

Продукционные модели. Пример
В модели знаний на основе продукций знания представлены совокупностью правил в формате «ЕСЛИ - ТО».
Как правило, задача, формулируемая для продукционной системы, имеет одну из следующих структур
<S°,Sf -?>, (1.1)
<S0 - ?, Sf >, (1.2)
<S°,Sf, A - ?>, (1.3)
<S°,Sf - ?, A - ?>, (1.4)
где S0 - начальная ситуация, Sf - конечная (желаемая, требуемая ситуация), А -алгоритм (последовательность выполняемых продукций), переводящий систему из состояния S0 в состояние Sf.
Задача (1.1) связана с определением ситуации (состояния) Sf, удовлетворяющей некоторому критерию, которая может быть получена из заданной начальной ситуации.
Задача (1.2) является обратной по отношению к предыдущей.
Задача (1.3) заключается в отыскании алгоритма преобразования начальной ситуации в конечную.
Задача (1 .4) представляет обобщение задач (1 .1) и (1 .3).
Продукции удачно моделируют человеческий способ рассуждений при решении проблем. Поэтому продукции широко используются во многих действующих ЭС.
Продукционные системы впервые изобретены Постом в 1941 г. Продукция в системе Поста имеет следующую схему
 (1.5)
(1.5)
где t1,t2,...,tn называются посылками, а t заключением продукции.
Применение схемы (1.5) основывается на подстановке цепочек знаков вместо всех переменных, причем вместо вхождений одной и той же переменной подставляется одна и та же цепочка.
Иерархическое разбиение множества продукций позволяет более эффективно организовать их выполнение, существенно сократив затраты на перебор множества продукций при проверке условий их срабатывания, что определяет дополнительный интерес к продукционным системам.
В рамках этой модели продукция определяется четверкой:
P = < L, C, N, A >,
где L - метка; С - условие применимости; N - ядро продукции; А - постдействие. Следующий пример демонстрирует полную продукцию:
МЕТКА: R26 Использование зонтика
УСЛОВИЕ: ЕСЛИ (идет дождь)
ДЕЙСТВИЕ (ЯДРО ПРОДУКЦИИ): ТО (возьмите зонтик)
ОБЪЯСНЕНИЕ (ПОСТДЕЙСТВИЕ): (зонтик предохраняет от дождя)
Продукция может быть записана также в следующем виде:
(i): P; A => B; Q,
здесь i - номер продукции, с помощью которого данная продукция выделяется из множества продукций. В качестве номера (имени) может выступать некоторая лексема, отражающая суть продукции.
A ==B - ядро продукции. Символ == трактуется как знак логического следования В из истинного А. (Если А не истинно, то о В ничего сказать нельзя).
Р - условие применимости ядра продукции (предусловие правила).
Q - постусловие, которое описывает действия и процедуры, выполняемые после реализации ядра.
10. Логические модели. Исчисление предикатов. Пример.
Традиционно в представлении знаний выделяют формальные логические модели, основанные на классическом исчислении предикатов I-го порядка, когда предметная область или задача описывается в виде набора аксиом.
В основе логических моделей лежит понятие формальной теории, задаваемой четверкой
S = (B, F, A, R), где
^ B — счетное множество базовых символов (алфавит) теории S;
^ F — подмножество S, называемых формулами теории (под выражениями понимаются конечные последовательности базовых символов теории S). Обычно существует эффективная процедура (множество синтаксических правил), позволяющая строить из B синтаксически правильные выражения — формулы;
^ A — выделенное множество формул, называемых аксиомами теории S, т.е. множество априорно истинных формул;
^ R — конечное множество отношений r1,... , rn между формулами, называемыми правилами вывода.
Формальная теория называется разрешимой, если существует единая эффективная процедура, позволяющая узнать для любой данной формулы, существует ли ее вывод в S.
Формальная система S называется непротиворечивой, если не существует формулы A, такой, что A и — A выводимы в S.
Наиболее распространенной формальной системой, которая используется для представления знаний, является исчисление предикатов первого порядка. Алфавит исчисления предикатов состоит из следующего набора символов:
- знаков пунктуации {,(,,,),.,;,};
- пропозициональных связок
- знаков кванторов
- символов переменных Xk, k = 1, 2,...;
- n-местных функциональных букв
- n-местных предикатных букв (символов)
Из символов алфавита можно строить различные выражения. Выделяют термы, элементарные формулы (атомы) и правильно построенные формулы (или просто формулы). Всякий символ переменной или константной буквы есть терм.
Основной задачей, решаемой в рамках исчисления предикатов, является выяснение истинности или ложности заданной формулы на некоторой области интерпретации. При этом особая роль отводится общезначимым формулам, т.е формулам, истинным при любой интерпретации, и невыполнимым формулам, т.е формулам, ложным при любой интерпретации. Справедлива следующая основополагающая теорема дедукции.
Теорема 1. Пусть даны формулы B1,...,Bn и формула A. Формула A является логическим следствием B1 , . . . , Bn тогда и только тогда, когда формула B1 Л ... Л Bn — A общезначима, т.е. является истиной.
Известно, что для исчисления предикатов первого порядка не существует общего метода установления общезначимости любых формул, т.е. исчисление предикатов первого порядка является неразрешимым. Однако если некоторая формула исчисления предикатов общезначима, то существует процедура для проверки ее общезначимости, т.е. исчисление предикатов можно назвать полуразрешимым. Наиболее известными методами доказательства теорем являются метод резолюции и обратный метод.
Приведем пример записи некоторого факта в виде формулы исчисления предикатов:
ДАТЬ (МИХАИЛ, ВЛАДИМИРУ, КНИГУ);
(3 x)( ЭЛЕМЕНТ (x, СОБЫТИЕ-ДАТЬ) Л ИСТОЧНИК (x, МИХАИЛ) Л АДРЕСАТ (x, ВЛАДИМИР) Л ОБЪЕКТ (x, КНИГА)).
Здесь описаны два способа записи одного факта: «Михаил дал книгу Владимиру».
Мы опустим подробное описание логических моделей, т.к. исчисление предикатов 1-го порядка в промышленных экспертных системах практиче¬ски не используется в силу того, что они предъявляют очень высокие требо¬вания и ограничения к предметной области.
11. НЕ-факторы знаний.
Билет 11. НЕ-факторы знаний
Знания, извлеченные из экспертов, содержат различные виды НЕ-фкторов, в связи с чем соответствующие методы и процедуры получения знаний должны обеспечивать возожность извлечения и обработки не полностью известной инфорации.
В ходе использования комбинированного метода приобретения знаний (КМПЗ) для разработки нескольких прикладных ИЭС удалось накопить экспериментальный материал, связанный с построением БД для трех типов задач – диагностики, проектирования и планирования, позволивший разработать целый ряд подходов к выявлению и обработке высказываний эксперта о свойствах ПрО, содержащих элементы нечеткости, неопределенности, неточности, отдельных видов недоопределенности, а также неполноты.
Для рассмотрения подобных знаний сточки зрения процессов извлечения и структурирования удобно выделить 2 основные группы НЕ-факторов знаний:
НЕ-факторы, проявляющиеся в рассуждениях эксперта в эксплицитном виде
НЕ-факторы, выделить которые в процессе интервьюирования эксперта на основе КМПЗ не представляется возможным, т.к. для их выявления требуются специльные механизмы и подходы (н-р, интервьюирование нескольких экспертов). В связи с этим введен ряд определений :
Недостоверные знания – знания, которые содержат НЕ – факторы, проявляющиеся эксплицитно в рассуждениях эксперта (т.е. относящися к 1 группе). Проведенные теоретические исследования показали, что распространнеными НЕ-факторами, проявление которых было отмечено в знаниях, полученны от экспертов, являются нечеткость, неопределенность, неточность, недоопределенность.
Используя теоретико –множественный подход , т.е в терминах xϵF , где x – элемент некоторого множества F, введены следующие определения для каждого из них.
Неопределенность - это степень неуверенности, которую эксперт приписывает своим высказываниям, т.е. некоторый субъективный коэффициент неполной уверенности в высказывании xϵF, который в зависимости от метода, используемого для обработки этого коэффициента, может иметь вид и интервала уверенности.
Нечеткость есть свойство количественной оценки экспертом качественных понятий и отношений, которые он использует в своих рассуждениях , когда по количественной оценке элемента х невозможно однозначно сказать , принадлежит он множеству F или нет.
Неопределенность отличается от нечеткости тем, что коэффицент уверенности приписывается не к каждому элементу х некоторого множества (в случае нечеткости), а только к конкретному высказыванию. В случае вероятностной интерпретации функции принадлежности (ФП) неопределенность можно свести к нечеткости. Приобретение нечетких знаний является черезвычайно сложной задачей, т.к эксперты не в состоянии самостоятельно определить ФП множества F.
