

Кодирование Информации.
Термин «информация» восходит к латинскому informatio– разъяснение, изложение, осведомленность. Информацию можно классифицировать разными способами, и разные науки это делают по-разному. Например, в философии различают информацию объективную и субъективную. Объективная информация отражает явления природы и человеческого общества. Субъективная информация создается людьми и отражает их взгляд на объективные явления. В информатике отдельно рассматривается аналоговая информация и цифровая. Это важно, поскольку человек благодаря своим органам чувств, привык иметь дело с аналоговой информацией, а вычислительная техника, наоборот, в основном, работает с цифровой информацией. Разница между аналоговой информацией и цифровой, прежде всего, в том, что аналоговая информация непрерывна, а цифровая дискретна. К цифровым устройствам относятся персональные компьютеры – они работают с информацией, представленной в цифровой форме, цифровыми являются и музыкальные проигрыватели лазерных компакт дисков.
Количество информации.
Содержательный подход к измерению информации.
Для человека информация — это знания человека. Рассмотрим вопрос с этой точки зрения. Получение новой информации приводит к расширению знаний. Если некоторое сообщение приводит к уменьшению неопределенности нашего знания, то можно говорить, что такое сообщение содержит информацию. Отсюда следует вывод, что сообщение информативно (т.е. содержит ненулевую информацию), если оно пополняет знания человека. Например, прогноз погоды на завтра — информативное сообщение, а сообщение о вчерашней погоде неинформативно, т.к. нам это уже известно. Нетрудно понять, что информативность одного и того же сообщения может быть разной для разных людей. Например: «2x2=4» информативно для первоклассника, изучающего таблицу умножения, и неинформативно для старшеклассника. Получение всяких знаний должно идти от простого к сложному. И тогда каждое новое сообщение будет в то же время понятным, а значит, будет нести информацию для человека. Очевидно, различать лишь две ситуации: «нет информации» — «есть информация» для измерения информации недостаточно. Нужна единица измерения, тогда мы сможем определять, в каком сообщении информации больше, в каком — меньше. Неопределенность знаний о некотором событии — это количество возможных результатов события.
Рассмотрим один пример. На книжном стеллаже восемь полок. Книга может быть поставлена на любую из них. Сколько информации содержит сообщение о том, где находится книга? Применим метод половинного деления. Зададим несколько вопросов уменьшающих неопределенность знаний в два раза.

Задаем вопросы: - Книга лежит выше четвертой полки? - Нет. - Книга лежит ниже третьей полки? - Да . - Книга — на второй полке? - Нет. - Ну теперь все ясно! Книга лежит на первой полке!
Каждый ответ уменьшал неопределенность в два раза. Всего было задано три вопроса. Значит набрано 3 бита информации. И если бы сразу было сказано, что книга лежит на первой полке, то этим сообщением были бы переданы те же 3 бита информации. Если обозначить возможное количество событий, или, другими словами, неопределенность знаний N, а буквой I количество информации в сообщении о том, что произошло одно из N событий, то можно записать формулу: 2^I = N Количество информации, содержащееся в сообщении о том, что произошло одно из N равновероятных событий, определяется из решения показательного уравнения: 2^I = N.
Единицы измерения информации
Единицы измерения информации. Бит. Байт. Бит – наименьшая единица представления информации. Байт – наименьшая единица обработки и передачи информации. Количество информации в сообщении, таким образом, зависит от того, насколько ново это сообщение для получателя. Если в результате получения сообщения достигнута полная ясность в данном вопросе (т.е. неопределенность исчезнет), говорят, что получена исчерпывающая информация. Это означает, что нет необходимости в дополнительной информации на эту тему. Напротив, если после получения сообщения неопределенность осталась прежней (сообщаемые сведения или уже были известны, или не относятся к делу), значит, информации получено не было (нулевая информация). Единица измерения информации называется бит (bit) – сокращение от английских слов binary digit, что означает двоичная цифра. В компьютерной технике бит соответствует физическому состоянию носителя информации: намагничено – не намагничено, есть отверстие – нет отверстия. При этом одно состояние принято обозначать цифрой 0, а другое – цифрой 1. Выбор одного из двух возможных вариантов позволяет также различать логические истину и ложь. Последовательностью битов можно закодировать текст, изображение, звук или какую-либо другую информацию. Такой метод представления информации называется двоичным кодированием (binary encoding). В информатике часто используется величина, называемая байтом (byte) и равная 8 битам. И если бит позволяет выбрать один вариант из двух возможных, то байт, соответственно, 1 из 256 (28).
Алфавитный подход к измерению информации.
