50. Hipo-технология
HIPO–технология – это многоуровневая дисциплина проектирования и документирования программ. В HIPO – технологии, для этой цели применяются три типа диаграмм (рис.20). Первый тип диаграмм – вспомогательный (рис.20, а) – он играет роль, аналогичную оглавлению всего проекта. Диаграммы первого типа заполняются в конце процесса проектирования, при оформлении документации и в самом процессе, активно, не участвуют. Второй тип диаграмм задает иерархию связи и сборки диаграмм третьего типа (рис.20, б). Диаграммы третьего типа являются основными в HIPO–технологии и предназначены для описания входа, выхода и процесса обработки информации (рис.20в). Эти диаграммы называются IPO – диаграммами.
В IPO–диаграммах выделены три колонки. В первой колонке, слева, записывается входная информация, в последней – выходная, а в средней, описан процесс обработки информации (алгоритм) (рис.20,в) язык заполнения IPO–диаграмм не оговаривается и может быть любым. В этом языке называется “что” делает каждый программный модуль на данном уровне проектирования. Каждая IPO–диаграмма, соответствует одному уровню (этапу, шагу) проектирования. На одной диаграмме может быть не более 6 – 7 программных блоков, уточняющих характер работы данной диаграммы. Это заставляет разработчика системы разбить ее по уровням, на небольшое число подсистем (не более 6-7) и построить для всей системы некоторое дерево проектирования. Название, присваиваемое данному блоку на одной диаграмме, должно быть кратким, общепонятным и обязательно сохраняться без изменений на всех диаграммах системы. При необходимости, каждое название может быть уточнено, расширено и пояснено в специальной области IPO–диаграмм, которая называется областью спецификаций. В этой области могут быть записаны некоторые рекомендации по тому, “как” реализуется блок на данном уровне рассмотрения.
Все IPO–диаграммы имеют строго формализуемую систему ссылок, которая задается наглядно на IPO–диаграммах второго типа (рис.20б). Если какой-либо блок уточняется другими IPO–диаграммами, то ему присваивается соответствующий номер. Если блок не имеет уточняющего номера связи, то его детализация закончена и он может быть непосредственно закодирован на соответствующем языке системы программирования. Формализованная система ссылок, позволяет разработчику и руководителю, легко следить за состоянием и влиять на процесс проектирования ПС. Согласно HIPO–технологии, процесс проектирования системы заканчивается только после окончания заполнения всех IPO–диаграмм проекта и увязки их друг с другом. Поэтому, процесс проектирования ПС сильно затягивается, зато процесс кодирования, отладки и выпуска документации осуществляется почти автоматически и может проводиться менее квалифицированным персоналом.
Важным в HIPO–технологии является явное указание данных на входе и выходе каждого шага алгоритма (процесса проектирования). Все данные задаются и связываются с процессом обработки данных, а так же помещаются структурно, в одно и то же место – слева и справа проектного листа (рис.20, в).
В HIPO–технологии существенную роль играет человеческий фактор и способ организации коллектива разработчиков для выполнения проекта. Такое утверждение справедливо для всех вышеописанных технологий.

