

Механизмы управления динамическими активными системами - Новиков Д.А., Смирнов И.М., Шохина Т.Е
..pdfx1,T |
T |
|
|
является решением задачи åδt F t ( y1,t ) → |
max |
для |
|
|
t =1 |
y1,T Y 1,T |
|
распределения дальновидности {δt}, тогда, если для распределе-
ния дальновидности {δ ′} выполняется соотношение: δt′+1 |
> δt +1 , |
|||||
|
|
|
t |
|
δt′ |
δt |
|
|
|
|
|
||
t = |
|
, и для |
любого |
y1,T |
выполняется |
условие |
1,T |
||||||
Y t ( y1,t −1) Y t (x1,t −1) , |
тогда |
x1,T является решением задачи с |
||||
распределением дальновидности {δt′}.
Завершив описание результатов, приведенных в [80], отме- тим, что при решении многих экономических задач полагают, что
распределение дальновидности имеет специфический вид δt (τ ) = δ t −τ , где δ является некоторой константой (так называе-
мым коэффициентом дисконтирования – см. также выше). Оказы- вается, что в этом случае задача сводится к исходной с помощью
замены Φ~ t ( y1,t ) = δ tΦt ( y1,t ) . Действительно, в каждый момент
принятия |
решения τ |
центр |
ищет максимум функции |
||
M |
|
|
|
|
|
åδ t −τ F t ( y1,t ) , что эквивалентно отысканию максимума функ- |
|||||
t =τ |
|
|
|
|
|
M ~t |
( y |
1,t |
) . Таким |
образом, |
ограничимся в дальнейшем |
ции åF |
|
||||
t =τ
постановкой задачи без учета зависимости распределения даль- новидности от момента принятия решений.
Вернемся к оценке эффективности различных режимов управления и ГПР. Фиксируем некоторое распределение дально-
видностей центра ξ0(t), t = 1,T , и будем исследовать эффектив- ность режимов управления при этом распределении дальновидно-
стей. Обозначим L1,T = (L0(1), L0(2), ..., L0(T)) – ГПР центра (как |
|||
|
0 |
L0(t) ≤ ξ0(t)); τ1 = 1, |
τ2 = τ1 + L0(τ1), |
отмечалось |
выше, |
||
τ3 = τ2 + L0(τ2) |
и т.д. – моменты принятия решений центром в |
||
модели ДАС3 |
с обязательствами (как отмечалось выше, ДАС3 |
||
отличается от |
ДАС2 |
наличием обязательств), |
следовательно |
50

[τi; τi+1] – интервалы времени, на которые центр фиксирует планы в моменты времени τi, i = 1, 2, ..., imax( L10,T ) – 1, где imax: τimax = T.
|
Если, с учетом решения задачи согласованного стимулирова- |
|||||||||||||||
ния |
(см. |
теоремы 1-2), целевая |
функция |
центра |
имеет вид |
|||||||||||
Φ t(y1,t) = H t(y1,t) – ct(y1,t), |
t = |
|
, |
то |
оптимальные |
в моделях |
||||||||||
1,T |
||||||||||||||||
ДАС1-ДАС4 плановые траектории x1,T , |
x1,T |
, x1,T и x1,T , соот- |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
1 |
|
2 |
3 |
|
4 |
|
ветственно, определяются следующим образом1: |
|
|||||||||||||||
(8) |
t |
= |
~t |
1,t-1 |
)= arg |
max |
t |
1,t-1 |
t |
|
|
|
||||
|
|
|
