

Распределение пространства на физических носителях
Кроме определения структуры базы данных, разработчик должен выделить место для базы данных на физическом носителе. И вновь конкретные действия зависят от того, какая именно СУБД используется. В случае персональной базы данных псе, что требуется сделать, — это присвоить базе данных каталог на диске и дать ей имя. После этого СУБД автоматически выделит пространство для хранения данных.
Другие СУБД, в особенности предназначенные для серверов и больших ЭВМ, требуют больших усилий. Чтобы повысить быстродействие и улучшить контроль, необходимо тщательно спроектировать распределение информации в базе данных по дискам и каналам. Например, в зависимости от специфики обработки приложений, может оказаться, что определенные таблицы лучше размещать на одном и том же диске. И наоборот, может быть важно, чтобы определенные таблицы не находились на одном и том же диске.
Рассмотрим, например, объект-заказ, скомпонованный из таблиц ЗАКАЗ, СТР0КА_ ЗАКАЗА и ТОВАР. Предположим, что при обработке заказа приложение считывает одну строку из таблицы ЗАКАЗ, несколько строк из таблицы СТР0КА_ЗАКАЗА и по одной строке из таблицы ТОВАР для каждой строки из таблицы СТР0КА_ЗАКАЗА. Далее, строки из таблицы СТР0КА_ЗАКАЗА, относящиеся к одному и тому же заказу, обычно сгруппированы вместе, а строки в таблице ТОВАР не сгруппированы никак. Эту ситуацию иллюстрирует рис. 3.
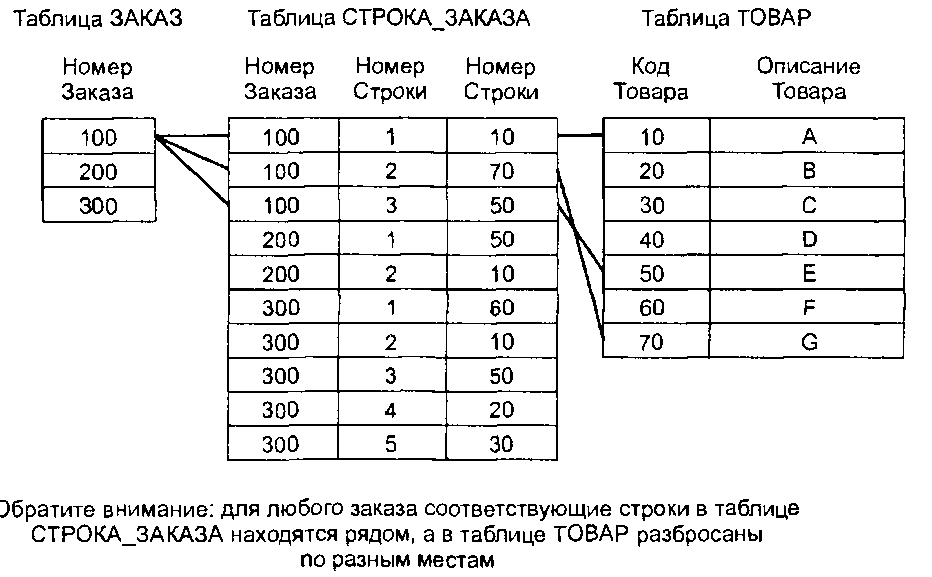
Рис.3. Данные для 3-х таблиц, представляющих заказ.
Теперь представим, что организация параллельно обрабатывает множество заказов и что у нее есть два диска: один большого объема и быстродействующий, а другой — меньшего объема и более медленный. Разработчик должен определить наилучшее место для хранения данных. Возможно, производительность улучшится, если таблица ТОВАР будет храниться на большом диске с быстрым доступом, а таблицы СТРОКА_ЗАКАЗА и ЗАКАЗ — на диске меньшего размера и быстродействия. А может быть, производительность будет выше, если поместить данные из таблиц ЗАКАЗ и СТРОКА_ЗАКАЗА за предыдущие месяцы на более медленный диск, а за текущий месяц — на более быстрый.
Мы не можем ответить на эти вопросы здесь, поскольку ответ зависит от объема данных, характеристик СУБД и операционной системы, размера и быстродействия дисков и каналов, а также от требований приложений, использующих эту базу данных. Смысл состоит в том, что все эти факторы необходимо принимать во внимание при выделении пространства для базы данных на физическом носителе.
