

35. Построение абстрактного синтаксического дерева.
Транслятор на основе текста программы формирует некоторый промежуточный код. Этот код м.б. абстрактным синтаксическим деревом (АСД).
АСД
– это абстрактное представление
конструкций языка, полученное из дерева
разбора. Обычно в АСД ключевые слова и
операторы не представляются в качестве
листьев,
связываются
с внутренним узлом, который выступает
в дереве разбора родительским для этих
листьев. Другое упрощение, используемое
в синтаксических деревьях, заключатся
в том, что цепочка для одиночных продукций
могут быть свернуты так:
Это абстрактное представление конструкции языка, полученное из дерева разбора. В этом дереве есть инф-ция, необходимая для распознавания синтаксиса языка и информация о структуре предложения.
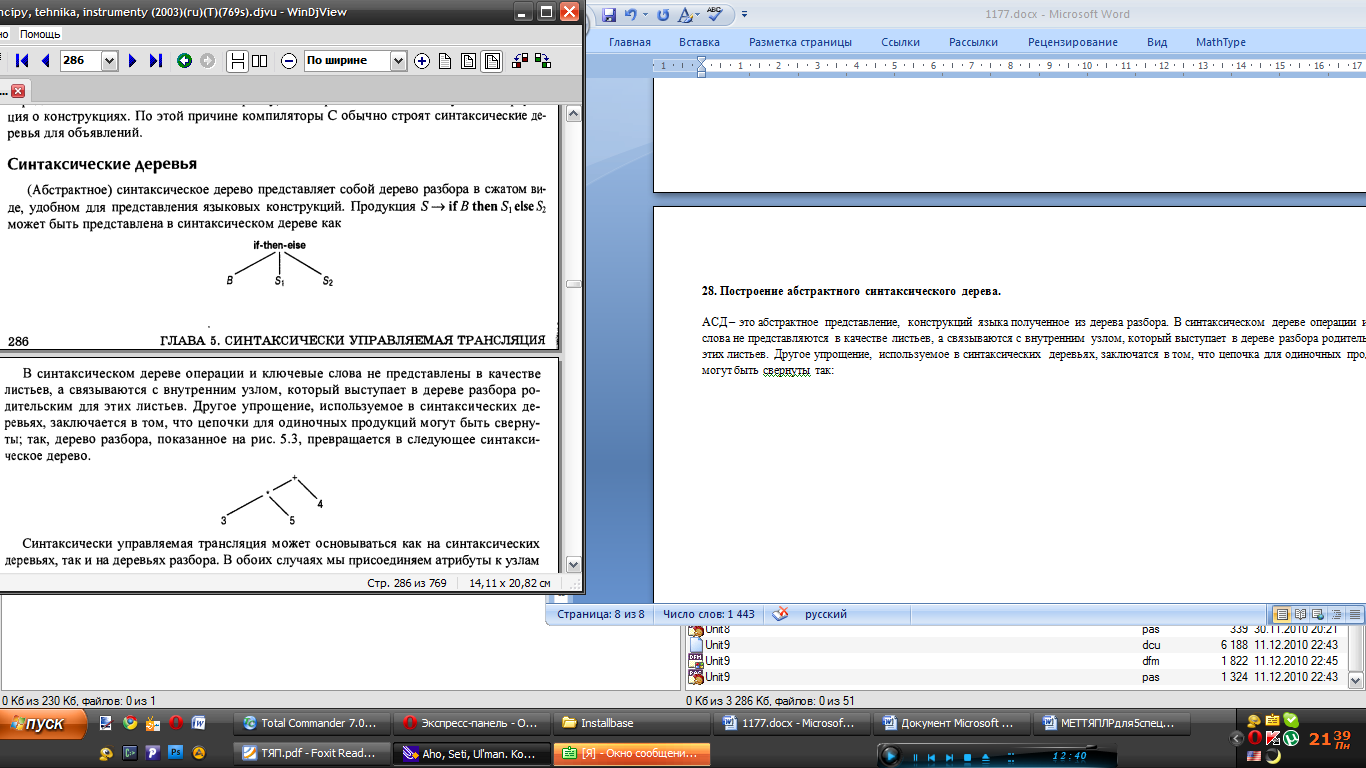
Если есть выражение a*5+b:
его представление в памяти
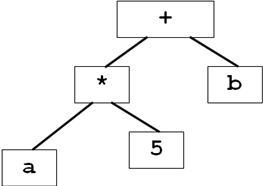
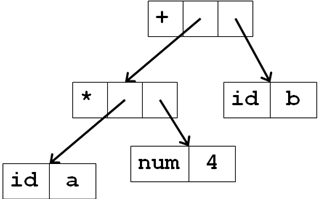
Построение синкт. деревьев для выражений подобно трансляции выражений в постфиксный вид. Мы строим поддеревья для подвыражений путем создания узлов для каждой операции и операндов. Узлы, дочерни по отношению к узлу операций, являются корнями поддеревьев для подвыражений, образующих операнды данной операции. Каждый узел в синтаксическом дереве может быть реализован как запись с несколькими полями. В узле операции одно поле идентифицирует операцию, а остальные поля содержат указатели на узлы операндов. Рассмотрим функции, которые можно применять для создания узлов: mknode(op,left,right) – создает узел операции с меткой op и двумя полями, содержащими указатель на left и right. mkleaf(id, entry) создает узел идентификатора с меткой id b и полем, содержащим entry, указатель на запись для этого идентификатора в таблице символов. mkleaf(num, val) – создает узел числа с меткой num и полем, содержащим val – значение числа. С помощью этих функций можно построить дерево для выражений (напр a-4+c)
36. Наследуемые атрибуты. Граф зависимостей.
