

3 Способа организации кэш:
Если каждый блок основной памяти имеет только одно фиксированное место, на котором может поместиться в кэш, то такой кэш называется кэшем с прямым отображением.
Если некоторый блок основной памяти располагается в любом месте кэша, то такой кэш называется полностью ассоциативным.
Если блок ОП может располагаться на ограниченном количестве мест в кэш, то такой кэш называется множественно-ассоциативным (частично-ассоциативный, n‑канальный).
Архитектура кэш-памяти. Прямое распределение информации в кэш-памяти.
Определение кэша с прямым отображением
Кэш с прямым отображением (direct mapped) - если каждый блок основной памяти имеет только одно фиксированное место в кэш-памяти.
Это наиболее простая организация кэш-памяти, при которой для отображение адресов блоков основной памяти на адреса кэш-памяти просто используются младшие разряды адреса блока.
Все блоки основной памяти, имеющие одинаковые младшие разряды в своем адресе, попадают в один блок кэш-памяти, т.е. (адрес блока кэш-памяти) = (адрес блока основной памяти) mod (число блоков в кэш-памяти)
Соответствие адресов ОП и памяти кэша

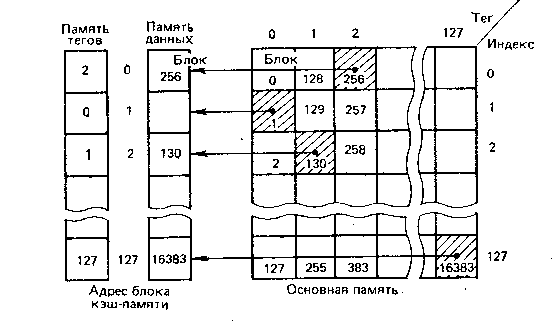
Кэш-память с прямым отображением состоит из памяти тегов и памяти данных. В идеале временные параметры и ёмкости у этих двух блоков совпадают. В соответствии с идеологией прямого отображения вся оперативная память делится на фиксированные области (количество областей совпадает с количеством адресов кэша), каждой из которых приписывается свой номер - индекс. Кроме того, вводится нумерация ячеек внутри блоков - каждой ячейке внутри блока присваивается свой тэг.
При записи в кэш ищем ячейку, адрес которой совпадает с индексом записываемой информации. После этого в память тэгов и память данных записываем соответственно тэг и данные, в соответствии с адресом ОП.
Чтение из КЭШа Пусть v (value) - данные, за которыми происходит обращение. Выбираем из переданного адреса индекс, и по этому индексу в теговой памяти находим предыдущее значение тэга. Далее, сравниваем предыдущее значение тэга с текущим значением, и если они совпадают, следовательно информацию в соответствующей ячейки памяти данных можно считать достоверной. Если не совпадают - ситуация кэш-промаха.
Недостатки:
Все блоки, находящиеся в одной и той же строке (с одинаковым индексом) не могут находиться в кэше одновременно. В то время как операция чтения соседних ячеек памяти является довольно распространённой.
Достоинства:
Простота реализации.
Архитектура кэш-памяти. Ассоциативное распределение информации в кэш-памяти.
Определения ассоциативных кэшей
Полностью ассоциативный кэш (fully associative) - если некоторый блок основной памяти может располагаться в любом месте кэш-памяти.
При полностью ассоциативной организации памяти, память логически неделима. То есть первые 14 старших разрядов адреса полностью адресуют тэг.
При записи в кэш-память. Выбираем любой "свободный" адрес памяти данных в кэш, переписываем по нему данные. Номер ячейки кэш, в которую были записаны данные, записываются в ассоциативную память данных (причём в качестве тэга будет записан адрес блока).
При чтении из кэш-памяти. В ассоциативной памяти просматриваем все записи и сравниваем тэги с текущим значением (путём полного перебора). Если найдена запись с искомым тэгом, считываем номер адреса кэша данных, где хранится искомая информация. Если запись не найдена, ситуация кэш-промаха. В случае кэш-попадания, по полученному адресу из памяти данных считываем искомые данные.
Кэш полностью ассоциативный: Соответствие адресов ОП и памяти КЭШа:


Недостатки: Ассоциативная память работает последовательно, поэтому ассоциативный кэш более медленный. Кроме того, ассоциативная память должна содержать в себе дополнительную информацию об адресах кэш-памяти данных. Эти дополнительные затраты делают ассоциативную кэш-память более дорогой.
Достоинства:Возможность одновременно держать в кэш-памяти соседние ячейки оперативной памяти (по сравнению с кэш-памятью с прямым отображением).
Архитектура кэш-памяти. Частично-ассоциативное распределение информации в кэш-памяти.
Множественно-ассоциативный кэш (set associative) - если некоторый блок основной памяти может располагаться на ограниченном множестве мест в кэш-памяти.
Если множество состоит из n блоков, то такое размещение называется множественно-ассоциативным с n каналами (n-way set associative). Для размещения блока прежде всего необходимо определить множество. Множество определяется младшими разрядами адреса блока памяти (индексом):
(адрес множества кэш-памяти) = (адрес блока основной памяти) mod (число множеств в кэш-памяти)
Блок может размещаться на любом месте данного множества.
