

BФедеральное агентство по образованию
Уральский государственный технический университет-УПИ
Имени первого Президента России Б. Н. Ельцина
Интеллектуальные информационные системы
Методические указания к выполнению лабораторных работ
для студентов всех форм и технологий обучения специальностей
Екатеринбург
УГТУ-УПИ
2010
УДК 681.3
Составители: Потанин Н.И.
Научный редактор д-р физ.-мат. наук проф.
Интеллектуальные информационные системы : методические указания к выполнению лабораторных работ для студентов специальностей
сост. Н.И. Потанин. Екатеринбург : УГТУ-УПИ, 2010. 74 с.
В методических указаниях приводится пример решения задачи с помощью пакета Квазар. Приведен порядок решения задачи в пакетах Квазар. Квазар: подготовка данных, ввод и проверка данных, решение задачи таксономии, задачи информативности признаков, задачи дискриминатнтного анализа.
Библиогр.: 4 назв. Рис. 48.
Подготовлено кафедрой информационных систем и технологий ИОИТ.
ООО УГТУ-УПИ, 2010
Терминология и задачи распознавания образов
Квазар
Пакет КВАЗАР является самостоятельным программным средством, предназначенным в основном для решения задач распознавания образов:
задачи классификации на основе обучения по прецедентам;
задачи таксономии;
3) задачи выбора информативной подсистемы признаков из заданной системы описания объектов.
Кроме того, с помощью пакета можно решать задачи:
формирования обучающей и проверочной выборок с целью последующего использования их при решении задачи обучения по прецедентам.
Стандартная модель входных данных РО
Как известно, методы распознавания образов и многомерной статистики обычно работают с множествами объектов (ситуаций, явлений, процессов), информация о которых задается в виде значений некоторого фиксированного набора признаков. Таким образом, исходными данными для пакета является множество векторов
![]()
Здесь![]() —
число векторов,
—
число векторов,
![]() —
число признаков,
—
число признаков,![]() —
—
![]() вектор
(
вектор
(![]() -е
наблюдение). Или, иначе говоря, на вход
пакета подается матрица типа
«объект-признак» следующего
вида:
-е
наблюдение). Или, иначе говоря, на вход
пакета подается матрица типа
«объект-признак» следующего
вида:
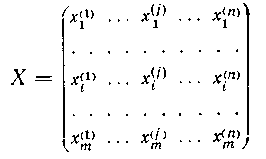
Здесь
![]() -я
строка представляет собой
-я
строка представляет собой
![]() -е
наблюдение, а
-е
наблюдение, а![]() -й
столбец образован значениями, которые
принимает
-й
столбец образован значениями, которые
принимает![]() -й
признак в различных наблюдениях.
-й
признак в различных наблюдениях.
В основном пакет КВАЗАР работает с данными в виде векторов, координатами которых могут быть произвольные вещественные и lдвоичные числа.
Как правило, данные первого типа перед обработкой подвергаются преобразованию, которое заключается в нормировании значений признаков по следующему правилу:
![]()
где![]() —
минимальное значение
—
минимальное значение![]() -го
признака,
-го
признака,![]() —
разность
между максимальным и минимальным
значениями
—
разность
между максимальным и минимальным
значениями
![]() -го
признака,
-го
признака,
![]() —
величина, выражающая значения
—
величина, выражающая значения![]() -го
признака
-го
признака
![]() -го
вектора до и после нормирования,
-го
вектора до и после нормирования,
![]() —
знак присваивания значения.
—
знак присваивания значения.
Нормирование позволяет избавиться от априорной неравнозначности признаков, обусловленной наличием у каждого признака своего интервала принимаемых им значений.
Задача классификации на основе обучения по прецедентам. Задача обучения с учителем
Пусть
известны
![]() классов
объектов
классов
объектов
![]() ,
которые
в заданном множестве
,
которые
в заданном множестве
![]() представлены
конечными
подмножествами
представлены
конечными
подмножествами
![]() векторов,
моделирующих
соответствующие объекты из указанных
классов;
при этом
векторов,
моделирующих
соответствующие объекты из указанных
классов;
при этом![]() .
.
Необходимо
найти правило,
с помощью которого можно было бы
достаточно надежно
классифицировать объекты (векторы) из
классов![]() .
.
Критерием качества искомого решающего правила часто служит процент правильно распознанных с его помощью векторов проверочной выборки. В пакете КВАЗАР проверочная выборка представляет собой часть векторов множества X, не участвующих в обучении.

Рис.
1.1. Пример линейного разделения двух
множеств
![]() на
плоскости
на
плоскости
На
рис. 1.1 представлен пример построения
линейной разделяющей функции в![]() для
случая двух классов (
для
случая двух классов (![]() и
и
![]() ).
Однако задача дискриминантного анализа
не так проста, как это может показаться.
Основные трудности при решении большинства
практических задач
состоят в том, что приходится иметь дело
с множествами
векторов, размерность которых значительно
больше
двух. Кроме того, обучающие множества
обычно не
являются линейно разделимыми, и поэтому,
как правило,
приходится применять методы построения
разделяющих
поверхностей сложной формы.
).
Однако задача дискриминантного анализа
не так проста, как это может показаться.
