

2. Классификация мкмд-систем
В МКМД-системе каждый процессорный элемент (ПЭ) выполняет свою программу достаточно независимо от других ПЭ. В то же время процессорные элементы должны как-то взаимодействовать друг с другом. Различие в способе такого взаимодействия определяет условное деление МКМД-систем на ВС с общей памятью и системы с распределенной памятью (рис. 5.7).
2.1. Вычислительные системы с общей памятью
В системах с общей памятью, которые характеризуют как сильно связанные, имеется общая память данных и команд, доступная всем процессорным элементам с помощью общей шины или сети соединений. Такие системы называются мультипроцессорами. К этому типу относятся симметричные мультипроцессоры (UMA (SMP), Symmetric Multiprocessor), системы с неоднородным доступом к памяти (NUMA, Non-Uniform Memory Access) и системы, с так называемой, локальной памятью вместо кэш-памяти (COMA, Cache Only Memory Access).
Если все процессоры имеют равный доступ ко всем модулям памяти и всем устройствам ввода-вывода и каждый процессор взаимозаменяем с другими процессорами, то такая система называется SMP-системой. В системах с общей памятью все процессоры имеют равные возможности по доступу к единому адресному пространству. Единая память может быть построена как одноблочная или по модульному принципу, но обычно практикуется второй вариант.
SMP-системы относятся к архитектуре UMA. Вычислительные системы с общей памятью, где доступ любого процессора к памяти производится единообразно и занимает одинаковое время, называют системами с однородным доступом к памяти UMA (Uniform Memory Access).
С точки зрения уровней используемой
памяти в архитектуре UMA рассматривают
три варианта построения мультипроцессора:
точки зрения уровней используемой
памяти в архитектуре UMA рассматривают
три варианта построения мультипроцессора:
- классическая (только с общей основной памятью);
- с дополнительным локальным кэшем у каждого процессора;
- с дополнительной локальной буферной памятью у каждого процессора (рис. 5.8).
С точки зрения способа взаимодействия процессоров с общими ресурсами (памятью и СВВ) в общем случае выделяют следующие виды архитектур UMA:
- с общей шиной и временным разделением (7.9);
- с координатным коммутатором;
- на основе многоступенчатых сетей.
Использование только одной шины ограничивает размер мультипроцессора UMA до 16 или 32 процессоров. Чтобы получить больший размер, требуется другой тип коммуникационной сети. Самая простая схема соединения – координатный коммутатор (рис. 5.10). Координатные коммутаторы используются на протяжении многих десятилетий для соединения группы входящих линий с рядом выходящих линий произвольным образом.
Координатный коммутатор представляет собой неблокируемую сеть. Это значит, что процессор всегда будет связан с нужным блоком памяти, даже если какая-то линия или узел уже заняты. Более того, никакого предварительного планирования не требуется.
Координатные коммутаторы вполне применимы для систем средних размеров (рис. 5.11).
Н а
основе коммутаторов 2x2 можно построить
многоступенчатые сети. Один из возможных
вариантов – сеть omega (рис. 5.12). Для n
процессоров и n модулей памяти тредуется
log2n
ступеней, n/2 коммутаторов на каждую
ступень, то есть всего (n/2)log2n
коммутаторов на каждую ступень. Это
намного лучше, чем n2
узлов (точек пересечения), особенно для
больших n.
а
основе коммутаторов 2x2 можно построить
многоступенчатые сети. Один из возможных
вариантов – сеть omega (рис. 5.12). Для n
процессоров и n модулей памяти тредуется
log2n
ступеней, n/2 коммутаторов на каждую
ступень, то есть всего (n/2)log2n
коммутаторов на каждую ступень. Это
намного лучше, чем n2
узлов (точек пересечения), особенно для
больших n.
Размер мультипроцессоров UMA с одной шиной обычно ограничивается до нескольких десятков процессоров, а для координатных мультипроцессоров или мультипроцессоров с коммутаторами требуется дорогое аппаратное обеспечение, и они ненамного больше по размеру. Чтобы получить более 100 процессоров, необходим иной доступ к памяти.
Для большей масштабируемости мультипроцессоров приспособлена архитектура с неоднородным доступом к памяти NUMA (NonUniform Memory Access). Как и мультипроцессоры UMA, они обеспечивают единое адресное пространство для всех процессоров, но, в отличие от машин UMA, доступ к локальным модулям памяти происходит быстрее, чем к удаленным.
