

2.3. Теория оптимальности
По мере того как все больше языков анализировалось с автосегментной и метрической точек зрения, обнаруживались повторяющиеся «межлингвистические шаблоны», предполагающие, что не за горами более высокий уровень экспланаторной адекватности. В 1993 году А. Принц и П. Смоленский представили новую модель фонологической деривации — теорию оптимальности (ТО) — в которой отказались от правил, а «объяснительное бремя» возложили исключительно на ограничения (из) универсальной грамматики (УГ).
Модель ТО состоит из двух основных функций. GEN создает большой (возможно, бесконечный) набор потенциальных выходов для любого данного входа, которые затем (EVAL-) оцениваются посредством заданного набора (из УГ) противоречивых ограничений1 (CON), которые тщательно «просеивают» набор кандидатов на предмет устранения всех выходов, кроме правильных. Грамматики отличаются по упорядочению ограничений.
ОТ проводит основное различие между ограничениями по точности совпадения и маркированности. Ограничения по точности совпадения — это ограничения на отношение между входом и потенциальным выходом. Они требуют, чтобы соответствующие сегменты были идентичны в некотором конкретном свойстве.
MAX-V: Don’t delete any V.
Assign a violation for every input V that lacks a correspondent in the output.
MAX-C: Don’t delete any C.
Assign a violation for every input C that lacks a correspondent in the output.
DEP-V: Don’t insert any V.
Assign a violation for every output V that lacks a correspondent in the input.
DEP-C: Don’t insert any C.
Assign a violation for every output C that lacks a correspondent in the input.
WT-IDENT: Don’t shorten or lengthen
Assign a violation for every output segment that has a different number of moras than its input correspondent.
IDENT (F): Don’t change feature F.
Assign a violation for every output segment that has a different specification for feature F than its input correspondent.
Такие ограничения удовлетворяются только в том случае, если выходной кандидат идентичен во всех отношениях входному. Выходной кандидат, удовлетворяющий этим ограничениям, называется точным.
Относительно упорядочения говорится, что:
Все языки имеют один и тот же набор ограничений.
Они имеют одни и те же ограничения по точности совпадения и маркированности.
Эти ограничения относятся к УГ — теории человеческого языка.
Разница между языками лежит в том, как эти ограничения упорядочены.
Для любых двух ограничений А и В, или А доминирует над В (А>>B), или В доминирует над А (B>>A).
Ранжирование ограничений для данного языка состоит из упорядочения ограничений в соответствии с этим отношением доминирования.
Оценка — это выбор одного выхода из всех кандидатов, в терминах набора упорядоченных ограничений.
- Для любого ограничения кандидат А гармоничнее кандидата В относительно этого ограничения, если у него меньше нарушений.
- Для упорядоченного набора ограничений кандидат А гармоничнее кандидата В, если А гармоничнее относительно самого высокого упорядоченного ограничения, по которому расходятся два кандидата.
- Оптимальный кандидат (выбранный кандидат) — это кандидат, который гармоничнее всех остальных относительно упорядоченных ограничений.
Относительно таблиц можно сказать, что:
Ограничения размещаются в столбцах в порядке упорядочения (ограничения более высокого порядка налево от более низкого).
Кандидаты размещаются в строках.
Вход дается в верхней левой ячейке.
Звездочки в каждой ячейке представляют число нарушений этого ограничения в этом кандидате.
«Палец» указывает на оптимального кандидата — фактический выход.
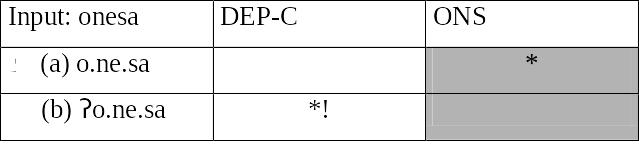
В данном случае
кандидат (а) — оптимальный кандидат,
так как он лучше (b)
по отношению к DEP-C,
самому высокому упорядоченному
ограничению, по которому они расходятся.
В данном случае
кандидат (а) — оптимальный кандидат,
так как он лучше (b)
по отношению к DEP-C,
самому высокому упорядоченному
ограничению, по которому они расходятся.
Фатальное нарушение указано восклицательным знаком после звездочки. Это и есть то нарушение, которое решило исход оценки в пользу (а).
Ячейки направо от фатального нарушения затемнены, указывая, что нарушения в этих ячейках несущественны для выбора.
Конфликт
Два ограничения конфликтуют, если можно улучшить положение дел в отношении одного из них, ухудшив ситуацию относительно другого.
ONS «конфликтует» с DEP-C из-за соотношения выгод и потерь.
Можно устранить слоги без начальных согласных (нарушающих ONS) путем вставления начального С (нарушая DEP-C).
Относительно логики упорядочения можно сказать следующее:
• Пусть некоторая маркированная структура свободно допускается в каком-то языке, то есть не связана с определенным контекстом.
• Тогда ограничение по маркированности, которое противостоит этой структуре, должно занимать подчиненное положение по отношению ко всем ограничениям по точности совпадения, конфликтующим с ним.