Значения атрибутов определяется семантическими правилами, связанными с продукциями грамматики. в зависимости от вида семантических правил атрибуты м.б. синтезируемыми и наследуемыми.
Синтезируемые — вычисляют свои значения не используя атрибуты своих «детей».
Наследуемые — вычисляют свои значения, обращаясь к «братьям» и «родителям».
Наследуемые атрибуты позволяют определить положение идентификатора относительно оператора присваивания.
Для применения в общем случае нужно уметь строить граф зависимостей. Зависимости можно представить стрелками. Если есть фрагмент дерева разбора, то мы можем граничные символы, имеющие атрибуты поставить в соответствие вершине графа (на обороте):
Если есть продукция A → XY и связанное с ней семантическое правило A.a := f (X.x, Y.y), то для них получится сл. фрагмент графа зависимостей:

Полученный граф должен быть ацикличным (не должно быть циклов), тогда сможем вычислить значения. Для определения порядка вычисления атрибутов нужно применить топологическую сортировку. Эта сортировка определяет порядок узлов графа зависимостей такой, что дуги графа выходят от более ранних узлов к более поздним. Граф зависимостей для последнего примера (на обороте).
У нас есть функция, которая получает два аргумента, функция вычисляет значение, которое присваивается атрибутам узла. В таком случае получится след. фрагмент графа зависимостей. Здесь мы видим фрагмент дерева разбора. Кружками обозначены атрибуты. Эти атрибуты яв-ся узлами графа зависимости. Дуги этого графа направлены и обозначают зав-ть одного атрибута от другого. От х зависит а – это как мы читаем стрелки. Отметим такой момент, что для того, чтобы вычислить значение атрибутов, граф зависимости должен быть ациклический.
37. L–атрибутные определения. Схемы трансляции. Порядок вычисления семантических правил.
Выделим класс синтаксически управляемых определений L-АО, чьи атрибуты всегда м.б. вычислены, если дерево разбора будет строится в глубину. L-left, т.к. значения атрибутов перемещаются слева направо.
Синтаксическое управление определения называется L-атрибутным, если каждый наследуемый атрибут символа Xi (1<=i<=n) в правой части продукции А→x1, x2,…,xn зависят только:
1)от атрибутов грамматических символов X1, X2,…,Xi-1 (расположенных левее него)
2) от наследуемых атрибутов символа А
А→ X1, X2,…,Xi,…,Xn
Схема трансляции
Схема трансляции – это КСГ, в которой с грамматическими символами связаны атрибуты, а в правых частях продукций между грамматических символов могут встречаться семантические действия, которые обычно заключаются в фигурные скобки.
В схеме трансляции используются как наследуемые, так и синтезируемые атрибуты.
Пример использования СТ, в котором индексные выражения с операциями «+» и «-» переводятся в постфиксные.
9-5+2 → 95-2+
Схема трансляции в постфиксную запись:
E → T R
R → addop T {print (addop.lexem)} R1 (addop – лекс. класс, включающий в себя знаки «+» и «-»).
T → num {print (num.value)}
 После
построения дерева вставим в него
семантические действия: При обходе в
глубину получим последовательность
операций {print},
печатающих постфиксную запись. Операции
{print}включают
в дерево как обычные терминалы.
После
построения дерева вставим в него
семантические действия: При обходе в
глубину получим последовательность
операций {print},
печатающих постфиксную запись. Операции
{print}включают
в дерево как обычные терминалы.
При обходе в глубину выполняются семантические действия и получается постфиксная запись. Семантические действия будут выполняться правильно при использовании L-атрибутных определений.
Практически это используется:
- при использовании только синтезируемых атрибутов необходимо семантические действия расположить в конце правой части соответствующей продукции.
- при использовании еще и наследуемых атрибутов необходимо руководствоваться следующими правилами:
1. наследуемый атрибут грамматического символа правой части продукции д.б. вычислен в действии, стоящем перед этим символом.
2. действие не д. обращаться к синтезируемому атрибуту символа, стоящего от него правее.
