

Деревья
Дерево– это иерархическая структура, состоящая из множествавершин(или элементов). Каждая вершина дерева относится к определенномууровнюи обладает тем свойством, что, помимо внутренней информации, в ней также содержатся указатели на вершины более низкого уровня.
Понятие уровняосновано на следующих положениях (рис.II–5):

Рис. II–5.
каждое дерево должно иметь одну самую верхнюю вершину, на которую не указывает ни одна из других вершин. Такую вершину называют корнем дерева;
ни одна вершина не может указывать на вершину, определенную ранее (на предыдущих уровнях);
вершины, на которые указывает корень дерева, являются вершинами первого уровня; они, в свою очередь, указывают на вершинывторого уровня, и так далее. Вершина (n-1)-го уровня указывает на вершину n-го, более низкого, уровня;
на самом нижнем уровне дерева размещаются вершины, определяемые как листья– вершины, которые не указывают ни на одну другую вершину дерева и состоят из внешних по отношению к дереву структур данных;
указатели в дереве всегда расположены так, что от корня к любой вершине дерева, в том числе и к любому листу, существует только один путь.
Дерево определяет рекурсивную структуру данных, которую можно определить следующим образом:
Дерево представляет собой множество вершин, которое либо является пустым, либо состоит из корня и некоторого множества починенных ему поддеревьев. Каждое поддерево представляет собой дерево.
Частным случаем дерева, широко используемым при решении различных задач, является двоичное дерево, каждая вершина которого указывает не более чем на две вершины более низкого уровня, определяющиелевоеиправоеподдеревья. На рис.II–6 схематически изображено двоичное дерево, представляющее выражение (a+b)*(c-d).

Рис. II–6
Левое и правое поддеревья в двоичном дереве не являются эквивалентными. Так, если рассмотреть два двоичных дерева, каждое из которых состоит только из двух вершин, но одно дерево представляет собой корень и левое поддерево, а другое – корень и правое поддерево, то эти два дерева определяют разные структуры (рис. II–7).

Рис. II–7
Примечание: если бы приведенные на рис.II–7 структуры были определены как обычное – не двоичное дерево, тогда они были бы эквивалентными.
Разработанные логические структуры определяют набор алгоритмов их обработки. Реализация алгоритма зависит от организации внутренних (физических) структур данных– или от способа представления данных в памяти компьютера.
Внутренние структуры данных
Отображение в памяти данных, имеющих линейную структуру и повторяющих линейную структуру памяти машины, не вызывает затруднений. Отображение данных с нелинейной структурой требует использование некоторой надстройки, позволяющей обрабатывать подобные данные. Реализация такой надстройки требует выполнения дополнительных операций для получения очередного элемента данных независимо от используемой системы программирования.
Для отображения абстрактных структур данных на физическую (линейную) память машины используются физические (или внутренние) структуры данных. Обычно внутренние структуры данных надстраиваются над базовой структурой памяти машины путем использования соответствующих программных средств. Каждая внутренняя структура данных строится из неделимых (с точки зрения структуры) частей, называемыхэлементами. Эти элементы практически эквивалентны элементам информации абстрактной структуры. Элемент может иметь несколько полей, часть из которых может использоваться для определения структуры.
В качестве внутренних структур данных используются векторы, списки и сети. В каждом конкретном случае внутренняя структура выбирается с таким расчетом, чтобы быть эквивалентной используемой абстрактном структуре данных или, по крайней мере, допускать простое отображение этой абстрактной структуры. Каждый тип внутренней структуры данных обладает рядом характерных свойств, независимых от используемого для обработки данных языка программирования. Тем не менее, здесь будут приводиться иллюстрации на языке С/С++.
Вектор
Векторпредставляет собой множество элементов, которые физически расположены последовательно друг за другом. Для определения вектора необходимо определить:
базовый адрес,
размер вектора (количество элементов),
размер одного элемента вектора.
При этом предполагается, что все элементы вектора должны иметь одинаковый размер (рис. II–8).

