

Лекция №4
Имитация литературного, музыкального и иных видов творчества на ЭВМ.
В основе этих программ лежала идея об использовании генераторов случайных чисел, интерпретируемых как нотные знаки со всеми присущими им параметрами, для порождения музыкального произведения за счет отбора из генерируемого потока нот лишь тех, которые удовлетворяли бы определенным правилам. Эти правила заимствовались из музыковедческой литературы и отражали специфику восприятия музыки человеком. Таким образом, в этих программах, как и в некоторых программах автоматизированного реферирования или доказательства теорем, использовался случайный процесс, детерминируемый системой ограничивающих модельных правил. Этот прием оказался в дальнейшем полезным и для ряда программ искусственного интеллекта. А сама возможность имитации творческого процесса человека в такой области, которая всегда считалась вершиной его интеллектуальной деятельности, имела немаловажное значение для понимания возможностей ЭВМ в этой сфере.
В середине же 50-х годов делаются первые попытки использования ЭВМ для генерации связных текстов, как поэтических, так и прозаических. Позжн специалисты в области искусственного интеллекта обратили внимание на эти работы. Сейчас же машинная графика стала вполне самостоятельным направлением и подобно распознаванию образов развивается вне рамок искусственного интеллекта, хотя и испытывает его влияние на свои методы и представления.
Эти разработки привели к появлению первых моделей и систем, которые знаменовали собой переход к созданию новой науки – искусственного интеллекта.
Тенденции развития теории ИИ в современном мире. Интеллектуальные информационно-поисковые системы. Интеллектуальные ИС в сети Интернет.
1. Нейронные сети
Это направление стабильно держится на первом месте. Продолжается совершенствование алгоритмов обучения и классификации в масштабе реального времени, обработки естественных языков, распознавания изображений, речи, сигналов, а также создание моделей интеллектуального интерфейса, подстраивающегося под пользователя. Среди основных прикладных задач, решаемых с помощью нейронных сетей, - финансовое прогнозирование, раскопка данных, диагностика систем, контроль за деятельностью сетей, шифрование данных. 2. Эволюционные вычисления
На развитие сферы эволюционных вычислений (ЭВ; автономное и адаптивное поведение компьютерных приложений и робототехнических устройств) значительное влияние оказали прежде всего инвестиции в нанотехнологии. ЭВ затрагивают практические проблемы самосборки, самоконфигурирования и самовосстановления систем, состоящих из множества одновременно функционирующих узлов. При этом удается применять научные достижения из области цифровых автоматов.
Модели автономного поведения предполагается активно внедрять во всевозможные бытовые устройства, способные убирать помещения, заказывать и готовить пищу, водить автомобили и т. п.
3. На третьем - пятом местах (по популярности) располагаются большие группы различных технологий.
3.1 Нечеткая логика
Системы нечеткой логики активнее всего будут применяться преимущественно в гибридных управляющих системах.
3.2 Обработка изображений
Продолжается разработка способов представления и анализа изображений. Дальнейшие развитие получат средства поиска, индексирования и анализа смысла изображений, согласования содержимого справочных каталогов при автоматической каталогизации, организации защиты от копирования, а также машинное зрение, алгоритмы распознавания и классификации образов.
3.3. Экспертные системы
Спрос на экспертные системы остается на достаточно высоком уровне. Наибольшее внимание сегодня привлечено к системам принятия решений в масштабе времени, близком к реальному, средствам хранения, извлечения, анализа и моделирования знаний, системам динамического планирования.
3.4. Интеллектуальные приложения
Рост числа интеллектуальных приложений, способных быстро находить оптимальные решения комбинаторных проблем (возникающих, например, в транспортных задачах), связан с производственным и промышленным ростом в развитых странах.
3.5. Распределенные вычисления
Распространение компьютерных сетей и создание высокопроизводительных кластеров вызвали интерес к вопросам распределенных вычислений - балансировке ресурсов, оптимальной загрузке процессоров, самоконфигурированию устройств на максимальную эффективность, отслеживанию элементов, требующих обновления, выявлению несоответствий между объектами сети, диагностированию корректной работы программ, моделированию подобных систем.
3.7. Интеллектуальная инженерия
Оценки качества, выявления возможности повторного использования, решения задач на параллельных системах.
