в том, что статический компонент в отличии от обычных компонентных данных существует в одном экземпляре для всех объектов этого типа данных, а поля обычных компонентных данных при создании нового объекта создаются вместе с ним , другими словами статическое поле одно на все объекты данного типа сколько бы их не было, а обычные компонентные данные тиражируются при создании объекта и у каждого объекта этого типа они свои. Мало того, если мы определили новый тип данных, но не создали ни одного объекта этого типа, то следовательно не существует и обычных компонентных данных, к которым мы могли бы обратиться с помощью имени объекта (ни одного объекта ещё нет). Тем не менее в этой ситуации статический компонент уже существует и к нему можно обратиться и даже инициализировать его с помощью имени типа и операции (::), например, record* record::begin=NULL; К статическому компоненту можно обратиться и обычным способом, как к обычным компонентным данным, с помощью имени объекта и операции точка (.) или указателя на объект и операции стрелочка (->).
В приведённом выше примере, мы воспользовались свойствами статических компонентов и сделали в определении типа record указатель на начало списка begin статическим компонентом. Это соответствует смыслу, которое мы вкладываем в указатель, он должен быть единственным для всех элементов типа record.
В примере также реализованы две функции работы со списком: вставка объекта в начало списка InsertBg() и очистки списка ClearList().
Объединения разнотипных данных
Со структурами "в близком родстве" находятся объединения, которые вводятся с помощью служебного слова union. Чтобы пояснить "степень родства" объединений со структурами, рассмотрим приведённый ниже пример.
struct ExamStruct { long L; int K[2]; char C[4]; } STR;
|
union ExamUnion { long L; int K[2]; char C[4]; } UNI;
|
Sizeof(ExamStruct) = 12 |
Sizeof(ExamUnion) = 4 |
В памяти элементы структуры размещаются следующим образом:
Каждому из элементов L, K[2], C[4] отведено по четыре байта
|
В памяти элементы объединения размещаются следующим образом
L
Под все элементы L, K[2], C[4] отводится четыре байта памяти.
|
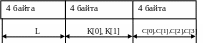

Итак, объединение можно рассматривать как структуру, все элементы которой при размещении в памяти имеют нулевое смещение от начала. Тем самым все элементы объединения размещаются в одном и том же участке памяти. Размер участка памяти, выделяемого для объединения, определяется максимальной из длин его элементов. В приведённом выше примере все элементы занимают в памяти четыре байта, поэтому объём памяти, занимаемый объектом UNI равен четырём байтам.
Объединения часто используются для того чтобы обеспечить доступ к одному и тому же фрагменту памяти с помощью разных форматов данных ( разными способами), так записав строчку UNI .C[1] мы получили доступ ко второму байту четырёхбайтовой переменной L и соответственно можем его модифицировать.
Приведём фрагмент кода, в котором объединение используется в качестве поля данных структурированного объекта. Этот же фрагмент является хорошим примером использования директивы препроцессора define, с помощью которой создаётся словарь терминов для абстракций из решаемой нами задачи. Так с помощью первой директивы define вводится синоним STAFF для типа данных struct sStaffType. Этот приём с одной стороны позволяет скрывать некоторые детали реализации, а с другой стороны делает наш код более читабельным и простым для понимания.
# define STAFF struct sStaffType
STAFF { // Учебно-вспомогательный персонал
int iYearsOfService; // Время работы (лет)
float fHourlyWage; // Почасовая оплата
};
# define STUDENT struct sStudentType
STUDENT{
float fGradePtAverage; // Средний рейтинг
int iLevel; // Год обучения
};
# define PROFESSOR struct sProfType
PROFESSOR {
int iDepartmentNumber; // Номер кафедры
float fAnnualSalary; // Годовая зарплата
};
# define NODE_TYPE enum eNodeType
typedef NODE_TYPE {student, professor, staff};
# define TREE struct sTree
TREE {
char sLastName[15]; // Фамилия
char sFirstName[15]; // Имя
int iAge; // Возраст
TREE *Left, *Right; // Указатели на левый и правый листья (ветви)
NODE_TYPE tag; // описатель типа узла - студент или профессор или УВП
union {
STUDENT student;
PROFESSOR professor;
STAFF staff;
} uNodeTag; // Обьединение, содержащее информацию по
}; // студенту или сотруднику университета
Итак, обратим внимание на определение структуры TREE, внутри которой есть поле данных uNodeTag, являющееся объединением структурированных типов данных STUDENT, PROFESSOR, STAFF. Предположим, что каждый объект типа TREE должен содержать запись либо о студенте, либо о профессоре, либо о преподавателе причём фамилия, имя и возраст должны присутствовать во всех трёх типах записей, а остальные поля данных у каждого типа будут свои. В записи о студенте будет хранится информация о среднем рейтинге и годе обучения, в записи о профессоре - номер кафедры и годовая зарплата, в записи о преподавателе – время работы и почасовая оплата. Для того чтобы при извлечении записи из массива или базы данных мы знали, какая информация хранится в поле uNodeTag вводится описатель типа узла tag. В соответствии с его определением в программе мы видим, что если он равен нулю, то это поле содержит информацию о студенте, если единица, то о профессоре, если двойку, то о преподавателе. (Естественно значение поля tag, как и значение всех остальных полей, мы задаём самостоятельно перед тем как поместить запись в массив, или в базу данных, или в линейный список и т.д.) Таким образом объект типа TREE с помощью объединения становится универсальным для хранения данных и о студентах, и о преподавателях , и о профессорах.
