

Матричні системи.
Назначение матричных вычислительных систем - обработка больших массивов данных (во многом схоже с назначением векторных ВС). В основе матричных систем лежит матричный процессор (array processor), состоящий из регулярного массива процессорных элементов (ПЭ).
Организация систем подобного типа на первый взгляд достаточно проста. Они имеют общее управляющее устройство, генерирующее поток команд, и большое число ПЭ, работающих параллельно и обрабатывающих каждый свой поток данных.
Между матричными и векторными системами есть существенная разница. Матричный процессор интегрирует множество идентичных функциональных блоков (ФБ), логически объединенных в матрицу и работающих в SIMD-стиле. Не столь существенно, как конструктивно реализована матрица процессорных элементов — на едином кристалле или на нескольких. Важен сам принцип - ФБ логически скомпонованы в матрицу и работают синхронно, то есть присутствует только один поток команд для всех. Векторный процессор имеет встроенные команды для обработки векторов данных, что позволяет эффективно загрузить конвейер из функциональных блоков. В свою очередь, векторные процессоры проще использовать, потому что команды для обработки векторов — это более удобная для человека модель программирования, чем SIMD.
Структуру матричной вычислительной системы можно представить в следующем виде.
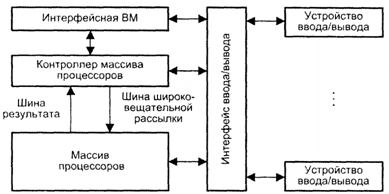
Обобщенная модель матричной ВС
Рассмотрим компоненты обобщенной модели матричной ВС.
Массив процессоров (МПр) осуществляет параллельную обработку множественных элементов данных.
Контроллер массива процессоров (КМП) генерирует единый поток команд, управляющий обработкой данных в массиве процессоров, выполняет последовательный программный код, реализует операции условного и безусловного переходов, транслирует в МПр команды, данные и сигналы управления. Команды обрабатываются процессорами в режиме жесткой синхронизации.
Сигналы управления используются для синхронизации команд и пересылок, а также для управления процессом вычислений, в частности определяют, какие процессоры массива должны выполнять операцию, а какие - нет.
Шина широковещательной рассылки служит для передачи команд, данных и сигналов управления из КМП в массив процессоров.
Шина результата служит для трансляции результатов вычислений из МПр в КМП (это требуется, поскольку выполнение операций условного перехода зависит от результатов вычислений).
Конвеєрні системи.
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах.
Выполнение типичной команды можно разделить на следующие этапы:
выборка команды - IF (по адресу, заданному счетчиком команд, из памяти извлекается команда);
декодирование команды / выборка операндов из регистров - ID;
выполнение операции / вычисление эффективного адреса памяти - EX;
обращение к памяти - MEM;
запоминание результата - WB.
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. В действительности, она даже несколько увеличивает время выполнения каждой команды из-за накладных расходов, связанных с управлением регистровыми станциями. Однако увеличение пропускной способности означает, что программа будет выполняться быстрее по сравнению с простой неконвейерной схемой.