

1. Реляционная модель данных. Отношения. Ключи. Операции над отношениями. Функции на отношениях. Теорема Хита. Нормализация. Первые три нормальные формы. Нормальная форма Бойса-Кодда.
Модель данных, т.е. концептуальное описание предметной области – самый абстрактный уровень проектирования баз данных.
Реляционная модель данных была предложена Е. Коддом, известным американским специалистом в области базы данных. Реляционная модель позволила решить одну из важнейших задач в управлении базами данных – обеспечить независимость представления и описания данных от прикладных программ, следствием чего было бы существенное упрощение проектирования и программирования баз данных.
Основные достоинства реляционного подхода к управлению базой данных:
- наличие небольшого набора абстракций, которые позволяют сравнительно просто моделировать большую часть распространенных предметных областей и допускают точные формальные определения, оставаясь интуитивно понятными.
- наличие простого и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных.
- возможность манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти.
Недостатки:
- некоторая ограниченность реляционных БД при использовании в так называемых нетрадиционных областях, в которых требуются предельно сложные структуры данных.
- невозможность адекватного отражения семантики предметной области.
Термин «реляционный» указывает прежде всего на то, что такая модель хранения данных построена на взаимоотношении составляющих ее частей, которые удобно представлять в виде двумерной таблицы. Реляционная модель данных представляет информацию в виде совокупности взаимосвязанных таблиц, которые принять называть отношениями или реляциями.
Столбцы отношения называют атрибутами, им присваиваются имена, по которым к ним затем производится обращение. Список имен атрибутов с указанием имени доменов (или типов, если домены не поддерживаются) называется схемой отношений. Доменом называется множество атомарных значений одного и того же типа. Домен представляет собой допустимое потенциальное множество значений данного типа. Степень отношения – это число его атрибутов. Отношение степени один называются унарными, степени два – бинарными, степени три – тернарными, а степени n – n-арными. Схемой базы данных называется множество именованных схем отношений. Кортеж, соответствующий данных схеме отношения, представляет собой множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. Степень кортежа совпадает со степенью соответствующей схемы отношения. Схему отношения иногда называют также заголовком отношения, а отношение как набор кортежей – телом отношения.
Поскольку отношение с математической точки зрения является множеством, а множества по определению не содержат совпадающих элементов, то никакие два кортежа отношения не могут быть дубликатами друг друга в любой произвольно заданный момент времени. Т.о., в отношении всегда должен присутствовать некоторый атрибут, определяющий уникальность строк таблицы. Такой атрибут называется первичным ключом отношения.
Определение: если R – отношение с атрибутами А1, А2, …, Аn, то множество атрибутов K=(Ai,Aj,…,Ak) отношения R является первичным ключом этого отношения тогда и только тогда, когда удовлетворяются два независимых от времени условия:
- уникальность – в произвольный момент времени никакие два различных кортежа отношения R не имеют одного и того же значения для А1- Аn.
- минимальность – ни один из атрибутов Ai,Aj,…,Ak не может быть исключен из К без нарушения уникальности.
В зависимости от количества атрибутов, входящих в ключ, различают простые и сложные (или составные) ключи.
Простой ключ – ключ, содержащий только один атрибут.
Сложный или составной ключ – ключ, состоящий из нескольких атрибутов.
Суперключ – сложный ключ с большим числом столбцов, чем необходимо для того, чтобы быть уникальным идентификатором.
В зависимости от того, содержит ли атрибут, являющийся первичным ключом, какую-либо информацию, различают искусственные и естественные ключи.
Искусственный или суррогатный ключ – ключ, созданный самой СУБД или пользователем с помощью некоторой процедуры, который сам по себе не содержит информации. Его часто используют вместо сложного ключа. Система поддерживает искусственный ключ, но он никогда не показывается пользователю.
Естественный ключ – ключ, в который включены значимые атрибуты и который содержит информацию.
Потенциальные или альтернативные ключи – несколько наборов атрибутов, которые также можно выбрать в качестве ключа.
Вторичный ключ – комбинация атрибутов, отличная от комбинации, составляющей первичный ключ. Для них могут задаваться ограничения:
- UNIQUE – ограничение уникальности, значения вторичных ключей не могут дублироваться.
- NOT NULL – значение атрибута не может принимать значение NULL.
Перекрывающиеся ключи – сложные ключи, которые имеют один или несколько общих столбцов.
Внешний ключ – это атрибут или множество атрибутов одного отношения, являющиеся ключом другого или того же самого отношения.
Для манипулирования отношениями используют операции реляционной алгебры. Отношения реляционной алгебры – это множества, поэтому средства работы с отношениями базируются на традиционных операциях теории множеств, которые дополняются некоторыми операциями, специфичными для баз данных.
Пусть F={A0, A1, …, An}, где A0, …, An – множества.
Отношение Р на множестве F – это подмножество декартова произведения, где dom(A0)* dom(A1)*…* dom(An), где dom(Aj) - это домен (множество значений) Aj, j=1..n. R[A0, A1, …, An] представляет Р на множестве { A0, A1, …, An } и называется схемой P. В R[A0, A1, …, An] каждый столбец Aj называется атрибутом R и обозначается как R.Aj, j=1..n.
Каждая строка R представляет кортеж и обозначается как <a0,a1,…,an>, где aj принадлежит dom(Aj). Значение атрибута Aj кортежа k, принадлежащего R, обозначается как k[Aj].
Чаще всего выделяют следующие операции реляционной алгебры:
- операция объединения двух отношение позволяет создать отношение, включающее все строки отношений операндов. Отношения-операнды должны иметь одинаковый набор атрибутов.
- операция пересечения – отношение, содержащее строки, которые входят одновременно в оба отношения-операнда. Отношения-операнды должны иметь одинаковый набор атрибутов.
- разность отношений используется для выделения строк, которые входят в первое отношение и не входят во второе. Отношения-операнды должны иметь одинаковый набор атрибутов.
- при выполнении операции произведения двух отношений, каждая строка первого отношения-операнда сцепляется (конкатенируется) с каждой строкой второго отношения-операнда. Множества атрибутов отношений-операндов не должны пересекаться.
- операция деления «обратна» операции умножения. Пусть имеются два отношения: делимое A с атрибутами {a1,a2,…,an,b1,b2,…,bm} и делитель B с атрибутами {b1,b2,…,bm}. Атрибут отношения А bi и атрибут отношения B bi определены на одном и том же домене и имеют одинаковое имя. Результат деления А на В – отношение С с атрибутами {a1,a2,…,an}.
- операция ограничения (селекции) – это выбор из отношения подмножества кортежей, удовлетворяющих заданному условию.
