

4.2.2 Удаление таблиц и изменение их структуры
Команда удаления таблицы имеет вид:
DROP имя_таблицы
Нельзя удалить таблицу, если существует внешние ключи, ссылающиеся на эту таблицу. Вместе с таблицей удаляются и созданные для нее индексы и триггеры.
Команда изменения структуры таблицы выглядит так:
ALTER TABLE имя_таблицы указания_по_изменению_структуры
Следует подчеркнуть, что команда ALTER TABLE служит для изменения в определении таблицы и может быть применена только к существующим таблицам. В качестве указаний по изменению структуры таблицы могут использоваться следующие фразы:
ADD [COLUMN] определение_столбца – добавить столбец.
Например:
ALTER TABLE t ADD n NUMBER(4) NOT NULL (t— имя существующей таблицы, n — имя нового столбца )
ADD [CONSTRAINT] ограничение — добавить ограничение.
Например:
ALTER TABLE t ADD PRIMARY KEY(n)
или
ALTER TABLE t ADD CONSTRAINT pk_t PRIMARY KEY(n)
В последнем примере ограничение первичного ключа получит имя pk_t
DROP COLUMN имя_столбца
DROP [CONSTRAINT] ограничение
Например:
ALTER TABLE t DROP PRIMARY KEY(n)
или
ALTER TABLE t DROP CONSTRAINT pk_t
ALTER TABLE t DROP COLUMN n
ALTER (MODIFY в Oracle) новое_определение_существующего_столбца
При этом можно изменить тип, размер, ограничение NULL/NOT NULL, значение по умолчанию. Конечно, нельзя изменить имя столбца. Для этого следует удалить столбец со старым именем и добавить новый столбец с нужным именем;
Следует отметить, что во многих случаях команда ALTER TABLE позволяет внести изменения в структуру таблицы, уже заполненной данными (если они удовлетворяют вводимым ограничениям). В некоторых случаях требуется, чтобы столбец был пустым, например, сервер Oracle при удалении столбца требует выполнения этого условия.
Например:
ALTER TABLE t
MODIFY c2 VARCHAR(200)
Увеличили предельный размер текста для столбца c2
4.2.3 Пример создания базы данных
Создадим демонстрационную базу данных из трех таблиц (Студенты, Предметы и Оценки), которая будет хранить сведения об успеваемости студентов. Структура данной БД, конечно, сильно упрощена по сравнению с тем, что требуется для решения реальной задачи учета успеваемости студентов. Однако как пример для обучения основам SQL такая структура вполне подойдет. Назначение каждого столбца на изображенной ниже схеме, очевидно, понятно (рис. 4.1).
Схема Базы Данных:
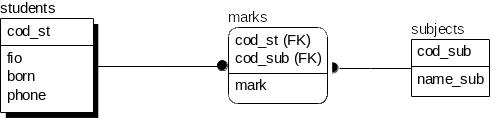
Рис. 4.1 – Схема демонстрационной базы данных
Приведем различные варианты команд DML для создания трех таблиц базы данных.
Создание таблицы students:
CREATE TABLE students
(
cod_st NUMBER(5) PRIMARY KEY,
name_st VARCHAR(100) NOT NULL,
born DATE NOT NULL,
phone CHAR (15)
)
Создание таблицы subjects:
CREATE TABLE subjects
(
cod_sub NUMBER (4),
name_sub VARCHAR(200) NOT NULL
)
Изменение таблицы subjects, добавление первичного ключа:
ALTER TABLE subjects
ADD PRIMARY KEY (cod_sub)
Изменение таблицы subjects, добавление ограничения уникальности названия предмета:
ALTER TABLE subjects
ADD UNIQUE (name_sub)
Создание таблицы marks:
CREATE TABLE marks
(
cod_st NUMBER(5) NOT NULL REFERENCES students
ON DELETE CASCADE,
cod_sub NUMBER(4) NOT NULL REFERENCES subjects ,
mark NUMBER(1) CHECK (mark BETWEEN 2 AND 5),
PRIMARY KEY(cod_st, cod_sub)
)