51. Р-технология разработки программного обеспечения
Все существующие способы повышения производительности труда программистов, основываются на модификации надстройки, тогда, как базис – принцип обработки информации в самой ЭВМ – остается неизменным (см.рис.17). Смысл работ по созданию R – технологий, заключается в модификации базиса таким образом, чтобы упростить процесс программирования, приблизить его к производственному процессу, более естественному для человека. Для этого предоставляется программисту программно – реализованная вычислительная машина, названная R – машиной, или сокращенно – RВМ. Затем, для этой машины строится соответствующая надстройка – R –язык и технология программирования, называемая R – технологией.В RВМ, программисту, предлагается включить в саму программу, явно заданную связь с данными, для чего, логическую схему программы (ЛСП), необходимо совместить с логической структурой данных (ЛСД), а функциональную часть программы, выделить отдельно. Для записи программы в R – технологии, предлагается использовать язык нагруженных ориентированных графов. На этом языке ЛСД, совмещенное с ЛСП, задается записью на дугах графа, соответствующих символов и предикатов, а функции обработки выделенных структур задаются на тех же дугах записью последовательности, только линейных операторов: операторов присвоения; операторов обращения к процедурам – функциям; операторов пересылки между памятями RВМ (рис.23). Обработка данных, не соответствующих ЛСД, блокируется – приводит к останову RВМ.Для RВМ изменилась технология программирования (рис.21). Она делится на два основных этапа. На первом – формально определяется структура информации без связи с каким-либо алгоритмом ее обработки. На втором этапе, эта структура рассматривается, как логическая схема, соответствующего алгоритма ее обработки и как некоторая схема работы коллектива программистов по доопределению исходной стуктуры. Доопределение, осуществляется только линейными операторами: операторы присвоения; операторы, полученные и стандартизованные на предыдущих этапах развития работ по R – технологии; операторы, записанные предварительно на языке одной из систем программирования и введенные пользователем в библиотеку.Иногда, в процессе доопределения, модифицируется исходная ЛСД, полученная на первом этапе. В результате доопределения, получается R–программа, которая, с помощью R–технологического комплекса автоматически генерируется в готовый программный продукт для работы на существующих ЭВМ.
Рассмотрим пример. Пусть требуется подсчитать в тексте число символов А и В. Текст ограничен справа символом “┐”.
Процесс проектирования R–программы, начинается с формального определения структуры исходного текста, иначе, ЛСД, в котором надо подсчитать число символов А и В. Определение производится независимо от какого-либо алгоритма выполнения этого подсчета. Строим нагруженный ориентированный граф (рис.22), где дуга “все” – символ внутреннего алфавита R–машины, означающий, в данном случае, что на дуге “все” может быть любой символ из тех, которые используются в тексте, дуга “А”, дуга” В” и дуга “┐”– выделяют символы “А” и “В”, которые следует подсчитать и символ “┐”говорит об окончании текста.На втором этапе, эта структура рассматривается, как ЛСП. Для правильного чтения R – программы, следует придерживаться фиксированного порядка просмотра дуг: около каждой вершины сверху – вниз, слева – направо; дуги, не содержащие записей, просматриваются в последнюю очередь. Полученную R–программу доопределяют до алгоритма подсчета символов А и В, для чего дописывается вершина и дуга начальных установок (НАЧУСТ), а три другие дуги доопределяются соответствующими линейными операторами (рис.23). Такой граф является окончательной R – программой. Этот граф записывается на R – языке:
R–программа: СЧЕТ БУКВ А В
счетчики r,f
НАЧУСТ r=0
f=0 СЧЕТ
СЧЕТ В f=f+1 СЧЕТ
А r=r+1 СЧЕТ
ПЕЧАТЬ(r,f) выход
все счет
конец
и вводится в машину. По этой записи формируется программа для реальной ЭВМ.
Анализ примера позволяет сделать следующие выводы общего характера. Во-первых, R–программа – это наглядный способ записи алгоритма. Во-вторых, для записи алгоритма в R – программе используются только линейные операторы типа операторов присвоения, обращения к процедурам (записи, чтения, поиска и т.д.). В-третьих, R–программа – это наиболее компактный способ записи алгоритма. Обычно R–программа в 1,5-3 раза содержит меньше символов, чем аналогичная программа на языке высокого уровня.
23. Проектирование технологических процессов методом адресации: метод заимствования ТП-аналога с параметрической настройкой.

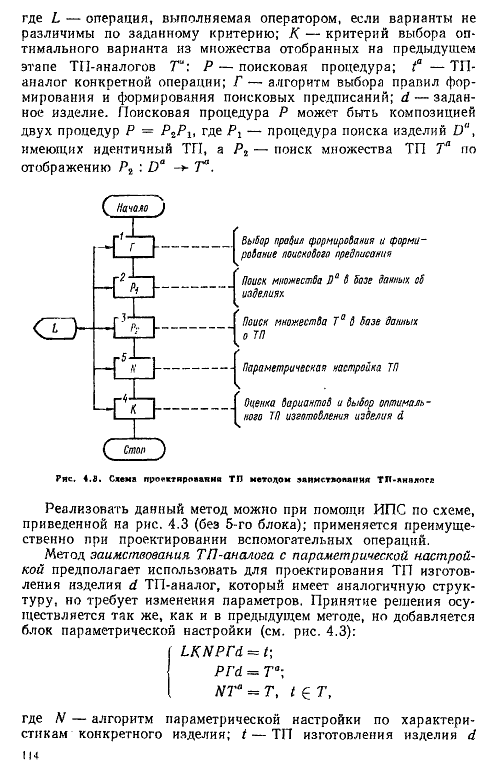

24. Проектирование технологических процессов методом адресации: метод заимствования ТП-аналога с изменением его структуры и параметрической настройкой.