- операция проекции позволяет выбрать из отношения-операнда определенные столбцы, исключая повторения.
- операция соединения – существует 2 типа: соединение по условию и естественное соединение. Соединение по условию: конкатенация строк отношений, затем полученная сцепленная строка проверяется на соответствие заданному условию. Естественное соединение: если отношения-операнды обладают общим атрибутом (возможно составным), то условие соединения может быть опущено, при этом подразумевается, что сравнение производится на равенство значений общих атрибутов.
- операция переименования изменяет имена атрибутов отношения.
- операция присваивания позволяет сохранить результат вычисления реляционного выражения в отношении БД.
- операция агрегации вычисляет глобальные функции агрегации (sum, max, min и т.д.).
Теорема Хита: Пусть R(А, В, С) является отношением, где А, В и С - атрибуты этого отношения. Если В функционально зависит от А, то R равно соединению его проекций {A, B}и {A, C}.
Это означает, что при наличии функциональной зависимости В от А проекции R[А, В] и R[А, С] образуют полную декомпозицию R.
Функциональная зависимость АВ называется полной функциональной зависимостью, если В зависит от всей группы атрибутов А, а не от ее части (подмножества). Например, если А=А1, А2, ..., Аk и А1,А2 В, то функциональная зависимость В от А неполная.
Первая нормальная форма (1НФ)Отношение находится в первой нормальной форме, если значения всех его атрибутов простые (атомарные), т. е. значение атрибута не должно быть множеством или повторяющейся группой. Ненормализованной структуре соответствует многоуровневая таблица (иерархия) в отличии от однородной табличной структуры.
Пример нарушения 1НФ: в колонке «дети» напротив одного родителя в одной ячейке написаны имена сразу нескольких детей.
Вторая нормальная форма (2НФ)Отношение находится во второй нормальной форме, если оно находится в первой нормальной форме и каждый непервичный атрибут функционально полно зависит от ключа.
Пример нарушения 2НФ: в таблице {ФИО,Должность,НаличиеКомпьютера} атрибут «Наличие компьютера» зависит только от одной части составного ключа «Должность», но не зависит от второй части ключа «ФИО».
Третья нормальная форма (3РФ)Отношение находится в третьей нормальной форме, если оно находится во второй нормальной форме и в нем отсутствуют транзитивные зависимости непервичных атрибутов от ключа.
Если АВ, А не зависит от В (В не является ключом), ВС, то АС.
Пример нарушения 3НФ: в таблице {ФИО,Отдел,ТелефонОтдела} существует транзитивная зависимость ФИО->Отдел, Отдел->ТелефонОтдела. Нужно выделить две таблицы: {ФИО,Отдел} и {Отдел,Телефон}.
Нормальная форма Бойса - Кодда (НФБК)Отношение находится в НФБК, если оно находится в третьей нормальной форме (3НФ) и в нем отсутствуют зависимости первичных атрибутов от непервичных.
Пример нарушения НФБК: в таблице {НомерКорта,ВремяНачалаИгры,Тариф,ФиоЧленаКлуба} атрибут «Тариф» зависит от НомераКорта и ФиоЧленаКлуба. Необходимо разбить эту таблицу на две других: { НомерКорта,ВремяНачалаИгры,ФиоЧленаКлуба } и { Тариф,ФиоЧленаКлуба, НомерКорта }.
2. Объекты в бизнесе и базах данных. Объектный анализ и проектирование программ. Объектная модель СУБД Caché. Виды классов и их структура (имя, свойства, параметры, методы, видимость, запросы, триггеры, наследование). Таблицы, классы, объекты и глобалы.
Представление объектов реального мира в виде плоских реляционных таблиц в большинстве случаев приводит к потере семантики. Однако, множество компаний, имеющих работающие приложения, построенные на базе реляционных таблиц, не желают переходить на объектно-ориентированную технологию, т.к. это приведет к большим затратам на этапе трансляции. Кроме этого, зависимость приложений от структурированного языка запросов (SQL), также является камнем преткновения при принятии решения о переходе на более развитую объектно-ориентированную технологию.
Рис.1. Архитектура Caché.
C aché
- это высокопроизводительная постреляционная
база данных, а также развитая система
управления базой данных (СУБД). Основным
отличием
БД Caché
от РБД и ООБД является универсальность
представления данных в Caché,
реализуемая с помощью т.н. единой
архитектуры данных. В рамках
этой архитектуры существует единое
описание объектов и таблиц, отображаемых
непосредственно в многомерные
структуры ядра
базы данных, ориентированного на
обработку транзакций. Имеющиеся серверы
Caché
Objects
и Caché
SQL
предоставляют
в распоряжение разработчика все наиболее
популярные интерфейсы, посредством
которых и унаследованные реляционные
и новые объектно-ориентированные
прикладные системы получают равноправный
доступ к данным. Кроме реляционного и
объектного доступов к данным,
разработчику
предлагается прямой
доступ к данным
(Caché
Direct),
т.е. доступ непосредственно к многомерным
структурам ядра. Архитектура Caché
приведена на рис. 1.
aché
- это высокопроизводительная постреляционная
база данных, а также развитая система
управления базой данных (СУБД). Основным
отличием
БД Caché
от РБД и ООБД является универсальность
представления данных в Caché,
реализуемая с помощью т.н. единой
архитектуры данных. В рамках
этой архитектуры существует единое
описание объектов и таблиц, отображаемых
непосредственно в многомерные
структуры ядра
базы данных, ориентированного на
обработку транзакций. Имеющиеся серверы
Caché
Objects
и Caché
SQL
предоставляют
в распоряжение разработчика все наиболее
популярные интерфейсы, посредством
которых и унаследованные реляционные
и новые объектно-ориентированные
прикладные системы получают равноправный
доступ к данным. Кроме реляционного и
объектного доступов к данным,
разработчику
предлагается прямой
доступ к данным
(Caché
Direct),
т.е. доступ непосредственно к многомерным
структурам ядра. Архитектура Caché
приведена на рис. 1.
Независимость хранения данных от способа их представления дает разработчику возможность создавать приложения на языках программирования, поддерживающих как реляционную технологию (ODBC, JDBC), так и объектную (Java, С++, XML и т.д.). При этом нет необходимости создавать промежуточную среду для конвертирования из одного формата представления данных в другой - Caché произведет необходимое конвертирование автоматически.
Объектная модель Caché поддерживает несколько видов классов (рис.2).
Рис.2. Объектная модель Caché
C aché
классы подразделяются на два типа –
классы типов данных и классы объектов.
