

International Organization for Standardization - iso (исо) - Международная организация по стандартизации
МЭК (International Electrotechnical Commission - IEC) - Международная электротехническая комиссия
МСЭ (International Telecommunication Union – ITU) - Международный союз электросвязи
European Computer Manufacturers Association – ЕСМА - Европейская ассоциация производителей вычислительных машин
ITSTC - Европейский институт стандартов по электросвязи
ETSI - Европейский институт телекоммуникационных стандартов
Institute of Electrical and Electronics Engineers – ieee- Институт инженеров по электротехнике и электронике
Тема 5. Реализация информационных технологий в составе информационных систем. Понятие и функции информационной системы. Классификация информационных систем. Геоинформационные системы, их назначение, возможности, функции. Банковские информационные системы и технологии.
Информационная система (ИС) - автоматизированная система (АС), предназначенная для организации, хранения, пополнения, поддержки и представления пользователям информации в соответствии с их запросами.
Функциональная схема ИС 1 – система организации, хранения и представления информации; 2 – система ввода, обновления и корректировки информации; 3 – система потребления информации.
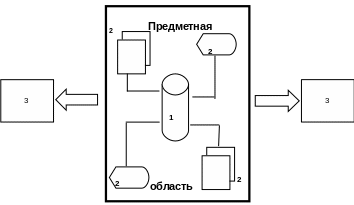
Область определения любой информационной системы (предметная область) представляет собой информационное пространство, содержащее совокупность информационных объектов. Каждый из объектов может быть описан с точки зрения систем организации и хранения, ввода, обработки и поиска информации , систем потребления информации и взаимосвязей данного объекта с другими объектами рассматриваемой предметной области.
В общем случае информационное пространство неоднородно, так как содержит информационные объекты, различающиеся по методам формирования, организации и пополнения информации.
Все преобразования информации, осуществляемые системой 1, можно свести к пяти основным процедурам:
хранение, поиск, обработка, ввод, вывод.
Первые три процедуры являются внутренними, а четвертая и пятая обеспечивают связь данной системы с объектами предметной области, т. е. источниками информации и внешней средой (потребителями информации).
Таким образом, любая ИС и обрабатываемая ею информация образуют сложную неоднородную систему.
Эффективность управления любой динамической системой (технологическим процессом, производством, процессом создания нового изделия и т. д.) во многом определяется тем, как организованы хранение, поиск, обработка и пополнение информации. Очевидно, что управление возможно только в той системе, в которой четко определены информационные связи как между отдельными элементами, так и с внешней средой. В этом случае обеспечиваются возможность координации деятельности различных подсистем, сопряжения данной системы управления с системами более высокого и более низкого уровней.
Информация, выдаваемая ИС потребителю, является одним из ресурсов, позволяющих повысить производительность труда и эффективность его деятельности. Важнейшим аспектом взаимоотношений потребителя и ИС является наиболее полное и удовлетворение информационной потребности пользователя, обеспечение эффективного использования информационных ресурсов.
Главная задача ИС - доведение информации до потребителя в требуемом объеме, в заданные сроки и удобной для восприятия форме.
Именно использование информационных ресурсов позволяет минимизировать расход всех других видов ресурсов (материальных, трудовых, финансовых, вычислительных) при информационном обеспечении потребителей.
Т.о., информационные ресурсы представляют собой один из обязательных элементов, необходимых для осуществления любого вида человеческой деятельности:
производства, управления, научных исследований, проектирования новой техники и технологии, подготовки и переподготовки кадров.
Одиночные, групповые, корпоративные, информационные системы
Одиночные информационные системы реализуются на автономном компьютере. Такая система может содержать несколько простых приложений, связанных общим информационным фондом, и рассчитана на работу одного пользователя или группы пользователей, разделяющих по времени одно рабочее место.
Групповые информационные системы ориентированы на коллективное использование информации членами рабочей группы (одного подразделения), чаще всего строятся на основе локальной вычислительной сети.
Однотипные или специализированные рабочие места обеспечивают вызов одного или нескольких конкретных приложений.
Общий информационный фонд представляет собой базу данных или совокупность файлов документов.
Корпоративные информационные системы
являются развитием систем для рабочих групп и ориентированы на масштаб предприятия, могут поддерживать территориально разнесенные узлы или сети.
Главная особенность – обеспечение доступа из подразделения к центральной или распределенной базе данных предприятия (организации) помимо доступа к информационному фонду рабочей группы.
В зависимости от особенностей использования информационные системы делят на две основные группы:
системы информационного обеспечения и системы, имеющие самостоятельное целевое назначение и область применения.
Системы (или подсистемы) информационного обеспечения входят в состав любой автоматизированной управляющей системы и являются важнейшими компонентами.
К числу ИС, имеющих самостоятельное значение, относятся
информационно-поисковые (ИПС), информационно-справочные системы (ИСС) и информационно-управляющие системы (ИУС).
Информационно-поисковые и информационно-справочные системы
Предназначены для хранения и представления пользователю информации (данных, фактографических записей, текстов, документов и т.п.) в соответствии с некоторыми формально задаваемыми характеристиками.
Для ИПС и ИСС характерны два основных этапа функционирования:
сбор и хранение информации; поиск и выдача информации пользователю.
Движение информации в таких системах осуществляется по замкнутому контуру от источника к потребителю информации. При этом ИПС или ИСС выступают лишь как средство ускорения поиска необходимых данных.
Наиболее сложным процессом выступает поиск необходимой информации, который осуществляется в соответствии со специально создаваемым поисковым образом документа (ПОД).
В зависимости от режима организации поиска ИПС и ИСС могут быть разделены на
документальные, библиографические, библиотечные, фактографические.
Документальные ИПС
ИПС – системы, в которых реализуется поиск в информационном фонде документов или текстов в соответствии с полученным запросом с последующим предоставлением пользователю этих документов или их копий. Вся обработка полученной информации в документальных ИПС осуществляется самим пользователем.
В зависимости от того, по каким хранимым документам или по их описаниям (вторичным документам) осуществляется поиск, документальные ИПС часто делят на системы
с библиотечным и c библиографическим поиском.
В первом случае поиск ведется в информационном фонде, содержащем первичные документы, во втором – в информационном фонде вторичных документов.
Фактографические ИПС
Реализуют поиск и выдачу фактов, текстов, документов, содержащих сведения, которые могут удовлетворить поступивший запрос пользователя. В этом случае осуществляются поиск не какого-то конкретного документа, а всей совокупности сведений по данному запросу, хранящихся в информационном фонде ИПС или ИСС.
Основным отличием фактографических информационно-поисковых систем от документальных является то, что эти системы предоставляют пользователю не только ранее введенный документ, но и обработанную информацию.
Информационно-поисковые и информационно-справочные системы
Еще одним признаком классификации ИПС и ИСС может выступать реализуемый
режим распространения информации.
По этому признаку различают:
системы с режимом избирательного распространения информации (ИРИ), обеспечивающие организацию периодического (раз в неделю, раз в месяц, раз в квартал и т. п.) поиска информации в соответствии с заданным постоянным запросом в массиве новых поступлений в информационный фонд ИПС и предоставление пользователю сообщений о появлении таких документов;
системы с режимом ретроспективного поиска (РП), реализующие поиск информации по заданным разовым запросам во всем информационном фонде ИПС или ИСС;
интегральные системы, в которых реализованы как ИРИ-, так и РП-режим.
Информационно-управляющие системы (ИУС)
Входят в состав автоматизированных систем управления и предназначены для подготовки и выдачи информации, необходимой для оказания управляющего воздействия на объект управления.
ИС, основанные на использовании гипермедиа-структур
Существует обширный класс ИС, основанных на использовании гипермедиа-структур, представляющих собой совокупность логически связанных текстовых, графических, аудио- и видеоматериалов.
В настоящее время эти системы нашли широкое применение в Internet (Intranet) при организации доступа данным на WWW-серверах
Географические информационные системы (ГИС)
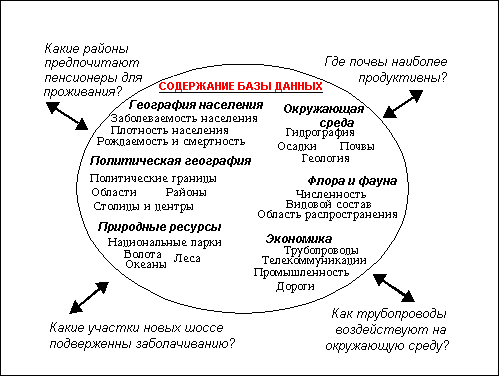
ГИС – автоматизированная ИС, предназначенная для обработки пространственно-временных данных, основой интеграции которых служит географическая информация.
ГИС является расширением концепции баз данных, дополняя их наглядностью представления и возможностью решения задач пространственного анализа.
Первые работы по ГИС - в Канаде и использовались в основном для целей землеустройства. Сейчас это один из наиболее бурно растущих сегментов рынка высоких компьютерных технологий, на котором работает большое количество крупных фирм, среди которых Intergraph, ESRI, Autodesk, CalComp и др.
В настоящее время области применения ГИС: землеустройство, контроль ресурсов, экология, муниципальное управление, транспорт, экономика, социальные задачи и др.
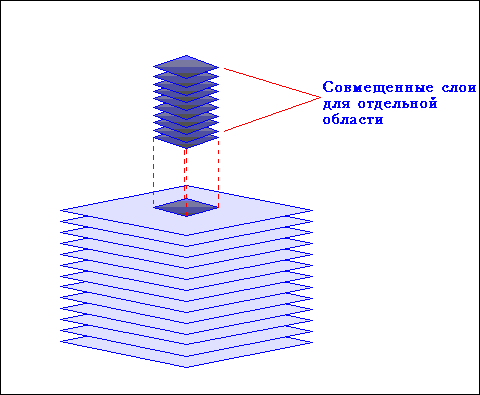
В ГИС информация привязана к карте или плану местности. Для одной географической области могут быть представлены несколько картографических слоев с разными объектами и соответственно разной информацией по этим объектам, например городские коммуникации, транспортные связи, лесные массивы, водоемы и т.п. Слои могут накладываться, образуя карту, ориентированную на решение конкретных задач.
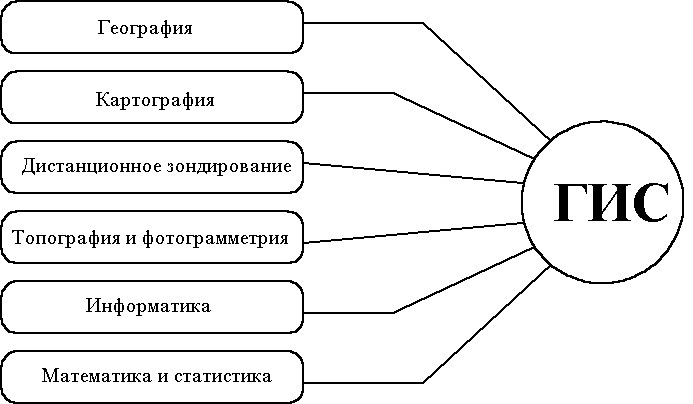
Связь ГИС с научными дисциплинами и технологиями
Типовые вопросы, на которые способна ответить ГИС
Где находится А?
Как расположено А по отношению к Б?
Сколько А расположено в пределах расстояния Б-С?
Каково значение функции Z в точке X?
Как велико по размерам Б?
Каков результат пересечения А и Б?
Каков оптимальный маршрут от Х до У?
Что находится в Х1, Х2,…,ХN?
Какие объекты следуют за теми, у которых наблюдается определенное сочетание определенных свойств?
Как изменится пространственное распределение объектов, если изменить их существующую классификацию?
Что может случиться с А, если изменится Б и его месторасположение относительно А?
Концептуальная схема организации данных в ГИС
ГИС – как интегрирующая технология

Сферы применения ГИС
По оперативности обработки данных
различают пакетные и оперативные ИС. ИС с пакетной обработкой можно встретить на больших ЭВМ. В современных ИС в основном преобладает режим оперативной обработки транзакций OLTP (OnLine Transaction Processing) для отражения актуального состояния предметной области в любой момент времени, а пакетная обработка занимает ограниченную нишу. (Транзакция представляет собой неделимый набор операций с БД, она завершается успешно, когда выполнены все ее операции, в противном случае происходит откат в состояние, предшествующее выполнению транзакции.) Для OLTP характерен регулярный поток простых транзакций, играющих роль заказов, платежей, запросов и т.п.
Основными требованиями являются производительность обработки транзакций и гарантированная доставка информации при удаленном доступе по телекоммуникациям.
Системы поддержки принятия решения (Decision Support System)
- особый тип ИС, в которых с помощью довольно сложных запросов производится выбор и анализ данных в различных разрезах (временных, географических) и по различным показателям. При этом развитые системы DSS включают средства:
извлечения данных из разнородных источников, включая неструктурированную информацию;
многомерного анализа данных;
обработки статистики;
моделирования правил и стратегии деловой деятельности;
деловой графики для представления результатов анализа;
анализа "что если";
искусственного интеллекта.
Средства искусственного интеллекта составляют экспертную подсистему, основанную на правилах из базы знаний и соответствующих механизмов вывода. В общем случае требование оперативности не является обязательным для таких систем с учетом сложности транзакций и аналитической обработки.
В классе DSS выделяется класс систем оперативной аналитической обработки OLAP (OnLine Analysis Processing). Здесь оперативность обработки достигается за счет применения мощной многопроцессорной вычислительной техники, специальных OLAP-серверов, современных методов многомерного анализа и специальных хранилищ данных Data Warehouse, накапливающих информацию (из разных источников за большой период времени) и обеспечивающих к ним оперативный доступ.
Офисные информационные системы
Значительная доля информации, циркулирующая в учреждениях, представляет собой неструктурированные данные из бумажных документов. Современные системы управления электронными документами EDMS нацелены на перевод бумажных документов в электронный вид и обеспечиваются средствами индексирования и поиска, некоторые из них обладают свойствами гипертекста.
Развитые офисные системы включают средства коллективной работы GroupWare, обеспечивающие автоматизацию делопроизводства с использованием электронной почты, средства заполнения бланков, электронных таблиц и текстовых редакторов.
Для автоматизации документооборота и контроля исполнительской дисциплины применяются методы и средства Workflow. В систему закладываются графы взаимоотношений работников учреждения, задания, привязка к документам и БД, маршруты движения документов.
Принципы создания информационных систем
1. Обеспечение общения конечного пользователя с ИС на профессионально-ограниченном естественном языке, представление входной и результирующей информации в привычной и удобной пользователю форме.
2. Обеспечение возможности решения задач управления, проектирования, др. по их постановкам и исходным данным независимо от сложности и наличия формальных математических моделей этих задач.
3. Обеспечение конечному пользователю таких условий работы, при которых он осуществляет процессы управления, планирования, пр. в режиме диалога с ЭВМ, оперируя понятиями своей предметной области, используя профессиональный опыт и навыки и принимая решения одновременно по множеству критериев, часть из которых не описана формально и не имеет количественного выражения.
Системы, построенные на основе данных принципов, можно разделить на три класса:
интеллектуальные диалоговые (вопросно-ответные);
расчетно-логические или системы поддержки принятия решений (для решений различных задач проектирования, организационного управления);
экспертные системы.
Проектирование любой ИС предполагает выделение в ее структуре двух составляющих:
внесистемное программно-информационное обеспечение (ПИО), организуемое вне вычислительной среды ИС;
внутрисистемное программно-информационное обеспечение (ПИО), представляющее собой систему организации и обработки информации в той вычислительной среде, в которой реализуется данная ИС.
