

10.4. Преобразование таблицы
Помимо изменения структуры таблицы, оператор alter table позволяет изменять параметры таблицы, например, ее название. Для этого используется конструкция rename [то] new_table, в результате применения которой таблица получает новое имя new_table. В листинге 10.10 таблица products базы данных shop переименовывается в components.

Для переименования таблиц существует также отдельный оператор rename table, который имеет следующий синтаксис:
RENAME TABLE tbl__name TO new_tbl_name [, tbl_name2 TO new_tbl_name2, . . . ]
Результатом работы оператора является переименование таблицы tbl_name в new_tbl_name. В одном операторе можно переименовать сразу несколько таблиц. В листинге ЮЛ I таблицы users и orders меняются именами.
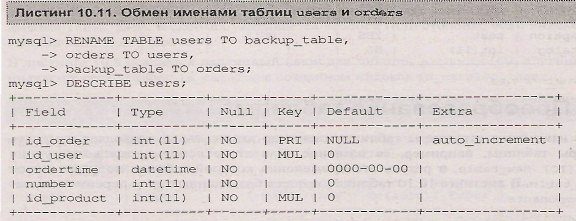
Так как в одной базе данных не может быть двух таблиц с одинаковыми именами, в листинге 10.11, таблице users потребовалось назначить временное имя backup_table, которое потом заменяется на orders.
Конструкция order BY field_name позволяет отсортировать записи таблицы по столбцу field_name. Следует учитывать, что созданная таблица не будет сохранять этот порядок строк после операций вставки и удаления. Так в листинге 10.12 записи таблицы catalogs сортируются по полю name.

В некоторых случаях эта возможность может облегчить операцию сортировки в MySQL, если таблица имеет такое расположение столбцов, которое вам нужно в дальнейшем. Эта опция в основном полезна, если заранее известен порядск, в котором преимущественно будут запрашиваться строки.
Конструкция auto_increment позволяет назначить новое значение для параметра таблицы auto_increment. В листинге 10.13 для таблицы catalogs выставляется значение auto_increment равное 1000, в результате чего добавление нового значения приведет к тому, что первичный ключ таблицы id_catalog получит значение 1000.

Помимо параметра auto_increment, таблицы имеют множество других параметров, кото рые можно изменять при помощи оператора alter table.
Тема 3.6. Добавление данных. Удаление данных. Обновление данных.
Добавление данных
После успешного создания базы данных и таблиц перед разработчиком встает задача заполнения таблиц данными. Традиционно в реляционных базах, данных для осуществления этой операции применяют три подхода:

Однострочный оператор INSERT
Однострочный оператор insert может использоваться в нескольких формах. Упрощенный синтаксис первой формы выглядит следующим образом:
![]()
Данный оператор вставляет новую запись в таблицу tbl, значения записи перечисляется в списке expression, порядок следования столбцов может задаваться списком col_name. Значения передаются в списке после ключевого слова values. Рассмотрим процесс вставки на примере таблицы catalogs (см. листинг 4.24). Таблица имеет два поля:

Добавить новую запись в таблицу catalogs можно при помощи запроса, представленного в листинге 6.1.

Как видно из листинга 6.1, в таблицу catalogs добавилась новая запись с первичным ключом id_catalogs, равным единице, и именем name — "Процессоры". Строковые значения необходимо помещать в кавычки, в то время как числовые значения допускается использовать без них.
Список столбцов col_name, размещенный после имени таблицы, позволяет изменить порядок следования столбцов при добавлении.

Как видно из листинга 6.2, порядок следования столбцов был изменен, сначала было добавлено название раздела name и лишь затем первичный ключ таблицы id_catalog. Следует помнить, что первичный ключ таблицы является уникальным значением и добавление уже существующего значения приведет к ошибке (листинг 6.3).