Основные трудности при решении большинства
практических задач
состоят в том, что приходится иметь дело
с множествами
векторов, размерность которых значительно
больше
двух. Кроме того, обучающие множества
обычно не
являются линейно разделимыми, и поэтому,
как правило,
приходится применять методы построения
разделяющих
поверхностей сложной формы.
Уточним здесь, какой смысл при работе с пакетом КВАЗАР вкладывается в понятие «решающее правило». Решающее правило можно определить как некоторым образом организованную совокупность числовых данных, получаемую обычно в процессе обучения и сравнительно несложную последовательность операций, приводящих к классификации предъявленного вектора на основе использования этой совокупности данных.
Например,
в случае линейного разделения двух
множеств в
![]() это
может быть вектор коэффициентов
разделяющей
гиперплоскости и алгоритм, который
сначала вычисляет скалярное
произведение данного вектора с
распознаваемым,
а затем анализирует знак полученного
скалярного произведения и выдает
результат классификации.
Последовательность операций, приводящая
к классификации вектора, обусловливает
класс распознающих
алгоритмов, а совокупность числовых
данных определяет
конкретный алгоритм распознавания.
Учитывая это и полагая последовательность
операций, используемых
при классификации, в рамках того или
иного
метода (подхода) некоторой постоянной
составляющей,
будем в дальнейшем под решающим правилом
упрощенно
понимать только соответствующую
совокупность
числовых данных. Часто, как отмечалось,
эти данные
представляют собой результат решения
задачи обучения и описывают границу,
разделяющую классы. Однако
в рамках некоторых подходов классификация
может
производиться без предварительного
построения разделяющих
границ в явном виде. В качестве решающего
правила, т. е. совокупности числовых
данных, определяющих
конкретный распознающий алгоритм, в
таких случаях используются непосредственно
векторы обучающей выборки. В качестве
примера здесь можно назвать
задачу классификации на основе
метода
это
может быть вектор коэффициентов
разделяющей
гиперплоскости и алгоритм, который
сначала вычисляет скалярное
произведение данного вектора с
распознаваемым,
а затем анализирует знак полученного
скалярного произведения и выдает
результат классификации.
Последовательность операций, приводящая
к классификации вектора, обусловливает
класс распознающих
алгоритмов, а совокупность числовых
данных определяет
конкретный алгоритм распознавания.
Учитывая это и полагая последовательность
операций, используемых
при классификации, в рамках того или
иного
метода (подхода) некоторой постоянной
составляющей,
будем в дальнейшем под решающим правилом
упрощенно
понимать только соответствующую
совокупность
числовых данных. Часто, как отмечалось,
эти данные
представляют собой результат решения
задачи обучения и описывают границу,
разделяющую классы. Однако
в рамках некоторых подходов классификация
может
производиться без предварительного
построения разделяющих
границ в явном виде. В качестве решающего
правила, т. е. совокупности числовых
данных, определяющих
конкретный распознающий алгоритм, в
таких случаях используются непосредственно
векторы обучающей выборки. В качестве
примера здесь можно назвать
задачу классификации на основе
метода![]() ближайших
соседей.
ближайших
соседей.
Для решения задачи в пакете используются четыре алгоритма:
алгоритм классификации с использованием однородных комитетов большинства ;
алгоритм классификации с использованием комитетов старшинства ;
3) рекуррентный алгоритм линейного разделения выпуклых оболочек двух множеств ;
алгоритм классификации на основе метода потенциальных функций.
Алгоритмы реализованы в пакете в виде отдельных программных модулей. Модули в основном однотипны и предназначены для выполнения следующих операций:
а) построение решающего правила (обучение);
б) оценка качества решающего правила;
в) рабочее распознавание;
г) запоминание решающего правила во внешней памяти ЭВМ.
При обращении к какому-нибудь из этих модулей в обязательном порядке выполняется только первая операция — построение решающего правила, необходимость выполнения остальных операций определяется конкретным заданием пользователя.
В дальнейшем, говоря о каком-либо из перечисленных алгоритмов, будем иметь в виду соответствующий программный модуль со всеми его возможностями.
В общих чертах характеризуя реализованные в пакете алгоритмы обучения по прецедентам, можно отметить следующее. Первый и третий алгоритмы предназначены для решения задачи при наличии двух разделяемых классов; другие алгоритмы могут работать с числом классов от двух до двадцати пяти.
Первый алгоритм позволяет получить несколько различных решающих правил, безошибочно классифицирующих материал обучения (при условии, что нет одинаковых векторов в обучающих выборках разных классов).
Четвертый алгоритм предназначен для линейного разделения классов, если такое разделение возможно. В случае пересечения выпуклых оболочек обучающих подмножеств пользователю выдается соответствующее сообщение.
Первые четыре алгоритма могут работать как с контролем качества решающего правила по проверочной выборке, так и без такого контроля. Обучение без контроля является, конечно, вынужденным режимом, и применять его следует лишь в крайних случаях, при работе с очень малым числом векторов.
Интересно также отметить, что решающие правила, получаемые с помощью первого и третьего алгоритмов, позволяют не только классифицировать объект, но и дать количественную оценку степени его принадлежности соответствующему классу. Делается это путем вычисления так называемого индекса принадлежности.
Решающие правила, как уже сказано выше, могут быть использованы для классификации как непосредственно после их построения, так и при последующих обращениях к пакету. В пакете имеется специальный программный модуль, обеспечивающий классификацию векторов с помощью ранее полученных решающих правил