А теперь познакомимся с другим способом измерения информации. Этот способ не связывает количество информации с содержанием сообщения, и называется он алфавитным подходом. При алфавитном подходе к определению количества информации отвлекаются от содержания информации и рассматривают информационное сообщение как последовательность знаков определенной знаковой системы. Проще всего разобраться в этом на примере текста, написанного на каком-нибудь языке. Для нас удобнее, чтобы это был русский язык. Все множество используемых в языке символов будем традиционно называть алфавитом. Обычно под алфавитом понимают только буквы, но поскольку в тексте могут встречаться знаки препинания, цифры, скобки, то мы их тоже включим в алфавит. В алфавит также следует включить и пробел, т.е. пропуск между словами. Полное количество символов алфавита принято называть мощностью алфавита. Будем обозначать эту величину буквой N. Например, мощность алфавита из русских букв и отмеченных дополнительных символов равна 54. В каждой очередной позиции текста может появиться любой из N символов. Тогда, согласно известной нам формуле, каждый такой символ несет I бит информации, который можно определить из решения уравнения: 2I = 54. Получаем: I = 5.755 бит. Применение алфавитного подхода удобно прежде всего при использовании технических средств работы с информацией. В этом случае теряют смысл понятия «новые — старые», «понятные — непонятные» сведения. Алфавитный подход является объективным способом измерения информации в отличие от субъективного содержательного подхода. Удобнее всего измерять информацию, когда размер алфавита N равен целой степени двойки. Например, если N=16, то каждый символ несет 4 бита информации потому, что 24 = 16. А если N =32, то один символ «весит» 5 бит. Ограничения на максимальный размер алфавита теоретически не существует. Однако есть алфавит, который можно назвать достаточным. С ним мы скоро встретимся при работе с компьютером. Это алфавит мощностью 256 символов. В алфавит такого размера можно поместить все практически необходимые символы: латинские и русские буквы, цифры, знаки арифметических операций, всевозможные скобки, знаки препинания.... Поскольку 256 = 28, то один символ этого алфавита «весит» 8 бит. Причем 8 бит информации — это настолько характерная величина, что ей даже присвоили свое название — байт. 1 байт = 8 бит. Сегодня очень многие люди для подготовки писем, документов, статей, книг и пр. используют компьютерные текстовые редакторы. Компьютерные редакторы, в основном, работают с алфавитом размером 256 символов. В этом случае легко подсчитать объем информации в тексте. Если 1 символ алфавита несет 1 байт информации, то надо просто сосчитать количество символов; полученное число даст информационный объем текста в байтах. В любой системе единиц измерения существуют основные единицы и производные от них. Для измерения больших объемов информации используются следующие производные от байта единицы: 1 килобайт = 1Кб = 2^10 байт = 1024 байта. 1 мегабайт = 1Мб = 2^10 Кб = 1024 Кб. 1 гигабайт = 1Гб = 2^10 Мб = 1024 Мб.
Название |
Условное обозначение |
Соотношение с другими единицами |
Килобит |
Кбит |
1 Кбит = 1024 бит = 2^10 бит |
Мегабит |
Мбит |
1 Мбит = 1024 Кбит = 2^20 бит |
Гигабит |
Гбит |
1 Гбит = 1024 Мбит = 2^30 бит |
Килобайт |
Кбайт (Кб) |
1 Кбайт = 1024 байт = 2^10 байт |
Мегабайт |
Мбайт (Мб) |
1 Мбайт = 1024 Кбайт = 2^20 байт |
Гигабайт |
Гбайт (Гб) |
1 Гбайт = 1024 Мбайт = 2^30 |
Прием-передача информации могут происходить с разной скоростью. Количество информации, передаваемое за единицу времени, есть скорость передачи информации или скорость информационного потока.
Очевидно, эта скорость выражается в таких единицах, как бит в секунду (бит/с), байт в секунду (байт/с), килобайт в секунду (Кбайт/с) и т.д.
СИСТЕМЫ СЧИСЛЕНИЯ(СС) - способы кодирования числовой информации,т.е. способ записи чисел с помощью некоторого алфавита, символы которого называют цифрами. Бывают позиционные и непозиционные СС.
НЕПОЗИЦИОННАЯ СИСТЕМА СЧИСЛЕНИЯ – в ней величина, которую обозначает цифра не зависит от положения в числе.
Самой популярной системой кодирования чисел оказалась позиционная, десятичная. Используются десять цифр. Значение каждой определяется той позицией, которую цифра занимает в записи числа. Эта система пришла из Индии, где она появилась не позднее VI века,европейцы заимствовали ее у арабов,назвав ее арабской. Из арабского языка заимствовано слово "цифра". Причина ее возникновения анатомическая-10 пальцев АНАТОМИЧЕСКАЯ система счисления (существовали пятиричные, двадцатиричные системы счисления)
В десятичной позиционной системе особую роль играет число 10 и его степени, например, 1996 - 6 единиц, 9 десятков, 9 сотен 1 тысяча или 1996=6+9*10+9*100+1*1000, т.к.1000=103 в третьей степени, 100=102, 10=101, т.о. 1996=1*103 + 9*102 + 9*101 +6*100.
ЛЮБОЕ ЧИСЛО В НУЛЕВОЙ СТЕПЕНИ РАВНО ЕДИНИЦЕ 10^0 = 1
Т.е. любое 4-х значное число можно записать в следующем виде:
N=a3*103+a2*102+a1*101+a0*100
a3, a2, a1, a0-десятичные цифры, от 1 до 9 или коэффициенты, 3 2 1 0 -разряды, степени, число 10 со степенями называют основанием системы счисления
Но основанием системы может быть не обязательно число 10, т.о. мы можем записать число в р-ичной системе, где основанием будут степени числа р Т.о. любое число N в р-ичной системе мы можем представить в виде формулы:
N=an*Pn+an-1*Pn-1+...+a1*P1+a0*P0
Если взять за основание 60, то придется использовать 60 разных цифр. Такая система была в Древнем Вавилоне.
