

Рассмотрим пример неархаического алгоритма на основе k-means. Общее представления алгоритма k-means
Шаг 0 выбор k производных исходных центров представляющие собой точки в пространстве исследуемых данных. Выбор этих центров некритичен и отражается лишь на время работы алгоритма.
Шаг 1. Разделения все объектов исследуемой выборки на k-групп наиболее близких к соответствующим выбранным центрам. Для определения меры близости. используется расстояние.
Шаг 2. Вычисление новых центров кластера для сформированных k групп. Способ определения центра кластера устанавливается аналитиком.
Шаг 3. Повторения 1,2 шага пока оценки кластеров не перестанут меняться. Для подобных алгоритмов наилучшими условиями применения будет представления исследуемой выборки как набора компактных примерно сферических групп, однако такое представление может позволят решить задачу кластеризации методами визуального анализа не прибегая к вычислению. Для повышения эффективности алгоритма и ему подобных следует рассмотреть формальное представление базовых понятий M={mj}j=1d
Вектор центров
кластеров C
 .
.
Матрица растояния
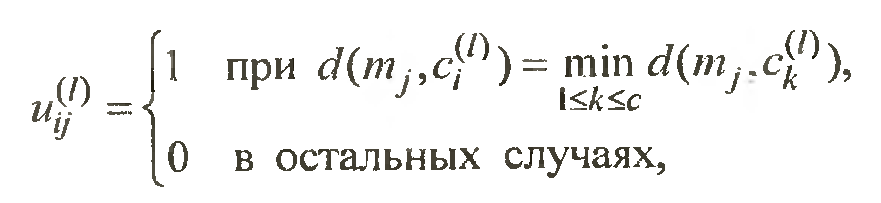 .
.
Целевая функция
![]()
набор ограничений
![]()
14 Лекция
Конструктивно алгоритм представляет собой итерационную процедуру следующего вида.
Шаг 1 Выбрать параметр точности δ Определяющие условие завершения алгоритма, принять номер итерации l=1
Шаг 2 определить центры кластеров по следующей формуле
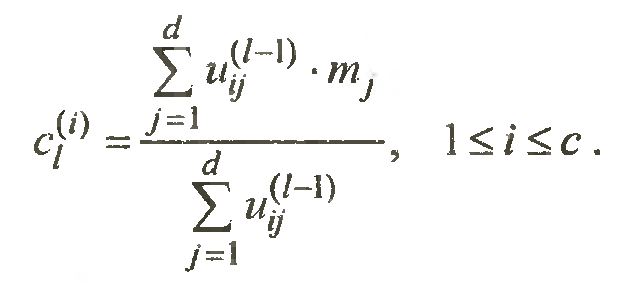
Шаг 3 пересчитать матрицу разбиении что бы минимизировать квадраты ошибок, для пересчета матрицы разбиения используется следующая формула
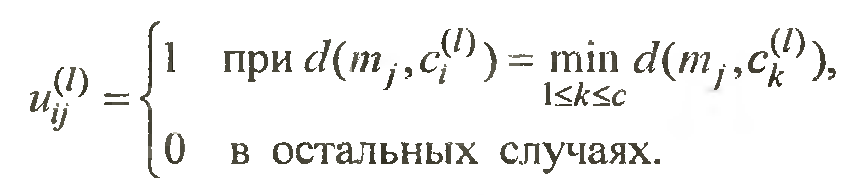
Шаг 4 проверить условия следующего вида:
![]()
Если условия выполняется то завершить алгоритм. В противном случаи перейти к шагу 2 приняв номер итерации l=l+1.
Главным недостатком данного алгоритма являться большой размер пространства разбиения, причиной этого недостатка является дискретность матрицы разбиения, для устранения этого недостатка вводиться понятие нечеткой принадлежности, данной понятие определяет принадлежность объекта к кластеров в виде некоторой функции с диапазоном значением 0…1. На основе данной функции реализован алгоритм Fuzzy C-means(файл Fuzzy C-means.pdf).
Визуальный анализ данных
Основной идей визуального анализа данных или Visual Mining является представление данных в некоторой визуально форме позволяющее аналитику погрузиться в данные работать с их нем визуальным представлением понять суть данных, сделать аналитические выводы и на прямую взаимодействовать с данными. В общем случаи визуальный анализ представляется как процесс генерации аналитикам гипотез эти гипотезы проверяются методом визуального анализа, методами интеллектуального анализа или методами статистического анализа.
Основные достоинства Visual Mining :
- лёгкость работы с неоднородными то есть с зашумленными данными;
- интуитивная понятность и отсутствие необходимости в сложных алгоритмах. Главная проблема как перейти к многомерному хранения к 2 или 3 мерного.
- высокая степень конфиденциальности результатов.
Базовые этапы визуального анализа:
Беглый анализ позволяющей выявить интересные шаблоны и сосредоточиться на одном или несколько из них
Увеличение и фильтрация. Выделанные на первом этапе шаблоны отфильтровуються и уточняются при различном увеличении масштаба.
Детализация по необходимости. На этом этапе возмодно отобразить более детальные данные если аналитик нуждается в дополнительной информации.
Основные характеристики методов визульаного анализа:
- характер визуализируемых данных
- методы визуализации и образы в виде которых могут быть представленные данные
- возможности взаимодействия с визуальными образами и методами.
Данные по своему характеру могут разделяться на следующие виды:
Одномерные данные;
Двумерные данные;
Многомерные данные, например результаты экспериментов;
Тексты и гиппер тексты;
Иерархические и связанные данные;
Алгоритмы и программы
По методами визуализация выделяющие следующие инструменты:
- стандартные 2D/3D образы;
- геометрические преобразование;
- отображение иконок;
- методы ориентированные по пикселю;
- иерархические образы;
- группа операций взаимодействия аналитика с визуальными образами.
- интерактивная фильтрация;
- масштабирования образов;
- интерактивное искажение;
- интерактивное комбинирование;
Перечень методов визуального анализа:
- методы стандартных методами 2D/3D образом, это есть графиками диаграмм гистограмма
Недостаток: невозможность приемлемой визуализации в сложных данных и больших данных
- группа методов геометрических преобразование: точки и матрицы, гиппер поля, поверхностные и объемные графики или контуры, метод параллельных координат, текстуры и растры,
- методы основанные работы с иконками: линейчие фигуры, лица Чернога, цветные иконки, грифы(наборы пиксели отображающие на 2D площадке)
- методы ориентированные на пиксели: метод заполнения пространства, рекурсивные шаблоны, мозаика
- методы использующие иерархические образы: метод наложения измерения, методы основанные на деревьях. При работе с древовидными картами должны соблюдаться следующие свойства:
1. если узел м1 является предком узла м2 то граничный прямоугольным м1 целиком окружает прямоугольным м2
2. ограниченные прямоугольники двух узлом пересекаются если один узел является предком другого
3. узлы занимают площадь пропорционально их весу
4. вес узла больше или равен сумме весов узлом его наследников