

2.4.4.Реализация списков
В этом разделе речь пойдет о нескольких структурах данных, которые можно использовать для представления списков. Будут рассмотрены реализации списков с помощью массивов и указателей. Каждая их этих реализаций осуществляет определенные операторы, выполняемые над списками более эффективно, чем другая.
Реализация списков посредством массивов
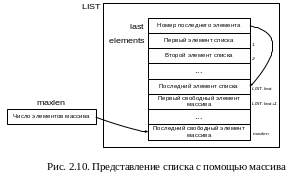
При реализации списков с помощью массивов элементы списка располагаются в смежных ячейках массива. На рис 2.10 представлена одна из возможных реализаций. В данном случае список представлен записью LIST, состоящей из поля last, указывающей на последний элемент списка и массива elements, в котором располагаются элементы списка. Поскольку элементы массива elements нумеруются с единицы, то значение last равно числу элементов списка. Длина массива elements храниться в константе maxlen.
Такое представление списка позволяет легко просматривать содержимое списка и вставлять новые элементы в его конец. Но вставка нового элемента в середину списка требует перемещения всех последующих элементов на одну позицию к концу массива, чтобы освободить место для нового элемента. Удаление элемента также требует перемещения элементов, чтобы закрыть освободившуюся ячейку.
Алгоритмы операторов INSERT, DELETE и LOCATE списка, реализованного на массиве, представлены блок-схемами на рис. 2.11, 2.12 и 2.13 соответственно.
Реализацию остальных операторов списка сделайте самостоятельно.



Реализация списков с помощью указателей
Реализация списков с помощью указателей освобождает от использования непрерывной области памяти для хранения списка. Это позволяет избавиться от перемещения элементов списка при вставке или удалении элементов. Однако ценой за это удобство становится дополнительная память для хранения указателей. Структура списка, реализованного с помощью указателей, представлена на рис.2.14. Список представлен записью LIST, состоящей из двух полей: last и elements. В поле last хранится число элементов списка, а в поле elements - указатель на первый элемент списка. Элемент списка хранится в записи, состоящей из двух полей: element и next. Поле element содержит значение элемента списка, а поле next - указатель на следующий элемент списка.
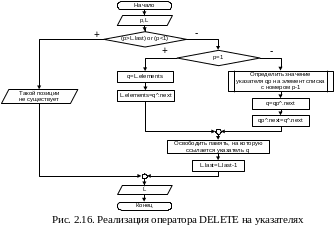
Реализация операторов INSERT и DELETE представлена блок-схемами на рис.2.15 и 2.16 соответственно.


2.4.5.Стеки
Стек - это специальный тип списка, в котором все вставки и удаления выполняются только на одном конце, называемом вершиной (top). Стеки иногда называют «магазинами», также для обозначения стеков используется аббревиатура LIFO (last-in-first-out - последний вошел - первый вышел). Интуитивными моделями стека могут служить патроны в магазине автоматического стрелкового оружия, книги, сложенные в стопку, или стопка тарелок; во всех этих моделях взять можно только верхний предмет, а добавить новый предмет можно, только положив его на верхний.
Абстрактные типы данных семейства STACK (cтек) обычно используют следующие пять операторов.
1. NULLSTACK(S). Делает стек S пустым. При реализации стека на списке S оператор NULLSTACK(S) эквивалентен NULLIST(S).
2. TOP(S). Возвращает элемент из вершины стека S. Если вершина стека соответствует первой позиции списка S, тогда TOP(S) можно записать в терминах общих операторов списка как RETRIVE(FIRST(S),S). Если вершина стека соответствует последней позиции списка S, тогда TOP(S) можно записать как RETRIVE(LAST(S),S).
3. POP(S). Удаляет элемент из вершины стека (выталкивает из стека). Если вершина стека соответствует первой позиции списка S, тогда этот оператор можно записать как DELETE(FIRST(S),S). Если вершина стека соответствует последней позиции списка S, тогда POP(S) записывается как DELETE(LAST(S),S). Иногда оператор POP(S) реализуется в виде функции, возвращающей удаляемый элемент.
4. PUSH(x,S). Вставляет элемент x в вершину стека S (заталкивает элемент в стек). Элемент, ранее находившийся в вершине стека, становится элементом, следующим за вершиной, и т.д. Если вершина стека соответствует первой позиции списка S, то данный оператор можно записать как INSERT(x,FIRST(S),S). Если вершина стека соответствует последней позиции списка S, то PUSH(x,S) записывается как INSERT(x, NEXT(LAST(S),S), S).
5. EMPTYSTACK(S). Эта функция возвращает значение true (истина), если стек S пустой, и значение false (ложь) в противном случае. При реализации стека на списке S оператор EMPTYSTACK(S) эквивалентен EMPTYLIST(S).