

18. Метод динамического программирования.
В задаче динамического программирования состояние динамической системы характеризуется n переменными состояния (фазовыми переменными) x1(t),...,хn(t), удовлетворяющими следующей системе дифференциальных уравнений первого порядка, называемых уравнениями состояния:
![]()
(1)
Здесь u1,…,um - управляющие воздействия. Тогда задача состоит в определении управлений
![]()
![]()
переводящих систему из состояния в
и минимизирующих критерий-функционал (критерий качества)
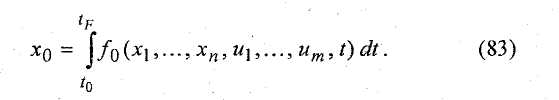
(2)
Предположим, что управляющие переменные удовлетворяют ограничению
![]() (3)
(3)
определяющим замкнутую область допустимых управлений.
Критерием качества (83) может являться, например, цена объекта, среднеквадратичная ошибка в обработке результатов эксперимента, время достижения цели и т.п.
Для решения задачи управления требуется задать подходящие граничные условия:
![]()
(4)
При этом начальное t0 и конечное tF времена могут быть неизвестными.
Предположим, что наложенные на управляющие переменные ограничения (3) имеют
![]()
вид (5)
Введем также
вспомогательные переменные
![]() ,
i=0,1,…,n
и функцию Гамильтона (гамильтониан):
,
i=0,1,…,n
и функцию Гамильтона (гамильтониан):
![]()
(6)
С помощью гамильтониана
Н исходная система дифференциальных
уравнений (1) и уравнения, необходимые
для определения вспомогательных функций
![]() ,
представляются в виде:
,
представляются в виде:
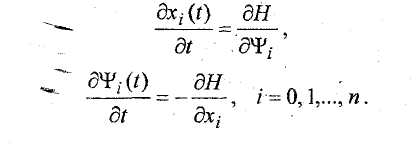
(7)
Уравнения (7), являющиеся необходимым условием экстремума функционала (2), называются уравнениями Гамильтона-Эйлера. Таким образом, оптимальное управление
uopt(t)=(u1opt(t),…,umopt(t)) определяет оптимальную траекторию xopt(t) в n- мерном фазовом пространстве и вдоль нее гамильтониан H удовлетворяет условиям (7).
19. Составляющие внемашинного информационного обеспечения систем управления. Системы классификации и кодирования информации.
Информационное обеспечение – это совокупность методов и средств по размещению и организации информации, включающих в себя системы: классификации и кодирования; унифицированные системы документации, рационализации документооборота и форм документов; методов создания внутримашинной информационной базы ИС.
Таким образом, сферы информационного обеспечения:
Внемашинная сфера (внемашинная информационная база и средства организации и ведения внемашинной информационной базы)
Внутримашинная сфера (внутримашинная информационная база и средства организации и ведения внутримашинной информационной базы)
Внемашинная информационная база служит источником формирования внутримашинной информационной базы. Наиболее важными вопросами подготовки внемашинного информационного обеспечения предметной области являются:
определение состава документов, содержащих необходимую информацию для решения задач пользователя;
определение форм документов и структуры информации (выявление структурных единиц информации и их взаимосвязей);
классификация и кодирование информации, обрабатываемой в задачах пользователя;
разработка инструктивных и методических материалов по ведению документов информации для обработки.
К средствам организации и ведения внемашинной информационной базы относятся:
Системы классификации и кодирования информации
Унифицированные системы документов
Инструктивные и методические материалы по ведению документов
Системы классификации и кодирования информации. Методы кодирования.
Разработаны три метода классификации объектов: иерархический, фасетный, дескрипторный. Эти методы различаются разной стратегией применения классификационных признаков.
Система кодирования - совокупность правил кодового обозначения объектов.
Код строится на базе алфавита, состоящего из букв, цифр и других символов. Код характеризуется:
длиной - число позиций в коде (может быть постоянная и переменная);
структурой - порядок расположения в коде символов, используемых для обозначения классификационного признака.
Можно выделить две группы методов, используемых в системе кодирования объектов которые образуют:
классификационную систему кодирования, ориентированную на проведение предварительной классификации объектов либо на основе иерархической системы, либо на основе фасетной системы;
регистрационную систему кодирования, не требующую предварительной классификации объектов
Различают последовательное и параллельное классификационное кодирование.
Последовательное кодирование используется для иерархической классификационной структуры. Параллельное кодирование используется для фасетной системы классификации.
Регистрационное кодирование используется для однозначной идентификации объектов и не требует предварительной классификации объектов. Различают порядковую и серийно-порядковую систему.
Порядковая система кодирования предполагает последовательную нумерацию объектов числами натурального ряда. Этот порядок может быть случайным или определяться после предварительного упорядочения объектов, например по алфавиту. Этот метод применяется в том случае, когда количество объектов невелико, например кодирование названий факультетов университета, кодирование студентов в учебной группе.
Серийно-порядковая система кодирования предусматривает предварительное выделение групп объектов, которые составляют серию, а затем в каждой серии производится порядковая нумерация объектов. Каждая серия также будет иметь порядковую нумерацию. По своей сути серийно-порядковая система является смешанной: классифицирующей и идентифицирующей. Применяется тогда, когда количество групп невелико.
Рассмотрим основные идеи методов классификации для создания систем классификации и кодирования.
