

Анализ предметной области: описание предметной области, выявление ограничений целостности, определение статуса (доступности, секретности) информации, определение потребностей пользователей, определение соответствия «данные—пользователь», определение объемно-временных характеристик обработки данных.
Проектирование структуры БД: определение состава и структуры файлов БД и связей между ними, выбор методов упорядочения данных и методов доступа к информации, описание БД на языке описания данных (ЯОД).
Задание ограничений целостности при описании структуры бд и процедур обработки бд:
задание декларативных ограничений целостности, присущих предметной области;
определение динамических ограничений целостности, присущих предметной области в процессе изменения информации, хранящейся в БД;
определение ограничений целостности, вызванных структурой БД;
разработка процедур обеспечения целостности БД при вводе и корректировке данных;
определение ограничений целостности при параллельной работе пользователей в многопользовательском режиме.
Первоначальная загрузка и ведение бд:
разработка технологии первоначальной загрузки БД, которая будет отличаться от процедуры модификации и дополнения данными при штатном использовании базы данных;
разработка технологии проверки соответствия введенных данных реальному состоянию предметной области. База данных моделирует реальные объекты некоторой предметной области и взаимосвязи между ними, и на момент начала штатной эксплуатации эта модель должна полностью соответствовать состоянию объектов предметной области на данный момент времени;
в соответствии с разработанной технологией первоначальной загрузки может понадобиться проектирование системы первоначального ввода данных.
Защита данных:
определение системы паролей, принципов регистрации пользователей, создание групп пользователей, обладающих одинаковыми правами доступа к данным;
разработка принципов защиты конкретных данных и объектов проектирования; разработка специализированных методов кодирования информации при ее циркуляции в локальной и глобальной информационных сетях;
разработка средств фиксации доступа к данным и попыток нарушения системы защиты;
тестирование системы защиты;
исследование случаев нарушения системы защиты и развитие динамических методов защиты информации в БД.
Обеспечение восстановления БД:
разработка организационных средств архивирования и принципов восстановления БД;
разработка дополнительных программных средств и технологических процессов восстановления БД после сбоев.
Анализ обращений пользователей БД: сбор статистики по характеру запросов, по времени их выполнения, по требуемым выходным документам
Анализ эффективности функционирования БД:
анализ показателей функционирования БД;
планирование реструктуризации (изменение структуры) БД и реорганизации БнД.
Работа с конечными пользователями:
сбор информации об изменении предметной области;
сбор информации об оценке работы БД;
обучение пользователей, консультирование пользователей;
разработка необходимой методической и учебной документации по работе конечных пользователей.
Подготовка и поддержание системных средств:
анализ существующих на рынке программных средств и анализ возможности и необходимости их использования в рамках БД;
разработка требуемых организационных и программно-технических мероприятий по развитию БД;
проверка работоспособности закупаемых программных средств перед подключением их к БД;
курирование подключения новых программных средств к БД.
11. Организационно-методическая работа по проектированию БД:
выбор или создание методики проектирования БД;
определение целей и направления развития системы в целом;
планирование этапов развития БД;
разработка общих словарей-справочников проекта БД и концептуальной модели;
стыковка внешних моделей разрабатываемых приложений;
курирование подключения нового приложения к действующей БД;
обеспечение возможности комплексной отладки множества приложений, взаимодействующих с одной БД.
4)Предметная область. Проектирование инфологической модели
Инфологическая модель представляет собой описание предметной области, основанное на анализе семантики объектов и явлений, выполненное без ориентации на использование в дальнейшем программных или технических компьютерных средств. Инфологическое проектирование - сбор, анализ и редактирование требований к данным. Для этого осуществляются следующие мероприятия:
обследование предметной области, изучение ее информационной структуры
выявление всех фрагментов, каждый из которых харакетризуется пользовательским представлением, информационными объектами и связями между ними, процессами над информационными объектами
моделирование и интеграция всех представлений
сущности
атрибуты представление аналитика
связи
По окончании данного этапа получаем концептуальную модель, инвариантную к структуре базы данных. Часто она представляется в виде модели "сущность-связь".
Основные элементы данного этапа:
Описание объектов предметной области и связей между ними;
Описание информационных потребностей пользователей (описание основных запросов к БД);
Описание алгоритмических зависимостей между данными;
Описание ограничений целостности, т.е. требований к допустимым значениям данных и к связям между ними.
Исследование предметной области необходимо проводить в целом для разрабатываемой системы, частью которой является и БД. При этом модель данных может быть создана только в случае, если выявлены все объекты системы, логика их взаимодействия, потоки передаваемой информации. База данных является хранилищем передаваемых данных, которые используются системой при работе.
Создание системы необходимо начинать c исследования процессов, происходящих в предметной области и используемых ими данных. При этом очень важно определить рамки системы и перечень выполняемых ей функций. Подобный анализ желательно проводить с участием экспертов предметной области и консультантов. При этом работа сводится к поэтапному выделению объектов, значимых функций системы, информационных потоков и системы их взаимосвязей. Целью подобного исследования является выделение значимых функций для разрабатываемой системы, их согласование, описание в терминах понятных как разработчику, так и будущему пользователю. На этом этапе важно понять смысловое значение данных, обрабатываемых в системе, отделить ключевые понятия предметной области от маловажных и вообще несущественных для рассматриваемого случая. Очень важно на этапе проектирования достичь взаимопонимания как между разработчиками системы, так и между экспертами предметной области, заказчиками и т.д., так как каждый имеет свое видение проекта.
Инфологическая модель создается по результатам проведения исследований предметной области. Инфологическая модель представляет собой описание будущей базы данных, представленное с помощью естественного языка, формул, графиков, диаграмм, таблиц и других средств, понятных как разработчикам БД, так и обычным пользователям. Назначение такой модели состоит в адекватном описании процессов, информационных потоков, функций системы с помощью общедоступного и понятного языка, что делает возможным привлечение экспертов предметной области, консультантов, пользователей для обсуждения модели и внесения исправлений. В данном случае под созданием инфологической модели будем понимать именно ее создание для БД. В общем случае, инфологическая модель может создаваться для любой проектируемой системы и представляет ее описание (в общем случае в произвольной форме).