В кэш-памяти с множественно-ассоциативным отображением осуществляется разделение блоков кэш-памяти и, соответственно, основной памяти на ряд множеств (групп). Для блоков ОП, принадлежащих одному множеству, реализуется принцип прямого отображения, то есть все блоки ОП из одного множества должны отображаться на определенное число блоков кэш-памяти соответствующего множества гораздо меньшей мощности. В свою очередь принцип отображения блоков ОП на блоки кэш-памяти внутри выбранного множества является ассоциативным: любой блок ОП, принадлежащий выбранному множеству, может помещаться на место любого блока кэш-памяти, принадлежащего соответствующему множеству.
При обращении к кэш-памяти из памяти тегов выбираются 4 тега блоков из одного множества (по одному из каждого банка) для параллельного сравнения с входным тегом из регистра адреса на компараторах CMP0 – CMP3. При совпадении одного из тегов блоков с входным тегом на выходе шифратора (кодера) формируется адрес банка для управления пересылкой данных между регистром данных и памятью данных через мультиплексор/демультиплексор. Банк соответствует столбцу памяти тегов и памяти данных. Каждый банк снабжается собственными схемами управления доступом, что допускает параллельное обращение ко всем банкам по одному адресу.
Соответствие адресов ОП и памяти КЭШа:


Стратегии обновления памяти и замещения (вытеснения) при кэшировании. Оценки затрат на дополнительное оборудование при реализации стратегий замещения.
Кэш-контроллер обязан обеспечивать коггерентность (coherency) - согласованность кэш-памяти с основной памятью. Допустим, к некоторой ячейке памяти, уже модифицированной в кэше, но еще не выгруженной в основную память, обращается периферийное устройство (или другой процессор) - кэш-контроллер должен немедленно обновить ОП, иначе оттуда прочитаются "старые" данные.
При чтении данных кэш-память даёт однозначный выигрыш в производительности. При записи данных выигрыш можно получить только ценой снижения надёжности.
Стратегия обновления ОП при записи:
1. Метод сквозной записи (write through) - обновляется слово, хранящееся в основной памяти. Если в кэш-памяти существует копия этого слова, то она также обновляется. Если же в кэш-памяти отсутствует копия этого слова, то либо из основной памяти в кэш-память пересылается строка, содержащая это слово (метод WTWA (write thru with allocation)– сквозная запись с распределением), либо этого не допускается (метод WTNWA (write thru not with allocation)– сквозная запись без распределения). При исполнении любой из модификаций при методе сквозной записи нет необходимости копировать удаляемый из кэш-памяти блок в ОП, так как его копия в ОП поддерживается актуальной.
2. Метод обратной записи (Write-Back ) – запись данных производится в кэш. Запись же в основную память производится позже (при вытеснении или по истечению времени). Модификация содержимого блока в кэш-памяти при обращении по записи не является причиной изменения копии этого блока в ОП. При обращении по записи к блоку, отсутствующем в кэш-памяти, обязательно осуществляется пересылка блока из ОП в кэш-память с последующей его модификацией только в кэш-памяти. Метод WB требует копирования блока из кэш-памяти в ОП только в момент удаления блока из кэш-памяти, то есть когда этот блок становится кандидатом на удаление.
- SWB (simple write-back - простая обратная запись) требует обязательной пересылки блока из кэш-памяти в ОП при его удалении из кэш-памяти, независимо от того, подвергается ли он модификации за время своего нахождения в кэш-памяти.
- FWB (flag write-back - флаговая обратная запись) предусматривает наличие специального флага модификации (UPDATE) у каждого блока. Установка этого флага производится при обращении к блоку по записи. При удалении блока из кэш-памяти его копирование в ОП осуществляется только при установленном флаге модификации.
Стратегия замещения: способ определения строки, удаляемой из кэш-памяти,
- метод LRU (замещение наименее используемой информации, наиболее давней): среди строк, являющихся объектами замещения, выбирается строка, к которой наиболее длительное время не было обращений. Общая реализация этого метода требует сохранения «бита возраста» для строк кэша и за счет этого происходит отслеживание наименее использованных строк (то есть за счет сравнения таких битов). В подобной реализации, при каждом обращении к строке кэша меняется «возраст» всех остальных строк.
Виды: True LRU, Pseudo LRU: упрощенная модификация LRU, в которой примерно в трети случаев в качестве кандидата на удаление выбирается предпоследний блок в цепочке обращений, Modified Pseudo LRU.
- метод FIFO (первым пришёл – первым вышел): среди всех строк, являющихся объектами замещения, выбирается та, которая самой первой была переслана в кэш-память.
- метод произвольного замещения: строка выбирается произвольно.
Реализация этих методов упрощается в указанной последовательности, но наибольшим эффектом обладает метод замещения наиболее давнего по использованию объекта (строки).
Пример: реализация механизма старения на основе матрицы старения. Есть: 4 ячейки КЭШа, в которую может отобразиться 4 ячейки ОП.