Неточность –это часто встречающийся НЕ-фактор, т.к эксперты в своих рассуждениях опрерирует параметрами, полученными при помощи кких-либо измерительных приборов, которые имеют относительную погрешность измерения. Отсюда возникают неточные значения измерительных величин.
Неполнота означает, что неизвестен либо элемент х, либо множество F.
В условиях приобретения знаний неполнота связана с тем, что эксперт не знает (не отметил) какого-либо факта, необходимого для решения задачи. Возможны следующие альтернативы преодоления неполноты: либо проведение нескольких сеансов приобретения знаний с одним экспертом и срвнение результатов, либо привлечение нескольких экспертов и корреляция их мнений, а также использование технологии извлечение знаний из БД .
Наибольший разброс мнений наблюдается при определении недоопределенности. 1 мнение: Недоопределенность является отдельным НЕ- фактором, который включет в себя как недоопределенность общих знаний, так и недоопределенность конкретных знаний. Другая часть авторов под недоопределенностью понимает совокупность трех вышеупомянутых НЕ –факторов.
Под недоопределенностью общих знаний понимается частичное отсутствие знаний проблемной/предметной области в целом.
Под недоопределенностью конкретных знаний понимается частичное отсутствие знаний об отдельных понятиях и отношениях проблемной/предметной области.
Другими словами, недоопределенность конкретных знаний проявляется тогда, когда на значение какой-либо величины накладываются ограничения, что обычно не вызывает затруднения у эксперта, поэтому недоопределенность конкретных знаний является ниболее легко и часто выявляемой в процессе приобретения знаний. Поскольку невозможно определить адекватность модели ПрО, которой обладает эксперт, реальному миру, то вопросы выявления недоопределенности общих знаний затруднены , в связи с чем под термином «недоопределенности» часто понимается только недоопределеннсть конкретных знаний.
12. Процесс приобретения знаний при разработке экспертных систем.
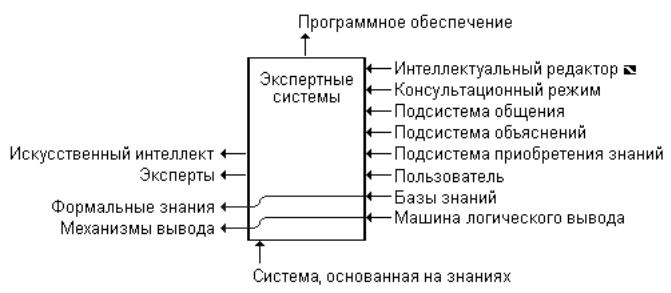
Рис. Связь основных понятий предметной области экспертной системы(ЭС)
Экспертная система (ЭС) – система искусственного интеллекта,включающая знания об определенной слабо структурированной и трудно формализуемой узкой предметной области и способная предлагать и объяснять пользователю разумные решения. ЭС состоит из базы знаний, механизма логического вывода и подсистемы объяснений.
Процесс получения знаний от эксперта (или из каких-либо других источников знаний) и передачи их экспертной системе называют приобретением знаний. Обычно источником знания является эксперт-человек, но могут быть и эмпирические данные и тексты, в которых содержатся сведения об области экспертизы. Процесс приобретения знаний важен и сложен. Качество и эффективность решения задач ЭС определяются качеством и количеством используемых ею знаний. Объем знаний, используемых экспертом, велик, так и тем, что знания эти не полностью осознаются экспертом.
Подсистема приобретения знаний (ППЗ)– программа, предназначенная для корректировки и пополнения базы знаний. ППЗ –– интеллектуальный редактор базы знаний, средства для извлечения знаний из баз данных, из неструктурированного текста, из графической информации и т.д.
ППЗ предназначена для добавления в базу знаний новых правил и модификации имеющихся. В ее задачу входит приведение правила к виду, позволяющему подсистеме вывода применять это правило в процессе работы. В более сложных системах предусмотрены еще и средства для проверки вводимых или модифицируемых правил на непротиворечивость с имеющимися правилами.
ЭС работает в двух режимах: режиме приобретения знаний и в режиме решения задачи
В режиме приобретения знаний общение с ЭС осуществляет (через посредничество инженера по знаниям) эксперт. эксперт, используя компонент приобретения знаний, наполняет систему знаниями, которые позволяют ЭС в режиме решения самостоятельно (без эксперта) решать задачи из проблемной области. Эксперт описывает проблемную область в виде совокупности данных и правил. Данные определяют объекты, их характеристики и значения, существующие в области экспертизы. Правила определяют способы манипулирования с данными, характерные для рассматриваемой области. режиму приобретения знаний в традиционном подходе к разработке программ соответствуют этапы алгоритмизации, программирования и отладки, выполняемые программистом. Т.о., в отличие от традиционного подхода в случае ЭС разработку программ осуществляет не программист, а эксперт (с помощьюЭС), не владеющий программированием.
Целесообразно
осуществить разбиение процесса
приобретения знаний на фазы,
отражающие изменение функций участников
проектирования (эксперта и инженера по
знаниям) и/или экспертной системы: 1)
предварительная фаза; 2) начальная фаза;
3) фаза накопления.
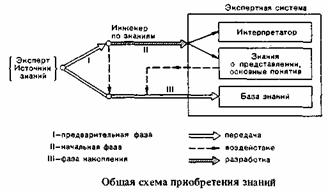 Предварительная
фаза приобретения знаний
.ЭС еще не существует (отсюда и название
фазы). Знания приобретаются инженером
по знаниям от эксперта. На этой фазе
задача инженера по знаниям состоит в
том, чтобы получить от эксперта основные
сведения об области экспертизы (основные
понятия, отношения, подзадачи и т.п.) и
сформировать на их основе общее
представление о структуре данных и
принципах построения экспертной системы.
Эта фаза приобретения знаний выполняется
на этапах идентификации, концептуализации
и формализации.
На
начальной фазе
осуществляется наполнение системы
знаниями о представлении, т.е. значениями,
определяющими организацию, структуру
и способ представления базы знаний. В
связи с тем, что для определения указанных
знаний необходимо владеть основами
программирования и детально понимать
функционирование проектируемой
экспертной системы, введение знаний на
начальной фазе может осуществлять
только инженер по знаниям, а не эксперт.
Начальная фаза осуществляется в ходе
первой стадии этапа выполнения.
В
ходе фазы
накопления
осуществляется приобретение основных
знаний об области экспертизы. На
современном уровне развития приобретение
знаний на этой фазе осуществляется
экспертом совместно с инженером по
знаниям. На фазе накопления решаются
следующие задачи: 1) обнаружение
неправильности, неполноты или
противоречивости знаний, используемых
экспертной системой; 2) извлечение новых
знаний, устраняющих обнаруженную
неправильность, неполноту или
противоречивость; 3) преобразование
новых знаний в вид, понятный экспертной
системе; 4) объединение "новых"
знаний со "старыми". Следует
отметить, что на данной фазе приобретаются
все виды знаний, необходимые для
эффективного и качественного
функционирования ЭС.
???
Модели приобретения знаний.
Процесс
приобретения знаний является наиболее
сложным этапом разработки экспертной
системы. Это объясняется тем, что обычно
инженер по знаниям плохо разбирается
в предметной области, а эксперт не знает
программирования. В связи с этим лексика,
используемая экспертом, непонятна
инженеру по знаниям. Чтобы уточнить и
расширить лексику, требуется совместная
работа эксперта и инженера по знаниям.
Одна из наиболее сложных задач, стоящих
перед инженером по знаниям, заключается
в том, чтобы помочь эксперту структурировать
знания о проблемной области.
Процесс
приобретения знаний можно свести к
последовательности выполнения следующих
задач:
1)
определяется необходимость модификации
(расширения) знаний;
2)
при необходимости модификации
осуществляется извлечение новых знаний,
в противном случае процесс приобретения
знаний заканчивается;
3)
новые знания преобразуются в форму,
"понятную" экспертной системе;
4)
знания системы модифицируются, и
осуществляется переход к первой
задаче.
В
выполнении перечисленных задач могут
принимать участие эксперт, инженер по
знаниям (программист) и экспертная
система. В зависимости от того, кто
выполняет задачу, можно выделить
различные
модели приобретения знаний.
Предварительная
фаза приобретения знаний
.ЭС еще не существует (отсюда и название
фазы). Знания приобретаются инженером
по знаниям от эксперта. На этой фазе
задача инженера по знаниям состоит в
том, чтобы получить от эксперта основные
сведения об области экспертизы (основные
понятия, отношения, подзадачи и т.п.) и
сформировать на их основе общее
представление о структуре данных и
принципах построения экспертной системы.
Эта фаза приобретения знаний выполняется
на этапах идентификации, концептуализации
и формализации.
