

22. Семантические сети предложений естественного языка.
Семантическая сеть (СС) – математическая модель, отображающая множество понятий относящихся к определенным классам объектов (семантика в языкознании изучает смысл единиц языка). В общем случае СС может быть представлена в виде гиперграфа, в котором вершины соответствуют понятиям, а дуги – отношениям. Графовая форма представления в СС дает большую простоту реализации отношений многих объектов ко многим, нежели в иерархической модели.
Основное преимущество этой модели в соответствии современным представлениям об организации долговременной памяти человека. Недостаток модели – сложность поиска вывода на семантической сети.
Начиная с конца 50-ых годов были созданы и применены на практике десятки вариантов семантических сетей. Несмотря на то, что терминология и их структура различаются, существуют сходства, присущие практически всем семантическим сетям:
- узлы семантических сетей представляют собой концепты предметов, событий, состояний;
- дуги семантических сетей создают отношения между узлами-концептами (пометки над дугами указывают на тип отношения);
- некоторые отношения между концептами представляют собой лингвистические падежи, такие как агент, объект, реципиент и инструмент (другие означают временные, пространственные, логические отношения и отношения между отдельными предложениями);
- концепты организованы по уровням в соответствии со степенью обобщенности так как, например, сущность, живое существо, животное, плотоядное.
Однако существуют и различия:
- понятие значения с точки зрения философии;
- методы представления кванторов общности и существования и логических операторов;
- способы манипулирования сетями и правила вывода, терминология.
Все это варьируется от автора к автору. Несмотря не некоторые различия, сети удобны для чтения и обработки компьютером, а также достаточно мощны, чтобы представить семантику естественного языка.
В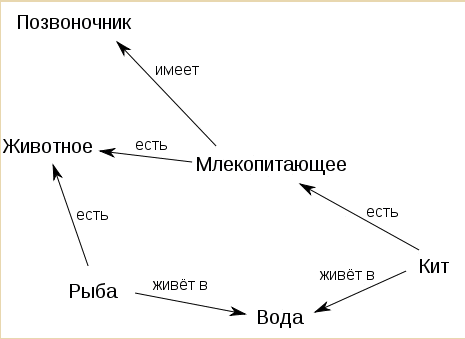 ажнейшими
типизированным отношениями объектов
являются: «Род» – «Вид», «Целое» –
«Часть», «Причина» – «Следствие»,
«Средство» – «Цель», «Аргумент» –
«Функция», «Ситуация» – «Действие».
Типизация отношений позволяет однозначно
интерпретировать смысл ситуаций,
отображаемых в базе знаний и настраивать
механизм вывода особенности этих
отношений. Так, отражение отношений
«Род» - «Вид» дает возможность осуществлять
наследование атрибутов классов объектов
и, таким образом, автоматизировать
процесс выведения заключений от общего
к частному. Способ представления
семантической сети в виде графа
представлен на рисунке 5.1. - В общем
случае под семантической сетью понимается
выражение, приведенное в формуле 5.1
S=(O,R1,R2,…,Rk),
(5.1)
ажнейшими
типизированным отношениями объектов
являются: «Род» – «Вид», «Целое» –
«Часть», «Причина» – «Следствие»,
«Средство» – «Цель», «Аргумент» –
«Функция», «Ситуация» – «Действие».
Типизация отношений позволяет однозначно
интерпретировать смысл ситуаций,
отображаемых в базе знаний и настраивать
механизм вывода особенности этих
отношений. Так, отражение отношений
«Род» - «Вид» дает возможность осуществлять
наследование атрибутов классов объектов
и, таким образом, автоматизировать
процесс выведения заключений от общего
к частному. Способ представления
семантической сети в виде графа
представлен на рисунке 5.1. - В общем
случае под семантической сетью понимается
выражение, приведенное в формуле 5.1
S=(O,R1,R2,…,Rk),
(5.1)
где O – множество объектов конкретной предметной области;
Ri i=1,n – множество отношений между объектами; i – тип отношений.
Из множества существующих методов построения семантической сети был выбран метод создания семантической сети из коллекции текстовых документов определенной предметной области. Суть метода заключается в пошаговом анализе текста, который приведен на рисунке:
5.2. -Процесс создания семантической сети
Н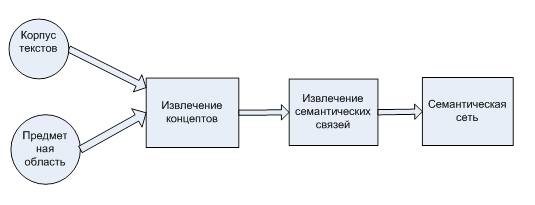 а
этапе извлечения концептов происходит
выделение ключевых слов, выделение
ключевых словосочетаний и группирование
словосочетаний. В свою очередь
группирование ключевых слов разбивается
на несколько этапов, приведенных ниже.
а
этапе извлечения концептов происходит
выделение ключевых слов, выделение
ключевых словосочетаний и группирование
словосочетаний. В свою очередь
группирование ключевых слов разбивается
на несколько этапов, приведенных ниже.
1. Нормализация, токенизация (выделение конкретных токенов – слов определенной части речи), лемматизация (процесс привода словоформы к лемме — её нормальной (словарной) форме – глагол к инфитиву, существительное к ед.ч. именит.падежу, прилагательное к муж.роду, ед.ч., именит.падежу).
2. Фильтрация на основе лингвистической информации: удаление стоп-слов, имен собственных, чисел, дат, всего остального кроме существительных и прилагательных.
3. Ранжирование слов-кандидатов с использованием статистической информации.
Выделение ключевых словосочетаний также делится на отдельные шаги.
1. Извлечение свободных словосочетаний.
2. Группирование словосочетаний-кандидатов, путем поиска наибольших общих подстрок.
3. Ранжирование словосочетаний.