

Оцінка математичного сподівання
Для незгрупованої вибірки вибірковим середнім називають статистику
![]() .
(4.2)
.
(4.2)
Для згрупованої вибірки вибірковим середнім називають статистику
![]() (4.3)
(4.3)
(тут
![]() - середні точки інтервалів групування;
- середні точки інтервалів групування;
- абсолютні частоти цих інтервалів).
Вибіркове середнє
використовується як оцінка теоретичного
математичного сподівання Мξ.
Величина
![]() ,
обчислена за формулою (4.2), є незсуненою
обґрунтованою оцінкою Мξ.
,
обчислена за формулою (4.2), є незсуненою
обґрунтованою оцінкою Мξ.
Оцінка дисперсії та середнього квадратичного відхилення
Для незгрупованої вибірки:
- вибірковою дисперсією називають статистику
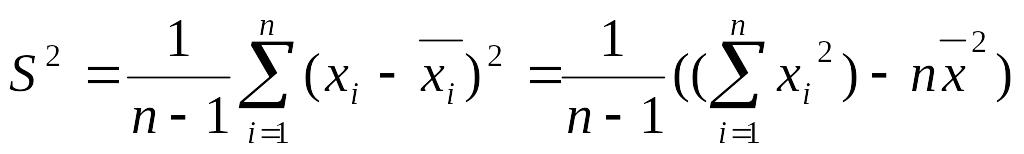 ;
(4.4)
;
(4.4)
- другим вибірковим центральним моментом називають статистику
![]() (4.5)
(4.5)
Для згрупованої вибірки:
- вибірковою дисперсією називають статистику
![]() ;
(4.6)
;
(4.6)
- другим вибірковим центральним моментом називають статистику
![]() (4.7)
(4.7)
де fi - абсолютна частота,
- середина і-го інтервалу групування,
обчислюється за формулою (4.3).
Вибірковим
середнім квадратичним відхиленням
називається статистика
![]() .
Статистики
.
Статистики
![]() та
та
![]() є статистичними оцінками середнього
квадратичного відхилення
випадкової величини .
є статистичними оцінками середнього
квадратичного відхилення
випадкової величини .
Оцінка медіани
Для незгрупованої вибірки для оцінки med розглядається елемент рангу (див. розділ 1), який називається вибірковою медіаною і позначається med або med х.
Д ля
згрупованої вибірки
в якості оцінки медіани можна взяти
абсцису точки перетину прямої у
= 0,5 та графіка функції кумулятивних
відносних частот (див. розділ 3). На
рисунку 4.1 зображено знаходження медіани
для згрупованої вибірки.
ля
згрупованої вибірки
в якості оцінки медіани можна взяти
абсцису точки перетину прямої у
= 0,5 та графіка функції кумулятивних
відносних частот (див. розділ 3). На
рисунку 4.1 зображено знаходження медіани
для згрупованої вибірки.
Рис.4.1
4) Оцінка моди
Для незгрупованої вибірки за оцінку моди mоd приймається вибірковий елемент, що має найбільшу частоту (див. таблицю частот в розділі 1 ) і позначається mоd.
Для згрупованої вибірки для обчислення моди використовується формула
![]() , (4.8)
, (4.8)
де m – номер модального інтервалу групування (тобто того, який містить максимальну кількість вибіркових значень);
h = am+1 - am; d = | fm - fm-1 |; d = | fm+1 - fm |.
Зміст формули (4.8) зрозумілий з рисунку 4.2.


Зауважимо, що якщо fm-1= fm= fm+1, то права частина формули (4.8) не визначена. В цьому випадку покладають:
![]() .
.
Якщо m = 1 або m = k, то у першому випадку покладають fm-1 = 0, а в другому fm+1 = 0.