На
начальной фазе
осуществляется наполнение системы
знаниями о представлении, т.е. значениями,
определяющими организацию, структуру
и способ представления базы знаний. В
связи с тем, что для определения указанных
знаний необходимо владеть основами
программирования и детально понимать
функционирование проектируемой
экспертной системы, введение знаний на
начальной фазе может осуществлять
только инженер по знаниям, а не эксперт.
Начальная фаза осуществляется в ходе
первой стадии этапа выполнения.
В
ходе фазы
накопления
осуществляется приобретение основных
знаний об области экспертизы. На
современном уровне развития приобретение
знаний на этой фазе осуществляется
экспертом совместно с инженером по
знаниям. На фазе накопления решаются
следующие задачи: 1) обнаружение
неправильности, неполноты или
противоречивости знаний, используемых
экспертной системой; 2) извлечение новых
знаний, устраняющих обнаруженную
неправильность, неполноту или
противоречивость; 3) преобразование
новых знаний в вид, понятный экспертной
системе; 4) объединение "новых"
знаний со "старыми". Следует
отметить, что на данной фазе приобретаются
все виды знаний, необходимые для
эффективного и качественного
функционирования ЭС.
???
Модели приобретения знаний.
Процесс
приобретения знаний является наиболее
сложным этапом разработки экспертной
системы. Это объясняется тем, что обычно
инженер по знаниям плохо разбирается
в предметной области, а эксперт не знает
программирования. В связи с этим лексика,
используемая экспертом, непонятна
инженеру по знаниям. Чтобы уточнить и
расширить лексику, требуется совместная
работа эксперта и инженера по знаниям.
Одна из наиболее сложных задач, стоящих
перед инженером по знаниям, заключается
в том, чтобы помочь эксперту структурировать
знания о проблемной области.
Процесс
приобретения знаний можно свести к
последовательности выполнения следующих
задач:
1)
определяется необходимость модификации
(расширения) знаний;
2)
при необходимости модификации
осуществляется извлечение новых знаний,
в противном случае процесс приобретения
знаний заканчивается;
3)
новые знания преобразуются в форму,
"понятную" экспертной системе;
4)
знания системы модифицируются, и
осуществляется переход к первой
задаче.
В
выполнении перечисленных задач могут
принимать участие эксперт, инженер по
знаниям (программист) и экспертная
система. В зависимости от того, кто
выполняет задачу, можно выделить
различные
модели приобретения знаний.
![]() В
ранних работах по искусственному
интеллекту взаимодействие с разрабатываемой
системой осуществлял только программист.
При разработке системы программисты
не отделяли знания (данные) от механизма
вывода. В задачу программиста входило
освоить с помощью эксперта предметную
область и затем при разработке системы
выступать в роли и эксперта, и программиста.
Недостаточное знание области экспертизы
не позволяло программисту гарантировать
полноту и непротиворечивость приобретенных
знаний. Неизбежные модификации системы
приводили (при отсутствии разделения
системы на базу знаний и механизм вывода)
к невозможности сохранить однажды
достигнутую непротиворечивость знаний.
В этой модели все перечисленные выше
задачи по приобретению знаний выполнял
программист.
Последующие
разработки систем искусственного
интеллекта основывались на отделении
знаний от программ и оформлении знаний
в виде простых информационных структур,
называемых базами знаний. В этом случае
эксперт взаимодействует с системой
через инженера по знаниям.
В
ранних работах по искусственному
интеллекту взаимодействие с разрабатываемой
системой осуществлял только программист.
При разработке системы программисты
не отделяли знания (данные) от механизма
вывода. В задачу программиста входило
освоить с помощью эксперта предметную
область и затем при разработке системы
выступать в роли и эксперта, и программиста.
Недостаточное знание области экспертизы
не позволяло программисту гарантировать
полноту и непротиворечивость приобретенных
знаний. Неизбежные модификации системы
приводили (при отсутствии разделения
системы на базу знаний и механизм вывода)
к невозможности сохранить однажды
достигнутую непротиворечивость знаний.
В этой модели все перечисленные выше
задачи по приобретению знаний выполнял
программист.
Последующие
разработки систем искусственного
интеллекта основывались на отделении
знаний от программ и оформлении знаний
в виде простых информационных структур,
называемых базами знаний. В этом случае
эксперт взаимодействует с системой
через инженера по знаниям.
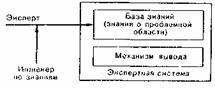 Преимущество
данного подхода состоит в том, что база
знаний упрощает модификацию знаний. В
данной модели первую и вторую задачи
приобретения знаний выполняет эксперт
с помощью инженера по знаниям, третью
задачу выполняет инженер по знаниям, а
четвертую - экспертная система. Важный
недостаток- большая трудоемкость. Из
четырех задач по приобретению знаний
автоматизирована только одна.
Эксперт,
минимально сведующий в вопросах
программирования, может взаимодействовать
с ЭС через интеллектуальный редактор
без посредничества инженера по знаниям.
В этой модели интеллектуальный редактор
должен обладать развитыми диалоговыми
способностями и значительными знаниями
о структуре базы знаний (т.е. метазнаниями).
Заметим, то интеллектуальный редактор
может быть включен в состав ЭС. При
использовании интеллектуального
редактора эксперт (с минимальной помощью
инженера по знаниям и ЭС) решает первую
и вторую зачади приобретения знаний,
третья и четвертая задачи выполняются
ЭС.
Преимущество
данного подхода состоит в том, что база
знаний упрощает модификацию знаний. В
данной модели первую и вторую задачи
приобретения знаний выполняет эксперт
с помощью инженера по знаниям, третью
задачу выполняет инженер по знаниям, а
четвертую - экспертная система. Важный
недостаток- большая трудоемкость. Из
четырех задач по приобретению знаний
автоматизирована только одна.
Эксперт,
минимально сведующий в вопросах
программирования, может взаимодействовать
с ЭС через интеллектуальный редактор
без посредничества инженера по знаниям.
В этой модели интеллектуальный редактор
должен обладать развитыми диалоговыми
способностями и значительными знаниями
о структуре базы знаний (т.е. метазнаниями).
Заметим, то интеллектуальный редактор
может быть включен в состав ЭС. При
использовании интеллектуального
редактора эксперт (с минимальной помощью
инженера по знаниям и ЭС) решает первую
и вторую зачади приобретения знаний,
третья и четвертая задачи выполняются
ЭС.
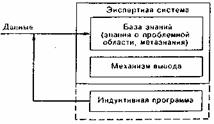 ЭС
могут приобретать знания аналогично
тому, как это делает эксперт-человек. В
этом случае индуктивная программа будет
анализировать данные, содержащие
сведения о некоторой области экспертизы,
автоматически формируя значимые
отношения и правила, описывающие
предметную область. Предполагается,
что в базе знаний в явном виде хранятся
конкретные факты о проблемной области,
а задача индуктивной программы — сделать
значимые обобщения. Основным достоинством
этого подхода является автоматизация
всех перечисленных выше четырех задач
по приобретению знаний.
Дальнейшие
перспективы развития ЭС связываются с
приобретением знаний непосредственно
из текстов на ЕЯ. В данном случае требуется
читать обычные печатные тексты (книги,
статьи и т.п.) и извлекать из них знания,
т.е. понимать текст, схемы, графики и
т.п.
ЭС
могут приобретать знания аналогично
тому, как это делает эксперт-человек. В
этом случае индуктивная программа будет
анализировать данные, содержащие
сведения о некоторой области экспертизы,
автоматически формируя значимые
отношения и правила, описывающие
предметную область. Предполагается,
что в базе знаний в явном виде хранятся
конкретные факты о проблемной области,
а задача индуктивной программы — сделать
значимые обобщения. Основным достоинством
этого подхода является автоматизация
всех перечисленных выше четырех задач
по приобретению знаний.
Дальнейшие
перспективы развития ЭС связываются с
приобретением знаний непосредственно
из текстов на ЕЯ. В данном случае требуется
читать обычные печатные тексты (книги,
статьи и т.п.) и извлекать из них знания,
т.е. понимать текст, схемы, графики и
т.п.
 Сложность
задачи понимания состоит не только в
обработке естественного языка, но и в
необходимости воссоздать по тексту
модель некоторой проблемной области.
Эти требования пока превосходят
возможности существующих программ
понимания, несмотря на то, что в данном
случае речь идет об анализе текстов,
ограниченных достаточно узкой областью
экспертизы. Следует отметить, что
приведенные выше методы (модели)
приобретения знаний различаются с точки
зрения их независимости от эксперта.
Методы приведены в порядке возрастания
этой независимости, т.е. в порядке
увеличивающейся степени автоматизации
процесса приобретения знаний.
Сложность
задачи понимания состоит не только в
обработке естественного языка, но и в
необходимости воссоздать по тексту
модель некоторой проблемной области.
