

Потоки ввода-вывода: разновидности, иерархия классов.
Обычно часть вычислительной платформы, которая отвечает за обмен данным, так и называется - система ввода/вывода. В Java она представлена пакетом java.io (input/output).
В Java для описания работы по вводу/выводу используется специальное понятие поток данных (stream). Поток данных связан с некоторым источником или приемником данных, способных получать или предоставлять информацию
В Java два типа потоков:
InputStream, OutputStream - байтовые потоки ввода и вывода;
Абстрактный класс InputStream предоставляет начальный интерфейс к потоку ввода данных и частично реализует его. С помощью набора методов, реализуемого классом InputStream, можно читать байты или массивы байтов, узнавать количество доступных для чтения данных, отмечать место в потоке, где в настоящий момент происходит чтение, сбрасывать указатель текущей позиции в потоке и пропускать ненужные байты в потоке.
Открыть поток ввода можно, создав объект класса InputStream. Закрыть его можно двумя способами: дождаться, пока сборщик мусора (garbage collector) Java будет искать в памяти компьютера неиспользуемые классы и закроет ваш поток, или же закрыть его методом close(), как обычно и делается.
Для создания потоков ввода применяется другой класс - OutputStream, который, как и InputStream, является абстрактным. Методы, предоставляемые OutputStream, позволяют записывать байты и массивы байтов в поток вывода. Как и InputStream, поток OutputStream открывается, когда вы его создаете, и закрывается либо сборщиком мусора, либо методом close().
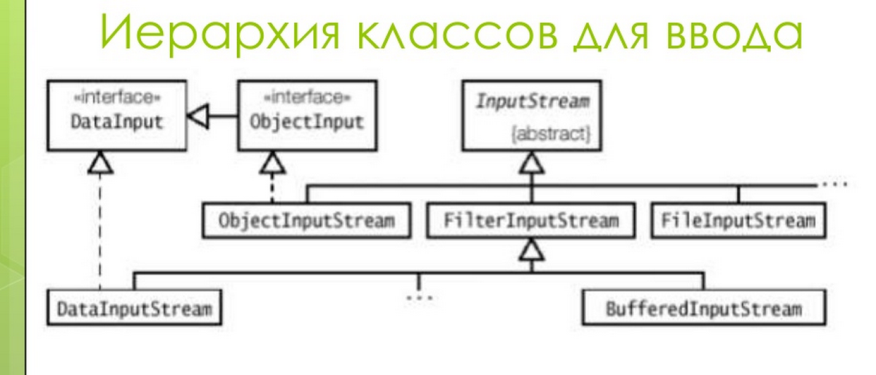
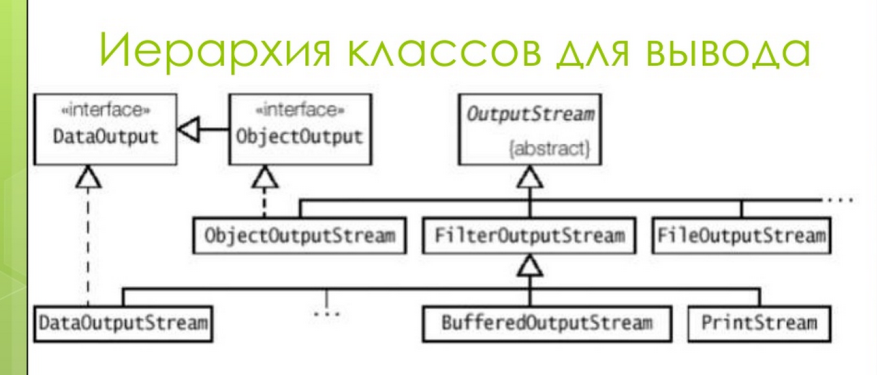
Reader, Writer - символьные потоки ввода и вывода. За правильное использование символов в операциях ввода/вывода предназначены наследники классов Reader (чтение) и Writer (запись). Их иерархия представлена
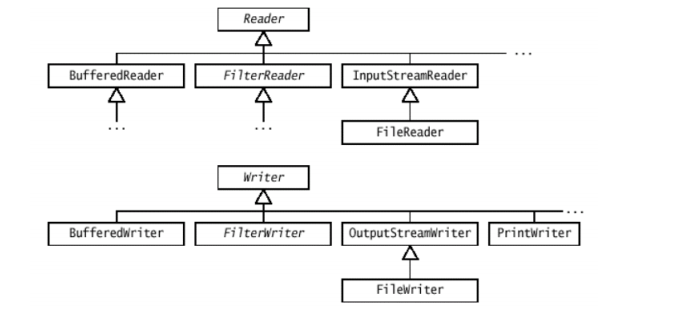
Потоки ввода-вывода: байтовые, символьные, буферизированные потоки.