Если основанием возьмем 2, получим систему всего с двумя цифрами: 0 и 1. К сожалению в этой системе даже небольшие числа записываются слишком длинно, так 1995 в двоичной системе записывается
199510=111110010112
Перевод из двоичной в десятичную систему счисления
Как узнать чему равно девятизначное двоичное число N=1111101002
Подпишем сверху каждый разряд
876543210 0 - 9 разряды (степени двойки)
1111101002 В двоичной системе особую роль играет двойка и ее степени. Т.о.111110100=1*28 +1*27 +1*26 +1*25 +1*24 +0*23+1*22 +0*21 +0*20 =1*256+1*128+1*64 +1*32 +1*16 +0*8 +1*4 +0*2 +0*1=256 + 128 + 64 + 32 + 16 + 0 + 4 + 0 +0 =500
ПЕРЕВОД В ДВОИЧНУЮ СИСТЕМУ СЧИСЛЕНИЯ ЧИСЕЛ ИЗ ДЕСЯТИЧНОЙ СИСТЕМЫ СЧИСЛЕНИЯ
Пусть
нужно перевести в двоичную систему
число 234. Будем делить 234 последовательно
на 2 и запоминать остатки, не забывая
про нулевые.
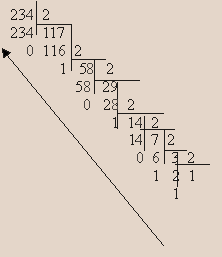
Выписав все остатки, начиная с последнего в обратном порядке ,получим двоичное разложение числа
23410 = 111010102
Восьмеричная и шестнадцатеричная системы счисления
Запись числа в двоичной системе удобна для компьютера, но громоздка для человека. На помощь приходят системы, родственные двоичной ВОСЬМИРИЧНАЯ СИСТЕМА СЧИСЛЕНИЯ использует 8 цифр: 0,1,2,3,4,5,6,7.
Единица, записанная в самом младшем разряде означает просто единицу (1*8 в нулевой степени), та же единица в следующем разряде обозначает 8 (1*8 в первой), в следующем 64(1*8 во второй)и т.д.
2 1 0 -- разряды (степени восьмерки) 1 0 08 =1*82 +0*81 +0*80 = 1*64+0+0=6410
8 - это 2 в третьей степени. При переводе в восьмиричную систему двоичное число из трех записывается одной цифрой.
Восьмиричная запись |
Двоичное представление |
впереди стоящий 0 ничего не значит |
0 |
000 |
|
1 |
001 |
|
2 |
010 |
|
3 |
011 |
|
4 |
100 |
|
5 |
101 |
|
6 |
110 |
|
7 |
111 |
Для перевода из двоичной в восьмиричную число, записанное в двоичной системе делим на триады справа налево Например , 11011100011=11 011 100 011 и заменить каждую группу одной восьмиричной цифрой 2 2 4 2 и получим 22428
Для перевода числа из восьмиричной системы в двоичную достаточно заменить каждую цифру на ее перевод в двоичную систему, представив каждую цифру в виде триады (1 в двоичной системе 1 добавляем до триады впереди 00)
6 |
1 |
1 |
110 |
001 |
001 |
Еще компактней выглядит запись двоичного числа в ШЕСТНАДЦАТИРИЧНОЙ СИСТЕМЕ СЧИСЛЕНИЯ.
Для первых 10 из 16 шестнадцатиричных цифр используются привычные цифры 0 1 2 3 4 5 6 7 8 9, а для остальных используют первые буквы латинского алфавита A-10 D-13 B-11 E-14 C-12 F-15
Цифра 1 в самом младшем разряде означает 1, в следующем разряде означает 16 (в первой степени), в следующем разряде 16*16 (162)=256, в следующем разряде 1*163 и т.д.
10016 =25610= 1*162+0*161+0*160=25610.
Цифра F, записанная в самом младшем разряде означает 15 в десятичной системе, F в следующем разряде означает 15*16 в первой степени в десятичной системе и т.д.
2 1 0 ----- разряды (степени числа 16) A F 016 =10*162+15*161+0*160=10*256+240+0*1=2560+240+0=280010
2 1 0 BAD16= 11*162+10*161+13*160=11*256+10*16+13*1=2816+160+13=298910
16 - это 2 в четвертой степени. При переводе из двоичной системы в шестнадцатиричную двоичное число из 4-х цифр кодируется числом из одной цифры в шестнадцатиричной системе.
Для перевода числа из шестнадцатеричной системы в двоичную достаточно заменить каждую цифру на ее перевод в двоичную, представив каждую цифру в виде сочетания четырех 1 и 0
A |
0 |
F |
AOF16 |
1010 |
0000 |
1111 |
Как осуществить перевод чисел из двоичной системы в шестнадцатиричную? Необходимо разбить число, записанное в двоичной системе на группы по 4 разряда справа налево, заменив каждую группу одной шестнадцатиричной цифрой
1101 |
1010 |
1101 |
в двоичной |
11 |
10 |
13 |
в десятичной |
B |
A |
D |
в шестнадцатиричной |
10 |
2 |
8 |
16 |
0 |
000 |
0 |
0 |
1 |
001 |
1 |
1 |
2 |
010 |
2 |
2 |
3 |
011 |
3 |
3 |
4 |
100 |
4 |
4 |
5 |
101 |
5 |
5 |
6 |
110 |
6 |
6 |
7 |
111 |
7 |
7 |
8 |
1000 |
10 |
8 |
9 |
1001 |
11 |
9 |
10 |
1010 |
12 |
A |
11 |
1011 |
13 |
B |
12 |
1100 |
14 |
C |
13 |
1101 |
15 |
D |
14 |
1110 |
16 |
E |
15 |
1111 |
17 |
F |
Кодирование текстовой информации
Для кодирования символьной или текстовой информации применяются различные системы: при вводе информации с клавиатуры кодирование происходит при нажатии клавиши, на которой изображен требуемый символ, при этом в клавиатуре вырабатывается так называемый scan-код, представляющий собой двоичное число, равное порядковому номеру клавиши.
