

Синхронізація і потоки даних
Як видно, в чіпсеті забезпечується взаємодія безлічі шин, більшість яких синхронні. Питання синхронізації вирішуються по-різному. У чіпсетів для шини Pentium пам'ять завжди працювала на частоті системної шини (60-100 Мгц), а частота шини PCI (номінал 33 Мгц) була до неї прив'язана з коефіцієнтом 1 : 2 або 1 : 3. При частоті системної шини, відмінної від 66 або 100 Мгц, шина PCI виявлялася або розігнаною, або приторможенной.
У чіпсетах з портом AGP частоту шини пам'яті прагнуть підвищити, інакше пам'ять стає вузьким местомом: до неї звертаються акселератор з AGP, що ведуть пристрої PCI і, нарешті, сам процесор. При цьому у процесора може бути частота шини всього 66 Мгц (як, наприклад, у процесорів Celeron). Для любителів розгонів корисна така властивість чіпсетів, як асинхронностъ — можливість щодо довільного завдання частот системної шини, шини пам'яті, порту AGP, шини PCL Відмітимо, що частота шин LPC і шини підключення хаба з BIOS (FWH) співпадає з частотою PCI (33 Мгц), і розгін шини PCI спричиняє за собою розгін і цих шин, проте поведінка їх абонентів на підвищених частотах може засмутити користувача неможливістю розгону. Звичайно ж, тут асинхронность умовна — опорний генератор все-таки один, але коефіцієнти для кожного домена синхронізації (групи тісно зв'язаних вузлів) задаються роздільно. Таким чином, можна зі всіх компонентів «вижати» максимум продуктивності. Проте при певних співвідношеннях частот компонентів (як правило, не рівних ступеню двійки) із-за проміжної буферизації даних спостерігається зниження сумарної продуктивності системи.
На мал. 4 позначені основні компоненти системної плати, інтерфейси, що зв'язують їх, і основні потоки транзакцій. Кружком на лініях
ініціатор транзакцій, стрілки вазують на цільовий пристрій, напрям передачі даних може бути будь-яким. Тут же вказана пікова пропускна спроможність інтерфейсів цих компонентів при різних частотах. На малюнку зображений однопроцесорний варіант. Підключення другого (і наступних) процесорів Pentium 4, Р6 і Pentium (якщо це можливо) не підвищує загальну продуктивність шини процесорів (вони розділяють загальну шину). Для процесорів Athlon ситуація інша: оскільки процесори підключаються до хабу виділеними каналами, сумарна потреба в пропускній спроможності для двопроцесорної шини подвоюється. У мультипроцесорних системах на процесорах з системною шиною HyperTransport питання пропускної спроможності ставляться інакше .
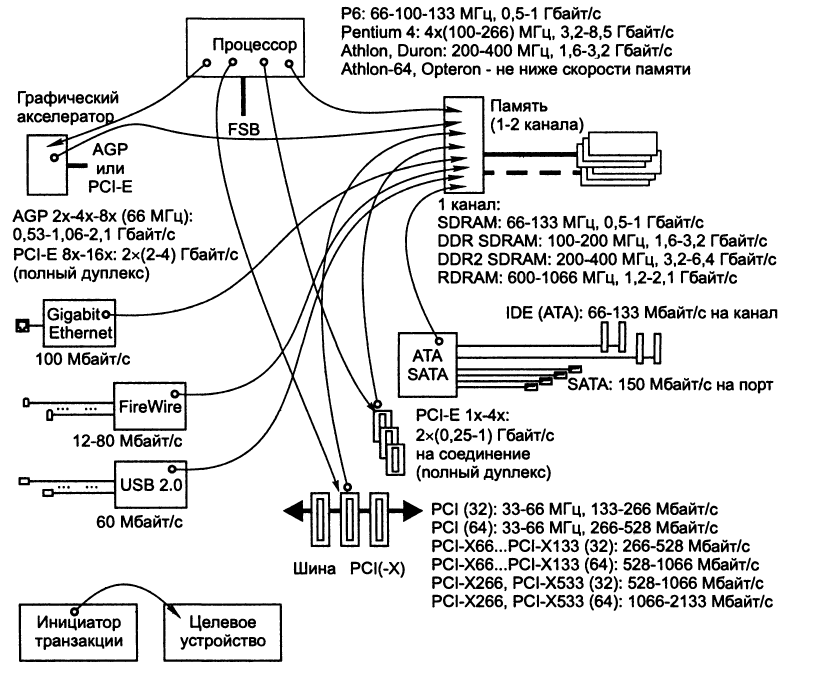
Мал. 4. Компоненти і потоки даних на системній платі
З малюнка видно, що в плані потоків даних центральним компонентом комп'ютера є пам'ять. Цілком очевидно, що комп'ютер повинен бути збалансований по пропускній спроможності інтерфейсів. Безглуздо робити пропускну спроможність будь-якого інтерфейсу вище за пропускну спроможність пам'яті — виграшу в продуктивності системи це не дасть, оскільки швидкість в кожному потоці визначається найменшою з швидкостей його джерела і приймача. Для підвищення пропускної спроможності пам'яті допускається застосування другого каналу, що робиться вже в багатьох чіпсетах для DDR SDRAM і RDRAM. Для SDRAM і DDR RDRAM таке рішення технічно обходиться дорожчим — дуже багато лінії інтерфейсу, проте ці труднощі вже подолані.
Інтерфейс підключення графічного адаптера (AGP або PCI-E), як правило, є наймогутнішим споживачем пропускної спроможності звернень до пам'яті з боку периферії. Наступними по «рівню домагань» є інтерфейси пристроїв зберігання (AT A, SAT A, SCSI), адаптера Gigabit Ethernet, шин FireWire і USB 2.0. Інтерфейс пристроїв зберігання (природно, і самі пристрої) визначає загальну продуктивність комп'ютера, оскільки через них проходить потік свопінгу для роботи віртуальної пам'яті. Пропускна спроможність решти інтерфейсів впливає лише на швидкість роботи з відповідною периферією.