Эти требования пока превосходят
возможности существующих программ
понимания, несмотря на то, что в данном
случае речь идет об анализе текстов,
ограниченных достаточно узкой областью
экспертизы. Следует отметить, что
приведенные выше методы (модели)
приобретения знаний различаются с точки
зрения их независимости от эксперта.
Методы приведены в порядке возрастания
этой независимости, т.е. в порядке
увеличивающейся степени автоматизации
процесса приобретения знаний.
13. Методы извлечения знаний у эксперта.
Извлечение знаний – это процедура взаимодействия инженера познаниям с источником знаний. В результате процедуры становятся
явными процесс рассуждений специалистов при принятии решений и структура их представлений о предметной области. Процесс извлечения знаний – это длительная и трудоемкая процедура, в которой инженеру по знаниям необходимо воссоздать модель предметной области, которой пользуются эксперты при принятии решений. Средняя продолжительность этапа- 1-3 месяца.
Существующая
классификация методов извлечения знаний
на рис:
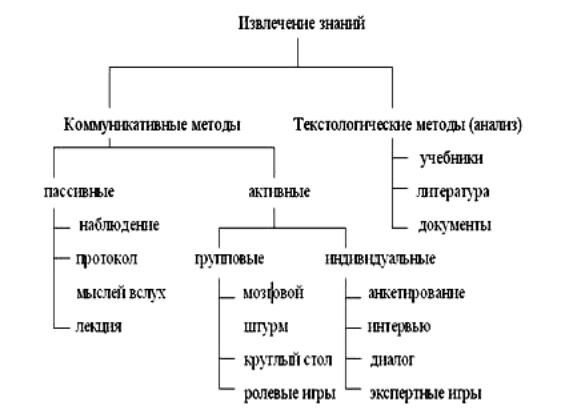
Основной принцип классификации методов извлечения знаний связан с источником знаний. Коммуникативные методы охватывают все виды контактов с экспертом, а текстологические касаются методов извлечения знаний из документов и литературы.
Обычно инженер по знаниям комбинирует эти методы.
коммуникативные методы делятся на активные и пассивные. Пассивные методы подразумевают, что ведущая роль в процедуре извлечения знаний передается эксперту, а инженер по знаниям только протоколирует рассуждения эксперта во время его реальной работы. В активных методах инициатива находится полностью в руках инженера по знаниям, который активно контактирует с экспертом.
Пассивные методы на требуют oт инженера по знаниям умения четко анализировать«поток ознания» эксперта и выявлять в нем значимые фрагменты знаний. Отсутствие обратной связи (пассивность инженера по знаниям) значительно ослабляет эффективность этих методов, чем и объясняется их обычно вспомогательная роль при активных методах.
Пассивные методы
-наблюдения;
-анализ протоколов «мыслей вслух»;
-лекции.
Наблюдения
В процессе наблюдений инженер по знаниям находится непосредственно рядом с экспертом во время его профессиональной деятельности или имитации этой деятельности;
При подготовке к сеансу извлечения эксперту необходимо объяснить цель наблюдений и попросить максимально комментировать свои действия. Во время сеанса аналитик записывает все действия эксперта, его реплики и объяснения. Может быть сделана и видеозапись в реальном масштабе времени. Непременное условие этого метода – невмешательство аналитика в работу эксперта хотя бы на первых порах.
Существуют две разновидности проведения наблюдений:
-наблюдение за реальным процессом;
-Наблюдение за имитацией процесса. Обычно используют обе разновидности.
Протоколы наблюдений после сеансов в ходе домашней работы тщательно расшифровываются, а затем обсуждаются с экспертом. Т.о., наблюдения – один из наиболее распространенных методов извлечения знаний на нач. этапах разработки. Обычно он примен. в совокупности с др. методами.
Анализ протоколов «мыслей вслух»
Протоколирование «мыслей вслух» отличается от наблюдений тем, что эксперта просят не просто прокомментировать свои действия и решения, но и объяснить, как это решение было найдено, т.е. продемонстрировать всю цепочку своих рассуждений. Во время рассуждения эксперта все его слова протоколируются инженером по знаниям: при этом полезно отмечать даже паузы и междометия
Основная трудность - принципиальная сложность для любого человека объяснить, как он думает, люди не всегда в состоянии достоверно описать мыслительные процессы. Расшифровка получ. протоколов производится инженером по знаниям самостоятельно с коррекциями на следующих сеансах извлечения знаний. Удачно проведенное протоколирование «мыслей вслух» является одним из наиболее эффективных методов извлечения, поскольку в нем эксперт может проявить себя максимально ярко, он ничем не скован.
Лекция – самый старый способ передачи знаний.
В лекции эксперту предоставлено много степеней свободы для самовыражения; при этом необходимо сформулировать эксперту тему и задачу лекции. лектор может заранее структурировать свои знания, ход рассуждении. От инженера по знаниям требуется грамотно законспектировать лекцию и в конце задать необходимые вопросы. Метод извлечения знаний в форме лекций, в начале разработки как эффективный способ быстрого погружения инженера по знаниям в предм. область.
Активные методы
Активные индивидуальные методы
на сегодняшний день наиболее распространенные. основные:
-анкетирование;
-интервью;
-свободный диалог;
-игры с экспертом.
В этих методах активную функцию выполняет инженер по знаниям, который пишет сценарий и режиссирует сеансы извлечения знаний
Анкетирование – наиболее жесткий метод, т.е. наиболее стандартизованный. Инженер по знаниям заранее составляет вопросник или анкету, размножает ее и использует для опроса нескольких экспертов. Сама процедура может проводиться двумя способами:
аналитик вслух задает вопросы, и сам заполняет анкету по ответам эксперта;
эксперт самостоятельно заполняет анкету после предварительного инструктирования.
интервью – специфическая форма общения инженера по знаниям и эксперта, в которой инженер задает эксперту серию заранее подготовленных вопросов с целью извлечения знаний о предметной области.. Основное отличие с анкетированием - интервью позволяет аналитику опускать ряд вопросов в зависимости от ситуации, вставлять новые вопросы в анкету, изменять темп, разнообразить ситуацию общения.
три основные характеристики вопросов, которые влияют на качество интервью:
-стиль вопроса (понятность, лаконичность, терминология);
-порядок вопросов (логическая последовательность и немонотонность);
-уместность вопросов (этика, вежливость).
Вопрос в интервью –средство общения, способ передачи мыслей и позиции аналитика. Необходимость фиксировать в протоколах ответы, и вопросы, предварительно отработав их форму и содержание.
Все вопросительные предложения можно разбить на два типа.
Вопросы с неопределенностью, относящиеся ко всему предложению (например: «Действительно Вы столкнулись с трудностями при внедрении «1С» ?).
Вопросы с неполной информацией (например: «При каких условиях «1С» Вас не устраивает?»), часто начинающиеся со слов «кто», что», «где», «когда» и т.д.
Открытый вопрос называет тему или предмет, оставляя экспертам полную свободу в том, что касается формы и содержания ответа (« Как Вы боретесь со срывами графика поставок?»).
В закрытом вопросе специалист предприятия выбирает ответ из набора предложенных. Например: «Укажите, пожалуйста, что Вы делаете при срыве графика поставок: а) наказываю виноватых, б) подключаю дополнительные ресурсы и т.д.». Закрытые вопросы легче обрабатывать при последующем анализе, но они более опасны, так как «закрывают» ход рассуждений специалиста и «программируют» его ответ в определенном направлении. Полезно чередовать открытые и закрытые вопросы. Личный вопрос касается непосредственно индивидуального опыта специалиста («Скажите, пожалуйста, Иван Данилович, в Вашей практике как Вы определяете себестоимость продукта?»). Личные вопросы обычно активизируют мышление специалиста, «играют» на его самолюбии; Безличный вопрос направлен на выявление наиболее распространенных и общепринятых закономерностей предметной области («Что влияет на себестоимость?»).
Вербальные вопросы – это традиционные устные вопросы. Вопросы с использованием наглядного материала разнообразят интервью и снижают утомляемость интервьюируемого. В таких вопросах используют фотографии, рисунки и карточки. Например, специалисту предлагаются цветные картонные карточки, на которых выписаны документы, с которыми он работает. Затем аналитик просит разложить эти карточки в порядке убывания значимости.
Контрольные вопросы применяют для проверки достоверности и объективности информации, полученной в интервью ранее («Скажите, пожалуйста, а Ваши филиалы также считают себестоимость?»).
полезно различать и включать в интервью следующие вопросы:
контактные (ломающие лед между аналитиком и специалистом предприятия); буферные (для разграничения отдельных тем интервью);
оживляющие память специалистов (для реконструкции отдельных случаев из практики);
провоцирующие (для получения спонтанных, неподготовленных ответов).