Байтовые и символьные потоки Java 2 определяет два типа потоков: байтовый и символьный. Байтовые потоки предоставляют удобные средства для обработки ввода и вывода байт. Байтовые потоки используются, например, при чтении или записи данных в двоичном коде. Символьные потоки предоставляют удобные средства для обработки ввода и вывода символов. Они используют Unicode и поэтому могут быть. Кроме того, в некоторых случаях символьные потоки более эффективны, чем байтовые. Первоначальная версия Java (Java 1.0) не включала символьные потоки, и таким образом, весь ввод/вывод был байтовым. Символьные потоки были добавлены в Java 1.1, а некоторые байтовые классы и методы были исключены.
Классы байтовых потоков Байтовые потоки определяются в двух иерархиях классов. Наверху этой иерархии — два абстрактных класса: InputStream и OutputStream. Каждый из этих абстрактных классов имеет несколько конкретных подклассов , которые обрабатывают различия между разными устройствами, такими, как дисковые файлы, сетевые соединения и даже буферы памяти. Абстрактные классы InputStream и OutputStream определяют несколько ключевых методов, которые реализуются другими поточными классами. Два наиболее важных— read() и write(), которые соответственно читают и записывают байты данных. Оба метода объявлены как абстрактные внутри классов InputStream и OutputStream и переопределяются производными поточными классами.
Классы символьных потоков Символьные потоки определены в двух иерархиях классов. Наверху этой иерархии два абстрактных класса: Reader и Writer. Они обрабатывают потоки символов Unicode. В Java существуют несколько конкретных подклассов каждого из них. Классы Reader и Writer – наследникиInputStream и OutputStream. Если с их помощью записывать или считывать текст, то сначала необходимо сопоставить каждому символу его числовой код. Такое соответствие называется кодировкой. Классы символьных потоков показаны в таблице. Абстрактные классы Reader и Writer определяют несколько ключевых методов, которые реализуются другими поточными классами. Два самых важных метода — read() и write(), которые читают и записывают символы данных, соответственно. Они переопределяются производными поточными классами.
Буферизованные Потоки
Буферизованные входные потоковые данные чтения от области памяти, известной как буфер; собственный входной API вызывают только, когда буфер пуст. Точно так же буферизованные потоки вывода пишут данные в буфер, и собственный выходной API вызывают только, когда буфер полон.
Программа может преобразовать небуферизованный поток в буферизованный поток,
Есть четыре буферизованных потоковых класса, используемые, чтобы обернуть небуферизованные потоки: BufferedInputStream и BufferedOutputStream создаёт буферизованные потоки байтов, в то время как BufferedReader иBufferedWriter создаёт буферизованные символьные потоки.
Потоки ввода-вывода: стандартные потоки, класс файла, объектные потоки.
Cтандартные потоки
Три потока определены в классе system статическими полями in, out и err. Их можно использовать без всяких дополнительных определений. Они называются соответственно стандартным вводом (stdin), стандартным выводом (stdout) и стандартным выводом сообщений (stderr). Эти стандартные потоки могут быть соединены с разными конкретными устройствами ввода и вывода.
