

Архитектура компьютера - Таненбаум Э
..pdfПроцесс ассемблирования |
533 |
имен содержится само имя (или указатель на него), его численное значение и иногда некоторая дополнительная информация. Она может включать:
1.Длину поля данных, связанного с символом.
2.Биты перераспределения памяти (которые показывают, изменяется ли значение символа, если программа загружается не в том адресе, в котором предполагал ассемблер).
3.Сведения о том, можно ли получить доступ к символу извне процедуры.
Таблица 7.7. Счетчик адреса команд используется для слежения за адресами команд. В данном примере операторы до MARIA занимают 100 байтов
Метка |
Код операции |
Операнды |
Комментарии |
Длина |
Счетчик адреса команд |
MARIA: |
MOV |
EAX, I |
EAX=I |
5 |
100 |
|
MOV |
EBX,J |
EBX=J |
6 |
105 |
ROBERTA: |
MOV |
ECX,К |
ECX=K |
6 |
111 |
|
IMUL |
EAX, EAX |
EAX=I*I |
2 |
117 |
|
IMUL |
EBX, EBX |
EBX=J*J |
3 |
119 |
|
IMUL |
ECX,ECX |
ECX=K*K |
3 |
122 |
MARILYN: |
ADD |
EAX,EBX |
EAX=I*I+J*J |
2 |
125 |
|
ADD |
EAX,ECX |
EAX=I*I+J*J+K*K |
2 |
127 |
STEPHANY: JMP |
DONE |
Переход к DONE |
5 |
129 |
|
Таблица 7.8. Таблица символьных имен для программы из табл. 7.7.
Символьное имя |
Значение Прочая информация |
MARIA |
100 |
ROBERTA |
111 |
MARILYN |
125 |
STEPHANY |
129 |
В таблице кодов операций предусмотрен по крайней мере один элемент для каждого символического кода операции в языке ассемблера (табл. 7.9). В каждом элементе таблицы содержится символический код операции, два операнда, числовое значение кода операции, длина команды и номер типа, по которому можно определить, к какой группе относится код операции (коды операций делятся на группы в зависимости от числа и типа операндов).
Таблица 7.9. Некоторые элементы таблицы кодов операций для ассемблера Pentium II
Код |
Первый |
Второй |
Шестнадцатеричный |
Длина |
Класс |
операции |
операнд |
операнд |
код |
команды |
команды |
ААА |
— |
— |
37 |
1 |
6 |
ADD |
EAX |
immed32 |
05 |
5 |
4 |
ADD |
reg |
reg |
01 |
2 |
19 |
AND |
EAX |
immed32 |
25 |
5 |
4 |
AND |
reg |
reg |
21 |
2 |
19 |

5 3 4 Глава 7. Уровень языка ассемблера
Вкачестве примера рассмотрим код операции ADD. Если команда ADD в качестве первого операнда содержит регистр ЕАХ, а в качестве второго — 32-битную константу (immed32), то используется код операции 0x05, а длина команды составляет 5 байтов. Если используется команда ADD с двумя регистрами в качестве операндов, то длина команды составляет 2 байта, а код операции будет равен 0x01. Все комбинации кодов операций и операндов, которые соответствуют данному правилу, будут отнесены к классу 19 и будут обрабатываться так же, как команда ADD с двумя регистрами в качестве операндов. Класс команд обозначает процедуру, которая вызывается для обработки всех команд данного типа.
Внекоторых ассемблерах можно писать команды с применением непосредственной адресации, даже если соответствующей команды не существует в выходном языке. Такие команды с «псевдонепосредственными» адресами обрабатываются следующим образом. Ассемблер назначает участок памяти для непосредственного операнда в конце программы и порождает команду, которая обращается к нему. Например, универсальная вычислительная машина IBM 3090 не имеет команд с непосредственными адресами. Тем не менее программист может написать команду
L 14.=F'5'
для загрузки в регистр 14 константы 5 размером в полное слово. Таким образом, программисту не нужно писать директиву, чтобы разместить слово в памяти, придать ему значение 5, дать ему метку, а затем использовать эту метку в команде L. Константы, для которых ассемблер автоматически резервирует память, называются литералами. Литералы упрощают читаемость и понимание программы, делая значение константы очевидным в исходном операторе. При первом проходе ассемблер должен создать таблицу из всех литералов, которые используются в программе. Все три компьютера, которые мы взяли в качестве примеров, содержат команды с непосредственными адресами, поэтому их ассемблеры не обеспечивают литералы. Команды с непосредственными адресами в настоящее время считаются обычными, но раньше они рассматривались как нечто совершенно необычное. Вероятно, широкое распространение литералов внушило разработчикам, что непосредственная адресация — это очень хорошая идея. Если нужны литералы, то во время ассемблирования сохраняется таблица литералов, в которой появляется новый элемент всякий раз, когда встречается литерал. После первого прохода таблица сортируется и продублированные элементы удаляются.
