

Модель сервера баз данными: назначение и описание
Применительно к этой модели используется так называемый механизм процедур. Хранимые процедуры программируются либо на языке SQL либо на языке процедурного расширения непроцедурного языка SQL. Эти процедуры являются разделяемыми между приложениями клиентов, хранятся и выполняются на сервере БД. Т.о., а отличие от SQL-сервера, для данной модели характерным является не передача SQL-запроса, а передача вызова хранимой процедуры.
П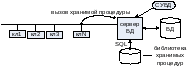 осле
вызова процедуры осуществляется
обращение к командам на языке SQL.
Осуществляется обработка данных по
заданному бизнес-правилу, и обработанные
данные передаются клиенту.
осле
вызова процедуры осуществляется
обращение к командам на языке SQL.
Осуществляется обработка данных по
заданному бизнес-правилу, и обработанные
данные передаются клиенту.
Т.е. преимущества данной модели состоят:
1) в уменьшении сетевого трафика.
2) создании заранее запрограммированных разделяемых процедур обработки, которые м.б. использованы всеми клиентами сети.
3) возможность использования централизованного администрирования прикладного обеспечения.
Процедура является разделяемой, она может использоваться одновременно, т.к. написание процедур сложно, то этим занимается администратор БД, а не клиенты.
Централизованное администрирование приложений.
ИС всегда открытые:
возможность ее модификации.
дополнения и т.д.
Настройка приложений осуществляется централизованно – рассылка настроек с сервера на все клиенты.
Модель удаленного доступа к данным: назначение и описание
Н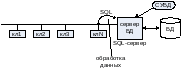 а
сервере устанавливается централизованная
БД, а обращения из клиентов осуществляются
(на получение данных) на языке SQL.
Возвращаются обработанные данные.
а
сервере устанавливается централизованная
БД, а обращения из клиентов осуществляются
(на получение данных) на языке SQL.
Возвращаются обработанные данные.
На SQL сервере устанавливается СУБД, которая ведет обработку поступающих от клиентов SQL-запросов. Т.о. в данном случае мы уменьшаем трафик сетевого обмена, т.к. по сети циркулирует SQL-запросы и обработанные данные. В существенной мере это по объему меньше, чем в модели файл-сервера. Однако, применительно к этой модели, наиболее узким звеном является SQL-сервер, т.к. он не только должен хранить централизованную БД, но и должен осуществлять обработку поступающих SQL-запросов. Поэтому к аппаратно-программируемой платформе SQL-сервера предъявляются повышенные требования по быстродействию. Определенная загрузка трафика будет иметь место, т.к. SQL-запросы могут занимать значительный объем.
Назначение и формат запросов на добавление, редактирование и удаление данных
DELETE FROM table
{[WHERE search_condition] }
[ORDER BY order_list]
UPDATE <объект>
SET <присваивание1 [, присваивание2, ...]>
[WHERE <условие>];
top(x) — команда выполнится только х раз
<объект> — объект, над которым выполняется действие (таблица или представление)
<присваивание> — присваивание, которое будет выполняться при каждом выполнении условия <условие>, или для каждой записи, если отсутствует раздел where
<условие> — условие выполнения команды
SET — после ключевого слова должен идти список полей таблицы, которые будут обновлены и непосредственно сами новые значения в виде
имя поля="значение"
Структура файла баз данных
состоит из заголовка, записей с данными и маркера "Конец файла"
Таб1 Структура заголовка.
-
Байт
Содержимое
Значение
0
1 байт
Правильный файл системы РЕБУС
03h CTRL-C нет примечаний
83h 128+^C есть примечания в файле .dbt
1-3
3 6айта
Дата последнего обновления ГГ ММ ДД
4-7
Int
Число записей в файле
8-9
Short
Число байт в заголовке
10-11
Short
Число байт в записи
12-14
3 байта
Резерв
15-27
13 байт
Резерв для локальной сети
18-31
14 байт
Резерв
32-nn
32*n
Вектор описания полей
Nn+1
1 байт
Конец векторов описания полей 0Dh, CTRL-M, ASCII 13
Таб2 Вектор описания поля. Длина - 32*N
-
Байт
Содержимое
Значение
0-10
char[11]
Имя поля (заполнено нулями)
11
1 байт
Тип поля ('C','N','L','D','M')
12-15
Int
Адрес поля данных ( формируется в памяти, на диске не используется)
16
1 байт (двоичный)
Длина поля
17
1 байт
Десятичный счетчик полей в двоичном коде
18-19
2 байт
Резерв для локальной сети
20
1 байт
ID рабочей области
21-22
2 байт
Резерв для локальной сети
23
1 байт
Флаг SET FIELDS
24-31
8 байт
Резерв
Структура записей с данными.
идут сразу за заголовком
Перед записью байт: ' ' 20h - запись существует.
' * ' 2Ah - запись удалена.
Поля в записи идут подряд.
Данные в полях хранятся в формате ASCII:
-
Значение
Тип
Содержимое
С
Символьный
N
Числовой
{ 0 - 9 }
L
Логический
{ Y y T t N n F f ? } да/нет/неизвестно
M
Примечание
10 цифр с номером блока в .dbt
D
Дата
ГГГГММДД
Признак конца файла - ASCII 26 (1Ah) CTRL-Z