Программная инженерия постепенно превращается в так называемую интеллектуальную инженерию, рассматривающую более общие проблемы представления и обработки знаний (пока основные усилия в интеллектуальной инженерии сосредоточены на способах превращения информации в знания).
3.8. Самоорганизующиеся СУБД
Самоорганизующиеся СУБД будут способны гибко подстраиваться под профиль конкретной задачи и не потребуют администрирования.
4. Следующая по популярности группа технологий ИИ.
4.1. Автоматический анализ естественных языков .
4.2. Высокопроизводительный OLAP-анализ и раскопка данных, способы визуального задания запросов.
4.3. Медицинские системы, консультирующие врачей в экстренных ситуациях, роботы-манипуляторы для выполнения точных действий в ходе хирургических операций.
4.4. Создание полностью автоматизированных киберзаводов, планирование работ, синхронизация цепочек снабжения, авторизации финансовых транзакций путем анализа профилей пользователей.
5. Традиционно высок интерес к ИИ в среде разработчиков игр и развлекательных программ (это отдельная тема). Среди новых направлений их исследований - моделирование социального поведения, общения, человеческих эмоций, творчества.
Функционирование информационно-поисковой системы
Общая схема функционирования традиционной ИПС представлена на Рис. 1. Основными процессами в ИПС являются индексирование документов и поиск документов по запросу пользователя.
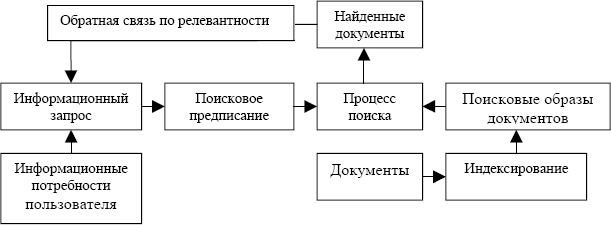
Рис. 1 Схема функционирования ИПС.
Процесс информационного поиска происходит следующим образом. Пользователь выражает свои информационные потребности в виде специального текста - информационного запроса к ИПС. Система формирует из информационного запроса поисковое предписание, переводя запрос на информационно-поисковый язык (ИПЯ). ИПЯ представляет собой формальный язык, который используется внутри ИПС для представления пользовательского запроса и хранимых документов. Описание документа на ИПЯ называется поисковым образом документа. В процессе поиска ИПС должна выбрать из массива документов те, которые содержательно релевантны запросу, то есть соответствуют информационным потребностям пользователя, выраженным в запросе. Такое определение релевантности не формально, поэтому определяют формальную релевантность, как соответствие, определяемое алгоритмически, путем сравнения поискового предписания и поискового образа документа. Критерий выдачи документа – формальное правило, определяющее степень формальной релевантности поискового образа документа и поискового предписания, по которому принимается решение о выдаче некоторого документа в ответ на информационный запрос.
В процессе индексирования, для каждого документа, хранящегося в системе, строится поисковый образ.
Обучение и самообучение. Адаптация и обучение
Все картинки, представленные на Error: Reference source not found, характеризуют задачу обучения. В каждой из этих задач задается несколько примеров (обучающая последовательность) правильно решенных задач. Задачу такого рода на описательном уровне можно сформулировать следующим образом: системе одновременно или последовательно предъявляются объекты без каких-либо указаний об их принадлежности к образам. Входное устройство системы отображает множество объектов на множество изображений и, используя некоторое заложенное в нее заранее свойство разделимости образов, производит самостоятельную классификацию этих объектов. После такого процесса самообучения система должна приобрести способность к распознаванию не только уже знакомых объектов (объектов из обучающей последовательности), но и тех, которые ранее не предъявлялись. Процессом самообучения некоторой системы называется такой процесс, в результате которого эта система без подсказки учителя приобретает способность к выработке одинаковых реакций на изображения объектов одного и того же образа и различных реакций на изображения различных образов.
Таким объективным свойством является свойство компактности образов. Взаимное расположение точек в выбранном пространстве уже содержит информацию о том, как следует разделить множество точек. Эта информация и определяет то свойство разделимости образов, которое оказывается достаточным для самообучения системы распознаванию образов.