Классы типов
данных
определяют допустимые значения констант
(литералов) и позволяют их контролировать.
Классы типов данных могут выступать
как системные или предопределенные
константы (%Integer,
%String
и т.д.), так и константы, определенные
пользователем. Классы типов данных не
могут содержать свойств. Невозможно
создать экземпляр класса типов данных,
что является главным отличием от классов
объектов.
aché
классы подразделяются на два типа –
классы типов данных и классы объектов.
Классы типов
данных
определяют допустимые значения констант
(литералов) и позволяют их контролировать.
Классы типов данных могут выступать
как системные или предопределенные
константы (%Integer,
%String
и т.д.), так и константы, определенные
пользователем. Классы типов данных не
могут содержать свойств. Невозможно
создать экземпляр класса типов данных,
что является главным отличием от классов
объектов.
Зарегистрированные классы обладают предопределенным поведением, т.е. набором встроенных функций, наследуемых из системного класса %RegisteredObject (следует также заметить, что знак процента определяет принадлежность класса или метода к системному классу) и отвечающих за создание новых объектов и за управление размещением объектов в памяти. Незарегистрированные классы не обладают предопределенным поведением и разработка функций класса целиком и полностью возлагается на разработчика.
Встраиваемые и хранимые классы обычно наиболее часто используются в проектах, поэтому рассмотрим их подробнее.
Встраиваемые классы.
Встраиваемые классы наследуют свое поведение от класса %SerialObject. Основной особенностью хранения встраиваемого класса является то, что в памяти объекты встраиваемых классов существуют как независимые экземпляры, однако могут быть сохранены в базе данных, только будучи встроены в другой класс.
Основным преимуществом использования встроенных классов является минимум издержек, связанных с возможным в будущем изменением набора одинаковых свойств классов, представленного в виде встраиваемого объекта.
Хранимые классы.
Хранимые классы наследуют свое поведение от класса %Persistent. Класс %Persistent предоставляет обширный набор функций своим наследникам, включающий создание объекта, подкачку объекта из БД в память, удаление объекта и т.д. Определимся с уникальной идентификацией объектов хранимых классов в памяти и в БД. Каждый экземпляр (объект) класса имеет 2 уникальных идентификатора – OID и OREF. OID (object ID) уникально идентифицирует объект, в таблице размещения объектов БД, т.е. на физическом носителе, а OREF (object reference) уникально идентифицирует объект, который был подкачан из БД и находится в памяти компьютера.
Хранимый класс (наследуемый от системного класса %Persistent) Caché предоставляет набор методов для работы с объектами. Эти методы включают: метод %New() – для создания нового объекта класса в памяти, метод %OpenId(OID) – для подкачки существующего объекта в память, метод %Delete(OID) – удаление объекта из БД, метод %Save() – сохранение объекта в БД, %Close() – удаление проекта из памяти.
Структура классов. Полный список элементов определения класса охватывает:
Имя класса - задает общее описание содержания класса.
Свойства - атрибуты .
Методы. Методами называют операции, которые может выполнять объект или класс объектов. Каждый метод обладает однозначным именем, формальной спецификацией аргументов и возвращаемого значения и кодом метода.
Наиболее часто используемыми разновидностями методов в разрабатываемых проектах являются метод-код и метод-выражение.
Метод-код содержит код, написанный на COS или Caché BASIC, который при компиляции преобразуется в программу Caché. Созданная программа вызывается каждый раз при обращении к методу класса или методу объекта.
Метод-выражение содержит одно выражение, результат выполнения которого является выходным значением метода.
Триггер (англ. trigger) — это хранимая процедура особого типа, которую пользователь не вызывает непосредственно, а исполнение которой обусловлено действием по модификации данных: добавлением INSERT, удалением DELETE строки в заданной таблице, или изменением UPDATE данных в определенном столбце заданной таблицы реляционной базы данных. Триггеры применяются для обеспечения целостности данных и реализации сложной бизнес-логики. Триггер запускается сервером автоматически при попытке изменения данных в таблице, с которой он связан. Все производимые им модификации данных рассматриваются как выполняемые в транзакции, в которой выполнено действие, вызвавшее срабатывание триггера. Соответственно, в случае обнаружения ошибки или нарушения целостности данных может произойти откат этой транзакции.
Параметры класса — это константы, то есть значения, устанавливаемые во время определения класса для всех объектов этого класса.
Запросы – это фильтры, позволяющие выделить набор объектов, удовлетворяющий каким-то условиям.
Индекс — это путь доступа к экземплярам класса. Индексы используются для оптимизации скорости выполнения запросов.
Класс в объектной модели представляет собой ни что иное, как таблицу в реляционной модели. А объект (экземпляр класса) – строку таблицы.
В чем состоит разница между объектом и классом? Класс - это структура данных и программный код, определяемые программистом. Класс состоит из описания характера данных, способа их хранения и кода, но не содержит никакой реальной информации. Объект – это реальная сущность, т.е. индивидуальный «экземпляр» класса». Например, счет №123456 является объектом класса «счет-фактура».
Глобалы – сохраняемые многопользовательские переменные. Глобалы – это длительно хранимые (как правило, многомерные) структуры данных, обрабатываемые в многопользовательской среде различными процессами. Например, приложение "Инвентаризация склада", содержащее описание изделия (размер, цвет и рисунок), может иметь следующую структуру данных:
^Склад(изделие,размер,цвет,рисунок) = количество
3. Анализ, проектирование и разработка программных продуктов. Моделирование бизнеса. Группа стандартов IDEF. Модели As IS, TO BE и FEO. Моделирование бизнес-процессов в стандартах IDEF0 и IDEF3.
Жизненный цикл программного обеспечения (ПО) представляет собой модель его создания и использования. Данная модель отражает его различные состояния, начиная с момента возникновения потребности в данном ПО и заканчивая моментом его полного выхода из употребления у всех пользователей.
Этап анализа предполагает подробное исследование бизнес-процессов (функций, определенных на предыдущем этапе) и информации, необходимой для их выполнения (сущностей, их атрибутов и связей (отношений)). Этот этап дает информационную модель, а следующий за ним этап проектирования — модель данных.
Вся информация о системе, собранная на этапе определения стратегии, формализуется и уточняется на этапе анализа. Особое внимание следует уделить полноте переданной информации, анализу информации на непротиворечивость, а также поиску неиспользуемой или дублирующейся информации.