||||||||||||||
x1 |
x1 |
(x1 |
|
Φ (x1 |
|
, y ), t = 1,T ; |
||||||||||
|
|
|
~t |
|
|
y t At ( x11,t−1 ) |
|
|
|
|
|
|
|
|||
(9) |
t |
= |
(x2 |
1,t-1 |
) = |
|
|
|
|
|
|
|
|
|
|
|
x2 |
x2 |
|
|
|
|
|
|
|
|
|
|
|
||||
= Projt arg |
|
max |
|
y t,t+ς0 (t) A0t,t+ς0 |
|
(10) xτ3i ,τi+1 = arg |
max |
Φ t( x |
yτi ,τi+1 A0τi ,τi+1
|
t+ς0( t ) |
|
|
|
(t ) |
å |
Φ t(x21,t-1, yt,τ), t = 1,T ; |
||
τ =t |
|
|
|
|
|
|
|
|
|
13,τi −1 , yτi ,τ ), i = 1,imax −1;
|
|
|
|
T |
|
|
|
(11) xt |
= Projt arg |
max |
å |
Φ t(y1,t), t = |
1,T |
. |
|
4 |
y |
1,T |
1,T |
|
|
|
|
|
|
A0 |
t =1 |
|
|
|
|
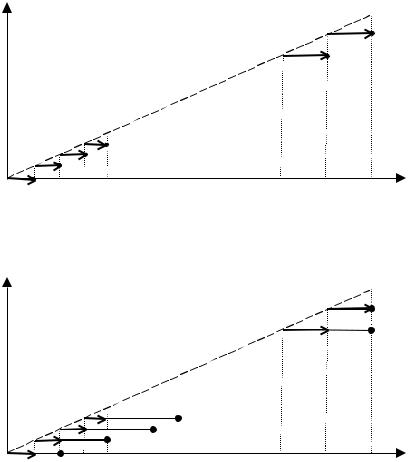
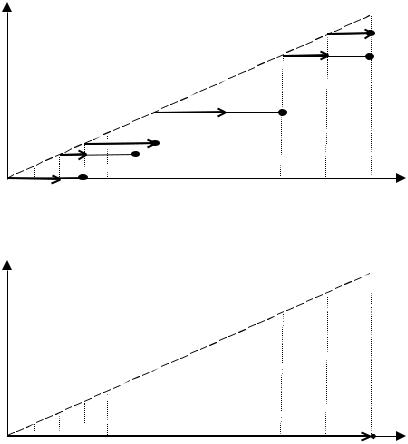
Рисунки 2-5 иллюстрируют последовательность принятия решений центром в моделях ДАС1-ДАС4 (черная точка обозна- чает горизонт дальновидности, стрелка – горизонт принятия решений с обязательствами).
1 В принципах планирования (2), (5) (6), (8)-(11) планы на текущий и будущий периоды (в зависимости от распределения дальновидности и горизонта принятия решений) определяются исходя из максимизации целевой функции центра в предположении, что действия АЭ в преды- дущих периодах совпадали с планами. Как отмечалось выше, отказ от этого предположения, то есть зависимость будущих планов от наблю- даемой траектории реализаций, является эффективным средством борьбы с эффектом обмена ролями и т.д.
51
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
|
|
|
t |
1 |
2 |
3 |
4 |
5 |
... |
T-2 |
T-1 |
T |
|
Рис. 2. Последовательность принятия решений центром |
|||||||
|
|
|
|
|
в модели ДАС1 |
|
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
... |
|
|
t |
1 |
2 |
3 |
4 |
5 |
T-2 |
T-1 |
T |
|
|
Рис. 3. Последовательность принятия решений центром |
|||||||
|
|
|
|
|
в модели ДАС2 |
|
|
|
52
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
|
|
|
t |
1 |
2 |
3 |
4 |
5 |
... |
T-2 |
T-1 |
T |
|
Рис. 4. Последовательность принятия решений центром |
|||||||
|
|
|
|
|
в модели ДАС3 |
|
|
|
|
|
|
|
|
|
|
|
t |
1 |
2 |
3 |
4 |
5 |
... |
T-2 |
T-1 |
T |
|
Рис. 5. Последовательность принятия решений центром |
|||||||
|
|
|
|
|
в модели ДАС4 |
|
|
|
Обсудим специфику модели ДАС3. Пусть центр обладает фиксированной дальновидностью ξ0 (1 < ξ0 < T), принимает ре- шения через каждые m0 периодов, и фиксирует свои планы на L0 периодов вперед. Условием того, что центр распланирует каждый период времени, является 1 ≤ m0 ≤ L0. Таким образом, предпола- гая что центр в каждый момент времени может принимать реше- ния только на те периоды, которые лежат в пределах его дально-
53
видности, получаем условие 1 ≤ m0 ≤ L0 ≤ ξ0 < T (последнее нера- венство отличает ДАС 3 от ДАС4).