- LFU – based: подсчитывает как часто используется элемент. Те элементы, обращения к которым происходят реже всего, вытесняются в первую очередь. Виды: LFU, FBR (Frequency Based Replacement)
5 .Смешанные:
LRFU, 2Q / MQ, LIRS (Low Inter-reference Redundancy Set), ARC
(Adaptive Replacement Cache)
.Смешанные:
LRFU, 2Q / MQ, LIRS (Low Inter-reference Redundancy Set), ARC
(Adaptive Replacement Cache)
Классификация стратегий замещения
1. По принципу замещения
- Недетерминированные
- По давности использования
- По частоте использования
- Смешанные
- Другие
2. По типу реализации
- Аппаратно реализуемые
- Программно реализуемые
Затраты на оборудование в LRU, PLRU и MPLRU
N – количество слоев
--LRU: F(N) = (N-1)*N/2;
--PLRU: F(N)=N-1;
--MPLRU: F(N)=3*N/2 – 2;
Суперкомпьютер: определение, области применения, обобщенные характеристики современных супер-ЭВМ. ТОР500 и ТОР50.
Суперкомпьютеры – это компьютеры общего назначения, т.е. программируемые на выполнение любой прикладной задачи. СК должен выполнять большие вычислительные задачи быстрее коммерческих систем. Производительность СК оценивается на операциях с плавающей точкой: Mflops, Gflops, Tflops, Pflops…
Суперкомпьютеры применяются для решения интенсивных вычислительных задач, таких как проблемы в области квантовой физике или механической физике, прогноз погоды, исследование климата, молекулярное моделирование, физические моделирования (такие как моделирование самолетов, моделирование взрыва ядерного оружия, и исследование относительно ядерного сплава), криптоанализ.
TOP500 List - November 2011: Rmax and Rpeak values are in TFlops.
1. “K Computer” , созданный компанией Fujitsu, на процессорах SPARC64 VIIIfx 2.0GHz и имеющий 705024 процессорных ядер, 1 410 048 Gb оперативной памяти, потребляющий при этом 12 659.89 Квт, и в 4 раза опережающий по уровню производительности своего соперника по второй строке. Победитель рейтинга расположен в Институте Вычислительных наук при научно-исследовательском центре RIKEN в Японии и работает с протрясающей, на сегодняшний день, производительностью в 10,51 Петафлопс, согласно измерениям бенчмарка Linpack.
Суперкомпьютер K Computer является первым в мире вычислителем, преодолевшим рубеж в 10 Петафлопс, или 10 квадриллионов операций с плавающей запятой в секунду.
2. китайский компьютер Tianhe-1A установленный в Национальном Суперкомпьютерном Центре, созданный на процессорах Xeon X5670 6C 2.93 GHz с ускорителями NVIDIA 2050
3. американский суперкомпьютер Cray XT5-HE или Jaguar, созданный на шестиядерных 2,6-ГГц -овых процессорах AMD Opteron. Он установлен в Национальной лаборатории Окриджа и его производительность по Linpack составляет 1,75 Петафлопс.
4. разработанный китайской компанией Dawning Information Industry, суперкомпьютер состоит из блейд-серверов TC3600, построенных на базе процессоров Intel Xeon 5650 и графических ускорителей NVIDIA Tesla C2050. Создатели заявляют, что возможностей масштабирования архитектуры хватит для достижения показателя в 3 петафлопс, в то время, как нынешний лидер может улучшить результат «всего» до 2,3 петафлопс.

ТОР-50 России:15-ая редакция от 20.09.2011

«Зацепление» команд. Архитектура векторного блока супер-ЭВМ CYBER-205. Особенности ее конвейеров, обеспечивающие механизм “зацепления команд”.
Архитектура векторного процессора Cyber 205
Особенностью векторного блока является реализация механизма зацепления команд используется в том случае, если вновь вычисленный операнд (результат предыдущей операции) является аргументом для операции следующей:A=B+C; D=A+E
В общем случае мы получаем, что полученные данные прогоняются через буферную память, затем по соответствующим каналам записываются в память. Затем через несколько тактов эти же данные читаем из памяти, прогоняем по всем каналам в векторный блок и предоставляем в качестве операнда. На этих пересылках теряется очень много времени. Для того, чтобы этого избежать, созданы аппаратно-программные средства, обобщённо называемые "механизмом зацепления команд".
Каждый из 4-х процессоров представляет собой коммутатор ("обменник") и 5 исполнительный конвейеров.
Э тот
блок работает следующим образом:
результаты выполнения команды из
конвейеров попадают опять в коммутатор.
Таким образом, есть возможность подачи
результатов на другой конвейер - минуя
процедуру записи в оперативную память.
Более того - при необходимости можно
задержать данные на несколько тактов
с помощью устройства задержки. Для
реализации этого механизма (на уровне
векторных команд), вCyber-205
было создано:
тот
блок работает следующим образом:
результаты выполнения команды из
конвейеров попадают опять в коммутатор.
Таким образом, есть возможность подачи
результатов на другой конвейер - минуя
процедуру записи в оперативную память.
Более того - при необходимости можно
задержать данные на несколько тактов
с помощью устройства задержки. Для
реализации этого механизма (на уровне
векторных команд), вCyber-205
было создано:
На уровне архитектуры:
На уровне общей архитектуры. Реализация обмена входными и выходными данными конвейеров через единый коммутатор. Возможность задержки данных на несколько тактов с помощью устройства задержки.
На уровне исполнительных конвейеров.(см.рис) Прежде всего, конвейеры сложения и умножения. Особенность: введены 2 типа обратных связей.
Накопление операций суммирования (для сложения в каждом такте).
Общая обратная связь. Когда результат операции (например, операции сложения) через определённую задержку (которой мы можем управлять программно) подаём результат на вход вместо одного из операндов.