На этапе проектирования формируется модель данных. Проектировщики получают входные данные анализа. Конечным продуктом этапа проектирования являются схема базы данных (если таковая существует в проекте) или схема хранилища данных (ER-модель) и набор спецификаций модулей системы (модель функций). Задачами проектирования являются:
рассмотрение результатов анализа и проверка их полноты;
семинары с заказчиком;
определение критических участков проекта и оценка ограничений проекта;
определение архитектуры системы;
принятие решения об использовании продуктов сторонних разработчиков, а также о способах интеграции и механизмах обмена информации с этими продуктами; проектирование хранилища данных: модель базы данных, бета-версия базы данных;
проектирование процессов и кода: окончательный выбор средств разработки, определение интерфейсов программ, отображение функций системы на ее модули и определение спецификаций модулей; определение требований к процессу тестирования;
определение требований безопасности системы.
При реализации проекта важно координировать группу (группы) разработчиков. Все разработчики должны подчиняться жестким правилам контроля исходных тестов. Группа разработчиков, получив технический проект, начинает писать код модулей. Основная их задача состоит в том, чтобы уяснить спецификацию: проектировщик написал, что надо сделать, разработчик определяет, как это сделать.
На этапе разработки осуществляется тесное взаимодействие проектировщиков, разработчиков и групп тестировщиков. В случае интенсивной разработки тестировщик буквально неразлучен с разработчиком, фактически становясь членом группы разработки.
Понятие "моделирование бизнес-процессов" пришло в быт большинства аналитиков одновременно с появлением на рынке сложных программных продуктов, предназначенных для комплексной автоматизации управления предприятием. Подобные системы всегда подразумевают проведение глубокого предпроектного обследования деятельности компании. Результатом этого обследование является экспертное заключение, в котором отдельными пунктами выносятся рекомендации по устранению "узких мест" в управлении деятельностью. На основании этого заключения, непосредственно перед проектом внедрения системы автоматизации, проводится так называемая реорганизация бизнес-процессов, иногда достаточно серьезная и болезненная для компании. Это и естественно, сложившийся годами коллектив всегда сложно заставить "думать по-новому". Подобные комплексные обследования предприятий всегда являются сложными и существенно отличающимися от случая к случаю задачами. Для решения подобных задач моделирования сложных систем существуют хорошо обкатанные методологии и стандарты. К таким стандартам относятся методологии семейства IDEF. С их помощью можно эффективно отображать и анализировать модели деятельности широкого спектра сложных систем в различных разрезах. При этом широта и глубина обследования процессов в системе определяется самим разработчиком, что позволяет не перегружать создаваемую модель излишними данными. В настоящий момент к семейству IDEF можно отнести следующие стандарты – IDEF 0-14.
IDEF0 - методология функционального моделирования. С помощью наглядного графического языка IDEF0, изучаемая система предстает перед разработчиками и аналитиками в виде набора взаимосвязанных функций (функциональных блоков - в терминах IDEF0). Как правило, моделирование средствами IDEF0 является первым этапом изучения любой системы;
IDEF3 – методология документирования процессов, происходящих в системе, которая используется, например, при исследовании технологических процессов на предприятиях. С помощью IDEF3 описываются сценарий и последовательность операций для каждого процесса. IDEF3 имеет прямую взаимосвязь с методологией IDEF0 – каждая функция (функциональный блок) может быть представлена в виде отдельного процесса средствами IDEF3. IDEF3 состоит из двух методов: Process Flow Description (PFD) — Описание технологических процессов, с указанием того, что происходит на каждом этапе технологического процесса; Object State Transition Description (OSTD) — описание переходов состояний объектов, с указанием того, какие существуют промежуточные состояния у объектов в моделируемой системе.
Модель as is- «как есть» -модель существующего сост-я орг-и. Данная модель позволяет систематизировать протекающие в данный момент процессы, а также используемые информацинные объекты. На основе этого выявляются узкие места в орг-и и взаимодействии бизнес-процессов, определяется необходимость тех или иных изменений существующей структуры. Такую модель часто называют функциональной и выполняют ее с исп-ем различных графич. Нотаций и case-средств. На этапе построения модели важным считается строить максимально приближенные к действительности модели.
Модель to be «как должно быть». Как правило, создается на основе as is с устранением недостатков в существующей организации бизнес-процессов, а также их совершенствованием и оптимизацией. Это достигается за счет устранения выявленных на базе анализа as is узких мест.
Feo (For Exposition Only) диаграмма- это диаграмма иллюстрация отдельных фрагментов модели и\или для иллюстрации альтернативой точки зрения, либо ее спец. Целей, которые не поддерживаются явно синтаксисом IDEF0. Это графическое описание, используемое для сообщения специфич. Факторов о диаграмме IDEF0. FEO диаграммы позволяют нарушить любое синтаксическое правило, поскольку эти диаграммы - фактически обычные картинки - копии стандартных диаграмм.
4. Моделирование реляционных баз данных в стандарте IDEF1X. Логическая и физическая модели. Модель, основанная на ключах. Виды связей между сущностями. Миграция ключей. Прямой и обратный инжиниринг. Перенос приложений от одной СУБД к другой.
Стандарт IDEF1X позволяет описывать структуру базы.
В организации стандарта IDEF1X реализован своеобразный подход к терминологии модели бизнеса:
- логическая модель
- ERD – обычно ER диаграммы относят концептуальному уровню. По сути это семантическая сеть.
- KB (Key Based) – диаграммы, основанные на ключах
- FA (Fully Attribute Model) – модель, описанная с атрибутами.
- физическая модель.
В логической модели есть только названия атрибутов, но нет типов.
Вообще говоря, ER- диаграмма – это частный случай семантической сети. Не обязательно ее отражение в реляционную модель будет работать эффективно. Например, если в задаче необходимо часто работать с деревьями, наиболее эффективная реализации получится в СУБД, специально оптимизированных для работы с деревьями (например, Cache). Иногда в больших комплексах это приводит к разделению задачи под несколько различных СУБД.
IDEF1X является методом для разработки реляционных баз данных и использует условный синтаксис, специально разработанный для удобного построения концептуальной схемы. Концептуальной схемой называется универсальное представление структуры данных в рамках коммерческого предприятия, независимое от конечной реализации базы данных и аппаратной платформы. Будучи статическим методом разработки, IDEF1X изначально не предназначен для динамического анализа по принципу 'AS IS', тем не менее, он иногда применяется в этом качестве.
Сущность в IDEF1X описывает собой совокупность или набор экземпляров похожих по свойствам, но однозначно отличаемых двух от друга по одному или нескольким признакам. Каждый экземпляр является реализацией сущности. Таким образом, сущность в IDEF1X описывает конкретный набор экземпляров реального мира.