Лемма 1. Пусть центр обладает фиксированной дальновидно- стью ξ0 (1 < ξ0 < T), принимает решения через каждые m0 перио- дов, и фиксирует свои планы на L0 периодов вперед (см. рисунки 6а) и 6б)). Такой способ принятия решения центром эквивалентен тому, что в первый период времени центр принимает и фиксирует план на L0 периодов вперед с дальновидностью ξ0, далее центр принимает и фиксирует решение на m0 периодов вперед в момен-
ты |
времени |
L0 + 1, L0 + m0, L0 + 2 m0, …, L0 + n m0, |
где |
||||||
é |
T - L0 |
ù |
|
|
|
|
|
|
|
n = ê |
ú , с дальновидностью ξ0 – L0 + m0 (см. рисунок 6б). |
|
|||||||
m0 |
|
||||||||
ë |
û |
|
|
|
|
|
|
|
|
Доказательство. В первый момент принятия решений центр |
|||||||||
находит планы по следующей формуле: |
|
||||||||
|
|
x1,L0 |
= Pr oj arg |
|
max |
ξ0 [Fτ ( y1,τ )] |
|
||
|
|
|
y |
1,L |
y |
1,ξ0 |
1,ξ0 |
å |
|
|
|
|
0 |
|
A0 |
τ =1 |
|
||
Опишем поведение центра в следующий момент m0 принятия решения. Согласно описанной выше модели поведения ДАС3, в
этот момент центр должен принять и зафиксировать решения на следующие L0 периодов. Но так как в прошлый раз (в первый момент времени) он уже фиксировал план на L0 первых периодов, а рассматривается момент принятия решения m0, и план на L0 – m0 периодов вперед уже существует, то центр не имеет права его менять. Таким образом, в момент m0 центр принимает и фиксиру- ет план на m0 периодов, начиная с L0 + 1. Оптимальные планы находятся по следующей формуле (здесь и далее до окончания
настоящего раздела в целях упрощения обозначений зависимость множеств допустимых действий от истории будет опускаться):
xL0+1,K,xL0+m0 |
= Proj |
arg |
|
max |
|
|
m0+ξ0 |
|
|
|
|
å Fτ (x1,min(τ,L0), |
|||||
|
yL0+1,L0+m0 |
yL0 |
+1,m0 |
+ξ0 AL0+1×L×Am0+ξ0 |
τ=m0 |
|
||
y L0 +τ ) = |
Pr oj arg |
|
|
max |
|
|
L0 |
+ |
|
|
|
{ åFτ (x1,τ ) |
|||||
yL0 +1,L0 +m0 |
yL0 +1,m0 +ξ0 AL0 +1×L×Am0 |
+ξ0 |
|
τ =m0 |
|
|||
54
|
m0 +ξ0 |
|
+1,τ ) } = |
|
|
+ |
å Φτ (x1,L0 , yL0 |
||
|
τ = L0 +1 |
|
|
|
= Pr oj arg |
|
max |
|
|
yL0 +1,L0 +m0 |
yL0 +1,m0 +ξ0 AL0 +1×L×Am0 |
+ξ0 |
|
|
L0 +(ξ0å+m0 − L0 ) Φτ (x1,L0 , yL0 +1,τ ) .
τ = L0 +1
Последнее соотношение означает, что поведение центра в момент времени m0 равносильно такому его поведению, при котором он принимает решения в момент L0 + 1 на m0 периодов вперед с дальновидностью ξ0 + m0 – L0.
Аналогично можно показать, что задача оптимального выбо- ра L0 (фактически – выбора m0) планов в периоде n m0 (где n-
целое и n ≤ |
T − L0 |
) для центра с дальновидностью ξ0, эквива- |
|
||
|
m0 |
|
лентна задаче оптимального выбора m0 планов в периоде L0 + (n –
1) m0 + 1 с дальновидностью ξ0 + m0 – L0. Действительно:
xL0 +(n−1)m0 +1,K, xL0 +nm0 =
Proj |
arg |
max |
|
|
|
yL0+(n−1)m0+1,L0+nm0 |
|
yL0+(n−1)m0+1,ξ0+nm0 AL0+(n−1)m0+1,ξ0+nm0 |
|
|
|
|
|
ξ0å+nm0 Φτ (x1,min(L0 +(n−1)m0,τ ) , yL0 +(n−1)m0 +1,τ ) = |
|||
|
|
τ =nm0 |
|
|
|
Proj |
arg |
max |
|
|
|
yL0+(n−1)m0+1,L0+nm0 |