• Такое упорядочение говорит, что предпочтительнее жить с (этой) маркированной структурой, чем менять что-либо.
marked structure than to change anything.
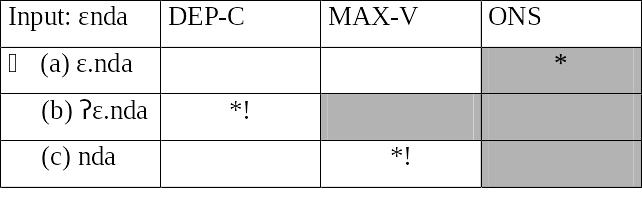
В шона свободно допускаются слоги без начальных согласных в нарушение ONS (например, εnda). Такие слоги можно было бы удалить, 1) вставляя (одну) C (ʔεnda) в нарушение DEP-C или 2) удаляя (одну) V (nda) в нарушение MAX-V. Упорядочение в таком случае должно быть следующим: DEP-C, MAX-V >> ONS.
 Запятая
между двумя ограничениями в упорядочении
указывает, что нет никакого свидетельства
относительно того, как они упорядочены.
Любое (из двух) упорядочение совместимо
с представленным на данный момент
свидетельством. Такой факт отмечается
в таблице пунктирной или точечной линией
между двумя столбцами ограничений.
Запятая
между двумя ограничениями в упорядочении
указывает, что нет никакого свидетельства
относительно того, как они упорядочены.
Любое (из двух) упорядочение совместимо
с представленным на данный момент
свидетельством. Такой факт отмечается
в таблице пунктирной или точечной линией
между двумя столбцами ограничений.
Задание 2.3. Какой кандидат является оптимальным в рассмотренном выше примере из шона и почему?
ФОРМАЛЬНЫЕ МОДЕЛИ И МОРФОЛОГИЯ
Если считать язык сложной системой, выполняющей функцию посредника между пространствами идей и звуков, тогда морфология — это такая подсистема этой системы, которая в равной степени ориентирована как на значение, так и на звучание.
Языковая модель, устанавливающая соответствие между значением (семантическим представлением) и выражающим его звучанием или начертанием (фонетическим или графическим представлением), предполагает правила, задающие такое соответствие. В таком случае морфология обеспечивает «поморфемное» соотнесение компонентов содержания высказывания и его звуковой структуры, т.е. внутренней и внешней стороны словоформ на основе правил, необходимых для точного определения особенностей и закономерностей звукового представления морфем.
Традиционно выделяют методы морфологического анализа с декларативной и процедурной ориентацией. Для методов с декларативной ориентацией характерно наличие полного словаря всех возможных словоформ для каждого слова конкретного языка, причем каждая словоформа снабжена полной и однозначной морфологической информацией, включающей как постоянные, так и переменные морфологические параметры. Задачей морфологического анализа в таком случае является поиск нужной словоформы в словаре и копирование морфологической информации, соответствующей найденной словоформе.
Морфология как раз и предназначена для описания словоформы конкретного языка более экономным способом, чем просто перечисление. Минимальные знаковые единицы словоформ задаются списком, который существенно меньше списка словоформ и создается процедурными методами. Слово разделяется на основу (псевдооснову) и аффикс (псевдофлексию), и в словарь входят только основы вместе со ссылками на соответствующие строки в таблице возможных аффиксов. При разбиении слова на основу и аффикс основным критерием служит неизменность основы во всех возможных словоформах данного слова. Если сравнивать с декларативными методами, то за счет повторяющихся аффиксов уменьшается суммарный объем словаря. Морфологический анализ сводится к выбору из словаря всех основ, совпадающих с начальными буквами анализируемого слова, и для каждой такой основы перебираются все возможные для нее аффиксы.
Формальные морфологические модели
Просодическая морфология
Просодическая, или неконкатенативная, модель появилась в 1970-80-е гг. вследствие изучения морфологии языков, типологически отличных от индоевропейских, и была представлена работами М. Хале, Ж.-Р. Верньо, Дж. Харриса. Суффиксы в таких языках могут не иметь постоянного звукового состава. Довольно распространенный процесс редупликации добавляет к основе копию нескольких начальных или конечных звуков корня. Изучение подобных явлений в словообразовании показало, что морфемы в таких случаях имеют тоже строго заданную форму — только вместо постоянного звукового состава у них постоянная просодическая форма.
Просодия может регулировать морфологические операции посредством ограничений, налагаемых на просодическую форму производного слова. Определенную просодическую структуру может иметь не только прибавляемый суффикс — в некоторых процессах словообразования на просодическую форму основы (корня) слова могут также налагаться ограничения. В одном из языков индейцев Никарагуа, суффикс -ka, означающий «его», может присоединяться только к основе, составляющей метрическую стопу, которая должна быть равна одному закрытому или двум открытым слогам. Если основа длиннее стопы, суффикс вставляется в середину слова сразу за метрической стопой основы. Такое явление называется инфиксацией, и в теории просодической морфологии инфиксация — это просто вариант суффиксации. Так как просодия разрешает присоединять суффикс только к основе, имеющей определенную просодическую форму, выполнение этого требования объясняет, почему аффикс появляется в середине слова.