3.1 Кодировка ASCII
Всего существует множество кодировочных таблиц. Рассмотрим сначала кодировочную таблицу ASCII (ASCII - American Standard Code for Information Interchange - Американский стандартный код для обмена информацией). Эта кодировка является наиболее известной. На практике обычно не бывает проблем с кодированием англоязычных текстов, поскольку первая половина кодировки стандартизована, но, к сожалению, для кодировки русских букв существует несколько кодировочных таблиц, что иногда создает проблемы при работе с текстами.
Для кодировки одного символа из таблицы отводится 8 бит. При обработке текстовой информации один байт может содержать код некоторого символа - буквы, цифры, знака пунктуации, знака действия и т.д. Каждому символу соответствует свой код в виде целого числа. Один байт как набор восьми битов позволяет закодировать 256 символов, что вполне достаточно для работы сразу с двумя обычными языками, например английским и русским. При этом все коды собираются в специальные таблицы, называемые кодировочными. С их помощью производится преобразование кода символа в его видимое представление на экране монитора. В результате любой текст в памяти компьютера представляется как последовательность байтов с кодами символов.
Таблица кодировки текстовой информации ASCII.

Первая половина таблицы ASCII стандартизована. Она содержит управляющие коды (от 0 до 31. Эти коды из таблицы изъяты, так как они не относятся к текстовым элементам. Вторая половина таблицы содержит национальные шрифты, символы псевдографики, из которых могут быть построены таблицы, специальные математические знаки. Нижнюю часть таблицы кодировок можно заменять, используя соответствующие драйверы - управляющие вспомогательные программы. Этот прием позволяет применять несколько шрифтов и их гарнитур. Невозможно использовать символы различных наборов кодировок в одном и том же документе. Так как каждый текстовый документ использует свой собственный набор кодировок, то возникают большие трудности с автоматическим распознаванием текста. Появляются новые символы (например: Евро), вследствие чего ISO разрабатывает новый стандарт ISO-8859-15, который весьма схож со стандартом ISO-8859-1. Разница состоит в следующем: из таблицы кодировки старого стандарта ISO-8859-1 были убраны символы обозначения старых валют, которые не используются в настоящее время, для того, чтобы освободить место под вновь появившиеся символы (такие, как Евро). В результате у пользователей на дисках могут лежать одни и те же документы, но в разных кодировках. Решением этих проблем является принятие единого международного набора кодировок, который называется универсальным кодированием или Unicode.
Данная кодировка решает пользовательские проблемы (см. выше), но создает новые, технические проблемы: как пересылать символы в формате Unicode, используя 8-битные байты? 8-битные единицы являются наименьшими передаваемыми единицами в большинстве компьютеров, а также являющимися минимальными единицами, используемыми при сетевых соединениях на основе протокола TCP/IP. Использование 1-го байта для представления 1-го символа стало эпизодом истории (факт появления такой кодировки обусловлен тем, что компьютеры зародились в Европе и США, где долгое время обходились 96 символами).
Существует 4 основных способа кодировки байтами в формате Unicode:
UTF-8: 128 символов кодируются одним байтом (формат ASCII), 1920 символов кодируются 2-мя байтами ((Roman, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic символы), 63488 символов кодируются 3-мя байтами (Китайский, японский и др.) Оставшиеся 2 147 418 112 символы (еще не использованы) могут быть закодированы 4, 5 или 6-ю байтами.
UCS-2: Каждый символ представлен 2-мя байтами. Данная кодировка включает лишь первые 65 535 символов из формата Unicode.
UTF-16:Является расширением UCS-2, включает 1 114 112 символов формата Unicode. Первые 65 535 символов представлены 2-мя байтами, остальные - 4-мя байтами.
USC-4: Каждый символ кодируется 4-мя байтами.
Получается, что 8 бит используются для кодирования европейских языков, а для китайского, японского и корейского языков много больше. Это может повлиять на объем занимаемого дискового пространства и на скорость передачи по сети. Для основных кодировок картина следующая (K(%) - увеличение дискового пространства и снижение скорости передачи по сети):
UTF-8: никаких изменений для американской ASCII, незначительное ухудшение (К = несколько %) для ISO-8859-1, К=50% для китайского, японского, корейского и К=100% для греческого и кириллицы.
UCS-2 и UTF-16: никаких изменений для китайского, японского, корейского; К=100% для американской ASCII, ISO-8859-1, греческого и кириллицы.
UCS-4: К=100% для китайского, японского, корейского; К=300% для американской ASCII, ISO-8859-1, греческого и кириллицы.
В итоге получается, что UTF-8 кодировка занимает меньше дискового пространства и позволяется передавать данные по сети с большей скоростью [10]. Unicode 3.0
Стандарт Unicode был разработан с целью создания единой кодировки символов всех современных и многих древних письменных языков. Каждый символ в этом стандарте кодируется 16 битами, что позволяет ему охватить несравненно большее количество символов, чем принятые ранее 7- и 8-битовые кодировки. Еще одним важным отличием Unicode от других систем кодировки является то, что он не только приписывает каждому символу уникальный код, но и определяет различные характеристики этого символа, например:
тип символа (прописная буква, строчная буква, цифра, знак препинания и т.д.);
атрибуты символа (отображение слева направо или справа налево, пробел, разрыв строки и т.д.);
соответствующая прописная или строчная буква (для строчных и прописных букв соответственно);
соответствующее числовое значение (для цифровых символов).
