

7. Встроенные функции и подзапросы
Встроенные функции могут использоваться только во фразе SELECT или в команде HAVING. Однако фраза SELECT, содержащая встроенную функцию, может быть частью подзапроса. Рассмотрим пример такого подзапроса:
Запрос: У кого из работников почасовая ставка выше среднего?
SELECT WORKER_NAME
FROM WORKER
WHERE HRLY_RATE >
(SELECT AVG(HRLY_RATE)
FROM WORKER)
Результат:
NAME
К. Немо
П.Мэйсон
Х. Колумб
Обратите внимание, что подзапрос не коррелирует с главным запросом. Подзапрос выдает ровно одно значение - среднюю почасовую ставку. Главный запрос выбирает работника только в том случае, если его ставка больше вычисленной средней.
В коррелированных запросах также могут использоваться встроенные функции:
Запрос: У кого из работников почасовая ставка выше средней почасовой ставки среди подчиненных того же менеджера?
В этом случае вместо вычисления одной средней почасовой ставки для всех работников мы должны вычислить среднюю ставку каждой группы работников, подчиняющейся одному и тому же менеджеру. Более того, наше вычисление должно производиться заново для каждого работника, рассматриваемого главным запросом:
SELECT A. WORKER_NAME
FROM WORKER A
WHERE A.HRLY_RATE >
(SELECT AVG(B.HRLY_RATE)
FROM WORKER В
WHERE B.SUPV_ID = A.SUPV_ID)
Результат:
A.WORKER NAME
К.Немо
П.Мэйсон
X.Колумб
Фраза WHERE подзапроса содержит ключевое условие корреляции. Это условие гарантирует, что среднее будет вычисляться только по тем рабочим, которые подчиняются тому же менеджеру, что и работник, рассматриваемый главным запросом.
8. Операции реляционной алгебры
Как отмечалось ранее и как вы, вероятно, заметили, SQL напоминает реляционное исчисление наличием целевого списка (фраза SELECT) и определяющего выражения (фраза WHERE). В SQL2, однако, реализованы некоторые операции реляционной алгебры, которые мы сейчас обсудим. В частности, объединение, пересечение, разность и соединение реализованы в явном виде как операторы SQL. Мы рассмотрим их по очереди.
Операторы UNION (объединение), INTERSECT (пересечение) и EXCEPT (разность). Как и в реляционной алгебре, операторы объединения, пересечения и разности применяются к двум таблицам, которые должны быть объединительно-совместимы. Этот термин в SQL имеет несколько отличающееся значение. Две таблицы объединительно-совместимы, если в них одинаковое число столбцов и соответствующие столбцы имеют совместимые типы данных, то есть такие типы, которые могут быть легко преобразованы друг в друга. Например, два числовых типа не обязательно должны совпадать, но они должны преобразовываться друг в друга.
Объединительно-совместимые таблицы. Две или более таблицы, имеющие эквивалентные (по количеству и областям) наборы столбцов.
При обсуждении объединения, пересечения и разности мы воспользуемся следующим примером (рис. 3).