Поддержка на уровне программных решений.
Для векторных процессоров механизм зацепления команд актуален, т.к. потери на пересылку больших массивов данных велики.
Архитектура Cyber 205:


Особенность реализации исполнительных конвейеров (на примере конвейера сложения):
Конвейер сложения векторного блока Cyber 205:
Определение конвейера. Таблица занятости. Классификация конвейеров. Временная организация и производительность конвейерных систем. Понятие “латентности”.
Конвейер - это цепочка исполнительных устройств. Команда, попав на вход конвейера, проходит все эти устройства. В общем случае, на одной ступени может выполняться только одно действие. То есть невозможно на одном АЛУ одновременно выполнять два суммирования, но зато можно в этот момент считать следующую инструкцию.
Идеальный конвейер (одновременно):
каждое вычисление базовой функции независимо от предыдущего;
вычисление каждой функции требует одной и той же цепочки подфункций;
подфункции тесно связаны между собой (вход одной является выходом предыдущей);
в
 ремена
вычислений различных подфункций
приблизительно равны.
ремена
вычислений различных подфункций
приблизительно равны.
Простейший конвейер: Параллелизм и конвейеризация


Tпосл ~ Снс – время одной операции.
Tконв ~ С/N, где N-число ступеней конвейера.
Таблица занятости: строки = кол-во ступеней конвейера, столбцы = такты синхронизации ступеней конвейера.
П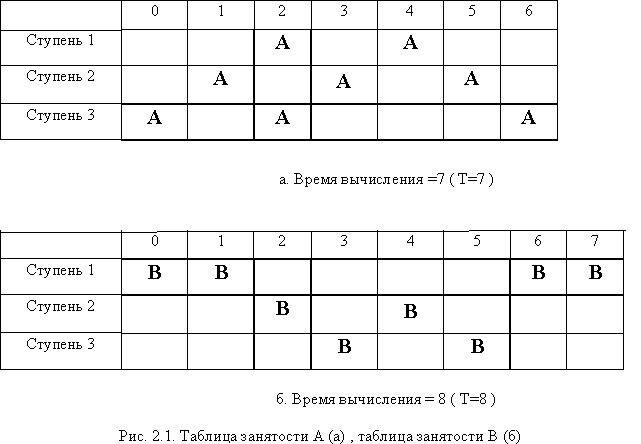 ример
конвейерного выполнения команд сложения:
ример
конвейерного выполнения команд сложения:
1) IFETCH – извлекатся СК и выбирается очередная команда из памяти
2) DECODE – декодирование ком-ды
3) EAGEN – выработка адреса в память для операндов
4) OPER FETCH1 – выборка 1-го операнда
5) OPER FETCH2 выборка 2-го операнда
6) EXEC – выполнение операции
7) SAVE – сохранение результатов
8) END OP – завершение операции (модиф. СК, выработка слово-состояния, установка флагов …)
Классификация конвейеров:
1. Однофункциональный: статический
2. Многофункциональный: динамический, статический
Временная организация, управление и производительность
Эффективное использование конвейера требует своевременной подачи на его вход исходных данных. Без такого потока последовательные ступени конвейера работают вхолостую и соответственно падает производительность системы. Также нужно тщательно определить диспетчеризацию - моменты времени, в которые каждая входная величина вводится в конвейер, чтобы гарантировать и высокую производительность, и отсутствие внутренних конфликтов.
Таблица занятости:
- В процедурах диспетчеризации предполагают, что точная схема использования ступеней известна для каждой входной величины до ее запуска в конвейер. Эти схемы могут быть описаны в виде двумерных таблиц, известных как таблицы занятости ( ТЗ ). Одна такая таблица представляет в точности одну схему, используемую для одной входной величины.
- Инициация таблицы занятости наступает тогда, когда начинается вычисление, которое проследует по определенному ею пути.
- Таким образом, инициация соответствует началу вычисления отдельной функции.
Свойства ТЗ:
- Одна таблица занятости может содержать несколько меток в одной строке или в одном столбце. Несколько меток в одной строке представляют либо неоднократное использование этой ступени на протяжении одного вычисления функции, либо, если метки занимают смежные графы, такую ступень, которая работает медленнее остальных.
- Точно так же допустимо иметь несколько меток в одном столбце, они представляют использование многих ступеней в один момент времени. Это соответствует введению параллелизма в вычисление функции.
Латентность ( Latency ):
- Ключевым параметром к определению производительности конвейера является латентность, т.е. число единиц времени, разделяющих инициации одной или различных таблиц занятости.
- Латентность может иметь любое неотрицательное значение, включая 0.
“Жадная” стратегия. Понятие MAL в теории конвейера. Лемма для статических конвейеров. Введение задержек для увеличения производительности конвейеров.
Жадная стратегия – стратегия, которая всегда между двумя инициациями вводит минимальную из латентностей, возможных в текущий момент времени.
Загружаем конвейер так: - сразу, как только такая возможность появилась - и это не приведёт к заторам на конвейере.