Если необходимо, чтобы новые записи с дублирующим ключом отбрасывались без генерации ошибки, нужно добавить после оператора insert ключевое слово IGNORE.
Листинг 6.4. Использование ключевого слова IGNORE.

Как видно из листинга 6.4, генерации ошибки не происходит, тем не менее новая запись также не добавляется.
При добавлении новой записи с уникальными индексами выбор такого уникального значения может быть непростой задачей. Для того чтобы не осуществлять дополнительный запрос, направленный на выявление максимального значения первичного ключа для генерации нового уникального значения, в MySQL введен механизм его стоматической генерации. Для этого достаточно снабдить первичный ключ --_catalog атрибутом auto_increment (см. главу 5). Тогда при создании новой записи з качестве значения id__catalog достаточно передать null или 0 — поле автоматически получит значение, равное максимальному значению столбца id_cataiog, плюс единица (листинг 6.5).

При вставке оператором insert не обязательно указывать все столбцы. Те столбцы, которые не указаны в списке, получат значение по умолчанию. Так, в листинге 6.6 значение id_catalog не передается оператору insert.


Так как id_catalog по умолчанию принимает значение null, которое вызывает механизм auto_increment, то поле id_catalog автоматически получает значение 5 (максимальное значение 4 плюс 1). Допускается добавление полностью пустых строк, это продемонстрировано в листинге 6.7

Так как текстовое поле name по умолчанию принимает пустую строку, новая запись содержит пустую запись. Значение по умолчанию можно подставить, если передать в качестве значения ключевое слово default (листинг 6.8).

Часто в прикладных программах требуется узнать значение, присвоенное столбцу и снабженное атрибутом auto_increment. Это может потребоваться для того, чтобы использовать сгенерированное значение первичного ключа в качестве вторичного в другой таблице или для каких-то других целей. Только что сгенерированное значение возвращает встроенная функция MySQL last_insert_id(), как это показано в листинге 6.9.

Например, если необходимо, чтобы следующее значение поля id_catalog приняло значение 16, а не 7, можно воспользоваться запросом, представленным в листинге 6.10

Кроме констант, в списке значений expression могут выступать выражения с участием столбцов из списка col_name.

Так, в листинге 6.11 для первой записи поле id_catalog принимает значение 6, а поле name значение 21 (7x3). Ссылаться в выражении можно только на столбцы, расположенные левее, ссылка на правые столбцы дает 0 (в случае столбца id_catalog это ( привело к автоматической генерации нового уникального значения 16 вместо ожидаемых 21).


Если при вставке нового значения задействован механизм auto_increment, to воспользоваться вновь сгенерированным значением не удастся (листинг 6.12), так сначала полю id_catalog присваивается значение 0, и лишь после того, как запись добавлена — генерируется новое значение.
Еще одной формой оператора insert является синтаксис с ключевым словом set
INSERT [INTO] tbl SET col_name=expr, ...
Оператор заносит в таблицу tbi новую запись, столбец coi_name в котором получает значение ехрr.

Запрос в листинге 6.13 аналогичен запросу в листинге 6.14

Форма оператора insert с ключевым словом set позволяет более гибко добавлять записи. Если имя столбца после set не встречается, полю присваивается значение по умолчанию.
Многострочный оператор INSERT
Многострочный оператор insert совпадает по форме с однострочным оператором. В нем используется ключевое слово values, после которого добавляется не один, а несколько списков expression. Так, в листинге 6.15 добавляется сразу пять записей при помощи одного оператора insert.


Точно так же, как и в случае однострочного варианта, допускается изменять порядок и состав списка добавляемых значений.

Пакетная загрузка данных
Для пакетной загрузки данных из текстового файла в таблицу в СУБД MySQL предназначен специальный оператор load data. Данный оператор работает быстрее, чем оператор insert, т. к. СУБД не требуется дополнительного времени на анализ синтаксиса оператора. Оператор имеет следующий синтаксис:
LOAD DATA [LOCAL] INFILE 'filename' INTO TABLE tbl
Если задано необязательное ключевое слово local, to файл читается с клиентского хоста. Если же local не указывается, то файл должен находиться на сервере.