Организация внесистемного предполагает формализованное описание всей используемой для обеспечения деятельности ИС информации, т. е. создание единой системы классификации и кодирования информации, разработку унифицированных форм документации, системы заполнения, хранения, представления и внесения изменений.
Внутрисистемное ПИО - совокупность данных, программных средств их описания, организация, хранение, накопление и доступ к информации в вычислительных системах, задействованных в данной ИС. От того, как спроектировано внутрисистемное ПИО, зависит эффективность функционирования ИС.
В структуре ИС особое место занимают базовые программно-информационные составляющие, являющиеся инвариантными по отношению к классам решаемых информационных задач, к числу которых относятся системы управления базами данных (СУБД), системы машинной графики (МГ), ИПС и т.п. Обычно при создании ИС можно (по крайней мере, в принципе) использовать базовые компоненты других систем, что в значительной мере снижает трудоемкость новой разработки.
Банковские Информационные технологии
С развитием телекоммуникационных сетей в банковском деле появились принципиально новые услуги по взаимодействию клиента и банка, которое может осуществляться на компьютерной основе. Связавшись с компьютером банка по телефонной сети через свой персональный компьютер, клиент после прохождения авторизации может проверить состояние своего счета и совершить с ним ряд операций. Подобные действия клиент может предпринимать и не имея компьютера, используя возможности средств телекоммуникаций и пластиковых карточек, которые несут в себе сведения о владельце и его финансовых возможностях.
Пластиковая карта
Это - персонифицированный платежный инструмент, предоставляющий возможность безналичной оплаты товаров и/или услуг, а также получения наличных средств в отделениях (филиалах) банков и банковских автоматах (банкоматах). Пластиковая карточка представляет собой пластину стандартных размеров (85.6 мм 53.9 мм 0.76 мм), изготовленную из устойчивой к механическим и термическим воздействиям пластмассы.
Пластиковая карточка представляет собой машинный носитель информации, который может быть классифицирован по способу ее записи и хранения.
Пластиковая карта – персонифицированный платежный инструмент, используемый для автоматизации безналичных расчетов, а также обналичивания имеющихся на карт-счете финансовых средств.
Магнитная карта – пластиковая карта, содержащая реквизиты связанного с ней карт-счета в электронной форме на магнитной полосе.
Смарт-карта – микропроцессорная пластиковая карта.
Данные о средствах – на карте! Пластиковая карта, внутри которой находится микропроцессор, способный производить вычисления. Внутри смарт-карты могут храниться электронные деньги, которые можно потратить в магазине и получить в специальном банкомате (деньги с обычного счета переводятся в электронную форму и помещаются внутрь смарт-карты). Смарт-карта может также содержать параметры пользователя (пароль, номер карты), что делает ее функционально похожей на ключ к банковскому счету. Может использоваться для идентификации, в качестве пропуска.
Электронный бумажник (Electronic Wallet (e-Wallet)) - устройство для работы со смарт-картами. Электронный бумажник может блокировать карту, прочитать ее баланс, показывает несколько последних операций и т.п.
Дебетовая карта – пластиковая карта, при открытии которой держатель должен внести некоторую сумму на счет в банке-эмитенте.
Банк-эмитент - банк, выпустивший в обращение пластиковые карты и проводящий расчеты (через банки-эквайеры) с пунктами обслуживания пластиковых карт.
Кредитная карта (Credit card (CC))- пластиковая карта, которая позволяет взять у банка краткосрочный кредит в пределах заранее оговоренной суммы. По окончанию месяца (или другого оговоренного срока) банк выставляет владельцу карты счет, в соответствии с которым ему необходимо погасить сумму задолженности перед банком.
Револьверная кредитная карточка - кредитная карточка с самовозобновляющимся по мере погашения долга кредитом.
Платежная карточка - пластиковая карточка, предоставляющая пользующемуся ею лицу возможность безналичной оплаты товаров или услуг.
Банкомат (Automatic Teller Machine, ATM) электронно-механическое устройство, предназначенное для выдачи наличных денег владельцам пластиковых карт. Банкомат оснащен процессором, дисплеем, клавиатурой и ридером, предназначенным для считывания информации с карточки. Банкоматом могут осуществляться следующие операции: - выдача и прием наличных денежных средств; - составление документов по операциям с использованием банковских карт; - выдача информации по счету; - осуществление безналичных платежей и т.д. Для идентификации пользователя карточка помещается в ридер и с клавиатуры вводится персональный идентификационный номер (ПИН-код), после чего банкомат проводит сеанс авторизации и, при успешном его завершении, выдает наличные.
Первые банкоматы в России были установлены в 1989 г. Госбанком СССР и Сбербанком СССР.
ПОС-терминал (POS-терминал (Point Of Sale)) он же торговый терминал – электронное устройство, устанавливаемое рядом с кассовым аппаратом торгово-сервисного предприятия и позволяющее считывать информацию с магнитной полосы или чипа карточки и осуществлять связь с банком для проведения авторизации с целью осуществления операции по банковской карточке.
Могут быть использованы для расчетов с использованием как магнитных карт, так и микропроцессорных. POS-терминал позволяет автоматизировать операции по обслуживанию карты и уменьшить время ообслуживания. В отличие от банкомата ПОС-терминал обслуживается кассиром. Результаты проведения авторизации оформляются сообщением на экране и распечаткой нескольких экземпляров чека.
Системы автоматизации работы банков
АРМ сотрудника кредитного отдела (АРМ СКО) обеспечивает заключение и ведение договора, его закрытие, формирование графиков погашения основного долга и выплаты процентов по различным схемам, а также контроль выполнения этих графиков и начисление пеней по основной части долга и по процентам. АРМ поддерживает стандартные и индивидуальные процентные ставки: по основной части долга, за неиспользованный кредит (если это не указано в договоре), за просроченный возврат ссуды или за несвоевременную выплату процентов за кредит. Т.о. АРМ СКО должен поддерживать реализацию целей, которые выставляются сотруднику банка, и обеспечивать его информацией для принятия решения по кредитованию и дальнейшему обслуживанию кредита. Для этого необходимо иметь сведения о кредитном потенциале банка, о кредитоспособности ссудозаемщика и рабочую информацию по обслуживанию кредита.
Комплекс АРМ СКО должен предусматривать использование компьютера для оформления кредитной сделки и ведения кредитного договора в течение всего периода его действия. С момента регистрации выдачи кредита до его погашения сотрудник кредитного отдела должен быть обеспечен своевременной информацией о размере платы за кредит, сроках ее внесения, а также иметь возможность накапливать некоторые статистические данные по направлениям кредитования, срокам, суммам кредита и другим параметрам. Эти данные используются как для планирования собственной деятельности банка, так и для составления отчетности.
АРМ сотрудника депозитного отдела обеспечивает привлечение временно свободных средств.
Относительно предметной технологии в этот АРМ включаются
такие же режимы, как и в АРМ СКО: заключение договора, расчет процентов по различным схемам, причисление их к остатку и др.
Системы автоматизации работы банков
Автоматизированная система "Клиент - Банк"
работает со следующими типами документов: сообщение участнику (участникам) системы; платежное поручение в рублевом (валютном) формате; ответ на платежное поручение; выписки по счету (счетам) клиента. Кроме того, каждому банку - пользователю системы предоставляется возможность сформировать документы произвольного вида.
Система "Клиент-Банк" позволяет:
передавать в банк платежные документы;
получать выписки со счетов клиентов;
получать (электронные копии платежных документов по зачислению средств на счета клиентов;
обмениваться с банком электронными текстовыми сообщениями;
получать справочную информацию (перечень выполняемых банковских операций, курсы валют и т. д.);
осуществлять импорт (экспорт) информации с системой автоматизации предприятия-клиента.
Система "Клиент-Банк" обладает многоуровневой системой защиты и обеспечивает достоверность, сохранность и конфиденциальность передаваемой информации.
Банковские сети
Межгосударственные межбанковские взаимодействия на территории СНГ осуществляются через центр межгосударственных расчетов (МГР) ЦБ РФ,
международные расчеты - через систему общества международных межбанковских финансовых коммуникаций SWIFT.
SWIFT (Society for World-Wide Interbank Financial Telecommunications) –
сообщество всемирных межбанковских финансовых телекоммуникаций - ведущая международная организация в сфере финансовых телекоммуникаций. Основные направления деятельности SWIFT: предоставление оперативного, надежного, эффективного, конфиденциального и защищенного от несанкционированного доступа телекоммуникационного обслуживания для банков и проведение работ по стандартизации форм и методов обмена финансовой информацией.
С этой целью создана структурированная система финансовых сообщений, с помощью которой можно осуществлять практически весь спектр банковских и других финансовых операций, включая операции, выполняемые на валютных и фондовых биржах.
Техническая инфраструктура SWIFT создавалась в 1970е годы и содержала компьютерные центры, расположенные по всему миру и соединенные высокоскоростными линиями передачи данных. SWIFT позволяет финансовым организациям из разных стран подключаться к ней, используя терминалы различных типов.
Первоначально сеть SWIFT включала в себя (SWIFT-1):
два операционных центра в США и Нидерландах;
пять активных систем в США и Нидерландах;
региональные процессоры с различных странах;
каналы связи общего пользования и специального назначения.
В операционных центрах проводится круглосуточный контроль технических средств и программного обеспечения, работающих в сети, собирается диагностическая информация, контролируются диагностические восстановительные процессы после сбоев.
Рост числа пользователей, трафика по сети и моральное старение оборудования привели к необходимости разработки и внедрения новой сетевой архитектуры – SWIFT-2.
Переход к SWIFT-2 начался в конце 1989 г. и к 1995 г. был полностью завершен.
В SWIFT-2 используются более производительные процессоры и сетевое оборудование, а также более совершенное ПО.
Как и в SWIFT-1, в SWIFT-2 используются два равноправных связанных между собой операционных центра (в Нидерландах и США). Для гарантии отказоустойчивости все их системы дублированы.
Кроме того, для дублирования самих систем в состоянии готовности поддерживаются еще два операционных центра в головных центрах компании.
Сеть SWIFT-2 базируется на четырехуровневой архитектуре и управляется системным управляющим процессором (System Control Processor - SCP).
В SWIFT-2 выделяются следующие уровни:
терминал пользователя, позволяющий ему подключиться к сети.
региональные процессоры, назначением которых является получение сообщений от пользователей с некоторой ограниченной территории и их проверка для первичной обработки на групповом процессоре (слайс-процессоре). Они обеспечивают поддержку протоколов прикладного уровня, контроль всех входящих сообщений на соответствие стандартам, осуществляют верификацию их контрольных сумм, генерируют пользователям сообщения об успешности прохождения их финансовых сообщений. Региональные процессоры размещены в операционных центрах и работают без участия человека.
групповые процессоры (слайс-процессоры), размещенные также в операционных центрах, осуществляют основную маршрутизацию сообщений, их архивирование, генерацию системных отчетов, обработку возвращенных сообщений, генерацию данных для расчетов с пользователями и др. , обработку системных сообщений.
процессоры управления системой - расположены в операционных центрах и предназначены для управления системой. Процессоры управления системой осуществляют мониторинг аппаратно-программного обеспечения, подключенного к сети, сбор информации о сбоях, управляют операциями по выходу из сбойных ситуаций, осуществляют динамическое управление ресурсами сети, контролируют санкционированность доступа к сети, работают с БД.
Понятие клиринга и его назначение
Клиринг (clearing) – процесс безналичного расчета взаимных требований участников платежной системы, основанный на зачете взаимных требований и обязательств. Используется во внутренних и международных расчетах в целях снижения потребности в оборотных средствах и упрощения обмена платежами. Осуществляется через банки или специальные расчетные палаты (первая учреждена в Лондоне в 1775).
Когда два банка имеют большие объемы общих платежей, клиринг и урегулирование межбанковских расчетов часто осуществляется на основе двустороннего соглашения: банки договариваются о взаимозачете посланных и полученных платежных поручений (расчете чистой суммы) и об осуществлении в определенное время взаимных расчетов по чистой стоимости платежей. Этот процесс носит название двустороннего взаимозачета.
Клиринговая система - сеть клиринговых учреждений, оснащенных современными программно-техническими средствами и системами передачи данных, функционирующих на единой нормативно-правовой базе.
Клиринговые системы
Во всех крупных странах существуют системы для межбанковских операций. В США: Fedwire - сеть федеральной резервной банковской системы, владелец - Федеральная резервная система банков США; C.H.I.P.S. (Clearing House Interbank Payment System) - межбанковская платёжная сеть, создана в 1970 годы для замены бумажной системы расчетов чеками на электронную систему расчетов между Нью-Йоркскими банками и иностранными клиентами; Bankwire - сеть для обслуживания частного коммерческого сектора, организована в 1952 году 10-тью банками США. После ряда реорганизаций была создана система Bankwire-II, услугами которой пользуется система кредитных карт MasterCard.
Во Франции межбанковские расчёты основаны на клиринговой системе S.I.T. Проект системы S.I.T. был разработан в 1982-1983 г. крупнейшими банками Франции. Взаимодействие банковских систем в S.I.T. происходит на основе выделенных каналов общедоступной сети Transpac. S.I.T. взаимодействует с платежными системами VIZA и MasterCard.
В Великобритании применяются системы C.H.A.P.S. (Clearing HousesAutomated Payment System) и B.A.С.S. (Bankers Automated Clearing Services). Первая из них схожа с Американской системой C.H.I.P.S. Cистема B.A.C.S. создана в 1968 году и, по состоянию на 1988 год, имела 16 банков-акционеров. Позднее система была преобразована в систему BACSTEL.
EAF и ELS - платежные системы в Германии.
Производственные ИС
САЕ — автоматизированные расчеты и анализ (Computer Aided Engineering);
CAD — автоматизированное конструирование (Computer Aided Design);
CAM — автоматизированная технологическая подготовка производства (Computer Aided Manufacturing).
ERP — планирование и управление предприятием (планирование ресурсов) (Enterprise Resource Planning);
MRP — (планирование производства (планирование ресурсов) (Manufacturing Requirement Planning);
MES — производственная исполнительная система (Manufacturing Execution System);
SCM — управление цепочками поставок (Suplly Chain Management);
CRM — управление взаимоотношениями с заказчиками (Customer Relationship Management);
SCADA — диспетчерское управление производственными процессами (Supervisory Control And Data Acquisition);
CNC — компьютерное числовое управление (Computer Numerical Control);
S&SM — управление продажами и обслуживанием (Sales and Service Management).
Для решения проблем совместного функционирования компонентов САПР различного назначения разрабатываются системы управления проектными данными PDM (Product Data Management).
СРС (Collaborative Product Commerce — совместный электронный бизнес) -интегрирующая система, управляет информацией, разделяемой другими автоматизированными системами предприятия - ERP, SCM, CRM, PDM и др.
SCADA
автоматизированная разработка, дающая возможность создания ПО системы автоматизации без реального программирования;
средства сбора первичной информации от устройств нижнего уровня;
средства управления и регистрации сигналов об аварийных ситуациях;
средства хранения информации с возможностью ее постобработки (как правило, реализуется через интерфейсы к наиболее популярным базам данных);
средства обработки первичной информации;
средства визуализации информации в виде графиков, гистограмм и т.п..