Кроме местоположения и объема пространства для данных пользователя, разработчику, возможно, потребуется также указать, должно ли это пространство увеличиваться по мере необходимости, и если да, то на какую величину. Как правило, величина такого приращения указывается либо в виде фиксированного значения, либо в виде процентов от первоначального объема занимаемого пространства.
При создании базы данных разработчику понадобится выделить файловое пространство для журналов базы данных. Следует знать, что СУБД ведет журнал изменений в базе данных, который потом, в случае необходимости, можно использовать для восстановления базы. Файловое пространство для журналов выделяется на этапе создания базы данных.
Составление плана обслуживания базы данных
План обслуживания (maintenance plan) базы данных — это расписание процедур, которые необходимо выполнять на регулярной основе. Эти процедуры включают в себя резервное копирование базы данных, сброс содержимого журнала базы данных в архивные файлы, проверка на наличие нарушений ссылочной целостности, оптимизация дискового пространства для данных пользователя и индексов и т. д. К этим вопросам мы также обратимся в главе 11, но имейте в виду, что план обслуживания базы данных должен составляться в процессе ее создания или вскоре после него.
Заполнение базы данных информацией
Когда база данных описана и для ее хранения выделено пространство на физическом носителе, можно начинать заполнение базы данных информацией. То, каким путем это делается, зависит от требования приложений и возможностей СУБД. В лучшем случае все данные уже находятся в формате, воспринимаемом компьютером, а в СУБД имеются возможности и средства, позволяющие упростить импорт данных с магнитных носителей. В худшем случае все данные должны вводиться вручную через клавиатуру с помощью прикладных программ, созданных разработчиками «с нуля». Большинство ситуаций, где необходимо конвертирование данных, находятся в промежутке между этими двумя крайними случаями.
Когда данные введены, необходимо проверить их корректность. Такая проверка утомительна и требует больших трудозатрат, однако она весьма важна. Зачастую, особенно в больших базах данных, есть смысл в написании специальных программ для проверки данных. Преимущества от использования этих программ вполне окупят время и деньги, затраченные командой разработчиков на их создание. Такие программы занимаются тем, что подсчитывают количество строк в различных категориях, вычисляют контрольные суммы, выполняют проверки допустимости значений данных и другие процедуры контроля.
Манипулирование реляционными данными
Мы обсудили проектирование реляционных баз данных и способы, при помощи которых структура базы данных описывается для СУБД. До сих пор, говоря об операциях с отношениями, мы рассуждали в обобщенной и интуитивной манере. Такая манера хороша, пока речь идет о проекте, но для реализации приложений нам нужен четкий и непротиворечивый язык, выражающий логику обработки. Такие языки носят название языков манипулирования данными (data manipulation languages, DML).
Категории языков манипулирования реляционными данными
На сегодняшний день предложено четыре стратегии манипулирования реляционными данными. Первая из стратегий, реляционная алгебра (relational algebra), определяет операторы, действующие на отношения (они подобны операторам высшей алгебры +, — и т. д.). Эти операторы позволяют манипулировать отношениями для достижения желаемого результата. Но реляционная алгебра трудна в использовании, отчасти потому, что она является процедурной. Это значит, что при использовании реляционной алгебры мы должны знать не только то, что мы делаем, но и то, как это делается.
Реляционная алгебра не используется в коммерческих системах обработки баз данных. Хотя ни одна коммерчески успешная СУБД не включает в себя инструментарий реляционной алгебры, мы будем обсуждать ее здесь, поскольку это поможет яснее представить себе манипулирование реляционными данными и заложит основу для изучения SQL.
Реляционное исчисление (relational calculus) — вторая стратегия манипулирования реляционными данными. Реляционное исчисление не является процедурным; оно представляет собой язык, выражающий то, что мы хотим сделать, без указания на то, как этого достичь. Вспомните переменную интегрирования в интегральном исчислении: эта переменная принимает значения из того диапазона, по которому происходит интегрирование. В реляционном исчислении есть подобная переменная. В кортежио-реляционном исчислении областью значений этой переменной являются кортежи отношения, а в доменно-реляционном исчислении — значения домена. В основе реляционного исчисления лежит область математики, называемая исчислением предикатов.