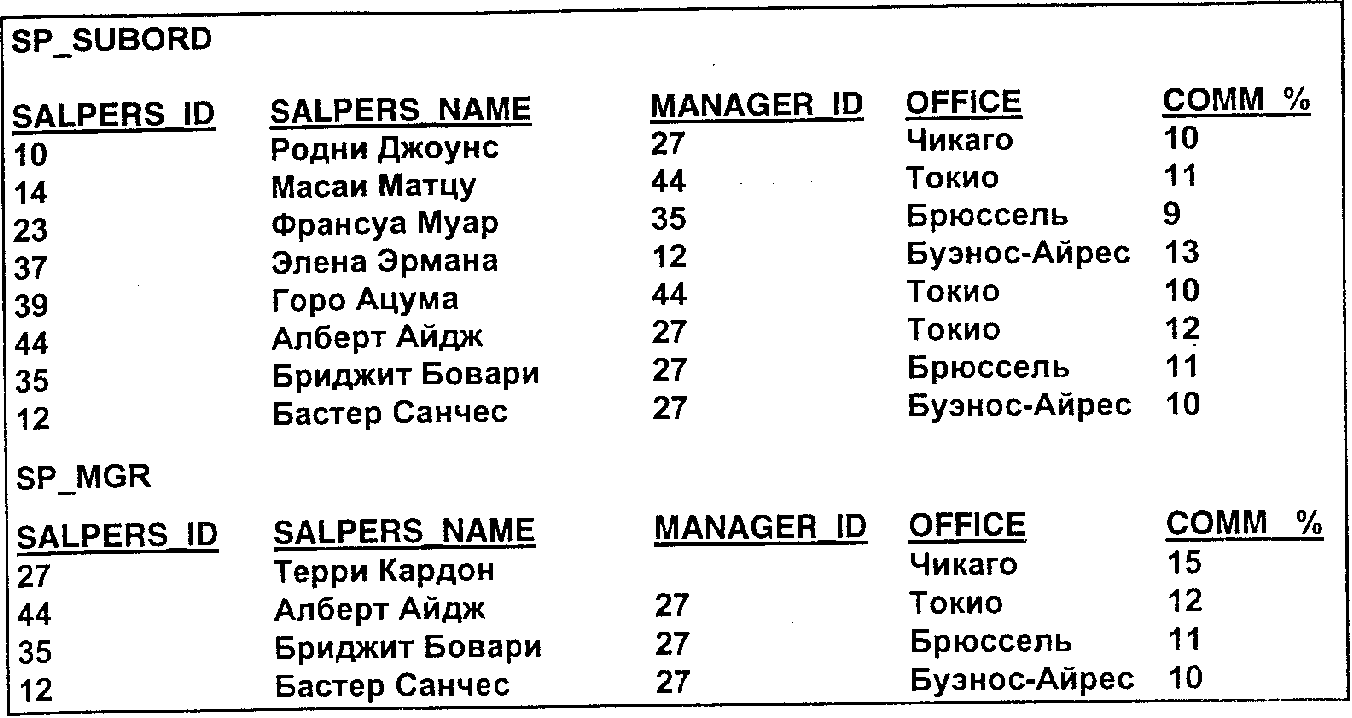
Рис. 3. Две реляционные таблицы с информацией о торговых агентах
UNION. Предположим, что мы хотим получить одну таблицу, содержащую информацию обо всех торговых агентах. Воспользуемся SQL-выражением
(SELECT * FROM SP_SUBORD)
UNION
(SELECT * FROM SP_MGR)
или в другом виде
SELECT *
FROM (TABLE SP_SUBORD UNION TABLE SP_MGR)
Результат представлен на рис. 4. Как и в реляционной алгебре, объединением двух реляционных таблиц будет реляционная таблица, содержащая каждую строку, лежащую хотя бы в одной из двух таблиц.
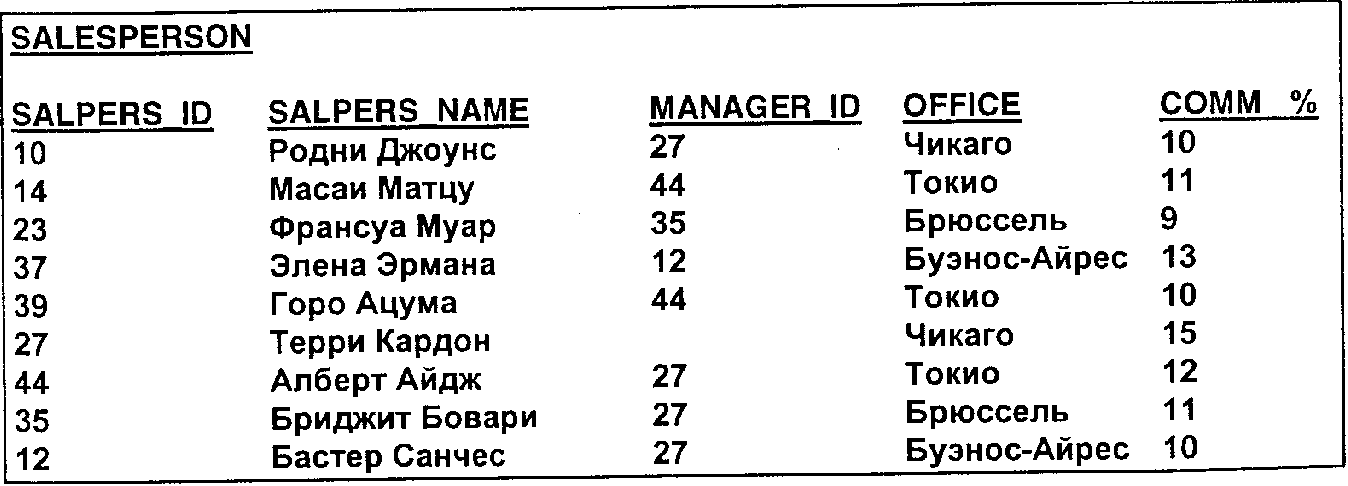
Рис. 4. Объединение таблиц SP_SUBORD и SP_MGR
В нашем примере ни одна строка не появляется более одного раза, даже если она есть в обеих таблицах. Однако, если мы воспользуемся формой
(SELECT * FROM SP_SUBORD)
UNION ALL
(SELECT * FROM SP_MGR)
или формой
SELECT *
FROM (TABLE SP_SUBORD UNION ALL TABLE SP_MGR)
то тогда те строки, которые входят в обе таблицы, будут повторяться в объединении дважды.
UNION. Операция, создающая теоретико-множественное объединение двух таблиц.
INTERSECT. Предположим, что мы хотим идентифицировать тех торговых агентов, которые одновременно подчиняются кому-либо и сами являются менеджерами. Другими словами, нам нужно пересечь две таблицы, чтобы найти строки, лежащие в них обеих. Мы воспользуемся SQL-выражением
INTERSECT. Операция, создающая теоретико-множественное пересечение двух таблиц.
(SELECT * FROM SP_SUBORD) INTERSECT
(SELECT * FROM SP_MGR)
или в другой форме
SELECT *
FROM (TABLE SP_SUBORD INTERSECT TABLE SP_MGR)
Результат представлен на рис. 5.

Рис. 5. Пересечение таблиц SP_SUBORD и SP_MGR