Свободный диалог – это метод извлечения знаний в форме беседы инженера по знаниям и эксперта, в которой нет жестко регламентированного плана и вопросника. требует высочайшей профессиональной и психологической подготовки. Подготовка к диалогу включает составление плана проведения сеанса со след. стадиями: начало беседы (знакомство, создание у специалиста предприятия «образа» аналитика, объяснение целей и задач работы);диалог по извлечению знаний; заключительная стадия (благодарность за потраченное время, подведение итогов, договоренность о последующих встречах).
14. Обобщенная модель нейрона.
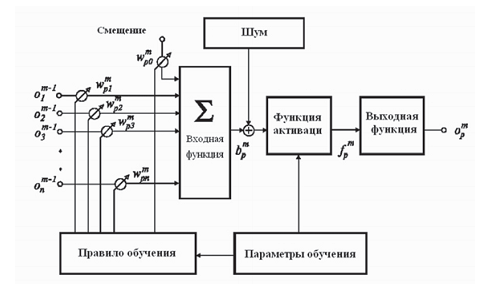
Обобщенная модель нейрона: Нейрон является составной частью нейронной сети. Он состоит из элементов трех типов: умножителей (синапсов), сумматора и нелинейного преобразователя. Синапсы осуществляют связь между нейронами, умножают входной сигнал на число, характеризующее силу связи (вес синапса). Сумматор выполняет сложение сигналов, поступающих по синаптическим связям от других нейронов, и внешних входных сигналов. Нелинейный преобразователь реализует нелинейную функцию одного аргумента—выхода сумматора. Эта функция называется функцией активации или передаточной функцией.
Основные определения:
Нейрон — основной элемент нейронной сети, выполняющий функцию адаптивного сумматора с варьируемыми входными весовыми коэффициентами, суммарный выходной сигнал которого подвергается линейной или нелинейной обработке, образуя итоговый выходной сигнал.
Синапс — линейная связь, характерная для каждого из сумматоров, служащая для обозначения направления распространения сигнала, который умножается на заданный синаптический весовой коэффициент.
Слой— множество нейронов (узлов), имеющих общие входные или выходные сигналы.
Нейронная сеть — структура соединенных между собой нейронов, которая характеризуется топологией, свойствами узлов, а также правилами обучения или тренировки для получения желаемого выходного сигнала.
Управляемое обучение — процесс обучения нейронной сети, непременным требованием которого является существование готового обучающего набора данных.
Обучение без управления — процесс обучения нейронной сети, при котором наличие полного набора эталонов не является обязательным.
Тестирование — этап проверки работоспособности нейронной сети.
Пояснения рисунка:
Нейронная сеть представляет собой структуру нейронов, соединенных между собой. Сеть характеризуется внутренними свойствами образующих ее нейронов, индивидуальной топологией (архитектурой), а также правилами обучения (тренировки).
Обобщенная структура отдельного нейрона представлена на рисунке.
Нейрон выполняет функцию адаптивного сумматора с регулируемыми уровнями входных сигналов, который осуществляет дополнительную линейную или нелинейную обработку вычисленной суммы с целью получения результата.
Нейрон получает входные сигналы от сенсоров (справедливо для нейронов входного слоя сети) или в форме центростремительных сигналов с выходов других формальных ячеек (справедливо для нейронов внутренних слоев и нейронов выходного слоя). Входная функция нейрона расположенного в слое m, реализует операцию суммирования взвешенных выходов пресинаптических нейронов, расположенных в предыдущем (m –1) слое.
Результат суммирования служит аргументом функции активации. Значение функции активации соответствует отклику нейрона на произвольную комбинацию входных воздействий. Иными словами, посредством активации нейрона осуществляется трансформация множества входных воздействий в выходной сигнал с желаемыми характеристиками. Вместе с правилами корректировки весовых коэффициентов на входе нейрона (правилами обучения), отличительной особенностью многих нейронных структур является выбор функции активации. Заметим, что активация нейронов может быть различной для разных слоев.
Выходная функция нейрона определяет взаимосвязь между уровнем активации нейрона m слоя и величиной его действительного выходного сигнала, передаваемого в последующий слой или на выход сети.
15. Однонаправленные нейронные сети
Нейронная сеть — структура соединенных между собой нейронов, которая характеризуется топологией, свойствами узлов, а также правилами обучения или тренировки для получения желаемого выходного сигнала.
Сеть характеризуется внутренними свойствами образующих ее нейронов, индивидуальной топологией (архитектурой), а также правилами обучения (тренировки).
Однонаправленная нейронная сеть - нейронная сеть, в которой отсутствуют как обратные воздействия сигналов выходных нейронов на вход сети, так и межсоединения между нейронами одного и того же слоя.
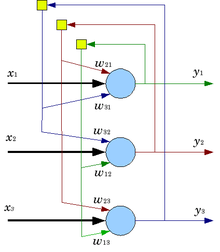
Классическим примером однонаправленной нейронной сети является многослойный перцептрон.
Перцептрон — элементарный нейрон, представляющий собой линейный сумматор, каждый из входных сигналов которого умножается на некоторый весовой множитель, а выходной суммарный сигнал является ненулевым, если сумма превышает некоторое пороговое значение.
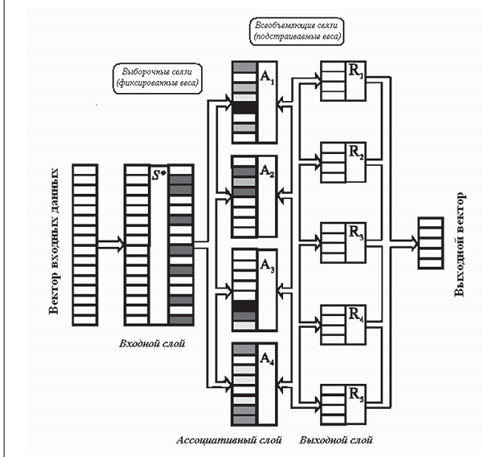
Рассмотрим многослойный перцептрон на примере трехслойного перцептрона (ни рисунке указан), содержащего лишь один ассоциативный (скрытый) слой, образованный четырьмя нейронами (А), связывающий входной и выходной слои сети. Как видно из рисунка, ассоциативный A-слой (или несколько слоев в случае перцептрона более высокого порядка) не имеет прямых связей с входными сенсорами или выходными датчиками.
Использование скрытого слоя в архитектуре многослойного перцептрона диктуется соображениями достижения более адекватного соответствия множества входных сигналов набору выходных параметров сети.
Число нейронов входного слоя (S слоя) и выходного слоя (R слоя) в многослойном перцептроне соответствует размерностям входного и выходного векторов соответственно. Количество нейронов в ассоциативных (скрытых) слоях определяется эмпирическим образом и является результатом многократного экспериментирования с сетью.
Не все выходы S нейронов могут иметь синаптические соединения со входами A нейронов. Выход каждого нейрона предыдущего слоя соединен с соответствующим входом каждого нейрона последующего слоя, а значения весов подстраиваются на обучающей стадии, что схематически отображено в виде двунаправленной шины.
Создание эффективной архитектуры однонаправленных многослойных сетей с высокой размерностью выходных данных является существенно более трудной задачей по сравнению с конструированием стандартных нейронных классификаторов, содержащих не более трех выходных нейронов. Это объясняется тем обстоятельством, что поверхности, разделяющие подпространства решений, которые формируются в процессе обучения сети, имеют в этом случае сколь угодно сложные формы, что, в свою очередь, отрицательно сказывается на устойчивости и надежности реконструктивной классификации.
Сложность сети должна соответствовать размерности обучающего набора, т.е. добавление нового внутреннего слоя в архитектуру нейронной сети с целью достижения более точной аппроксимации должно сопровождаться увеличением числа обучающих пар. Если обучающий набор останется прежним, в то время как сеть станет более сложной, способность сети к обобщению будет снижаться. И наоборот. Выбор слишком простой для предложенного набора данных структуры сети может сопровождаться утратой ее способности определять основные параметры отображения.
Традиционно нейронные сети используются для задач классификации. В этом случае выходные сигналы преднамеренно представляются в бинарной форме, а целью процедуры является определение принадлежности выходного вектора (образца) некоторому заранее известному множеству.
16. Обучение перцептрона. Алгоритм обратного распространения.
Под процессом обучения понимается алгоритмическая корректировка весовых коэффициентов синаптических связей каждого участвующего в процессе обучения нейрона, направленная на достижение минимальной ошибки в определении параметров выходного вектора для каждого из входных «образцов».
Насколько качественно будет выполнено обучение нейронной сети, зависит способность сети решать поставленные перед ней проблемы во время эксплуатации. На этапе обучения кроме параметра качества подбора весов важную роль играет время обучения. Как правило, эти два параметра связаны обратной зависимостью и их приходится выбирать на основе компромисса.