В рамках теории просодической морфологии связь фонологии и морфологии предстает в виде двух основных способов влияния просодии на процессы словообразования. Во-первых, многие морфологические операции используют просодические (не сегментные) структуры для построения новых слов — при этом или аффиксы являются отдельными частями просодической иерархии (как при редупликации), или основа слова должна иметь определенную просодическую форму (как при инфиксации). Во-вторых, просодия определяет конечные цели словообразования, как в случаях, когда вся результирующая структура или производное слово должны быть определенной длины, т.е. иметь определенную просодическую форму (как, например, в семитских языках).
Двухуровневая морфология
В случае двухуровневой морфологии есть два уровня представления языковой информации: поверхностный и глубинный. На поверхностном уровне слова представлены так, как они произносятся или пишутся. На глубинном (лексическом) уровне представлен алфавит символов, включающий специальные диакритические символы. Эти два уровня связаны между собой возможными соответствиями между символами поверхностной и глубинной структур. В формальной записи последовательность следующая: символ глубинной структуры : символ поверхностной структуры, например, а : а. Использование той или иной пары в определенном контексте ограничивается правилами.
В двухуровневой морфологии правила применяются параллельно, поэтому нет промежуточных уровней представления. В данной модели при применении правил устанавливается однозначное соответствие между парами глубинных и поверхностных символов. Например, вместо замены при переписывании символа а на символ b, как, например, в генеративной фонологии, правила двухуровневой морфологии устанавливают однозначное соответствие между этими символами. Таким образом, а не превращается в b и остается доступным другим правилам.
В генеративной фонологии правила работают только в одном направлении — продукции словоформ, а в двухуровневой модели правила могут применяться в двух направлениях: как в направлении генерации словоформ, так и в направлении распознавания уже готовых (словоформ). Эта особенность двухуровневой модели полезна в компьютерных разработках — система может не только генерировать правильные словоформы, но и распознавать вводимые пользователем словоформы.
Возьмем, к примеру, запись правила, определяющего необходимость эпентетической вставки е в английском языке при образовании множественного числа существительных и глаголов 3-го лица ед. числа в Present Simple с основой, оканчивающейся на s, z, x, ch, sh.
+ :e <= s x z [{sc}h] : _ s.
Согласно этому правилу на стыке основы, оканчивающейся на s, z, x, ch, sh, и показателя множественного числа s границе основы (граница обозначена знаком +) на поверхностном уровне должно соответствовать e.
В фигурных скобках перечисляются возможные варианты (в нашем случае это sh и ch). Вся последовательность заключена в прямые скобки. По умолчанию (когда не указан контекст) границе будет соответствовать «ноль». Указание контекста налагает ограничение, и границе соответствует e. Применение правила тогда будет выглядеть так:
#box + s#


0box e s0
Лексикон — особый блок в двухуровневой морфологии, основная роль которого заключается в определении возможных сочетаний морфов. Во-вторых, он является отсеивающим негативный материал фильтром.
Двухуровневая морфология
Двухуровневая морфология — первая общая модель в истории компьютерной лингвистики, предназначенная для анализа и порождения морфологически сложных языков.
Традиционно фонологические грамматики, формализованные в 60-х годах Хомским и Хале, состояли из упорядоченной последовательности правил подстановки, которые преобразовывали абстрактные фонологические представления в поверхностные формы посредством ряда промежуточных представлений. Такие правила имеют общую форму x → y / z _ w, где x, y, z и w могут быть произвольно сложными строками или матрицами признаков. В математической лингвистике такие правила называют контекстно-зависимыми правилами подстановки.
Важное математическое свойство преобразователей с конечным числом состояний: для любой пары преобразователей, примененных последовательно, существует эквивалентный индивидуальный преобразователь. Любой каскад преобразователей правил в принципе можно «объединить» в один преобразователь, который отображает/преобразует лексические формы непосредственно в соответствующие поверхностные формы и наоборот без всяких промежуточных представлений.

![]()
Подобного рода теоретические озарения не сразу привели к практическим результатам. Разработка компилятора для правил подстановки оказалась очень сложной задачей. Стало ясно, что создание компилятора в качестве первого шага требовало полной реализации основных автоматных (с конечным числом состояний) операций — таких как объединение, пересечение, дополнение и композиция.
Традиционно фонологические правила подстановки описывают соответствие между лексическими формами и поверхностными формами как однонаправленное последовательное преобразование из лексических форм в поверхностные. Даже если было возможно эффективно смоделировать порождение поверхностных форм посредством преобразователей с конечным числом состояний, не было так уж очевидно, что это приведет к эффективной процедуре для анализа в обратном направлении — от поверхностных форм к лексическим.
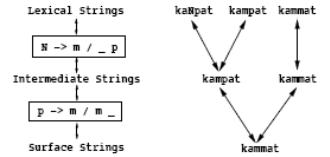
Рассмотрим для пример два последовательно применяемых правила подстановки N → m / _ p и p → m / m _ .