Потоки out и err — это экземпляры класса Printstream, организующего выходной поток байтов. Эти экземпляры выводят информацию на консоль методами print (), println () и write (), которых в классе Printstream имеется около двадцати для разных типов аргументов.
Поток err предназначен для вывода системных сообщений программы: трассировки, сообщений об ошибках или, просто, о выполнении каких-то этапов программы. Такие сведения обычно заносятся в специальные журналы, log-файлы, а не выводятся на консоль. В Java есть средства переназначения потока, например, с консоли в файл.
Поток in — это экземпляр класса inputstream. Он назначен на клавиатурный ввод с консоли методами read(). Класс inputstream абстрактный, поэтому реально используется какой-то из его подклассов.
класс файла
Для работы с физическим файлами и каталогами (директориями), расположенными на внешних носителях, в приложениях Java используются классы из пакета java.io.
Класс File служит для хранения и обработки в качестве объектов каталогов и имен файлов. Этот класс не содержит методы для работы с содержимым файла, но позволяет манипулировать такими свойствами файла, как права доступа, дата и время создания, путь в иерархии каталогов, создание, удаление файла, изменение его имени и каталога и т.д.
Объект класса File создается одним из нижеприведенных способов:
File myFile = new File(”\\com\\myfile.txt”);
File myDir = new File(”c:\\jdk1.6.0\\src\\java\\io”);
File myFile = new File(myDir, ”File.java”);
File myFile = new File(”c:\\com”, ”myfile.txt”);
File myFile = new File(new URI(”Интернет-адрес”));
В первом случае создается объект, соответствующий файлу, во втором – подкаталогу. Третий и четвертый случаи идентичны. Для создания объекта указывается каталог и имя файла. В пятом – создается объект, соответствующий адресу
в Интернете.
При создании объекта класса File любым из конструкторов компилятор не выполняет проверку на существование физического файла с заданным путем.
Объектные Потоки
Так же, как потоки данных поддерживают ввод-вывод примитивных типов данных, объектные потоки поддерживают ввод-вывод объектов. Больше всего, но не все, стандартные классы поддерживают сериализацию своих объектов. Те, которые действительно реализуют интерфейс маркера Serializable.
Объектные потоковые классы ObjectInputStream и ObjectOutputStream. Эти классы реализация ObjectInput и ObjectOutput, которые являются подынтерфейсами DataInput и DataOutput. Это означает, что все примитивные методы ввода-вывода данных, покрытые Потоками данных, также реализуются в объектных потоках. Таким образом, объектный поток может содержать смесь примитивных и объектных значений. Если readObject() не возвращает объектный ожидаемый тип, пытаясь бросить его к корректному типу может бросить a ClassNotFoundException.
Сериализация: понятие, процесс сериализации и десериализации
Сериализация это процесс сохранения состояния объекта в последовательность байт; десериализация это процесс восстановления объекта, из этих байт. Java Serialization API предоставляет стандартный механизм для создания сериализуемых объектов.
Зачем сериализация нужна?
В сегодняшнем мире типичное промышленное приложение будет иметь множество компонентов и будет распространено через различные системы и сети. В Java всё представлено в виде объектов; Если двум компонентам Java необходимо общаться друг с другом, то им необходим механизм для обмена данными. Есть несколько способов реализовать этот механизм. Первый способ это разработать собственный протокол и передать объект. Это означает, что получатель должен знать протокол, используемый отправителем для воссоздания объекта, что усложняет разработку сторонних компонентов. Следовательно, должен быть универсальный и эффективный протокол передачи объектов между компонентами. Сериализация создана для этого, и компоненты Java используют этот протокол для передачи объектов.
Как сериализовать объект?
Для начала следует убедиться, что класс сериализуемого объекта реализует интерфейс java.io.Serializable.