3. синтезируемый атрибут нетерминала левой части правила м.б. вычислен только после всех используемых им атрибутов. Такое действие помещается в конце левой части продукции
31. L–атрибутные грамматики в детерминированном разборе сверху–вниз. а) Устранение левой рекурсии. б) Проектирование детерминированного транслятора.
Определение:
Символ
![]() в
КС-грамматике
в
КС-грамматике
![]() называется
рекурсивным, если для него существует
цепочка вывода вида
называется
рекурсивным, если для него существует
цепочка вывода вида
![]() ,
где
,
где
![]() .
Определение:
Если
.
Определение:
Если
![]() и
и
![]() ,
то рекурсия называется левой, а грамматика
,
то рекурсия называется левой, а грамматика
![]() -
леворекурсивной.
Определение:
Если
-
леворекурсивной.
Определение:
Если
![]() и
и
![]() ,
то рекурсия называется правой, а
грамматика
-
праворекурсивной.
Определение:
Если
и
,
то рекурсия представляет собой цикл.
Любая КС-грамматика может
быть как леворекурсивной, так и
праворекурсивной, а также леворекурсивной
и праворекурсивной одновременно.
Некоторые алгоритмы
левостороннего разбора для КС-языков
не работают с леворекурсивными
грамматиками, поэтому возникает
необходимость исключить левую рекурсию
из правил грамматики.
Любую
КС-грамматику можно преобразовать к
нелеворекурсивному виду или
неправорекурсивному виду.
АЛГОРИТМ
УСТРАНЕНИЯ ЛЕВОЙ РЕКУРСИИ
,
то рекурсия называется правой, а
грамматика
-
праворекурсивной.
Определение:
Если
и
,
то рекурсия представляет собой цикл.
Любая КС-грамматика может
быть как леворекурсивной, так и
праворекурсивной, а также леворекурсивной
и праворекурсивной одновременно.
Некоторые алгоритмы
левостороннего разбора для КС-языков
не работают с леворекурсивными
грамматиками, поэтому возникает
необходимость исключить левую рекурсию
из правил грамматики.
Любую
КС-грамматику можно преобразовать к
нелеворекурсивному виду или
неправорекурсивному виду.
АЛГОРИТМ
УСТРАНЕНИЯ ЛЕВОЙ РЕКУРСИИ
Шаг
1.
Обозначим нетерминальные символы
грамматики так:
![]() ,
,
![]() .
Шаг
2.
Рассмотрим правила для символа
.
Шаг
2.
Рассмотрим правила для символа
![]() .
Если эти правила не содержат левой
рекурсии, то перенесем их в множество
правил
.
Если эти правила не содержат левой
рекурсии, то перенесем их в множество
правил
![]() без
изменений, а символ
добавим
в множество нетерминальных символов
без
изменений, а символ
добавим
в множество нетерминальных символов
![]() .
Иначе
запишем правила для
в
виде , где ни одна из цепочек
.
Иначе
запишем правила для
в
виде , где ни одна из цепочек
![]() ,
,
![]() не
начинается с символов
не
начинается с символов
![]() ,
таких, что
,
таких, что
![]() .
Вместо этого правила
в множество
запишем
два правила вид:
Символы
и
.
Вместо этого правила
в множество
запишем
два правила вид:
Символы
и
![]() включаем
в множество
.
Теперь
все правила для
начинаются
либо с терминального символа, либо с
нетерминального символа
,
такого, что
включаем
в множество
.
Теперь
все правила для
начинаются
либо с терминального символа, либо с
нетерминального символа
,
такого, что
![]() .
Шаг
3.
Если
.
Шаг
3.
Если
![]() ,
то грамматика
,
то грамматика
![]() построена,
перейти к шагу 6, иначе
построена,
перейти к шагу 6, иначе
![]() ,
,
![]() и
перейти к шагу 4.
Шаг
4.
Для символа
и
перейти к шагу 4.
Шаг
4.
Для символа
![]() в
множестве правил
заменить
все правила вида
в
множестве правил
заменить
все правила вида
![]() ,
где
,
где
![]() ,
на правила вида
,
на правила вида
![]() ,
причем
,
причем
![]() -
все правила для символа
.
Так
как правая часть правил
уже
начинается с терминального символа или
нетерминального символа
,
-
все правила для символа
.
Так
как правая часть правил
уже
начинается с терминального символа или
нетерминального символа
,
![]() ,
то и правая часть правил для символа
будет
удовлетворять этому условию.
Шаг
5.
Если
,
то и правая часть правил для символа
будет
удовлетворять этому условию.
Шаг
5.
Если
![]() ,
то перейти к шагу 2, иначе
,
то перейти к шагу 2, иначе
![]() и
перейти к шагу 4.
Шаг
6.
Целевым сиволом грамматики
ставновится
символ
,
соответсвующий символу
и
перейти к шагу 4.
Шаг
6.
Целевым сиволом грамматики
ставновится
символ
,
соответсвующий символу
![]() исходной
грамматики
.
исходной
грамматики
.