Информационно-управляющая структура производственного предприятия
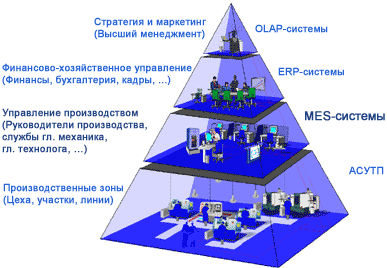
MES – это система управления производством, которая связывает воедино все бизнес-процессы предприятия с производственными процессами, оперативно поставляет объективную и подробную информацию руководству. Кроме того, она проводит анализ и определяет наиболее эффективное решение проблемы. Например, для конкретного руководителя таким решением может быть переход на другие источники сырья, внедрение систем автоматизации в определенные точки технологического процесса, изменение графика поставок или сокращение ручного труда.
По определению APICS (American Production and Inventory Control Society), система MES – это информационная и коммуникационная система производственной среды предприятия.
Более развернутым является определение, принятое в некоммерческой ассоциации MESA (Manufacturing Enterprise Solutions Association), объединяющей производителей и консультантов-внедренцев MES-систем:
MES – это автоматизированная система управления производственной деятельностью предприятия, которая в режиме реального времени: планирует; оптимизирует; контролирует; документирует производственные процессы от начала формирования заказа до выпуска готовой продукции.
Основные функции MES.
1. Контроль состояния и распределение ресурсов (RAS) – управление ресурсами производства (машинами, инструментальными средствами, методиками работ, материалами, оборудованием) и другими объектами (например, документами о порядке выполнения каждой производственной операции). В рамках этой функции описывается детальная история ресурсов и гарантируется правильность настройки оборудования в производственном процессе, отслеживается состояние оборудования в режиме реального времени.
2. Оперативное/детальное планирование (ODS) – оперативное и детальное планирование работы, основанное на приоритетах, атрибутах, характеристиках и свойствах конкретного вида продукции, детальный и оптимальный расчет загрузки оборудования при работе конкретной смены.
3. Диспетчеризация производства (DPU) – текущий мониторинг и диспетчеризация процесса производства, отслеживание выполнения операций, занятости оборудования и людей, выполнения заказов, объемов, партий, контроль в реальном времени выполнения работ в соответствии с планом. В режиме реального времени отслеживаются все происходящие изменения и вносятся корректировки в план цеха.
4. Управление документами (DOC) – контроль содержания и прохождения документов, которые должны сопровождать выпускаемое изделие, включая инструкции и нормативы работ, способы выполнения, чертежи, процедуры стандартных операций, программы обработки деталей, записи партий продукции, сообщения о технических изменениях, передачу информации от смены к смене, а также обеспечение возможности вести плановую и отчетную цеховую документацию.
5. Сбор и хранение данных (DCA) – информационное взаимодействие различных производственных подсистем для получения, накопления и передачи технологических и управляющих данных, циркулирующих в производственной среде предприятия.
6. Управление персоналом (LM) – предоставление информации о персонале с заданной периодичностью, включая отчеты о времени и присутствии на рабочем месте, слежение за соответствием сертификации, а также возможность учитывать и контролировать основные, дополнительные и совмещаемые обязанности персонала, такие как выполнение подготовительных операций, расширение зоны работы.
7. Управление качеством продукции (QM) – предоставление данных измерений о качестве продукции, в том числе и в режиме реального времени, собранных с производственного уровня, обеспечение должного контроля качества и особый контроль «критических точек». Может предложить действия по исправлению ситуации в данной точке на основе анализа корреляционных зависимостей и статистических данных причинно-следственных связей контролируемых событий.
8. Управление производственными процессами (PM) – отслеживание заданного производственного процесса, автоматическое внесение корректив или предложение соответствующего решения оператору для исправления или повышения качества текущих работ.
9. Управление производственными фондами (техобслуживание) (MM) – поддержка процесса технического обслуживания, планового и оперативного ремонта производственного и технологического оборудования и инструментов в течение всего производственного процесса.
10. Отслеживание истории продукта (PTG) – предоставление информации о том, где и в каком порядке велась работа с данной продукцией. Информация о состоянии может включать отчет о персонале, работающем с этим видом продукции, компоненты продукции, материалы от поставщика, партию, серийный номер, текущие условия производства, несоответствие установленным нормам, индивидуальный технологический паспорт изделия.
11. Анализ производительности (PA) – отчеты о реальных результатах производственных операций, сравнение их с предыдущими и ожидаемыми результатами. Представленные отчеты могут включать такие измерения, как использование ресурсов, наличие ресурсов, время цикла производственного ресурса, соответствие плану, стандартам и др.
Главное отличие MES от ERP: MES-системы, оперируя производственной информацией, позволяют корректировать либо полностью перерассчитывать производственное расписание в течение рабочей смены столько раз, сколько это необходимо. В ERP-системах по причине большого объема административно-хозяйственной и учетно-финансовой информации перепланирование может осуществляться не чаще одного раза в сутки.
За счет быстрой реакции на происходящие события и применения математических методов компенсации отклонений от производственного расписания, MES-системы позволяют оптимизировать производство и сделать его более рентабельным.
MES-системы, собирая и обобщая данные, полученные от различных производственных систем и технологических линий (нижний уровень пирамиды), выводят на более высокий уровень организацию всей производственной деятельности, начиная от формирования производственного заказа и до отгрузки готовой продукции на склады.
MES-системы реализуют связь в реальном времени производственных процессов с бизнес процессами предприятия и улучшают финансовые показатели предприятия, включая повышение отдачи основных фондов, ускорение оборота денежных средств, снижение себестоимости, своевременность поставок, повышение размера прибыли и производительности.
MES-системы формируют данные о текущих производственных показателях, включая реальную себестоимость продукции, необходимые для более качественного функционирования ERP систем.
Т.о., MES - это связующее звено между ориентированными на финансово-хозяйственные операции ERP-системами и оперативной производственной деятельностью предприятия на уровне цеха, участка или производственной линии.
Тема 6 Пользовательские интерфейсы информационных систем. Составные части интерфейса, их характеристика. Структура диалога типа «вопрос-ответ». Структура диалога типа «меню». Экранные формы. Многооконные WIMP-интерфейсы. Интеллектуальные интерфейсы.
Составные части интерфейса ИС
Каждую ИС можно оценивать двумя критериями: точностью и удобством.
Точность означает, что при поступлении на вход системы заданных значений на ее выходе получаются ожидаемые результаты.
Критерий удобства означает, что при работе с ИС пользователь не должен существенно менять стиль своей работы.
Интерфейс включает все аспекты ИС, с которой непосредственно соприкасается пользователь. Его основной функцией является организация диалога, обеспечивающего интеграцию профессиональных потребностей и интересов пользователей с ресурсами ИС. При этом интерфейс рассматривается как отдельный компонент, в котором можно выделить составляющие его элементы.
Интерфейс обеспечивает связь между пользователем и процессом, выполняющим некоторое задание. Это дает возможность определять, какие задания сделать активными в данный момент, как передавать им данные для обработки и принимать результаты обработки.
Процессы по выполнению заданий вызываются интерфейсом в требуемые моменты времени. Поэтому интерфейс — это основной процесс, а процессы, выполняющие различные задания, являются неосновными, или фоновыми.
Интерфейс человек-компьютер включает:
– процесс диалога, который связывает фоновые процессы в систему;
– набор процессов ввода-вывода, которые обеспечивают физическую связь между пользователем и процессом диалога.
Эта обобщенная структура представлена на след слайде.
Составные части интерфейса ИС (на примере интерфейса ИПС)
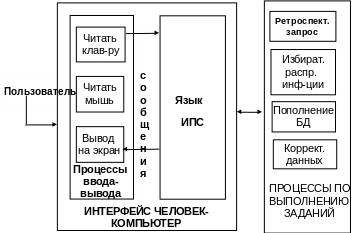
Процессы ввода-вывода
Процессы ввода-вывода – процессы передачи и приема данных между пользователем и компьютером через физические устройства.
Устройства вывода:
– монохромные и цветные дисплеи на базе ЭЛТ (оперативная текстовая и графическая информация);
– лазерные, матричные, струйные принтеры (текстовый и графический вывод);
– графопостроители (графический вывод);
– синтезаторы речи (речевой вывод).
Устройства ввода:
– клавиатура (текстовый ввод);
– планшеты (графический ввод);
– знаковый и строчный сканер (ввод документов);
– световое перо, сенсорный экран, манипуляторы «мышь», «джойстик», шар (позиционирование и выбор);
– речевой ввод и машинное зрение.
При выборе необходимых устройств учитывают следующие факторы.
Содержание и формат обрабатываемых данных. Для одних задач необходим диапазон текстовых символов, для других - графический режим с высокой разрешающей способностью.
Объем ввода-вывода. Увеличение объема входных данных предполагает наличие автоматического сбора данных.
Ограничения, накладываемые пользователем и рабочей средой. Например, клавиатура может не подойти для использования в цехах.
Ограничения, связанные с другими аппаратными и программными средствами, которые используются в системе.
Процесс диалога
Диалог между человеком и компьютером – это обмен информацией между вычислительной системой и пользователем, проводимый с помощью интерактивного терминала и по определенным правилам.
Процесс диалога – это механизм обмена информацией, который можно рассматривать как оболочку, включающую все входящие в систему процессы по выполнению определенных заданий. Процессы ввода-вывода обеспечивают обмен на самом верхнем уровне; на этом уровне диалоговый процесс должен правильно интерпретировать каждое слово и звук.
Задачи диалогового процесса:
Определение задания, которое пользователь возлагает на систему;
Прием логически связанных входных данных и размещение их в переменных соответствующего процесса и в нужном формате;
Вызов процесса выполнения требуемого задания;
Вывод результатов обработки по окончании процесса в подходящем для пользователя формате.
Сообщения
Во время диалога происходит обмен информацией между его участниками.
Информация передается в виде сообщений.
В диалоге существует несколько типов сообщений (след. слайд).
Классификация сообщений в соответствии с выполняемыми ими функциями

Сообщения
Подсказка – это выходное сообщение системы, побуждающие пользователя, вводит данные.
Команда – входное управляющее сообщение, предназначенное для управления ходом диалога.
Входные данные – данные, необходимые для выполнения процесса.
Сообщение об ошибке – это сигнал диалогового процесса о том, что невозможно дальнейшее выполнение работы, потому что вызванный процесс выполнения задания не может обработать введенное сообщение.
Выходные данные – это данные, которые возвращает процесс по окончании обработки задания. Процесс выполнения задания передает выходные данные в стандартной форме на вход диалогового процесса, который преобразует их в подходящий для пользователя формат.
Сообщение о состоянии системы – это информация для пользователя о том, что произошло или происходит в системе.
Справочная информация – это информация, поясняющая, как должен поступить пользователь в той или иной ситуации.
Входные сообщения
Входное сообщение позволяет: выбрать режимы диалога, например, получение справки; выбрать нужный процесс выполнения задания; вводить данные для выполнения задания.
Диалог можно классифицировать с учетом формата входных сообщений и гибкости, позволяющей пользователю вводить сообщения.
Диалог, управляемый системой – это диалог, в котором процесс жестко задает, какое задание необходимо выбрать и какие данные необходимо вводить. Осуществляется с помощью системы подсказок.
Диалог, управляемый пользователем – это диалог, в котором инициатива принадлежит пользователю, т.е. он непосредственно задает команду на выполнение нужного задания.
Форматы сообщений: коды; цепочки ключевых слов; ограниченный/естественный язык (ОЕЯ); естественный язык (ЕЯ).
Коды – это способ сокращенного обозначения элементов данных или заданий, который является основной частью большинства ИС. Входные данные можно закодировать с помощью функциональных ключей или с помощью подходящей мнемоники. Коды позволяют уменьшить объем вводимых данных, что увеличивает скорость ввода, снижает количество ошибок.
Программно-подобный формат (цепочки ключевых слов)- сообщения представляют собой операторы, похожие на операторы языка программирования высокого уровня. Этот формат обычно используется в диалоге, управляемом пользователем, например, при работе с СУБД.
Сообщения на ОЕЯ часто используются для построения диалогов, управляемых системой.
Цель использования ЕЯ — дать возможность оператору вести диалог с системой, как с человеком.
Проверка входных данных
Проверка входных данных сводится к сравнению пользователем сообщения с допустимыми именами задания. Список возможных имен при этом представляется в виде массива строковых переменных. Входная строка сравнивается со строками этого массива с помощью определенных функций.
Проверка входных данных осуществляется путем сравнения формата входного сообщения с заданным в спецификации, что не гарантирует от ошибок ввода данных, а только обеспечивает правильную форму записи.
Вследствие этого входные данные могут быть совершенно произвольными. Например, ввод наименования товара можно проверить лишь на соответствие заданной длине; содержимое может состоять из любой комбинации символов. И поэтому, для обозначения товара лучше пользоваться кодами, а не их названиями.
Подсказки
Существует ряд форматов вывода подсказок в диалоге человек-компьютер.
Самый сложный формат – меню, когда наряду с запросом на ввод сообщения выводятся допустимые форматы ввода. При этом меню может быть выведено в текстовом или графическом виде (в виде пиктограмм) и содержит набор возможностей, которые выбираются пользователем с помощью специальных указателей.
Система может с помощью вопроса уточнить, какой тип данных требуется, не выводя всех возможных значений. Подсказка может также содержать указания на требуемый формат входного сообщения. Если нужно ввести несколько параметров, то удобнее всего это сделать с помощью формы, которую заполняет пользователь.
Наконец, система просто может вывести запрос на ввод команды, без уточнения формата данных.
Выводы
Интерфейс человек-компьютер включает два основных компонента:
– процесс диалога, который связывает фоновые процессы в один процесс;
– набор процессов ввода-вывода, который обеспечивают физическую связь между пользователем и процессом диалога.
Диалоговые процессы можно классифицировать по формату поддерживаемых входных сообщений (грамматике) и по способу ведения диалога (управляемые пользователем или системой).
Классификацию можно уточнить с учетом вида подсказок, инициализирующих запрос на ввод.
Независимо от грамматики или способа ведения диалога, в основе интерфейса лежит следующий цикл:
– явный и неявный запрос на ввод данных;
– ввод данных через процесс ввода;
– проверка входных данных,
который повторяется, пока не будут приняты приемлемые входные данные. Если выводится запрос на ввод команды, следующий шаг будет зависеть от введенной команды.
СТРУКТУРА ДИАЛОГА ТИПА ВОПРОС-ОТВЕТ
Особенности структуры диалога типа вопрос-ответ
Структура диалога типа вопрос и ответ (Q&A) основана на аналогии с обычным интервью. Система берет на себя роль интервьюера и получает информацию от пользователя в виде ответов на вопросы. Это наиболее известная структура диалога, т.к. для ее реализации необходимы процессы ввода и вывода.
В каждой точке диалога система выводит в качестве подсказки один вопрос, на который пользователь дает один ответ. В зависимости от полученного ответа система может решить, какой следующий вопрос задавать. Например, типичный сеанс диалога этого типа может иметь вид, представленный на след. слайде.
Если ошибочный ответ вводится в структуру Q&A, ИС выдает сообщение об ошибке и снова выводит подсказку; этот процесс повторяется до тех пор, пока не будет получен приемлемый ответ. Ответ обычно вводится в виде текстовой строки. Эта строка может представлять собой либо объект из списка возможных объектов (выбираемый объект), либо произвольные данные.
