

Приклад використання інтерактивного sql в субд mysql
СУБД MySQL користується широкою популярністю в програмістсь- кому середовищі, хоча не набула статусу гранду серед СУБД, проте широко розповсюджена й працює під різними платформами. Зокрема, даний приклад ілюструє роботу інтерактивного SQL під операційною системою Linux Debian.
Для початку роботи в командному рядку введемо:
...$ mysql
Командна оболонка шелла видасть запрошення на зразок: welcome to the mysql monitor, commands end with ; or g. your mysql connection id is 46 to server version: 3.22.32-log type 'help' for help. mysql>
то у відповідь на нього наберіть q, залишимо на якийсь час інтерпретатор sql запитів, і займемося адмініструванням сервера mysql. Перш за все необхідно встановити пароль адміністратора сервера БД. Тепер потрібно завести користувачів і дати їм деякі права. Все адміністрування проводиться через звичайні таблиці mysql, а їхня правка також здійснюється стандартними sql командами. Найперша таблиця, яка визначає допуск користувача до сервера, так і називається - user. Щоб з’ясувати хто у нас там є, й що він може робити, наберемо:
mysqldump -и root -р -opt mysql user>mysql-users.sql
стосуються сервера В цілому. І Іривілеї grunt, references, index і utter №ЮЇЬ можливість передавати права, а також змінювати, зв’язувати й індексувати таблиці,
Два важливі зауваження.
По-перше, дані в цій таблиці, за умовчанням розповсюджуються на всі БД, що є на сервері. Тому не варто надавати цій таблиці жодних привілеїв, що стосуються таблиць. Краще це робити з точністю до окремих полів і адрес хостів та прав користувачів в інших таблицях, а ця таблиця повинна тільки дозволяти вхід на сервер.
По-друге, привілеї, які стосуються сервера в цілому, налаштовуються тільки в цій таблиці, і хоча б один користувач, у даному випадку root, повинен мати ці привілеї, інакше сервер стане некерованим.
Якщо у ваші плани входить дати доступ до сервера всім користува-
• • г* • і • • • і If •• ечгч*
чам і під будь-яким їм ям, заведіть користувача з порожнім їм ям . Ті ж правила застосовуються до імен і адрес комп'ютерів-хостів. Тепер, поправивши записи в таблиці, але в жодному випадку не її структуру, відправимо команди назад в mysql.
...$ mysql -и root -p < mysql-users.sql і попросимо сервер перечитати змінені права ...$ mysqladmin -и root -р reload
Ще одне зауваження щодо паролів. У розглянутому нами файлі поля паролів порожні, і це треба негайно виправити. Правити їх у текстовому файлі незручно, тому що mysql використовуваний для шифрування пароля окрему програму, і зберігає пароль у зашифрованому вигляді. Щоб установити пароль, наприклад, користувачеві «user2», треба виконати таку команду:
...$ mysql mysql -і 'update user setpassword=password(«0») where user=«user2»;'
Відмінність від звичайної системи паролів у тому, що імена користувачів БД можуть бути не пов'язані з їхніми реєстраційними іменами в системі, користувачі не можуть міняти свої паролі, і цей пароль відомий адміністраторові БД.
Розібравшись із найпершою адміністративною таблицею user, решта таблиць: db, host, tables_priv, columns_priv, func - змінюємо аналогічно.
Кожну з команд, що посилається mysql, можна задавати або в моніторі запитів mysql, або з командного рядка, або створивши файл і відправивши його до інтерпретатора mysql через той же монітор. При роботі в інтерпретаторі завжди повідомляється час, витрачений на виконання запиту, а при виведенні у файл (канал) не малюється рамочка навколо таблиці. Це робиться тільки для нашої зручності, і не впливає ні на результат, ні на сам sql запит.
Далі вже можна робити залипмкщо, звичайно, початкова база готова. Нехай у нас є телефонна база даних. Тоді до неї можна робити інтерактивні залити, наприклад:
select p.phonum, р. па im, s. nie к, b.bldng
from phone p, street s, building b # короткі синоніми таблиць where
p.bd_id=b.bd_id # таким чином and b.st_id=s.st_id # зв'язують таблиці and p.phonum like «%1234%» # власне запит order by p.naim;
Зауважимо, що в секторі клієнт-серверних застосувань Mysql цілком здатний конкурувати з визнаними комерційними СУБД, навіть із такими як Sybase. Але вся потужність MySql розкривається в поєднанні з технологіями Internet.