Создание инфологической модели является естественным продолжением исследований предметной области, но в отличие от него является представлением БД с точки зрения проектировщика (разработчика). Наглядность представления такой модели позволяет экспертам предметной области оценить ее точность и внести исправления. От правильности модели зависит успех дальнейшей разработки.
5)Концептуальная модель
Концептуальная (содержательная) модель — это абстрактная модель, определяющая структуру моделируемой системы, свойства её элементов и причинно-следственные связи, присущие системе и существенные для достижения цели моделирования.
Построение концептуальной модели включает следующие этапы:
1) определение типа системы;
2) описание внешних воздействий;
3) декомпозиция системы.
Выделяют три вида концептуальных моделей: логико-семантические, структурно-функциональные и причинно-следственные.
Логико-семантическая модель – описание объекта в терминах соответствующих предметных областей знаний. Анализ таких моделей осуществляется средствами логики с привлечением специальных знаний.
При построении структурно-функциональной модели объект рассматривается как целостная система, которую расчленяют на отдельные подсистемы или элементы. Части системы связывают структурными отношениями, описывающими подчиненность, логическую и временную последовательность решения задач.
Причинно-следственная модель служит для объяснения и прогнозирования поведения объекта. Такие модели ориентированы на следующие моменты: 1) выявление главных взаимосвязей между подсистемами; 2) выявление определенного влияния различных факторов на состояние объекта; 3) описание динамики интересующих разработчика параметров.
Формальная модель является представлением концептуальной модели с помощью формальных языков. К таким языкам относятся математический аппарат, алгоритмические языки, языки моделирования.
Определение концептуальной модели.
Определение границ системы. На первом шаге в концептуальной модели обычно в словесной форме приводятся сведения о природе и параметрах (характеристиках) элементарных явлений исследуемой системы, о виде и степени взаимодействия между ними, о месте и значении каждого элементарного явления в процессе функционирования системы. Две функциональные границы:
граница, отделяющая проблему от всего остального мира;
граница между системой и окружающей средой.
Следующим шагом на пути создания концептуальной модели служит выбор уровня детализации модели (стратификация). Модель системы представляется в виде совокупности частей (подсистем, элементов). В эту совокупность включаются все части, которые Mining – это в ближайшем будущем основной источник достоверных данных для исследования сложных социотехнических систем. Здесь существует две альтернативы:
использование данных непосредственно.
(Главный путь) Использование теоретико-вероятностных или частотных распределений. Очевидно, что значительная часть параметров системы - это случайные величины. Особое значение имеет обоснование выбора адекватных законов распределения случайных величин, аппроксимация функций и т.д. COMOD технология, выявление закономерностей.
Этот выбор имеет фундаментальное значение по двум причинам:
1) При использовании необработанных данных вы можете имитировать только прошлое: возможными будут только те события, которые уже случались, нет особенностей функционирования системы в будущем. Если объект статичен или цикличен это одно, а если нет!!! А одна из важнейших функций имитационной модели – прогноз.
2) Обязательно необходимы испытания на чувствительность выходных значений параметров модели к изменению используемых вероятностных распределений и табличных входных данных.
Экспертные оценки. Когда нет достоверных экспериментальных и эмпирических данных (нет БД, новый объект), приходится полагаться на субъективные оценки.
В таких случаях важно полагаться на мнение коллектива экспертов, а не одного лица. Знание моделируемого процесса и по возможности облеченных правом принятия решений.
Для выявления индивидуальных точек зрения и формирование единого мнения существует несколько методов. Одним из наиболее полезных методов является метод
6)Функции регистратур InterNet на примере раздачи IP-адресов InterNet.
Раздача IP-адресов осуществляется регистратурами.

Пример получения IP-адресов KSTU (до смены адресов в 2004г.)
Основные понятия:
IANA - The Internet Assigned Numbers Authority (Управление назначением адресов в Internet) - организация, осуществляющая контроль за распределением всего пространства Internet адресов, включая IP-адреса. IANA выделяет адресное пространство Региональным регистратурам в соответствии с их потребностями. Сервер http://www.iana.org/ .
Главная база данных, по сетям, поддерживается Регистрационной службой Интернет (InterNIC - www.internic.net). Базу можно посмотреть по адресу rs.internic.net и whois.internic.net.
Через WWW-интерфейс http://www.internic.net/whois.html
RIR - Regional Internet Registry (Региональная регистратура Internet) - организация, занимающаяся распределением адресного пространства в пределах одного из 4-х регионов (Северная Америка, Латинская Америка, Европа, Азия). Региональные регистратуры осуществляют координацию деятельности Локальных регистратур.
Северная Америка и Африка ниже экватора - поддерживается ARIN (American Registry for Internet Numbers) http://www.arin.net/ .
Латинская Америка и Караибские острова - поддерживается LACNIC (Regional Latin-American and Caribbean IP Address Registry) http://lacnic.net/ .
Европа ближний восток, центральная Азия, Африка до экватора - база данных поддерживается RIPE Network Coordination Centre (RIPE NCC) http://www.ripe.net/.
Базу можно посмотреть по адресу whois.ripe.net.
Документы по регистрации можно посмотреть здесь http://www.ripe.net/ripe/docs/alltitle.html
Азия и Тихоокеанский регион - поддерживается APNIC (Asia Pacific Network Information Centre) http://www.apnic.net/ .
LIR - Local Internet Registries (Локальная регистратура Internet) - организация, занимающаяся распределением адресного пространства пользователям сетей (сервис-провайдерам и их абонентам) и оказанием сопутствующих регистрационных услуг. Как правило, Локальными регистратурами управляют крупные сервис-провайдеры и корпоративные сети.
LIR'ы делятся на: Extra largeLargeMediumSmallExtra small
Самая большая (Extra large) российская LIR - РосНИИРОС (Российский НИИ Развития Общественных Сетей) http://www.ripn.net . Полный список европейских LIR'ов, по странам, можно посмотреть по адресу http://www.ripe.net/lir/registries/indices/data/ .
ISP - Internet Service Provider (сервис-провайдер Internet) - поставщик услуг Internet.
End-user (конечный пользователь) - организация, которая использует выделенное ей адресное пространство для работы своих сетей и подключенная к сети Internet.
Экзаменационный билет № 19
Аппроксимация функций.
Архитектура информационных систем.
Пользователи банков данных.