Листинг 1.
import java.io.Serializable; class TestSerial implements Serializable { public byte version = 100; public byte count = 0; }
Интерфейс Serializable это интерфейс-маркер; в нём не задекларировано ни одного метода. Но говорит сериализующему механизму, что класс может быть сериализован. Теперь у нас есть всё необходимое для сериализации объекта, следующим шагом будет фактическая сериализация объекта. Она делается вызовом метода writeObject() класса java.io.ObjectOutputStream, как показано в листинге 2. Листинг 2.
public static void main(String args[]) throws IOException { FileOutputStream fos = new FileOutputStream("temp.out"); ObjectOutputStream oos = new ObjectOutputStream(fos); TestSerial ts = new TestSerial(); oos.writeObject(ts); oos.flush(); oos.close(); }
Алгоритм сериализации Java
Алгоритм сериализации делает следующие вещи:
запись метаданных о классе ассоциированном с объектом
рекурсивная запись описания суперклассов, до тех пор пока не будет достигнут java.lang.object
после окончания записи метаданных начинается запись фактических данных ассоциированных с экземпляром, только в этот раз начинается запись с самого верхнего суперкласса
рекурсивная запись данных ассоциированных с экземпляром начиная с самого низшего суперкласса
Сериализация: изменение протокола по умолчанию, создание собственного протокола
Сериализация объектов - это процесс сохранения состояния объектов в виде последовательности байтов, а также процесс восстановления в дальнейшем из этих байтов "живых" объектов. Java Serialization API предоставляет разработчикам Java стандартный механизм управления сериализацией объектов. API мал и легок в применении, а его классы и методы просты для понимания.
Изменение протокола по умолчанию
-------------------
Создание своего собственного протокола: интерфейс Externalizable
Вместо реализации интерфейса Serializable, можно реализовать интерфейс Externalizable, который содержит два метода:
public void writeExternal(ObjectOutput out) throws IOException;
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;
Для создания собственного протокола нужно просто переопределить эти два метода. Здесь ничего не делается автоматически. Протокол полностью в ваших руках. Хотя это и наболее сложный способ, при этом он наиболее контролируемый. Возьмем, к примеру, ситуацию с альтернативным типом сериализации: запись и чтение PDF файлов Java приложением. Если вы знаете как читать и записывать PDF файлы (требуется определенная последовательность байт), вы можете создать протокол с учетом специфики PDF используя методы writeExternal и readExternal.
Так же, как и в рассмотренных случаях, нет никакой разницы в том, как используется класс, реализующий Externalizable. Вы просто вызываете методы writeObject() или readObject() и эти расширяемые методы будут вызываться автоматически.
GUI: AWT против Swing (различия), иерархия классов, менеджеры расположения.
Язык Java содержит 2 библиотеки классов, предназначенных для разработки приложений, реализующих графический интерфейс пользователя (GUI – graphics user interface):
- библиотека AWT (Abstract Window Toolkit – набор абстракций для работы с окнами) поставляется в составе JDK в пакете java.awt
-библиотека JFC (Java Foundation Classes) более известная как Swing поставляется в составе JDK в пакете javax.swing.
В первых версиях языка (Java 1.0, 1.1) программистам была доступна только библиотека AWT, JFC пакет впервые был представлен общественности на "JavaOne developer" конференции в 1997 году и был включен в версию Java 2. Он расширяет функциональность обычных компонентов (меток, кнопок, переключателей, списков и т.п.) и добавляет новые: панели со вкладками, панели с прокруткой, деревья и таблицы и др.
Важно отметить, что в отличие от AWT-компонентов Swing-компоненты не реализованы специфическим для платформы кодом. Вместо этого они написаны полностью на Java, поэтому являются платформно независимыми. Такие элементы принято называть облегченными (lightweight).