Если вы не собираетесь становиться теоретиком реляционной технологии, вам, скорее всего, не понадобится изучать реляционное исчисление. Оно никогда не используется в коммерческих системах обработки баз данных, и в его изучении для наших целей нет необходимости. Таким образом, мы не будем обсуждать его в этой книге.
Хотя реляционное исчисление трудно для понимания и использования, его непроцедурный характер является преимуществом. Поэтому разработчики СУБД начали поиск других непроцедурных стратегий, который привел к появлению третьей и четвертой категорий языков манипулирования реляционными данными.
Языки, ориентированные на преобразования (transform-oriented languages), — это класс непроцедурных языков, которые преобразуют входные данные, имеющие вид отношений, в результат, представляющий собой одно отношение. В этих языках имеются простые в использовании структуры, позволяющие указать действия, которые необходимо совершить с предоставленными данными. SQUARE, SEQUEL и SQL — это примеры языков, ориентированных на преобразования.
Четвертая категория языков манипулирования реляционными данными — это графические языки. К этой категории относятся запрос по образцу (Query-by-Example) и запрос из формы (Query-by-Form). В числе продуктов, поддерживающих эту категорию, можно упомянуть Approach (фирмы Lotus) и Access. Пользователю выдается графическое представление одного отношения или более. Представление может иметь вид формы для ввода данных, электронной таблицы или какой-либо другой структуры. СУБД преобразует представление в соответствующее отношение и формирует запросы (скорее всего, на SQL) от лица пользователя. После этого пользователи инициируют выполнение операторов DML, по они об этом не знают. Четыре категории языков манипулирования реляционными данными:
♦ реляционная алгебра;
♦ реляционное исчисление;
♦ языки, ориентированные на преобразования (например, SQL);
♦ запрос по образцу, запрос из формы.
Интерфейсы языков манипулирования данными
В этом разделе мы рассмотрим четыре вида интерфейсов, с помощью которых осуществляется манипулирование информацией в базе данных.
Манипулирование данными посредством форм
В большинстве реляционных СУБД имеются средства для создания форм. Некоторые формы генерируются автоматически при определении таблицы, другие должны создаваться разработчиком. Помощь в этом процессе может оказать интеллектуальный ассистент, присутствующий, например, в Access. Форма может иметь вид таблицы (электронной таблицы), в которой одновременно показываются несколько строк отношения. Есть и другой вид форм, где каждая строка отношения представляется отдельно. На рис. 4 и 5 приведены примеры обоих типов форм для таблицы PATIENT с рис. 1. Большинство продуктов обеспечивают некоторую гибкость в обработке форм и отчетов. Например, строки для обработки могут выбираться по значениям столбцов и могут быть отсортированы. Таблица па рис. 4 отсортирована по значению поля AccountNumber.
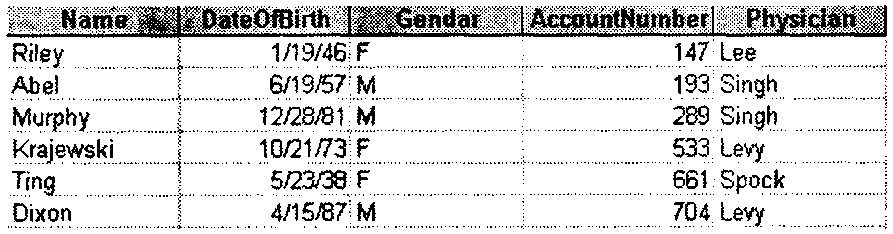
Рис.4. Пример табличной экранной формы.
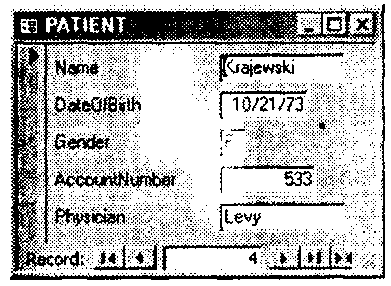
Рис.5. Пример однострочной экранной формы.
Многие формы, генерируемые по умолчанию, содержат в себе данные только из одного отношения. Если нужно получить данные из двух или более отношений, тогда, как правило, нужно создавать специальные формы с помощью средств СУБД. Такие средства позволяют создавать как многотабличные, так и многострочные формы. Поскольку использование этих средств сильно зависит от конкретной СУБД, мы не будем рассматривать их далее.