В нулевом такте начинает выполняться первая операция (Б1). Этот момент отмечен первой стрелкой снизу. Теперь ждём, когда можно будет загрузить вторую операцию (Б2).В нулевом и первом такте не можем, т.к. первая ступень уже занята операцией Б1, а во втором не можем потому, что это приведёт к затору на второй ступени в четвёртом такте (там выполняется ещё первая команда, а уже должна начинать вторая). Итак, загружаем Б2 в третьем такте. Эта операция отмечена второй стрелкой под таблицей. Теперь на конвейере выполняются Б1 и Б2.
А когда мы можем загрузить следующую, Б3? Как видим, только на 11 такте, конвейер при этом уже будет полностью пустой, и всё повторится.
Латентность: сколько времени нам надо ждать, прежде чем запихнуть на конвейер следующую команду? Ответ - 3 такта для второй команды (после загрузки первой), и 8 тактов - для загрузки третьей (после второй). Далее - циклично, для 4-й команды 3 такта, для 5-й команды 8 тактов... Поэтому записываем в угловых скобках: L=<3,8>. Среднее значение, можно получить как (3+8)/2.


«Терпеливая» стратегия для В
В соответствии с "Терпеливой" стратегией мы не загружаем следующую операцию сразу, как только можем, а немного ждём. На рисунке видим, что полного освобождения конвейера (как в случае "жадной") не происходит, ресурсы конвейера распределяются оптимальнее и латентность (средняя) оказывается меньше, несмотря на то, что вторая команда загружается не через 2, а через 4 такта.
Лемма для статического конвейера
Для любого конвейера со статической конфигурацией, реализующего некоторую таблицу занятости, величина MAL всегда > или = MAX числу меток в любой строке этой таблицы.
MAL - Минимальное Среднее значение Латентности. Т.е. это количество тактов, которое мы должны подождать, прежде чем загрузим на конвейер следующую инструкцию. Почему оно не меньше числа "крестиков" в каждой ступени конвейера, я думаю, понятно. Если у нас есть операция, которая выполняется за 3 такта, и все 3 такта первая ступень занята, то независимо от всех остальных ступеней мы не сможем загрузить в конвейер ничего другого, пока эти 3 такта не пройдут, иначе будут столкновения. Почему MAL может оказаться больше - тоже понятно. Может оказаться так, что операция выполняется 10 тактов, а в каждой ступени по 5 действий, но если запустить следующую операцию даже через 5 тактов, всё равно произойдут столкновения. Это должно быть понятно из того, что я написал выше. Как средняя латентность может быть минимальной? Для "Жадной" стратегии средняя латентность у операции В оказалась 5,5, а для "Терпеливой" она 4. Вот 4 и есть минимальная средняя латентность.
Введение задержек для увеличения производительности:


Теория конвейера: вектор столкновений. Диаграмма переходов. Пример.
В каждом состоянии закодирована информация, называемая вектором столкновений. Такой вектор является d-разрядной двоичной последовательностью, где d — время вычисления для таблицы занятости. При этом d разрядов нумеруются от 0 до d-1 слева направо; 0 в i-й позиции означает, что у инициации, начатой через i единиц времени после текущего момента, не будет столкновений ни с одной из незавершенных в текущий момент инициации, а 1 означает, что столкновения будут и поэтому инициация должна быть запрещена.
Д иаграмма
состояний для операции В: Диаграмма
состояний для операции А
иаграмма
состояний для операции В: Диаграмма
состояний для операции А

Теперь посмотрим, как формально показать, что будет, если загружать следующую инструкцию в разные такты. Для этого введём вектор столкновений. Это вектор из единиц и нулей. Длина вектора равна числу тактов выполнения операции. Например, если в третьей позиции этого вектора 0, то мы можем запустить в конвейер следующую операцию, и ни на одной ступени столкновений не произойдёт. Любая операция выполнится за фиксированное число тактов, равное длине вектора (столкновений-то нет). Если в этой позиции 1, то в этом такте начинать загружать на конвейер следующую операцию нельзя. Смотрим рис. 2.4. Основной здесь - квадратик "Начальное состояние": 11100111. Таким образом, мы можем запустить вторую инструкцию в третьем, четвёртом такте. Либо в 8-м, когда конвейер будет уже пуст. В последнем случае мы попадаем в то же самое состояние. Это стрелка ">=8". Т.е. мы можем запустить следующую операцию и в 8, и в 9, и в 10 такте, это уже ничего не изменит, конвейер будет пуст. Стрелка "3" соответствует запуску следующей команды в 3-м такте (см. рис. "Жадная" стратегия). В этом случае (как мы уже видели) следующая команда может быть загружена только после полного освобождения конвейера, через 8 тактов. Снова попадаем на пустой конвейер. Стрелка "4" соответствует "Терпеливой" стратегии. Из этого (11110111) состояния есть два пути. Можно загружать каждую следующую инструкцию через 4 такта после предыдущей (см. "Терпеливую" стратегию), либо ждать освобождения конвейера, снова попадая в Начальное состояние. Таким образом, из каждого состояния выходит N+1 стрелка, где "N" - число нулей, а "+1" - это переход в Начальное состояние.

Векторные процессоры: определение, 2 типа векторных процессоров, архитектура аппаратных средств, особенности системы команд. Примеры архитектуры векторных процессоров.
Векторный процессор— это процессор, в котором операндами некоторых команд могут выступать упорядоченные массивы данных — векторы. Отличается от скалярных процессоров, которые могут работать только с одним операндом в единицу времени. Стандартные векторные процессоры выполняют операции над векторами очень большой размерности.