Связи между сущностями
Связи в IDEF1X представляют собой ссылки, соединения и ассоциации между сущностями. Связи это суть глаголы, которые показывают, как соотносятся сущности между собой. Ниже приведен ряд примеров связи между сущностями:
Отдел состоит из нескольких Сотрудников.
Самолет перевозит нескольких Пассажиров.
С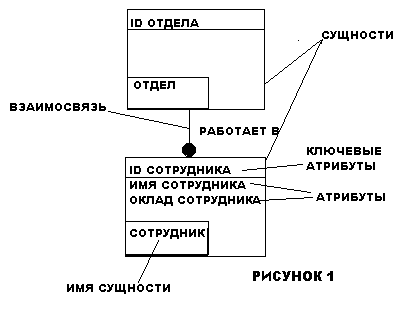 отрудник
готовит
разные Отчеты.
отрудник
готовит
разные Отчеты.
Во всех перечисленных примерах взаимосвязи между сущностями соответствуют схеме один ко многим. Это означает, что один экземпляр первой сущности связан с несколькими экземплярами второй сущности. Причем первая сущность называется родительской, а вторая - дочерней. На рис. 1 приводится диаграмма связи между Сотрудником и Отделом.
Отношения 'многие ко многим' обычно используются на начальной стадии разработки диаграммы, например, в диаграмме зависимости сущностей, и отображаются в IDEF1X в виде сплошной линии с точками на обоих концах. Так как отношения 'многие ко многим' могут скрыть другие бизнес правила или ограничения, они должны быть полностью исследованы на одном из этапов моделирования. Например, иногда отношение 'многие ко многим' на ранних стадиях моделирования идентифицируется неправильно, на самом деле представляя два или несколько случаев отношений 'один ко многим' между связанными сущностями. Или, в случае необходимости хранения дополнительных сведений о связи 'многие ко многим', например, даты или комментария, такая связь должна быть заменена дополнительной сущностью, содержащей эти сведения.
Идентификация сущностей. Представление о ключах
Сущность описывается в диаграмме IDEF1X графическим объектом в виде прямоугольника. На рис.2 приведен пример IDEF1X диаграммы. Каждый прямоугольник, отображающий собой сущность, разделяется горизонтальной линией на часть, в которой расположены ключевые поля и часть, где расположены не ключевые поля. Верхняя часть называется ключевой областью, а нижняя часть - областью данных. Ключевая область объекта СОТРУДНИК содержит поле 'Уникальный идентификатор сотрудника', в области данных находятся поля 'Имя сотрудника', 'Адрес сотрудника', 'Телефон сотрудника' и т.д.
К лючевая
область содержит первичный
ключ для
сущности. Первичный
ключ - это
набор атрибутов, выбранных для
идентификации уникальных экземпляров
сущности. Атрибуты первичного ключа
располагаются над линией в ключевой
области. Не ключевой атрибут - это
атрибут, который не был выбран ключевым.
лючевая
область содержит первичный
ключ для
сущности. Первичный
ключ - это
набор атрибутов, выбранных для
идентификации уникальных экземпляров
сущности. Атрибуты первичного ключа
располагаются над линией в ключевой
области. Не ключевой атрибут - это
атрибут, который не был выбран ключевым.
В качестве первичных ключей могут быть использованы несколько атрибутов или групп атрибутов. Атрибуты, которые могут быть выбраны первичными ключами, называются кандидатами в ключевые атрибуты (потенциальные атрибуты). Кандидаты в ключи должны уникально идентифицировать каждую запись сущности. В соответствии с этим, ни одна из частей ключа не может быть NULL, не заполненной или отсутствующей.
Правила, по которым выбирается первичный ключ из списка предполагаемых ключей, устанавливают, что атрибуты и группы атрибутов должны:
1) Уникальным образом идентифицировать экземпляр сущности.
2) Не использовать NULL значений.
3) Не изменяться со временем. Экземпляр идентифицируется при помощи ключа. При изменении ключа соответственно меняется экземпляр.
4) Быть как можно более короткими для использования индексирования и получения данных.
При выборе первичного ключа для сущности разработчики модели часто используют дополнительный (суррогатный) ключ, т.е. произвольный номер, который уникальным образом определяет запись в сущности. Суррогатный ключ лучше всего подходит на роль первичного ключа потому, что является коротким и быстрее всего идентифицирует экземпляры в объекте. К тому же суррогатные ключи могут автоматически генерироваться системой так, чтобы нумерация была сплошной.
Потенциальные ключи, которые не выбраны первичными, могут быть использованы в качестве вторичных или альтернативных ключей. С помощью альтернативных ключей часто отображают различные индексы доступа к данным в конечной реализации реляционной базы.
Если сущности в IDEF1X диаграмме связаны, связь передает ключ (или набор ключевых атрибутов) дочерней сущности. Эти атрибуты называются внешними ключами. Внешние ключи определяются как атрибуты первичных ключей родительского объекта, переданные дочернему объекту через их связь. Передаваемые атрибуты называются мигрирующими.
В IDEF1X концепция зависимых и независимых сущностей усиливается типом взаимосвязей между двумя сущностями. Если необходимо, чтобы внешний ключ передавался в дочернюю сущность (и, в результате, создавал зависимую сущность), то можете создать идентифицирующую связь между родительской и дочерней сущностью. Идентифицирующие взаимосвязи обозначаются сплошной линией между сущностями.
Неидентифицирующие связи, являющиеся уникальными для IDEF1X, также связывают родительскую сущность с дочерней. Неидентифицирующие связи используются для отображения другого типа передачи атрибутов внешних ключей - передача в область данных дочерней сущности (под линией). Неидентифицирующие связи отображаются пунктирной линией между объектами. Так как переданные ключи в неидентифицирующей связи не являются составной частью первичного ключа дочерней сущности, то этот вид связи не проявляется ни в одной идентифицирующей зависимости. В этом случае и ОТДЕЛ, и СОТРУДНИК рассматриваются как независимые сущности.
Тем не менее, взаимосвязь может отражать зависимость существования, если бизнес-правило для взаимосвязи определяет то, что внешний ключ не может принимать значение NULL. Если внешний ключ должен существовать, то это означает, что запись в дочерней сущности может существовать только при наличии ассоциированной с ним родительской записи.
Связь является идентифицирующей тогда и только тогда, когда первичный ключ дочерней сущности содержит внешний ключ, идущий от родительской сущности. Если такой вещи нет - связь будет неидентифицирующей.
Пример: Есть две сущности - ВОПРОС и ОТВЕТ. Связь ВОПРОС-ОТВЕТ является идентифицирующей, поскольку сущность ОТВЕТ не может быть однозначно определена, если не задана сущность ВОПРОС (просто ответов без вопроса нет).