Иерархическая система классификации — самая традиционная. Она имеет структуру «древа знаний», в котором определенная совокупность знаний (универсум) последовательно делится на все более узкие подклассы. Существует много универсальных иерархических классификаций, охватывающих сразу все отрасли человеческих знаний.
Например, в библиографической практике наиболее широко используются Библиотечно-библиографическая классификация (ББК), Универсальная десятичная классификация (УДК), Классификация для массовых библиотек и некоторые другие.
Количество уровней классификации, соответствующее числу признаков, выбранных в качестве основания деления, характеризует глубину классификации.
К достоинствам иерархической системы классификации можно отнести
простоту построения; использование независимых классификационных признаков в различных ветвях иерархической структуры.
А к недостаткам - жесткую структуру, которая приводит к сложности внесения изменений, так как приходится перераспределять все классификационные группировки; невозможность группировать объекты по заранее не предусмотренным сочетаниям признаков.
Суть метода последовательного кодирования заключается в следующем: сначала записывается код старшей группировки 1-го уровня, затем код группировки 2-го уровня, затем код группировки 3-го уровня и т.д. В результате получается кодовая комбинация, каждый разряд которой содержит информацию о специфике выделенной группы на каждом уровне иерархической структуры.
Фасетная система классификации (ее еще называют параллельной классификацией) в отличие от иерархической позволяет выбирать признаки классификации независимо как друг от друга, так и от семантического содержания классифицируемого объекта. Признаки классификации называются фасетами (facet - рамка). Каждый фасет (Фi) содержит совокупность однородных значений данного классификационного признака. Причем значения в фасете могут располагаться в произвольном порядке, хотя предпочтительнее их упорядочение.
Первая фасетная классификация (Классификация двоеточием) была разработана известным индийским библиографом и библиотекарем Ш.Р. Ранганатаном в 1933 г.
Механизм построения фасетной классификации и ее использование при индексировании документов можно показать на примере классификации кинофильмов. В качестве основных фасетов для кинофильмов выделим, например, жанр, метраж, цвет и формат. В каждом фасете перечислим свойственные ему конкретные характеристики. В результате получим классификацию, представленную в таблице.
Используя методику параллельного кодирования с помощью фасетной формулы или кода можно выразить содержание документа, относящееся к кинофильму любого класса.
Например:
Ж1:М1:Ц2:Ф2 — художественный полнометражный цветной широкоэкранный.
Жанр |
Метраж |
Цвет |
Формат |
Ж1 художественные |
М1 полнометражные |
Ц1 черно-белые |
Ф1 обычные |
Ж2 документальные |
М2 короткометражные |
Ц2 цветные |
Ф2 широкоэкранные |
Ж3 хроникальные |
|
Ц3 комбинированные |
|
Ж2:М2:Ц1:Ф1 — документальный короткометражный черно-белый обычный. И т. д.
Дескриптор — ключевое слово, определяющее некоторое понятие, которое формирует описание объекта и дает принадлежность этого объекта к классу, группе и т.д.
Введем понятие текстовой БД. Объектами хранения в текстовых БД являются тексты. Под текстом будут пониматься неструктурированные данные, построенные из строк.
Основной целью любой текстовой БД является хранение, поиск и выдача документов, соответствующих запросу пользователя. Такие документы принято называть релевантными.
Ввиду того, что автоматизированный поиск документов на естественных языках достаточно затруднен, возникает вопрос о проектировании некоторых формальных языков, предназначенных для отображения основного смыслового содержания документов и запросов в БД. Такие языки называют информационно-поисковыми. В настоящее время разработано достаточно большое количество информационно-поисковых языков, которые отличаются не только по своим изобразительным свойствам, но и по степени семантической силы.
Информационно – поисковые языки, получившие название дескрипторных, основаны на применении принципов координатного индексирования, при котором смысловое содержание документа может быть с определенной степенью точности и полноты задано списком ключевых слов, содержащихся в тексте.
Дескрипторные языки привязаны к лексике текстов. Ключевые слова из текстов выбираются исходя из разных целей, соответственно, критерии выбора могут различаться. Для построения дескрипторного языка критерием отбора ключевых слов, как правило, служат информативность слова и частота его встречаемости в тексте. Универсальными структурами дескрипторного языка являются лексические единицы, парадигматические и синтагматические отношения.
Парадигматические отношения могут задаваться как:
Отношения вид–род (вышестоящий дескриптор);
Отношения род–вид (нижестоящие дескрипторы);
Синонимы;
Ассоциативные связи.
В большинстве автоматизированных информационных систем при индексировании документов и запросов применяется контроль с помощью тезауруса.
В тезаурусы помещаются дескрипторы и недескрипторы, хотя существуют тезаурусы только из дескрипторов. Как дескрипторы, так и недескрипторы приводят к единой грамматической форме (нормализуют). Как правило, дескрипторы употребляются в форме существительных или именных словосочетаний. Тезаурус может быть построен по принципу дескрипторных статей, состоявших из заглавного дескриптора и списка дескрипторов и недескрипторов с обозначением парадигматических отношений.
Парадигматические отношения представляют собой внетекстовые отношения между лексическими единицами. На их основании происходит группировка лексических единиц в парадигмы. Синтагматические отношения представляют собой отношения лексических единиц в тексте, т.е. они выражают семантику контекста.
При переводе основного смыслового содержания документов и запросов с естественного языка на дескрипторный информационно – поисковый язык существуют определенные правила, называемые системой индексирования. Результатом перевода документа является поисковый образ документа, а запроса–поисковый образ запроса.