Как и в случае объединения, ни одна строка не появляется в пересечении более одного раза. Однако, если в одной таблице имеется m копий строки, а в другой таблице имеется n копий строки, и m<n, то пересечение будет содержать m копий этой строки, если мы воспользуемся таким синтаксисом:
(SELECT * FROM SP_SUBORD)
INTERSECT ALL
(SELECT * FROM SP_MGR)
Как и в случае объединения, ключевое слово ALL означает, что повторы строк нужно рассматривать как отдельные строки.
EXCEPT. Предположим, что мы хотим найти всех торговых агентов, которые никому не подчиняются. Мы хотим вычесть таблицу SP_SUBORD из таблицы SP_MGR. В SQL-92 разность множеств поддерживается оператором EXCEPT. В нашем примере мы воспользуемся выражением
EXCEPT. Операция, создающая теоретико-множественную разность двух таблиц.
(SELECT * FROM SP_SUBORD)
EXCEPT
(SELECT * FROM SP_MGR)
или в другой форме
SELECT *
FROM (TABLE SP_SUBORD EXCEPT TABLE SP_MGR)
Результат представлен на рис. 6.

Рис. 6. Результат операции SP_MGR - SP_SUBORD
Если мы воспользуемся синтаксисом
(SELECT * FROM SP_SUBORD)
EXCEPT ALL
(SELECT * FROM SP_MGR)
в случае, когда в таблице SP_MGR имеется m копий строки, а в таблице SP_SUBORD имеется n копий строки, где m > n, то в результирующей таблице будет m-n копий этой строки. Если же m <= n, то в результирующей таблице не будет ни одной копии этой строки.
Теперь, когда мы дали общее представление об операторах SQL UNION, INTERSECT и EXCEPT, мы хотим взглянуть на них более пристально. Ограничение, накладываемое на таблицу, к которой применяются операторы объединительной совместимости, кажется слишком сильным. В конце концов, как часто мы имеем дело с таблицами, у которых в точности одинаковые столбцы? Рассмотрим слегка модифицированный синтаксис операторов и примеры, в которых ограничение не соблюдается. Рассмотрим такой запрос:
Запрос: Кто из штукатуров начинает работу 9 октября?