|
yL0+(n−1)m0+1,ξ0+nm0 AL0+(n−1)m0+1,ξ0+nm0 L 0 + ( n − 1 ) m 0 |
τ ( x |
1 , τ ) |
+ |
|
|
τ =ånm 0 Φ |
|
|
|
ξ0 +nm0
åΦτ (x1,L0 +(n−1)m0 , yL0 +(n−1)m0 +1,τ ) =
τ= L0 +(n−1)m0 +1
Proj |
arg |
max |
yL0+(n−1)m0+1,L0+nm0 |
|
yL0+(n−1)m0+1,ξ0+nm0 AL0+(n−1)m0+1,ξ0+nm0 |
L0 +(n−1)m0å+(ξ0 +m0 −L0 ) Φτ (x1,L0 +(n−1)m0 , y L0 +(n−1)m0 +1,τ ) . ∙
τ =L0 +(n−1)m0 +1
На рисунке 6, иллюстрирующем лемму 1, ромбиком обозна- чен момент принятия решения, жирной стрелкой – горизонт
55
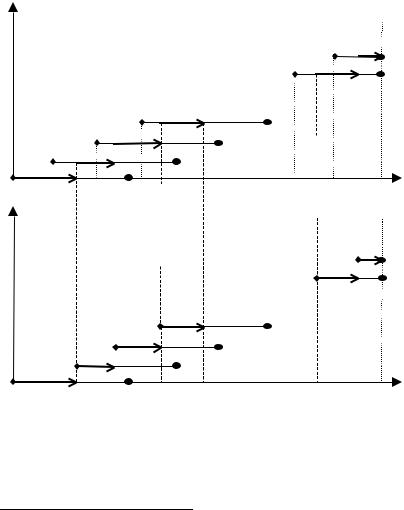
принятия решения (или на какие периоды принимаются решения |
|||||||
в данный момент времени), жирной точкой обозначен горизонт |
|||||||
дальновидности. |
|
|
|
|
|
||
|
a) |
|
|
|
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
|
|
t |
1 |
2 |
3 |
4 |
... |
T-2 |
T-1 |
T |
|
б) |
|
|
|
|
|
|
|
|
|
|
... |
|
|
|
|
|
|
|
|
|
|
t |
1 |
2 |
3 |
4 |
... |
|
T-2 T-1 |
T |
|
|
Рис. 6а), 6б). Принятие решений в модели ДАС3 |
|
||||
|
|
|
в соответствии с леммой 1 |
|
|
||
Завершив обсуждение специфики модели ДАС3, введем сле- дующие функции1:
1 Отметим, что при переходе к целевым функциям вида (12) «автома- тически» учитывается требование принадлежности плановой траек- тории соответствующей допустимой области (см. описание метода штрафов в [59]), что позволяет в (13)-(16), в отличие от (8)-(11),
искать в каждом периоде максимумы по независимым от предыстории
56
|
|
ì |
t |
|
|
|
|
|
t |
1,t |
ï |
åFτ (x1,τ ), |
x1,t Î A01,t |
|
|
||
|
||||||||
(12) F (x |
|
) = í |
|
|
|
, t = 1,T , |
||
|
|
τ =1 |
|
1,t |
1,t |
|||
|
|
ï |
- ¥, |
x |
||||
|
|
î |
|
Ï A0 |
||||
тогда плановые траектории (8)-(11) можно определить следую- щим образом (положим F0(×) = 0):
|
t |
~t |
1,t-1 |
|
t |
1,t-1 |
t |
t-1 |
1,t-1 |
|
|
|
|
|
|
|
||
(13) |
) Î Arg |
)], t = 1,T ; |
||||||||||||||||
x1 |
= x1 |
(x1 |
max [F (x1 |
|
, y ) – F |
|
(x1 |
|||||||||||
|
|
|
|
|
y t At |
|
|
|
|
|
|
|
|
|
|
|
|
|
(14) |
t |
~t |
1,t-1 |
) Î |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x2 |
= x2 |
(x2 |
|
[ F t +ξ0 (t) (x21,t-1, |
yt,t +ξ0 (t) ) – |
|||||||||||||
Î Projt Arg |
max |
|||||||||||||||||
|
|
|
y t,t+ς0 (t) At × At+1 ×...× At+ξ0 (t) |
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
F t(x21,t-1)], t = |
|
; |
|||||||
|
xτ3i ,τi+1 Î Arg |
|
|
|
|
|
1,T |
|||||||||||
(15) |
|
max |
[ Fτi+1 ( x31,τ i |
−1 , yτ i ,τ i+1 ) – |
||||||||||||||
|
|
|
|
yτi ,τi+1 Aτi ×Aτi +1×...×Aτi+1 |
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
- |
Fτ i ( x31,τ i |
−1 )], i = |
|
; |
|||||||||
|
|
|
|
|
1,imax -1 |
|||||||||||||
(16) |
xt |
Î Projt Arg max |
F T(y1,T), t = |
|
. |
|
|
|
|
|
|
|
|
|
||||
1,T |
|
|
|
|
|
|
|
|
|
|||||||||
4y1,T A1,T
Всоответствии с выражениями (13)-(16), эффективности управления в моделях ДАС1-ДАС4 можно записать в виде:
(17)Ki = FT( xi1,T ), i = 1, 4 .
Вернемся к сравнению эффективностей различных режимов
управления в динамических АС.