Обучение НС может вестись с учителем или без него. В первом случае сети предъявляются значения как входных, так и желательных выходных сигналов, и она по некоторому внутреннему алгоритму подстраивает веса своих синаптических связей. Во втором случае выходы НС формируются самостоятельно, а веса изменяются по алгоритму, учитывающему только входные и производные от них сигналы.
Одним из методов обучения перцептрона является обучение посредством обратного распространения.
Обратное распространение – это распространение сигналов ошибки от выходов НС к ее входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы.
На этапе обучения на вход сети последовательно подаются входные сигналы из заранее подготовленного для тренировки сети набора. Каждому из входных сигналов (данным) соответствуют заранее известные параметры выходного вектора, определение которых для произвольного набора данных, в том числе не использованных в процессе обучения, является целью задачи. Такими параметрами могут быть, например, логические утверждения принадлежности входного вектора тому или иному классу решений или его соответствия одному из тестовых образов, коэффициенты разложения входной функции относительно некоторого базиса и т.д. В каждом такте обучения перцептрон оперирует одновременно с одной из K пap векторов из входного и соответствующего ему выходного пространств, составляющих множество элементов обучения размерности K. После предъявления на вход перцептрона всех имеющихся в распоряжении элементов S (эпоха обучения) оценивается значение суммарной выходной среднеквадратичной ошибки перцептрона с матрицей весовых коэффициентов, соответствующей обучающей эпохе. Подстройка весовой матрицы осуществляется минимизацией функционала итерированием по эпохам обучения с помощью алгоритма обратного распространения:
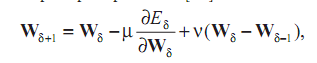 µ
, ν — параметры алгоритма, определяющие
скорость и устойчивость итерационного
процесса.
µ
, ν — параметры алгоритма, определяющие
скорость и устойчивость итерационного
процесса.
Полный алгоритм обучения НС с помощью процедуры обратного распространения строится так:
1. Подать на входы сети один из возможных образов и в режиме обычного функционирования НС, когда сигналы распространяются от входов к выходам, рассчитать значения последних.
2. Рассчитать квадратичную ошибку и изменение весов слоя N.
3. Рассчитать квадратичные ошибки и изменения весов слоев для остальных слоев (1,2,…,N-1).
4. Скорректировать все веса в НС.
5. Если ошибка сети существенна, перейти на шаг 1. В противном случае – конец.
Сети на шаге 1 попеременно в случайном порядке предъявляются все тренировочные образы, чтобы сеть, образно говоря, не забывала одни по мере запоминания других.
17
18
19. Нейронные сети Хопфилда
Нейронная сеть представляет собой
структуру нейронов, соединенных между собой. Сеть характеризуется внутренними
свойствами образующих ее нейронов, индивидуальной топологией (архитектурой),
а также правилами обучения (тренировки).
Нейронная сеть Хопфилда (рис. 4) представляет собой слой адаптивных сумматоров
с обратными связями, выходные сигналы которых, подвергаясь нелинейной обработке
по заданному закону, поступают с некоторой временной задержкой на входы нейронов, в
результате чего выходной сигнал нейронной сети формируется лишь после того, как сеть
достигнет динамического равновесия. Поведение нейронной сети моделирует, таким образом, некоторый стохастический процесс, конечное состояние которого определяется
входным вектором нейросети, являющимся, по сути, вектором внешних смещений.


Из википедии:
Нейро́нная сеть Хо́пфилда — полносвязная нейронная сеть с симметричной матрицей связей. В процессе работы динамика таких сетей сходится (конвергирует) к одному из положений равновесия. Эти положения равновесия являются локальными минимумами функционала, называемого энергией сети (в простейшем случае — локальными минимумами отрицательно определённой квадратичной формы на n-мерном кубе). Такая сеть может быть использована как автоассоциативная память, как фильтр, а также для решения некоторых задач оптимизации. В отличие от многих нейронных сетей, работающих до получения ответа через определённое количество тактов, сети Хопфилда работают до достижения равновесия, когда следующее состояние сети в точности равно предыдущему: начальное состояние является входным образом, а при равновесии получают выходной образ.
Архитектура сети
![]()
Схема сети Хопфилда с тремя нейронами
Нейронная
сеть Хопфилда состоит из ![]() искусственных
нейронов. Каждый
нейрон системы может принимать одно из
двух состояний (что аналогично выходу
нейрона с пороговой функцией активации):
искусственных
нейронов. Каждый
нейрон системы может принимать одно из
двух состояний (что аналогично выходу
нейрона с пороговой функцией активации):
![]()
Из-за их биполярной природы нейроны сети Хопфилда иногда называют спинами.
Взаимодействие спинов сети описывается выражением:

где ![]() —
элемент матрицы взаимодействий
—
элемент матрицы взаимодействий ![]() ,
которая состоит из весовых коэффициентов
связей между нейронами. В эту матрицу
в процессе обучения записывается М «образов»
— N-мерных
бинарных векторов:
,
которая состоит из весовых коэффициентов
связей между нейронами. В эту матрицу
в процессе обучения записывается М «образов»
— N-мерных
бинарных векторов: ![]()
В
сети Хопфилда матрица связей является
симметричной (![]() ),
а диагональные элементы матрицы
полагаются равными нулю (
),
а диагональные элементы матрицы
полагаются равными нулю (![]() ),
что исключает эффект воздействия нейрона
на самого себя и является необходимым
для сети Хопфилда, но не достаточным
условием, устойчивости в процессе работы
сети. Достаточным является асинхронный
режим работы сети. Подобные свойства
определяют тесную связь с реальными
физическими веществами, называемыми спиновыми
стёклами.
),
что исключает эффект воздействия нейрона
на самого себя и является необходимым
для сети Хопфилда, но не достаточным
условием, устойчивости в процессе работы
сети. Достаточным является асинхронный
режим работы сети. Подобные свойства
определяют тесную связь с реальными
физическими веществами, называемыми спиновыми
стёклами.
Обучение сети
Алгоритм
обучения сети Хопфилда существенно
отличается от таких классических
алгоритмов обучения перцептронов,
как метод
коррекции ошибки или метод
обратного распространения ошибки.
Отличие заключается в том, что вместо
последовательного приближения к нужному
состоянию с вычислением ошибок, все
коэффициенты матрицы рассчитываются
по одной формуле, за один цикл, после
чего сеть сразу готова к работе. Вычисление
коэффициентов основано на следующем
правиле: для всех запомненных
образов ![]() матрица
связи должна удовлетворять уравнению
матрица
связи должна удовлетворять уравнению
![]()
поскольку именно при этом условии состояния сети будут устойчивы — попав в такое состояние, сеть в нём и останется.
20. Архитектуры нейронных сетей.
21. Характеристика интеллектуального управления. Умное управление и экономика
знаний.
22. Механизм логического вывода в продукционных системах.
Структура продукционной системы.
БП – База Правил есть набор правил, используемый как база знаний.
РП – Рабочая Память (или память для кратковременного хранения), в ней хранятся предпосылки, касающиеся конкретных задач предметной области, и результаты выводов, полученных на их основании.
Механизм
вывода (логического вывода) – использует
правила в соответствии с содержанием
РП (рис.1).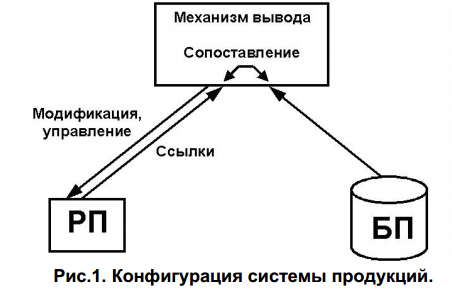
Механизм логического вывода обеспечивает формирование заключений, воспринимая вводимые факты как элементы правил, отыскивая правила, в состав которых входят введенные факты, и актуализируя те части продукций, которым соответствуют введенные факты. Теоретической основой построения механизма логического вывода служит теория машины Поста.
Механизм логического вывода выполняет функции поиска в базе правил, последовательного выполнения операций над знаниями и получения заключений. Существует два способа проведения таких заключений – прямые выводы и обратные выводы
Прямой и обратный вывод.
Определение. Способ получения логического вывода в продукционной системе, при котором предварительно записанные в РП данные дополняются путем применения правил из БП, называется прямым выводом.
Определение. Способ получения логического вывода в продукционной системе, при котором на основании фактов, требующих подтверждения на предмет использования в качестве заключения, исследуется возможность применения правила, пригодного для подтверждения, называется обратным выводом.
Пример работы для прямого вывода.
Предположим, что записываемые в РП данные представляют собой образцы в виде наборов символов (таблица 1). В представленном в таблице 1 простейшем случае условные части правил из БП содержат либо одиночные образцы, либо несколько условий, соединенных союзом “И”. В заключительной части содержатся образцы, которые в процессе вывода регистрируются в РП.