Програмно-вбудований(embeded) SQL
Інтерактивна форма роботи з SQL адекватна для адміністратора баз даних, можлива для певних категорій користувачів, проте зовсім неприйнятна для всіх програмістів і переважної більшості користувачів БД. Програм но-вбудований SQL (Embedded SQL) призначений для того, щоб вбудовувати SQL запити в прикладну програму. Але як це зробити?
Як «пояснити» компілятору C++, COBOL чи PL/1, що частина програми це не оператори мови, а оператори якогось іншого коду? Ця проблема дещо нагадує задачу реалізації мережевої моделі по стандарту CODASYL. Там теж застосовується мови високого рівня. Принципова різниця полягає в тому, що на відміну від схем та підехем стандарту CODASYL, які по-суті є підмножинами процедурних мов, SQL є декларативною. Як з'єднати можливості мови програмування структурного рівня (змінні, розгалуження, цикли) і використати можливості SQL (запити декларативного типу, де вже не на програміста, а на СУБД лягає обов’язок по їхній оптимізаиії й вибору плану виконання )?
Ці й деякі інші проблеми вирішуються декількома способами. Ці способи частково описані й у стандарті SQL-92. На даний момент використовуються два варіанти програмного SQL: статичний та динамічний. Розглянемо, що являє собою кожний варіант.
Статичний SQL є різновид програмного SQL, призначеного для вбудовування SQL-операторів у текст програми мовою програмування високого рівня. Розглянемо ще раз алгоритм виконання SQL-запитів в інтерактивному режимі роботи. Легко бачити, що користувач змушений очікувати результатів виконання запиту протягом усього часу роботи алгоритму. Якщо через якийсь час користувачеві знову потрібно буде виконати той же самий запит, СУБД знову проробить ті ж самі дії, що й при попере-
дньому зверненні. У наявності деяка недосконалість механізму: ті самі етапи виконуються щораз заново для однакових запитів; СУБД не може обробляти інтерактивні запити з випередженням. Рішення подібних проблем очевидне - частина дій по обробці запиту необхідно виконувати один раз, зберігати результат у якомусь вигляді, а потім використати стільки разів, скільки необхідно. Ця ідея є однією з основних ідей програмного SQL. Отже, програмний, а зокрема, і статичний SQL дозволяє: використати оператори інтерактивного SQL у тексті програми мовою програмування високого рівня;
поряд з операторами інтерактивного SQL використати нові спеціальні конструкції, що доповнюють SQL, і збільшують його можливості; для передачі параметрів у запит використати в тексті запиту змінні, оголошені в програмі;
для повернення в програму результатів запиту використати спеціальні конструкції, відсутні в інтерактивному SQL;
здійснювати компіляцію запитів разом із програмою, забезпечуючи, як наслідок погоджену роботу програми й СУБД.
Заздалегідь (на етапі компіляції-) виконувати дії по аналізу й оптимізації запитів, заощаджуючи час, що витрачаєтья на етапі виконання програми.
Розглянемо два основних етапи, пов'язаних із роботою статичного SQL - компіляцію та виконання програми. Схема компіляції й збирання програми виглядає в такий спосіб: програма, що включає оператори мови програмування високого рівня разом з операторами SQL, подається на вхід спеціального препроцесора, що виділяє з її частини, пов’язані з SQL. Замість інструкцій вбудованого SQL препроцесор підставляє виклики спеціальних функцій СУБД. Бібліотеки таких функцій для зв'язку з мовами програмування існують для всіх розповсюджених серверних СУБД. Варто особливо відзначити, що ці бібліотеки мають «закритий» інтерфейс, тобто розробники можуть міняти його за своїм розсудом, відповідно обновивши препроцесор. Усе це говорить про те, що програміст не повинен втручатися в цей процес. Самі інструкції SQL препроцесор виділяє в окремий файл. Програма надходить на вхід звичайного компілятора мови програмування, після чого виходять об'єктні модулі. Далі ці об'єктні модулі разом із бібліотеками СУБД збираються в один виконує модуль, що, - додаток. Поряд із цими операціями відбувається робота з файлом, що містить SQL- інструкції. У літературі цей модуль часто зветься «модуль запитів до бази даних» (Database Request Module, DBRM). Обробку цього модуля здійснює спеціальна утиліта, що зазвичай називається BIND. Для кожної інструкції SQL утиліта виконує наступні дії:
здійснює синтаксичний аналіз запиту (перевіряє, чи є запит коректним);
перевіряє, чи існують у базі даних ті об'єкти, на які посилається запит;
вибирає, яким чином здійснювати виконання запиту - план виконання запиту.
Усі плани виконання запитів зберігаються в СУБД для наступного використання.
Рис.