Проектирование даталогической модели
Информационная модель. Основные способы сбора исходных данных. Метод Дэльфы
Четыре уровня модели TCP/IP стека.
1)Аппроксимация функций-замена одной ф-ции другой ф-цией. Состоящий в замене одних объектов другими, в том или ином смысле близкими к исходным, но более простыми.
Аппроксимацию называют точечной, если f(x) задана на конечном множестве точек (узлов) x0, x1, ... , xm.
Если f(x) задана на непрерывном множестве значений аргументов, то аппроксимацию называют интегральной.
2)Архитектура информационных систем.
Централизованная обработка данных: на одном компьютере установлены и функционируют средства пользовательского интерфейса, обеспечивающие интерактивный режим работы, программы приложений и файлы БД вместе с СУБД.
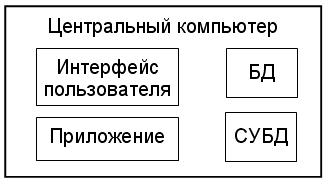
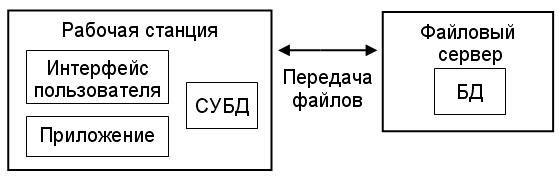
2. Файл-серверная распределенная обработка данных : на рабочей станции находятся средства пользовательского интерфейса, программы приложений и СУБД, а на сервере хранятся файлы БД. Вся обработка данных выполняется на рабочей станции.
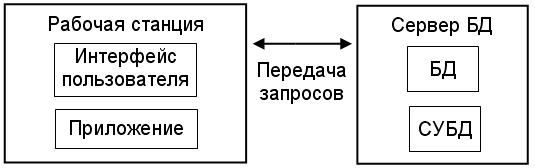
3. Клиент-серверная двухуровневая распределенная обработка данных : на рабочей станции находятся средства пользовательского интерфейса и программы приложений, на сервере БД хранятся СУБД и файлы БД. Рабочие станции (клиенты) посылают серверу запросы на данные, сервер выполняет извлечение и предварительную обработку данных.
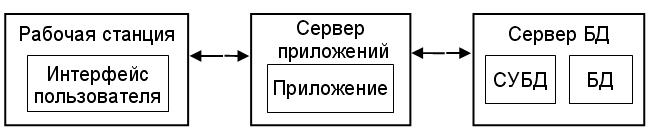
4. Клиент-серверная трехуровневая распределенная обработка данных : на рабочей станции находятся только средства пользовательского интерфейса, на сервере приложений – программы приложений, а на сервере БД хранятся СУБД и файлы БД. Вся логика обработки информации поддерживается на сервере приложений.
5. Клиент-серверная многоуровневая распределенная обработка данных: трехуровневая клиент-серверная архитектура при наличии в сети нескольких серверов приложений и серверов БД. Каждый сервер приложений, как правило, обслуживает потребности какой-либо одной функциональной подсистемы и располагается в головном для подсистемы структурном подразделении, например, сервер приложения по управлению сбытом – в отделе сбыта, сервер приложения по управлению снабжением – в отделе закупок и т.д.
Многоуровневая архитектура
Многоуровневая архитектура является развитием архитектуры клиент-сервер и в своей классической форме состоит из трех уровней:
1. нижний уровень представляет собой приложения клиентов, выделенные для выполнения функций и логики представления PS и PL и имеющие программный интерфейс для вызова приложения на среднем уровне;
2. средний уровень представляет собой сервер приложений, на котором выполняется прикладная логика BL и с которого логика обработки данных DL вызывает операции с БД DS ;
3. верхний уровень представляет собой специализированный сервер БД, выделенный для услуг обработки данных DS и файловых операций FS (без риска использования хранимых процедур).
Интернет/интранет-технологии
В развитии технологий Интернет/интранет основное внимание пока уделяется разработке инструментальных программных средств. При этом отсутствуют развитые средства разработки приложений, работающих с БД. Компромиссным решением для создания удобных и простых в использовании и сопровождении ИС, эффективно работающих с БД, стало объединение Интернет/интранет-технологии с многоуровневой архитектурой. При этом структура ИС приобретает следующий вид: браузер – сервер приложений – сервер БД – сервер динамических страниц – web -сервер.
Благодаря интеграции Интернет/интранет-технологий и архитектуры клиент-сервер процесс внедрения и сопровождения ИС существенно упрощается.
3)Пользователи банков данных.
Как любой программно-организационно-технический комплекс, банк данных существует во времени и в пространстве. Он имеет определенные стадии своего развития: 1.Проектирование. 2.Реализация. 3.Эксплуатация; 4.Модернизация и развитие. 5.Полная реорганизация.
На каждом этапе своего существования с банком данных связаны разные категории пользователей.
Определим основные категории пользователей и их роль в функционировании банка данных:
Конечные пользователи. Это основная категория пользователей, в интересах которых и создается банк данных. В зависимости от особенностей создаваемого банка данных круг его конечных пользователей может существенно различаться. Это могут быть случайные пользователи, обращающиеся к БД время от времени за получением некоторой информации, а могут быть регулярные пользователи. В качестве случайных пользователей могут рассматриваться, например, возможные клиенты вашей фирмы, просматривающие каталог вашей продукции или услуг с обобщенным или подробным описанием того и другого. Регулярными пользователями могут быть ваши сотрудники, работающие со специально разработанными для них программами, которые обеспечивают автоматизацию их деятельности при выполнении своих должностных обязанностей. Например, менеджер, планирующий работу сервисного отдела компьютерной фирмы, имеет в своем распоряжении программу, которая помогает ему планировать.и распределять текущие заказы, контролировать ход их выполнения, заказывать на складе необходимые комплектующие для новых заказов. Главный принцип состоит в том, что от конечных пользователей не должно требоваться каких-либо специальных знаний в области вычислительной техники и языковых средств.
Администраторы банка данных. Это группа пользователей, которая на начальной стадии разработки банка данных отвечает за его оптимальную организацию с точки зрения одновременной работы множества конечных пользователей, на стадии эксплуатации отвечает за корректность работы данного банка информации в многопользовательском режиме. На стадии развития и реорганизации эта группа пользователей отвечает за возможность корректной реорганизации банка без изменения или прекращения его текущей эксплуатации.