Ещё раз хочу обратить внимание на определение поля uNodeTag внутри структуры TREE:
union {
STUDENT student;
PROFESSOR professor;
STAFF staff;
} uNodeTag;
Поскольку объект типа uNodeTag необходим нам только внутри структурированного объекта типа TREE , то нет смысла засорять глобальную область и определять новый тип объединения за пределами TREE. Именно поэтому объединение определено внутри структурированного объекта TREE и не имеет имени типа. Зато сразу видно, что собой представляет объект uNodeTag. Такой приём очень распространён при программировании на Windows.
Деревья
Рассмотрим деревья – наиболее важные нелинейные структуры, которые встречаются при работе с компьютерными алгоритмами.
Формально дерево определяется как конечное множество Т одного или более узлов со следующими свойствами:
существует один выделенный узел, а именно – корень данного дерева Т;
остальные узлы (за исключением корня) распределены среди m0 непересекающихся множеств Т1, …, Тm и каждое из этих множеств в свою очередь, является деревом; деревья Т1, …, Тm называются поддеревом данного корня.
Как видно из определения, оно является рекурсивным, и тем самым отражает рекурсивное свойство всех древовидных структур.
С
A======== B====== H===== J===== C====== D==== E===== G=== F=====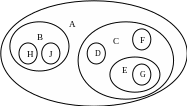 пособы
представления дерева
пособы
представления дерева 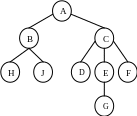
a) b) c)
(A (B (H) (J) ) (C (D) (E(G)) (F) ) )
d)
Рис. Способы изображения древовидных структур: а) обычная схема дерева; b) вложенные множества; c) список с отступами; d) вложенные скобки.
Кроме понятия дерева в литературе часто используется понятие леса. Лес – это множество содержащие несколько непересекающихся деревьев. Для примера, если исключить корневой узел А, то мы получим лес.
Важнейшим подмножеством деревьев являются так называемые бинарные деревья. Бинарное дерево это конечное множество узлов, которое может быть пустым, либо состоять из корня вместе с двумя другими бинарными деревьями. Другими словами каждый его узел может иметь 0, 1, .2 детей (но не более); мы будем различать левых и правых детей.
Существует есттественный способ представления любого леса в виде бинарного дерева. Соответствующее бинарное дерево получим за счёт связывания детей каждой семьи и удаления всех вертикальных связей, за исключением связи с родителем первого ребёнка.
Приведени схемы 1 к 3 имеет большое значение . Оно называется естественным соответствием между лесом и бинарными деревьями.
Решение многих алгоритмических задач приводит к необходимости работать с древовидными структурами, так например, алгоритмический анализ алгебраического выражения y=3ln(x+1) – a/x2 приводит к построению дерева вида:
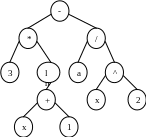
Обход в прямом порядке : посетить корень первого дерева; пройти поддеревья первого дерева; пройти оставшиеся деревья.
- * 3 ln + x 1 / a ^ x 2
Обход в обратном порядке : пройти поддеревья первого дерева; посетить корень первого дерева; пройти оставшиеся деревья. 3 x 1 + ln * a x 2 ^ / -
Битовые поля структур и объединений
Внутри структур и объединений могут в качестве их компонентом (элементов) использоваться битовые поля. Каждое битовое поле представляет целое или беззнаковое целое значение, занимающее в памяти фиксированное число битов (в компиляторе ВС++ от 1 до 16 бит). Битовые поля могут быть только элементами структур, объединений (и, как увидим в дальнейшем, классов), т.е. битовые поля не могут появляться как самостоятельные объекты программ. Битовые поля не имеют адресов, т.е. для них не определена операция &, нет указателей и ссылок на битовые поля. Они не могут объединяться в массивы. Назначение битовых полей - обеспечить удобный доступ к отдельным битам данных. С помощью битовых полей можно формировать объекты с длиной внутреннего представления, не кратной байту. Это позволяет плотно "упаковывать" информацию и тем самым экономить память, например, при работе с однобитовыми флажками.