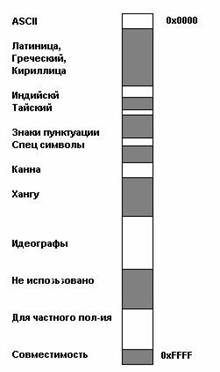
Весь
диапазон кодов от 0 до FFFF разбит на
несколько стандартных подмножеств,
каждое из которых соответствует либо
алфавиту какого-то языка, либо группе
специальных символов, сходных по своим
функциям. На приведенной ниже схеме
содержится общий перечень подмножеств
Unicode 3.0.
Формат UTF-8: Стандарт Unicode является основой для хранения и текста во многих современных компьютерных системах. Однако, он не совместим с большинством Интернет-протоколов, поскольку его коды могут содержать любые байтовые значения, а протоколы обычно используют байты 00 - 1F и FE - FF в качестве служебных. Для достижения совместимости были разработаны несколько форматов преобразования Unicode (UTFs, Unicode Transformation Formats), из которых на сегодня наиболее распространенным является UTF-8. Этот формат определяет следующие правила преобразования каждого кода Unicode в набор байтов (от одного до трех), пригодных для транспортировки Интернет-протоколами. Таблица 2. Формат UTF-8. Диапазон Unicode Двоичный код символа Байты UTF-8 (двоичные)
0000 - 007F 00000000 0zzzzzzz 0zzzzzzzz
0080 - 07FF 00000yyy yyzzzzzz 110yyyyy 10zzzzzz
0800 – FFFF xxxxyyyy yyzzzzzz 1110xxxx 10yyyyyy 10zzzzzz
Здесь x,y,z обозначают биты исходного кода, которые должны извлекаться, начиная с младшего, и заноситься в байты результата справа налево, пока не будут заполнены все указанные позиции. Формат UTF-16: Дальнейшее развитие стандарта Unicode связано с добавлением новых языковых плоскостей, т.е. символов в диапазонах 10000 - 1FFFF, 20000 - 2FFFF и т.д., куда предполагается включать кодировку для письменностей мертвых языков, не попавших в таблицу, приведенную выше. Для кодирования этих дополнительных символов был разработан новый формат UTF-16. Для базовой языковой плоскости, т.е. для символов с кодами от 0000 до FFFF, он совпадает с Unicode. Поэтому, если вы не собираетесь писать Веб-страницы на языке шумеров или майя, можете смело отождествлять два эти формата.
Файл. Форматы файлов Файл – наименьшая единица хранения информации, содержащая последовательность байтов и имеющая уникальное имя.
Основное назначение файлов – хранить информацию. Они предназначены также для передачи данных от программы к программе и от системы к системе. Другими словами, файл – это хранилище стабильных и мобильных данных. Но, файл – это нечто большее, чем просто хранилище данных. Обычно файл имеет имя, атрибуты, время модификации и время создания.
Файловая структура представляет собой систему хранения файлов на запоминающем устройстве, например, на диске. Файлы организованы в каталоги (иногда называемые директориями или папками). Любой каталог может содержать произвольное число подкаталогов, в каждом из которых могут храниться файлы и другие каталоги.
Способ, которым данные организованы в байты, называется форматом файла.
Для того чтобы прочесть файл, например, электронной таблицы, нужно знать, каким образом байты представляют числа (формулы, текст) в каждой ячейке; чтобы прочесть файл текстового редактора, надо знать, какие байты представляют символы, а какие шрифты или поля, а также другую информацию. Все файлы условно можно разделить на две части – текстовые и двоичные. Текстовые файлы – наиболее распространенный тип данных в компьютерном мире. Для хранения каждого символа чаще всего отводится один байт, а кодирование текстовых файлов выполняется с помощью специальных таблиц, в которых каждому символу соответствует определенное число, не превышающее 255. Файл, для кодировки которого используется только 127 первых чисел, называется ASCII-файлом (сокращение от American Standard Code for Information Intercange – американский стандартный код для обмена информацией), но в таком файле не могут быть представлены буквы, отличные от латиницы (в том числе и русские). Большинство национальных алфавитов можно закодировать с помощью восьмибитной таблицы. Для русского языка наиболее популярны на данный момент три кодировки: Koi8-R, Windows-1251 и, так называемая, альтернативная (alt) кодировка.
Такие языки, как китайский, содержат значительно больше 256 символов, поэтому для кодирования каждого из них используют несколько байтов. Но чисто текстовые файлы встречаются все реже. Документы часто содержат рисунки и диаграммы, используются различные шрифты. В результате появляются форматы, представляющие собой различные комбинации текстовых, графических и других форм данных.
Двоичные файлы, в отличие от текстовых, не так просто просмотреть, и в них, обычно, нет знакомых слов – лишь множество непонятных символов. Эти файлы не предназначены непосредственно для чтения человеком. Примерами двоичных файлов являются исполняемые программы и файлы с графическими изображениями.
Кодирование графической информации. В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части – растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element). Код пиксела содержит информации о его цвете.
Для черно-белого изображения (без полутонов) пиксел может принимать только два значения: белый и черный (светится – не светится), а для его кодирования достаточно одного бита памяти: 1 – белый, 0 – черный.