(SELECT * FROM WORKER
WHERE SKILL_TYPE = 'Штукатур')
INTERSECT CORRESPONDING BY (WORKER_ID)
(SELECT * FROM ASSIGNMENT
WHERE START_DATE = '09.10')
Результат:
WORKER ID
1520
Мы выделили часть SQL-выражения, важную для нашего обсуждения. Две фразы SELECT определяют две таблицы, которые явно не являются объединительно-совместимыми. Однако мы можем взять их пересечение, оговорив, что рассматриваются только те столбцы, которые есть в обеих таблицах. Мы указываем, какие столбцы рассматривать, в команде CORRESPONDING BY. В нашем случае рассматривается только столбец WORKER_ID. Система оставит из результатов выполнения команд SELECT только значения в столбце WORKER_ID, Затем она возьмет пересечение этих двух множеств, и это будет результат запроса. Таким образом, в результате получится список ИД тех работников, которые имеют специальность «штукатур» и получили работу, которая должна начинаться 9 октября - в точности это и требовалось.
Такой же подход используется для операторов UNION и EXCEPT. Фраза CORRESPONDING BY следует за оператором и перечисляет столбцы, общие для обеих рассматриваемых таблиц. Рассмотрим еще несколько примеров:
Запрос: Какие здания являются зданиями офисов или же на них назначен рабочий 14127
(SELECT * FROM BUILDING
WHERE TYPE = 'Офис')
UNION CORRESPONDING BY (BLDG_ID)
(SELECT * FROM ASSIGNMENT
WHERE WORKER_ID = 1412)
Результат:
BLDG_ID
312
210
111
460
435
515
Запрос: На какие здания офисов не назначен рабочий 1235?
(SELECT * FROM BUILDING
WHERE TYPE = 'Офис')
EXCEPT CORRESPONDING BY (BLDG_ID)
(SELECT * FROM ASSIGNMENT
WHERE WORKER_ID = 1235)
Результат:
BLDG ID
210
111
Вы, вероятно, заметили, что эти запросы относительно легко сформулировать. Мы просто определяем подходящие подмножества строк из двух таблиц, а затем применяем соответствующий оператор UNION, INTERSECT или EXCEPT. Это существенно расширяет практические возможности языка, поскольку многие люди считают, что подобные запросы проще формулировать, пользуясь именно таким подходом. Например, применим к последнему запросу «старый» подход SQL:
SELECT BLDG_ID
FROM BUILDING
WHERE TYPE = 'Офис' AND
NOT EXISTS (SELECT *
FROM ASSIGNMENT
WHERE BUILDING.BLDG_ID = ASSIGNMENT.BLDG_ID
AND WORKER_ID = 1235)
В этом решении использован коррелированный подзапрос и оператор NOT EXISTS. Естественно предположить, что большинству людей значительно сложнее сформулировать такое решение, чем решение с оператором EXCEPT. Тем не менее, обратите внимание, что запрос можно было бы реализовать с помощью старого синтаксиса SQL. Это не так просто.
Оператор JOIN (соединение). SQL2 содержит несколько операторов соединения в явной форме: естественное соединение, внутреннее соединение, несколько внешних соединений, объединительное соединение и кросс-соединение. Мы рассмотрим только естественное и внутреннее соединения.
Естественное соединение. Соответственно названию, естественное соединение имеет то же значение в SQL, что и в реляционной алгебре. Предположим, что мы хотим соединить таблицы WORKER и ASSIGNMENT. Мы можем использовать такой синтаксис:
WORKER NATURAL JOIN ASSIGNMENT
Результатом выполнения этой команды будет такая же таблица, которая получилась бы в результате выполнения выражения
SELECT P.WORKER_ID, WORKER_NAME, HRLY_RATE, SKILL_TYPE,
SUPV_ID, WORKER_ID, BLDG_ID, START_DATE, NUM_DAYS
FROM WORKER, ASSIGNMENT
WHERE P.WORKER_ID = ASSIGNMENT.WORKER_ID,
за исключением того, что первый столбец будет называться WORKER_ID, а не P.WORKER_ID. В общем случае естественное соединение, связывает две таблицы по всем их общим столбцам, но эти столбцы включаются в результирующую таблицу только один раз. В результирующей таблице сначала располагаются общие столбцы, затем столбцы первой таблицы, затем оставшиеся столбцы второй таблицы.
