

Модели данных, которые используются для хранения данных (Эдгар Кодд)
FASMI (БАРМИ) — 5 требований :
Fast. Анализ должен быть быстрым. Время отклика не более 5 с.
Analysis. Предполагает возможность основных типов статистического и числового анализа, который задается в приложении или пользователем.
Shared. Контроль доступа пользователей к информации.
Multidimensional. Многомерная.
Information. Возможность обращаться к любой информации независимо от места хранения.

Средства OLAP делятся на два класса:
Серверный OLAP;
OLAP-приложения.
В настоящее время существуют три подхода к построению хранилищ данных:
Многомерная модель хранилища (MOLAP).
Реляционная (ROLAP).
Гибридная (HOLAP).
Правила Кодда
Многомерность представления данных. М-СУБД должна поддерживать многомерность, по крайней мере, на концептуальном уровне.
Прозрачность. Пользователь не должен знать, какие средства применяются для хранилища.
Доступность. М-СУБД должно автоматически отображать ответ на запрос наилучшим образом.
Производительность не должна зависеть от количества измерений.
Поддержка архитектуры клиент-сервер.
Равноправность всех измерений — не должно быть базовых измерений.
Динамическая обработка разряженных матриц.
Поддержка многопользовательского режима работы.
Поддержка операций должна быть для любых измерений.
Максимально удобный интерфейс.
Различные способы визуализации данных.
Неограниченное число измерений.
MOLAP
— структура хранения данных. При добавлении измерения гиперкуб перестраивается. Такая структура позволяет реализовать быстрое чтение и поиск данных (от 10 до 100).
Измерение — это множество, образующее одну из граней гиперкуба.
Значение — данные, которые подвергаются анализу в ячейках куба. Основные операции над гиперкубом:
Сечение — одно или больше значений фиксируется.
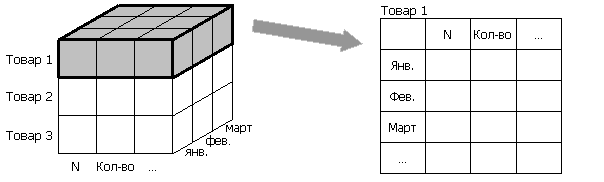
Вращение — изменение порядка представления измерения (применяется к двухмерным таблицам).
Свертка и детализация.

При свертке устанавливается иерархия измерений.
При свертке одно или более измерений замыкается значением более высокого уровня иерархии с агрегацией данных.
Недостатки MOLAP: Нерациональное использование памяти — все измерения и все аргументы функции хранятся в многомерном виде, много пустых ячеек.
MOLAP используют при небольшой базе данных и стабильном наборе измерений.
ROLAP
— гиперкуб эмулируется на логическом уровне.
Преимущество — база данных может быть большой. Недостаток — медленное выполнение аналитических запросов.
Базу данных представляют обычно в ненормализованном виде специальным образом. Используется два вида таблиц (структура — звезда):
Фактологическая таблица;
Таблица измерений или справочников.
В справочниках перечисляется множество значений одного измерения гиперкуба.

При большом числе измерений применяют схему, которая называется «снежинка» (атрибуты помещаются в отдельные таблицы).
HOLAP
В этом случае, при реализации запросов к хранилищу большое значение играют оптимизаторы СУБД. Основные данные хранятся в реляционной базе, а агрегированные — в многомерной структуре (кубе), так как ситуация, когда для анализа нужны все данные, возникает достаточно редко. Обычно каждый аналитик использует свое направление. В этом случае многомерные данные представляются в виде киосков данных.

Хранилища данных делятся на 4 группы в зависимости от размера:
Малые (до 106 ячеек данных)
Средние (до 108)
Крупные (~ 108)
Сверхбольшие (~ 109)
Большинство СУБД имеют специальные средства для создания хранилища данных.