Сеанс диалога типа «вопрос-ответ»
Какой гроссбух ? поставки
Команда ? отослать
Тип объекта ? счет
Номер объекта ? 123456
Клиент ? С123
Вопросы системы, ответы пользователя
Критерии разработки диалога типа вопрос-ответ
Структура диалога типа вопрос и ответ в достаточной степени обеспечивает поддержку пользователя, т. к. даже краткий наводящий вопрос может быть сделан самопоясняющим. Например, в наводящий вопрос можно включить дополнительную информацию:
Счет от (дд/мм/гг/):
Задаваемые вопросы должны быть краткими и понятными для пользователя. В структуру Q&A можно включить любую дополнительную информацию. Если пользователю для ответа на какой-либо вопрос нужна справка, система может предоставить ему подробную информацию на поставленный вопрос, например:
Команда? Help
Допустимые команды:
Post - переслать данные в программу финансового учета
Report – вывести расчет баланса, анализ предложений или людей по возрастам
Выводы
Хотя структура Q&А несколько устарела с развитием ИТ, у нее тем не менее имеются определенные достоинства.
Это - промежуточная структура, которая может удовлетворить требования различных пользователей.
Структура Q&А часто используется при реализации диалога со множеством "ответвлений", т. е. в тех случаях, когда на каждый вопрос предусматривается большое число ответов, каждый из которых влияет на то, какой вопрос будет задан следующим.
По этой причине структура Q&А часто используется в качестве диалоговой структуры в ИС.
СТРУКТУРА ДИАЛОГА ТИПА МЕНЮ
Сущность структуры меню заключается в том, что у пользователя есть список возможных вариантов данных для ввода, из которого нужно выбрать то, что требуется. Существуют разные форматы представления меню на экране; некоторые примеры меню приведены на следующих слайдах.
Форматы представления меню: а) – список объектов, выбираемых указанием цифровых кодов; б) – список объектов, выбираемых указанием мнемонических кодов
Виды страхования
1. Мотор
2. Мебель
3. Имущество
4. Персонал
5. Жизнь
6. Разное
Ваш выбор?
а)
Виды страхования
Мтр Мотор
Мбл Мебель
Имщ Имущество
Прс Персонал
Жзн Жизнь
Рзн Разное
Ваш выбор?
б)
Форматы представления меню:

Форматы представления меню: г) - меню в виде пиктограмм; д) - меню в виде строки данных.

Особенности структуры диалога типа меню
Меню в виде списка объектов, выбираемых указанием цифровых (а) или мнемонических кодов (б) – традиционный формат.
Другие форматы, такие, как меню в виде блоков (в), стали популярными с появлением "оконной" техники вывода данных.
Меню в виде строки данных (д) может появляться вверху или внизу экрана и часто остается в этой позиции на протяжении всего диалога. Т.о., посредством меню удобно отображать возможные варианты данных для ввода, доступные в любое время работы в диалоге.
Еще один распространенный способ представления используется для отображения дополнительных меню в виде блоков данных, которые "выпадают" на экран в текущем положении курсора либо непосредственно из строки меню верхнего уровня. Эти меню исчезают после выбора варианта.
Меню в виде пиктограмм (д) представляет собой множество блоков объектов выбора, разбросанных по всему экрану; часто объекты выбора содержат графическое представление вариантов работы.
Критерии разработки диалога типа меню
Меню можно применять для ввода управляющих сообщений и данных. Структура меню зависит от размера и организации меню, от способа выбора пунктов меню и реальной потребности пользователя. В идеале экранное меню должно содержать 5—6 пунктов; следует избегать списка из 10 или более пунктов. Также реализуется меню в виде блока данных, для ввода которых нужно набирать лишь слова "Да" или "Нет".
При большом числе возможных вариантов выбора их следует сгруппировать в иерархию небольших меню. На след. слайде показано меню, которое может появиться после выбора пользователем пункта "Мотор" из меню "Виды страхования", приведенного на одном из пред. слайдов.
Критерии разработки диалога типа меню
Внутри каждого меню с иерархической структурой пункты должны следовать в естественном порядке, если его можно установить, в противном случае их следует располагать в алфавитном порядке. Пункт меню, связанный с завершением работы, помещают в конце меню.
Структура типа меню предусматривает работу с механизмом указания и выбора: меню представляет собой изображение тех объектов, которые выбираются пользователем. Меню должно состоять из ограниченного числа больших, удобно расположенных и четко выделенных объектов выбора. Текущий выбранный объект выделяется.
Вместо указания пользователь может сообщить о своем выборе вводом соответствующего идентификатора. Для этого используется аббревиатура пунктов или кодированные идентификаторы для каждого пункта меню. Имена пунктов меню часто выбираются так, чтобы их первые символы были уникальны. В этом случае для идентификации выбора достаточно единственной буквы.
Идентификаторы можно закодировать с помощью функциональных клавиш, мнемонических или цифровых кодов. Функциональные клавиши можно "настроить" так, чтобы каждая из них соответствовала отдельному пункту меню. Такой подход используется в банкоматах, где различные кнопки соответствуют определенным операциям, например получению денег по чеку и т. д. В том случае, когда пользователь вводит кодированные идентификаторы, само изображение меню должно подсказывать, что надо вводить. Мнемонические обозначения применяются там, где сокращение имеющихся в меню слов трудно для понимания. Числовые коды — это способ кодирования возможных вариантов в меню, который используют в тех случаях, когда нет других более доступных обозначений.
Выводы
Структура типа меню – это естественная среда, выбор объектов которой осуществляется путем указания.
Это, по существу, интерфейс пользователя, подготовленный для работы с манипулятором «мышь».
Структура типа меню изображает точный список вариантов и дает возможность пользователю выбрать из них:
- вводом идентификатора с клавиатуры;
- просмотром списка на экране;
- прямым указанием объекта на экран и т.д.
СТРУКТУРА ДИАЛОГА
НА ОСНОВЕ ЭКРАННЫХ ФОРМ
В отличие от структуры типа вопрос-ответ, в которой одновременно задается только один вопрос, в экранных формах перед пользователем ставится сразу несколько вопросов (след. слайд). Это множество вопросов постоянно в том смысле, что ответ на предыдущий вопрос не влияет на то, какой вопрос будет задан следующим.
Диалог на основе экранной формы
Фамилия [………….]
Имя [……………….]
Отчество [………….]
Год рождения [……...]
Место рождения [……………………]
Серия паспорта [……………]
F1 – помощь F2 – ввод данных ESC - выход
Диалог типа экранной формы позволяет редактировать ответ перед вводом. Пользователь может временно пропускать вопросы и возвращаться к ответу на предыдущий вопрос. Работа с формой продолжается до тех пор, пока не будет нажата клавиша, означающая конец ввода.
ИС может проверять каждый ответ непосредственно после ввода или вывести список ошибок после заполнения формы целиком.
В структуре типа экранной формы, так же как и в структурах типа вопрос-ответ и меню, отдельный ответ может выбираться из списка возможных вариантов либо он вводится в виде произвольных значений.
Критерии разработки диалога на основе экранных форм
Формы являются естественным способом ввода данных там, где источником информации служит существующая канцелярская форма.
Важно, чтобы форма, отображаемая на экране, была похожа на ту форму на бумаге, которая является источником информации. Не обязательно, чтобы внешний вид этих форм совпадал, но все вводимые элементы данных должны располагаться в том же относительном порядке и иметь такой же формат, что и в исходном документе.
В тех случаях, когда физическая форма служит источником данных, от диалога требуется лишь незначительная дополнительная поддержка. Поскольку пользователю требуется просто внести в нее информацию, весь экран практически можно заполнить вопросами в виде кратких заголовков. Единственное требование состоит в том, чтобы пользователь мог прочесть введенную им информацию с целью контроля.
Для каждого вопроса сообщения об ошибках и справочная информация должны быть предусмотрены, и пользователь должен иметь возможность получить справку по любому вопросу формы. Пользователю можно оказать поддержку, включив некоторые элементы формата ответа в вопрос или поле ответа, например:
Дата Счета (дд/мм/гг) [_______]
или
Дата Счета [__/__/____ ]
Выводы
Структура типа экранной формы соответствует такой организации ввода, которая обычно используется в прикладных системах бухгалтерских расчетов и обработки заказов.
Эта структура работает быстрее по сравнению со структурой типа вопрос-ответ, она может манипулировать более широким диапазоном входных данных, нежели меню, и ее могут использовать пользователи любой квалификации.
Поскольку эта структура имеет последовательную, а не древовидную организацию, она не подходит для работы в режиме выбора вариантов.
МНОГООКОННЫЕ
WIMP-ИНТЕРФЕЙСЫ
Аббревиатура WIMP расшифровывается следующим образом:
W — информация представляется пользователю на экране дисплея в виде нескольких окон (windows);
I—объекты, с которыми информационная система имеет дело, представляются в виде пиктограмм (Icons);
M — выборка производится с помощью манипулятора типа «мышь» (mouse);
P — означает меню, которые автоматически всплывают (pop-up) на экране или которые пользователь может «вытянуть» (pull down) из строки меню.
Эти интерфейсы являются продолжением работ, проведенных в начале 70-х гг. в Исследовательском центре Пало-Альто фирмы «Ксерокс Корпорэйшн», их популярность в настоящее время объясняется ростом числа персональных компьютеров.
WIMP-интерфейсы поддерживаются такими ОС, как Apple Macintosh, Microsoft Windows, др., а также пакетами прикладных программ, которые подчиняются тем же соглашениям.
Окна
Окно – это специальная (обычно прямоугольная) область физического окна, с помощью которого пользователь обозревает отдельные аспекты своего взаимодействия с задачей.
Концепция окон в компьютерных системах не нова, она используется с тех пор, как появились дисплеи, работающие в постраничном режиме.
Статические окна имеют фиксированный размер и занимают фиксированное положение на экране: они часто называются черепицами.
Динамические окна появляются по необходимости и исчезают, когда пользователь закончил работу с ними. Эти окна появляются в предопределенной позиции, и пользователь может изменять размер и позиции окон, перекрывая при этом одно окно другим. Эти особенности типичны для последних интерфейсов ИС, основанных на окнах.
Окна и вспомогательные буферы
В безоконной среде выходные процессы записываются непосредственно в область памяти, зарезервированную для отображения (карты) физического экрана.
Многооконная среда обычно вводит промежуточный шаг, как показано на след. слайде.
Многооконная среда
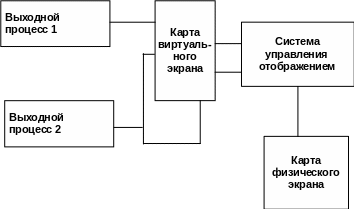
В системе управления окнами входные и выходные процессы записываются в виртуальные буферы экрана, а не на физический экран.
Система может поддерживать несколько отдельных буферов виртуального экрана одновременно; выходной процесс может записывать в любой из этих буферов. Эти буферы могут иметь любой размер и размещаться на любом удобном участке памяти (на диске или частично на диске и частично в памяти) и называются эти буферы вспомогательными.
Выходные процессы работают со вспомогательными буферами.
Вспомогательные буферы можно классифицировать, с учетом доступа, который они обеспечивают для пользователя и для диалога, следующим образом:
– буферами вывода являются буферы, которые диалог заполняет через выходной процесс; пользователь не может изменить содержимое такого буфера;
– буферами ввода являются буферы, в которые пользователь набирает содержание посредством входного процесса;
– буферами редактирования являются буферы, в которых содержимое могут изменять как пользователь, так и диалог; типичными примерами являются символьные буферы системы подготовки текстов.
Функции системы управления отображением
За отображение на физическом экране содержимого тех частей буфера, которые лежат под окнами, отвечает процесс, называемый управлением отображением.
Он обеспечивает функции:
– открытия и закрытия окна;
– перемещения окна относительно его промежуточного буфера;
– перемещения окна относительно экрана;
– изменения размеров или атрибутов окна.
Пользователь может работать с окнами либо через командный язык, либо путем прямого манипулирования. Система прямого манипулирования обращается с элементами окон как с конкретными объектами, которые могут быть физически обработаны средствами указания и выборки, экранными кнопками.
Многооконная технология обеспечивает пользователя доступом к информации, которая может поступать из многих источников или из задач.
Пиктограмма
Пиктограмма – это небольшое окно с изображением, отражающим содержимое буфера, с которым она связана.
Если пиктограмма раскрывается, то содержимое соответствующего буфера появится в окне. Например, если раскрывается пиктограмма для дисковода А, то появляется другое окно, которое в свою очередь содержит несколько пиктограмм, представляющих содержимое диска. Если одна из пиктограмм раскроется, то появится следующее окно, содержащее ее суть.
Фактически пиктограммы образуют наглядное меню доступных в текущий момент программ и данных.
Критерии проектирования для WIMP-интерфейсов
Окна являются эффективным способом группирования информации на экране. Содержимое окна должно образовывать логическую последовательность, соответствующий формат и использовать минимальную яркость, необходимую для выделения наиболее важной информации. Эти же критерии должны также применяться и к целому экрану. Не рекомендуется использовать сложное кодирование кнопок мыши или сложные последовательности нажатия кнопок.
В помощь опытным пользователям интерфейс ИС должен допускать сокращения, такие, как прямое указание идентификатора меню вместо его полного просмотра; использование командных строк и функциональных ключей как альтернативу управления позицией.
Рабочая станция должна иметь необходимую мощность для поддержки интерфейса.
Выводы
Многооконная технология обеспечивает пользователя доступом к информации, которая может приходить из многих источников или из задач.
Многооконный WIMP-интерфейс является одним из наилучших механизмов, который обеспечивает мощный набор средств для «форматирования» выходных сообщений и для обеспечения выборки и указания ввода.
ИНТЕЛЛЕКТУАЛЬНЫЕ ИНТЕРФЕЙСЫ
Все интерфейсы, которые рассматривались до сих пор, были «слепыми»: пересылка информации между физическими процессами ввода-вывода и пользователем включала только простое механическое преобразование сообщений.
Типы интерфейсов, рассматриваемые далее, имеют общие характеристики, которые позволяют называть их интеллектуальными. Основная особенность: преобразования, включенные в интерфейс, должны осуществляться в контексте отображаемой предметной области. Такой интерфейс должен обладать некоторыми знаниями о мире задачи, в котором функционируют он и пользователь (сл. слайд)
Особенность интеллектуальных интерфейсов заключается в том, что они используют форму распознавания образов для интерпретации входных сообщений от пользователя в свете системной модели мира. Возникают две проблемы: сам по себе механизм распознавания образов, и обеспечение модели мира, которая приобретает и хранит образы. При этом требуется большая компьютерная мощность для обработки правил, используемых компьютерной системой при принятии даже простых решений.
Интеллектуальные интерфейсы являются сферой активных совместных исследований в области взаимодействия человек-компьютер и искусственного интеллекта.
Тема 7. Представление данных в информационных системах. Управление файлами. Управление базами данных. Архитектура систем баз данных; три уровня архитектуры, архитектура “клиент-сервер”, распределенная обработка. Введение в реляционные, объектно -ориентированные базы данных. Системы управления базами данных и автоматизированные банки данных. Языки определения данных, управления данными и запросов. 2 часа.
Системы БД сегодня являются основой построения большинства ИС и используются при автоматизации практически всех сфер человеческой деятельности.
Например, доступ к БД необходим при работе с библиотечной ИС, содержащей сведения обо всех книгах, имеющихся в библиотеке, ее читателях, заявках на бронирование книг и т.д. В ней обычно содержатся средства, позволяющие читателям находить нужную им книгу по названию, фамилиям авторов или указанной тематике. С помощью такого рода систем организуется учет движения книг, другие операции, необходимые в библиотечной деятельности.