Соответствующие преобразователи однозначно отображают/преобразуют лексическую форму ‘kaNpat’ в ‘kammat’ с ‘kampat’ в качестве промежуточного представления. Однако если применить те же самые преобразователи в обратном направлении ко входу ‘kammat’, мы получим три результата.
![]()
Причина этого в том, что поверхностная форма «kammat» имеет два потенциальных источника на промежуточном уровне. Применение правила p → m / m _ отображает/преобразует «kampat» и «kammat» в одну и ту же поверхностную форму. Промежуточная форма ‘kampat’ в свою очередь может получиться или из «kampat» или из «kaNpat» посредством применения правила N → m / _ p . Эти два преобразователя правил однозначны по нисходящей, но многозначны в восходящем направлении.
Асимметрия — «встроенное» свойство генеративного подхода к фонологическому описанию. Если все правила носят детерминистический и обязательный характер и если порядок правил фиксирован, каждая лексическая форма порождает только одну поверхностную форму. Но поверхностная форма обычно может бить порождена более чем одним способом, и число возможных анализов растем с числом правил.
Koskenniemi (Финляндия) в своей диссертации (1983) предложил Двухуровневую Морфологию (модель с комплексной увязкой параметров (constraint-based model), которая базируется на 3-х основополагающих идеях:
Правила носят характер ограничений «символ-в-символ», применяемых параллельно, а не последовательно — как правила подстановки.
Ограничения могут относиться к лексическому контексту, поверхностному контексту или к обоим контекстам в одно и то же самое время.
Лексический поиск и морфологический анализ выполняются вместе.
Проиллюстрируем первые два принципа на рассмотренном выше примере kaNpat. Ниже представлено двухуровневое описание лексико-поверхностного отношения.
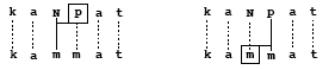
![]()
Линии «указывают» пары: каждый символ в лексической строке ‘kaNpat’ и его реализации в поверхностной строке ‘kammat’.
Ограничение на окружение/контекст для пары N:m — за ней сразу же следует p с лексической стороны. На самом деле ограничение еще жестче. В этом контексте все другие возможные реализации лексического N запрещены. Подобным же образом пара p:m требует предшествующего поверхностного m, и никакая другая реализация p не разрешена здесь. Эти два ограничения не зависят друг от друга. Действуя параллельно, они приводят к тому же самому результату, что и каскад двух правил подставки. В системе обозначений Коскенними эти правила записываются как N : m ↔ _ p : и p : m ↔ :m _ , где ↔ есть оператор, объединяющий контекстное ограничение с запрещением любой другой реализации для лексического символа пары. Двоеточие в правом контексте первого правила p: указывает, что речь идет о лексическом символе; двоеточие в левом контексте второго правила : m указывает поверхностный символ.

Сетевая морфология
Эта модель создавалась для описания морфологии языков, в которых значительная часть информации выражается с помощью окончаний. Ее основная идея в том, что морфологический уровень языка представляет собой иерархически организованную сеть. В качестве примера возьмем формализм DATR, в котором информация также организована в виде сети, состоящей из узлов и переходов. В узле может содержаться информация о словоформе, о лексеме или о целом классе лексем и с ним связана пара path/value (путь/значение). Путь — это последовательность грамматических характеристик (атрибутов), а значение — это конкретные признаки лексемы или словоформы. В качестве примера возьмем описание причастия настоящего времени английского глагола skate:
Путь |
Значение |
syn(tactic) cat(egory) |
verb |
syn type |
main |
syn form |
present participle |
mor(phological) form |
skate ing |
В модели DATR эту информацию можно записать другим способом — с помощью уравнений:
Word1:
<syn cat> = verb
<syn type> = main
<syn form> = present participle
<mor form> = skate ing.
С целью экономного представления информации вводится понятие сети с наследованием. Согласно принципу наследования элементы подкласса наследуют все характеристики класса в целом. Механизм наследования заключается в том, что в систему описания вводят новые узлы и так называемые дескрипторы, содержащие грамматическую и морфологическую информацию, общую для нескольких словоформ, например:
VERB:
<syn cat> == verb
<syn type> == main.
Тогда можно переписать всю информацию для словоформы skating следующим образом:
Word1:
<syn cat> == VERB:<syn cat>
<syn type> == VERB:<syn type>
<syn form> == present participle
<mor form> == skate ing.
Аналогичным образом можно записать информацию о словоформе loved:
Word2:
<syn cat> == VERB:<syn cat>
<syn type> == VERB:<syn type>
<syn form> == passive participle
<mor form> == love ed.
Вопросы:
Назовите основные методы морфологического анализа.
Какие морфологические явления удобно описывать с позиций просодической морфологии?
Как применяются правила в двухуровневой морфологии?
Как представлена информация о морфологических явлениях в сетевой морфологии?
ФОРМАЛЬНЫЕ МОДЕЛИ И СИНТАКСИС
Формальные грамматики
Формальные грамматики — это системы правил, математически строго задающие (или характеризующие) множество цепочек, т.е. конечных последовательностей символов.