В листинге 7.5 показана процедура, которая лежит в основе первого прохода ассемблера. Названия процедур были выбраны таким образом, чтобы была ясна их суть. Листинг 7.5 представляет собой хорошую отправную точку для изучения. Он достаточно короткий, он легок для понимания, и из него видно, каким должен быть следующий шаг — это написание процедур, которые используются в данном листинге.
Листинг 7.5. Первый проход простого ассемблера |
|
|
public static void pass_one() { |
|
|
// Эта процедура - первый проход ассемблера |
|
|
boolean more_input=true; |
//флаг, |
который останавливает первый проход |
String line, symbol, literal, opcode; |
//поля команды |
|
int location_counter, length, value, type; //переменные |
|
|
final int END STATEMENT = -2; |
//сигналы |
конца ввода |

|
|
|
|
|
Процесс ассемблирования |
535 |
|||||
location_counter = 0; |
//ассемблирование первой команды в ячейке 0 |
|
|
|
|||||||
imtialize_tables(), |
//общая инициализация |
|
|
|
|
|
|
|
|||
while (more_input) { |
|
//more_input получает значение «ложь» с помощью END |
|
||||||||
line = read_next_line(); |
//считывание строки |
|
|
|
|
|
|
||||
length =0; |
|
|
//# байт в |
команде |
|
|
|
|
|
|
|
type =0. |
|
|
//тип команды |
|
|
|
|
|
|
|
|
if (line_isjiot_coniment(line)) { |
|
|
|
|
|
|
|
|
|||
symbol = check_for_symbol(line), |
//Содержит ли строка метку? |
|
|
|
|||||||
if (symbol |
!- null) |
|
|
//если да, |
то записывается |
символ |
и значение |
||||
enter_new_symbol(symbol. 1ocation_counter), |
|
|
|
|
|
|
|||||
literal = check_for_literal(line). |
//Содержит ли строка литерал? |
|
|
||||||||
if (literal |
!= null) |
|
|
//если да, |
то он |
вводится в |
таблицу |
||||
enter_new_literal(1itera1); |
|
|
|
|
|
|
|
|
|||
|
|
|
|
//Теперь определяем тип кода операции. |
|
||||||
|
|
|
|
//-1 значит недопустимый код операции. |
|
||||||
opcode = extract_opcode(line). |
//определяем место кода |
операции |
|
|
|||||||
type =search_opcode_table(opcode). |
//находим формат, |
например. OP REG1.REG2 |
|
||||||||
if (type < 0) |
|
|
|
//Если это не |
код |
операции, является |
|||||
|
|
|
|
//ли |
это директивой? |
|
|
|
|
|
|
type = search_pseudo_table(opcode). |
|
|
|
|
|
|
|
||||
switch(type) { |
|
|
|
//определяем |
длину |
команды |
|
||||
case l.length=get_length_of_typel (line), break, |
|
|
|
|
|
|
|||||
case 2 Iength=get_length_of_type2(line); break. |
|
|
|
|
|
|
|||||
|
|
|
|
//другие случаи |
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
} |
|
|
|
|
|
|
|
|
|
|
|
wnte_temp_file(type, opcode, length, line), |
//информация для второго прохода |
|
|||||||||
location_counter = |
location_counter + length, //обновление счетчика |
адреса команд |
|
||||||||
if (type == END_STATEMENT) { |
|
|
//завершился ли ввод? |
|
|
||||||
morejinput - false. |
|
|
|
//если да. |
то выполняем служебные действия- |
||||||
rewind_temp_for_pass_two(). |
|
|
//перематываем |
файл обратно |
|
||||||
sort_literal_table(). |
|
|
//сортируем |
таблицу литералов |
|||||||
remove_redundant_literals(); |
|
|
//и удаляем из |
нее |
дубликаты |
|
|||||
Одни процедуры будут относительно короткими, например check_jor_symbol, которая просто выдает соответствующее обозначение в виде цепочки символов, если таковое имеется, и выдает ноль, если его нет. Другие процедуры, например get_length_of_type1 и get_length_ofjtype2, могут быть достаточно длинными и могут сами вызывать другие процедуры. Естественно, на практике типов будет не два, а больше, и это будет зависеть от языка, который ассемблируется, и от того, сколько типов команд предусмотрено в этом языке.