В ВУЗе могут существовать базы данных с информацией о студентах, профессорско-преподавательском составе, факультетах и кафедрах, др. данные, необходимые для функционирования комплексных информационно-аналитических систем и их подсистем (учета кадров, бухгалтерской, документооборота, информационного обеспечения учебной деятельности и т.п.).
БД по народонаселению содержат сведения о жителях города, региона и т.п., необходимые для функционирования систем налогообложения, здравоохранения, образования, социальной защиты, др.
При проектировании и изготовлении изделий необходимы БД по отработанным и спроектированным изделиям-прототипам, по характеристикам проектируемых изделий, по параметрам технологического процесса изготовления изделий, по используемым сырью и материалам и т.п.
ФАЙЛОВЫЕ СИСТЕМЫ
Традиционные файловые системы, реализованные в различных ОС, имеют ограничения, препятствующие их широкому использованию при построении ИС: Разделение и изоляция данных; Дублирование данных; Зависимость от программ и данных; Несовместимость форматов файлов; Фиксированные запросы и быстрое увеличение количества приложений.
Разделение и изоляция данных. Данные изолированы в отдельных файлах, что требует значительных трудозатрат при извлечении необходимой информации, часто - выполнения синхронной обработки файлов.
Дублирование данных. Из-за децентрализованной работы с информацией выполняется дублирование данных, что приводит к неэкономному расходованию памяти, часто- к нарушению целостности данных.
Зависимость от данных. Физическая структура и способ хранения записей файлов данных жестко зафиксированы в коде программ приложений. Это значит, что изменить существующую структуру данных достаточно сложно. Данная особенность называется зависимостью от программ и данных.
Несовместимость форматов файлов. Структура файлов зависит от языка программирования приложения. Прямая несовместимость таких файлов затрудняет процесс их совместной обработки.
Фиксированные запросы и быстрое увеличение количества приложений. В процессе работы у пользователей возникает потребность в новых запросам к данным, реализация которых осуществляется в виде приложений, что ведет к увеличению их количества. При этом часто нарушаются меры по обеспечению безопасности или целостности данных, не предусматриваются средства восстановления в случае сбоя, доступ к файлам ограничивается одним пользователем.
Системы с базами данных.
Все перечисленные ограничения файловых систем являются следствием двух факторов:
- Определение данных содержится внутри приложений, а не хранится отдельно и независимо от них;
- Помимо приложений не предусмотрено никаких других инструментов доступа к данным и их обработки.
Для повышения эффективности работы был разработан подход, основанный на использовании БД (database) и систем управления базами данных, или СУБД (Database Management System — DBMS). Далее представлено определение этих терминов, а также рассмотрены компоненты среды СУБД.
База данных
БД - набор совместно используемых логически связанных данных, сопровождаемый описанием этих данных, предназначенный для удовлетворения информационных потребностей групп пользователей.
Поясним сказанное. БД — это совокупность данных, которые однократно определяются, а затем используются одновременно многими пользователями. Вместо разрозненных файлов с избыточными данными здесь все данные собраны вместе с минимальной долей избыточности. БД хранит не только рабочие данные, но и их описания. БД еще называют набором интегрированных записей с самоописанием.Описание данных называется системным каталогом (system catalog), или словарем данных (data dictionary), а сами элементы описания называют метаданными (meta-data), т.е. "данными о данных". Наличие самоописания данных в БД обеспечивает в ней независимость между программами и данными (program-data independence). Структура данных при этом отделена от приложений и хранится в БД. Добавление новых структур данных или изменение существующих никак не влияет на приложения, при условии, что они не зависят непосредственно от изменяемых компонентов.
Данные в БД "логически связаны". При анализе информационных потребностей пользователей следует выделить сущности, атрибуты и связи. Сущностью (entity) называют отдельный тип объекта (человек, изделие, понятие или событие), который нужно представить в БД. Атрибут (attribute) - свойство, которое описывает некоторую характеристику описываемого объекта; связь (relationship) — это то, что объединяет сущности. Подобная БД представляет сущности, атрибуты и логические связи между объектами. Иначе говоря, БД содержит логически связанные данные.
СУБД - это ПО, с помощью которого пользователи могут определять, создавать и поддерживать БД, а также осуществлять к ней контролируемый доступ. СУБД взаимодействует с ПП пользователя и БД и позволяет:
• определять БД с помощью языка определения данных (DDL — Data Definition Language).
• вставлять, обновлять, удалять и извлекать информацию из БД с помощью языка управления данными (DML — Data Manipulation Language). Наличие централизованного хранилища всех данных и их описаний позволяет использовать DML для организации запросов, его называют языком запросов (query language). Существует процедурные (procedural) и непроцедурные (non-procedural) DML: первые обрабатывают информацию в БД последовательно, запись за записью, вторые - оперируют наборами записей. С помощью процедурных DML указывается, как можно получить желаемый результат, непроцедурные же DML используются для описания того, что следует получить. Наиболее известный непроцедурный язык - язык структурированных запросов (Structured Query Language — SQL), который определяется стандартом ISO и фактически является обязательным языком для любых реляционных СУБД.
• обеспечивать контролируемый доступ к БД с помощью: системы обеспечения безопасности; системы поддержки целостности данных; системы управления параллельной работой приложений; системы восстановления, позволяющей восстановить БД до предыдущего непротиворечивого состояния, нарушенного в результате сбоя; доступного пользователям каталога.
СУБД содержат в себе механизм создания представлений (view), который позволяет пользователю иметь свой взгляд на БД. DDL включает средства определения представлений, каждое из которых является некоторым подмножеством БД.
Кроме того, представления обеспечивают: Дополнительный уровень безопасности за счет возможности исключения данных, которые не должны видеть некоторые пользователи; Настройку внешнего интерфейса БД; Сохранение внешнего интерфейса БД неизменным даже при внесении изменений в ее структуру.
Т.о., представление обеспечивает полную независимость программ от реальной структуры данных.
Банк данных – универсальные базы данных, предназначенные для обслуживания прикладных программ, вместе с соответствующими СУБД.
Информационно-поисковая система – частный случай банка данных, предназначенный для хранения, поиска и вывода на устройства ЭВМ необходимой информации.
Компоненты среды СУБД. В общем случае в среде СУБД можно выделить следующие пять основных компонентов: аппаратное обеспечение, программное обеспечение, данные, процедуры и пользователи.
Аппаратное обеспечение. Для работы СУБД и приложений необходимо некоторое аппаратное обеспечение. Оно может варьироваться в широких пределах — от единственного персонального компьютера или одного мейнфрейма до информационно-вычислительной сети. При этом одни СУБД предназначены для работы только с конкретными типами ОС или оборудования, другие могут работать с широким кругом аппаратного обеспечения и различными ОС.
Программное обеспечение. Этот компонент охватывает ПО самой СУБД и прикладных программ, вместе с ОС, включая и сетевое программное обеспечение, если СУБД используется в сети.
Обычно приложения создаются на языках третьего поколения, таких как С, COBOL, Fortran, Ada или Pascal, или на языках четвертого поколения, таких как SQL, операторы которых внедряются в программы на языках третьего поколения.
Кроме того, СУБД может иметь свои собственные инструменты четвертого поколения, предназначенные для быстрой разработки приложений с использованием встроенных непроцедурных языков запросов, генераторов отчетов, форм, графических изображений.
Данные. Самым важным компонентом среды СУБД с точки зрения конечных пользователей являются данные, играющие роль моста между компьютером и человеком. БД содержит как рабочие данные, так и метаданные, cтруктура БД называется схемой.
В системном каталоге содержатся следующие сведения:
• имена, типы и размеры элементов данных;
• имена связей;
• ограничения целостности данных;
• имена зарегистрированных пользователей, которым предоставлены некоторые права доступа к данным;
• используемые индексы и структуры хранения — например, инвертированные файлы.
Процедуры. К процедурам относятся инструкции и правила, которые должны учитываться при проектировании и использовании БД. Пользователям и обслуживающему персоналу БД необходимо предоставить документацию, содержащую подробное описание процедур использования и сопровождения данной системы, включая инструкции о правилах выполнения действий по работе с СУБД и БД (регистрация в СУБД, запуск и останов СУБД, создание резервных копий БД и т.п.).
Пользователи. Последним компонентом среды СУБД являются пользователи системы.
Распределение обязанностей в системах с базами данных
Рассмотрим пятый компонент среды СУБД — ее пользователей. Среди них можно выделить группы: администраторы данных и баз данных, прикладные программисты и конечные пользователи.
Администраторы данных и баз данных. Администратор данных (АД, Data Administrator — DA) отвечает за управление данными, включая планирование БД, разработку и сопровождение стандартов, правил использования данных, а также за концептуальное и логическое проектирование БД. Концептуальное проектирование БД выполняется независимо от таких деталей, как целевая СУБД, приложения, языки программирования, др. физические характеристики. Логическое проектирование проводится с учетом особенностей выбранной модели данных: реляционной, сетевой, иерархической, объектно-ориентированной. АД дает свои рекомендации руководству, контролируя направления развития БД установленным целям.
Администратор базы данных (АБД, Database Administrator — DBA) отвечает за физическую реализацию БД, включая физическое проектирование и воплощение проекта, за обеспечение безопасности и целостности данных, а также за обеспечение призводительности приложений. По сравнению с АД, обязанности АБД носят более технический характер, он должен быть профессиональным специалистом в области ИТ.
Прикладные программисты разрабатывают приложения, предоставляющие пользователям необходимые им функциональные возможности. Эти приложения могут создаваться на различных языках программирования 3-го или 4-го поколений.
Конечные пользователи являются потребителями возможностей БД — она создается для того, чтобы обслуживать их информационные потребности. Конечные пользователи обычно обращаются к БД с помощью приложений, вводя простейшие команды или выбирая команды меню. Опытные конечные пользователи могут использовать SQL, некоторые могут создавать собственные прикладные программы.
История развития СУБД
В середине 60-х годов корпорация IBM совместно с фирмой NAA (North American Aviation) разработали первую СУБД - иерархическую систему IMS (Information Management System), которая остается основной иерархической СУБД, используемой на мейнфреймах и в настоящее время.
В 60-х годах появилась система IDS (Integrated Data Store) фирмы General Electric, относящаяся к классу сетевых СУБД. Сетевая СУБД позволила создавать более сложные взаимосвязи между данными и послужила основой для разработки первых стандартов БД. Для создания таких стандартов в 1965 году на конференции CODASYL (Conference on Data Systems Languages) была сформирована рабочая группа List Processing Task Force, переименованная в 1967 году в Data Base Task Group (DBTG). Отчет этой группы был опубликован в 1971 году и содержал следующие утверждения:
• Сетевая схема — это логическая организация всей БД в целом, которая включает
определение имени БД, типа каждой записи и компонентов записей каждого типа.
• Подсхема — это часть БД, видимая конкретными пользователями или
приложениями.
• Язык управления данными — инструмент для определения характеристик и
структуры данных, а также для управления ими.
DBTG предложила стандартизировать три различных языка:
• Язык определения данных DDL для схемы, который позволит АБД описать ее.
• Язык определения данных DDL для подсхемы, который позволит определять в
приложениях те части БД, доступ к которым будет необходим.
• Язык манипулирования данными DML.
Системы, разработанные в соответствии с этими предложениями - CODASYL-системы. CODASYL- и иерархические системы - СУБД первого поколения. Один из основных их недостатков-отсутствие теоретических основ.
История развития СУБД
В 1970 году Э. Ф. Кодд , работавший в корпорации IBM, опубликовал статью о реляционной модели данных (РМД), позволявшей устранить недостатки прежних моделей. Вслед за этим появилось множество реляционных СУБД, первые коммерческие продукты - в конце 70-х - начале 80-х годов. Особенно следует отметить System R, разработанную в корпорации IBM в конце 70-х годов. На основе этого проекта были получены важнейшие результаты:
• разработан язык структурированных запросов SQL;
• В 80-х годах были созданы различные коммерческие реляционные СУБД — например, DB2 или SQL/DS корпорации IBM, Oracle корпорации Oracle , др.
В настоящее время существует несколько сотен различных реляционных СУБД для мейнфреймов и ПЭВМ. Примеры многопользовательских СУБД: система Informix фирмы Informix Software, Inc.; Oracle. Примеры реляционных СУБД для ПК: Access и FoxPro фирмы Microsoft; Paradox и Visual dBase фирмы Borland, др. Реляционные СУБД относятся к СУБД второго поколения. Однако РМД также обладает недостатками — в частности, ограниченными возможностями моделирования. Для решения этой проблемы был выполнен большой объем исследовательской работы. В 1976 году Чен предложил модель "сущность-связь" (Entity-Relationship model — ER-модель), которая стала основой методологии концептуального проектирования БД и методологии логического проектирования реляционных БД.
В ответ на возрастающую сложность приложений БД появились объектно-ориентированные СУБД, или ОО СУБД (Object-Oriented DBMS — OODBMS), и объектно-реляционные СУБД, или ОР СУБД (Object-Relational DBMS — ORDBMS). Это - СУБД третьего поколения.
В СССР в середине 70-х годов в НПО «Алтай» была разработана ИПС, основу которой составляла универсальная объектно-ориентированная иерархическая СУБД, нашедшая широкое применение при решении задач проектирования и управления и предвосхитившая многие более поздние разработки такого рода.
Преимущества и недостатки СУБД
Преимущества:
контроль за избыточностью данных;
непротиворечивость данных;
больше полезной информации при том же объеме хранимых данных;
cовместное использование данных;
поддержка целостности данных;
повышенная безопасность;
применение стандартов;
повышение эффективности с ростом масштабов системы; возможность нахождения компромисса при противоречивых требованиях;
повышение доступности данных и их готовности к работе; улучшение показателей производительности;
упрощение сопровождения системы за счет независимости от данных;
улучшенное управление параллельностью;
развитые службы резервного копирования и восстановления.
Контроль за избыточностью данных.
Как уже говорилось , традиционные файловые системы неэкономно расходуют внешнюю память, сохраняя одни и те же данные в нескольких файлах. При использовании БД предпринимается попытка исключить избыточность данных за счет интеграции файлов, чтобы избежать хранения нескольких копий одного и того же элемента информации.
Однако полностью избыточность информации в БД не исключается, а лишь контролируется ее степень. В одних случаях ключевые элементы данных необходимо дублировать для моделирования связей, а в других случаях некоторые данные потребуется дублировать из соображений повышения производительности системы.
Непротиворечивость данных.
Устранение избыточности данных или контроль над ней позволяет сократить риск возникновения противоречивых состояний.
Если элемент данных хранится в базе только в одном экземпляре, то для изменения его значения потребуется выполнить только одну операцию обновления, причем новое значение станет доступным сразу всем пользователям БД. А если этот элемент данных хранится в БД в нескольких экземплярах, то такая система сможет следить за тем, чтобы копии не противоречили друг другу.
Больше полезной информации при том же объеме хранимых данных.
Благодаря интеграции рабочих данных организации можно получать дополнительную информацию, основанную на использовании интегрированных данных.
Совместное использование данных.
Файлы обычно принадлежат отдельным лицам , которые используют их в своей работе.