Обозначим J(t) – множество периодов, от которых зависит выигрыш в периоде t. В силу принципа причинности и введенных
выше предположений " t Î J(t) t £ t, t = 1,T . Положим также,
что t Î J(t), t = 1,T .
Обозначим N(t) – множество периодов, выигрыши в которых зависят от стратегий, выбираемых в периоде t. В силу принципа причинности и введенных выше предположений " t Î N(t) t ³ t,
t Î N(t), t = 1,T .
Множества J(t) и N(t) взаимозависимы:
допустимым множествам.
57

(18) J(t) = {t £ t | t Î N(t)}, N(t) = {t ³ t | t Î J(t)}, t = 1,T .
Предположим, что существуют целые числа J и N не мень- шие единицы и не большие T, такие, что
(19)" t = 1,T J(t) = {max (1, t – J); …; t},
(20)" t = 1,T N(t) = {t; …; min (t + N, T)}.
Очевидно, что, если выполнено (18)-(20), то J = N.
Параметр J назовем памятью АС (точнее – памятью центра),
так как он отражает максимальное число предыдущих периодов (исключая текущий), влияющих на выигрыш в текущем периоде.
Напомним, что выше были введены такие параметры центра как: x0(t) – его дальновидность, отражающая число будущих периодов (исключая текущий период), которые он принимает во внимание при выборе своей стратегии в текущем периоде (перио- де t), и горизонт принятия решений L0(t), который в модели ДАС3 соответствует числу будущих периодов (включая текущий пери- од), на которые центр берет обязательства в текущем периоде.
Обозначим
(21) x0 = min |
x0(t), L0 = max L0(t) |
t =1,T |
t =1,T |
и рассмотрим соотношение между памятью J, дальновидностью x0 и обязательствами L0. Введем следующее условие:
(22)J + (L0 – 1) £ x0.
Выполнение условия (22) можно назвать принципом адек-
ватности1 для ДАС (адекватности возможностей системы управ- ления – центра – условиям функционирования и сложности управляемой системы), так как оно требует, чтобы в любой мо- мент времени дальновидность центра, то есть его возможности по учету будущих последствий принимаемых решений, были не ниже суммы сложности системы (отражаемой ее памятью) и условий функционирования (отражаемых вынужденными обяза- тельствами).
Принцип адекватности позволяет выявить условия, при кото-
рых взятие обязательств не изменяет эффективности управления
– ниже приводится ряд формальных результатов.
1 См. аналоги и ссылки в [51].
58

Теорема 5а. Если выполнены предположения А.0, А.1, А.2’’, А.3, А.4 и условие (22), то в ДАС со связанным стимулированием режимы управления ДАС2 и ДАС3 эквивалентны: K2 = K3.
Теорема 5а является частным случаем формулируемой и до- казываемой ниже теоремы 5б.
Если условия типа (22) не выполняются,1 то существуют ДАС, в которых реализуются любые соотношения между эффек- тивностями K2 и K3 (обоснованием справедливости этого утвер- ждения являются приводимые ниже примеры 6 и 7).
Интуитивно можно было бы предположить, что ДАС1 долж- на обладать минимальной эффективностью, далее должна была бы следовать ДАС3 (дальновидность увеличилась по сравнению с ДАС1, но имеются обязательства), затем – ДАС2 (отказ от обяза- тельств), и, наконец, ДАС4. То, что ДАС4 обладает максимальной (среди базовых четырех ДАС) эффективностью очевидно. Одна- ко, оказывается, что возможны любые соотношения между эф- фективностями ДАС1 и ДАС2, а также ДАС2 и ДАС3. Ниже приводятся примеры, иллюстрирующие противоречия "здравому смыслу": в примере 6 рассматривается модель ДАС, в которой эффективность ДАС1 выше, чем ДАС2 (то есть увеличение даль- новидности не приводит к увеличению эффективности), а в при- мере 7 – модель ДАС, в которой эффективность ДАС3 выше, чем ДАС2 (наличие обязательств приводит к повышению эффектив- ности).
Пример 6. (эффективность ДАС1 выше эффективности ДАС2).
Рассмотрим трехпериодную модель, в которой человек (на- пример, чиновник) выбирает свою судьбу – быть ли ему богатым, но брать взятки, или не купаться в роскоши, но быть честным. Чиновник имеет два возможных действия: "Воровать" или рабо- тать честно ("Не воровать"). Во все три периода у него для выбо- ра есть эти два действия.
В первом периоде, если он выбирает "Не воровать", то его полезность Φ1( y1) равна 3. Если он выбирает действие "Воро-
1 Для этого достаточно нарушения принципа адекватности в одном периоде.
59