Симетричність вибірки
Якщо випадкова величина має симетричний розподіл, то слід сподіватися, що вибірка, отримана при дослідженні , також симетрична, тобто “симетрично” розсіяна навколо деякого центру. Ознакою симетричності вибірки є так зване емпіричне правило Юла: симетрична вибірка повинна мати одну моду, яка може бути обчислена за формулою:
![]() (4.9)
(4.9)
Для конкретності наближену рівність розуміємо так: вибіркова мода відрізняється від моди, отриманої за формулою (4.9), не більше ніж на 10% від середнього квадратичного відхилення.
Контрольні питання
Що таке статистична оцінка числового параметру випадкової величини?
Назвіть відомі вам критерії якості статистичних оцінок.
Що таке збіжність за імовірністю?
Чому статистичну оцінку ми вважаємо випадковою величиною?
Що таке статистика?
Які числові параметри можуть прийматися за центр розсіювання випадкової величини?
Що таке математичне сподівання випадкової величини? Сформулюйте основні властивості математичного сподівання.
Яку статистику приймають за оцінку математичного сподівання?
Довести, що величина , обчислена за формулою (4.2), є обґрунтованою незсуненою оцінкою математичного сподівання.
Що таке дисперсія? Назвіть основні властивості дисперсії. Що характеризує дисперсія? Як оцінити її за вибіркою?
Які статистики наближують середнє квадратичне відхилення?
Що таке медіана випадкової величини? Як оцінюється медіана за вибіркою?
Що таке мода випадкової величини?
Що є ознакою симетричності вибірки?
Назвіть відомі вам методи точкового статистичного оцінювання та сформулюйте, в чому саме вони полягають.
Розділ 5. Статистичні оцінки квантилів
Означення. Квантилем рівня ( 0 < < 1 ) у випадку неперервних розподілів називається число U , яке є найменшим розв’язком рівняння = , де – функція розподілу досліджуваної випадкової величини.
Геометрично це означає, що квантиль рівня - це найменша з абсцис точок перетину прямої у = з графіком функції у = (рис.5.1).
Зауваження. При означенні квантиля рівня слова “найменший розв’язок” необхідні для усунення неоднозначності, яка може виникати при розв’язанні рівняння = . Так, наприклад, графіки функцій у = та у = можуть мати нескінченну множину спільних точок (тобто рівняння у = має нескінченну кількість розв’язків), в той час як квантиль рівня визначається однозначно.

Рис. 5.1
Означення. Процентилем рівня ( 0 < < 100 ) називається число Q, яке зв’язане з квантилем співвідношенням: Q= U(/100)
Так, наприклад, Q30 = U0,3; Q50= U0,5.
Означення. Вибірковий квантиль рівня - це число U , яке має ту властивість, що приблизно -частина вибіркових даних менше за число U.
Зауваження. Дане означення не визначає вибірковий квантиль однозначно. В літературі можна зустріти різні рекомендації щодо обчислення вибіркових квантилів. Вони несуттєво відрізняються один від одного.
Аналогічну властивість має вибірковий процентиль Q: менше за Q приблизно % вибірки. Дане означення вибіркового квантиля (процентиля) пов’язане з тією властивістю теоретичного квантиля, що для неперервної випадкової величини квантиль рівня задовольняє умові: P( <U ) = , тобто імовірність того, що випадкова величина під час експерименту прийме значення менше за число U, дорівнює . (Наприклад, якщо U0,3 = -7, то P( < -7 ) = 0,3.)
Вибіркові квантилі (процентилі) U (Q) є наближенням для теоретичних квантилів U (процентилів Q).
Знаходження вибіркових квантилів (процентилів)
- за незгрупованою вибіркою
Для знаходження вибіркового квантиля (процентиля) рівня треба спочатку знайти ранг цього квантиля (процентиля). В літературі можна знайти різні вирази з цього приводу. В даній роботі рекомендуються наступні формули:
![]() (для квантилів) (5.1)
(для квантилів) (5.1)
![]() (для
процентилів) (5.2)
(для
процентилів) (5.2)
де n – об’єм вибірки.
Наприклад,
якщо
=
0,3, n=80,
то маємо:
![]() .
.