Разработчики и администраторы приложений. Это группа пользователей, которая функционирует во время проектирования, создания и реорганизации банка данных. Администраторы приложений координируют работу разработчиков при разработке конкретного приложения или группы приложений, объединенных в функциональную подсистему. Разработчики конкретных приложений работают с той частью информации из базы данных, которая требуется для конкретного приложения.
Не в каждом банке данных могут быть выделены все типы пользователей. Мы уже знаем, что при разработке информационных систем с использованием настольных СУБД администратор банка данных, администратор приложений и разработчик часто существовали в одном лице. Однако при построении современных сложных корпоративных баз данных, которые используются для автоматизации всех или большей части бизнес-процессов в крупной фирме или корпорации, могут существовать и группы администраторов приложений, и отделы разработчиков. Наиболее сложные обязанности возложены на группу администратора БД.
В составе группы администратора БД должны быть:
системные аналитики;
проектировщики структур данных и внешнего по отношению к банку данных информационного обеспечения;
проектировщики технологических процессов обработки данных;
системные и прикладные программисты;
операторы и специалисты по техническому обслуживанию.
4)Проектирование даталогической модели
Датологическое проектирование - преобразование требований к данным в структуры данных. На выходе получаем СУБД-ориентированную структуру базы данных и спецификации прикладных программ. На этом этапе часто моделируют базы данных применительно к различным СУБД и проводят сравнительный анализ моделей
записи
элементы данных представление программиста
связи между записями
Содержанием даталогического проектирования является определение модели данных. Модель данных - это набор соглашений по способам представления сущностей, связей, агрегатов, системы классификации.
Проектирование логической структуры предполагает:
· разбиение всей информации по отношениям (таблицам);
· определение состава полей (атрибутов) каждого отношения;
· определение ключа каждого отношения;
· определение связей и обеспечение целостности по связям.
Конечным результатом даталогического проектирования является' описание логической структуры базы данных..
Спроектировать логическую структуру базы данных означает определить все информационные единицы и связи между ними, задать их имена; если для информационных единиц возможно использование разных типов, то необходимо определить их тип. Следует также задать некоторые количественные характеристики, например длину поля.
Подход к даталогическому проектированию. Каждый тип модели данных и каждая разновидность модели, поддерживаемая конкретной СУБД, имеют свои специфические особенности. Вместе с тем имеется много общего во всех структурированных моделях данных и принципах проектирования БД в их среде. Все эта дает возможность использовать единый методологический подход к проектированию структуры базы данных (что отражается в ИЛМ).
При проектировании логической структуры БД осуществляются преобразование исходной инфологической модели в модель данных, поддерживаемую конкретной СУБД, и проверка адекватности полученной даталогической модели отображаемой предметной области.
Для любой предметной области существует множество вариантов проектных решений ее отображения в даталогической модели. Методика проектирования должна обеспечивать выбор наиболее подходящего проектного решения.
Минимальная логическая единица данных (несмотря на их разные названия) семантически для всех СУБД одинакова и соответствует либо идентификатору объекта, либо свойству объекта или процесса.
Связи между сущностями предметной области, отраженные в инфологической модели, могут отображаться в даталогической модели либо посредством совместного расположения соответствующих им информационных элементов, либо путем объявления связи между ними. Связь может передаваться как на внутризаписном, так и межзаписном уровне.
5)Информационная модель. Основные способы сбора исходных данных. Метод Дэльфы
Информационная модель — модель объекта, представленная в виде информации, описывающей существенные для данного рассмотрения параметры и переменные величины объекта, связи между ними, входы и выходы объекта и позволяющая путём подачи на модель информации об изменениях входных величин моделировать возможные состояния объекта. Информационная модель — совокупность информации, характеризующая существенные свойства и состояния объекта, процесса, явления, а также взаимосвязь с внешним миром
Способы сбора д-х:
*опрос (телефонный, личный, по почте) – выяснение мнений, представлений, знаний людей по различным вопросам
*наблюдение – охват обстоятельств органами чувств без воздействия на объект наблюдения
*эксперимент – исследование влияния одного фактора на другой при одновременном контроле всех прочих факторов, *анкетный способ, метод интервью, в неживой природе (например, в геологии или археологии);
*в биологических системах (например, из жизни животных и растений); *в технических устройствах (например, телевидение, телеграфные сообщения); *в жизни общества (например, исторические сведения, реклама, средства массовой информации, общение людей). Носителем информации может быть любой материальный предмет (бумага, камень и т.д.);
Метод Дельфы был разработан в корпорации РЭНД.
1)Это итерационная процедура, которая позволяет подвергать мнение каждого эксперта критике со стороны всех остальных, не заставляя их фактически сталкиваться лицом к лицу. Это значит:
2)Создать механизм, обеспечивающий сохранение анонимности точек зрения отдельных лиц и тем самым свести к минимуму влияние красноречивых и обладающих даром убеждать личностей на поведение группы в целом.
3)Все взаимодействия между членами группы находятся под контролем со стороны координатора. Координатор регулирует процедуру анализа мнений и сохраняет их анонимность.
4)Групповая оценка вычисляется им путем некоторого усреднения (обычно посредством нахождения среднего значения, или медианы) и доводится до сведения всех членов группы.
Цель метода Дельфы — уменьшить психологическое давление, испытываемое некоторыми людьми при личном контакте, и, следовательно, исключить влияние на конечный результат особо красноречивой или сильной личности. Однако метод нельзя считать полностью надежным. Отмеченные недостатки:
Неизвестно, какое влияние на расхождение мнений оказывает желание участников приспособиться к общему мнению группы.
Возложение на членов группы ответственности за обоснование своих мнений явно влечет за собой стремление экспертов располагать оценки ближе к медиане без особой аргументации.
Участники, которые первоначально были уверены, что обладают сильными аргументами в пользу своего мнения, легко могут отказаться от своих позиций, когда видят, что им не удалось сразу же убедить остальных членов группы. Это может усилить «эффект толпы» вместо того, чтобы уменьшить его, как ожидалось.
Метод Дельфы, предполагающий анонимность мнений, итеративную процедуру обработки результатов, управляемую обратную связь, числовые оценки и статистическое определение групповой оценки, является ценным инструментом исследования для разработчиков имитационных моделей.