Пиксел на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксел недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксел, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 – черный, 10 – зеленый, 01 – красный, 11 – коричневый.
На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов – красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций:
R R G G B B цвет цвет 0 1 0 0 0 0 черный красный 0 1 0 0 1 1 синий розовый 0 1 1 1 0 0 зеленый коричневый 0 1 1 1 1 1 голубой белый
Разумеется, если иметь возможность управлять интенсивностью (яркостью) свечения базовых цветов, то количество различных вариантов их сочетаний, порождающих разнообразные оттенки, увеличивается. Количество различных цветов – К и количество битов для их кодировки – N связаны между собой простой формулой: 2^N = К.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения – линия, прямоугольник, окружность или фрагмент текста – располагается в своем собственном слое, пикселы которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т.д.) Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличие от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость). Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые, в свою очередь, содержат определенное количество точек (пикселей).
Каждому пикселю присвоен код, хранящий информацию о цвете пикселя.
Для получения черно-белого изображения (без полутонов) пиксель может принимать только два состояния: “белый” или “черный”.
Тогда для его кодирования достаточно 1 бита: 1 – белый, 0 – черный.
Пиксель на цветном дисплее может иметь различную окраску. Поэтому 1 бита на пиксель – недостаточно.
Для кодирования 4-цветного изображения требуется два бита на пиксель, поскольку два бита могут принимать 4 различных состояния.
Может использоваться, например, такой вариант кодировки цветов:
00 – черный
10 – зеленый
01 – красный
11 – коричневый.
Цветное изображение на экране монитора формируется за счет смешивания трех базовых цветов: красного, зеленого, синего.
Из трех цветов можно получить восемь комбинаций: Черный - 0 0 0 Синий - 0 0 1 Зеленый - 0 1 0 Голубой - 0 1 1 Красный - 1 0 0 Розовый - 1 0 1 Коричневый - 1 1 0 Белый - 1 1 1
Следовательно, для кодирования 8-цветного изображения требуется три бита памяти на один пиксель.
Для получения богатой палитры цветов базовым цветам могут быть заданы различные интенсивности, тогда количество различных вариантов их сочетаний, дающих разные краски и оттенки, увеличивается.
Шестнадцатицветная палитра получается при использовании 4-разрядной кодировки пикселя: к трем битам базовых цветов добавляется один бит интенсивности. Этот бит управляет яркостью всех трех цветов одновременно.
Также графическая информация может быть представлена в виде векторного изображения.
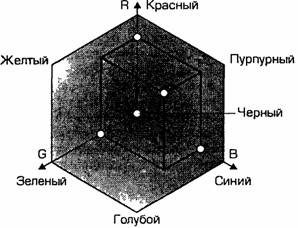
Цветовая модель RGB.
Наиболее проста для понимания и очевидна цветовая модель RGB. В этой цветовой модели работают мониторы и бытовые телевизоры. Любой цвет считается состоящим из трех основных компонентов: красного (Red), зеленого (Green) и синего (Blue). Эти цвета цветовой модели называются основными. Считается также, что при наложении одного компонента на другой яркость суммарного цвета увеличивается. Совмещение трех компонентов дает нейтральный цвет (серый), который при большой яркости стремится к белому цвету. Так формируется цветовая модель RGB.
Цветовая
модель RGB соответствует тому, что мы
наблюдаем на экране монитора, поэтому
данную цветовую модель применяют всегда,
когда готовится изображение, предназначенное
для воспроизведения на экране. Если
изображение проходит компьютерную
обработку в графическом редакторе, то
его тоже следует представить в цветовой
модели RGB. В графических редакторах
имеются средства для преобразования
изображений из одной цветовой модели
в другую цветовую модель.
Метод получения нового оттенка суммированием яркостей составляющих компонентов называют аддитивным методом. Он применяется всюду, где цветное изображение рассматривается в проходящем свете («на просвет»): в мониторах, слайд-проекторах и т. п.
Нетрудно догадаться, что чем меньше яркость, тем темнее оттенок. Поэтому в аддитивной модели центральная точка, имеющая нулевые значения компонентов (0,0,0), имеет черный цвет (отсутствие свечения экрана монитора). Белому цвету соответствуют максимальные значения составляющих (255, 255, 255).
Модель
RGB является аддитивной, а ее компоненты:
красный, зеленый и синий — называют
основными цветами.
Цветовая модель CMYk.
Цветовая модель CMYK скорее всего вам не понадобится, если вы будете печатать на принтере.
Желательно знать, что такое цветовая модель CMYK.