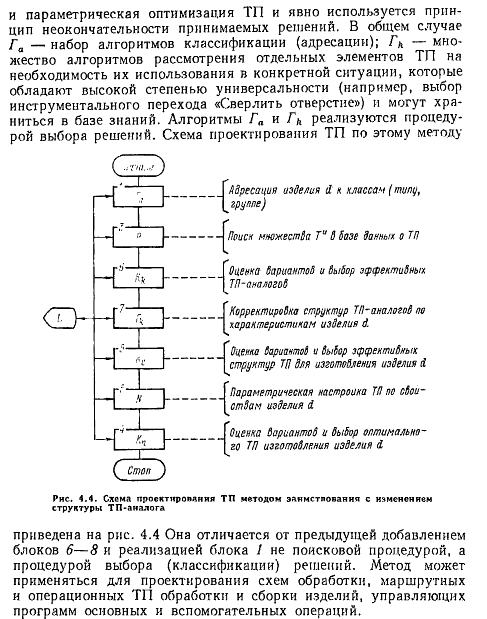
25. Проектирование технологических процессов методом синтеза: метод синтеза с использованием ТП-аналога



26. Проектирование технологических процессов методом синтеза: метод синтеза с элементами-аналога

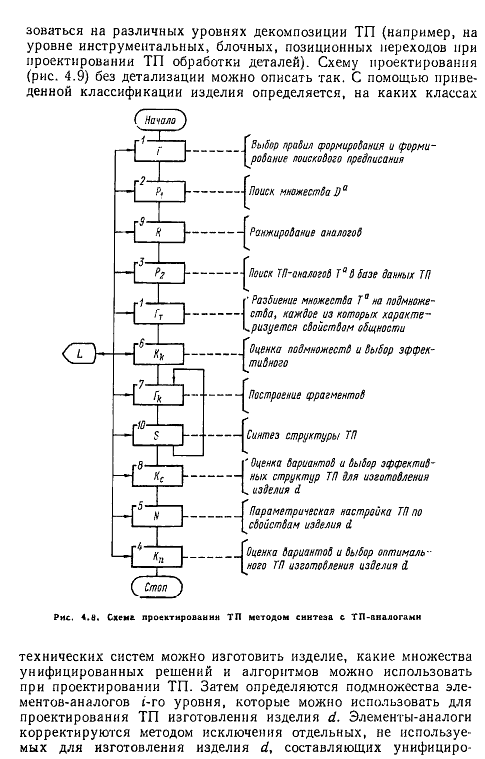
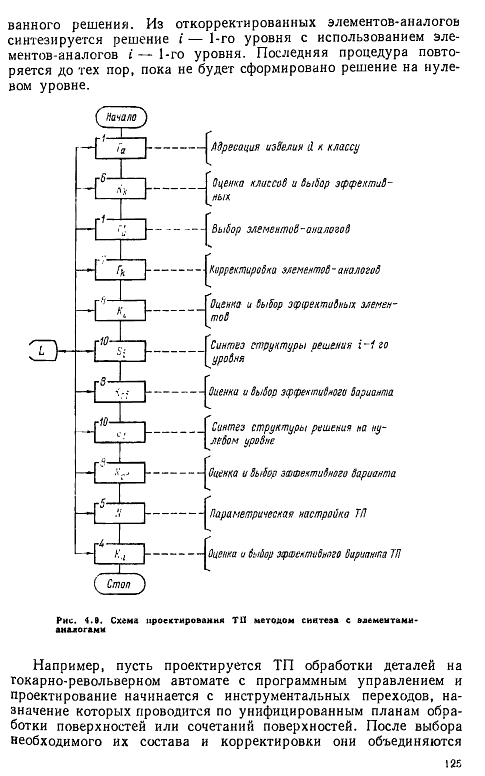

27. Проектирование технологических процессов методом синтеза: метод синтеза без аналогов


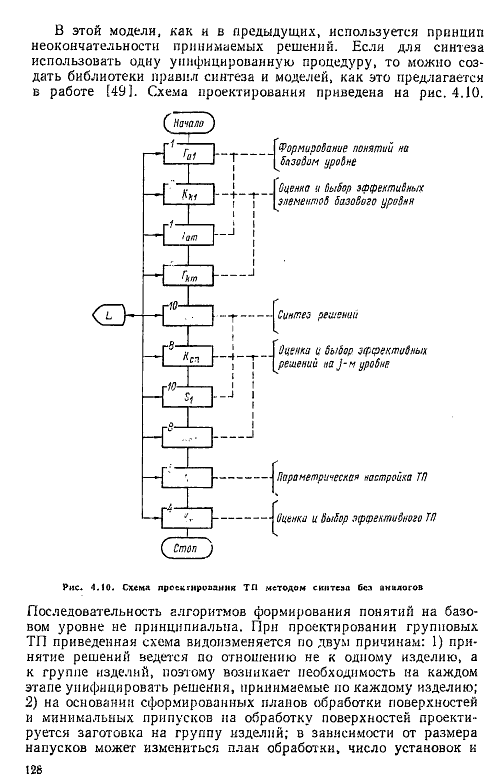
распределение переходов по операциям, поэтому возникает необходимость
во вторичном проектировании ТП, но уже сверху
вниз, т. е. от маршрутов до ходов.
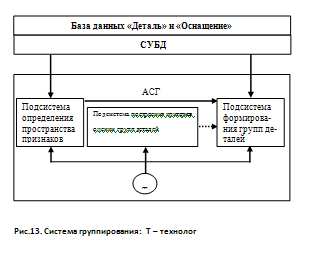
28. Система группирования деталей: назначение, методы группирования, их достоинства и недостатки, состав и структура, принцип действия
В настоящее время группирование деталей осуществляется по двум основным методикам: на основе построения классификационных рядов и на основе анализа деталей в n-мерном признаковом пространстве. Рассмотрим вторую методику как наиболее перспективную для реализации на ЭВМ.
Постановка
задачи. Пусть задано множество деталей
D, каждая деталь d
D описывается n признаками d = (mi1,
mi2,…,min). Необходимо разбить множество
деталей D на D1, D2,…,Dk при условии
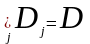 и в общем случае
и в общем случае
 .
Количество групп деталей заранее
неизвестно.
.
Количество групп деталей заранее
неизвестно.