Цепочки могут состоять из языковых элементов разных уровней: например, словоформы — это цепочки морфем, а словосочетания и предложения — цепочки слов. Таким образом, можно сказать, что формальные грамматики имеют дело с абстрактными объектами.
Формальные грамматики можно разделить на два класса:
распознающие, которые могут определять правильность цепочек. Если цепочки признаются грамматически правильными, грамматика может дать информацию об их строении.
порождающие, которые могут строить правильные цепочки, давать информацию об их грамматических характеристиках, а также не порождают неграмматичные цепочки.
И в распознающих, и в порождающих грамматиках все утверждения формулируются в четко определенных символах с применением строго определенных правил. Это делает формальные грамматики очень простыми с точки зрения их логического строения.
Порождающей грамматикой называется упорядоченная четверка, состоящая из:
1) основного алфавита;
2) непересекающегося с ним вспомогательного алфавита;
3) одного символа из вспомогательного алфавита, который называется начальным и обозначает множество тех языковых объектов, для описания которых предназначена порождающая грамматика;
4) конечного множества правил.
В порождающей грамматике правила имеют вид x → y. Данное правило применяется так: в цепочке отыскивается левая часть правила, т.е. x, после чего записывается новая цепочка, в которой на месте x стоит y.
Цепочки, задаваемые формальной грамматикой, должны состоять только из терминальных символов. Посредством применения правил все нетерминальные символы должны быть заменены на терминальные. Множество цепочек, задаваемых порождающей грамматикой, называется языком.
Основное требование к порождающей грамматике — достижение адекватности на различных уровнях. Считается, что грамматика, в которой грамматичные объекты также приемлемы с точки зрения носителя языка, достигает так называемой наблюдательной адекватности.
Следующее требование к грамматике — это описательная адекватность, которой она обладает, если моделирует владение языком, т.е. отделяет правильные предложения от неправильных, как это делает носитель естественного языка.
Объяснительной адекватности теория достигает, когда она в состоянии объяснить, каким образом данная грамматика может быть усвоена ребенком в процессе овладения родным языком.
Вершинная грамматика составляющих (Head-Driven Phrase Structure Grammar)
Вершинная грамматика составляющих (далее ВГС) — одна из основных теорий формального синтаксиса, в последние десятилетия конкурирующая с генеративной грамматикой. Ее авторы Карл Поллард и Иван Саг. ВСГ — «потомок» Обобщенной грамматики составляющих (Generalized Phrase Structure Grammar), теории, возникшей в начале 80-х гг. Кроме идей последней в ВГС использованы идеи категориальной грамматики и формальных методов представления структур данных (PATR).
Обобщенную грамматику составляющих от генеративной грамматики отличает отказ от трансформационных правил — все типы предложений, включая и те, которые в генеративной теории рассматриваются как результат трансформаций, в Обобщенной грамматике составляющих порождались в результате действия контекстно-свободных правил фразовой структуры.
ВГС унаследовала идею отказа от трансформаций. Ее авторы пишут, что эта теория (ВГС) имеет под собой психолингвистическую основу, поскольку порождение предложений не является результатом трансформаций, т. е. последовательных преобразований синтаксической структуры высказывания.
ВГС описывается в терминах контекстно-свободных ограничений, что означает, что при построении высказывания происходит постоянное приращение разного рода информации.
Сторонники ВГС исходят из того, что любое предложение структурно упорядочено. Возможность сегментации предложения на более мелкие группы отражает наличие внутренней структуры. В принципе построение структуры может идти «сверху вниз» — т. е. от более крупных фраз к составляющим их словам, либо от слов к фразовым составляющим. Однако такой критерий выделения фраз, как интуиция лингвиста, не является в полной мере удовлетворительным. Критерием, позволяющим или не позволяющим выделять составляющие (части) предложения, является грамматика языка. Грамматика рассматривается как набор грамматических конструкций или правил, и поэтому при определении грамматичности предложения нужно опираться на факт наличия определенных конструкций (правил) в грамматике языка, устанавливающих, какие составляющие могут и должны входить в предложение, чтобы оно было грамматичным.
Авторы ВГС ссылаются на психолингвистические работы, подтверждающих важную роль лексикона для порождения и понимания предложений. Поэтому помимо грамматики в построении предложений задействован лексикон, в котором хранятся дефиниции слов. В каждой фразе есть слова, несущие наиболее важную информацию и определяющие тип фразы. Именно эта идея лежит в основе ВГС — фразовая структура строится вокруг понятия лексической вершины, т. е. слова, информация о котором определяет основные грамматические свойства фразы в целом. В эту информацию включаются данные о частеречной принадлежности (например, существительные являются вершинами именных групп, глаголы — глагольных и т.д.), а также информация о зависимостях (например, в английском языке для всех глаголов необходимо подлежащее, но существуют значительные различия в том, какое дополнение требуется после глагола: прямое, косвенное или придаточное предложение). Считается также, что лексическая вершина несет в себе основную семантическую информацию, которая распространяется на всю фразу.