6.4. Схема компіляції програми зі
вбудованими інструкціями статичного
Схема виконання програми виглядає в такий спосіб:
При необхідності виконати запит програмою здійснюється виклик спеціальної функції СУБД, що відшукує вже сформований раніше план виконання запиту.
СУБД
виконує
запит відповідно до обраного плану.
Результат виконання запиту надходить
у додаток. Основними командами статичного
SQL
є:
EXEC
SQL
специфікатор,
що вказує, що наступна за ним інструкція
є інструкцією вбудованого SQL
9
у
мові С - ознака закінчення інструкції
вбудованого SQL
DECLARE
TABLE
повідомляє
таблицю, що потім буде використовуватися
в інструкціях вбу-
|
дованого SQL |
SQLCODE |
змінна для обробки помилок |
SQISTATE |
змінна для обробки помилок |
GET DIAGNOSTICS |
інструкція для обробки помилок |
WHENEVER SQLWARN1NG GOTO SQLERROR NOT FOUND CONTINUE |
інструкцій для спрощення набір спільно використовувані обробки помилок |
BEGIN DECLARE SECTION END DECLA RE SECTION |
інструкції для визначення області, у якій будуть оголошені змінні, у наслідку використовувані в запитах SQL |
INTO |
використовується в операторі SELECT для вказівки змінної, у яку необхідно помістити результат виконання запиту |
• можуть використатися тільки в тих місцях, де в запитах зазвичай стоять константи. Наприклад, неможливо параметризувати ім'я таблиці, з якої проводиться вибірка, а також назви колонок. У результаті ми приходимо до наступного висновку. При використанні статичного варіанта вбудованого (програмного) SQL необхідно на етапі написання програми точно знати склад запитів, які необхідно буде виконувати в програмі. У багатьох випадках це обмеження є істотним. Для його усунення реалізовано новий різновид програмного SQL — динамічний Розглянемо коротко основні ідеї динамічного SQL.
Динамічний SQL
Ще один різновид програмного призначена для вбудовування SQL-операторів у текст програми мовою програмування високого рівня, який допускає динамічне формування й виконання запитів під час роботи програми. Історія виникнення динамічного багато в чому пов'язана з компанією ІВМ, що впровадила цей потужний інструмент у свою СУБД DВ2. Стандарт SQL-89 не підтримував динамічний SQL. Лише в 1992 році в стандарт SQL-2 були включені специфікації динамічного SQL. Для того щоб використати цей інструментарій у своїх програмах, необхідно розуміти основні концепції та ідеї, закладені в динамічний SQL і принципи його функціонування. Саме це і є предметом розгляду в даному розділі. Теоретики вважають основною концепцією динамічного таке твердження: вбудована інструкція SQL не записується у вихідний текст програми[13]. Замість цього програма формує текст інструкції під час виконання в одній зі своїх областей даних, а потім передає сформовану інструкцію в СУБД для динамічного виконання.
Згадаємо, як працювала статична SQL. Схема використання передбачала 2 етапи - компіляція програми й виконання програми. На етап компіляції лягало основне навантаження в тому розумінні, що він вирішував питання перевірки, розбору й оптимізації запитів, оскільки було відомо, що саме розбирати й оптимізувати. Цілком очевидно, що подібну двоетапну схему не можна реалізувати для динамічного SQL, адже на етапі компіляції програми ще невідомо, що саме потрібно розбирати й оптимізувати. Які наслідки цієї зміни? Будь-який механізм має свої переваги й недоліки. Переваги динамічного SQL у тому, що він дозволяє формувати запит до бази даних під час роботи програми, реагуючи на ті або інші події, що відбулися. Така можливість є життєво важливою для клієнт-серверної й триланко- вої архітектури, у яких структура бази даних і ділові правила мають тенденцію до зміни, що вимагає певної гнучкості при організації процесу обробки даних. Недолік динамічного SQL — низька продуктивність у порівнянні зі статичним. Дійсно, багато з операцій, що виконувалися на етапі компіляції один раз, тепер виконуються безпосередньо під час роботи програми. У зв'язку із цим, вважається правильним рекомендувати використання статичного різновиду SQL, там, де тільки можливо. У свою чергу апарат динамічного SQL треба застосовувати тільки там, де без цього обійтись неможливо. Розглянемо схему функціонування динамічного SQL. Схема передбачає одноетапне й двоетапне виконання інструкцій. Одноета- пне виконання інструкцій здійснюється командою EXECUTE в такій послідовності:
IMMEDIATE. Модуль, що виконує, (запуск на виконання).
Виконання звичайних інструкцій МПВУ.