В рамках концепции NUMA реализуется подходы, обозначаемые аббревиатурами NC-NUMA и CC-NUMA.
Если время доступа к удаленной памяти не скрыто (т.к. кэш-память отсутствует), то такая система называется NC-NUMA (No Caching NUMA – NUMA без кэширования) (рис. 5.13).
Если присутствуют согласованные КЭШи, то система называется CC-NUMA (Coherent Cache Non-Uniform Memory Architecture – NUMA с согласованной кэш-памятью) (7.14).

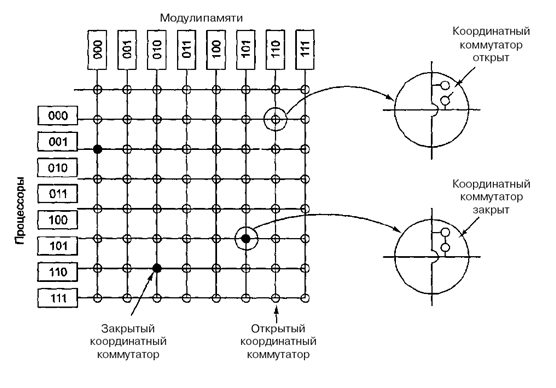
Рис. 5.10. Структура координатного коммутатора

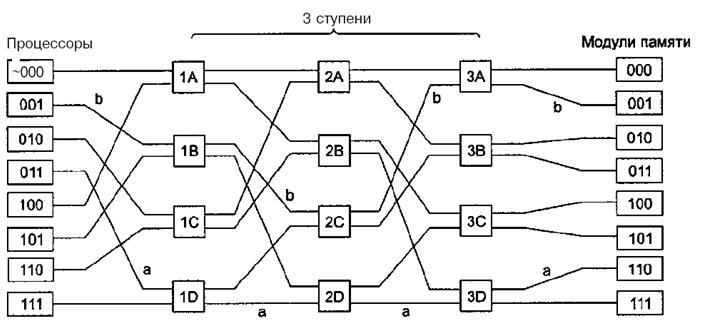
Рис. 5.12. Структура UMA-системы на основе сети Omega
Согласно технологии CC-NUMA, каждый узел в системе владеет собственной основной памятью, но с точки зрения процессоров имеет место глобальная адресуемая память, где каждая ячейка любой локальной основной памяти имеет уникальный системный адрес. Когда процессор инициирует доступ к памяти и нужная ячейка отсутствует в его локальной кэш-памяти, кэш-память второго уровня (L2) процессора организует операцию выборки. Если нужная ячейка находится в локальной основной памяти, выборка производится с использованием локальной шины. Если же требуемая ячейка хранится в удаленной секции глобальной памяти, то автоматически формируется запрос, посылаемый по сети соединений на нужную локальную шину и уже по ней к подключенному к данной локальной шине кэшу. Все эти действия выполняются автоматически, прозрачны для процессора и его кэш-памяти.
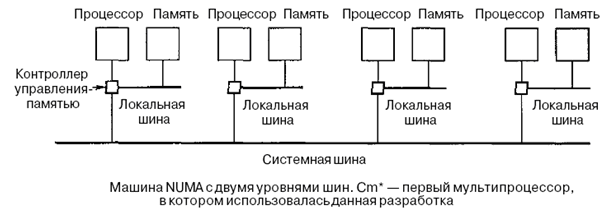
Рис. 5.13. Структура ВС NC-NUMA Cm*
Способы обеспечения совместимости кэшей:
1. Отслеживание системной шины (низкая масштабируемость, простота технической реализации).