БД принадлежит группам пользователей или всей организации в целом и может совместно использоваться всеми зарегистрированными пользователями. При такой организации работы большее количество пользователей может работать с большим объемом данных. Более того, при этом можно создавать новые приложения на основе уже существующей в БД информации и добавлять в нее только те данные, которые в настоящий момент еще не хранятся в ней, а не определять заново требования ко всем данным, необходимым новому приложению. Новые приложения могут также использовать такие предоставляемые СУБД функциональные возможности, как определение структур данных и управление доступом к данным, организация параллельной обработки и обеспечение средств копирования/восстановления, исключив необходимость реализации этих функций со своей стороны.
Поддержка целостности данных.
Целостность БД означает корректность и непротиворечивость хранимых в ней данных. Целостность обычно описывается с помощью ограничений, т.е. правил поддержки непротиворечивости, которые не должны нарушаться в БД. Ограничения можно применять к элементам данных внутри одной записи или к связям между записями. Т.о., интеграция данных позволяет АБД задавать требования по поддержке целостности данных, а СУБД применять их.
Повышенная безопасность.
Безопасность БД заключается в защите данных от несанкционированного доступа со стороны пользователей. Без привлечения соответствующих мер безопасности интегрированные данные становятся более уязвимыми, чем данные в файловой системе. Однако интеграция позволяет АБД определить требуемую систему безопасности БД, а СУБД привести ее в действие. Система обеспечения безопасности может быть выражена в форме учетных имен и паролей для идентификации пользователей, которые зарегистрированы в этой БД. Доступ к данным со стороны зарегистрированного пользователя может быть ограничен только некоторыми операциями (извлечением, вставкой, обновлением и удалением).
Применение стандартов.
Интеграция позволяет АБД определять и применять необходимые стандарты. Например, стандарты предприятия, государственные и международные стандарты могут регламентировать формат данных при обмене ими между системами, соглашения об именах, форму представления документации, процедуры обновления и правила доступа.
Повышение эффективности с ростом масштабов системы.
Комбинируя все рабочие данные в одной БД и создавая набор приложений, которые работают с одним источником данных, можно добиться существенной экономии средств.
Возможность нахождения компромисса для противоречивых требований.
Потребности одних пользователей могут противоречить потребностям других. Поскольку БД контролируется АБД, он может принимать решения о проектировании и способе ее использования, при которых имеющиеся ресурсы всего предприятия в целом будут использоваться наилучшим образом.
Улучшение показателей производительности.
Как уже упоминалось выше, в СУБД предусмотрены стандартные функции, которые программист обычно должен самостоятельно реализовать в приложениях для файловых систем. На базовом уровне СУБД обеспечивает все низкоуровневые процедуры работы с файлами, которую обычно выполняют приложения. Наличие этих процедур позволяет программисту сконцентрироваться на разработке более специальных, необходимых пользователям функций, не заботясь о подробностях их воплощения на более низком уровне. Во многих СУБД также предусмотрена среда разработки четвертого поколения с инструментами, упрощающими создание приложений баз данных. Результатом является повышение производительности работы программистов и сокращение времени разработки новых приложений.
Упрощение сопровождения системы за счет независимости от данных.
В файловых системах описания данных и логика доступа к данным встроены в каждое приложение, что делает программы зависимыми от данных. В СУБД описания данных отделены от приложений, а потому приложения защищены от изменений в описаниях данных.
Улучшенное управление параллельностью.
В файловых системах при одновременном доступе к одному и тому же файлу двух пользователей может возникнуть конфликт двух запросов, результатом которого будет потеря информации или утрата ее целостности. В СУБД предусмотрена возможность параллельного доступа к БД и гарантируется отсутствие подобных проблем.
Развитые службы резервного копирования и восстановления.
Ответственность за обеспечение защиты данных от сбоев аппаратного и программного обеспечения в файловых системах возлагается на пользователя. В СУБД предусмотрены средства сокращения объема потерь информации от возникновения различных сбоев.
Недостатки СУБД
cложность
большой размер ПО
высокая cтоимость
дополнительные затраты на аппаратное обеспечение
затраты на преобразование приложений
производительность
более серьезные последствия при выходе системы из строя.
Сложность.
Обеспечение функциональности, которой должна обладать каждая хорошая СУБД, сопровождается ее усложнением. Чтобы воспользоваться всеми преимуществами СУБД, проектировщики и разработчики БД, АД и АБД, а также конечные пользователи должны хорошо понимать функциональные возможности СУБД. Непонимание принципов работы системы может привести к неудачным результатам проектирования со всеми вытекающими отсюда последствиями.
Размер программного обеспечения.
Сложность и широта функциональных возможностей приводит к тому, что СУБД становится программным продуктом, который может занимать много места на диске и требовать большого объема оперативной памяти для эффективной работы.
Стоимость СУБД.
В зависимости от имеющейся вычислительной среды и требуемых функциональных возможностей, стоимость СУБД может варьироваться в очень широких пределах – от нескольких сот до нескольких сот тысяч долларов. Кроме того, следует учесть ежегодные расходы на сопровождение системы, которые составляют некоторый процент от ее стоимости.
Дополнительные затраты на аппаратное обеспечение.
Для удовлетворения требований, предъявляемых к дисковым накопителям со стороны СУБД и БД, может понадобиться приобрести дополнительные устройства хранения информации. Более того, для достижения требуемой производительности может понадобиться более мощный компьютер, который, возможно, будет работать только с СУБД.
Затраты на преобразование приложений.
В некоторых ситуациях стоимость СУБД и дополнительного аппаратного обеспечения может оказаться несущественной по сравнению со стоимостью преобразования существующих приложений для работы с новой СУБД и новым аппаратным обеспечением. Эти затраты также включают стоимость подготовки персонала для работы с новой системой, а также оплату услуг специалистов, которые будут оказывать помощь в преобразовании и запуске новой системы.
Производительность.
Обычно файловая система создается для некоторых специализированных приложений, а потому ее производительность может быть весьма высока. Однако СУБД предназначены для решения более общих задач и обслуживания сразу нескольких приложений, в результате многие приложения в новой среде будут работать не так быстро, как прежде.
Более серьезные последствия при выходе системы из строя.
Централизация ресурсов повышает уязвимость системы. Поскольку работа всех пользователей и приложений зависит от готовности к работе СУБД, выход из строя одного из ее компонентов может привести к полному прекращению всей работы предприятия.
СРЕДА БАЗЫ ДАННЫХ
Основная цель СУБД - предложить пользователю абстрактное представление данных, скрыв конкретные особенности хранения и управления ими. Следовательно, отправной точкой при проектировании БД должно быть общее описание информационных потребностей пользователей, которые должны найти свое отражение в создаваемой БД.
Более того, поскольку БД является общим ресурсом, то каждому пользователю может потребоваться свое, отличное от других представление о характеристиках информации, сохраняемой в БД. Для удовлетворения этих потребностей архитектура современных СУБД в той или иной степени строится на базе так называемой архитектуры ANSI-SPARC, рассматриваемой ниже.
Трехуровневая архитектура ANSI-SPARC
Первая попытка создания стандартной терминологии и общей архитектуры СУБД была предпринята в 1971 году группой DBTG, признавшей необходимость использования двухуровневого подхода, построенного на основе использования системного представления, т.е. схемы , и пользовательских представлений, т.е. подсхем. Сходные терминология и архитектура были предложены в 1975 году Комитетом планирования стандартов и норм SPARC (Standards Planning and Requirements Committee) Национального Института Стандартизации США (American National Standard Institute — ANSI), ANSI/X3/SPARC (ANSI, 1975). Комитет ANSI/SPARC признал необходимость использования трехуровневого подхода. Хотя модель ANSI/SPARC не стала стандартом, тем не менее она представляет собой основу для понимания некоторых функциональных особенностей СУБД.
В данном случае для нас важным моментом в этих и последующих разработках является идентификация трех уровней абстракции, т.е. трех различных уровней описания элементов данных. Эти уровни формируют трехуровневую архитектуру, которая охватывает внешний, концептуальный и внутренний уровни, как показано на след. слайде.
Трехуровневая архитектура ANSI-SPARC
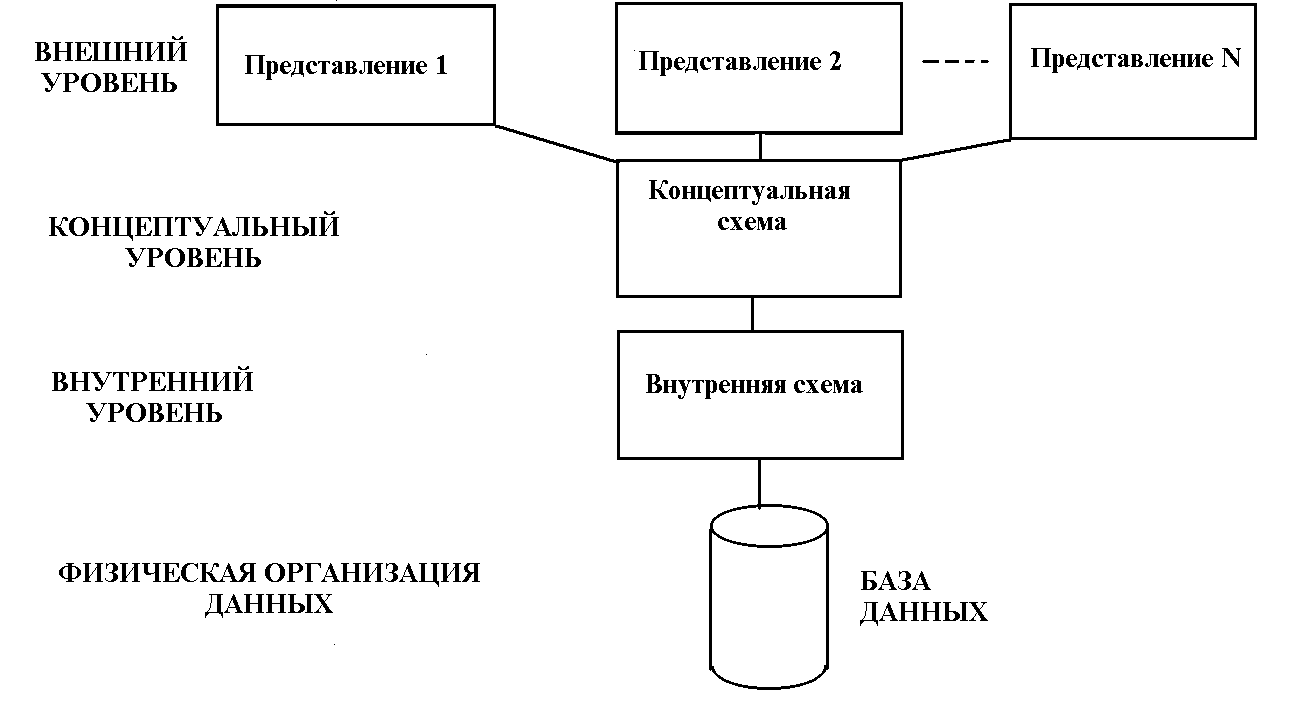
Цель трехуровневой архитектуры - отделение пользовательского представления БД от ее физического представления. Ниже перечислены причины такого разделения.
• Каждый пользователь должен иметь возможность обращаться к одним и тем же данным, используя свое собственное представление о них. Каждый пользователь должен иметь возможность изменять свое представление о данных, причем это изменение не должно оказывать влияния на других пользователей.
• Пользователи не должны непосредственно иметь дело с подробностями физического хранения данных в базе
• Администратор БД должен иметь возможность изменять структуру хранения данных, не оказывая влияния на пользовательские представления.
• Внутренняя структура БД не должна зависеть от таких изменений физических аспектов хранения информации, как переход на новое устройство хранения.
• АБД должен иметь возможность изменять концептуальную или глобальную структуру БД без какого-либо влияния на всех пользователей.
Уровень, на котором воспринимают данные пользователи, называется внешним уровнем (external level), тогда как СУБД и ОС воспринимают данные на внутреннем уровне (internal level). Именно на внутреннем уровне данные реально сохраняются с использованием всех структур и файловой организации. Концептуальный уровень (conceptual level) представления данных предназначен для отображения внешнего уровня на внутренний и обеспечения необходимой независимости друг от друга.
Внешний уровень.
Внешний уровень состоит из нескольких различных внешних представлений БД. Каждый пользователь имеет дело с представлением предметной области, выраженным в наиболее удобной для него форме.
Помимо этого, различные представления могут по-разному отображать одни и те же данные. Например, один пользователь может просматривать даты в формате (день, месяц, год), а другой — в формате (год, месяц, день). Некоторые представления могут включать производные или вычисляемые данные, которые не хранятся в БД как таковые, а создаются по мере надобности. Представления могут также включать комбинированные или производные данные из нескольких объектов.
Концептуальный уровень.
Промежуточным уровнем в трехуровневой архитектуре является концептуальный уровень. Этот уровень содержит логическую структуру всей БД (с точки зрения АБД). Фактически, это полное представление требований к данным, которое не зависит от любых соображений относительно способа их хранения.
На концептуальном уровне представлены следующие компоненты: все сущности, их атрибуты и связи; накладываемые на данные ограничения; семантическая информация о данных; информация о мерах обеспечения безопасности и поддержки целостности данных.
Концептуальный уровень поддерживает каждое внешнее представление, в том смысле, что любые доступные пользователю данные должны содержаться (или могут быть вычислены) на этом уровне. Однако этот уровень не содержит никаких сведений о методах хранения данных.
Внутренний уровень.
Внутренний уровень описывает физическую реализацию БД и предназначен для достижения оптимальной производительности и обеспечения экономного использования дискового пространства.
Он содержит описание структур данных и организации отдельных файлов, используемых для хранения данных в ЗУ. На этом уровне осуществляется взаимодействие СУБД с методами доступа ОС с целью размещения данных на запоминающих устройствах, извлечения данных и т.д.
На внутреннем уровне хранится следующая информация: сведения о распределении дискового пространства для хранения данных и индексов; описание подробностей сохранения записей (с указанием реальных размеров сохраняемых элементов данных); сведения о размещении записей; сведения о сжатии данных и выбранных методах их шифрования.
Схемы, отображения и экземпляры.
Общее описание БД называется ее схемой. Существует три типа схем, определямым в соответствии с трехуровневой архитектурой. На верхнем уровне имеются внешние схемы (подсхемы), соответствующие разным представлениям данных. На концептуальном уровне описание БД называют концептуальной схемой, на нижнем уровне — внутренней схемой (след. слайд).
Концептуальная схема описывает все элементы данных и связи между ними, с указанием необходимых ограничений поддержки целостности данных. Для каждой БД - только одна концептуальная схема. На нижнем уровне находится внутренняя схема, которая является полным описанием внутренней МД. Она содержит определения хранимых записей, методы представления, описания полей данных, сведения об индексах и выбранных схемах хеширования. Для каждой БД - только одна внутренняя схема.
СУБД отвечает за установление соответствия между этими схемами, а также за проверку их непротиворечивости. Для установления соответствия между любыми внешней и внутренней схемами СУБД должна использовать информацию из концептуальной схемы. Концептуальная схема связана с внутренней посредством отображения “концептуальный - внутренний”. Оно позволяет СУБД найти фактическую запись или набор записей на физическом устройстве хранения, которые образуют логическую запись в концептуальной схеме, с учетом любых ограничений, установленных для выполняемых над данной логической записью операций. Оно также позволяет обнаружить любые различия в именах объектов, именах атрибутов, порядке следования атрибутов, их типах данных и т.д. Каждая внешняя схема связана с концептуальной с помощью отображения “внешний - концептуальный”. С его помощью СУБД может отображать имена пользовательского представления на соответствующую часть концептуальной схемы.