Для решения задачи необходимо определить пространство признаков, в котором необходимо проводить разбиение множества деталей на группы, построить критерии оценки групп деталей, сформировать группы деталей. Поэтому в состав автоматизированной системы группирования (АСГ) деталей входят три подсистемы (рис.13). Работа этих подсистем предполагает организацию базы данных “Деталь” и “Оснащение” и обслуживание ее системой управления базами данных (СУБД).
Подсистема определения признакового пространства предназначена для анализа существующих групп деталей и формирования минимальной по составу системы признаков, в которой возможно группирование и последующая адресация новых деталей с одной из спроектированных групп деталей.
Анализ групп основывается на пространственно-геометрическом рассмотрении сформированных технологом групп в n-мерном пространстве признаков. Задача ставится следующим образом. Заданы элементы dD, тип решающего правила и допустимые затраты N0. Требуется найти такую систему признаков X, которая обеспечивала бы разделение групп при минимальных затратах на описание элементов множества D.
Система признаков должна быть такой, чтобы расстояние между исходными группами деталей были бы максимальны. Расстояние между группами – это геометрическое расстояние между центрами групп. Под затратами понимается стоимость ошибок распознавания.
Смысл формальных методов решения такой задачи сводится в основном к проверке выбранной технологом системы признаков на достаточность и необходимость. В процессе работы подсистемы допускается введение технологом новых признаков.