2
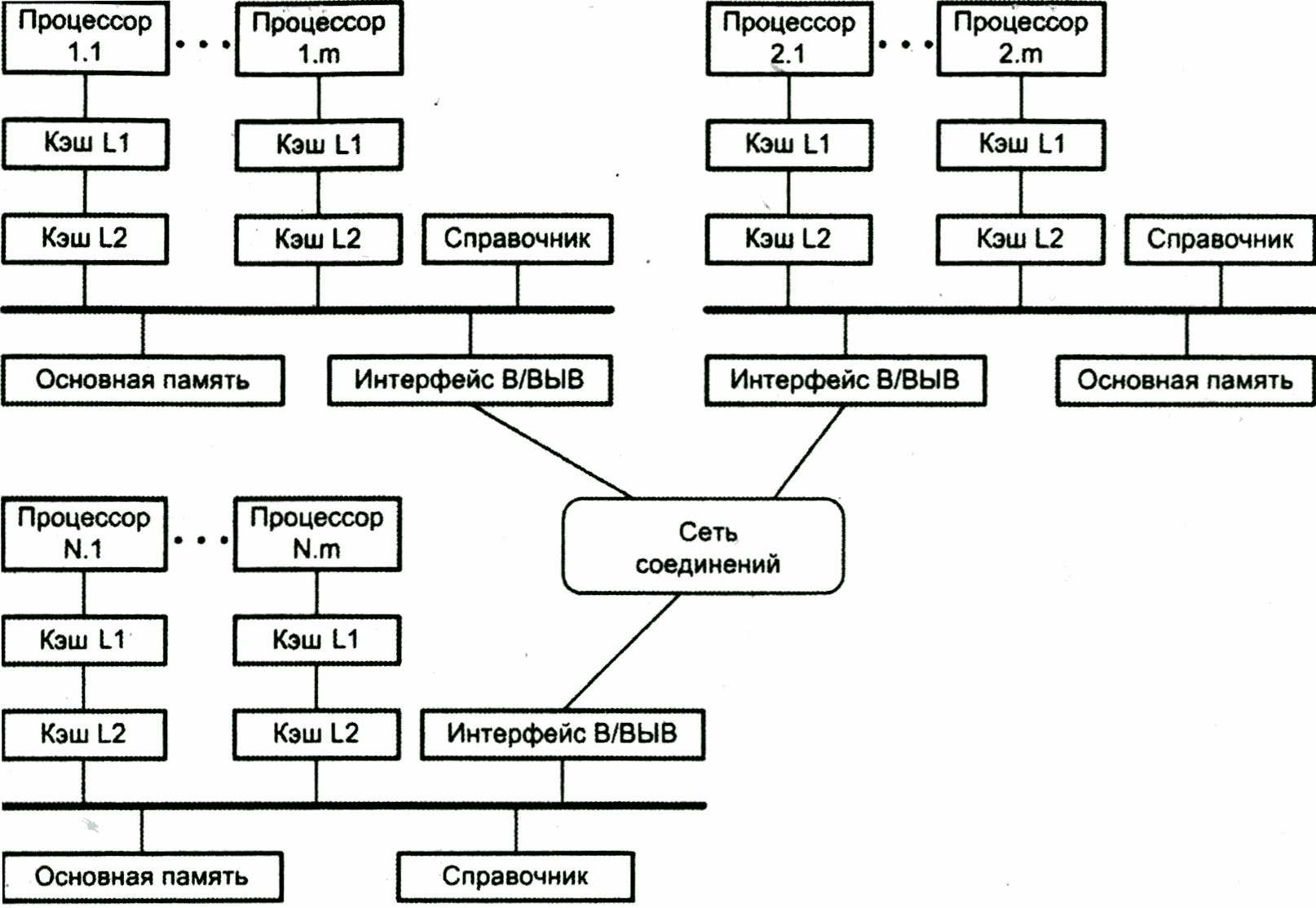
Рис. 5.14. Структура системы типа CC-NUMA
. Использование каталога (хранение БД кэш-строк в высокоскоростном специализированном аппаратном обеспечении).Машины NUMA имеют один большой недостаток: обращения к удаленной памяти происходят гораздо медленнее, чем обращения к локальной памяти. Было предложено использовать основную память процессора как кэш-память – архитектура COMA (Cache Only Memory Access).
Особенности архитектуры COMA:
1. Локальная память каждого процессора рассматривается как кэш для доступа «своего» процессора.
2. Кэши всех процессоров рассматриваются как глобальная память системы, а сама глобальная память отсутствует.
3. Данные не привязаны к конкретному модулю памяти и не имеют уникального адреса, остающегося неизменным в течение всего времени существования переменной.
4. Данные переносятся в кэш-память того процессора, который последним их запросил. Перенос данных из одного локального кэша в другой не требует участия в этом процессе операционной системы, но подразумевает сложную и дорогостоящую аппаратуру управления памятью.