

Простейшие интуитивные (эвристические) модели
Эти модели особенно эффективны для целей сертификации. Было разработано несколько моделей для оценки числа ошибок. Они основаны на более слабых предположениях, чем сложные модели.
Предполагается начать тестирование двумя независимыми группами. В течение некоторого времени производится параллельное тестирование системы, затем результаты собираются и сравниваются.
N1, N2 – число обнаруженных каждой группой ошибок
N12 – число ошибок, обнаруженных дважды (обеими группами)
N – число ошибок в программе (неизвестное)
Е – эффективность тестирования


Предполагаем, что возможность обнаружения одинакова. Это серьезное предположение не лишенное смысла. Можно рассматривать каждое подмножество N как аппроксимацию всего пространства.
Например, если первая группа обнаружила 10% ошибок, то она должна было найти примерно 10% всякого случайным образом выбранного подмножества, например подмножества N2. Можно сказать, что

Если выполнить подстановку для N2 получим
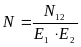
Очевидно, самый простой способ оценки числа ошибок – сравнить оценки, основанные на исторических данных, в частности на среднем числе ошибок, приходящихся на 1 оператор в предыдущих проектах. В литературе есть сведения о частоте ошибок, но они не очень обширны. Имеющиеся данные ориентированы по отраслям и берутся как среднее значение по некоторому количеству операторов (например, 10 ошибок на 1000 операторов).
Пример: данные IBM для OS/360, OS/VS1, OS/VS2:

x – многократно исправляемый модуль или число модулей, которые потребовали 10 и более исправлений.
y – число модулей, потребовавших 1 или несколько исправлений.
z – полное число исправлений в модулях.
Из-за неопределенностей во всех рассмотренных модулях пока самый разумный подход – воспользоваться несколькими моделями и объединить их результаты. Например, данные по прежним проектам можно использовать для грубой оценки. Далее можно использовать модель с двумя параллельными группами. Далее – тестирование с искусственным внесением ошибок, определить достоверность С по модели Миллса, а также использовать другие модели.
Объединение результатов нескольких тестов:
Средняя величина
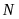 ,
,
Минимальные оценки
Максимальные оценки
Интервальные оценки
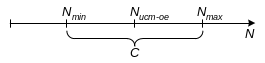

Имитационные модели
Такие модели, которые имитируют процессы появления ошибок, процесс обнаружения ошибок, процесс исправления ошибок с точки зрения надежности ПО.
Часто программу представляют как последовательность узлов, дуг и петель ориентированного графа.
Узлы – точки в которых части программы объединяются или разъединяются.
Дуги – последовательности линейных участков. В них размещаются команды.
Тестирование ПО. Испытания ПО при сертификации
Детерминированное тестирование при проектировании. Детерминированное испытание при сертификации
Принципы и задачи детерминированного тестирования

Основной задачей детерминированного тестирования является установление факта работоспособности программ и соответствие их техническому заданию, а также выявление и устранение ошибок и доведение характеристик программ до уровня требований, заданных заказчиком.
Диагностирование производится автоматическими человеко-машинными системами, в которых:
на долю человека приходится анализирующая роль в обнаружении ошибок, их анализ и принятие решений на их корректировку;
вычислительные системы обеспечивают исполнение программы, управление заданиями и тестами, селективное информирование о ходе тестирования.
При детерминированном тестировании получаются результаты при фиксированном наборе исходных данных, а так же сравнение этих значений с эталонными. Диапазон варьирования исходных данных и число вариантов сочетания переменных определяют достоверность отладки. Сравнение результатов исполнения с эталонами, как правило, происходит автоматически. Если результат отличается от эталона, определяется место и тип ошибки.
В зависимости от используемой при тестировании информации различают два метода:
Метод проверки по исходным данным и результатам.
Программу рассматривается, как чёрный ящик и после установления факта неработоспособности на каком-то наборе используется информация о структуре программы, т.е. от общего к частному с надеждой, что ошибки нет.
Метод с учётом промежуточных результатов.
Анализируются логические маршруты исполнения программы и промежуточные результаты в точках маршрута. Проверка программы осуществляется походу её исполнения от частного к общему с уверенностью, что ошибка есть. Метод – белый ящик.
«Серый ящик» – частично структура известна, а частично – нет.
Метод белого ящика более прост при локализации ошибок, но требует больше времени, чем метод проверки по окончательным результатам.
Процесс отладки программы при детерминированном тестировании подразделяется на следующие этапы:
планирование отладки;
составление тестов и задач на отладку и исполнение программы;
информирование о результатах по задачам теста;
анализ результатов, обнаружение и локализация ошибок;
устранение ошибок и корректировка исходного текста программы.
Детерминированное тестирование включает:
выбор последовательности контрольных точек, входы и выходы из программы;
выбор наборов значений исходных данных;
выбираются промежуточные точки контроля и перечень переменных, подлежащих контролю в этих точках, маршруты исполнения программы.
Порядок тестирования может быть:
безусловный, т.е. независимый от результатов исполнения предыдущих наборов;
условным.