В средствах векторной обработки под вектором понимается одномерный массив однотипных данных (обычно в форме с плавающей запятой). Если обработке подвергаются многомерные массивы, их также рассматривают как векторы.
Векторный процессор может быть реализован в двух вариантах:
- дополнительный блок к универсальной ВС.
- основа самостоятельной ВС.
Первая архитектура, отличная от однопроцессорной появилась в конце 1960-х. Векторные процессоры - основа первых супер-ЭВМ. Основные области применения - задачи, в которых данные были бы записаны в матричной форме (прогноз погоды, ядерная физика).
Пути построениявекторных процессоров:
1. программный: пишется специальная библиотека программ, выполняющих векторные операции, ориентированная под конкретную имеющуюся платформу;
2. аппаратный: проектируется сначала скалярный компьютер+добавляются микрокоды векторных операций
3. изначально разрабатывалась векторная машина (с векторными командами).
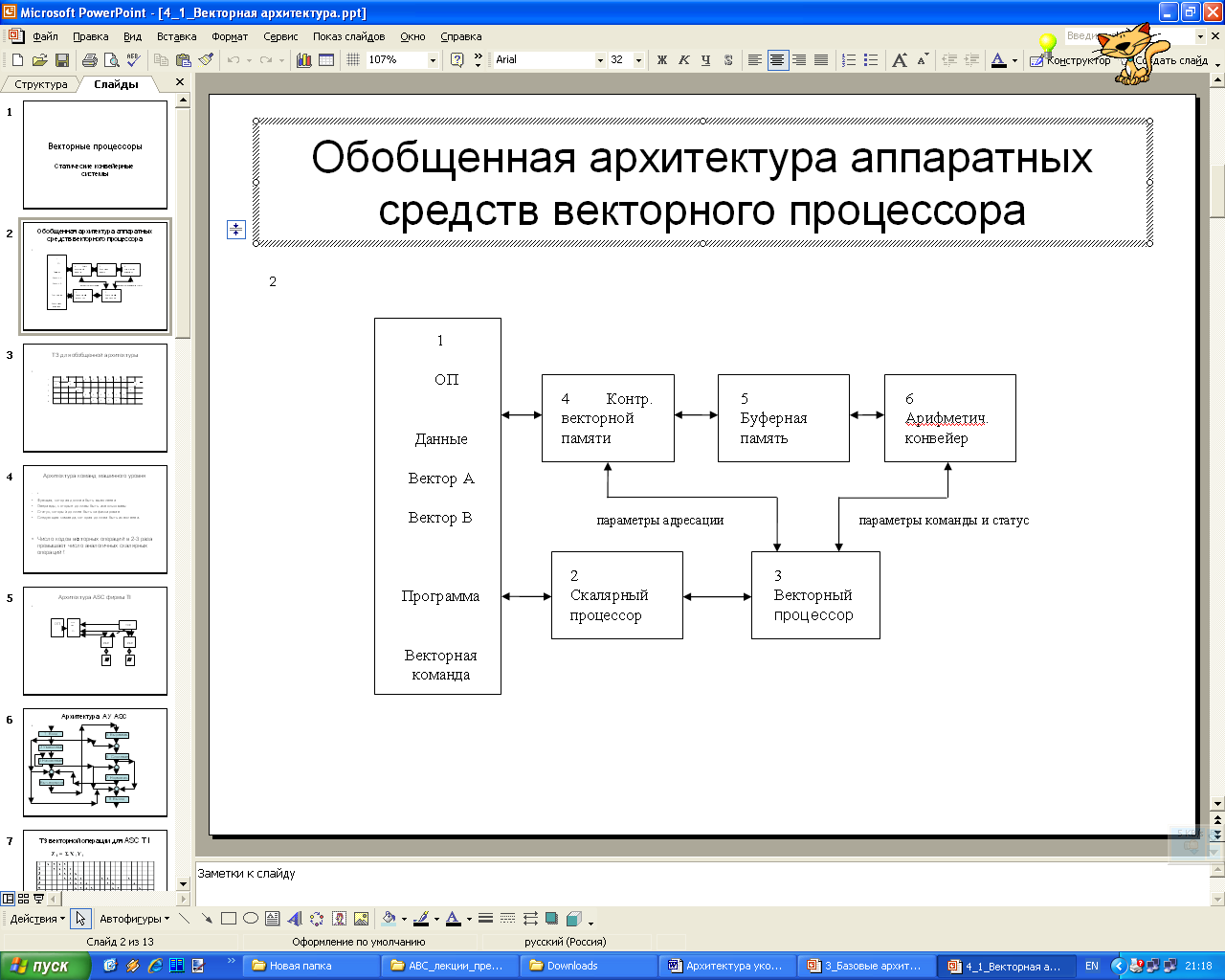
Архитектура аппаратных средств:
Оперативная память. Это общее название включает в себя не только непосредственно оп-это может быть достаточно сложная иерархическая структура, включающая кэши и регистры. Причём, регистров может быть достаточно много - кроме скалярных, есть векторные регистры для хранения массивом. Быстродействие памяти во многом лимитирует быстродействие всего векторного процессора. Система памяти - это самая сложная подсистема векторного процессора. Для векторных компьютеров определён принцип расслоения памяти (для того, чтобы обеспечить суммарное быстродействие). Принцип расслоения памяти применяется и в обычных ПК, но там коэффициент расслоения небольшой. А в векторных процессорах коэффициент расслоения самый высокий на фоне других систем: 64, 128, 256. Всё это делается для того, чтобы запросное число (количество данных, поступающих из памяти за один цикл обращения) было как можно больше (хотя бы порядка ~ 100 или нескольких сотен). Требования к оперативной памяти достаточно высоки.