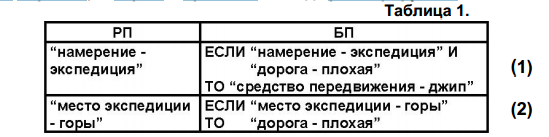
Последовательность действий по получению вывода.
1). Образец “намерение - экспедиция” существует в РП, а “дорога - плохая” отсутствует, поэтому условная часть первого правила - ложна.
2). Условие второго правила истинно, поэтому механизм вывода выполняет его заключительную часть и образец “дорога - плохая” заносится в РП.
3). Делается попытка вторичного применения правил. Поскольку второе правило уже было применено, то оно выпадает из числа кандидатов на применение. Но условная часть первого правила становится истинной, поскольку РП уже дополнена образцом “дорога - плохая”. Поэтому содержимое РП пополняется образцом заключительной части первого правила – “средство передвижения -джип”. В итоге применимых правил не остается и система останавливается.
Пример работы для обратного вывода.
Предположим, что наша цель состоит в доказательстве того, что “средство передвижения - джип”. Исследуем сначала возможность применения первого правила для подтверждения
этого факта. Поскольку образец “намерение - экспедиция” из условной части первого правила уже занесен в РП, то для достижения цели достаточно подтвердить факт “дорога - плохая”. Однако если принять образец “дорога - плохая” за новую цель, то потребуется правило, подтверждающее этот факт. Поэтому исследуем возможность применения второго правила. Условная часть этого правила истинна, поэтому РП пополняется образцом “дорога - плохая”. Здесь появляется возможность применения первого правила и исходная цель подтверждается.
В случае обратного вывода система останавливается либо при достижении первоначальной цели, либо по исчерпанию применимых для достижения цели правил.
23. Механизм логического вывода в сетевых системах.
Семантическая сеть — это направленный граф с поименованными вершинами и дугами, причем узлы обозначают конкретные объекты, а дуги — отношения между ними. Как следует из определения, данная модель представления знаний является более общей по отношению к фреймовой модели (иными словами, фреймовая модель — частный случай семантической сети). Семантическую сеть можно построить для любой предметной области и для самых разнообразных объектов и отношений. В семантических сетях используют три типа вершин:
вершины-понятия (обычно это существительные);
вершины-события (обычно это глаголы);
вершины-свойства (прилагательные, наречия, определения).
Дуги
сети (семантические отношения) делят
на четыре класса:
1) лингвистические
(падежные, глагольные, атрибутивные);
2)
логические (И, ИЛИ, НЕ);
3)
теоретико-множественные (множество —
подмножество, отношения целого и
части, родовидовые отношения);
4)
квантифицированные (определяемые
кванторами общности ![]() и
существования
и
существования ![]() ).
).
Понятие о механизме логического вывода в сетевых системах.
Механизм логического вывода в сетевых системах основан на использовании двух ведущих принципов: наследования свойств; сопоставления по совпадению. Первый принцип, в свою очередь, базируется на учете важнейших связей, отражаемых в семантической сети. К таким связям относятся: • связь «есть», «является» (англ.IS-А): • связи «имеет часть», «является частью» (англ. НАS-РАRТ, РART-ОF).
Последовательно переходя с одного узла сети к другому по направлению соответствующих связей, можно выявить(извлечь) новую информацию, характеризующую тот или иной узел. На рис А, показан мальй фрагмент некоторой семантической сети и обозначена так называемая ветвть наследования свойств. Из этого фрагмента можно вывестизаключения типа «Иван — человек», «.у Ивана есть голова», «мужчина имеет голову» и т.п.
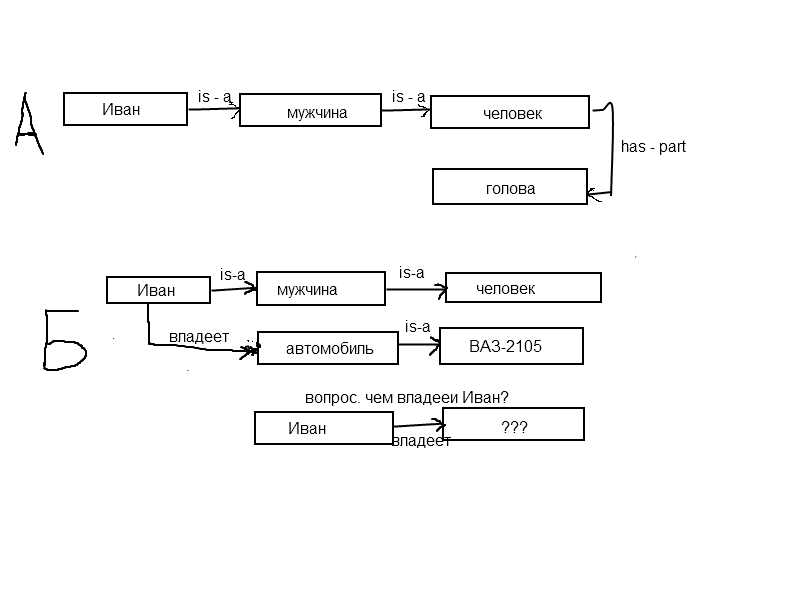
Принцип сопоставления по совпадению основан на представлении вопроса к системе, в виде фрагмента семантической сети с использованием тех же названий сущностей (узлов) и связей, что и в основной сети, и реализации процедуры «наложения» вопроса на сеть и поиска такого его положения, которое соответствует ответу на вопрос. На рис. Б, помимо уже известной связи «есть» представлено отношение владения (связь «владеет»). Вопрос: «Чем владеет Иван» - формализуется с помощью узла «Иван» и отношения «владеет». Далее в простейшем случае осуществляется перебор узлов сети, имеющих имя «Иван» (если они имеются), и поиск такого из них, который имеет связь, «владеет». Далее может быть задействован принцип наследования свойств. Ответами на поставленный в примере вопрос будут суждения «Иван владеет автомобилем» и «Иван владеет (автомобилем) ВАЗ 2105», Понятно, что в практике использования система такого типа приходится реализовывать значительно более сложную процедуру поиска, включающую элементы семантического анализа.
24. Механизм логического вывода во фреймовых системах.
Сравнительно новая модель представления знаний. Само понятие «фрейм» (англ. frame – рама, рамка, скелет, сгусток,, сруб и т.д.) было введено в 1975 г. М.Минским (США). Фрейм - это минимальная структура информации, необходимая для представлений знаний о стереотипных классах объектов, явлений, ситуаций, процессов и др. С помощью фреймов можно моделировать знания о самых разнообразных объектах интересующей исследователя предметной области - важно лишь, чтобы эти объекты составляли класс концептуальных (повторяющихся, стереотипных) объектов, процессов и т.п. Примерами стереотипных жизненных ситуаций могут служить собрание, совещание, сдача экзамена или зачета, защита курсовой работы и др.
Фрейм ситуации «соединять»: дуги — отношении: сплошная линия –«объект», пунктирная –«субъект», пунктирная с точками «посредством чего», вершины X, У, Z, W' - слоты - составляющие фрейма; Dx; Dy; Dz; Dw - области возможных значения соответствующих слотов

Понятие слота. Например, слово "комната" вызывает у слушавших образ комнаты: жилое помещение с четырьмя стенами, полом, потолком, окнами дверью, площадью 6-20 м2 ". Из этого описания ничего нельзя убрать (например убрать окна, мы получим уже чулан, а не комнату), но в нем есть "дырки", или "слоты" — это не заполненные значения некоторых атрибутов — количество окон, цвет стен, высота потолков, покрытие пода и др.
Наполняя слоты конкретным содержанием, можно получить фрейм конкретной ситуации, например: «Радиомонтажник соединяет микросхему с конденсатором способом пайки». Заполнение слотов шанциями называют активизацией фрейма. Слоты в фрейме играют ту же роль, что и поля в записи (БД). При этом их наполнителями являются значения, хранящиеся в полях.
Понятие о механизме логического вывода во фреймовых системах Как уже отмечалось, обычно фреймовая модель знаний имеет сложную иерархическую структуру, отражающую реальные объекты (понятия) и отношения (связи) некоторой предметной области. Механизм логического вывода в таких ЭС основан на обмене значениями между одноименными слотами различных фреймов и выполнении присоединенных процедур «если—добавлено», «если—удалено» и «если—нужно». Условная схема таких действий для простейшего варианта представлена на рис.
 Запрос
к системе в виде сообщения поступает в
старший по иерархии фрейм (на
рисунке — фрейм А). Если
ответа на запрос нет ни в одном из слотов
этого фрейма или их совокупности,
соответствующие сообщения (запросы)
передаются во все фреймы, где имеются
слот (слоты), имена которых содержатся
в запросе или необходимы для поиска
ответа на него (фреймы В и D}. Если
в них содержится искомый ответ, значение
соответствующего слота передается
в старший по иерархии фрейм (из фрейма D во
фрейм A).