Большинство известных алгоритмов самообучения способны выделять только абстрактные образы. Различие между ними состоит, по-видимому, в формализации понятия компактности, это повышает ценность алгоритмов самообучения, так как часто сами образы заранее никем не определены, а задача состоит в том, чтобы определить, какие подмножества изображений в заданном пространстве представляют собой образы. Хорошим примером такой постановки задачи являются социологические исследования, когда по набору вопросов выделяются группы людей. В таком понимании задачи алгоритмы самообучения генерируют заранее не известную информацию о существовании в заданном пространстве образов, о которых ранее никто не имел никакого представления.
Кроме того, результат самообучения характеризует пригодность выбранного пространства для конкретной задачи обучения распознаванию. Если абстрактные образы, выделяемые в процессе самообучения, совпадают с реальными, то пространство выбрано удачно. Чем сильнее абстрактные образы отличаются от реальных, тем "неудобнее" выбранное пространство для конкретной задачи.
Обучением обычно называют процесс выработки в некоторой системе той или иной реакции на группы внешних идентичных сигналов путем многократного воздействия на систему внешней корректировки. Такую внешнюю корректировку в обучении принято называть "поощрениями" и "наказаниями". Механизм генерации этой корректировки практически полностью определяет алгоритм обучения. Самообучение отличается от обучения тем, что здесь дополнительная информация о верности реакции системе не сообщается.
Адаптация — это процесс изменения параметров и структуры системы, а возможно, и управляющих воздействий на основе текущей информации с целью достижения определенного состояния системы при начальной неопределенности и изменяющихся условиях работы.
Обучение — это процесс, в результате которого система постепенно приобретает способность отвечать нужными реакциями на определенные совокупности внешних воздействий, а адаптация — это подстройка параметров и структуры системы с целью достижения требуемого качества управления в условиях непрерывных изменений внешних условий.
Главная черта, делающая обучение без учителя привлекательным, – это его "самостоятельность". Процесс обучения, как и в случае обучения с учителем, заключается в подстраивании весов синапсов. Некоторые алгоритмы, правда, изменяют и структуру сети, то есть количество нейронов и их взаимосвязи, но такие преобразования правильнее назвать более широким термином – самоорганизацией, и в рамках данной главы они рассматриваться не будут. Очевидно, что подстройка синапсов может проводиться только на основании информации, доступной в нейроне, то есть его состояния и уже имеющихся весовых коэффициентов. Исходя из этого соображения и, что более важно, по аналогии с известными принципами самоорганизации нервных клеток, построены алгоритмы обучения Хебба.
Полный алгоритм обучения с применением вышеприведенных формул будет выглядеть так:
1. На стадии инициализации всем весовым коэффициентам присваиваются небольшие случайные значения.
2. На входы сети подается входной образ, и сигналы возбуждения распространяются по всем слоям согласно принципам классических прямопоточных (feedforward) сетей[1], то есть для каждого нейрона рассчитывается взвешенная сумма его входов, к которой затем применяется активационная (передаточная) функция нейрона, в результате чего получается его выходное значение yi(n), i=0...Mi-1, где Mi – число нейронов в слое i; n=0...N-1, а N – число слоев в сети.
3. На основании полученных выходных значений нейронов по формуле (1) или (2) производится изменение весовых коэффициентов.
4. Цикл с шага 2, пока выходные значения сети не застабилизируются с заданной точностью. Применение этого нового способа определения завершения обучения, отличного от использовавшегося для сети обратного распространения, обусловлено тем, что подстраиваемые значения синапсов фактически не ограничены.
На втором шаге цикла попеременно предъявляются все образы из входного набора.
Следует отметить, что вид откликов на каждый класс входных образов не известен заранее и будет представлять собой произвольное сочетание состояний нейронов выходного слоя, обусловленное случайным распределением весов на стадии инициализации. Вместе с тем, сеть способна обобщать схожие образы, относя их к одному классу. Тестирование обученной сети позволяет определить топологию классов в выходном слое. Для приведения откликов обученной сети к удобному представлению можно дополнить сеть одним слоем, который, например, по алгоритму обучения однослойного перцептрона необходимо заставить отображать выходные реакции сети в требуемые образы.