Тупики, способы их распознавания и разрушения.
Одним из наиболее чувствительных недостатков метода сериализации транзакций на основе синхронизационных захватов является возможность возникновение тупиков (deadlocks) между транзакциями. Тупики возможны при применении любого из рассмотренных нами вариантов.
Вот простой пример возникновения тупика между транзакциями T1 и T2:
транзакции T1 и T2 установили монопольные захваты объектов r1 и r2 соответственно;
после этого T1 требуется совместный захват r2, а T2 - совместный захват r1;
ни одна из транзакций не может продолжаться, следовательно, монопольные захваты не будут сняты, а совместные - не будут удовлетворены.
Поскольку тупики возможны, и никакого естественного выхода из тупиковой ситуации не существует, то эти ситуации необходимо обнаруживать и искусственно устранять.
Основой обнаружения тупиковых ситуаций является построение (или постоянное поддержание) графа ожидания транзакций. Граф ожидания транзакций - это ориентированный двудольный граф, в котором существует два типа вершин - вершины, соответствующие транзакциям, и вершины, соответствующие объектам захвата. В этом графе существует дуга, ведущая из вершины-транзакции к вершине-объекту, если для этой транзакции существует удовлетворенный захват объекта. В графе существует дуга из вершины-объекта к вершине-транзакции, если транзакция ожидает удовлетворения захвата объекта.
Легко показать, что в системе существует ситуация тупика, если в графе ожидания транзакций имеется хотя бы один цикл.
Для распознавание тупика периодически производится построение графа ожидания транзакций (как уже отмечалось, иногда граф ожидания поддерживается постоянно), и в этом графе ищутся циклы. Традиционной техникой (для которой существует множество разновидностей) нахождения циклов в ориентированном графе является редукция графа.
Редукция состоит в том, что прежде всего из графа ожидания удаляются все дуги, исходящие из вершин-транзакций, в которые не входят дуги из вершин-объектов. (Это как бы соответствует той ситуации, что транзакции, не ожидающие удовлетворения захватов, успешно завершились и освободили захваты). Для тех вершин-объектов, для которых не осталось входящих дуг, но существуют исходящие, ориентация исходящих дуг изменяется на противоположную (это моделирует удовлетворение захватов). После этого снова срабатывает первый шаг и так до тех пор, пока на первом шаге не прекратится удаление дуг. Если в графе остались дуги, то они обязательно образуют цикл.
Статистики реляционной базы данных.
Реляционная база данных — база данных, основанная на реляционной модели данных. Слово «реляционный» происходит от англ. relation (отношение[1]). Для работы с реляционными БД применяют реляционные СУБД.
Использование реляционных баз данных было предложено доктором Коддом из компании IBM в 1970 году.
Статистика
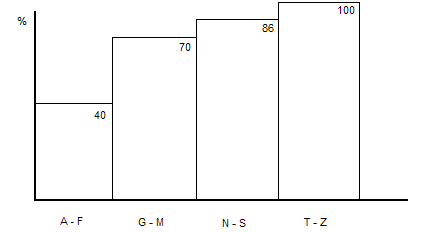
Для оценки потенциального числа строк, извлекаемого из таблицы, РСУБД использует статистику. Статистика имеет вид гистограмм для каждой колонки таблицы, где по горизонтали располагается шкала значений, а высотой столбца отмечается оценка числа строк в процентах от общего числа строк.
Таким образом, если из таблицы извлекаются строки со значением колонки C с ограничением [V1, V2], то можно оценить число строк, попадающих в этот интервал. Алгоритм оценки числа извлекаемых строк следующий:
Определить, в какие интервалы гистограммы попадает ограничение [V1, V2];
Найти оценки числа строк Ri для каждого интервала i в процентах.
Если [V1, V2] попадает в некоторый интервал [S1, S2] частично или полностью лежит в интервале, то:
Найти пересечение [V1, V2] и [S1, S2]
Откорректировать число значений в частичном интервале (это либо Ri * (V1 — S2 + 1) / (S1 — S2 + 1), либо Ri * (S1 — V2 + 1) / (S1 — S2 + 1), либо Ri * (V1 — V2 + 1) / (S1 — S2 + 1));
Иначе оценка для интервала равна Ri;
Просуммировать оценки в процентах для всех интервалов;
Перевести оценку в процентах в число строк (см. ниже).
Как правило, СУБД не знает и не может знать точное число строк в таблице (даже для выполнения запроса SELECT COUNT(*) FROM TABLE выполняется сканирование первичного индекса), поскольку в базе могут храниться одновременно несколько образов одной и той же таблицы с различным числом строк. Для оценки числа строк используются следующие данные:
Число страниц в таблице
Длина страницы
Средняя длина строки в таблице
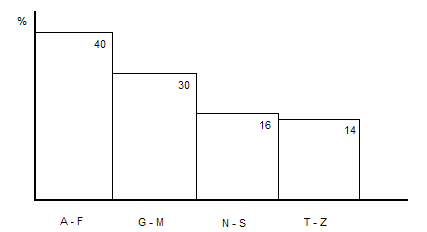
Статистика так же может храниться нарастающим итогом. В этом случае каждый интервал содержит суммарную оценку всех предыдущих интервалов плюс собственную оценку. Для получения оценки числа строк для ограничения [V1, V2] достаточно из оценки интервала, в который попадает V2, вычесть оценку интервала, в который попадает V1.
Сбор статистики для построения гистограмм осуществляется либо специальными командами СУБД, либо фоновыми процессами СУБД. При этом, ввиду того, что база может содержать существенный объём данных, делается выборка меньшего объёма из всей генеральной совокупности строк. Оценка репрезентативности (достоверности) выборки может осуществляться, например, по критерию согласия Колмогорова.
Если данные в таблице существенно изменяются в короткий промежуток времени, то статистика перестает быть актуальной и оптимизатор принимает неверные решения о полном сканировании таблиц. Режим работы базы данных должен быть спланирован таким образом, чтобы поддерживать актуальную статистику, либо не использовать оптимизацию на основе статистики.