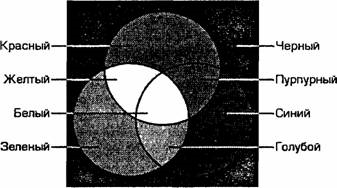
Цветовая модель CMYK используется для подготовки не экранных, а печатных изображений. Они отличаются тем, что их видят не в проходящем, а в отраженном свете. Чем больше краски положено на бумагу, тем больше света она поглощает и меньше отражает. Совмещение трех основных красок в цветовой модели CMYk поглощает почти весь падающий свет, и со стороны изображение выглядит почти черным. В отличие от модели RGB в цветовой модели CMYK увеличение количества краски приводит не к увеличению визуальной яркости, а наоборот к ее уменьшению. Поэтому для подготовки печатных изображений используется не аддитивная (суммирующая) модель, а субтрактивная (вычитающая) модель. Цветовыми компонентами этой модели являются не основные цвета, а те, которые получаются в результате вычитания основных цветов из белого:
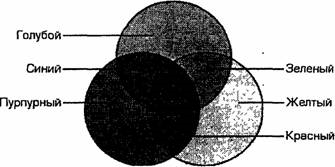
ГОЛУБОЙ (Суап)=БЕЛЫЙ-КРАСНЫЙ=ЗЕЛЕНЫЙ+СИНИЙ;
ПУРПУРНЫЙ (Magenta)=БЕЛЫЙ-ЗЕЛЕНЫЙ=КРАСНЫЙ+СИНИЙ;
ЖЕЛТЫЙ (Yellow)=БЕЛЫЙ-СИНИЙ=КРАСНЫЙ+ЗЕЛЕНЫЙ
Эти три цвета называются дополнительными, потому что они дополняют основные цвета до белого.
Существенную трудность в полиграфии представляет черный цвет. Теоретически его можно получить совмещением трех основных или дополнительных красок, но на практике результат оказывается негодным. Поэтому в цветовую модель CMYk добавлен четвертый компонент — черный. Ему эта система обязана буквой К в названии (black),
Цветоделение в цветовой модели CMYk.
В
типографиях цветные изображения печатают
в несколько приемов. Накладывая на
бумагу по очереди голубой, пурпурный,
желтый и черный отпечатки, получают
полноцветную иллюстрацию. Поэтому
готовое изображение, полученое на
компьютере, перед печатью разделяют на
четыре составляющих одноцветных
изображения. Этот процесс называется
цветоделением. Современные графические
редакторы имеют средства для выполнения
этой операции.
 В
отличие от модели RGB, в цветовой модели
CMYK центральная точка имеет белый цвет
(отсутствие красителей на белой бумаге).
К трем цветовым координатам добавлена
четвертая — интенсивность черной
краски. Ось черного цвета выглядит
обособленной, но в этом есть смысл: при
сложении цветных составляющих с черным
цветом все равно получится черный цвет.
В
отличие от модели RGB, в цветовой модели
CMYK центральная точка имеет белый цвет
(отсутствие красителей на белой бумаге).
К трем цветовым координатам добавлена
четвертая — интенсивность черной
краски. Ось черного цвета выглядит
обособленной, но в этом есть смысл: при
сложении цветных составляющих с черным
цветом все равно получится черный цвет.
Сложение цветов в цветовой модели CMYK каждый может проверить, взяв в руки голубой, розовый и желтый карандаши или фломастеры. Смесь голубого и желтого на бумаге дает зеленый цвет, розового с желтым — красный и т. д. При смешении всех трех цветов получается неопределенный темный цвет. Поэтому в этой модели черный цвет и понадобился дополнительно.
Цветовая модель HSB.
По сути, цветовая модель HSB использует тот же набор основных цветов.
Некоторые графические редакторы позволяют работать с цветовой моделью HSB. Если цветовая модель RGB наиболее удобна для компьютера, а цветовая модель CMYK — для типографий, то цветовая модель HSB наиболее удобна для человека. Цветовая модель HSB проста и интуитивно понятна.
В цветовой модели HSB тоже три компонента: оттенок цвета (Hue), насыщенность цвета (Saturation) и яркость цвета (Brightness). Регулируя эти три компонента, можно получить столь же много произвольных цветов, как и при работе с другими цветовыми моделями.
Цветовая
модель HSB удобна для применения в тех
графических редакторах, которые
ориентированы не на обработку готовых
изображений, а на их создание своими
руками. Существуют такие программы,
которые позволяют имитировать различные
инструменты художника (кисти, перья,
фломастеры, карандаши), материалы красок
(акварель, гуашь, масло, тушь, уголь,
пастель) и материалы полотна (холст,
картон, рисовая бумага и пр.). Создавая
собственное художественное произведение,
удобно работать в цветовой модели HSB, а
по окончании работы его можно преобразовать
в цветовую модель RGB или CMYK, в зависимости
от того, будет ли оно использоваться
как экранная или печатная
иллюстрация.
 Значение
цвета выбирается как вектор, выходящий
из центра окружности. Точка в центре
соответствует белому (нейтральному)
цвету, а точки по периметру — чистым
цветам. Направление вектора определяет
цветовой оттенок и задается в цветовой
модели HSB в угловых градусах. Длина
вектора определяет насыщенность цвета.
Яркость цвета задают на отдельной оси,
нулевая точка которой имеет черный
цвет.
Векторная графика (vector graphics) —
вид компьютерной графики, используемой
в приложениях для рисования. В отличие
от растровой графики позволяет
пользователю создавать и модифицировать
исходные изобразительные образы при
подготовке рисунков, технических
чертежей и диаграмм путем их вращения,
увеличения или уменьшения, растягивания.
Графические образы создаются и хранятся
в памяти ЭВМ в виде формул, описывающих
различные геометрические фигуры, которые
являются компонентами изображения.
Помимо данных, описывающих изображение,
векторные файлы содержат «заголовок»,
где отражается общая для чтения файла
информация, и «палитру», в которой
помещаются сведения о цвете всех (в том
числе наименьших) объектов изображения.
Сжатие
информации - проблема, имеющая достаточно
давнюю историю, гораздо более давнюю,
нежели история развития вычислительной
техники, которая (история) обычно шла
параллельно с историей развития проблемы
кодирования и шифровки информации.