Схема (описание БД) создается в процессе проектирования БД и изменяется редко. Содержащаяся в БД информация может меняться часто — например, всякий раз при вставке сведений о том или ином объекте. Совокупность информации, хранящейся в БД в любой момент времени, называется состоянием БД.
Независимость от данных в трехуровневой архитектуре ANSI-SPARC
Независимость от данных.
Основным назначением трехуровневой архитектуры является обеспечение независимости от данных, которая означает, что изменения на нижних уровнях никак не влияют на верхние уровни. Различают два типа независимости от данных: логическую и физическую.
Логическая независимость от данных означает полную защищенность внешних схем от изменений, вносимых в концептуальную схему. Такие изменения концептуальной схемы, как добавление или удаление новых сущностей, атрибутов или связей, должны осуществляться без внесения изменений в уже существующие внешние схемы или переписывания прикладных программ.
Физическая независимость от данных означает защищенность концептуальной схемы от изменений, вносимых во внутреннюю схему. Такие изменения внутренней схемы, как использование различных файловых систем или структур хранения, разных устройств хранения, модификация индексов или хеширование, должны осуществляться без необходимости внесения изменений в концептуальную или внешнюю схемы. Пользователем могут быть замечены изменения только в общей производительности системы. Принятое в архитектуре ANSI-SPARC двухэтапное отображение может сказываться на эффективности работы, но при этом оно обеспечивает высокую независимость от данных.
Языки баз данных.
Внутренний язык СУБД для работы с данными состоит из двух частей: языка определения данных DDL и языка управления данными DML.
DDL используется для определения схемы БД, а DML — для чтения и обновления данных, хранимых в базе.
Эти языки называются подъязыками данных, поскольку в них отсутствуют конструкции для выполнения всех вычислительных операций, обычно используемых в языках программирования высокого уровня.
Во многих СУБД предусмотрена возможность внедрения операторов подъязыка данных в программы, написанные на таких языках высокого уровня, как COBOL, Fortran, Pascal, Ada или С. В этом случае язык высокого уровня принято называть базовым языком (host language). Помимо механизма внедрения, для большинства подъязыков данных также предоставляются средства интерактивного выполнения их операторов, вводимых пользователем непосредственно со своего терминала.
Языки баз данных.
DDL используется как для определения новой схемы, так и для модификации уже существующей. Этот язык нельзя использовать для управления данными. Результатом компиляции DDL-операторов является набор таблиц, хранимый в системном каталоге. В системном каталоге интегрированы метаданные — т.е. данные, которые описывают объекты БД, а также позволяют упростить способ доступа к ним и управления ими.
Метаданные включают определения записей, элементов данных, а также другие объекты, представляющие интерес для пользователей или необходимые для работы СУБД. Перед доступом к реальным данным СУБД обычно обращается к системному каталогу. Для обозначения системного каталога также используются термины словарь данных и каталог данных.
Языки баз данных.
DML - язык, содержащий набор операторов для поддержки основных операций манипулирования содержащимися в базе данными. К операциям управления данными относятся : вставка в БД новых сведений; модификация сведений, хранимых в БД; извлечение сведений, содержащихся в БД; удаление сведений из БД.
Т.о., одна из основных функций СУБД заключается в поддержке языка манипулирования данными, с помощью которого пользователь может создавать выражения для выполнения перечисленных выше операций с данными. Понятие манипулирования данными применимо как к внешнему и концептуальному уровням, так и к внутреннему уровню.
DML отличаются базовыми конструкциями извлечения данных. Следует различать два типа языков DML: процедурный и непроцедурный. Основное отличие между ними заключается в том, что процедурные языки указывают , как можно получить результат оператора DML, тогда как непроцедурные языки описывают , какой результат будет получен. Как правило, в процедурных языках записи рассматриваются по отдельности, тогда как непроцедурные языки оперируют с целыми наборами записей.
Языки баз данных.
С помощью процедурного DML пользователь (программист), указывает на то, какие данные ему необходимы и как их можно получить. Это значит, что пользователь должен определить все операции доступа к данным (осуществляемые посредством вызова соответствующих процедур), которые должны быть выполнены для получения требуемой информации. Обычно такой DML позволяет извлечь запись, обработать ее и, в зависимости от полученных результатов, извлечь другую запись, которая должна быть подвергнута аналогичной обработке, и т.д. Подобный процесс извлечения данных продолжается до тех пор, пока не будут извлечены все запрашиваемые данные. Языки DML сетевых и иерархических СУБД обычно являются процедурными
Непроцедурные DML позволяют определить весь набор требуемых данных с помощью одного оператора извлечения или обновления. С помощью таких DML пользователь указывает, какие данные ему нужны, без определения способа их получения. СУБД транслирует выражение на DML в процедуру (или набор процедур), которая обеспечивает манипулирование затребованным набором записей. Данный подход освобождает пользователя от необходимости знать детали внутренней реализации структур данных и особенности алгоритмов, используемых для извлечения и возможного преобразования данных. Непроцедурные языки часто также называют декларативными языками. Реляционные СУБД обычно включают поддержку непроцедурных языков манипулирования данными — чаще всего это язык структурированных запросов SQL (Structured Query Language) или язык запросов по образцу QBE (Query-by-Example). Часть непроцедурного DML, которая отвечает за извлечение данных, называется языком запросов.
Языки баз данных.
Языки 4GL - Fourth-Generation Language. Если для организации некоторой операции с данными на языке третьего поколения (3GL) типа COBOL потребуется написать сотни строк кода, то для реализации этой же операции на языке 4-го поколения достаточно нескольких строк (Языки третьего поколения - процедурные, 4GL – непроцедурные, реализованы в виде «инструментов четвертого поколения» ). Пользователю не требуется определять все этапы выполнения программы, а достаточно лишь определить нужные параметры, на основании которых данные инструменты автоматически осуществят генерацию приложения.
Типы 4GL:
• языки представления информации, например языки запросов или генераторы отчетов;
• специализированные языки, например языки электронных таблиц и БД;
• генераторы приложений, которые при создании приложений обеспечивают определение, вставку, обновление или извлечение сведений из БД;
• языки очень высокого уровня, предназначенные для генерации кода приложений.
Примеры языков четвертого поколения - SQL и QBE.
Языки баз данных. 4GL (продолжение).
Генератор форм - интерактивный инструмент, предназначенный для быстрого создания шаблонов ввода и отображения данных в экранных формах. Позволяет пользователю определить внешний вид экранной формы, ее содержимое и место расположения на экране. Позволяют создавать вычисляемые атрибуты с использованием арифметических операторов или обобщающих функций, а также задавать правила проверки вводимых данных.
Генератор отчетов - инструмент создания отчетов на основе хранимой в БД информации. Пользователю предоставляются средства создания запросов к БД и извлечения из нее информации, используемой для отчетов. Генератор отчета позволяет либо автоматически определять вид получаемых результатов, либо с помощью специальных команд создавать свой собственный вариант внешнего вида документа. Два основных типа генераторов отчетов: языковой и визуальный. В первом случае для определения нужных для отчета данных и внешнего вида документа вводят команды на некотором подъязыке. Во втором случае для этих целей используется визуальный инструмент, подобный генератору форм.
Генератор графического представления данных - инструмент, предназначенный для извлечения информации из БД и отображения ее в виде диаграмм с графическим. Обычно с помощью подобного генератора создаются гистограммы, круговые, линейчатые, точечные диаграммы и т.д.
Генератор приложений - инструмент для создания программ, взаимодействующих с БД. Пользователь указывает, какие задачи программа должна выполнить, а генератор приложений определяет, как их следует выполнить.
Модели данных и концептуальное моделирование
Упоминалось, что схема создается с помощью некоторого языка определения данных. Это - язык определения данных конкретной целевой СУБД, являющийся языком, с помощью которого трудно описать требования к данным так, чтобы созданная схема была доступна пониманию пользователей разных категорий. Чтобы достичь такого понимания, требуется составить описание схемы на некотором, более высоком уровне, которое будем называть моделью данных. При этом под моделью данных (МД) мы будем понимать интегрированный набор понятий для описания данных, связей между ними и ограничений, накладываемых на данные в пределах некоторой предметной области.
Модель является представлением объектов и событий предметной области, а также существующих между ними связей. Модель данных можно рассматривать как сочетание трех указанных ниже компонентов.
• Структурная часть, т.е. набор правил, по которым может быть построена БД.
• Управляющая часть, определяющая типы допустимых операций с данными (сюда относятся операции обновления и извлечения данных, а также операции изменения структуры БД).
• Набор ограничений поддержки целостности данных.
Для отображения архитектуры ANSI-SPARC можно определить следующие три связанные МД:
• внешнюю МД, отображающую представления каждого существующего в организации типа пользователей;
• концептуальную МД, отображающую логическое (или обобщенное) представление о данных, независимое от типа выбранной СУБД;
• внутреннюю МД, отображающую концептуальную схему определенным образом, понятным выбранной целевой СУБД.
В литературе предложено и опубликовано достаточно много МД. Они подразделяются на три категории: объектные (object-based), МД на основе записей (record-based) и физические МД. Первые две - для описания данных на концептуальном и внешнем уровнях, последняя — на внутреннем уровне.
Объектные модели данных.
При построении объектных моделей данных используются такие понятия как сущности, атрибуты и связи. Сущность — отдельный элемент (сотрудник, изделие, понятие или событие) предметной области, который должен быть представлен в БД. Атрибут — свойство, которое описывает некоторый аспект объекта и значение которого следует зафиксировать, а связь является ассоциативным отношением между сущностями.
Наиболее общие типы объектно-ориентированных МД:
•Модель типа "сущность-связь", или ER-модель (Entity-Relationship model).
• Семантическая модель.
• Функциональная модель.
• Объектная модель.
В настоящее время ER-модель стала одним из основных методов концептуального проектирования БД. Объектная модель расширяет определение сущности с целью включения в него не только атрибутов, которые описывают состояние объекта, но и действий, которые с ним связаны, т.е. его поведение.
Модели данных на основе записей.
В модели на основе записей БД состоит из нескольких записей фиксированного формата, которые могут иметь разные типы. Каждый тип записи определяет фиксированное количество полей, каждое из которых имеет фиксированную длину. Существует три основных типа логических МД на основе записей: реляционная модель данных (relational data model), сетевая модель данных (network data model) и иерархическая модель данных (hierarchical data model).
Реляционная модель данных.
Реляционная модель данных основана на понятии математических отношений. В реляционной модели данные и связи представлены в виде таблиц, каждая из которых имеет несколько столбцов с уникальными именами. При этом в реляционной модели данных единственное требование состоит в том, чтобы БД с точки зрения пользователя выглядела как набор таблиц.
Однако такое восприятие относится только к логической структуре базы данных, т.е. к внешнему и концептуальному уровням архитектуры ANSI/SPARC. Оно не относится к физической структуре БД, которая может быть реализована с помощью разнообразных структур хранения.
Сетевая модель данных.
В сетевой модели данные представлены в виде коллекций записей, а связи — в виде наборов указателей.
Сетевую модель можно представить как граф с записями в виде узлов графа и наборами в виде его ребер.
Иерархическая модель данных.
Иерархическая модель является ограниченным подтипом сетевой модели. В ней данные также представлены как коллекции записей, а связи — как наборы. Однако в иерархической модели узел может иметь только одного родителя. Иерархическая модель может быть представлена как древовидный граф с записями в виде узлов и связями в виде ребер (дуг).
Самый верхний узел называется корневым узлом. В структуре дерева могут быть выделены поддеревья, каждое из которых исходит из одного родительского узла ( дочернего для узла более высокого уровня).
Все узлы дерева, за исключением корневого, должны иметь родительский узел. Узлы представляют интересующие нас объекты, а связи между ними определяются самим расположением узлов и ребер, образующих данную древовидную структуру.
Физические модели данных.
Физические модели данных описывают то, как данные хранятся в компьютере, представляя информацию о структуре записей, их упорядоченности и существующих путях доступа.
Концептуальное моделирование.
Концептуальная схема является "сердцем" БД. Она поддерживает все внешние представления, а сама поддерживается средствами внутренней схемы. Однако внутренняя схема является всего лишь физическим воплощением концептуальной схемы.
Именно концептуальная схема призвана быть полным и точным представлением требований к данным в рамках некоторой предметной области. В противном случае определенная часть информации о предприятии будет упущена или искажена, в результате чего могут возникнуть трудности при попытках полной реализации одного или нескольких внешних представлений.
Концептуальное моделирование БД - это процесс конструирования модели использования информации. Этот процесс не зависит от таких подробностей, как используемая СУБД, прикладные программы, языки программирования или любые другие вопросы физической организации информации.
Подобная модель называется концептуальной моделью данных.
Функции СУБД
Далее мы рассмотрим типы функций и служб (сервисов), которые должна обеспечивать типичная СУБД. В свое время Кодд предложил перечень из восьми сервисов, которые должны быть реализованы в любой полномасштабной СУБД (Codd, 1982). Ниже приводится краткое описание каждого из них
Хранение, извлечение и обновление данных. СУБД должна предоставлять пользователям возможность сохранять, извлекать и обновлять данные в БД. Это самая фундаментальная функция СУБД. Из предыдущего ясно, что способ реализации этой функции в СУБД должен позволять скрывать от конечного пользователя внутренние детали физической реализации системы (например, файловую организацию или используемые структуры хранения).
Каталог, доступный конечным пользователям. СУБД должна иметь доступный конечным пользователям и функциям СУБД каталог, в котором хранится описание элементов данных. Системный каталог, или словарь данных, является хранилищем информации, описывающей данные в БД (это - метаданные). Обычно в системном каталоге хранятся следующие сведения:
• имена, типы и размеры элементов данных;
• имена связей;
• накладываемые на данные ограничения поддержки целостности;
• имена санкционированных пользователей, которым предоставлено право доступа к данным;
• внешняя, концептуальная и внутренняя схемы и отображения между ними;
• статистические данные, например частота транзакций и счетчики обращений к объектам БД.
Системный каталог позволяет достичь преимуществ, перечисленных ниже.
• Информация о данных может быть централизованно собрана и сохранена, что позволит контролировать доступ к этим данным, как и к любому другому ресурсу.
• Благодаря централизованному хранению избыточность и противоречивость описания отдельных элементов данных могут быть легко обнаружены.
• Внесенные в БД изменения могут быть запротоколированы.
• Последствия любых изменений могут быть определены еще до их внесения, поскольку в системном каталоге зафиксированы все существующие элементы данных, установленные между ними связи, а также все их пользователи.
• Меры обеспечения безопасности могут быть дополнительно усилены.
• Появляются новые возможности организации поддержки целостности данных.
• Может выполняться аудит сохраняемой информации.
Поддержка транзакций. СУБД должна иметь механизм, который гарантирует выполнение либо всех операций обновления данной транзакции, либо ни одной из них. Транзакция представляет собой набор действий, выполняемых отдельным пользователем или прикладной программой с целью доступа или изменения содержимого базы данных. Примерами простых транзакций может служить добавление в базу данных, удаление из нее или обновление сведений о том или ином объекте.
Если во время выполнения транзакции произойдет сбой, БД попадает в противоречивое состояние, поскольку некоторые изменения уже будут внесены, а остальные — еще нет. Поэтому все частичные изменения должны быть отменены для возвращения БД в прежнее, непротиворечивое состояние.