При описании структуры высказывания приписывание грамматических характеристик очень часто объясняется с помощью метафоры прозрачности. Эта метафора хорошо показывает разницу между внешней и внутренней структурой высказывания. Предположим, что перед нами стоит задача упаковать некоторые предметы А и В вместе, и новую упаковку назвать Х. Следующее задание — упаковать Х и Y вместе, и назвать новую упаковку Z. Чтобы выполнить второе задание, мы просто возьмем Х и упакуем его вместе с Y, не заглядывая внутрь и не зная, что внутри Х. Так же можно рассматривать и предложение: можно анализировать информацию, которая относится к фразе в целом, без анализа свойств каждого отдельного элемента этой фразы. Таким образом, компоненты фразы — это одно, а свойства фразы — это другое.
Помимо метафоры прозрачности в ВГС широко используется метафора родства. Например, считается, что элементы, которые составляют одну фразу (слова или словосочетания), находятся в сестринских отношениях между собой.
В ВГС используется два основных типа записи: древовидная структура и скобочная запись. Древовидные структуры проигрывают скобочным по компактности и наглядности описания. Скобочная запись удобна, поскольку наглядно показывает не только внешнюю, но и внутреннюю структуру фразы, а также включает весь массив необходимой информации о составляющих фразу элементах, т.е. о словах. Скобочная запись имеет форму признаковой матрицы. Эти матрицы удобны для отражения взаимодействия синтаксиса и семантики высказывания. В общем виде такая матрица имеет вид:

 l1 v1
l1 v1
l2 v2 ,
г де l1…ln — имена признаков, v1…vn — соответствующие им значения, например:
NUM SG
PERS THIRD
Э та матрица содержит информацию о том, что единица высказывания обладает признаками числа (NUM) и лица (PERS), которые соответственно принимают значение «единственное» (SG) и «третье» (THIRD).
Значения признаков сами могут быть признаковыми структурами, и тогда матрица будет иметь более сложный вид.
Лексикон организован в виде иерархической сети с наследованием, что позволяет создавать достаточно компактные перекрестные ссылки на информацию о словах при ее значительном объеме.
В ВГС информация о лингвистических элементах передается посредством структур признаков (feature structures). Признаки имеют иерархическую организацию и хранятся в лексиконе.
Самый простой тип структуры признаков — это всего две части: атрибут и его значение, т.е. снова признаковые матрицы. Например, атрибут лексемы — время, а его значение — настоящее. Эти данные можно записать так:
[tense present].
У каждого атрибута есть список возможных значений. Так, у атрибута tense список значений может включать past, present, future. Предлагаемый в ВГС способ представления лингвистической информации позволяет одновременно описывать сложные комплексы атрибутов и значений, например:
 number singular
number singular
gender feminine
П онятие структура признаков рекурсивно в том смысле, что не только пара атрибут-значение может составлять структуру признаков, но также, в определенном контексте, и значение, и набор других структур признаков. Например:
 inflection number singular
inflection number singular
gender feminine
Данная запись отражает информацию о том, что у атрибута inflection в качестве значения выступают number singular, gender feminine.
К наиболее высокому уровню в иерархии структур признаков относятся следующие классы:
role features (фразовые роли);
synsem features, содержащие синтаксическую и семантическую информацию;
val features, отражающие информацию о валентности;
phon features, в которых содержится фонетическая информация.
Фразовые роли — это признаки, приписываемые дочерним узлам, составляющим фразу. Они показывают, как элементы фразы соотносятся с фразой в целом. Атрибут называется ролью (role), и в каждой фразе у одного из элементов значение атрибута будет вершиной (head). Вершиной считается тот узел, который в наибольшей степени определяет свойства фразовой группы в целом. Помимо значения head атрибут role может принимать следующие значения: complement, modifier, specifier, filler.
Фразы получают свое название в зависимости от ролей, выполняемых составными элементами. Например, фраза
[[realize] [how beautiful she is]]
получит характеристику head-complement phrase, поскольку [realize] имеет значение head, а [how heavy they are] — complement.
Синтактико-семантические роли — это класс структур семантических признаков, в котором выделяются два типа: внутренние признаки и признаки отношений. Внутренние признаки — это информация о том, что собой представляет элемент фразы. Признаки отношений показывают, что эти элементы делают в данном контексте. Далее они подразделяются на грамматические функции и тета-роли. Среди грамматических функций выделяются субъект (subject), объект (object) и косвенные роли (oblique). При этом субъект — аналог подлежащего, объект — прямое дополнение, которое может выступать в роли подлежащего в пассивной конструкции, а косвенные роли — все остальное.
Тета-роли — это семантические роли референтов предложения. Тета-ролями являются: агенс и пациенс, источник и цель действия, экспериенцер, т.е. лицо, находящееся в определенном состоянии, содержание и стимул. Последние три служат для описания психологических ситуаций и эмоциональных состояний.
Роли подразделяются на семантические и синтаксические, поскольку они не всегда однозначно соотносятся.
Внутренние признаки далее делятся на две группы, которые обозначаются syn и sem. Синтаксические признаки подразделяются на вершинные признаки и признаки уровня. Под вершинными признаками понимают такие свойства элемента фразы, которые «проектируются» на материнский узел, т.е. на фразу в целом. Признаки уровня определяют различные уровни структуры высказывания.
