

3)Архитектуры приложений. Основные различия между архитектурами приложений.
Основная архитектура приложения может принимать различные формы. Основные различия между архитектурами приложений состоят в количестве систем, участвующих в работе приложения. Эта классификация производится по количеству звеньев (tiers).
Система SQL Server может быть реализована либо как:
клиент-серверная,
автономная "настольная" система.
Клиент-серверная система SQL Server может иметь:
двухзвенную установку (two-tiersetup),
трехзвенную установку (three-tiersetup).
Независимо от варианта установки, ПО и БД SQL Server размещаются на центральном компьютере, который называется сервер базы данных (database server).
Пользователи работают на отдельных компьютерах, которые называются клиенты (clients).
Доступ пользователей к серверу базы данных производится в:
двухзвенных системах при помощи приложений с их компьютеров-клиентов;
в трехзвенных системах при помощи приложений, выполняющихся на специально предназначенном для этой цели компьютере, который называется сервер приложений (application server).
Двухзвенная архитектура:
В двухзвенных приложениях службы представления и БД размещаются на разных системах (компьютерах).
При помощи двухзвенных приложений каждый пользователь может иметь одно или несколько соединений с БД SQL Server.
Трехзвенная архитектура:
В трехзвенных приложениях уровень БД, уровень приложения и уровень служб представления выделены в три разные компоненты.
В типичных трехзвенных приложениях используется промежуточный уровень для обслуживания многочисленных соединений от уровня служб представления, благодаря чему уменьшается количество соединений с SQL Server. Кроме того, этот промежуточный уровень может выполнять значительный объем работы, связанной с реализацией специфики целевых задач (логики предметной области), освобождая БД для решения тех задач, которые она выполняет лучше всего, – для доставки требуемых данных.
Однозвенная архитектура
Однозвенная (one-tier, single-tier) архитектура – это система, в которой все службы БД, приложения и представления (пользовательский интерфейс) размещены на одной системе. Системы такого типа не производят обработку вне тех компьютеров, на которых они исполняются.
Примером однозвенной архитектуры может служить БД Microsoft Аccess с локальными службами представления.
Пример однозвенной архитектуры с SQL Server найти гораздо труднее.
4)Абстрактный тип данных «Стек». Методы реализации стеков.
Стек - это специальный тип списка, в котором все вставки и удаления выполняются только на одном конце, называемом вершиной (top). Для обозначения стеков иногда используется аббревиатура LIFO (last-in-first-out - последний вошел - первый вышел).
Области применения стека
передача параметров в функции;
трансляция (синтаксический и семантический анализы, генерация кодов и т.д.);
реализация рекурсии в программировании;
реализация управления динамической памятью и т.п.
Операторы, выполняемые над стеком
1. MAKENULL(S) -Делает стек S пустым.
2. TOP(S). -Возвращает элемент из вершины стека S.
3. POP(S). - Удаляет элемент из вершины стека
4. PUSH(x, S). - Вставляет элемент х в вершину стека S (заталкивает элемент в стек). Элемент, ранее находившийся в вершине стека, становится элементом, следующим за вершиной, и т.д. В терминах общих операторов списка данный оператор можно записать как
5. EMPTY(S)- возвращает значение true (истина), если стек S пустой, и значение false (ложь) в противном случае.
Методы реализации стеков
Стеки могут представляться в памяти либо в виде вектора, либо в виде цепного списка.
При векторном представлении под стек отводится сплошная область памяти, достаточно большая, чтобы в ней можно было поместить некоторое максимальное число элементов, которое определяется решаемой задачей.
В процессе заполнения стека место последнего элемента (его адрес ) помешается в указатель вершины стека.
Если указатель выйдет за верхнюю границу стека, то стек считается переполненным и включение нового элемента становится невозможным.
Поэтому для стека надо отводить достаточно большую память, однако если стек в процессе решения задачи заполняется только частично, то память используется неэффективно.
Так как под стек отводится фиксированный объем памяти, а количество элементов переменно, то говорят, что стек в векторной памяти - это полустатическая структура данных.
Списковая структура стека
При списковом представлении стека память под дескриптор и под каждый элемент стека получают динамически.
Включение и выборка элемента осуществляются с начала списка, которое одновременно является вершиной стека. Переполнение стека в этом случае не происходит, однако алгоритмы обработки сложнее.
Схема реализации стека с помощью массива
Можно зафиксировать "дно" стека в самом низу массива (в ячейке с наибольшим индексом) и позволить стеку расти вверх массива (к ячейке с наименьшим индексом).
К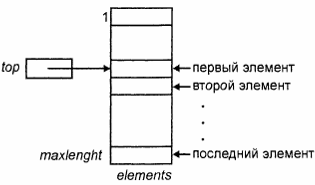 урсор
с именем top
(вершина) будет указывать положение
текущей позиции первого элемента стека.
урсор
с именем top
(вершина) будет указывать положение
текущей позиции первого элемента стека.
Для такой реализации стеков можно определить абстрактный тип STACK следующим образом:
type STACK = record
top: integer;
element: array[1..maxlength] of elementtype
end;
В этой реализации стек состоит из последовательности элементов
element[top], element[top + 1], ..., element[maxlength].
Билет №14.