Структурирование программ имеет и другие преимущества помимо простоты программирования. Если ассемблер пишется группой людей, разнообразные процедуры могут быть разбиты на куски между программистами. Все подробности получения входных данных спрятаны в процедуре read_next_line. Если эти детали нужно изменить (например, из-за изменений в операционной системе), то это повлияет только на одну подчиненную процедуру, и никаких изменений в самой процедуре passjone делать не нужно.
По мере чтения программы во время первого прохода ассемблер должен анализировать каждую строку, чтобы найти код операции (например, ADD), определить


|
Процесс ассемблирования |
537 |
more_input = false; |
// если да, то выполняем служебные операции |
|
finishjjpO; |
// завершение |
|
}
Процедура второго прохода более или менее сходна с процедурой первого прохода: строки считываются по одной и обрабатываются тоже по одной. Поскольку мы записали в начале каждой строки тип, код операции и длину (во временном файле), все они считываются, и таким образом, нам не нужно проводить анализ строк во второй раз. Основная работа по порождению кода выполняется процедурами eval_type1, eval_type2 и т. д. Каждая из них обрабатывает определенную модель (например, код операции и два регистра-операнда). Полученный в результате двоичный код команды сохраняется в переменной code. Затем совершается контрольное считывание. Желательно, чтобы процедура write_code просто сохраняла в буфере накопленный двоичный код и записывала файл на диск большими порциями, чтобы сократить рабочую нагрузку на диск.
Исходный оператор и выходной (объектный) код, полученный из него (в шестнадцатеричной системе), можно напечатать или поместить в буфер, чтобы напечатать потом. После переустановки счетчика адреса команды вызывается следующий оператор.
До настоящего момента предполагалось, что исходная программа не содержит никаких ошибок. Но любой человек, который когда-нибудь писал программы на каком-либо языке, знает, насколько это предположение не соответствует действительности. Наиболее распространенные ошибки приведены ниже:
1.Используемый символ не определен.
2.Символ был определен более одного раза.
3.Имя в поле кода операции не является допустимым кодом операции.
4.Код операции не снабжен достаточным количеством операндов.
5.У кода операции слишком много операндов.
6.Восьмеричное число содержит 8 или 9.
7.Недопустимое применение регистра (например, переход к регистру).
8.Отсутствует оператор END.
Программисты весьма изобретательны по части новых ошибок. Ошибки с неопределенным символом часто возникают из-за опечаток. Хороший ассемблер может вычислить, какой из всех определенных символов в большей степени соответствует неопределенному, и подставить его. Для исправления других ошибок ничего кардинального предложить нельзя. Лучшее, что может сделать ассемблер при обнаружении оператора с ошибкой, — это вывести сообщение об ошибке на экран и попробовать продолжить процесс ассемблирования.
Таблица символов
Во время первого прохода ассемблер аккумулирует всю информацию о символах и ихзначениях. Этуинформацию ондолжен сохранить в таблице символьных имен, к которой будет обращаться при втором проходе. Таблицу символьных имен можно организовать несколькими способами. Некоторые из них мы опишем ниже.


5 40 Глава 7. Уровень языка ассемблера
Трансляция исходной процедуры в объектном модуле — это переход на другой уровень, поскольку исходный язык и выходной язык имеют разные команды и запись. Однако при связывании перехода надругой уровень не происходит, поскольку программы на входе и на выходе компоновщика предназначены для одной и той же виртуальной машины. Задача компоновщика — собрать все процедуры, которые транслировались раздельно, и связать их вместе, чтобы в результате получился исполняемый двоичный код. В системах MS-DOS, Windows 95/98 и NT объектные модули имеют расширение .obj, а исполняемые двоичные программы — расширение .ехе. В системе UNIX объектные модули имеют расширение .о, а исполняемые двоичные программы не имеют расширения.