Поля базы данных должны быть разделены символом табуляции. Тогда выполнение запроса, представленного в листинге 6.17, приводит к заполнению базы таблицы catalogs.


Перед конструкцией into table можно разместить одно из двух ключевых слов, которые управляют обработкой ситуации, когда данные из текстового файла дублируют : значения первичного или уникальных ключей:

Загрузка данных при помощи оператора load data без использования ключевых слов I shore и replace приведет к сообщению об ошибке (листинг 6.18). Однако использование оператора replace приводит к полной замене содержимого таблицы catalogs.


Ключевое слово ignore number lines позволяет задать количество number строк, которые необходимо пропустить от начала файла. Эта конструкция используется для того, чтобы пропустить заголовки столбцов, часто располагаемых на первой строке текстового файла (листинг 6.19).

Кроме базового синтаксиса, оператор load data допускает дополнительные опции, позволяющие задать формат файла данных. Это осуществляется при помощи следующих ключевых слов:

Ключевое слово lines позволяет задать символ начала и конца строки при помощи конструкций starting by и terminated by соответственно. Так, по умолчанию строка в текстовом файле должна заканчиваться символом перевода строки \п. Однако при создании текстовых файлов в среде Windows строка заканчивается двумя символами \г\п, что может приводить к неправильной интерпретации файла данных и потере информации. При помощи конструкции terminated by можно переопределить символ конца строки. Представленный в листинге 6.20 SQL-запрос при использовании его в операционной системе Windows может выглядеть следующим образом.

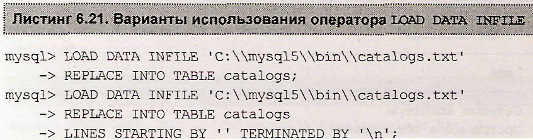
По умолчанию в качестве начальной строки задается пустая строка, таким образом, запросы в листинге 6.21 идентичны.
Ключевое слово fields позволяет задать порядок обработки полей, совместно с ним применяются следующие конструкции:

Запросы, представленные в листинге 6.22, идентичны.

Пусть формат текстового файла данных таков, что поля разделены запятыми, значения обрамлены двойными кавычками, а строки заканчиваются символом \r\n (Windows стиль).

Тогда запрос, загружающий данные из такого файла, может выглядеть так, как это представлено в листинге 6.23.

Удаление данных
Время от времени возникает задача удаления записей из базы данных, например, комплектующие могут устаревать и быть снятыми с производства. Для того чтобы отразить этот факт в учебной базе данных, необходимо удалить соответствующую запись в таблице products.
Для удаления записей из таблиц предусмотрено два оператора:
- DELETE
- TRUNCATE TABLE
Оператор DELETE
Оператор delete имеет следующий синтаксис:
DELETE FROM tbl
WHERE where_definition
Order by ...
LIMIT rows
Оператор удаляет из таблицы tbl записи, удовлетворяющие условию where_definition. В листинге 8.1 из таблицы catalogs удаляются записи, имеющие значение первичного ключа id_catalog больше двух.
Листинг 8.1. Удаление записей из таблицы catalogs
mysql> DELETE FROM catalogs WHERE id_catalog > 2;
mysql> SELECT * FROM catalogs;
+ +
id_catalog I name I
+ +
2 |Материнские платы
1 | Процессоры |
Если в операторе delete отсутствует условие where, из таблицы удаляются все запросы.