По данным опросов:
*Личные дискуссии не дают столь же эффективных результатов, как метод Дельфы.
*Точность оценки улучшается с ростом числа членов группы и количества итераций.
*Точность оценки падает с увеличением интервала времени между ответами членов группы.
*При использовании, метода Дельфы достигается большее согласие между групповым мнением и мнениями отдельных членов группы, чем при методах, требующих личных контактов. Эта сторона дела, очевидно, особенно важна, если некоторые из членов группы являются руководящими работниками, ответственными за внедрение результатов имитационного моделирования.
6)Четыре уровня модели TCP/IP стека.
Стек протоколов TCP/IP
TCP/IP - собирательное название для набора (стека) сетевых протоколов разных уровней, используемых в Интернет. Особенности TCP/IP:
Открытые стандарты протоколов, разрабатываемые независимо от программного и аппаратного обеспечения;
Независимость от физической среды передачи;
Система уникальной адресации;
Стандартизованные протоколы высокого уровня для распространенных пользовательских сервисов.

Стек протоколов TCP/IP
Стек протоколов TCP/IP делится на 4 уровня:
Прикладной,
Транспортный,
Межсетевой,
Физический и канальный.
Позже была принята 7-ми уровневая модель ISO, но она не используется.
Данные передаются в пакетах. Пакеты имеют заголовок и окончание, которые содержат служебную информацию. Данные, более верхних уровней вставляются, в пакеты нижних уровней.
Экзаменационный билет № 20
Квадратичная аппроксимация (МНК).
Области применения и примеры реализации информационных систем.
Процесс прохождения пользовательского запроса.
Этапы развития ИС
Общая характеристика инструментальных средств моделирования. Языки системы моделирования.
Уникальный 32-битный IP-адрес в InterNet.
1)Квадратичная аппроксимация (МНК).
2)Области применения и примеры реализации информационных систем.
1. Бухгалтерский учет. Это классическая область применения информационных технологий и наиболее часто реализуемая сегодня задача. Во-первых, ошибка бухгалтера может стоить очень дорого, поэтому очевидна выгода использования возможностей автоматизации бухгалтерии. Во-вторых, бухучет легко формализуется, так что разработка систем его автоматизации не является технически сложной. Однако это весьма трудоемко, т.к. к системам бухучета предъявляются повышенные требования в отношении надежности и максимальной простоты и удобства в эксплуатации.
2. Управление финансовыми потоками. Внедрение ИТ в управление финансовыми потоками также обусловлено критичностью этой области управления предприятия к ошибкам. Неправильно построив систему расчетов с поставщиками и потребителями, можно спровоцировать кризис наличности даже при налаженной сети закупок, сбыта и хорошем маркетинге.
3. Управление складом, ассортиментом, закупками. Можно автоматизировать процесс анализа движения товара, тем самым отследив и зафиксировав те 20% ассортимента, которые приносят 80% прибыли. Подобный анализ позволяет также ответить на главный вопрос: как получить максимальную прибыль при постоянной нехватке средств?
4. Управление производственным процессом. Это очень трудоемкая задача. Основные механизмы здесь – планирование и оптимальное управление. Автоматизированное решение задачи УПП дает возможность грамотно планировать, учитывать затраты, оперативно управлять процессом выпуска продукции и т.д.
5. Управление маркетингом. Управление маркетингом подразумевает сбор и анализ данных о фирмах-конкурентах, их продукции и ценовой политике, а также моделирование параметров внешнего окружения для определения оптимального уровня цен, прогнозирования прибыли и планирования рекламных кампаний.
6. Документооборот. Это очень важный процесс деятельности любого предприятия. Отлаженная система документооборота отражает реально происходящую производственную деятельность и дает возможность администрации воздействовать на нее. Поэтому автоматизация документооборота позволяет повысить эффективность управления.
7. Оперативное управление предприятием. ИС, решающая задачи ОУП, строится на основе БД, в которой фиксируется вся информация о предприятии. ИС ОУП включает в себя массу программных решений автоматизации бизнес-процессов на предприятии. Важнейшее требование к таким ИС – гибкость, способность к адаптации и развитию.
8. Предоставление информации о фирме. Развитие сети Интернет привело к необходимости создания корпоративных серверов для предоставления информации о предприятии. Практически каждое уважающее себя предприятие имеет свой web-сервер, который решает целый ряд задач. Среди них две основные задачи: создание имиджа предприятия и разгрузка справочной службы компании.
3)Процесс прохождения пользовательского запроса.
Рисунок 1.3 иллюстрирует взаимодействие пользователя, СУБД и ОС при обработке запроса на получение данных. Цифрами помечена последовательность взаимодействий:
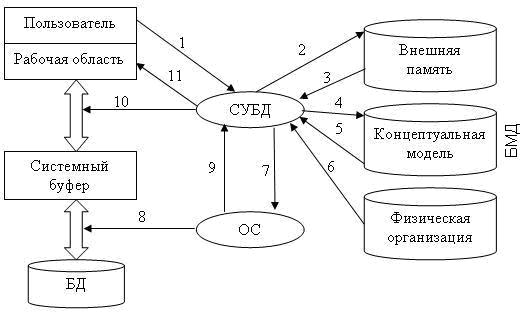
Рис. 1.3 . Схема прохождения запроса к БД
1. Пользователь посылает СУБД запрос на получение данных из БД.
2. Анализ прав пользователя и внешней модели данных, соответствующей данному пользователю, подтверждает или запрещает доступ данного пользователя к запрошенным данным.
3. В случае запрета на доступ к данным СУБД сообщает пользователю об этом (стрелка 11) и прекращает дальнейший процесс обработки данных, в противном случае СУБД определяет часть концептуальной модели, которая затрагивается запросом пользователя.
4. СУБД получает информацию о запрошенной части концептуальной модели.
5. СУБД запрашивает информацию о местоположении данных на физическом уровне (файлы или физические адреса).
6. В СУБД возвращается информация о местоположении данных в терминах операционной системы.
7. СУБД вежливо просит операционную систему предоставить необходимые данные, используя средства операционной системы.
8. Операционная система осуществляет перекачку информации из устройств хранения и пересылает ее в системный буфер.
9. Операционная система оповещает СУБД об окончании пересылки.