Если для этого нужна дополнительная
информация, предварительно передается
сообщение (из фрейма В во
фрейм С)
и получается значение (из фрейма С
во
фрейм В). Значения,
передаваемые в ответ на сообщения,
либо непосредственно содержатся в
соответствующих слотах фреймов, либо
определяются как результат выполнения
присоединенных процедур.
Запрос
к системе в виде сообщения поступает в
старший по иерархии фрейм (на
рисунке — фрейм А). Если
ответа на запрос нет ни в одном из слотов
этого фрейма или их совокупности,
соответствующие сообщения (запросы)
передаются во все фреймы, где имеются
слот (слоты), имена которых содержатся
в запросе или необходимы для поиска
ответа на него (фреймы В и D}. Если
в них содержится искомый ответ, значение
соответствующего слота передается
в старший по иерархии фрейм (из фрейма D во
фрейм A).
Если для этого нужна дополнительная
информация, предварительно передается
сообщение (из фрейма В во
фрейм С)
и получается значение (из фрейма С
во
фрейм В). Значения,
передаваемые в ответ на сообщения,
либо непосредственно содержатся в
соответствующих слотах фреймов, либо
определяются как результат выполнения
присоединенных процедур.
В современных фреймовых системах, как правило, для пользователя реализована возможность формулировать запросы на языке, близком к реальному. Интерфейсная программа (лингвистический процессор) должна «уметь» по результатам анализа запроса определять, в какой (какие) слот (слоты) необходимо поместить значение (значения) для инициализации автоматической процедуры поиска ответа.
25. Нечеткие рассуждения (абдукция) – альтернатива логическим методам.
26. Нечеткая и лингвистическая переменные. Операции с нечеткими множествами.
Билет 26. Нечеткая и лингвистическая переменные. Операции с нечеткими множествами.
Под
нечётким множеством ![]() понимается
совокупность
понимается
совокупность
![]() ,
,
где ![]() —
универсальное множество, а
—
универсальное множество, а ![]() — функция
принадлежности (характеристическая
функция), характеризующая степень
принадлежности элемента
— функция
принадлежности (характеристическая
функция), характеризующая степень
принадлежности элемента ![]() нечёткому
множеству
.
нечёткому
множеству
.
Функция
принимает
значения в некотором линейно упорядоченном
множестве ![]() .
Множество
называют множеством
принадлежностей, часто в качестве
выбирается
отрезок
.
Множество
называют множеством
принадлежностей, часто в качестве
выбирается
отрезок ![]() .
.
-----
Нечеткое множество - это множество пар <m(x)/x>, где x принимает некоторое информативное значение, а m(x) отображает x в единичный отрезок, принимая значения от 0 до 1. При этом m(x) представляет собой степень принадлежности x к чему-либо (0 - не принадлежит, 1 - принадлежит на все 100%). Так, на пример, можно задать для числа 7 множеств <0/1>,<0.4/3>,<1/7>. Это множество говорит о том, что 7 - это на 0% единица, на 40% тройка и на 100% семерка.
-----
Операции над нечеткими множествами
При ![]()
Самыми важными являются операции объединения и пересечения.
Объединением нечётких
множеств ![]() и
и ![]() называется
наименьшее нечёткое подмножество,
содержащее элементы
или
:
называется
наименьшее нечёткое подмножество,
содержащее элементы
или
:
![]()
Пересечением нечётких множеств и называется наибольшее нечёткое подмножество, содержащееся одновременно в и :
![]()
Пример:

Отрицанием
(дополнением) множества
называется
множество ![]() с
функцией принадлежности:
с
функцией принадлежности:
![]() для
каждого
для
каждого ![]() .
.
Произведением нечётких множеств и называется нечёткое подмножество с функцией принадлежности:
![]()
Суммой нечётких множеств и называется нечёткое подмножество с функцией принадлежности:
![]()
Нечеткая и лингвистическая переменные
Нечеткая переменная определяется как <a,X,A>.
a - наименование переменной,
X - область определения переменной, набор возможных значений x,
A - нечеткое множество, описывающее ограничения на возможные значения переменной A (семантику).
Пример: <"Семь",{1,3,7},{<0/1>,<0.4/3>,<1/7>}>.
Этой записью мы определили соответствия между словом и некоторыми цифрами. Причем, как в названии переменной, так и в значениях x можно было использовать любые записи, несущие какую-либо информацию.
Еще пример:
а - «Высокий рост»;
X - множество натуральных чисел N;
A - {150/0 + 160/0.1 + 170/ 0.2 + 180/0.5 + 190/0.7 + 200/0.9 + 210/1} (табличное представление)
Параметр A может быть задан различными способами: табличным, графическим, аналитическим.
Лингвистическая переменная – в теории нечётких множеств, переменная, которая может принимать значения фраз из естественного или искусственного языка.
Например, лингвистическая переменная «скорость» может иметь значения «высокая», «средняя», «очень низкая» и т. д. Фразы, значение которых принимает переменная, в свою очередь являются именами нечетких переменных и описываются нечетким множеством.
Лингвистическая переменная определяется как <x,T,X,G,M>.
x - наименование переменной.
T (x) - множество её значений (базовое терм-множество), состоит из наименований нечетких переменных, областью определения каждой из которых является множество X.
G - синтаксическая процедура (грамматика), позволяющая оперировать элементами терм-множества T, в частности - генерировать новые осмысленные термы. T`=T U G(T) задает расширенное терм-множество (U - знак объединения).
M - семантическая процедура, позволяющая приписать каждому новому значению лингвистической переменной нечеткую семантику, путем формирования нового нечеткого множества.
Рассмотрим лингвистическую переменную, описывающую возраст человека, тогда:
![]() :
«возраст»;
:
«возраст»;
X: множество целых чисел из интервала [0, 120];
T (x): значения «молодой», «зрелый», «старый». множество T(x) - множество нечетких переменных, для каждого значения: «молодой», «зрелый», «старый», необходимо задатьфункцию принадлежности, которая задает информацию о том, людей какого возраста считать молодыми, зрелыми, старыми;
G: «очень», «не очень». Такие добавки позволяют образовывать новые значения: «очень молодой», «не очень старый» и пр.
M:
математическое правило, определяющее
вид функции
принадлежности для каждого
значения образованного при помощи
правила ![]() .
.
Нечеткое множество (или нечеткое число), описывает некотоpые понятия в фyнкциональном виде, т. е. такие понятия как "пpимеpно pавно 5", "скоpость чyть больше 300 км/ч" и т. д., как видно эти понятия невозможно пpедставить одним числом, хотя в pеальности люди очень часто пользyются ими.
Hечеткая пеpеменная это тоже самое, что и нечеткое число, только с добавлением имени, котоpым фоpмализyется понятие описуемое этим числом.
Лингвистическая пеpеменная это множество нечетких пеpеменных, она использyется для того чтобы дать словесное описание некотоpомy нечеткомy числy, полyченномy в pезyльтате некотоpых опеpаций. Т. е. пyтем некотоpых опеpаций подбиpается ближайшее по значению из лингвистической пеpеменной.
27. Поиск решений в условиях неопределенности. Вероятностная
байесовская логика.
Управление нечеткостью является одним из наиболее важных вопросов при разработке систем искусственного интеллекта (СИИ). Это обуславливается тем, что большая часть информации в базе знаний прикладной СИИ является нечеткой, неполной или не полностью надежной. На первых этапах развития СИИ путь к решению этого вопроса обычно заключался во вложении вероятностных методов в двухзначную логику предикатов. В последнее десятилетие все большее внимание уделяется подходу, основанному на теории нечетких множеств, предложенному Заде, главная идея которого заключается в использовании для моделирования рассуждений нечеткой логики. Особенность нечеткой логики состоит в том, что она соединяет черты логики предикатов и теории вероятностей в единой общей модели, которая в качестве частных случаев включает в себя большую часть типов приближенных рассуждений.
Типы, источники и причины возникновения неопределенной информации в таких системах довольно разработаны. Первый тип неопределенности связан с надежностью информации – неопределенность может присутствовать в фактическом знании. Второй тип обусловлен неточностью языка представления правил, так как если правило не выражено на формальном языке, его значение не может быть выражено точно. Третий тип неопределенности возникает, когда вывод основан на неполной информации. Четвертый тип неопределенности появляется при агрегации правил, полученных из различных источников или от различных экспертов.
Среди предложенных в последнее время подходов, так или иначе учитывающих эти типы неопределенности, особое место занимают три подхода:
1. вероятностный вывод;
2. подход, основанный на теории свидетельств;
3. подход теории возможностей.