Среди вершинных признаков нужно выделить подкласс категориальных признаков, которые не только характеризуют частеречную принадлежность вершины фразы, но и определяют тип фразы при данной вершине.
Признаки уровня делятся на две подгруппы: лексикализованность и максимальность. Лексикализованность указывает, является ли данная единица отдельным словом, а максимальность определяет, является данный элемент аргументом при предикате или основным составляющим элементом фразы.
Валентностные роли описывают способность лексических единиц вступать в связи друг с другом в высказывании, а фонетические роли описывают звуковой облик единиц лексикона.
Лексико-функциональная грамматика
Изучение типологически разных языков показывает, что между морфологическими и синтаксическими средствами языка существует определенное соотношение: чем более развита морфология, тем свободнее используемый порядок слов при построении высказываний на этом языке. И наоборот, чем беднее морфологические средства, тем строже соблюдается жесткий порядок слов. Морфологические и синтаксически средства являются альтернативными способами выражения грамматических значений — т.е. в разных языках одно и то же значение может быть выражено либо морфологическим средствами, либо синтаксическими. Как пишет Джоан Бреснан: «Morphology competes with syntax». Именно эта идея легла в основу теории, получившей название «Лексико-функциональная грамматика» (далее ЛФГ). Оформление ЛФГ в отдельную теорию относят к 1982 году, когда появилась статья двух американских синтаксистов Каплана и Бреснан «Lexical-Functional Grammar: a Formal System for Grammatical Representation».
В ЛФГ высказывание описывается с помощью двух структур: структуры составляющих (c-structure) и функциональной структуры (f-structure), показывающей, в каких отношениях друг к другу находятся элементы высказывания. Другими словами, f-структура слова или некоторой цепочки слов (в том числе целого предложения) содержит значения основных грамматически релевантных признаков данного слова или цепочки. В ЛФГ грамматические отношения получили название грамматических функций.
Поскольку в ЛФГ для описания структуры высказывания используются два вида структур, можно наглядно показать, какие структурные различия существуют между конкретными языками, а также какие структурные характеристики являются общими.
Структура составляющих в ЛФГ в принципе не отличается от структуры составляющих генеративной грамматики. Она представляет собой дерево, порождаемое контекстно-свободными правилами типа S → NP + VP; VP → V + NP. Однако роль структуры составляющих (далее с-структура) в ЛФГ значительно скромнее, чем в генеративной грамматике.
При сопоставлении структурных схем одного и того же высказывания в разных языках выясняется, что структуры составляющих (с-структуры) различны, а вот f-структура высказывания будет единой. Это связано с тем, что с помощью f-структуры передаются одинаковые отношения между участниками ситуации: например, отношения между субъектом и объектом действия, характер самого действия и т.д. Рассмотрим используемый Робертом Ван Валином пример и посмотрим, как выглядит с-структура предложения Juan sees a dog в четырех типологически разных языках.



 S
(немецкий) S
(корейский)
S
(немецкий) S
(корейский)
NP VP NP NP V



V NP


D N
Juan seiht einen Hund Juan-i kay-lul po-n-ta
NOM see – 3sgPRES a-ACC dog Juan-NOM dog-ACC see-PRES-IND
S (Запотек, Мексика) S (Тоба Батак, Инденезия)




V NP NP VP NP


Žle?ele žwa beko? V NP
PRES-see Juan dog Mangida biang si Juan
ACTIVE-see dog PN Juan
(PN – показатель имени собственного)
В ЛФГ с помощью матрицы признаков f-структура этого высказывания (общая для всех языков, поскольку речь идет об одних и тех же отношениях) записывается так:

SUBJ PRED “Juan”
OBJ PRED “dog”
DEF -
NUM SG
TENSE PRES
PRED “see”
<(↑SUBJ)(↑SUBJ)>”
Различие в f-структуре для разных языков будет единственно в фонетическом облике конкретных слов в высказывании. В признаковой матрице вершины синтаксических групп имеют метку PRED, а все грамматические отношения есть признаки, в каждой конкретной f-структуре получающие свое значение.
Для ответа на вопрос о соотношении между f-структурой и с-структурой в ЛФГ были созданы с-структуры с функциональными аннотациями.
S


NP VP


 (↑SUBJ)=↓ ↑ = ↓
(↑SUBJ)=↓ ↑ = ↓
VP NP
↑ = ↓ (↑OBJ)=↓

Juan seiht ein-en Hund
(↑PRED)=’Juan’ (↑PRED)= ‘see (↑PRED) = ‘dog
(↑NUM) = SG <(↑SUBJ) (↑OBJ)>’ (↑DEF) = -
(↑GEND) = MASC (↑TENSE) = PRES (↑NUM) = SG
(↑CASE) = NOM (↑ SUBJ NUM) = SG (↑GEND) = MASC
(↑ SUBJ PERS) = 3 (↑CASE) = ACC
При таком способе записи вся релевантная грамматическая информация представлена эксплицитно (в явном виде). Стрелки отсылают либо к материнскому узлу (↑), либо к вершине синтаксической группы (↓). Запись (↑SUBJ) =↓ означает, что слово Juan является в высказывании подлежащим, запись (↑OBJ) =↓ указывает, что einen Hund есть дополнение в составе материнского узла глагольной группы.