Якщо ранг вибіркового елемента відомий, то легко знайти відповідний вибірковий елемент (див. розділ 1).
- за згрупованою вибіркою
Будемо знаходити вибіркові квантилі (процентилі) графічним способом. Для цього використаємо графік кумулятивної функції розподілу відносних частот (див. розділ 3). На рівні, що відповідає заданому числу , проведемо пряму у = до перетину з кумулятою. Найменша з абсцис точок перетину графіків і є шуканий квантиль (див. рис. 5.1).
Зауваження. При проведенні прямої у= необхідно узгодити рівень з одиницями, в яких проградуйована вісь Оу. Якщо вісь Оу проградуйована в процентах, то - рівень квантиля – необхідно помножити на 100, а рівень процентиля залишити без змін.
Контрольні питання
1. Що таке квантиль (процентиль) рівня у випадку неперервних розподілів?
2. Який статистичний та імовірнісний зміст квантиля рівня ?
3. Як зв’язані між собою квантилі і процентилі?
4. Яка частина вибірки лежить між числами
![]() і
і
![]() ?
?
5. Якому методу статистичного точкового оцінювання відповідає графічний спосіб за згрупованою вибіркою?
Розділ 6. Інтервальні оцінки параметрів нормально розподіленої випадкової величини
У попередньому розділі вивчалися точкові оцінки невідомих числових параметрів випадкової величини, тобто оцінки, що задавалися одним числом. Якщо оцінка * наближувала параметр , то виникало питання, наскільки точне це наближення, тобто яке відхилення * від . Додатнє число , для якого виконується рівність | *- | < характеризує точність оцінки * для параметра . Чим менше число , тим краще оцінка * наближує . Але * - випадкова величина, та й параметр невідомий. Тому про нерівність | *- | < (або її еквівалент *- < < * + ) можна говорити лише з деякою імовірністю. Треба навчитися будувати інтервали, які накриють шукані параметри з потрібною імовірністю.
Означення. Довірчим інтервалом рівня (0 < < 1) для невідомого параметра називають числовий інтервал [z1, z2], який накриває невідомий параметр з імовірністю (1-), тобто
P{ [z1, z2] } = 1- (6.1)
Число (1-) називають надійністю, або довірчою імовірністю відповідного інтервалу.
При побудові довірчих інтервалів число задається заздалегідь. Найчастіше за береться одне з чисел = 0,1, = 0,05 або = 0,01. Тоді відповідні надійності: 0,9, 0,95 або 0,99. Відзначимо, що інтервальні оцінки невідомих параметрів задаються двома числами z1, z2 - початком і кінцем інтервалу, якому повинен належати невідомий параметр з відповідною імовірністю.
Для побудови довірчих інтервалів необхідно знати розподіли величин, які при цьому використовуються.
Означення. Нехай 1, 2, ... , n – незалежні випадкові величини, кожна з яких має розподіл N(0;1). Тоді, за означенням, випадкова величина = 12 + 22 + ... + n2 має розподіл 2 з n ступенями свободи (позначення ~ n2).
Означення. Нехай 1
та 2 -
незалежні випадкові величини, причому
1 ~
N(0;1), а 2
~ n2.
Тоді, за означенням, випадкова величина
 має розподіл Стьюдента з n
ступенями свободи (позначення
~ tn).
має розподіл Стьюдента з n
ступенями свободи (позначення
~ tn).