Значение
цвета выбирается как вектор, выходящий
из центра окружности. Точка в центре
соответствует белому (нейтральному)
цвету, а точки по периметру — чистым
цветам. Направление вектора определяет
цветовой оттенок и задается в цветовой
модели HSB в угловых градусах. Длина
вектора определяет насыщенность цвета.
Яркость цвета задают на отдельной оси,
нулевая точка которой имеет черный
цвет.
Векторная графика (vector graphics) —
вид компьютерной графики, используемой
в приложениях для рисования. В отличие
от растровой графики позволяет
пользователю создавать и модифицировать
исходные изобразительные образы при
подготовке рисунков, технических
чертежей и диаграмм путем их вращения,
увеличения или уменьшения, растягивания.
Графические образы создаются и хранятся
в памяти ЭВМ в виде формул, описывающих
различные геометрические фигуры, которые
являются компонентами изображения.
Помимо данных, описывающих изображение,
векторные файлы содержат «заголовок»,
где отражается общая для чтения файла
информация, и «палитру», в которой
помещаются сведения о цвете всех (в том
числе наименьших) объектов изображения.
Сжатие
информации - проблема, имеющая достаточно
давнюю историю, гораздо более давнюю,
нежели история развития вычислительной
техники, которая (история) обычно шла
параллельно с историей развития проблемы
кодирования и шифровки информации.
Все алгоритмы сжатия оперируют входным потоком информации, минимальной единицей которой является бит, а максимальной - несколько бит, байт или несколько байт.
Целью процесса сжатия, как правило, есть получение более компактного выходного потока информационных единиц из некоторого изначально некомпактного входного потока при помощи некоторого их преобразования.
Основными техническими характеристиками процессов сжатия и результатов их работы являются: степень сжатия (compress rating) или отношение (ratio) объемов исходного и результирующего потоков; скорость сжатия - время, затрачиваемое на сжатие некоторого объема информации входного потока, до получения из него эквивалентного выходного потока; качество сжатия - величина, показывающая на сколько сильно упакован выходной поток, при помощи применения к нему повторного сжатия по этому же или иному алгоритму.
Все способы сжатия можно разделить на две категории: обратимое и необратимое сжатие.
Под необратимым сжатием подразумевают такое преобразование входного потока данных, при котором выходной поток, основанный на определенном формате информации, представляет, с некоторой точки зрения, достаточно похожий по внешним характеристикам на входной поток объект, однако отличается от него объемом.
Степень сходства входного и выходного потоков определяется степенью соответствия некоторых свойств объекта (т.е. сжатой и несжатой информации в соответствии с некоторым определенным форматом данных), представляемого данным потоком информации.
Такие подходы и алгоритмы используются для сжатия, например данных растровых графических файлов с низкой степенью повторяемости байтов в потоке. При таком подходе используется свойство структуры формата графического файла и возможность представить графическую картинку приблизительно схожую по качеству отображения (для восприятия человеческим глазом) несколькими (а точнее n) способами. Поэтому, кроме степени или величины сжатия, в таких алгоритмах возникает понятие качества, т.к. исходное изображение в процессе сжатия изменяется, то под качеством можно понимать степень соответствия исходного и результирующего изображения, оцениваемая субъективно, исходя из формата информации. Для графических файлов такое соответствие определяется визуально, хотя имеются и соответствующие интеллектуальные алгоритмы и программы. Необратимое сжатие невозможно применять в областях, в которых необходимо иметь точное соответствие информационной структуры входного и выходного потоков. Данный подход реализован в популярных форматах представления видео и фото информации, известных как JPEG и JFIF алгоритмы и JPG и JIF форматы файлов.
Обратимое сжатие всегда приводит к снижению объема выходного потока информации без изменения его информативности, т.е. - без потери информационной структуры.
Представление целых чисел в компьютере.
Целые числа являются простейшими числовыми данными, с которыми оперирует ЭВМ. Для целых чисел существуют два представления: беззнаковое (только для неотрицательных целых чисел) и со знаком. Очевидно, что отрицательные числа можно представлять только в знаковом виде. Целые числа в компьютере хранятся в формате с фиксированной запятой.
Представление целых чисел в беззнаковых целых типах.
Для беззнакового представления все разряды ячейки отводятся под представление самого числа. Например, в байте (8 бит) можно представить беззнаковые числа от 0 до 255. Поэтому, если известно, что числовая величина является неотрицательной, то выгоднее рассматривать её как беззнаковую.
Представление целых чисел в знаковых целых типах.
Для представления со знаком самый старший (левый) бит отводится под знак числа, остальные разряды - под само число. Если число положительное, то в знаковый разряд помещается 0, если отрицательное - 1. Например, в байте можно представить знаковые числа от -128 до 127.
Прямой код числа.
Представление числа в привычной форме "знак"-"величина", при которой старший разряд ячейки отводится под знак, а остальные - под запись числа в двоичной системе, называется прямым кодом двоичного числа. Например, прямой код двоичных чисел 1001 и -1001 для 8-разрядной ячейки равен 00001001 и 10001001 соответственно. Положительные числа в ЭВМ всегда представляются с помощью прямого кода. Прямой код числа полностью совпадает с записью самого числа в ячейке машины. Прямой код отрицательного числа отличается от прямого кода соответствующего положительного числа лишь содержимым знакового разряда. Но отрицательные целые числа не представляются в ЭВМ с помощью прямого кода, для их представления используется так называемый дополнительный код.