Виклик функцій СУБД для виконання інструкцій вбудованого SQL.
Аналіз синтаксису Перевірка наявності об'єктів. Оптимізація (вибір
плану)
Виконання плану.
Команда EXECUTE IMMEDIA ТЕ.
Схема виконання інструкції передбачає: двоетапне динамічне формування команди SQL у рядковому вигляді під час роботи програми; двое- тапна передача рядкового вигляду інструкції в СУБД за допомогою команди EXECUTE IMMEDIATE', двоетапне виконання інструкції системою керування БД, що включає синтаксичний аналіз, перевірку параметрів, оп- тимізацію (вибір плану) і виконання цього плану. Основні проблеми одностайної схеми полягають у тому, що вона не дозволяє виконувати інструкції SELECT (тому що немає засобів для повернення в додаток результатів запиту) і приводить до нераціональних витрат обчислювальних ресурсів (тому що при повторному виконанні тієї ж інструкції знову буде витрачений час на всі ті ж дії по її інтерпретації й виконанню).
Двоетапне виконання інструкцій ґрунтується на наступному міркуванні: швидше за все, команда динамічного SQL у такому виді, як вона на-
дходить на виконання, буде виконуватися неодноразово. ГІри цьому мо> жуть мінятися якісь конкретні деталі. А це значить, що інструкцію можна параметризувати. Використання параметризованих інструкцій дозволяє зробити схему виконання двоетапним, розділивши процес на «підготовку інструкції» і «виконання інструкції».
Рис.
6.5. Схема виконання програми із
вбудованими інструкціями динамічного
SQL
із
застосуванням
двоетапної схеми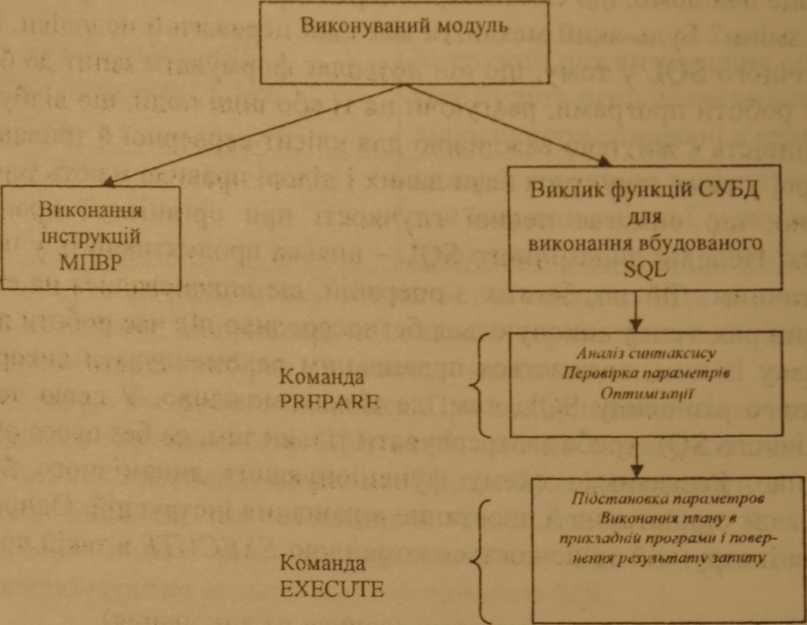
На етапі підготовки можна здійснити синтаксичний аналіз інструкції, інтерпретувати її та підготуватися до виконання, вибравши план виконання. На етапі виконання СУБД підставляє значення параметрів (отримані із програми) і використає сформований раніше план виконання для досягнення результату. При цьому реалізується ідея одноразового виконання тих дій, які можна виконати один раз. Так, підготовлена один раз інструкція може.бути виконана десятки разів із різними параметрами. Основними командами динамічного SQL є:
EXECUTE IMMEDIATE -Негайне виконання інструкції;
PREPARE- Підготовка інструкції до виконання ;
EXECUTE - Виконання підготовленої раніше інструкції;
DESCRIBE - Спеціальна команда, що бере участь при поверненні результату виконання інструкцій динамічного SQL;
DECLARE CURSOR - Різновид інструкції DECLARE CURSOR, що застосовувалася раніше в рамках статичного SQL, яка містить замість запиту його ім'я (пов'язане із запитом за допомогою інструкції PREPARE);
OPEN FETCH CLOSE - Різновид інструкцій для роботи з курсором у динамічному SQL.
Як ми бачимо основу цих операторів складають згадувані в розділі оператори , які в мові SQL називаються операторами управлінням курсо- pa(Cursor Control Language).