

Порядок построения er-модели
каждом внешнем представлении выявить понятия и их свойства, исходя из анализа экономических документов. Их должно быть не более 6-7 в каждом представлении.
Обозначить понятия именами, которые должны быть краткими, отражать смысл и быть привычными для пользователя.
Выбрать ключевое свойство (свойства). Если такого нет, то вводят условное свойство «Порядковый №».
Выявить связи между понятиями и сущностями.
Найти общие свойства понятий (обобщение);
Рассмотреть все пары понятий и определить ассоциативные связи;
Определить степень каждой связи.
Записать формулы расчета, связывающие вычисляемые свойства.
Объединить модели, построенные для разных внешних представлений. Объединение ведут по 2-4 модели за один шаг, получая более сложные объекты и устраняя противоречия (например, разные наименования одних свойств и одинаковые – для разных понятий).
27. Любое упорядочение (расположение) данных на диске называется структурой хранения. Совершенная СУБД должна содержать несколько разных структур хранения для различных частей системы. Следует также предусмотреть возможность изменения структуры хранения по мере изменения требований к производительности системы.
Индексирование.
Важнейшим элементом любой СУБД является наличие средств ускоренного поиска данных. Этот механизм обычно реализуется введением так называемы индексных файлов с расширением idх и cdx. Один файл базы данных может быть проиндексирован по нескольким полям и иметь любое число индексов. Эти файлы содержат один элемент, так называемый индексный ключ. Этот ключ позволяет отсортировать записи данных в алфавитном, хронологическом или числовом порядке для поля, по которому выполнено индексирование. Допускается индексирование и по логическим полям.
Различают два типа индексных файлов:
Простой индексный файл имеет расширение файла IDX и содержит один индексный ключ. Существуют также компактные простые индексные файлы, которые благодаря сжатию данных, занимают приблизительно в шесть раз меньше места по сравнению с обычным индексным файлом.
Составной (мультииндексный) файл имеет расширение CDX и может осуществлять управление одновременно несколькими индексными ключами, хранящихся в индексном выражении. Отдельные ключи называются тегами. Каждый тег имеет свое имя.
Составные файлы могут быть двух видов:
Структурный составной файл имеет такое же имя файла как и файл базы данных. Данный индексный файл всегда автоматически открывается вместе со своей базой данных. Его нельзя закрыть до ее закрытия, но можно сделать не активным.
Обычный составной файл имеет произвольное имя файла, не совпадающее с именем файла базы данных.
28. Любое упорядочение (расположение) данных на диске называется структурой хранения. Совершенная СУБД должна содержать несколько разных структур хранения для различных частей системы. Следует также предусмотреть возможность изменения структуры хранения по мере изменения требований к производительности системы, для ускорения доступа к данным.
Хеширование
Суть методов хеширования состоит в том, что мы берем значения ключа (или некоторые его характеристики) и используем его для начала поиска, то есть мы вычисляем некоторую хеш-функцию h(k) и полученное значение берем в качестве адреса начала поиска. То есть мы не требуем полного взаимно-однозначного соответствия, но, с другой стороны, для повышения скорости мы ограничиваем время этого поиска (количество дополнительных шагов) для окончательного получения адреса. Таким образом, мы допускаем, что нескольким разным ключам может соответствовать одно значение хеш-функции (один адрес). Подобные ситуации называются коллизиями. Значения ключей, которые имеют одно и то же значение хеш-функции, называются синонимами. Вероятность возникновения коллизий играет немаловажную роль в оценке качества хеш-функций.
Поэтому при использовании хеширования как метода доступа необходимо принять два независимых решения:
Выбрать хэш-функцию;
Выбрать метод разрешения коллизий.
Для ускорения доступа к данным в таблицах можно использовать предварительное упорядочивание таблицы в соответствии со значениями ключей.
Например, для ускорения доступа к данным в таблицах можно использовать предварительное упорядочивание таблицы в соответствии со значениями ключей. Для сокращения времени доступа к данным в таблицах используется случайное упорядочивание или хеширование. При этом данные организуются в виде таблицы при помощи хеш-функции h, используемой для вычисления адреса по значению ключа.
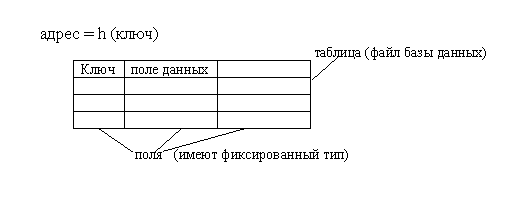
Идеальной хеш-функцией является такая hash-функция, которая для любых двух неодинаковых ключей дает неодинаковые адреса. k1<>k2 => h(k1) <> h(k2). Подобрать такую функцию можно в случае, если все возможные значения ключей заранее известны. Такая организация данных носит название совершенное хеширование. В случае заранее неопределенного множества значений ключей и ограниченной длины таблицы подбор совершенной функции затруднителен. Поэтому часто используют хеш-функции, которые не гарантируют выполнение условия.