Сервисы управления параллельностью. СУБД должна иметь механизм, который гарантирует корректное обновление БД при параллельном выполнении операций обновления многими пользователями.
При этом параллельный доступ сравнительно просто организовать, если все пользователи выполняют только чтение данных, поскольку в этом случае они не могут помешать друг другу. Конфликт с нежелательными последствиями легко может возникнуть, например, если хотя бы один из них попытается обновить данные.
СУБД должна гарантировать, что при одновременном доступе к БД многих пользователей подобных конфликтов не произойдет.
Сервисы восстановления. При обсуждении поддержки транзакций упоминалось, что при сбое транзакции база данных должна быть возвращена в непротиворечивое состояние,что должно гарантироваться возможностями СУБД.
Сервисы контроля доступа к данным. СУБД должна иметь механизм, гарантирующий возможность доступа к БД только санкционированных пользователей. Термин “безопасность" относится к защите БД от преднамеренного или случайного несанкционированного доступа. Предполагается, что СУБД обеспечивает механизмы подобной защиты данных.
Поддержка обмена данными. СУБД должна обладать способностью к интеграции с коммуникационным ПО с целью организации доступа удаленных пользователей к централизованной БД (в рамках системы распределенной обработки).
Службы поддержки целостности данных. СУБД должна обладать инструментами контроля за тем, чтобы данные и их изменения соответствовали заданным правилам.
Целостность БД означает корректность и непротиворечивость хранимых данных и выражается в виде ограничений или правил сохранения непротиворечивости данных, которые не должны нарушаться в базе.
Помимо перечисленных возможностей, часто к СУБД предъявляются требования поддержки еще двух сервисов, охарактеризованных ниже.
Службы поддержки независимости от данных. СУБД должна обладать инструментами поддержки независимости программ от структуры БД.
Понятие независимости от данных рассматривалось выше. Обычно она достигается за счет реализации механизма поддержки представлений или подсхем.
Вспомогательные службы. СУБД должна предоставлять некоторый набор различных вспомогательных служб. Вспомогательные утилиты обычно предназначены для оказания помощи АБД в эффективном администрировании базы данных. Одни утилиты работают на внешнем уровне, а потому они, в принципе, могут быть созданы самим АБД, тогда как другие функционируют на внутреннем уровне системы и потому должны быть предоставлены самим разработчиком СУБД. Ниже приводятся некоторые примеры подобных утилит.
• Утилиты импортирования, предназначенные для загрузки базы данных из плоских файлов, а также утилиты экспортирования, которые служат для выгрузки базы данных в плоские файлы.
• Средства мониторинга, предназначенные для отслеживания характеристик функционирования и использования базы данных.
• Программы статистического анализа, позволяющие оценить производительность или степень использования базы данных.
• Инструменты реорганизации индексов, предназначенные для перестройки индексов и обработки случаев их переполнения.
• Инструменты сборки мусора и перераспределения памяти для физического устранения удаленных записей с запоминающих устройств, объединения освобожденного пространства и перераспределения памяти в случае необходимости
Архитектура многопользовательских СУБД
Рассмотрим кратко различные типовые архитектурные решения, используемые при реализации многопользовательских СУБД, а именно: с телеобработкой, файл- серверными и клиент-серверными системами.
Телеобработка .
Традиционной архитектурой многопользовательских систем является схема, получившая название "телеобработки", при которой один компьютер соединен с несколькими "неинтеллектуальными" терминалами так, как показано на след. слайде.
С терминалов посылаются сообщения пользовательским приложениям, в свою очередь, приложения обращаются к необходимым службам СУБД. Таким же образом сообщения возвращаются назад на пользовательский терминал.
При такой архитектуре вся нагрузка возлагается на центральный компьютер, который должен выполнять не только действия прикладных программ и СУБД, но и значительную работу по обслуживанию терминалов (например, форматирование данных, выводимых на экраны терминалов)
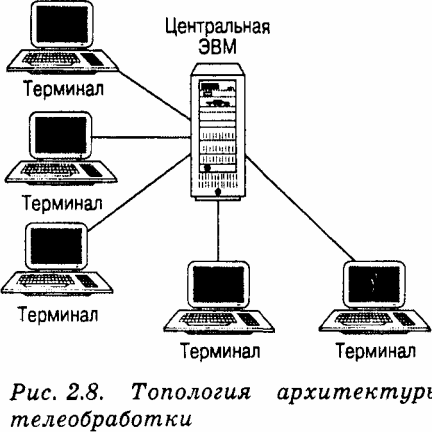
Файл – серверные системы.
Системы данного типа функционируют в рамках ЛВС, управляемых ОС соответствующего типа. При этом файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД. Однако пользовательские приложения и сама СУБД размещены и функционируют на отдельных рабочих станциях, и обращаются к файловому серверу только по мере необходимости получения доступа к нужным им файлами — как показано на след. слайде. Таким образом, файловый сервер функционирует просто как совместно используемый жесткий диск.
Очевидно, что архитектура с использованием файлового сервера обладает следующими основными недостатками:
- Большой объем сетевого трафика.
- На каждой рабочей станции должна находиться полная копия СУБД.
- Управление параллельностью, восстановлением и целостностью усложняется, поскольку доступ к одним и тем же файлам могут осуществлять сразу несколько экземпляров СУБД.
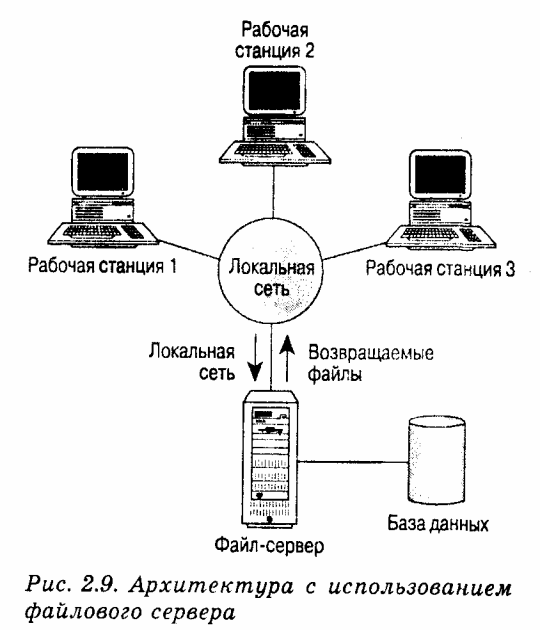
Клиент-серверные системы.
При данном подходе предполагается существование клиентского процесса, требующего определенных ресурсов, а также серверного процесса, который эти ресурсы предоставляет. При этом совсем необязательно, чтобы они находились на одном и том же компьютере. На практике системы данного типа реализуются в рамках информационно-вычислительных сетей (не обязательно ЛВС) под управлением клиент-серверных ОС (след. слайд).
Клиентская часть управляет пользовательским интерфейсом и логикой приложения, действуя как интеллектуальная рабочая станция, на которой выполняются приложения БД. Клиент принимает от пользователя запрос, проверяет синтаксис и генерирует запрос к базе данных на SQL или другом языке БД. Затем он передает сообщение серверу, ожидает поступления ответа и форматирует полученные данные для представления их пользователю. Сервер принимает и обрабатывает запросы к БД, а затем передает полученные результаты обратно клиенту. Такая обработка включает проверку полномочий клиента, обеспечение требований целостности, поддержку системного каталога, а также выполнение запроса и обновление данных. Помимо этого, поддерживается управление параллельностью и восстановлением.
Выполняемые клиентом и сервером операции:
Клиент: Управляет пользовательским интерфейсом; Принимает и проверяет синтаксис введенного пользователем запроса; Выполняет приложение; Генерирует запрос к БД и передает его серверу; Отображает полученные данные пользователю.
Сервер: Принимает и обрабатывает запросы к БД со стороны клиентов; Проверяет полномочия пользователей; Гарантирует соблюдение ограничений целостности; Выполняет запросы / обновления и возвращает результаты клиенту; Поддерживает системный каталог; Обеспечивает параллельный доступ к БД; Обеспечивает управление восстановлением.
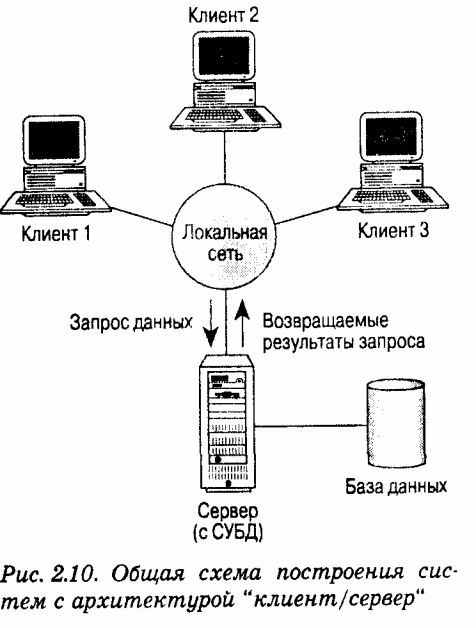
Этот тип архитектуры обладает преимуществами:
- Обеспечивается более широкий доступ к существующим БД.
- Повышается общая производительность системы:клиенты и сервер находятся на разных компьютерах, их процессоры способны выполнять приложения параллельно.
- Стоимость аппаратного обеспечения снижается. Мощный компьютер с большой дисковой памятью нужен только серверу — для хранения и управления БД.
- Сокращаются коммуникационные расходы. Приложения выполняют часть операций на клиентских компьютерах и посылают через сеть только запросы к БД, что позволяет существенно сократить объем пересылаемых по сети данных.
- Повышается уровень непротиворечивости данных. Сервер может самостоятельно управлять проверкой целостности данных, поскольку все ограничения определяются и проверяются только в одном месте.
- Эта архитектура хорошо согласуется с архитектурой открытых систем.
- Данная архитектура может быть использована для организации средств работы с распределенными БД, т.е. с набором нескольких БД, логически связанных и распределенных в сети.
Данная архитектура рассматривается обычно в трехуровневом варианте, при котором функциональная часть прежнего, толстого (интеллектуального) клиента разделяется на две части. В трехуровневой архитектуре тонкий (неинтеллектуальный) клиент на рабочей станции управляет только пользовательским интерфейсом, тогда как средний уровень обработки данных управляет всей остальной логикой приложения. Третьим уровнем здесь является сepвep БД. Эта трехуровневая архитектура оказалась более подходящей для Internet и intranet, где в качестве клиента может использоваться обычный Web-броузер.
Выводы.
СУБД является базовой структурой ИС, в корне изменившей методы работы многих организаций.
Предшественницей СУБД была файловая система, при работе с которой каждая программа определяла и управляла своими собственными данными. Имели место избыточность данных и зависимость программ от данных.
Появление СУБД было вызвано необходимостью разрешить проблемы, характерные для файловых систем. БД — это совместно используемый набор логически связанных данных (и описание этих данных), который предназначен для удовлетворения информационных потребностей организации. СУБД — это ПО, которое позволяет пользователям определять, создавать и обслуживать БД, а также управлять доступом к ней.
Доступ к БД осуществляется с помощью СУБД. В СУБД предусмотрен язык определения данных DDL, с помощью которого пользователи могут определять структуру БД, а также язык управления данными DML, с помощью которого пользователи могут вставлять, удалять и извлекать данные из базы.
СУБД позволяет организовать контроль за доступом пользователей к БД. Она предоставляет средства поддержки безопасности и целостности данных, обеспечивает параллельную работу приложений, средства копирования/восстановления, а также позволяет организовать доступный пользователям каталог. В типичной СУБД также предусмотрен механизм создания представлений, предназначенных для упрощения вида данных, с которыми имеют дело пользователи.
Среда СУБД состоит из аппаратного обеспечения (компьютеров), программного обеспечения (СУБД, ОС и приложений), данных, процедур и пользователей. К пользователям относятся АД и АБД, проектировщики БД, прикладные программисты и конечные пользователи.
Иерархические и CODASYL-системы представляют собой первое поколение СУБД. Типичным представителем иерархической модели является IMS (Information Management System), a сетевой (CODASYL-модели) — IDS (Integrated Data System). Обе появились в середине 60-х годов. Реляционная модель, впервые предложенная Э. Ф. Коддом в 1970 году, - основа второго поколения СУБД. В настоящее время существует более 100 различных типов реляционных СУБД.
Третье поколение СУБД представляют объектно-реляционные и объектно-ориентированные СУБД. В СССР в середине 70-х годов была разработана универсальная СУБД, которую с точки зрения сегодняшнего дня можно отнести к системам третьего поколения
Среди преимуществ подхода, основанного на использовании БД, следует отметить контролируемую избыточность, непротиворечивость, совместное использование, повышенную безопасность и целостность данных.
Среди недостатков можно указать сложность, высокую стоимость и снижение производительности приложений, а также возможность серьезных последствий при выходе системы из строя.
В архитектуре ANSI-SPARC используются три уровня абстракции: внешний, концептуальный и внутренний. Внешний уровень состоит из пользовательских представлений БД. Концептуальный уровень является обобщенным представлением о структуре БД. Он определяет информационное содержимое БД, не зависящее от способа хранения информации. Внутренний уровень является компьютерным представлением БД. Он определяет, как представлены данные, в какой последовательности располагаются записи, какие созданы индексы и указатели, используется ли схема хеширования и какая именно.
• Внешне - концептуальное отображение преобразует запросы и результаты их выполнения между внешним и концептуальным уровнями описания структуры БД. Концептуально - внутреннее отображение преобразует запросы и результаты их выполнения между концептуальным и внутренним уровнями описания структуры данных.
• Схема БД — это описание ее структуры. Независимость от данных позволяет каждому уровню существовать независимо от изменении, происходящих на более низких уровнях. Логическая независимость от данных обозначает защищенность внешних схем по отношение к изменениям концептуальной схемы, а физическая независимость от данных — защищенность концептуальной схемы по отношению к изменениям внутренней схемы.
• Подъязык данных состоит из двух частей: языка определения данных DDL (Data Definition Language) и языка управления данными DML (Data Manipulation Language). Язык DDL используется для описания структуры БД, а язык DML — для чтения и обновления самой БД.
Модель данных — это набор понятий, которые могут быть использованы для описания множества данных, операций с данными, а также набора ограничений целостности данных. Их можно разбить на три широкие категории: объектные модели данных, модели данных на основе записей и физические модели данных. Первые две модели используются для описания данных на концептуальном и внешнем уровнях, а последняя — на внутреннем уровне. К объектным моделям данных относятся: модель "сущность-связь", семантическая, функциональная и объектно-ориентированная модели, а к моделям данных на основе записей — реляционная, сетевая и иерархическая модели. Концептуальное моделирование — это процесс определения архитектуры БД, не зависящей от таких подробностей ее реализации, как целевая СУБД, набор прикладных программ, используемые языки программирования или любые другие физические аспекты БД.
Понятие архитектуры "клиент/сервер" обозначает способ взаимодействия программных компонентов (клиента и сервера), при котором клиентский процесс требует получения некоторого ресурса, а сервер его предоставляет. Обычно, клиент управляет пользовательским интерфейсом, а сервер — функциональной частью БД.
Системный каталог является одним из фундаментальных компонентов СУБД. Он содержит "данные о данных", или метаданные. Каталог должен быть доступен пользователям. Служба IRDS (Information Resource Dictionary System) — это новый стандарт ISO, который определяет методы доступа к словарю данных. При этом допускается их совместное использование и передача из одной системы в другую.