Сущности ДОМ и КВАРТИРА. Сущность КВАРТИРА не может быть однозначно определена, если не задана сущность ДОМ.
Что касается неидентифицирующих связей. Есть сущность ЗВАНИЕ и сущность ПОЛЬЗОВАТЕЛЬ. Пользователь обладает каким-то званием (например, "Ученик"), но сущность Пользователь может быть однозначно определена и без этого звания (например, по e-mail). То есть поле Звание таблицы Пользователь не входит в первичный ключ сущности Пользователь.
Процесс генерации физической схемы базы данных из логической модели данных называется прямым проектированием (Forward Engineering). При генерации физической схемы, ERwin позволяет включать триггеры ссылочной целостности, хранимые процедуры, индексы, ограничения и другие возможности, доступные при определении таблиц в СУБД.
Аналогично, процесс генерации логической модели из физической базы данных называется обратным проектированием (Reverse Engineering). ERwin позволяет быстро создать модель данных путем обратного проектирования имеющейся базы данных. После того как создана модель ERwin, можно произвести обратное проектирование структуры базы данных, а затем легко перенести его в другой формат базы данных.
5. Структуры предприятий. Менеджмент. Обеспечение бизнес-процессов. Матричные диаграммы. Методологии управления mrpi, mrpii, erp.
Менеджмент (от англ. management — управление, руководство, менеджмент, администрация, дирекция, умение владеть) — разработка (моделирование и т.д.), создание (организация), максимально эффективное использование (управление) и контроль социально-экономических систем.
Структуры предприятий делятся на вертикальные и горизонтальные.
Вертикальные структуры предприятия:
Линейная структура (чистая иерархия).
Штабная организация (исправляет недостатки линейной).
Дивизионная организация (от англ. слова Division).
Горизонтальные структуры предприятия:
Бригадная структура (чисто горизонтальная структура).
Матричная структура (сочетает в себе положительные свойства горизонтальной и вертикальной структур).
Линейная структура эффективна для стабильных экономических ситуаций. Это наиболее распространенная структура. Иерархия предполагает жесткое распределение компетентности. Если бизнес меняющийся, то иерархическая структура не подходит. Эта система обладает одной неприятной особенностью: она может вырождаться в систему, целью которой является поддержание самой себя. Так как организация обладает памятью, то сломать структуру можно, но потеряется память.
Для избежания проблем на иерархии создается штаб, который может подчиняться, например, директору. Когда проблема решается, то штаб распускается.
Дивизионная организация применяется для того, чтобы снизить нагрузку топ-менеджеров. В дивизионной структуре есть группа топ-менеджеров, которым подчиняются дивизии, имеющие между собой горизонтальную связь. Задача верхнего звена – определить, правильно ли работает дивизион.
В бригадной структуре основой является организация работ по рабочим группам (бригадам) по принципам: автономная работа рабочих групп (бригад); самостоятельное принятие решений рабочими группами и координация деятельности по горизонтали; замена жестких управленческих связей бюрократического типа гибкими связями; привлечение для разработки и решения задач сотрудников разных подразделений.
Матричная структура – это система с многократным подчинением (обычно в проектных организациях в крупных компаниях). Члены проектной команды находятся не только в прямом подчинении руководителя проекта, но и в подчинении руководства функциональных подразделений. Управление идет по двум линиям: проектной и функциональной.
Бизнес-процесс - устойчивая, целенаправленная совокупность взаимосвязанных видов деятельности, которая по определенной технологии преобразует входы в выходы, представляющие ценность для потребителя. Наиболее простым определением данного термина можно считать цепочку работ (операций, функций), результатом которой является какой-либо продукт или услуга.
Бизнес-процессы могут подвергаться моделированию с помощью различных методов. Под бизнес-моделированием (деловым моделированием) понимают деятельность по формированию моделей организаций, включающую описание деловых объектов (подразделений, должностей, ресурсов, ролей, процессов, операций, информационных систем, носителей информации и т. д.) и указание связей между ними.
При формализации описания предприятия минимальную фиксированную единицу действия или активности называют бизнес-функцией (БФ).
Матричная диаграмма (таблица качества; матрица связей, матричное представление данных) – инструмент, позволяющий выявлять важность различных неочевидных (скрытых) связей, т. е. исследовать структуру проблемы. Обычно используются двумерные матрицы в виде таблиц со строками и столбцами.
Символ на пересечении строки и столбца указывает на наличие связи между соответствующими элементами и ее относительную важность.
Применение матричной диаграммы: часто бизнес-функции помещаются в таблицу, в которой по горизонтали располагаются бизнес-функции, а по вертикали исполнители. На пересечении строк и столбцов указывается время выполнения функции исполнителем. уммируя значения по строкам можно узнать загруженность исполнителя.
Перед 2 мировой войной на ряде европейских предприятий стало понятно, что для управления дискретным производством нужно прежде всего решить задачу планирования ресурсов. В дальнейшем, такие системы были компьютеризированы. Необходимыми условиями успеха таких систем являются:
- эффективная компьютерная система.
- точные спецификации продуктов ВОМ (Bill Of Materials)
- сведения о состоянии запасов готовых продуктов, их компонентов, материалов и сырья
- достаточно большая длительность цикла обработки
- надежное определение длительности производственных и закупочных циклов
- возможность реализации главного календарного плана без чрезмерных усилий
- активное участие всего топ-менеджмента.
MRP (Material Requirements Planning) – [Автоматизированное планирование потребности сырья и материалов для производства]. Методология планирования потребности в материальных ресурсах, заключающаяся в определении конечной потребности в ресурсах по данным объемно-календарного плана производства. Ключевым понятием методологии является понятие "разузлование", т.е. приведение древовидного состава изделия к линейному списку (Bill of Materials), по которому планируется потребность и осуществляется заказ комплектующих. Ее усовершенствованная версия, Closed Loop MRP (планирование потребности в материалах в замкнутом цикле), позволила динамически корректировать планы закупок при возникновении нештатных отклонений от них.
CRP (Capacity Requirements Planning) – Планирование производственных ресурсов. Данная концепция схожа с MRP, но вместо единого понятия состава изделия она оперирует такими понятиями, как "обрабатывающий центр", "машина", "рабочие ресурсы", ввиду чего технически реализация CRP более сложна. Обычно применяется совместно с MRP ввиду тесной логической связи при планировании. Методологии MRP/CRP применяются в АСУП производственных предприятий.