Рис. II–8
Вектор соответствует линейной структуре памяти машины и представляет собой имя, данное базовой структуре памяти машины. К отдельным элементам вектора можно непосредственно обратиться, используя базовый адрес вектора и порядковый номер элемента в векторе. На уровне базовой структуры памяти машины для организации доступа к i-му элементу вектора его адрес вычисляется следующим образом:
Адресi=базовый_адрес+ (i-1)*размер_элемента
Представление вектора в языке С/С++
Вектор практически соответствует одномерному массиву, что не вызывает проблем его использования в программах. В языке С/С++ вектор определяется как массив элементов определенного типа, при этом язык не накладывает ограничения на тип элемента массива:
тип_элемента имя_массива [ количество_элементов ];
Тогда имя_массива определяет базовый адрес вектора,количество_элементов – размер вектора итип_элемента– размер элемента вектора.
Примеры:
int a[12], b[3];
char s[80];
struct S{ ... };
S x[100];
В двух первых примерах использован стандартный (предопределенный языком С/C++) тип элементов массивов – intиchar. В последнем примере тип элемента массива определяется программистом (в соответствии с тем, как он определит структуруstruct S).
Следует помнить, что в языке С при определении данных типа структура необходимо добавлять слово struct, т.е. последний пример на языке С будет выглядеть так:
struct S{ ... };
struct S x[100];
Можно сохранить синтаксис, аналогичный используемому в языке С++, если определить имя структуры с помощью предложения typedef:
typedef struct S{ ... }S;
S x[100];
В дальнейшем в примерах будет использоваться синтаксис языка С++.
Доступ к элементу массива в языке С/С++ можно осуществить двумя способами:
с помощью индекса, при этом в языке С/С++ первый элемент массива имеет значение индекса 0, а последний – (количество_элементов– 1),
с помощью указателя.
И в том, и в другом случае при осуществлении доступа к некоторому элементу массива (вектора) адрес элемента вычисляется без участия программиста. Правила работы с массивами в языке С/С++ изложены в части I.
Списки
Списокпредставляет собой множество элементов, каждый из которых состоит из двух полей. Первое поле содержит указатель на информацию, определяемую этим элементом, второе – указатель на следующий элемент списка (рис.II–9). Список, составленный из таких элементов, представляет собойлинейный список.

Рис. II–9
Информацией, определяемой таким элементом списка, может быть другой список или некоторая внешняя по отношению к рассматриваемой структура данных. Она может размещаться вне элемента списка или внутри него, в зависимости от характеристик элементов отображаемой абстрактной структуры данных. В то же время информация, определяемая элементом списка, является неделимой с точки зрения выполнения операций с данным списком.
Доступ к списку как к единому целому обеспечивается определением начала списка (т.е. первого элемента списка). Обычно список определяется специальным указателемна начало списка. Последний элемент списка в поле указателя на следующий элемент может иметь специальную запись – так называемый "пустой" указатель (NULLили0). Список, определенный таким образом, получил названиелинейного односвязного списка(рис.II–10).

Рис. II–10
Можно определить список, задав вместо указателя специальный – головнойэлемент, в котором поле указателя на информацию не используется, а поле указателя на следующий элемент определяет начало списка. Такой список получил названиесписка с головным элементом(рис.II–11).
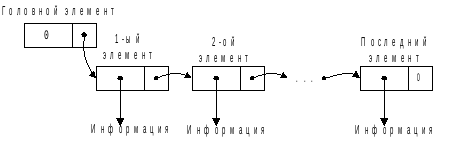
Рис. II–11
Последний элемент списка вместо пустого указателя может содержать указатель на первый элемент списка; в этом случае говорят о циклическомсписке, который также может быть просто списком или списком с головным элементом (рис.II–12).

Рис. II–12
Наконец, каждый элемент списка может содержать, помимо указателя на информацию, еще два указателя – на следующий и предыдущий элементы списка. Такой список называется двусвязными определяется своими началом (первым элементом) и концом (последним элементом списка).
Двусвязный список, как и односвязный, может быть линейным и циклическим; начало и конец списка могут быть заданы с помощью указателей или с помощью головных элементов (рис. II–13).

Рис. II–13
Таким образом, элементы списка могут располагаться в памяти машины в произвольном порядке, поскольку каждый элемент списка сам определяет следующий за ним элемент; это позволяет отображать на линейную память машины нелинейные структуры данных.
Представление списка в языке С/С++
Для задания списка в программе следует определить структуру элемента списка и задать начало списка (и его конец, если используется двусвязный список).
Элемент односвязного списка определяется с помощью структуры следующим образом:
struct Item{
тип info;
Item *next;
};
В этом определении слово типопределяет тип информационной части элемента списка; это может быть, как уже говорилось, указатель на информацию или сама информация; информация может быть представлена базовыми типами языка или типами, определенными программистом (т.е. другими структурами). Конкретный способ задания информационного поля в элементе списка определяется конкретным приложением.
Сам список задается указателем на его первый элемент:
Item *first;
Сети
Сетьпредставляет собой множество элементов (называемыхузлами), каждый из которых состоит из нескольких полей. Одно поле содержит указатель на информацию, определяемую этим элементом, а все остальные – указатели на другие узлы сети (рис.II–14).

Рис. II–14
В общем случае в сети могут быть использованы узлы разных типов, поэтому с каждым типом узла связывают формат, определяющий назначение конкретных полей. Формат предполагается внешним по отношению к множеству узлов, составляющих сеть.
Сети используются для отображения сложных абстрактных структур данных. Хотя рассмотренные выше списки и пригодны для отображения таких структур, они нередко могут оказаться неэффективными и недостаточно наглядными. Более эффективными и наглядными внутренними структурами могут быть сети. Например, приведенное ранее арифметическое выражение (a+b)*(c-d)может быть задано в форме сети так, как это показано на рис.II–15.

Рис. II–15