Применение ограничения limit позволяет задать максимальное число записей, котрые могут быть уничтожены. В листинге 8.3 удаляются все записи таблицы orders, но не более 3 записей
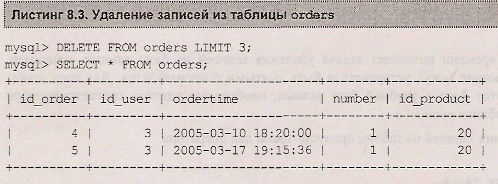
Так как таблица содержит 5 записей, то в результате в таблице остаются две записи. Инструкция order by обычно применяется совместно с ключевым словом limit. Например, если необходимо удалить 20 первых записей таблицы, то производится сортировка по полю datetime — это гарантирует, что удаляться будут в первую очередь самые старые таблицы.
Оператор TRUNCATE TABLE
Оператор truncate table, в отличие от оператора delete, полностью очищает таблицу и не допускает условного удаления. То есть оператор truncate table аналогичен оператору delete без условия where и ограничения limit. В отличие от оператора delete, удаление происходит гораздо быстрее, т. к. осуществляется не перебор каждой записи, а полное очищение таблицы.

Обновление данных
Операция обновления позволяет менять значения полей в уже существующих записях, это может понадобиться при изменении цен комплектующих, их количества на складе и т. д. Для обновления данных предназначены операторы update и replace. Первый позволяет обновлять отдельные поля в уже существующих записях, тогда как оператор replace больше похож на insert, за исключением того, что если старая запись в данной таблице имеет то же значение индекса unique или primary key, что и новая, то старая запись перед занесением новой будет удалена.
Оператор UPDATE
Оператор update имеет следующий синтаксис:

В инструкции, сразу после ключевого слова update, указывается таблица tbl, которая подвергается изменению. В предложении set указывается, какие столбцы подвергаются обновлению и устанавливаются их новые значения. Необязательное условие WHere позволяет задать критерий отбора строк— обновлению будут подвергаться только те строки, которые удовлетворяют условию where_definition.
В листинге 9.1 запись в таблице catalogs "Процессоры" изменяется на "Процессоры (Intel)".


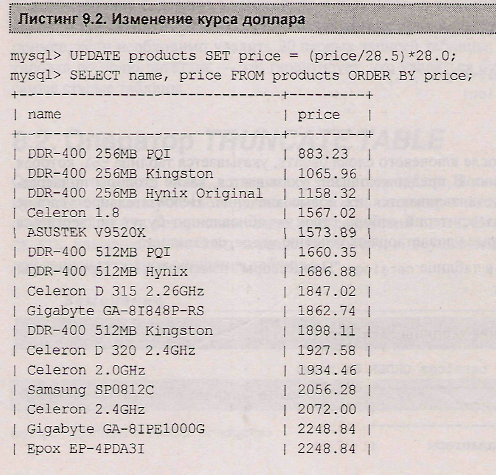
Изменения можно производить не только над выборочными записями, но и над всей таблицей в целом. Пусть требуется изменить цену комплектующих в учебной базе данных в связи с изменением курса доллара. Для этого следует разделить цену в рублях на старый курс (28.5), чтобы получить цену в долларах, и умножить результат на новый курс (28.0).
Если указывается необязательное ключевое слово ignore, to команда обновления не будет прервана, даже если при обновлении возникнет ошибка дублирования ключей. Строки, из-за которых возникают конфликтные ситуации, обновлены не будут.
Оператор REPLACE
Оператор replace работает точно так же, как insert, за исключением того, что если старая запись в данной таблице имеет то же значение индекса unique или primary key, что и новая, то старая запись перед занесением новой будет удалена. Следует учитывать, что если не используются индексы unique или primary key, то применение команды replace не имеет смысла, т. к. она работает просто как insert.
Синтаксис оператора rename аналогичен синтаксису оператора insert:
![]()
В таблицу tbl вставляются значения, определяемые в списке после ключевого слова VAlues. Задать порядок столбцов можно при помощи необязательного списка col_name, следующего за именем таблицы tbl. Точно так же, как и в случае оператора insert, оператор replace допускает многострочный формат. Пример использования оператора приведен в листинге 9.5, где в таблицу catalogs добавляется пять новых записей.