10. СУБД выбирает из доставленной информации, находящейся в системном буфере, только то, что нужно пользователю, и пересылает эти данные в рабочую область пользователя.
БМД — это База Метаданных, именно здесь и хранится вся информация об используемых структурах данных, логической организации данных, правах доступа пользователей и, наконец, физическом расположении данных. Для управления БМД существует специальное программное обеспечение администрирования баз данных, которое предназначено для корректного использования единого информационного пространства многими пользователями. СУБД обладает достаточно развитым интеллектом, который позволяет ей не повторять бессмысленных действий.
4)Этапы развития ИС
Информационная система – система ввода, вывода, хранения, обработки данных создаваемая для обеспечения функционирования различных процессов.
50 гг. – решение отдельных экономических задач;
70 гг. – системы комплексной автоматизации;
80 гг. – системы локальной автоматизации построения АРМ;
90 гг. – развитие телекоммуникаций и появление КИС, которые позволили автоматизировать все функции фирмы и отхватить весь цикл работ.
5)Общая характеристика инструментальных средств моделирования. Языки системы моделирования.
Если выбор технических средств сейчас не вызывает особых затруднений (95% - ПК, 5% - специализированные серверы приложений, рабочие станции SUN), то выбор программных средств зачастую довольно сложен:
А) В настоящее время известно более 500 языков моделирования. Такое множество языков частично обусловлено разнообразием классов моделируемых систем, целей и методов моделирования.
Б) Желание упростить и ускорить процесс создания моделей (сделать доступным не только для профессиональных программистов) привело к реализации идеи автоматизации программирования имитационных моделей (не язык, а система моделирования). Создан ряд систем моделирования, которые избавляют исследователя от программирования. Это наиболее перспективное направление развития средств имитационного моделирования.
Концептуальная и информационная модели. Программа создается автоматически по одной из формализованных схем на основании задаваемых исследователем параметров системы, внешних воздействий и особенностей функционирования. Автоматизация одного из наиболее трудных этапов создания имитационной модели – только рутинная часть
6)Уникальный 32-битный IP-адрес в InterNet.
1.2.2 IP-адрес - уникальный идентификатор (адрес) устройства, подключённого к интернету
IPv4 - адрес является уникальным 32-битным идентификатором IP-интерфейса в Интернет (длина IPv4 адреса составляет 32 бит, что дает в общей сложности 232 возможных адресов (чуть более 4 млрд. адресов, IPv4 адреса записываются как четыре блока цифр от 0 до 255 разделенных точками, например 192.168.254.123).
IPv6 - адрес является уникальным 128-битным идентификатором IP-интерфейса в Интернет, иногда называют Internet-2, адресного пространства IPv4 уже стало не хватать, поэтому постепенно вводят новый стандарт.
IP-адреса принято записывать разбивкой всего адреса по октетам (8), каждый октет записывается в виде десятичного числа, числа разделяются точками. Например, адрес
10100000010100010000010110000011 записывается как
10100000.01010001.00000101.10000011 = 160.81.5.131
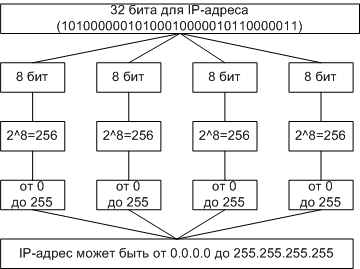
Перевод адреса из двоичной системы в десятичную IP-адрес хоста состоит из номера IP-сети, который занимает старшую область адреса, и номера хоста в этой сети, который занимает младшую часть.
160.81.5.131 - IP-адрес
160.81.5. - номер сети
131 - номер хоста
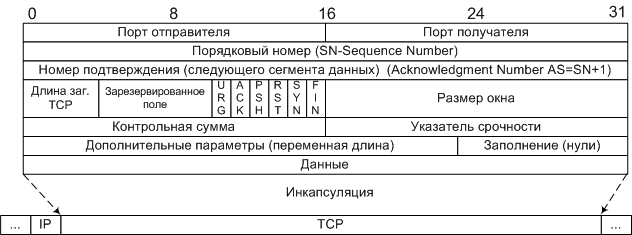
Структура дейтограммы TCP. Слова по 32 бита.
Длина заголовка - задается словами по 32бита.
Размер окна - количество байт, которые готов принять получатель без подтверждения.
Контрольная сумма - включает псевдо заголовок, заголовок и данные.
Указатель срочности - указывает последний байт срочных данных, на которые надо немедленно реагировать.
URG - флаг срочности, включает поле "Указатель срочности", если =0 то поле игнорируется.
ACK - флаг подтверждение, включает поле "Номер подтверждения, если =0 то поле игнорируется.
PSH - флаг требует выполнения операции push, модуль TCP должен срочно передать пакет программе.
RST - флаг прерывания соединения, используется для отказа в соединении
SYN - флаг синхронизация порядковых номеров, используется при установлении соединения.
FIN - флаг окончание передачи со стороны отправителя
Экзаменационный билет № 21
Интерполяция функций. Интерполяционный полином Лагранжа.
Проект. Классификация проектов.
Архитектура БД. Физическая и логическая независимость.
Понятия проекта и проектирования ИС
Факторы выбора инструментальных средств моделирования. Механизмы формирования системного времени.
Инкапсуляция пакетов в стеке TCP/IP.
1)Интерполяция функций. Интерполяционный полином Лагранжа.
2)Проект. Классификация проектов.
Проект – это ограниченное по времени целенаправленное изменение отдельной системы с изначально четко определенными целями, достижение которых определяет завершение проекта, с установленными требованиями к срокам, результатам, риску, рамкам расходования средств и ресурсов и к организационной структуре.
Проекты можно классифицировать по различным признакам. Отметим основные из них.
Класс проекта определяется по составу и структуре проекта. Обычно различают монопроект (отдельный проект, который может быть любого типа, вида и масштаба) и мультипроект (комплексный проект, состоящий из ряда монопроектов ).
Тип проекта определяется по основным сферам деятельности, в которых осуществляется проект. Можно выделить пять основных типов проекта: технический, организационный, экономический, социальный, смешанный.
Масштаб проекта определяется размером бюджета и числом участников: мелкие проекты, малые проекты, средние проекты, крупные проекты. Можно рассматривать масштаб проекта в более конкретной форме – отраслевые, корпоративные, ведомственные, проекты предприятия.
