

26.Uniprocessor scheduling.
The aim of processor scheduling is to assign processes to be executed by the processor or processors over time, in a way that meets system objectives, such as response time, throughput, and processor efficiency. In many systems, this scheduling activity is broken down into three separate functions: long-, medium-, and shortterm scheduling.The names suggest the relative time scales with which these functions are performed.
Long-term scheduling is performed when a new process is created. This is a decision whether to add a new process to the set of processes that are currently active.Medium-term scheduling is a part of the swapping function.This is a decision whether to add a process to those that are at least partially
in main memory and therefore available for execution. Short-term scheduling is the actual decision of which ready process to execute next.
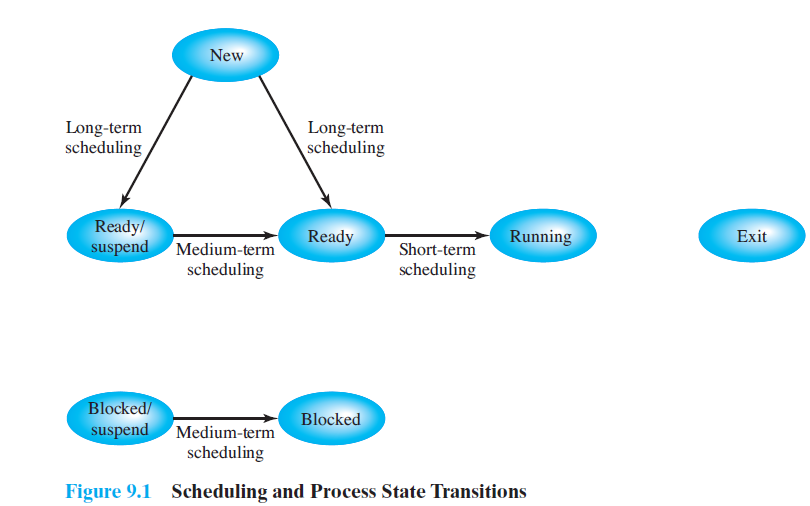
Scheduling affects the performance of the system because it determines which processes will wait and which will progress.This point of view is presented in. Fundamentally, scheduling is a matter of managing queues to minimize queuing delay and to optimize performance in a queuing environment.
27.Implementation of disk scheduling algorithms sstf, scan.
Shortest Service Time First The SSTF policy is to select the disk I/O request that requires the least movement of the disk arm from its current position.Thus, we always choose to incur the minimum seek time. Of course, always choosing the minimum seek time does not guarantee that the average seek time over a number of arm movements will be minimum. However, this should provide better performance than FIFO. Because the arm can move in two directions, a random tie-breaking algorithm may be used to resolve cases of equal distances.
With the exception of FIFO, all of the policies described so far can leave some request unfulfilled until the entire queue is emptied.That is, there may always be new requests arriving that will be chosen before an existing request. A simple alternative that prevents this sort of starvation is the SCAN algorithm, also known as the elevator algorithm because it operates much the way an elevator does.
With SCAN, the arm is required to move in one direction only, satisfying all outstanding requests en route, until it reaches the last track in that direction or until there are no more requests in that direction.This latter refinement is sometimes referred to as the LOOK policy. The service direction is then reversed and the scan proceeds in the opposite direction, again picking up all requests in order. the SCAN policy behaves almost identically with the SSTF policy. Indeed, if we had assumed that the arm was moving in the direction of lower track numbers at the beginning of the example, then the scheduling pattern would have been identical for SSTF and SCAN. However, this is a static example in which no new items are added to the queue. Even when the queue is dynamically changing, SCAN will be similar to SSTF unless the request pattern is unusual. Note that the SCAN policy is biased against the area most recently traversed. Thus it does not exploit locality as well as SSTF or even LIFO. It is not difficult to see that the SCAN policy favors jobs whose requests are for tracks nearest to both innermost and outermost tracks and favors the latest arriving jobs.The first problem can be avoided via the C-SCAN policy, while the second problem is addressed by the N-step-SCAN policy.