Подсистема построения критериев оценки групп вырабатывает вспомогательную информацию для подсистемы группирования, позволяющую установить оптимальный состав формируемых групп. В качестве критериев оценки групп можно использовать трудоемкость обработки групп деталей. Величиной, ограничивающей размер групп, служит фонд времени оборудования, предназначенного для обработки деталей на том или ином оборудовании от признаков Х, в котором описываются детали. В этом случае применяются методы множественной корреляции, группового учета аргументов и т.п.
Подсистема группирования служит для формирования групп деталей и для описания их в заданном признаковом пространстве. Алгоритм группирования деталей заключается в следующем.
Определяется расстояние между группируемыми деталями в пространстве признаков и строится матрица расстояний С = cij.
Сij =vk*fkj-fki,
где сij – расстояние между i-ой и j-ой деталями;
n – количество признаков;
vk – весовой коэффициент k-го признака;
fki и fkj – значение k-признака для i-ой и j-ой детали соответственно.
Для повышения объективности определения расстояния между деталями все признаки делятся на количественные (длина деталей, количество ступеней и т.п.) и качественные (группа обрабатываемости материала, наличие резьбы и т.п.). Для первой группы признаков расстояние определяется как разность численных значений, а для второй – подчиты-вается взвешенное расстояние по Хеммингу. В этом случае пространство качественных признаков представляет собой n-мерный двоичный куб, расстояние между вершинами которого ( по Хеммингу) равно числу несовпадающих разрядов, соответствующих n – разрядных двоичных векторов. Например, пусть даны два двоичных вектора OIII и IIIO, расстояние между ними равно 2.
Второй этап – это выявление центров группирования деталей. Для этого все множество деталей представляется в виде графа, в котором множеством вершин являются детали, а ребро между вершинами существует в том случае, когда расстояние между деталями Сij≤С0, где С0 является наперед заданным числом. Тогда отыскание центров группирования сводится к задаче отыскания максимально полных подграфов (клик) построенного графа. Те подграфы, для которых кликовое число (или плотность) максимально, берутся в качестве центров группирования. Кликовое число – это число вершин подграфов. В [Кристофидес Н. Теория графовов. Алгоритмический подход. М.: Мир, 1978] описан алгоритм отыскания максимальных, полных подграфов.
Затем определяется количество деталей, которые могут войти в группу, центр которой был определен на предыдущем этапе. Возможный размер группы (иначе радиус группирования) задается технологом, либо оценивается по критерию группирования.
Полученные группы оцениваются и отбираются те, которые включают максимальное количество деталей. Причем отобранные группы должны отличаться хотя бы одной деталью и объединение этих групп должно содержать все группируемые детали.
По данной методике формируются, в общем случае, группы с перекрытиями, т.е. одна деталь может попасть в две и большее количество групп.
Не следует путать два различных случая:
требования отсутствия зоны перекрытия между группами, которые спроектированы технологом и используются в подсистеме выбора признакового пространства, и
возможность и даже желательное наличие зоны перекрытия между группами при группировании деталей.
В первом случае требование не пересечения определяется соображениями уменьшения времени и повышения точности работы системы. Во втором случае речь идет о перекрытиях между вновь формируемыми группами. Здесь наличие зон перекрытия позволяет более гибко организовывать производственную систему, учитывать ее динамику. Практически, благодаря зонам перекрытия мы можем продлить “время жизни” создаваемых групп, что имеет крайне важное для производства значение. Группирование деталей, выбор оборудования для групп, оснащение их групповыми приспособлениями, разработка групповых ТП – все виды работы проводятся достаточно редко. В основном при поступлении новых деталей проводится их адресация к ранее существовавшим группам. Однако возможность адресации ограничивается загрузкой оборудования. Наличие зон перекрытия позволяет выравнивать загрузку за счет перераспределения деталей между группами. Причем, чем больше величина зон перекрытия, тем проще можно проводить перераспределение деталей. Ограничивается она затратами на оснащение групп, которые не должны превышать эффекта от возрастания "времени жизни” групп. Нетрудно заметить, что допущение перекрытия облегчает задачи определения графика запуска – выпуска деталей.