Грамматические функции можно приписывать также на этапе записи правил, по которым строятся с-структуры для конкретного языка, например:
1. S → NP + VP
(↑SUBJ) =↓ ↑ = ↓
2. VP → V + NP
↑ = ↓ (↑OBJ) =↓
В первом правиле f-описание указывает, что NP является подлежащим, а во втором правиле f-описание характеризует именную группу как дополнение.
Такое аннотирование с-структур позволяет выводить из них полные f-структуры.
В ЛФГ формулируется критерий грамматичности предложения. Предложение грамматично в том и только в том случае, если его f-структура является:
полной (содержит f-структуры для всех зависимых в модели управления предиката (Completeness Condition));
связной (содержит f-структуры только для тех зависимых, которые заполняют определенную валентность глагола (Coherence Condition)).
Эти два требования есть ограничения на f-структуру в лексико-функциональной грамматике, позволяющие избегать порождения неграмматичных с-структур.
В отличие от генеративной грамматики ЛФГ не допускает изменения грамматических отношений в результате трансформаций. Например, в ЛФГ нет трансформации пассива — теория предусматривает порождение пассивных предложений «напрямую» в пассивном залоге.
Все грамматические функции в ЛФГ делятся на те, которые могут подвергаться дальнейшей подкатегоризации, и те, которые не могут далее распределяться по подкатегориям.
В первой группе грамматических функций можно выделить семантически неограниченные и ограниченные отношения. К первым относятся функции субъекта, прямого и косвенного дополнения. Ко вторым — функции обладателя, а также формы косвенных падежей. К функциям, которые не поддаются дальнейшей подкатегоризации, относятся функции адъюнкта, фокуса и топика высказывания.
Лексикон играет особую роль в ЛФГ. Запись в лексиконе содержит информацию об аргументной структуре, а также грамматических функциях лексемы. Соотнесение аргументной структуры с конкретной грамматической информацией называется лексической формой.
С помощью лексической формы в ЛФГ проводится различие между глаголами в активном и пассивном залоге. Изменения в лексической форме записываются в виде правил, например:
SUBJ → 0/OBJ (OBJ = косвенный падеж)
OBJ → SUBJ.
Субъект действия или опускается, или заменяется словоформой в косвенном падеже, а объект становится подлежащим. Применим эти правила для записи конкретного глагола:
‘break < (↑SUBJ) (↑OBJ)>’ → ‘broken <(↑OBJ)/0 (↑SUBJ)>’
AGENT PATIENT AGENT PATIENT
Лексические правила в ЛФГ играют роль синтаксических трансформаций в трансформационной грамматике.
ЛФГ является достаточно сильным научным направлением, взаимодействующим как с психологией, так и с компьютерной лингвистикой. С ее помощью описаны разнообразные языковые явления на материале многих языков, в том числе и на материале русского языка.
Вопросы:
Что такое формальная грамматика?
Назовите уровни адекватности формальной грамматики.
Какая грамматика называется порождающей?
Почему ВГС удобна для описания взаимодействия синтаксиса и семантики высказывания?
Какой способ записи структуры предложения используется в ВГС?
Как описывается структура предложения в лексико-функциональной грамматике?
СПИСОК ЛИТЕРАТУРЫ
Баранов А.Н. Введение в прикладную лингвистику / А.Н. Баранов — М.: Эдиториал УРСС, 2001. – 358 с.
Городецкий Б.Ю. Компьютерная лингвистика: моделирование языкового общения / Б.Ю. Городецкий // Новое в зарубежной лингвистике. — М.: «Наука», 1989. — Вып. XXIV : Компьютерная лингвистика. — С. 5-34.
Новое в зарубежной лингвистике. Прикладная лингвистика. — М., 1983. Вып. XII. — 461 с.
Потапова Р.К. Новые информационные технологии и лингвистика : учеб. пособие для студентов вузов / Р.К. Потапова — М. : Эдиториал УРСС, 2005. — 364 с.
Прикладное языкознание: учебник / авт.: С.А. Аверина, И.В. Азарова, Е.Л. Алексеева и др. : Отв. ред. А.С. Герд. — СПб. : Изд-во С-Петербург. ун-та, 1996. — 525 с.
Тестелец Я.Г. Введение в общий синтаксис / Я.Г Тестелец — М.: Изд-во Рос. гос. гуманит. ун-та, 2001. — 796 с.
Фундаментальные направления современной американской лингвистики: Сб. обзоров / Под ред. А.А. Кибрика, И.М. Кобозевой, И.А. Секериной — М.: Изд. Моск. ун-та, 1997. — 454 с.
Хомский Н. Аспекты теории синтаксиса / - Н. Хомский — М. : «Наука», 1972. — 234 с.
1 «Конфликт» ограничений по мнению авторов может быть решен посредством их строгого упорядочения.