MRPII (Manufacturing Resources Planning) – [Планирование и управление всеми производственными ресурсами предприятия: сырьем, материалами, оборудованием, трудозатратами]. Планирование производства. Интегрированная методология, включающая MRP/CRP и, как правило, MPS (Master Planning Shedule – методология "объемно-календарного планирования") и FRP (Finance Requirements Planning – Планирование финансовых ресурсов). При использовании данной методологии обязательно подразумевается анализ финансовых результатов производственного плана.
ERP (Enterprise Resources Planning) – [Управление корпоративными ресурсами. К свойствам MRPII добавилось управление финансовыми ресурсами, маркетинг. ERP концепция – первая направленная на управление бизнесом, а не только производства, как MRP]. Концепция бизнес-планирования. Под ERP подразумевается "интегрированная" система, выполняющая функции, предусмотренные концепциями MPS-MRP/CRP-FRP. Важным отличием от методологии MRPII является возможность "динамического анализа" и "динамического изменения плана" по всей цепочке планирования. Конкретные возможности методологии ERP существенно зависят от программной реализации. Концепция ERP более "размыта", чем MRPII. Если MRPII имеет явно выраженную направленность на производственные компании, то методология ERP оказывается применимой и в торговле, и в сфере услуг, и в финансовой сфере.
6. Интернет-реклама. Методы оценки эффективности.
Интернет-реклама — реклама, размещаемая в сети Интернет; представление товаров, услуг или предприятия в сети Интернет, адресованное массовому клиенту и имеющее характер убеждения.
Реклама в Интернете обладает рядом преимуществ в отличие от обычной рекламы: возможность оперативного анализа и корректировки рекламной кампании, интерактивность (связь потребителя с рекламодателем для оформления заказа непосредственно через рекламный носитель и т. п.), относительно низкая стоимость, возможности автоматизации таргетинга и профайлинга и т. п.
За счет возможности отслеживания реакции и действий пользователя сети Интернет рекламодатель может быстро вносить изменения в действующую рекламную кампанию. Желаемые действия пользователя называются конверсия. Ключевым отличием Интернет рекламы от любой другой есть возможность отслеживания рекламных контактов.
Виды интернет-рекламы
Медийная реклама — размещение текстово-графических рекламных материалов на сайтах, представляющих собой рекламную площадку. По многим признакам аналогична рекламе в печатных СМИ. Однако, наличие у баннера гиперссылки, возможности анимированного изображения и возможности звонка из баннера на мобильный телефон (WOW-call), значительно расширяют воздействие медийной рекламы. Как правило, медийная реклама имеет форму баннерной рекламы.
Контекстная реклама — размещение текстово-графических рекламных материалов на контекстных площадках.
Поисковая реклама — размещение текстово-графических рекламных материалов рядом с результатами поиска на сайтах, либо на сайтах партнеров ПС (поисковых систем), предлагающих пользователю функцию поиска. Демонстрация тех или иных рекламных сообщений зависит от поискового запроса пользователя.
Геоконтекстная реклама — хотя под геоконтекстной рекламой чаще всего понимают рекламу в мобильных телефонах с учётом местоположения пользователя, реклама на веб-картах (например, Google Maps, Яндекс. Карты, Карты@Mail.ru) так же относится к разряду LBA (location-based advertising) и относится к интернет-рекламе. Рекламные сообщения показываются пользователю при просмотре участка карты с учётом контекста запроса. Например, можно просмотреть все салоны красоты в определенном районе города.
Вирусная реклама — вид рекламных материалов, распространителями которой является сама целевая аудитория, благодаря формированию содержания, способного привлечь за счет яркой, творческой, необычной идеи или с использованием естественного или доверительного послания. Как правило в виде такой рекламы выступают интересные видеоролики, flash-приложения и др.
Другие виды рекламы в Интернете как правило совмещают признаки медийной и поисковой рекламы или же переносят эти признаки в смежные с размещением на интернет-страницах области: так, видами Интернет-рекламы считаются размещение рекламы в рассылках по подписке и размещение рекламы в клиентах программ, установленных на рабочей станции пользователя.
Продакт-плейсмент в онлайн играх — интеграция рекламируемого продукта или бренда в игровой процесс, является одним из новых и быстро растущих сегментов рынка интернет-рекламы. Примером такого рода игр могут выступать как очень простые «казуальные» однопользовательские игры, так и большие глобальные многопользовательские стратегии и RPG. По своей сущности, для эффективной рекламы в играх наиболее подходящими являются многопользовательские экономические онлайн игры и бизнес-симуляторы, где собственно товары, услуги и бренды являются основными элементами геймплея.
Другие виды продвижения в Интернете:
C использованием электронной почты (Рассылки подписчикам, Размещение рекламы в новостных рассылках, Индивидуальные письма);
Поисковая оптимизация (SEO) - присутствие ссылки в первых строках результатов поиска по наиболее популярным запросам;
Всплывающие (pop-up) окна и spyware;
Просмотр рекламы за плату или подписка на рекламу;
Электронная доска объявлений;
Участие в рейтингах.
Показатели эффективности
Первичными показателями, используемыми при оценке посещаемости рекламируемого сайта и анализе эффективности интернет-рекламы, являются хит (или посещаемость — запрос к веб-серверу для получения файла) и хост (уникальный компьютер, выдающий эти запросы к веб-серверу, уникальный IP-адрес компьютера, с которого выполняется доступ).
CTR (англ. Click-Through Rate) — основной показатель эффективности интернет-рекламы (синоним — кликабельность, по-русски может называться «откликом»): CTR=Nclick/Nview * 100%
где Nclick — количество нажатий на рекламное сообщение, Nview — количество показов рекламного сообщения посетителю веб-сайта. CTR измеряется в процентах, и является важным показателем эффективности работы рекламного сообщения.
Для динамической рекламы в рунете CTR колеблется от 0,1 % до 3 %.
CTB (англ. Click-To-Buy) — показатель эффективности интернет-рекламы, измеряемый как отношение CTB=Nclients/Nvisitors * 100%
Показатель CTB отражает конверсию посетителей (Nvisitors) в покупателей (Nclients), его иногда называют коэффициентом конверсии.
CTI (англ. Click-To-Interest) — показатель эффективности интернет-рекламы, измеряемый как отношение CTB=Ninterest/Nvisitors * 100%
Заинтересованным (Ninterest) считается тот посетитель сайта, который пролистал несколько его страниц, либо вернулся сюда снова, либо запомнил адрес сайта и факт его существования.
CTR зависит от вида рекламного сообщения и обстоятельств его показа. CTB и CTI зависят от сервера рекламодателя.
