

Похибки першого й другого роду
Результати статистичного доведення можна навести у вигляді таблиці:
-
H0
Правильна
Хибна
Приймають
+
Помилка другого роду,

Відкидають
Помилка першого роду,
+
Як звичайно, нульову гіпотезу формулюють так, щоб негативний вплив (шкода) помилки першого роду був меншим, ніж вплив помилки другого роду. З імовірністю ми можемо помилково віднести дані, що відповідають гіпотезі H0, до H1. Мірою якості критерію, або потужністю критерію, є число 1- (рис.6.1).

Рис. 6.1. Розподіли
![]() і
і
![]() значень функції-статистики, якщо
правильна нульова гіпотеза чи проста
альтернативна гіпотеза, відповідно.
Тут:
значень функції-статистики, якщо
правильна нульова гіпотеза чи проста
альтернативна гіпотеза, відповідно.
Тут:
![]() – критичне значення статистики, що
відділяє область прийняття нульової
гіпотези
– критичне значення статистики, що
відділяє область прийняття нульової
гіпотези
![]() (з рівнем значущості
)
від критичної області
(з рівнем значущості
)
від критичної області
![]() (нульову гіпотезу відкидаємо);
(нульову гіпотезу відкидаємо);
![]() – ймовірність помилки другого роду.
– ймовірність помилки другого роду.
Параметричні й непараметричні критерії
Статистичні критерії поділяють на параметричні і непараметричні. Для застосування параметричних критеріїв необхідно перевірити виконання додаткових умов, наприклад, підпорядкування вибірки певному закону розподілу. Непараметричні ж критерії не потребують додаткових перевірок, але мають меншу потужність.
Критерій погодженості хі-квадрат
Цей критерій використовують для перевірки частотного розподілу деякого параметра двох об’єктів або вибірки і заданого розподілу (планового теоретичного, еталонного об’єкта).
Нехай задано вибірку, яку можна розбити на k класів (груп). Класи вибирають так, щоб у кожному з них було достатньо значень (не менше шести-восьми), інакше класи об’єднують. Завдання полягає в перевірці гіпотези, що кількість появи значень у кожному з класів (інтервалів) узгоджується із заданим. Схема статистичного доведення така.
1. Формулювання гіпотези
H0:
![]() для всіх
для всіх
![]() ;
;
H1:
![]() хоча б для одного
,
хоча б для одного
,
де
![]() – фактична кількість – частота –
(експериментальних) даних в i-му
класі;
– фактична кількість – частота –
(експериментальних) даних в i-му
класі;
![]() – очікувана (планова, теоретична)
кількість даних в i-му
класі;
– кількість класів (груп);
– очікувана (планова, теоретична)
кількість даних в i-му
класі;
– кількість класів (груп);
![]() – частотне відношення;
– частотне відношення;
![]() – теоретична ймовірність.
– теоретична ймовірність.
2. Вибір рівня значущості .
3. Обчислюємо статистику Пірсона
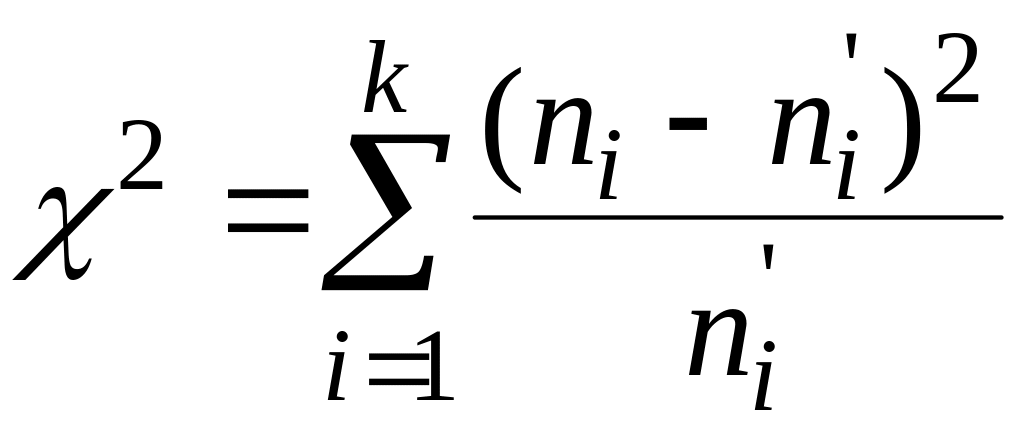 або
або
 . (6.1)
. (6.1)
4. Статистика
має однойменний розподіл
(Пірсона), з
![]() ступенями вільності (
ступенями вільності (![]() – “degree of
freedom” (англ.) – ступені
вільності). Якщо теоретичний закон
розподілу має параметри, які оцінюють
на підставі вибірки (наприклад, середнє
та дисперсія для нормального закону
розподілу), то
додатково потрібно зменшити на кількість
оцінюваних параметрів (тому для
нормального розподілу матимемо
– “degree of
freedom” (англ.) – ступені
вільності). Якщо теоретичний закон
розподілу має параметри, які оцінюють
на підставі вибірки (наприклад, середнє
та дисперсія для нормального закону
розподілу), то
додатково потрібно зменшити на кількість
оцінюваних параметрів (тому для
нормального розподілу матимемо
![]() ).
).
5. Знаходимо критичні значення статистики
![]() .
.
6. Перевіряємо критерій: якщо
![]() ,
то порівнювані розподіли статистично
не відрізняються.
,
то порівнювані розподіли статистично
не відрізняються.
Приклад. Перевірити узгодженість експериментальних даних нормальному закону розподілу.
Статистичний матеріал розбиваємо на класи (з використанням формули Стеджерса або з інших міркувань, наприклад, з урахуванням правила “трьох сигм”). Для ефективності критерію домагаємося, щоб кількість класів була не менше шести–семи, а кількість даних у кожному класі – не менше п’яти. Інакше потрібно збільшити сусідні класи. Отже, можна вважати, що критерій ефективно застосовувати, якщо обсяг вибірки досягає 50–60 значень.
Далі знаходимо точкові оцінки математичного
сподівання та дисперсії (або стандартного
відхилення):
![]() .
Ступені вільності:
.
Для обчислення теоретичної кількості
значень в i-му
класі скористаємося властивостями
частотного відношення та інтегральної
функції розподілу
.
Ступені вільності:
.
Для обчислення теоретичної кількості
значень в i-му
класі скористаємося властивостями
частотного відношення та інтегральної
функції розподілу
![]() :
:
![]() , (6.2)
, (6.2)
де
![]() – межі (інтервал) k-го
класу. Обчисливши статистику (6.1) і
знайшовши для неї верхнє критичне
значення
– межі (інтервал) k-го
класу. Обчисливши статистику (6.1) і
знайшовши для неї верхнє критичне
значення
![]() ,
робимо висновок щодо нульової гіпотези
,
робимо висновок щодо нульової гіпотези
![]() .
Очевидно, що для добре узгоджених
теоретичного й експериментального
розподілу значення повинне бути малим,
тому розглядаємо тільки праву альтернативу
.
Очевидно, що для добре узгоджених
теоретичного й експериментального
розподілу значення повинне бути малим,
тому розглядаємо тільки праву альтернативу
![]() .
.