3)Архитектура БД. Физическая и логическая независимость.
База данных (БД) — именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации БД, изображенная на рис. 1.2:
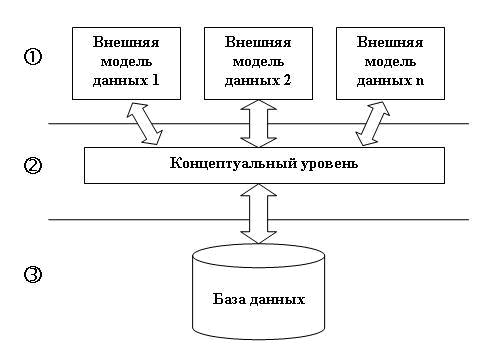
Рис. 1.2. Трехуровневая модель системы управления базой данных, предложенная ANSI
Уровень внешних моделей — самый верхний уровень, где каждая модель имеет свое «видение» данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров.
Концептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира.
Физический уровень — собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации.
Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных. Это именно то, чего не хватало при использовании файловых систем.
Выделение концептуального уровня позволило разработать аппарат централизованного управления базой данных
4)Понятия проекта и проектирования ИС
Под проектом ИС понимаются проектно-конструкторскую документацию, в которой представлено описание проектных решений по созданию и эксплуатации ИС в конкретной программной среде.
Под проектированием ИС понимается комплекс взаимосвязанных мероприятий, предназначенный для достижения поставленных целей в течение ограниченного периода и при установленном бюджете.
Проектирование ИС представляет собой сложную, трудоемкую и длительную работу. Основная доля трудозатрат приходится на прикладное программное обеспечение (ПО) и базы данных (БД).
Проектирование ИС охватывает три основные области:
проектирование объектов данных, которые будут реализованы в базе данных;
проектирование программ, экранных форм, отчетов, которые будут обеспечивать выполнение запросов к данным;
учет конкретной среды или технологии, а именно: топологии сети, конфигурации аппаратных средств, используемой архитектуры (файл-сервер или клиент-сервер), параллельной обработки, распределенной обработки данных и т.п.
Проектирование ИС всегда начинается с определения цели проекта. В общем виде цель проекта можно определить как решение ряда взаимосвязанных задач, включающих в себя обеспечение на момент запуска системы и в течение всего времени ее эксплуатации:
требуемой функциональности системы и уровня ее адаптивности к изменяющимся условиям функционирования;
требуемой пропускной способности системы;
требуемого времени реакции системы на запрос;
безотказной работы системы;
необходимого уровня безопасности;
простоты эксплуатации и поддержки системы.
Процесс создания ИС представляет собой процесс построения и последовательного преобразования ряда согласованных моделей на всех этапах жизненного цикла (ЖЦ) ИС. На каждом этапе ЖЦ создаются специфичные для него модели - организации, требований к ИС, проекта ИС, требований к приложениям и т.д. Модели формируются рабочими группами команды проекта, сохраняются и накапливаются в репозитории проекта. Создание моделей, их контроль, преобразование и предоставление в коллективное пользование осуществляется с использованием специальных программных инструментов - CASE-средств.
Процесс создания ИС делится на ряд этапов (стадий), ограниченных некоторыми временными рамками и заканчивающихся выпуском конкретного продукта (моделей, программных продуктов, документации и пр.).
Обычно выделяют следующие этапы создания ИС: формирование требований к системе, проектирование, реализация, тестирование, ввод в действие, эксплуатация и сопровождение.
Начальным этапом процесса создания ИС является моделирование бизнес-процессов, протекающих в организации и реализующих ее цели и задачи. Модель организации, описанная в терминах бизнес-процессов и бизнес-функций, позволяет сформулировать основные требования к ИС. Это фундаментальное положение методологии обеспечивает объективность в выработке требований к проектированию системы. Множество моделей описания требований к ИС затем преобразуется в систему моделей, описывающих концептуальный проект ИС. Формируются модели архитектуры ИС, требований к программному обеспечению (ПО) и информационному обеспечению (ИО). Затем формируется архитектура ПО и ИО, выделяются корпоративные БД и отдельные приложения, формируются модели требований к приложениям и проводится их разработка, тестирование и интеграция.
Целью начальных этапов создания ИС, выполняемых на стадии анализа деятельности организации, является формирование требований к ИС, корректно и точно отражающих цели и задачи организации-заказчика. Чтобы специфицировать процесс создания ИС, отвечающей потребностям организации, нужно выяснить и четко сформулировать, в чем заключаются эти потребности. Для этого необходимо определить требования заказчиков к ИС и отобразить их на языке моделей в требования к разработке проекта ИС так, чтобы обеспечить соответствие целям и задачам организации.
Задача формирования требований к ИС является одной из наиболее ответственных, трудно формализуемых и наиболее дорогих и тяжелых для исправления в случае ошибки. Современные инструментальные средства и программные продукты позволяют достаточно быстро создавать ИС по готовым требованиям. Но зачастую эти системы не удовлетворяют заказчиков, требуют многочисленных доработок, что приводит к резкому удорожанию фактической стоимости ИС. Основной причиной такого положения является неправильное, неточное или неполное определение требований к ИС на этапе анализа.
На этапе проектирования прежде всего формируются модели данных. Проектировщики в качестве исходной информации получают результаты анализа. Построение логической и физической моделей данных является основной частью проектирования базы данных. Полученная в процессе анализа информационная модель сначала преобразуется в логическую, а затем в физическую модель данных.
Параллельно с проектированием схемы базы данных выполняется проектирование процессов, чтобы получить спецификации (описания) всех модулей ИС. Оба эти процесса проектирования тесно связаны, поскольку часть бизнес-логики обычно реализуется в базе данных (ограничения, триггеры, хранимые процедуры). Главная цель проектирования процессов заключается в отображении функций, полученных на этапе анализа, в модули информационной системы. При проектировании модулей определяют интерфейсы программ: разметку меню, вид окон, горячие клавиши и связанные с ними вызовы.
Конечными продуктами этапа проектирования являются:
схема базы данных (на основании ER-модели, разработанной на этапе анализа);
набор спецификаций модулей системы (они строятся на базе моделей функций).