Побудова довірчих інтервалів для невідомих математичного сподівання та дисперсії нормально розподіленої випадкової величини базується на теоремі:
Якщо x1, x2, …, xn - вибірка з теоретичним розподілом N(μ; σ), то:
1) статистики та S2 - незалежні
(нагадаємо,
що
![]() ;
;
![]() )
;
)
;
2)
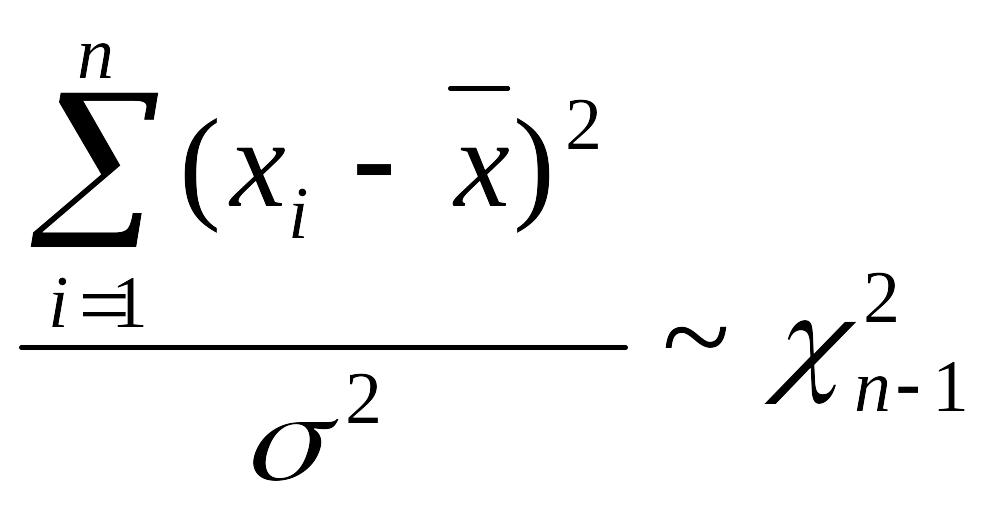 ;
;
3)
![]() .
.
За допомогою цієї теореми легко довести, що за умови нормальності теоретичного розподілу
а) довірчим інтервалом рівня a для математичного сподівання є інтервал
![]() ,
,
де
![]() - квантиль рівня 1-/2
розподілу Стьюдента з n-1
ступенями свободи. Квантилі t -
розподілу знаходяься за таблицею додатку
3. Для значення об’єму вибірки n,
якого немає у таблиці, потрібно знайти
наближене проміжне значення квантиля
Un
до двох сусідніх
- квантиль рівня 1-/2
розподілу Стьюдента з n-1
ступенями свободи. Квантилі t -
розподілу знаходяься за таблицею додатку
3. Для значення об’єму вибірки n,
якого немає у таблиці, потрібно знайти
наближене проміжне значення квантиля
Un
до двох сусідніх
![]() і
і
![]() згідно з наступною формулою
згідно з наступною формулою
![]() ,
,
де ni < n < ni+1.
б) довірчим інтервалом рівня a для дисперсії є інтервал
 ,
,
де
![]() - квантиль рівня 1-/2
розподілу 2
з n-1 ступенями
свободи. Квантилі 2-розподілу
знаходяться за таблицею додатку 4. Якщо
значення об’єму вибірки n
відсутнє у таблиці, то квантиль Un
визначається як наближене проміжне
значення до двох сусідніх
і
згідно з наступною формулою
- квантиль рівня 1-/2
розподілу 2
з n-1 ступенями
свободи. Квантилі 2-розподілу
знаходяться за таблицею додатку 4. Якщо
значення об’єму вибірки n
відсутнє у таблиці, то квантиль Un
визначається як наближене проміжне
значення до двох сусідніх
і
згідно з наступною формулою
![]() ,
,
де ni < n < ni+1.
Контрольні питання
1. Що таке інтервальна оцінка? Чим вона відрізняється від точкової?
2. Як розуміти термін “точність оцінки”? Чому про точність інтервальної оцінки можна говорити лише з деякою імовірністю?
3. Що таке довірчий інтервал рівня для невідомого параметра?
4. Пояснити зміст рівності (6.1).
5. За допомогою якої теореми будуються довірчі інтервали для невідомих математичного сподівання та дисперсії нормально розподіленої випадкової величини?
6. Як знайти вибіркову дисперсію, якщо відомі відповідні довірчі інтервали та об’єм вибірок?
Розділ 7. Перевірка статистичних гіпотез - 1.
Гіпотези відносно імовірностей та середніх значень