Хотя Java 2 продолжает поддерживать пакет AWT, но по приведенным выше причинам Sun настоятельно рекомендует использовать Swing. Для облегчения работы программистов названия Swing элементов начинаются с буквы J в отличие от названий в AWT (например, Button в AWT и JButton в Swing).
Ч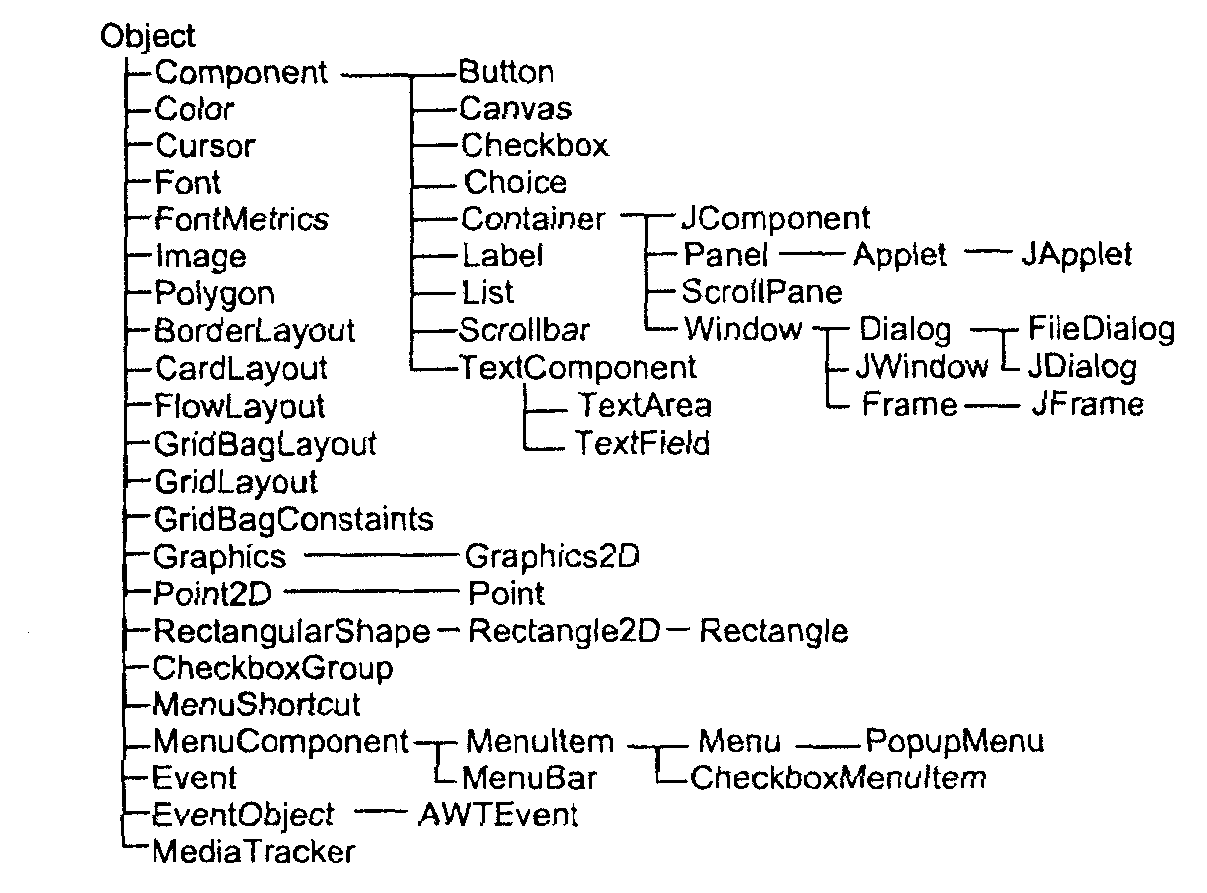 асть
иерархии классов библиотек AWT
и Swing представлена на рис
асть
иерархии классов библиотек AWT
и Swing представлена на рис