Все приведенные выше показатели эффективности сочетают друг с другом, исследуют поодиночке и в соответствии с результатами анализа воздействуют на ход рекламной кампании интернет-проекта.
VTR (View-Through-Rate) — показатель субъективной привлекательности рекламного средства, оценивается как процентное соотношение числа просмотров Nviews к числу показов Nshows рекламного сообщения, а также служит оценкой числа осуществившихся рекламных контактов: VTR=Nviews/Nshows * 100%
Не менее важно, также, оценивать влияние рекламной кампании на объём и структуру аудитории сайта (количественные характеристики: максимальная аудитория, нерегулярная аудитория и т. д.).
В настоящее время выбор средств в рунете для подсчета необходимых показателей ограничивается только показателями счётчиков, установленных на сайте веб-издателя. С помощью счётчиков можно определить:
посещаемость ресурсов, где размещается рекламное сообщение;
целый ряд данных по посещаемости рекламируемого сайта.
Кроме того, часть данных по рекламной кампании поступает непосредственно от сайтов, размещающих у себя рекламное сообщение. Это:
график и схема размещения;
количество показов, кликов (как минимум, с разбивкой по каждому из дней, по каждому из рекламных сообщений, по каждой схеме размещения), CTR;
дополнительные данные. Это информация, полученная о посетителях, собранная в базу данных (к примеру, анкеты, регистрация, база IP-адресов и т. п.).
Внутри компании рекламодатель сам может проводить анализ звонков, поступающих заявок, покупок, контрактов и т. п.
Маркетинговая позиция
Оценка эффективности интернет-рекламы включает технические, экономические, организационные и другие аспекты. По каждому критерию эффективности в ходе рекламной кампании проводятся оценки и в соответствии с ними принимаются необходимые меры по корректировке, развитию и совершенствованию системы маркетинга. В соответствии с этим выделяют следующие группы параметров эффективности:
Экономические. Оценка экономической эффективности выбранного варианта построения маркетинговой системы предприятия.
Организационные. Степень интеграции новой информационной системы с существующей системой, с существующей деятельностью предприятия.
Маркетинговые. Эффективность проведения маркетинговой программы реализации и продвижения веб-сайта в Интернете. Эффективность использования веб-маркетинга.
7. Принципы моделирования программных продуктов с использованием UML
Большинство существующих методов объектно-ориентированного анализа и проектирования (ООАП) включают как язык моделирования, так и описание процесса моделирования. Язык моделирования – это нотация (в основном графическая), которая используется методом для описания проектов.
Нотация представляет собой совокупность графических объектов, которые используются в моделях; она является синтаксисом языка моделирования. Например, нотация диаграммы классов определяет, каким образом представляются такие элементы и понятия, как класс, ассоциация и множественность.
Процесс – это описание шагов, которые необходимо выполнить при разработке проекта.
Унифицированный язык моделирования UML (Unified Modeling Language) – это преемник того поколения методов ООАП, которые появились в конце 80-х и начале 90-х гг.
Язык UML представляет собой общецелевой язык визуального моделирования, который разработан для спецификации, визуализации, проектирования и документирования компонентов программного обеспечения, моделирования бизнес-процессов, системного проектирования и отображения организационных структур и др. Язык UML одновременно является простым и мощным средством моделирования, который может быть эффективно использован для построения концептуальных, логических и графических моделей сложных систем самого различного целевого назначения. UML не является языком программирования, но на основании UML-моделей возможна генерация кода.
Конструктивное использование языка UML основывается на понимании общих принципов моделирования сложных систем и особенностей процесса объектно-ориентированного проектирования (ООП) в частности. Выбор выразительных средств для построения моделей сложных систем предопределяет те задачи, которые могут быть решены с использованием данных моделей. При этом одним из основных принципов построения моделей сложных систем является принцип абстрагирования, который предписывает включать в модель только те аспекты проектируемой системы, которые имеют непосредственное отношение к выполнению системой своих функций или своего целевого предназначения. При этом все второстепенные детали опускаются, чтобы чрезмерно не усложнять процесс анализа и исследования полученной модели.
Другим принципом построения моделей сложных систем является принцип многомодельности. Этот принцип представляет собой утверждение о том, что никакая единственная модель не может с достаточной степенью адекватности описывать различные аспекты сложной системы. Применительно к методологии ООП это означает, что достаточно полная модель сложной системы допускает некоторое число взаимосвязанных представлений (views), каждое из которых адекватно отражает некоторый аспект поведения или структуры системы. При этом наиболее общими представлениями сложной системы принято считать статическое и динамическое представления, которые в свою очередь могут подразделяться на другие более частные представления.) феномен сложной системы как раз и состоит в том, что никакое ее единственное представление не является достаточным для адекватного выражения всех особенностей моделируемой системы.
Еще одним принципом прикладного системного анализа является принцип иерархического построения моделей сложных систем. Этот принцип предписывает рассматривать процесс построения модели на разных уровнях абстрагирования или детализации в рамках фиксированных представлений. При этом исходная или первоначальная модель сложной системы имеет наиболее общее представление (метапредставление). Такая модель строится на начальном этапе проектирования и может не содержать многих деталей и аспектов моделируемой системы.
Главными в разработке UML были следующие цели:
– предоставить пользователям готовый к использованию выразительный язык визуального моделирования, позволяющий разрабатывать осмысленные модели и обмениваться ими;
– предусмотреть механизмы расширяемости и специализации для расширения базовых концепций;
– обеспечить независимость от конкретных языков программирования и процессов разработки;
– обеспечить формальную основу для понимания этого языка моделирования (язык должен быть одновременно точным и доступным для понимания, без лишнего формализма);
– стимулировать рост рынка объектно-ориентированных инструментальных средств;
– интегрировать лучший практический опыт.
Язык UML находится в процессе стандартизации, проводимом OMG (Object Management Group) – организацией по стандартизации в области объектно-ориентированных методов и технологий, в настоящее время принят в качестве стандартного языка моделирования и получил широкую поддержку в индустрии ПО.
В UML используются следующие виды диаграмм:
1) Структурные диаграммы:
Диаграмма классов
Диаграмма компонентов
Композитной/составной структуры
Диаграмма кооперации (UML2.0)
Диаграмма развёртывания
Диаграмма объектов
Диаграмма пакетов
Диаграмма профилей (UML2.2)
2) Диаграммы поведения:
Диаграмма деятельности
Диаграмма состояний
Диаграмма прецедентов
Диаграммы взаимодействия:
Диаграмма коммуникации (UML2.0)
Диаграмма обзора взаимодействия (UML2.0)
Диаграмма последовательности
Диаграмма синхронизации (UML2.0)