

Модель Джелинского-Моранды, Шика-Волвертона.
Модель Джелинского-Моранды. Допущения у модели:
Время до очередного отказа распределено по экспотенциальному закону
Все ошибки равновероятны и их появление не зависит друг от друга
Частота появления ошибок (функция риска, интенсивность отказа) пропорциональна числу не выявленных ошибок
λ(ti) = Kjm * [Eo – (i - 1)], где Eo – число ошибок в ПО до начального тестирования, Kjm – коэффициент Джелинского-Моранды, ti – интенсивность времение между i = 1 и i, обнаруженной ошибкой и число ошибок, обнаруженных к моменту отладки t.
λ(ti) постоянна на интервале между 2-мя смежными моментами появления ошибок
Каждая обнаруженная ошибка в ПО немедленно устраняется и число ошибок уменьшается на 1
Ошибки корректируются без внесения новых ошибок
Модель Шика-Волвертона. Дополнительно к модели Джелинского-Моранды используются:
Частота появления ошибок пропорциональна времени отладки программы ti:
λ(ti) = Kjm * [Eo – (i - 1)] * ti
Геометрическая модель.
В данной модели предполагается, что исходное число ошибок в программе – эта величина нефиксированная и все ошибки не равновероятны. Считается, что по мере отладки обнаруживать ошибки становится труднее. Т.о. ПО никогда не освобождается от ошибок.
Основные предпосылки этой модели:
Общее число ошибок неограниченно.
Обнаружение ошибок равновероятно.
Обнаружение ошибок – процесс независимый от ошибок.
ПО работает к условиям близким к реальным.
Интенсивность обнаружения ошибок образует геометрическую прогрессию, и она в интервале между появлениями ошибок постоянна.
λ(ti) = D *
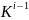 , где λ(0) = D , D
– исходное значение интенсивности
отказа, К – константа пропорциональности,
0<K<1, ti –
время между появлениями i-1
и i-ой обнаруженной ошибок.
, где λ(0) = D , D
– исходное значение интенсивности
отказа, К – константа пропорциональности,
0<K<1, ti –
время между появлениями i-1
и i-ой обнаруженной ошибок.
Как правило, интенсивность геометрической модели определяется методом максимального правдоподобия.
Статистическая модель Миллса.
В программу заносится несколько известных ошибок S. Эти ошибки вносятся случайным образом. Затем делается предполжение, что вероятность обнаружения собственных ошибок и обнаруженных одинакова. Т.о., тестируя программу и отсортировывая собственные и внесенные ошибки, можно оценить превоначальное число ошибок в программе E0:
Е0 = S*n / V
S – количество внесенных ошибок
n – количество найденных собственных ошибок
V – число найденных внесенных ошибок.
Достоинства:
1) математически проста и интуитивно понятна;
2) психологическое –при обнаружении не всех внесенных ошибок тестирование вынуждено продолжаться.
Недостатки:
1) Процесс внесения ошибок, т.к. предполагается что чобственные и внесенные ошибки появляются с равной вероятностью. Т.о, вносимые ошибки должны быть типичны для этой программы.
Модель Нельсона.
В основе модели лежит представление программы в виде некоторой функции F(Ei), где Ei набор значений данных, необходимых для выполнения набора программы
E = {Ei|i = 1,2,…,N} – число возможных наборов вх. данных
Выполнение (прогон) программы приводит к получению для каждого Ei определенного значения F(Ei). Наличие дефектов в программе приводит к тому, что получается некоторая F', отличная от F. Для некоторого Ei отклонение F’ от F находится в некоторых допустимых пределах ∆I, т.е. для получения премнемого результата необходимо выполнение сл.условия |F’(Ei) – F(Ei)| <= i
Множество наборов, не удовлетворяющих данному условию, образуют подмножество Ee и называется рабочими отказами.
Вероятность Q того, что прогон программы приведет к отказу равна вероятности, что набор входных данных Ei, используемый в данном прогоне, принадлежит множетсву Ee
Q = ne/N, N – число возможных наборов значений входных данных,
ne – число различных наборов значений, содержаихся в Ee
P = 1 – Q – вероятность удачного прохода.