Скалярный процессор. Выполняет все функции обычного процессора (обрабатывает поток команд и имеет все необходимые устройства для выполнения скалярных операций) + дополнительные функции: распознавая наличия векторной команды (передаёт её векторному процессору (3)).
Векторный процессор. Базовые функции векторного процессора (при получении векторной команды):
Декодирование
Выработка системы сигналов для арифметического конвейера (6). Функция - выбор исполнительного устройства.
Вычисление логических параметров адресации (адресация к вектору).
Сопровождение выполнения операции.
Анализ состояния (по завершению операции).
Контроллер векторной памяти. На основе логических адресов векторов выдаёт последовательность адресов для обращения к физической памяти чтение/запись результата. Передаёт в буферную память (5).
Буферная память. Пассивное устройство. Нужно, т.к. поступают данные не равномерно во времени, а выдаются данные синхронно.
Арифметический конвейер. Один или несколько конвейеров, выполняющих векторные операции. Это может быть либо сложный конвейер (настраиваемый), либо набор конвейеров.
Т аблица
занятостидля
обобщенной архитектуры:
аблица
занятостидля
обобщенной архитектуры:
А - выборка векторной команды
В - передача векторной команды и её декодирование векторным контроллером.
С - начальная выборка данных (запись/чтение)
D - выполнение команды
E - окончательное запоминание (запись) - может занимать большое количество тактов.
F - завершение операции - очистка буферов/регистров, выставление признаков состояния.
Архитектура команд машинного уровня
Функция, которая должна быть выполнена
Операнды, которые должны быть использованы
Статус, который должен быть зафиксирован
Следующая команда, которая должна быть исполнена.
Число кодов векторных операций в 2-3 раза превышает число аналогичных скалярных операций!
Система команд векторного процессора поддерживает работу с векторными регистрами и обязательно включает в себя команды:
загрузки векторного регистра содержимым последовательных ячеек памяти, указанных адресом первой ячейки этой последовательности;
выполнения операций над всеми элементами векторов, находящихся в векторных регистрах;
сохранения содержимого векторного регистра в последовательности ячеек памяти, указанных адресом первой ячейки этой последовательности.
Примеры: Архитектура VP-200 фирмы Fujitsu, Архитектура векторного процессора S-810 Hitachi
Архитектура векторного процессора SX-4,5,6,7,8 фирмы NEC, Архитектура АУ ASC
Системы хранения данных. Требования к СХД и задачи СХД. Концепция многоуровневых хранилищ данных. Классификация СХД.
Центр (хранения и) обработки данных (ЦОД/ЦХОД) — это специализированное здание для размещения серверного и коммуникационного оборудования и подключения абонентов к каналам сети Интернет. Дата-центр исполняет функции обработки, хранения и распространения информации.
Структура Центра Обработки Данных (ЦОД / Datacenter):
- Аппаратное и ПО
- Серверный комплекс
- СХД
- Системы управления и мониторинга
- Системы информационной и физической защиты
- Сетевая инфраструктура
- Инженерная инфраструктура
- Организационная инфраструктура (персонал+регламентирующая документация)
Системы хранения данных (СХД) – комплексное программно-аппаратное решение по организации надёжного хранения данных и предоставления гарантированного к ним доступа.
Требования к современным системам хранения данных:
- Требования к надежности хранения данных
- Требования к надежности доступа к данным
- Требования к объему хранимых данных
- Требования к скорости доступа к данным
- Требования к защищенности доступа к данным
- Требования к сложности управления и конфигурирования
Задачи системы хранения данных:
1. Соединение (Connecting) – обеспечение передачи данных между вычислительными системами и хранилищами
- шины (ATA, SCSI,..), точка-точка (FCPP,..)
- коммутируемые среды Fibre Channel, Ethernet,..
2. Хранение (Storing) – низкоуровневое взаимодействие систем и устройств хранения при помощи специальных команд и протоколов направленное на сохранение данных
- Модель взаимодействия: инициатор – цель
- Блочный ввод/вывод
- Понятие адресного пространства: область доступных адресов для данного устройства
3. Упорядочивание (Filing) – определение места объектов данных в хранилище и предоставление данных приложениям и пользователям
- Выделение места под объекты хранения
- Файловый ввод/вывод
- Управление доступом на уровне объектов хранения
Многоуровневая архитектура систем долговременного хранения данных:
Уровень 0 – Performance: Твердотельные накопители (Flash/DRAM/Hybrid)
Уровень 1 – Default: Fibre Channel HDD или SAS HDD
Уровень 2 – Cost focused: Serial ATA HDD
Уровень 3 – Capacity optimized: Сжатые или дедуплицированные данные на SATA HDD / Кассетные накопители
Подходы к реализации систем хранения данных (10 лет назад): DAS, SAN, NAS
Подходы к реализации систем хранения данных (современность):
1. Непосредственно подключаемые системы (DAS)
2. С использованием сетевых технологий:
- С использованием IP-сетей: IP SAN (представляет собой архитектурное решение для подключения внешних устройств хранения данных, таких как дисковые массивы, ленточные библиотеки, оптические приводы к серверам таким образом, чтобы операционная система распознала подключённые ресурсы как локальные.), NAS (специализированное устройство, служащее в качестве выделенного высокопроизводительного шлюза для доступа к разделяемым данным на файловом уровне через сетевую среду общего назначения, как правило, посредством сетевой файловой системы.), CAS (для хранения и организации доступа к данным с неизменным содержимым с учетом специальных требований по безопасности данных, времени хранения данных и доступу к данным. Адресация объектов данных осуществляется не по имени, а по содержанию с использованием алгоритмов хеширования.), COS