Исходная |
|
Объектный |
|
|
|
процедура1 |
|
модуль 1 |
|
|
|
Исходная |
|
Объектный |
|
Исполняемый |
|
Транслятор |
Компоновщик |
двоичный |
|||
процедура2 |
модуль 2 |
||||
|
|
код |
|||
|
|
|
|
||
Исходная |
|
Объектный |
|
|
|
процедура3 |
|
модуль 3 |
|
|
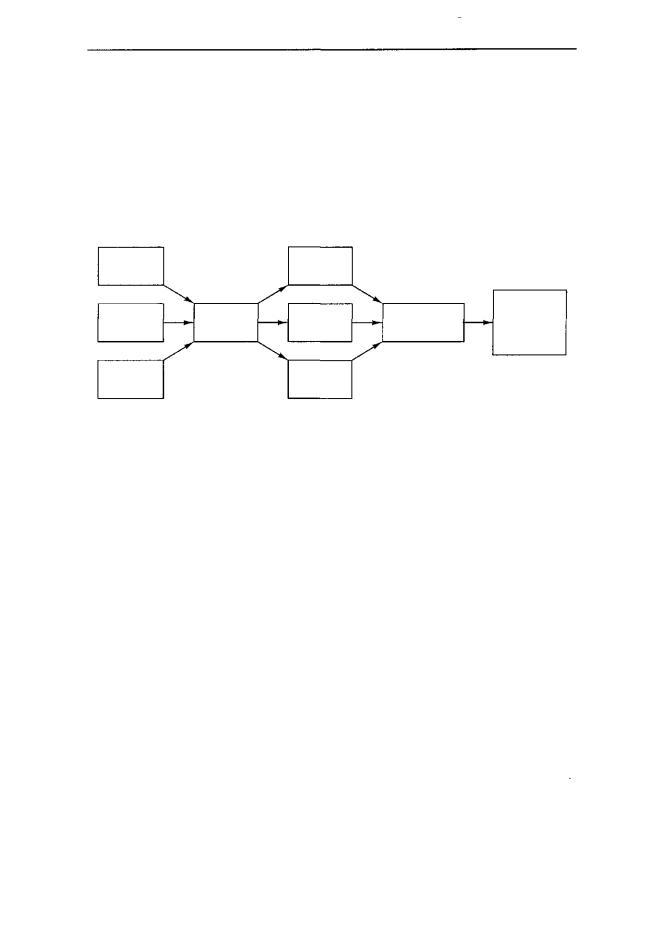
Рис.7.2.Дляполученияисполняемойдвоичнойпрограммыизсовокупности оттранслированных независимо друг от друга процедур используется компоновщик
Компиляторы и ассемблеры транслируют каждую исходную процедуру как отдельную единицу. На это есть веская причина. Если компилятор или ассемблер считывал бы целый ряд исходных процедур и сразу переводил бы их в готовую программу на машинном языке, то при изменении одного оператора в исходной процедуре потребовалось бы заново транслировать все исходные процедуры.
Если каждая процедура транслируется по отдельности, как показано на рис. 7.2, то транслировать заново нужно будет только одну измененную процедуру, хотя понадобится заново связать все объектные модули. Однако связывание происходит гораздо быстрее, чем трансляция, поэтому выполнение этих двух шагов (трансляции и связывания) сэкономит время при доработке программы. Это особенно важно для программ, которые содержат сотни или тысячи модулей.
Задачи компоновщика
В начале первого прохода ассемблирования счетчик адреса команды устанавливается на 0. Этот шаг эквивалентен предположению, что объектный модуль во время выполнения будет находиться в ячейке с адресом 0. На рис. 7.3 показаны 4 объектных модуля для типичной машины. В этом примере каждый модуль начинается с команды перехода BRANCH к команде MOVE в том же модуле.
Чтобы запустить программу, компоновщик помещает объектные модули в основную память, формируя отображение исполняемого двоичного кода (рис. 7.4, а). Цель — создать точное отображение виртуального адресного пространства ис-