Определение структуры с битовыми полями имеет такой формат:
struct { тип_поля имя_поля: жирина_поля; тип_поля имя_поля: ширина_поля;
} имя_структуры;
Здесь тип_поля - один из базовых целых типов int, unsigned int (сокращенно unsigned), signed int (сокращенно signed), char, short, long и их знаковые и беззнаковые варианты. (В языке Си стандарт ANSI допускает только знаковый или беззнаковый вариант типа int.)
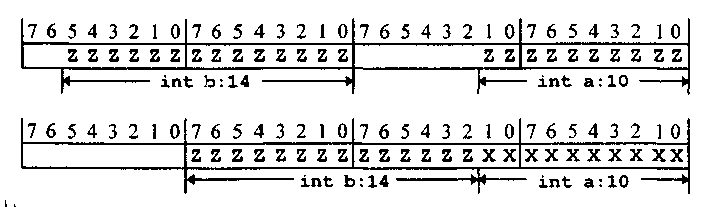
имя_поля - идентификатор, выбираемый пользователем; ширина-поля - целое неотрицательное десятичное число, значение которого , обычно не должно превышать длины слова конкретной ЭВМ.
Таким образом, диапазон возможных значений ширины..поля существенно зависит от реализации. В компиляторах ТС++ и ВС++ ширина-поля может выбираться в диапазоне от 0 до 16. Пример определения структуры с битовыми полями:
struct { int а: 10; int b:14; } хх, *рх;
Для обращения к битовым полям используются те же конструкции, что и для обращения к обычным элементам структур:
имя_структуры.имя_поля
укаэатель_на_структуру->имя_поля
ссылка_на_структуру.имя_поля
(* указатель_на_струхтуру).имя_поля
Например, для введенной структуры хх и указателя рх допустимы такие операторы:
хх. а = 1; рх = &хх; рх->Ь = 48;
От реализации зависит порядок размещения полей структуры в памяти ')ВМ. Поля могут размещаться как справа налево, так и слева направо. Кроме того, реализация определяет, как размещаются в памяти битовые ноля, длина которых не кратна длине слова и(или) длине байта (рис. 7.7). Для компиляторов, работающих на IBM PC, поля, размещенные в начале описания структуры, имеют младшие адреса. Именно такое размещение изображено на рис. 7.7.
В компиляторах часто имеется возможность изменять размещение битовых полей, выравнивая их по границам слов или выполняя плотную упаковку. Некоторые возможности влиять на размещение битовых полей в памяти имеются и на уровне синтаксиса самого языка Си++. Во-первых, мри определении битового поля разрешается не указывать его имя. В этом случае (когда указаны только двоеточие и ширина поля) в структуру вводятся неиспользуемые (недоступные'» биты, формирующие промежуток между значимыми полями. Например
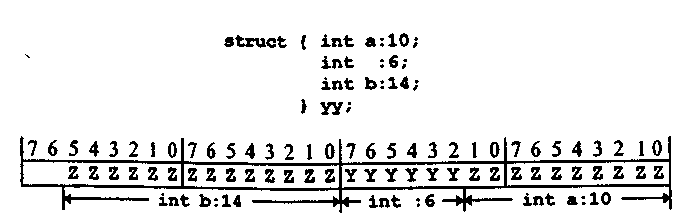
Рис. 7.8. Структура с безымянным полем
В структуре уу между полем int a: 10 и полем int Ь:14 размещаются 6 бит, не доступных для использования. Их назначение - выравнивание полей по плану программиста (рис. 7.8).
Битовые поля в объединениях используются для доступа к нужным битам того или иного объекта, входящего в объединение. Например, следующее объединение позволяет замысловатым способом сформировать код символа тУ (равный 68):
union { char simb;
struct { int x:5; int y:3; ) hh; } cod;
cod.hh.x = 4; cod.hh.y = 2; cout « cod.simb; // Выведет на экран символ 'D'
Рис. 7.9 иллюстрирует формирование кода 68, соответствующего символу 'd'.
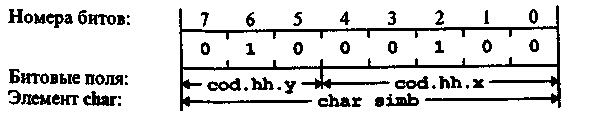
Рис. 7.9. Объединение со структурой из битовых полей
Для иллюстрации особенностей объединений и структур с битовыми полями рассмотрим следующую программу:
//Р7-05.СРР - битовые поля, структуры, объединения tinclude <iostream.h>
// Функция упаковывает в один байт остатки от деления // на 16 двух целых чисел - параметров: unsigned char cod(int a,int b) { union { unsigned char z;
struct { unsigned int x:4; // Младшие биты unsigned int y:4; // Старшие биты } hh; } un ;
un.hh.x = a % 16; un.hh.y = b % 16; return un.z;
)
// Функция изображает на экране двоичное представление
// байта-параметра: