

I,j :I nteger; I - значение инф. Поля очередной
вершины, j - № уровня}
type
pstack=^element; {Опишем запись для стека. Информац.
element=record поля имеют тип ptree - дерева}
m:ptree;
next:pstack
end;
Var p,h:pstack;
procedure putstack(n:ptree);
begin
new(p);
p^.m:=n;
p^.next:=h;
h:=p
end;
procedure getstack(var n:ptree);
begin
p:=h;
n:=p^.m;
h:=p^. next;
dispose (p)
end;
begin
h:=nil; {стек в начале пуст}
j:=0;
i:=0;
new(kor); {0- уровень, -зн.верш. входим в корень!}
t:=kor;
t^.dat:=i;
t^.r:=nil;
t^.l:=nil;
inc(i);
repeat
while j<n
do begin {спуск}
new(v);
v^.dat:=i;
v^.l:=nil;
v^.l:=nil;
v^.r:=nil;
Inc(I); {создаем новый узел – вершину}
if t^.l=nil
then t^.l:=v
else t^.r:=v; {связывает его с левой или
правой ветвью узла предыдущего уровня}
putstack(t); {запомним: пока в стеке!}
t:=v;
{write (t^.dat);}
Inc(j); {переместим указатель t и переход
end; на следующий уровень}
repeat {подъем}
getstack(t);
dec(j) {взять из стека}
until (j=0) or (t^.r=nil); {либо дошли до корня,
либо не заполнена правая ветвь}
until (t=kor) and (t^.r<>nil); {дошли до корня, и правая
end. ветвь не пуста}
14.4.3. Алгоритмы работы с двоичными упорядоченными деревьями (деревьями поиска)
Двоичное дерево упорядочено (является деревом поиска), если в нём все ключи левого поддерева каждого узла меньше, чем ключ узла, а ключи правого поддерева – больше. Ключ – признак, по которому ведётся поиск – значение одного из информационных полей дерева.
П р и м е р. Необходимо создать базу данных «Рейтинг» для хранения сведений о студентах и их успеваемости. При этом программа должна обеспечивать: 1) добавление новых записей, 2) вывод отсортированной по какому-либо признаку информации (например, по алфавиту, по среднему баллу успеваемости), 3) быстрый поиск нужной записи (например, по фамилиям студентов, по номеру группы), 4) удаление записи.
type preit = ^ treit;
treit = record
fam: string [20]; {фамилия};
Ngr: integer; {№ группы};
srb: real {ср. балл}
…
l, r: preit;
end;
Для выполнения указанных задач удобно хранить информацию в виде упорядоченного двоичного дерева. При этом выбор ключа зависит от поставленной задачи. Если необходимо хранить и выводить информацию по алфавиту, а также вставлять элементы, не нарушая алфавитного порядка, то ключом будет поле fam типа string. Если информация дерева была отсортирована по среднему баллу – соответственно ключом будет поле srb типа real и т. д.
Почему в виде двоичного дерева удобнее хранить подобную информацию, чем в виде, например, связанных списков? Рассмотрим п р и м е р. Пусть необходимо построить связанный список, в котром фамилии распределены по алфавиту, при этом на вход данные поступают случайным образом. В этом случае иногда запись будет вставлена в начало списка, иногда – в конец, иногда – в середину. В среднем, до определения положения вставки новой записи придётся просматривать половину списка. Процесс поиска можно было бы ускорить, если бы вместо такого последовательного просмотра можно было сравнить новую запись с записью из середины списка. В результате такого сравнения можно решить, помещать новую запись после средней или до неё. И далее половину списка игнорировать. Этот процесс следует повторять до тех пор, пока не найдём искомую запись (при поиске) или подходящее место (при вставке).
Например, если в списке 64 записи, то такой метод потребует максимум 7 сравнений, а обычный поиск, в среднем, 32 сравнения. В идеальном случае описанную структуру можно представить в виде двоичного дерева.
Таким образом, в упорядоченных массивах можно быстро найти нужную информацию. Динамические списки можно быстро пополнять новыми элементами, используя память из кучи. Двоичные упорядоченные деревья соединяют оба этих качества и позволяют быстро осуществлять двоичный поиск информации.
Пусть записи поступали в следующем порядке: L, E, R, A, W, H, P, а необходимо запомнить их в алфавитном порядке. Для простоты положим, что каждая запись содержит поле-букву, которое и является ключом. Тогда отсортированный список и упорядоченное двоичное дерево будут выглядеть, показано на рис. 14.6 и 14.7.

Рис. 14.6. Отсортированный список
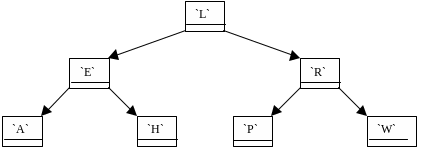
Рис. 14.7. Упорядоченное двоичное дерево
Алгоритм построения двоичного дерева, а также включение новых элементов (процедура bild) будет выглядеть следующим образом:
1. Первая поступившая запись выбирается «корнем» дерева.
2. При поступлении каждая следующая запись сравнивается с корневой.
2.1. Если поступившая запись предшествует корневой, идти в левое
поддерево.
2.2. Иначе – в правое поддерево.
3. Если того поддерева, в которое можно вставить новую запись не существует (на что указывает значение nil левой или правой связи), то новую запись надо вставить в этом месте (тем самым формируя новое поддерево, состоящее из единственной записи).
При этом для вставки новой записи нет необходимости изменять связи, указывающие на другие записи, как для связывания списка.
Алгоритм просмотра входящих в упорядоченное дерево записей и изображения записей, отсортированных по выбранному ключу (prozm (kor)):
Изобразить записи левого поддерева и т. д., пока не будет встречено пустое поддерево, тогда никаких действий не предпринимать.
Изобразить корневую запись.
Напечатать записи правого поддерева, пока не будет встречено пустое поддерево.
Алгоритм двоичного поиска в упорядоченном дереве:
Если дерево не пусто, сравнить искомый ключ с тем, что в корне дерева.
Если ключи совпадают, поиск завершён.
Если ключ в корне больше искомого, выполнить поиск в левом поддереве.
Если ключ в корне меньше искомого, выполнить поиск в правом поддереве.
Если дерево пусто (пройдены все элементы), поиск неудачен.