Кроме того, на этапе проектирования осуществляется также разработка архитектуры ИС, включающая в себя выбор платформы (платформ) и операционной системы (операционных систем). В неоднородной ИС могут работать несколько компьютеров на разных аппаратных платформах и под управлением различных операционных систем. Кроме выбора платформы, на этапе проектирования определяются следующие характеристики архитектуры:
Этап проектирования завершается разработкой технического проекта ИС.
На этапе реализации осуществляется создание программного обеспечения системы, установка технических средств, разработка эксплуатационной документации.
Этап тестирования - После завершения разработки отдельного модуля системы выполняют автономный тест, который преследует две основные цели:
обнаружение отказов модуля (жестких сбоев);
соответствие модуля спецификации (наличие всех необходимых функций, отсутствие лишних функций).
После того как автономный тест успешно пройдет, модуль включается в состав разработанной части системы и группа сгенерированных модулей проходит тесты связей, которые должны отследить их взаимное влияние.
Далее группа модулей тестируется на надежность работы, то есть проходят, во-первых, тесты имитации отказов системы, а во-вторых, тесты наработки на отказ. Первая группа тестов показывает, насколько хорошо система восстанавливается после сбоев программного обеспечения, отказов аппаратного обеспечения. Вторая группа тестов определяет степень устойчивости системы при штатной работе и позволяет оценить время безотказной работы системы. В комплект тестов устойчивости должны входить тесты, имитирующие пиковую нагрузку на систему.
Затем весь комплект модулей проходит системный тест - тест внутренней приемки продукта, показывающий уровень его качества. Сюда входят тесты функциональности и тесты надежности системы.
Последний тест информационной системы - приемо-сдаточные испытания. Такой тест предусматривает показ информационной системы заказчику и должен содержать группу тестов, моделирующих реальные бизнес-процессы, чтобы показать соответствие реализации требованиям заказчика.
Необходимость контролировать процесс создания ИС, гарантировать достижение целей разработки и соблюдение различных ограничений (бюджетных, временных и пр.) привело к широкому использованию в этой сфере методов и средств программной инженерии: структурного анализа, объектно-ориентированного моделирования, CASE-систем.
5)Факторы выбора инструментальных средств моделирования. Механизмы формирования системного времени.
1) Факторы выбора инструментальных средств моделирования:
В какой форме будет описываться объект исследования: непрерывная, дискретная система или смешанный вариант.
Проблемно-ориентированная среда (ARENA, ARIS) или универсальная система (GPSS) На выбор той или иной системы влияет выполнение следующих условий: 1) Наличие практического опыта работы с конкретным инструментальным средством, в том числе и наличие обученного персонала. Все современные системы достаточно сложны (особенно в части средств организации эксперимента и анализа). 2) Стоимость лицензии и стоимость разработки. Их соотношение со средствами, выделенными на проект. Современные проблемно-ориентированные системы моделирования очень дороги, по сравнению с просто языками моделирования. 3) Размерность создаваемой модели (несложный объект, учебные задачи и т.д.). Современные средства моделирования достаточно функциональны. Поэтому при небольшой размерности целесообразнее ориентироваться на более простую систему (GPSS/W), даже если она не очень вписывается в предметную область. 4) Предметная область объекта исследования. Возможность или ее отсутствие выбрать конкретную проблемно-ориентированную систему.
Внутренние факторы: а) Виды возможных статистических испытаний. Хотя современные системы моделирования в этом отношении достаточно функциональны, тем не менее, специфика все-таки имеется. Поэтому, если исследуемая система требует разнообразных средств анализа и испытаний необходимо учитывать этот фактор при выборе конкретной системы моделирования. б) Степень трудности изменения структуры модели. Если структура моделируемой системы неочевидна или подвержена изменениям (новый объект, предпроектное обследование), то этот фактор, безусловно, является очень важным. в) Способ организации учета времени и происходящих действий.
2) Определение механизма регламентации событий и процессов.
Регламентация имеет 2 аспекта: «продвижение» времени, т.е. корректирование временной координаты состояния системы; обеспечение согласованности различных блоков и событий в системе. Поскольку действия, выполняемые отдельными блоками, зависят от действий и состояния других элементов, они должны быть скоординированы во времени, или «синхронизированы».
Существуют два основных метода задания времени: С помощью фиксированных интервалов времени. Отсчет системного времени ведется через заранее определенные интервалы постоянной длины. Модели с непрерывным изменением состояния. С помощью переменных интервалов времени. Состояние моделируемой системы обновляется с появлением каждого существенного события независимо от интервала времени между ними (время событий). Модели с дискретным изменением состояния.
Каждый из методов имеет свои преимущества: последовательная обработка событий и обработка событий пакетами или группами. Модели с фиксированным шагом проще реализуются, но существует риска не правильного выбора интервала времени (слишком большой) и, соответственно потеря точности модели.
Метод фиксированных шагов:
События появляются регулярно и распределены во времени равномерно.
В течение цикла моделирования T появляется очень много событий, причем математическое ожидание продолжительности событий невелико.
Точная природа существенных событий не ясна. Например, на начальном этапе имитационного исследования.
Метод переменных интервалов времени:
Позволяет существенно экономить машинное время моделирования в случае статических систем, в которых существенные события могут длительное время не наступать.
Не требует определения величины времени приращения
Может эффективно использоваться при неравномерном распределении событий во времени и (или) большой величине математического ожидания их продолжительности.
6)Инкапсуляция пакетов в стеке TCP/IP.
Данные передаются в пакетах. Пакеты имеют заголовок и окончание, которые содержат служебную информацию. Данные, более верхних уровней вставляются, в пакеты нижних уровней.
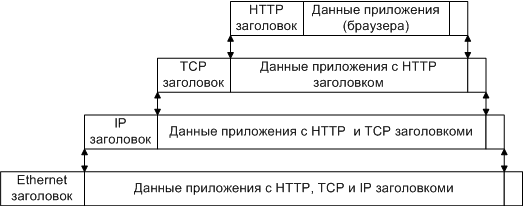
Пример инкапсуляции пакетов в стеке TCP
Особенности TCP/IP:
открытые стандарты протоколов, разрабатываемые независимо от программного и аппаратного обеспечения;
независимость от физической среды передачи;
система уникальной адресации;
стандартизованные протоколы высокого уровня для распространенных пользовательских сервисов.