NATURAL JOIN. Оператор, соединяющий таблицы в том случае, если общие столбцы имеют равные значения.
JOIN USING. Предположим, у нас есть две таблицы А и В, и у них есть общие столбцы К, L, М и N. Предположим, что мы хотим соединить таблицы не по всем общим столбцам, а только по столбцам L и N. Тогда мы можем воспользоваться следующим выражением:
A JOIN В USING (L, N)
Это выражение даст тот же результат, что и SELECT-выражение, в котором в команде SELECT будут сначала перечислены столбцы L и N, за которыми следуют оставшиеся столбцы А и оставшиеся столбцы В. Фраза WHERE в таком выражении должна иметь вид
WHERE A.L = B.L AND A.N = B.N
JOIN USING. Операция, связывающая таблицы только по указанным общим столбцам, имеющим равные значения.
JOIN ON. Если мы хотим задать более общее условие соединения двух таблиц, то можем пользоваться этой формой. Например, предположим, что мы хотим присоединить таблицу WORKER к ней самой, связав WORKER ID с SUPV_ID, чтобы получить информацию о менеджере каждого работника. Воспользуемся следующим выражением:
WORKER W JOIN WORKER SUPV
ON W.SUPV_ID = SUPV.WORKER_ID
В этом примере мы создали две копии таблицы WORKER и дали им псевдонимы W и SUPV, соответственно. Фраза ON содержит условие равенства SUPV_ID копии W и WORKER_ID копии SUPV таблицы WORKER.
JOIN ON. Операция, связывающая таблицы при выполнении условия.
Теперь рассмотрим некоторые вариацвв предыдущего примера. Вместо того чтобы использовать существующую таблицу или представление данных в условии соединения, мы можем использовать таблицы, полученные в результате выполнения других операций. Проиллюстрируем этот подход несколькими примерами запросов.
Запрос: Выдать данные о назначении и работнике для каждого штукатура, начинающего работу 9 октября.
(SELECT * FROM WORKER WHERE SKILL_TYPE = 'Штукатур')
NATURAL JOIN
(SELECT * FROM ASSIGNMENT WHERE START_DATE = '09.10')
Возможно, вы заметили, что этот запрос почти идентичен тому, который использовался ранее для иллюстрации работы оператора INTERSECT. Разница состоит в том, что вместо того, чтобы просто получить список WORKER_ID, мы получим всю связанную с работником информацию, поскольку кортежи таблицы WORKER будут связаны с кортежами таблицы ASSIGNMENT.
Запрос: Выдать данные о назначении, работнике и здании для каждого штукатура, начинающего работу 9 октября и работающего на жилом доме.
(SELECT * FROM WORKER WHERE SKILL_TYPE = 'Штукатур')
NATURAL JOIN
(SELECT * FROM ASSIGNMENT WHERE START_DATE = '09.10')
NATURAL JOIN
(SELECT * FROM BUILDING WHERE TYPE - 'Жилой дом')
В этом случае WORKER_ID и BLDG_ID - столбцы, по которым выполняется соединение - будут стоять в таблице результатов первыми, за ними будут следовать оставшиеся столбцы таблиц WORKER, ASSIGNMENT, BUILDING (именно в таком порядке). Если в результате мы получаем избыточную информацию, то можем поместить все это выражение внутрь выражения SELECT FROM, указывающего нужные столбцы:
SELECT WORKER_ID, START_DATE, BLDG_ID, ADDRESS
FROM (SELECT * FROM WORKER WHERE SKILL_TYPE = 'Штукатур')
NATURAL JOIN
(SELECT * FROM ASSIGNMENT WHERE START_DATE = '09.10')
NATURAL JOIN
(SELECT * FROM BUILDING WHERE TYPE = 'Жилой дом')