- FC SAN: FCoE SAN
- Унифицированные
3. Virtual Appliance - предоставляет возможности виртуализации хранилищ и сетей хранения (SAN).
Системы хранения данных. Основные подходы к реализации СХД. Подходы DAS и SAN (FC, FCoE, IP).
Системы хранения данных (СХД) – комплексное программно-аппаратное решение по организации надёжного хранения данных и предоставления гарантированного к ним доступа.
Подходы к реализации систем хранения данных (10 лет назад):
DAS, SAN, NAS
1 .
Непосредственно подключаемые системы
(DAS)
.
Непосредственно подключаемые системы
(DAS)
2. С использованием сетевых технологий:
- С использованием IP-сетей: IP SAN, NAS (специализированное устройство, служащее в качестве выделенного высокопроизводительного шлюза для доступа к разделяемым данным на файловом уровне через сетевую среду общего назначения, как правило, посредством сетевой файловой системы.), CAS (для хранения и организации доступа к данным с неизменным содержимым с учетом специальных требований по безопасности данных, времени хранения данных и доступу к данным. Адресация объектов данных осуществляется не по имени, а по содержанию с использованием алгоритмов хеширования.), COS
- FC SAN: FCoE SAN
- Унифицированные
3. Virtual Appliance - предоставляет возможности виртуализации хранилищ и сетей хранения (SAN).
DAS - Direct Attached Storage (самая первая технология хранения данных) - непосредственно подключенное (присоединенное) хранилище данных (по каналу SAS, режим точка-точка) - в простейшем случае – жесткий диск подключенный к контроллеру на материнской плате.
Доступность данных зависит от работоспособности всех компонент на пути от потребителя к хранилищу (рис).
Традиционная клиент-серверная архитектура вычислений с DAS:
- Не отвечает современным требованиям для систем высокой надежности
- Не отвечает современным требованиям по объему хранимых данных
- Может применятся в серверных решениям начального уровня
Недостатки DAS-хранилищ:
- Ограничение на длину соединений (Проблем: надежного хранения данных+монтажа оборудования)
- Наивысшая стоимость обслуживания
- Проблема с балансировкой ресурсов
- Проблема масштабируемости
Применение DAS:
В серверных системах начального уровня (SOHO): Единицы серверов+Не требуется доступность системы в режиме 24/7:
+ относительно невысокая стоимость
+ относительная простота управления и администрирования
+ простота создания архивных копий в случае одного сервера
SAN – Storage Area Network - сети хранения данных: строятся на базе специализированного оборудования и интерфейсов, снимают проблемы DAS-хранилищ
S AN
– сеть,
предназначенная в первую очередь для
обмена данными между системами хранения
данных и вычислительными системами, а
также обеспечивает безопасную и надежную
пересылку данных.
AN
– сеть,
предназначенная в первую очередь для
обмена данными между системами хранения
данных и вычислительными системами, а
также обеспечивает безопасную и надежную
пересылку данных.
SAN - представляет собой архитектурное решение для подключения внешних устройств хранения данных, таких как дисковые массивы, ленточные библиотеки, оптические приводы к серверам таким образом, чтобы операционная система распознала подключённые ресурсы как локальные. Применение: на больших предприятиях.
Состав:
-коммуникационная инфраструктура,
-управляющая инфраструктура.
Типы SAN:
1. Fibre Channel (..,4, 8, 10, 16,.. Гбит/с) - волоконный канал) — семейство протоколов для высокоскоростной передачи данных. Стандартизацией FC используется как стандартный способ подключения к системам хранения данных уровня предприятия. Fibre Channel Protocol — транспортный протокол, инкапсулирующий протокол SCSI по сетям Fibre Channel.
-FCoE (10,.. Гбит/с): Fibre Channel over Ethernet - это протокол, утвержд. в 2009г. FCoE переносит фреймы Fibre Channel через Ethernet, инкапсулируя кадры Fibre Channel в jumbo frames Ethernet-а.
2. IP: iSCSI (Internet SCSI) (1, 10,.. Гбит/с): Internet Small Computer System Interface — протокол, который базируется на TCP/IP и разработан для установления взаимодействия и управления системами хранения данных, серверами и клиентами.
Системы на основе iSCSI могут быть построены на любой достаточно быстрой физической основе, поддерживающей протокол IP, например Gigabit Ethernet или 10G Ethernet. Использование стандартного протокола позволяет применять стандартные средства контроля и управления потоком, а также существенно уменьшает стоимость оборудования по сравнению с сетями Fibre Channel.